一、开篇引言:为什么重点攻克这四大排序?
1.1 八大排序整体分类:简单排序 vs 高阶排序
数据结构中的八大排序算法,是算法入门与面试的核心基础,根据实现难度、算法思想与时间复杂度,可明确划分为两大阵营:
-
简单排序:冒泡排序、选择排序、插入排序、希尔排序
-
高阶排序:归并排序、快速排序、堆排序、基数排序
前四类简单排序逻辑直观、容易上手,但时间复杂度大多为O(n²) ,仅适用于小规模数据;而后四类高阶排序,依托分治、树形结构、非比较排序 等进阶思想,将时间复杂度优化至O(n log n) 或线性级别,是处理大规模数据、应对面试手撕代码、算法刷题的核心门槛,也是本文的重点讲解对象。
1.2 四大排序定位:各自不可替代的核心价值
四大高阶排序没有绝对的优劣,每一种算法都有其独有的核心场景,无法互相替代:
-
归并排序 :唯一稳定的O(n log n)比较排序,链表排序最优解,适合需要保留元素相对顺序的场景
-
快速排序:工业级综合效率之王,常数级开销极低,是绝大多数通用排序场景的首选
-
堆排序 :原地排序、无递归依赖,内存占用极致可控,适合内存受限、动态TopK场景
-
基数排序 :少数线性时间复杂度的非比较排序,海量固定位数数据排序效率碾压比较型排序
1.3 本文学习前置条件与整体学习思路
四大高阶排序均依赖特定前置知识点,盲目学习极易出现看不懂原理、写不出代码的问题,以下是各章节前置依赖速查表:
|------|----------------|-----------------------|
| 算法章节 | 前置知识 | 建议预习 |
| 归并排序 | 递归思想、辅助数组使用 | 递归函数调用过程、数组拷贝逻辑 |
| 快速排序 | 双指针、分治思想 | 数组分区、区间边界处理 |
| 堆排序 | 完全二叉树、数组模拟树结构 | 父子节点索引 i,2i+1,2i+2 换算 |
| 基数排序 | 取余/除法运算、队列/桶结构 | 数字个十百位提取逻辑 |
最优学习路径:先掌握比较型排序(归并→快速→堆),理解分治与树形排序思想,最后学习非比较型的基数排序,循序渐进降低学习难度。
二、排序算法核心评判标准(前置基础知识)
学习排序算法不能只背原理,必须掌握四大核心评判维度,所有算法的优劣、场景选型都基于这四个标准。
2.1 时间复杂度:最好/最坏/平均情况解析
时间复杂度衡量排序算法的执行效率,是算法最核心的指标,分为三种场景:
-
平均时间复杂度:随机数据下的常规效率,是日常选型的主要依据
-
最好时间复杂度:数据完全有序时的最优效率
-
最坏时间复杂度:数据极端无序/有序时的最差效率,面试必考重点
2.2 空间复杂度:原地排序 vs 非原地排序
-
原地排序 :仅使用常数级额外空间O(1),不依赖额外数组、队列等存储结构,内存友好
-
非原地排序 :需要开辟额外存储空间,空间复杂度高于O(1),适合内存充足场景
2.3 稳定性:稳定排序与不稳定排序的定义及应用场景
稳定排序 :排序后,原数组中相等元素的相对顺序保持不变。
不稳定排序:相等元素的相对顺序可能被打乱。
经典应用场景:二次排序。例如先对学生数组按分数排序,再按班级排序,若排序算法稳定,分数的排序结果不会被打乱;若不稳定,会出现排序错乱。
2.4 递归与非递归实现的优劣差异
-
递归实现 :代码简洁、逻辑清晰、易于理解调试;缺点是递归深度过大时会出现栈溢出风险
-
非递归实现:通过迭代/栈模拟实现,无栈溢出问题、运行更可控;缺点是代码繁琐、边界处理复杂
三、分治思想经典(一):归并排序(Merge Sort)
3.1 核心原理:分而治之、拆分+合并双阶段逻辑
归并排序是分治思想最经典的实现 ,核心逻辑可概括为八个字:先拆后合,分而治之。
-
拆分:将原数组不断对半拆分,直到每个子数组仅有一个元素(单个元素天然有序)
-
合并:将两个有序子数组,按照大小规则合并为一个新的有序数组,逐层回溯完成整体排序
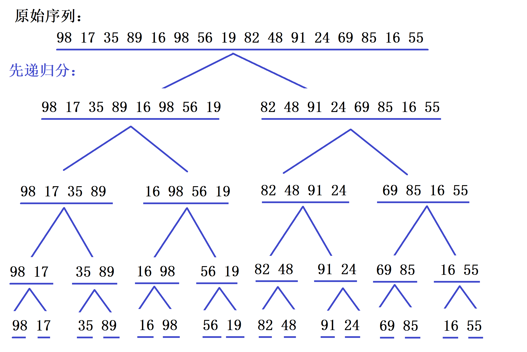
3.2 完整执行流程:图文分步拆解排序全过程
以数组 [98 17 35 89 16 98 56 19 82 48 91 24 69 85 16 55] 为例:
-
第一层拆分:拆分为
[98 17 35 89 16 98 56 19]和[82 48 91 24 69 85 16 55] -
