在 UniPi"先想象视频、再解码动作"的地基上,VLP 引入视觉语言模型做分层子目标提议与价值打分,再用树搜索把长程任务一步步推演出来------专治视频世界模型"一口气画长片就翻车"的误差累积顽疾。
上一篇我们讲了 UniPi:它把决策变成"拍一段执行视频 + 用逆动力学读出动作",奠定了级联式 WAM 的基本盘。但 UniPi 有个绕不开的软肋------让它一口气生成一段长视频去完成长程任务,画着画着就跑偏了:物体瞬移、凭空消失、动作前后矛盾。短任务还行,任务一长,错误像滚雪球一样越滚越大。
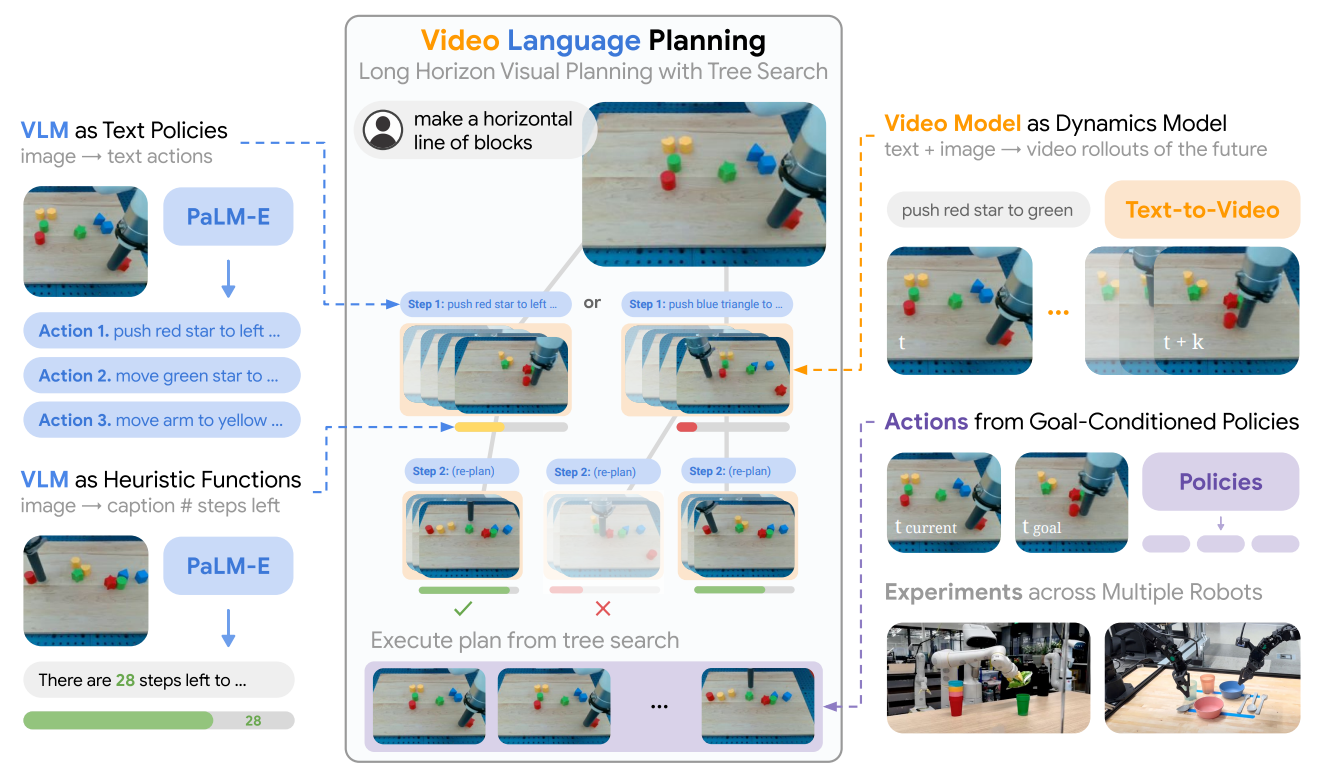
VLP(Video Language Planning,视频语言规划)就是冲着这个痛点来的。它发表在 ICLR 2024,作者班底和 UniPi 高度重合(Yilun Du、Mengjiao Yang 等),外加 Google DeepMind 的一票机器人研究者(Pete Florence、Andy Zeng 等)。一句话概括它的进步:与其赌一把生成完美长视频,不如把长任务拆成一连串短目标,每走一步都'想几种可能、评一评分、挑最好的留下',像下棋一样搜索出一条靠谱的长程计划。
一、要解决什么问题:长程任务里的"误差雪崩"
先用生活场景把痛点讲透。
假设你让机器人"把桌上一堆积木摆成一条直线"。这不是一个动作能搞定的,而是一长串:先挪这块、再推那块、调整间距、对齐边缘......这叫长程任务(long-horizon task)。
UniPi 式的做法,是让视频模型一次性想象出从乱到整的完整过程 。问题在于,视频生成模型对物理的把握并不精确------它可能在第 5 秒让一块积木悄悄消失,在第 8 秒让另一块瞬移到桌子另一头。短视频里这种小毛病不致命,可一旦视频拉长到几十上百帧,早期的一点点偏差会被后续生成不断放大 ,最终整段"计划"面目全非。这就是误差累积(compounding error),是所有自回归/长序列生成模型的通病。
打个比方:让一个人闭着眼睛凭想象一口气画完一幅复杂的工笔画,越画到后面越离谱;但如果让他画一笔、睁眼看一眼、不对就擦掉重画,最后这幅画就靠谱多了。VLP 干的就是后面这件事------给"闭眼想象"的视频模型,配上一双"睁眼检查、随时回退"的眼睛。
二、核心思想与直觉:把"模型"凑成"三个角色"
VLP 的精髓,是把现成的两类大模型拆解复用成三个不同角色 ,再用一套树搜索把它们串起来。它依然是级联式 WAM(先规划出视频、再解码出动作),但在"规划"这一层做得远比 UniPi 精细。
三个角色分别是:
-
VLM 当"策略"(提议者) :视觉语言模型(VLM,能同时看图、读文字并理解二者关系的大模型)看一眼当前画面和最终目标,提议出"下一步应该做的那个抽象子动作",并且用自然语言 描述出来(比如"把红色积木向右移")。注意,它提议的是一句文字指令,不是低层电机指令。
-
文本到视频模型当"动力学"(推演者) :拿到这句子动作文字,一个文本到视频模型 就把它"演"出来------从当前画面出发,生成一小段(最多约 16 帧)"执行这个子动作后世界会变成什么样"的短视频。它扮演的是世界模型 / 动力学模拟器的角色:给一个动作,预测未来状态。
-
VLM 当"价值函数"(打分者) :同一个 VLM 换个用法,对推演出来的新画面打分------估计"从这个状态出发,还差几步能到目标" 。剩的步数越少,说明这一步走得越好,价值越高。这就是一个启发式价值函数(heuristic value function)。
有了"提议---推演---打分"这三件套,长程规划就变成了一个再经典不过的树搜索(tree search)问题:从当前状态出发,提议几个候选动作(树的分叉),各自推演出后续画面(生成子节点),用价值打分挑出有希望的分支,剪掉没希望的,再往下展开......如此反复,最终搜出一条从起点贯通到目标的长视频计划。