第二层拆分:继续对半拆分,得到四个子数组
[98 17 35 89]、[16 98 56 19]、[82 48 91 24]、[69 85 16 55] -
第三层拆分:拆分为8个二元子数组,`98 17`、`35 89`、`16 98`、`56 19`、`82 48`、`91 24`、`69 85`、`16 55`
-
四次层差分:拆分为16个一元子数组
-
逐层合并:两两合并有序数组,最终还原为完整有序数组
[16 16 17 19 24 35 58 55 56 69 82 85 89 91 98 98]
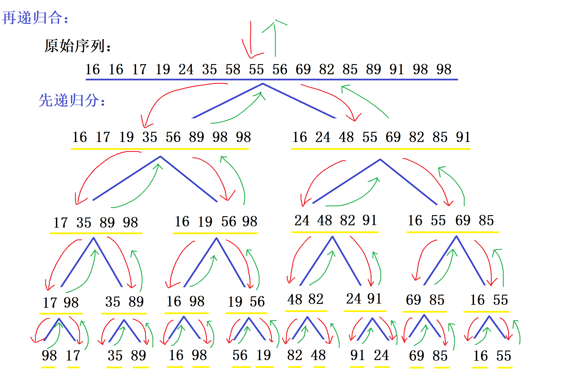
注:本图右侧的递归和从下向上为合并顺序。
3.3 代码实现
3.3.1 递归版(标准写法)
核心逻辑:递归拆分数组,拆分至单个有序元素后,借助辅助数组合并有序子数组,最终完成整体排序,代码简洁直观,是面试标准手写版本。
完整递归版代码(可直接运行)
cpp
void Merge(int arr[], int left, int mid, int right)
{
//0.assert
assert(arr != NULL);
//1.申请一块辅助空间,用于存储排好序的数组
int* brr = (int*)malloc((right - left + 1) * sizeof(int));
if (brr == NULL)
exit(EXIT_FAILURE);
//2.定义两个变量分别指向左右两个区间的起始位置
int i = left, j = mid + 1;
//3.进入while循环,循环条件i和j还未越界(还合法)
int idx = 0; //应该将数据插入brr的下标
while (i <= mid && j <= right)
{
//4.比较i和j指向的值,谁小谁向下放(brr)
if (arr[i] <= arr[j])
brr[idx++] = arr[i++];
else
brr[idx++] = arr[j++];
}
//5.循环退出条件为有一方已经完全插入brr
while (i <= mid)
brr[idx++] = arr[i++];
while (j <= right)
brr[idx++] = arr[j++];
//6.将brr中的已经排序好的数赋值给arr对应位置
for (int m = 0; m < right - left + 1; m++)
{
arr[left + m] = brr[m];
}
//7.释放brr
free(brr);
brr = NULL;
}
//递归分
void Divid(int arr[], int left, int right)
{
if (left >= right)
return;
int mid = (left + right) / 2; //mid为左区间右边界
Divid(arr, left, mid); //先对左边组继续递归分 [left, mid]
Divid(arr, mid+1, right); //再对右边组继续递归分 [mid+1, right]
Merge(arr, left, mid, right);
}
void Merge_Sort(int arr[], int len)
{
//调用递归分
Divid(arr, 0, len - 1);
}3.3.2 非递归版(迭代归并)
消除递归栈溢出风险,通过迭代控制子数组长度,从小到大逐层合并有序区间,适合大规模数据、超长递归深度场景。
完整非递归(迭代)版代码
cpp
void Merge(int arr[], int left, int mid, int right)
{
//0.assert
assert(arr != NULL);
//1.申请一块辅助空间,用于存储排好序的数组
int* brr = (int*)malloc((right - left + 1) * sizeof(int));
if (brr == NULL)
exit(EXIT_FAILURE);
//2.定义两个变量分别指向左右两个区间的起始位置
int i = left, j = mid + 1;
//3.进入while循环,循环条件i和j还未越界(还合法)
int idx = 0; //应该将数据插入brr的下标
while (i <= mid && j <= right)
{
//4.比较i和j指向的值,谁小谁向下放(brr)
if (arr[i] <= arr[j])
brr[idx++] = arr[i++];
else
brr[idx++] = arr[j++];
}
//5.循环退出条件为有一方已经完全插入brr
while (i <= mid)
brr[idx++] = arr[i++];
while (j <= right)
brr[idx++] = arr[j++];
//6.将brr中的已经排序好的数赋值给arr对应位置
for (int m = 0; m < right - left + 1; m++)
{
arr[left + m] = brr[m];
}
//7.释放brr
free(brr);
brr = NULL;
}
void Merge_Sort(int arr[], int len)
{
if (arr == NULL || len <= 1)
return;
/*
i:当前左组的起点
gap:左组长度
i + gap:右组的第一个元素下标
条件 i + gap < len 的意思是:必须保证右组存在,才能进行左右组合并!
*/
// gap:每组的元素个数
for (int gap = 1; gap < len; gap *= 2)
{
// 每次合并两个长度为 gap 的小区间
for (int i = 0; i + gap < len; i += 2 * gap)
{
int left = i;
int mid = i + gap - 1;
int right = i + 2 * gap - 1;
// 处理最后一组不够 2*gap 的情况,防止越界
if (right >= len)
right = len - 1;
Merge(arr, left, mid, right);
}
}
}3.4 常见错误
-
边界陷阱:合并区间剩余元素遗漏:合并两个有序区间时,只完成双指针遍历阶段,忘记拷贝左右区间剩余元素,导致数组部分数据缺失、排序错乱,是手写代码最高频错误。
-
递归陷阱:区间边界错误:递归拆分时mid值计算错误、区间重复覆盖,或递归终止条件写错,导致数组越界、死递归、排序不彻底。
-
内存陷阱:辅助空间未释放(C语言重点):手动malloc开辟的临时辅助数组,排序结束后未free释放,造成严重内存泄漏,工程代码必查问题。
-
稳定性陷阱:相等元素交换:合并判断条件误写为arri > arrj,会导致相等元素交换,直接破坏归并排序的稳定性。
3.5 算法复杂度与稳定性深度分析
-
时间复杂度 :最好/最坏/平均均为O(n log n)。拆分过程固定为log n层,每层合并总操作数为n,无极端场景退化。
-
空间复杂度 :O(n),需要开辟同等大小的辅助数组,属于非原地排序。
-
稳定性 :稳定排序。合并过程中,相等元素会优先保留原数组左侧元素,相对顺序不变。
3.6 核心优缺点、适用场景
| 类别 | 详细说明 |
|---|---|
| 核心优点 | 1. 性能稳定:全程维持O(n log n)排序效率,无任何数据场景下的性能退化问题; 2. 排序稳定:相等元素相对顺序保持不变,可支持二次排序业务场景; 3. 适配性强:天然适配链表排序,仅需修改指针无需额外拷贝,是链表排序最优解。 |
| 核心缺点 | 1. 内存开销大:排序过程需要占用O(n)额外辅助空间,非原地排序; 2. 存在栈风险:递归实现方式在超大数据量下,递归深度过大,存在栈溢出风险。 |
适用场景
- 需要稳定排序的业务场景(保留相等元素相对顺序)
- 链表排序(最优唯一解,无需数组拷贝、仅改指针)
- 逆序对统计、多路归并等算法变式题型
- 数据量大、要求排序效率稳定、不允许性能退化的场景
3.7 面试高频考点
问1:简述归并排序完整执行流程?
答:归并排序基于分治思想,分为拆分与合并两个阶段。
**拆分:**递归将数组对半拆分,直至子数组长度为1,天然有序;
**合并:**每次将两个相邻的有序子数组,通过辅助数组合并为一个整体有序数组,逐层向上回溯,最终完成全数组排序。
问2:归并排序为什么没有最坏复杂度退化,全程稳定O(n log n)?