这套设计的妙处在于:误差被"切片"了。每一步只生成一小段短视频(短视频里误差还来不及放大),生成完立刻用价值函数体检一遍,走歪的分支当场剪掉。于是长程任务被分解成一连串"短生成 + 即时纠错",误差雪崩从根上被遏制住。
三、方法详解:那棵"会剪枝的树"到底怎么长
3.1 三个角色各自怎么实现
VLM 策略 πᵥₗₘ(x, g) → a :输入当前图像 x 和目标 g,输出一句抽象子动作文字 a。实现上有两种路子:要么用少样本提示(给几个动作标注的例子让它照葫芦画瓢),要么在短轨迹片段上微调。这部分沿用了 PaLM-E 一系的做法。
文本到视频动力学 fᵥₘ(x, a) :输入图像 x 和短指令 a,输出一段从 x 起步、最长约 16 帧的短视频 x₁:ₛ。它就是 UniPi 那种视频扩散模型,但在这里被当作"走一步看一步"的局部模拟器用,而不是一口气画完全程。
VLM 启发式 Hᵥₗₘ(x, g) :预测"从画面 x 到目标 g 还剩多少步"。训练方式很巧:在长轨迹上随机取一帧,让模型预测"这一帧到轨迹结束还有几步",于是它学会了估计"距离完成的远近"。
3.2 树搜索的完整流程(算法核心)
把上面三件套组装起来,VLP 的规划循环大致是这样(对应论文的 Algorithm 1):
- 维护 B 条平行的候选计划(beam,束):像同时下 B 盘棋,保留多条有希望的路线,避免一条道走到黑。
- 每个规划步 h(共 H 步深) :
- 对每条 beam,让 VLM 策略提议 A 个候选子动作(语言分支);
- 每个候选动作再让视频模型生成 D 段视频变体(视频分支)------同一句指令也可能演出不同结果,多采几个样更稳;
- 于是每条 beam 下冒出 A×D 个候选未来,用价值函数 Hᵥₗₘ 全部打分,挑出分最高的那个未来留下;
- 每隔若干步(如 5 步)做一次束的优胜劣汰:淘汰当前价值最低的 beam,复制价值最高的 beam,把算力集中到有希望的路线上。
- H 步走完,取价值最高的那条 beam,即为最终的长视频计划。
你会发现这就是把**束搜索(beam search)**这套 NLP 里的经典解码策略,搬到了"以视频为状态、以子动作为决策"的具身规划上。A(语言分支)、D(视频分支)、B(束宽)、H(规划深度)这几个旋钮,共同决定了搜索树的胖瘦和深浅。
3.3 从"长视频计划"到"电机指令"
搜出长视频计划后,机器人还是只认电机指令。这最后一步交给一个短程目标条件策略(goal-conditioned policy) πcontrol(x, x_g):输入"当前画面 x"和"视频计划里的下一帧目标 x_g",输出低层控制动作 u。训练时随机取轨迹中的一帧和它若干步后的未来帧,让策略学会"从当前奔向那个近期目标"。
这里有个被实验证明很关键的细节------要对计划里的每一帧都密集地施加目标条件去控制 ("Goal Policy Every"),而不是只盯着最后一帧("Goal Policy Last")。差距相当大:密集执行能拿到 95.8 的奖励 / 92% 完成率,而只看末帧只有 85.0 / 66%。直觉上也好理解------计划是一帧帧画出来的,那就该一帧帧地跟着走,而不是只记住终点、中间放飞。论文里还对比了把这一步换成 UniPi 式逆动力学的版本(89.7 / 80%),结论是"逐帧目标条件策略"略胜一筹,但二者都远好于"只盯末帧"------这再次印证了 UniPi 留下的判断:动作提取这一棒,可以灵活地用逆动力学或目标条件策略来接,关键是要密集地利用视频里的每一步信息。
3.5 边走边改:接收视界重规划
光有"搜索出一条长计划"还不够,因为真机执行时世界是会变的------东西没推到位、夹爪滑了一下,现实和计划就对不上了。VLP 为此采用了接收视界控制(receding horizon control) :执行固定的一小段后,就拿当下真实的画面当新起点,重新规划一次。