答:归并排序的拆分层数固定为logn层,与原始数据有序、无序无关;且每一层所有子数组的合并总操作数固定为n次,总运算量恒定,不存在分区不均、极端数据退化问题,因此最好、最坏、平均复杂度均为O(n log n)。
问3:归并排序是稳定排序的根本原因?
答:合并两个有序子数组时,当左右区间元素相等,优先保留左侧原数组元素,不会交换相等元素的位置,严格保留原始相对顺序,因此排序稳定。
问4:归并排序递归和非递归版本的区别?各自优缺点?
答:①递归版:代码简洁、逻辑清晰、易于手写调试;缺点是大数据量下递归深度过大,存在栈溢出风险。②非递归(迭代)版:自底向上合并,无递归栈溢出问题,工程稳定性更强;缺点是边界处理复杂,代码繁琐。
问5:为什么归并排序是链表排序的最优解?
答:数组归并需要辅助空间、大量元素拷贝;而链表不依赖连续内存,合并有序链表仅需修改指针指向,无需开辟额外空间、无需数据拷贝,时间开销极低,是链表排序唯一最优的O(n log n)算法。
问6:归并排序的核心缺点,工程中为什么不常用?
答:必须依赖O(n)额外辅助数组,空间开销大;常数级时间开销高于快速排序,通用场景效率不如优化后快排,内存受限场景无法使用。
问7:归并排序可以原地实现吗?有什么弊端?
答:可以实现原地归并排序,但会极大增加数组元素移动的次数,时间复杂度常数开销剧增,牺牲排序效率,工程中几乎不使用。
问8:逆序对问题为什么只能用归并排序解决?
答:逆序对统计需要利用有序合并过程统计跨区间逆序,归并排序拆分后左右区间有序,可在合并时线性统计逆序数量,其他排序算法不具备该特性。
逆序对 :在一个数组中,对于下标 i<j,如果满足 ai > aj,则称 (ai,aj)为一组逆序对。
3.8 经典优化
-
小规模数组优化:子数组长度小于阈值时,改用插入排序,减少递归拆分开销
-
空间优化:原地归并排序,无需辅助数组,但会牺牲部分排序效率,时间复杂度略有上升
3.9 📌 推荐练习题目
-
LeetCode 912(排序数组):基础排序代码落地
-
LeetCode 148(排序链表):归并排序核心专属场景
-
剑指 Offer 51(数组中的逆序对):归并排序经典变式题
四、分治思想经典(二):快速排序(Quick Sort)
4.1 核心思想:分治+基准值(Pivot)分区交换
快速排序是综合效率最高的比较型排序 ,同样基于分治思想,核心逻辑:选基准、分区间、递归排序。不同于归并排序的均匀拆分,快排通过基准值将数组划分为「小于基准、大于基准」的两个区间,实现非均匀拆分。
4.2 核心流程:选基准、分区、递归子区间排序
-
选基准:从数组中选取一个元素作为基准值(Pivot)
-
分区:通过双指针遍历,将小于基准的元素放左侧,大于基准的元素放右侧
-
递归:对左右两个子区间重复上述操作,直至子区间长度为1,排序完成
4.3 基础递归代码实现(双边指针)
双边指针为常用标准写法,左右指针相向遍历,交换不符合分区规则的元素,最终交换基准值到正确位置,代码简洁、边界清晰。
cpp
//挖空法(单次划分函数)
//返回值:划分好的基准值所在位置
int Partition(int arr[], int begin, int end)
{
int left = begin;
int right = end;
int pivot = arr[left];
while (left < right)
{
//找右侧比基准值小的值
while (left < right && arr[right] >= pivot)
right--;
//找左侧比基准值大的值
while (left < right && arr[left] <= pivot)
left++;
//交换begin与end指向的值
int tmp = arr[left];
arr[left] = arr[right];
arr[right] = tmp;
}
//将基准值放到left处
arr[begin] = arr[left];
arr[left] = pivot;
return left;
}
//快速排序的递归函数
void Quick(int arr[], int left, int right)
{
if (left >= right)
return;
int par = Partition(arr, left, right);
Quick(arr, left, par - 1);
Quick(arr, par + 1, right);
}
void Quick_Sort2(int arr[], int len)
{
//一进来立刻启动快速排序的递归函数
Quick(arr, 0, len - 1);
}4.4 常见错误
-
分区陷阱:指针终止位置错误:双指针循环条件写错、指针移动顺序颠倒,导致基准值最终位置偏移,左右区间分区错乱,排序结果错误。
-
递归陷阱:死递归问题:递归区间包含基准值下标,未排除pivotIndex,导致区间无法收敛,出现无限递归、程序卡死。
-
边界陷阱:有序数组超时:未做三数取中优化,有序/逆序数组触发O(n²)最坏复杂度,大数据量直接超时。
-
重复元素陷阱:大量重复数据退化:普通双路快排无法处理重复元素,大量相等元素会导致分区不均,性能急剧下降,必须用三路快排。
-
非递归陷阱:栈区间入栈顺序错误:栈后进先出特性未匹配,入栈顺序颠倒导致区间遍历混乱,排序错乱。
4.5 三大经典优化方案(面试重点)
4.5.1 三数取中法选基准
默认选取首/尾元素作为基准,在数组有序/逆序时会触发最坏复杂度O(n²) 。三数取中法通过选取「左端、右端、中间」三个元素的中位数作为基准,彻底规避有序数据退化问题。
优化1:三数取中法基准选择代码
cpp
// 数组交换工具函数
void swap(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 三数取中,获取基准值下标
int getPivot(int arr[], int left, int right) {
int mid = left + (right - left) / 2;
// 排序三个数,取中位数
if (arr[left] > arr[mid]) swap(arr, left, mid);
if (arr[left] > arr[right]) swap(arr, left, right); //前两部保证left位置的数一定是最小的
if (arr[mid] > arr[right]) swap(arr, mid, right); //保证mid位置的数 <= right位置的数
// 将中位数交换到left位置,复用原有分区逻辑
swap(arr, mid, left);
return left;
}4.5.2 小规模区间改用插入排序
递归拆分的极小区间,递归开销远大于排序开销。当子数组长度小于阈值(通常10-20)时,改用插入排序,大幅降低常数级开销。
优化2:小区间插入排序优化 + 完整优化快排
cpp
#define INSERT_SORT_THRESHOLD 15
// 数组交换工具函数
void swap(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
// 插入排序(适配极小区间)
void insertSort(int arr[], int left, int right) {
for (int i = left + 1; i <= right; i++) {
int temp = arr[i];
int j = i - 1;
while (j >= left && arr[j] > temp) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = temp;
}
}
// 三数取中获取基准
int getPivot(int arr[], int left, int right) {
int mid = left + (right - left) / 2;
if (arr[left] > arr[mid]) swap(arr, left, mid);
if (arr[left] > arr[right]) swap(arr, left, right);
if (arr[mid] > arr[right]) swap(arr, mid, right);
swap(arr, mid, left);
return left;
}
// 双边分区
int partition(int arr[], int left, int right) {
int pivot = arr[left];
int i = left, j = right;
while (i < j) {
while (i < j && arr[j] >= pivot) j--;
while (i < j && arr[i] <= pivot) i++;
swap(arr, i, j);
}
swap(arr, left, i);
return i;
}
// 综合优化快排(三数取中+插入排序优化)
void quickSortOpt(int arr[], int left, int right) {
if (left >= right) return;
// 小区间直接插入排序
if (right - left + 1 <= INSERT_SORT_THRESHOLD) {
insertSort(arr, left, right);
return;
}
// 三数取中选基准
getPivot(arr, left, right);
int pivotIndex = partition(arr, left, right);
quickSortOpt(arr, left, pivotIndex - 1);
quickSortOpt(arr, pivotIndex + 1, right);
}4.5.3 三路快排
针对大量重复元素的数组,将数组划分为「小于基准、等于基准、大于基准」三个区间,等于基准的区间无需递归,大幅减少递归次数,解决重复元素导致的性能退化,是面试高频考点。
优化3:三路快排完整代码
cpp
#define INSERT_SORT_THRESHOLD 15
void swap(int arr[], int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
void insertSort(int arr[], int left, int right) {
for (int i = left + 1; i <= right; i++) {
int temp = arr[i];
int j = i - 1;
while (j >= left && arr[j] > temp) {
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = temp;
}
}
int getPivot(int arr[], int left, int right) {
int mid = left + (right - left) / 2;
if (arr[left] > arr[mid]) swap(arr, left, mid);