这套"走一段、看一眼、重规划"的循环,和 3.2 节树搜索里"每隔几步淘汰最差束"是同一种哲学在两个尺度上的体现------规划时在想象里纠错,执行时在现实里纠错,双重保险地把误差摁住。它和模型预测控制(MPC,一种"每步都基于最新状态重新优化未来"的经典控制思想)一脉相承,只不过这里被优化的"未来",是一段由视频世界模型生成的画面。
3.4 一张表看清三个角色
| 角色 | 由谁扮演 | 输入 → 输出 | 在规划中的职责 |
|---|---|---|---|
| 策略(提议者) | VLM | 当前图+目标 → 抽象子动作文字 | 给出"下一步大概做什么"的候选 |
| 动力学(推演者) | 文本到视频模型 | 当前图+子动作文字 → 短视频 | 模拟"做了这步后世界变啥样" |
| 价值(打分者) | VLM | 图+目标 → 剩余步数估计 | 评估每个候选未来的好坏,指导剪枝 |
| 控制(执行者) | 目标条件策略 | 当前图+下一帧目标 → 电机指令 | 把视频计划逐帧翻译成真实动作 |
核心公式与逻辑梳理
把 VLP 的"三件套 + 树搜索"用形式化语言串起来,整套流程是 6 步:
- VLM 提议 :给定当前画面 x x x 与目标 g g g,VLM 策略 π V L M \pi_{\mathrm{VLM}} πVLM 提议出多个候选子动作的自然语言描述。
- 视频推演 :文本到视频模型 f V M f_{\mathrm{VM}} fVM 把每个子动作"演"成一小段短视频,相当于在想象里前进一步。
- 价值打分 :VLM 启发式 H V L M H_{\mathrm{VLM}} HVLM 对推演出的新画面打分,估计"距离目标还差几步"。
- 束搜索剪枝 :在 B B B 条候选计划上同步展开 A × D A\times D A×D 个分支,按价值排序留下最优、淘汰落后的束。
- 目标条件控制 :用控制策略 π c o n t r o l \pi_{\mathrm{control}} πcontrol 把视频计划逐帧翻译成低层电机指令。
- 接收视界重规划:执行一小段后,以最新真实画面为新起点重跑搜索,让规划在执行中持续被现实校准。
公式 1:三件套的形式化定义
π V L M ( x , g ) → a , x 1 : S = f V M ( x , a ) , H V L M ( x , g ) ∈ R \pi_{\mathrm{VLM}}(x, g)\rightarrow a,\qquad x_{1:S}=f_{\mathrm{VM}}(x, a),\qquad H_{\mathrm{VLM}}(x, g)\in \mathbb{R} πVLM(x,g)→a,x1:S=fVM(x,a),HVLM(x,g)∈R
- 符号说明 : x x x 是当前画面(RGB 图), g g g 是目标的自然语言描述, a a a 是 VLM 提议出的子动作文字(如"把红积木向右移"); x 1 : S x_{1:S} x1:S 是文本到视频模型从 x x x 出发、按子动作 a a a 推演出的 S S S 帧短视频; H V L M ( x , g ) H_{\mathrm{VLM}}(x,g) HVLM(x,g) 输出一个实数,对应"从 x x x 到 g g g 的剩余步数估计"(值越大代表越接近完成)。
- 这条式子在做什么 :用三个函数把"策略---动力学---价值"三种角色一次摆清。亮点是它们全由现成大模型扮演 ------VLM 一身二用(既当策略又当价值),视频模型当物理引擎------VLP 没有训练一个庞然大物,而是把已有大脑编排了起来。
公式 2:树搜索的目标函数