if (arr[left] > arr[right]) swap(arr, left, right);
if (arr[mid] > arr[right]) swap(arr, mid, right);
swap(arr, mid, left);
return left;
}
/**
* 三路快排:解决大量重复元素数组退化问题
*/
void quickSortThreeWay(int arr[], int left, int right) {
if (left >= right) return;
if (right - left + 1 <= INSERT_SORT_THRESHOLD) {
insertSort(arr, left, right);
return;
}
// 三数取中选基准
getPivot(arr, left, right);
int pivot = arr[left];
// lt:小于区间末尾,gt:大于区间开头,i:当前遍历指针
int lt = left, gt = right, i = left + 1;
while (i <= gt) {
if (arr[i] < pivot) {
swap(arr, lt++, i++);
} else if (arr[i] > pivot) {
swap(arr, i, gt--);
} else {
// 等于基准,直接后移,无需处理
i++;
}
}
// 递归排序小于、大于区间,等于区间无需递归
quickSortThreeWay(arr, left, lt - 1);
quickSortThreeWay(arr, gt + 1, right);
}4.6 非递归(栈实现)版本代码
基础递归版代码简洁,但极端数据下递归深度可达O(n),触发栈溢出。非递归版本通过栈模拟递归过程,手动存储待排序区间,彻底解决栈溢出问题,工程中更常用。
cpp
//挖空法(单次划分函数)
//返回值:划分好的基准值所在位置
int Partition(int arr[], int begin, int end)
{
int left = begin;
int right = end;
int pivot = arr[left];
while (left < right)
{
//找右侧比基准值小的值
while (left < right && arr[right] >= pivot)
right--;
//找左侧比基准值大的值
while (left < right && arr[left] <= pivot)
left++;
//交换begin与end指向的值
int tmp = arr[left];
arr[left] = arr[right];
arr[right] = tmp;
}
//将基准值放到left处
arr[begin] = arr[left];
arr[left] = pivot;
return left;
}
//快速排序(非递归):将左右边界依次压入栈
#include<stack>
void Quick_Sort(int arr[], int len)
{
//创建一个栈,将[0--len-1]押入栈
std::stack<int> st;
st.push(0);
st.push(len-1);
while (!st.empty())
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
int par = Partition(arr, left, right);
//判断右侧是否有两个数以上
if (par + 1 < right)
{
//先压左再压右
st.push(par + 1);
st.push(right);
}
//判断左侧是否有两个数以上
if (par - 1 > left)
{
st.push(left);
st.push(par - 1);
}
}
}4.7 复杂度与稳定性分析:最坏时间复杂度O(n²)成因
-
平均时间复杂度 :O(n log n),常数开销极低,效率最优
-
最坏时间复杂度 :O(n²),触发场景:数组完全有序/逆序,且固定选取首尾为基准,导致分区极度不均匀
-
空间复杂度:递归栈空间,平均O(log n),最坏O(n)
-
稳定性 :不稳定排序,跨区间交换元素会破坏相等元素的相对顺序
4.8 优缺点、工业级应用场景
|----------|----------------------------------------------------------------------------------------------------------------------------|
| 核心优点 | 1. 通用场景综合速度最快,常数开销极小,CPU缓存命中率高; 2. 原地排序,仅需 O(log n) 递归栈空间,内存开销极低; 3. 支持多种优化方案,适配有序、重复数据等极端场景; 4. 支持区间裁剪,可高效解决 TopK 局部排序问题。 |
| 核心缺点 | 1. 原生版本存在最坏 O(n²) 性能退化(有序数组); 2. 排序不稳定,无法用于需要保序的二次排序场景; 3. 递归实现存在栈溢出风险,超大数据量需手动模拟栈; 4. 分区逻辑边界复杂,手写代码极易出错。 |
应用场景:
-
通用海量数据排序:业务中绝大多数无序数组排序场景,性价比最高;
-
TopK 高频查询:无需全排序,通过分区裁剪快速筛选极值数据;
-
含大量重复数据排序:采用三路快排,彻底规避性能退化问题。
4.9 高频面试题
问1:简述快速排序核心原理与执行流程?