x 1 : H ⋆ = arg max x 1 : H ∼ f V M , π V L M H V L M ( x H , g ) x_{1:H}^{\star} = \arg\max_{\,x_{1:H}\,\sim\, f_{\mathrm{VM}},\,\pi_{\mathrm{VLM}}}\ H_{\mathrm{VLM}}(x_H,\ g) x1:H⋆=argx1:H∼fVM,πVLMmax HVLM(xH, g)
- 符号说明 : x 1 : H x_{1:H} x1:H 表示一条长度为 H H H 的"想象出来的视频计划",下标 ∼ \sim ∼ 表示这条计划是由 π V L M \pi_{\mathrm{VLM}} πVLM 不断提议、 f V M f_{\mathrm{VM}} fVM 不断推演联合采样 得到的; x H x_H xH 是计划末帧; arg max \arg\max argmax 表示挑出让末帧价值最高的那条计划。
- 这条式子在做什么 :把"长程规划"严格写成一个在视频空间上的搜索问题 ------目标是找到一条让末帧最接近目标的想象轨迹。它和经典 NLP 里的束搜索是同源思路,只不过这里搜索的不是 token 序列,而是一段段会演化的画面。
公式 3:束搜索单步展开
s c o r e ( x 1 : h ( b ) ) = H V L M ( x h ( b ) , g ) , B h + 1 = T o p B ( ⋃ b = 1 B ⋃ i = 1 A ⋃ j = 1 D { x 1 : h ( b ) ⊕ f V M ( x h ( b ) , a i ( b ) ) j } ) \mathrm{score}(x_{1:h}^{(b)}) = H_{\mathrm{VLM}}\!\left(\,x_h^{(b)},\ g\,\right),\quad \mathcal{B}{h+1}=\mathrm{Top}B\!\left(\,\bigcup{b=1}^{B}\,\bigcup{i=1}^{A}\,\bigcup_{j=1}^{D}\,\{x_{1:h}^{(b)}\oplus f_{\mathrm{VM}}(x_h^{(b)},\,a_i^{(b)})_j\}\,\right) score(x1:h(b))=HVLM(xh(b), g),Bh+1=TopB(b=1⋃Bi=1⋃Aj=1⋃D{x1:h(b)⊕fVM(xh(b),ai(b))j})
- 符号说明 : B h + 1 \mathcal{B}_{h+1} Bh+1 是规划到第 h + 1 h+1 h+1 步时保留的束集合; b ∈ 1 , B b\in1,B b∈1,B 索引 B B B 条并行候选计划, i ∈ 1 , A i\in1,A i∈1,A 索引 VLM 提议的 A A A 个候选子动作, j ∈ 1 , D j\in1,D j∈1,D 索引视频模型的 D D D 个采样变体; ⊕ \oplus ⊕ 表示视频拼接; T o p B ( ⋅ ) \mathrm{Top}_B(\cdot) TopB(⋅) 按价值打分保留前 B B B 条。
- 这条式子在做什么 :揭示了"提议 × 视频采样 × 束宽"三个旋钮如何共同决定搜索树的胖瘦 。实验里之所以"束宽 1→2、分支 4→16"就能让难任务从 0% 提到 16%,本质就是这个公式里 A , D , B A,D,B A,D,B 联合放大了每一层的搜索面,给价值函数更多剪枝机会。
公式 4:目标条件控制策略
π c o n t r o l ( x , x g ) → u , u t = π c o n t r o l ( x t , x t + Δ ) 对每个 t 密集执行 \pi_{\mathrm{control}}(x,\ x_g)\rightarrow u,\qquad u_t = \pi_{\mathrm{control}}(x_t,\ x_{t+\Delta})\ \text{对每个 }t\text{ 密集执行} πcontrol(x, xg)→u,ut=πcontrol(xt, xt+Δ) 对每个 t 密集执行
- 符号说明 : x x x 是当前真实观测, x g x_g xg 是视频计划里的近期目标帧(不是末帧!是临近的下一帧), u u u 是低层电机指令;下半部分强调实际执行时对计划的每一帧都重新调用一次 π c o n t r o l \pi_{\mathrm{control}} πcontrol,而不是只盯末帧。
- 这条式子在做什么 :把"想象出来的视频"逐帧翻译成"现实里的动作"。论文实验里"对每帧密集执行"比"只盯末帧"完成率高 26 个百分点(92% vs 66%),印证了:视频计划的价值在过程里,而不在终点------每一帧都是一次微型目标,跟着走才能稳。
四、实验怎么做·结果说明了什么
4.1 测试平台:从仿真到三套真机
VLP 在仿真和真机上都做了验证,尤其难得的是它在三种不同硬件本体上都跑通了,证明这套范式不挑机器人:
- 仿真:Language Table 桌面操作环境,三个难度递增的长程任务------"移动到区域""按颜色分组""摆成直线"。
- 真机一:Language Table 真实桌面平台。
- 真机二:7 自由度移动机械臂(做开关抽屉这类任务)。
- 真机三 :14 自由度双臂 ALOHA 平台,做需要灵巧协调的多物体堆叠------"先把碗叠起来,再把杯子叠到碗上,最后把餐具叠到杯子上"。这种又长又需要双臂配合的任务,最能体现长程规划的价值。
4.2 关键结果:长程任务上的"降维打击"
先看视频计划的正确率(生成的长视频是否真的把任务规划对了,单位 %)。这一项最能直接体现"分步搜索 vs 一口气生成"的差距:
| 任务 | UniPi(仿真) | VLP(仿真) | UniPi(真机) | VLP(真机) |
|---|---|---|---|---|
| 移动到区域 | 2 | 58 | 4 | 78 |
| 按颜色分组 | 4 | 98 | 12 | 100 |
| 摆成直线 | 2 | 66 | 4 | 56 |
差距是数量级的。最典型的"摆成直线"任务,UniPi 一口气生成只有 2% 能规划对,VLP 靠树搜索做到 66%------16 倍以上的提升。这就是"短生成+即时纠错"对"长生成赌一把"的碾压。
再看真实执行的成功率(50 个环境、1500 步预算,奖励分 / 完成率 %):
| 任务 | VLP | RT-2(VLA 基线) | PaLM-E | LAVA |
|---|---|---|---|---|
| 按颜色分组 | 95.8 / 92% | 46.0 / 26% | 43.5 / 2% | --- |
| 移动到区域 | 87.3 / 64% | --- | --- | 59.8 / 22% |
| 摆成直线 | 65.0 / 16% | --- | --- | 33.5 / 0% |
对照同期强劲的 VLA 基线(RT-2、PaLM-E)和 LAVA,VLP 在长程任务上的完成率往往是它们的数倍。值得玩味的是"摆成直线"------即便 VLP 也只有 16% 完成率,可基线干脆是 0%,足见这类任务有多硬,也足见"规划"相比"反应式策略"在长程上的不可替代。
4.3 最迷人的发现:性能随"算力 / 搜索预算"水涨船高
VLP 有一个非常"大模型时代"的特质------给它越多算力(越胖越深的搜索树),它就规划得越好。以最难的"摆成直线"为例(成功率 %):
| 配置(束 / 语言分支 / 视频分支) | 成功率 |
|---|---|
| 1 / 1 / 1(退化成 UniPi 式单次生成) | 4 |
| 1 / 1 / 4(只多采视频样本) | 10 |
| 1 / 4 / 4(再多提议候选动作) | 22 |
| 2 / 4 / 4(再加一条束做优胜劣汰) | 56 |
这条曲线意义重大:它说明 VLP 把长程规划变成了一个可以用"花更多算力换更好结果"来稳定改进的问题------这正是测试时(inference-time)扩展的雏形。代价是慢:规划一段视频大约要半小时。
4.4 消融:价值函数和搜索深度,缺一不可
- 去掉价值函数会塌方 :没有 VLM 当价值函数打分剪枝,"按颜色分组"从 98% 暴跌到 42%。这说明会推演还不够,必须会评判------树搜索的灵魂正是那双"打分剪枝"的眼睛。
- 搜索要够深够宽:规划深度从 1 加到 2、束宽从 1 加到 2、分支从 4 加到 16,"摆成直线"的完成率从 0% 提到 16%。浅而窄的搜索等于没搜。
五、亮点与为什么重要
- 把"规划"正式请进了视频世界模型:UniPi 只有"想象",VLP 补上了"在想象上做搜索与决策"。它让视频世界模型第一次具备了"走一步、看一步、回退一步"的深思熟虑能力。
- 零件全是现成大模型,靠"组装"取胜 :VLM 一身二用(策略+价值)、视频模型当动力学,VLP 几乎没有从头训练新的庞然大物,而是巧妙地把它们编排成一个规划器。这种"用编排换能力"的思路极具启发性。
- 误差累积有了系统性解法:通过"短视频分步生成 + 价值剪枝 + 束的优胜劣汰 + 接收视界重规划",把长程误差雪崩压了下去,这是对 UniPi 最直接的修补。
- 算力可扩展性:性能随搜索预算平滑上升,为后来"测试时计算扩展"在具身规划上的应用打了样。
六、局限与未解
作者很坦诚地列了几条短板:
- 状态只是图像,丢了 3D:VLP 拿 RGB 图像当世界状态,很多任务里这不够------它看不到完整的三维结构、遮挡背后的东西。
- 物理仍不精确:作为动力学模拟器的视频模型,仍会让物体凭空出现或瞬移,物理一致性是硬伤。
- 互联网知识有时"用错地方":迁移到训练数据稀少的新物体时,模型偶尔会把不相干的网络先验生搬硬套过来。
- 物体恒存性(object permanence):在很长的视频里保持物体始终如一地存在,仍是公开难题。
- 慢:半小时规划一段视频,离实时部署还很远。
这些坑,又一次为后来者指明了方向:要更精确的物理、要 3D/多模态状态、要更快的推理。
七、在 WAM 谱系中的位置
VLP 仍属于级联式 → 像素空间显式规划 → 学习式动作提取 这一支,是 UniPi 的直系升级版:
- 承接 UniPi:复用"视频当世界模型、目标条件策略当动作提取器"的两阶段框架,但把"规划"从"单次长视频生成"升级为"VLM 提议 + 树搜索 + 价值剪枝"的分层规划,针对性地解决了长程误差累积。
- 启发 RoboEnvision(本系列 03) :VLP 用"分步短生成 + 搜索"来抗误差,靠的是反复推演,代价是慢;RoboEnvision 则换个思路------非自回归地先生成各子任务关键帧、再插值出长视频,从生成范式上另辟蹊径地对抗误差累积。二者可看作针对同一痛点的两种不同药方。
- 与 This&That(本系列 04)互补:VLP 解决的是"长程怎么不崩",This&That 解决的是"任务指令怎么不歧义",二者修补的是 UniPi 的不同侧面。
如果说 UniPi 让机器人学会了"闭眼想象未来",那么 VLP 就是教会了它"睁眼审视自己的想象,并择优而行"------这是从单纯的生成,迈向真正的规划的关键一步。
八、参考
- 论文:《Video Language Planning》(VLP)
- 作者:Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Kaelbling, Andy Zeng, Jonathan Tompson
- 会议:ICLR 2024
- arXiv:https://arxiv.org/abs/2310.10625
注:本文为基于该论文公开信息的学习性解读,方法名、基准与数字均取自论文原文以便检索与复核;解读与类比为作者原创组织。