答:快排基于分治思想,核心三步:①选基准:从区间中选取一个元素作为pivot;②分区:通过双指针将区间划分为「小于基准、大于基准」两部分;③递归:对左右两个子区间重复分区操作,直至子区间长度为1,全局有序。
问2:快排最坏时间复杂度O(n²)的触发场景与根本原因?
答:触发场景:数组完全有序/完全逆序,且固定选取数组首尾为基准值。根本原因:每次分区极度不均匀,一个区间仅含基准元素,另一个区间包含剩余所有元素,递归深度退化为n,每层遍历n次,总复杂度O(n²)。
问3:快速排序为什么是不稳定排序?
答:快排存在远距离跨区间元素交换,会打乱相等元素的原始相对顺序。例如序列2a,2b,1,交换2a和1后,两个相等的2的顺序被颠倒,稳定性失效。
问4:快排平均效率高于归并、堆排的核心原因?
答:快排数据访问具有良好的局部性,CPU缓存命中率高;常数级运算开销极小,无额外数组拷贝、无堆化递归遍历,通用随机数据下综合性能最优,是工业排序默认实现。
问5:三数取中法的作用与原理?
答:作用: 彻底解决有序数组导致的快排性能退化。**原理:**选取区间左端、右端、中间三个元素的中位数作为基准,保证分区相对均匀,杜绝极端单边分区场景。
问6:小区间插入排序优化的意义?
答:极小区间的递归开销远大于排序本身开销,当子数组长度小于阈值(10-15)时,改用简单插入排序,减少递归调用次数,大幅降低常数耗时,提升整体性能。
问7:三路快排解决什么问题?原理是什么?
答:专门解决大量重复元素数组的性能退化问题。原理:将数组划分为小于、等于、大于基准的三个区间,等于基准的区间已经有序,无需递归,极大减少递归次数,重复元素越多优化效果越明显。
问8:如何彻底解决快排递归栈溢出问题?
答:放弃递归实现,采用数组栈手动模拟递归过程,手动存储、弹出待排序区间,彻底规避系统递归栈深度限制,适合超大数据量。
问9:快排为什么不需要全排序就能求TopK?
**TopK:**在无序数组中,不用对整个数组排序,直接找出「前 K 大 / 前 K 小」的元素,或第 K 个极值元素(第 K 大、第 K 小)
答:
- 快排分区特性 :每次
partition后,基准值 pivot 的位置就是它最终的有序位置,左边全小、右边全大。- 假设基准下标为
pos:
- 若
pos == n-K:当前 pivot 就是第 K 大元素,直接返回- 若
pos < n-K:左边区间无用,只递归右区间- 若
pos > n-K:右边区间无用,只递归左区间- 直接裁剪掉一半无关区间,不用遍历全部数据 ,所以不需要全排序,时间复杂度优化到 O(n)
4.10 📌 推荐练习题目
-
LeetCode 912(排序数组):对比各版本快排性能
-
LeetCode 215(数组中的第K个最大元素):快排分区思想经典应用
-
LeetCode 75(颜色分类):三路快排核心变式题
五、树形结构排序:堆排序(Heap Sort)
5.1 前置知识:二叉堆(大顶堆/小顶堆)核心特性
堆排序依托完全二叉树实现,通过数组模拟树形结构,核心特性必须掌握:
-
数组存储规则 :下标为i的节点,左子节点下标为 2i+1 ,右子节点下标为 2i+2 ,父节点下标为 (i-1)/2
-
大顶堆:任意父节点值 ≥ 子节点值,堆顶为数组最大值
-
小顶堆:任意父节点值 ≤ 子节点值,堆顶为数组最小值
-
堆化(heapify):调整节点位置,使局部子树满足堆的特性,是堆排序的核心操作
5.2 堆排序核心思想:建堆 + 堆顶交换排序
堆排序核心两步走:初始化建堆构建全局堆结构,再通过交换堆顶+堆化完成排序。全程在原数组操作,是极致的原地排序算法。
5.3 关键步骤
-
初始化建堆 :从最后一个非叶子节点(下标 n/2-1)向前遍历,逐个执行堆化操作,将原数组转为大顶堆
-
首尾交换:将堆顶最大值与数组末尾元素交换,最大值落到最终有序位置
-
缩小堆范围+重新堆化:排除末尾已排序元素,对剩余无序区间重新堆化,重复交换操作直至排序完成
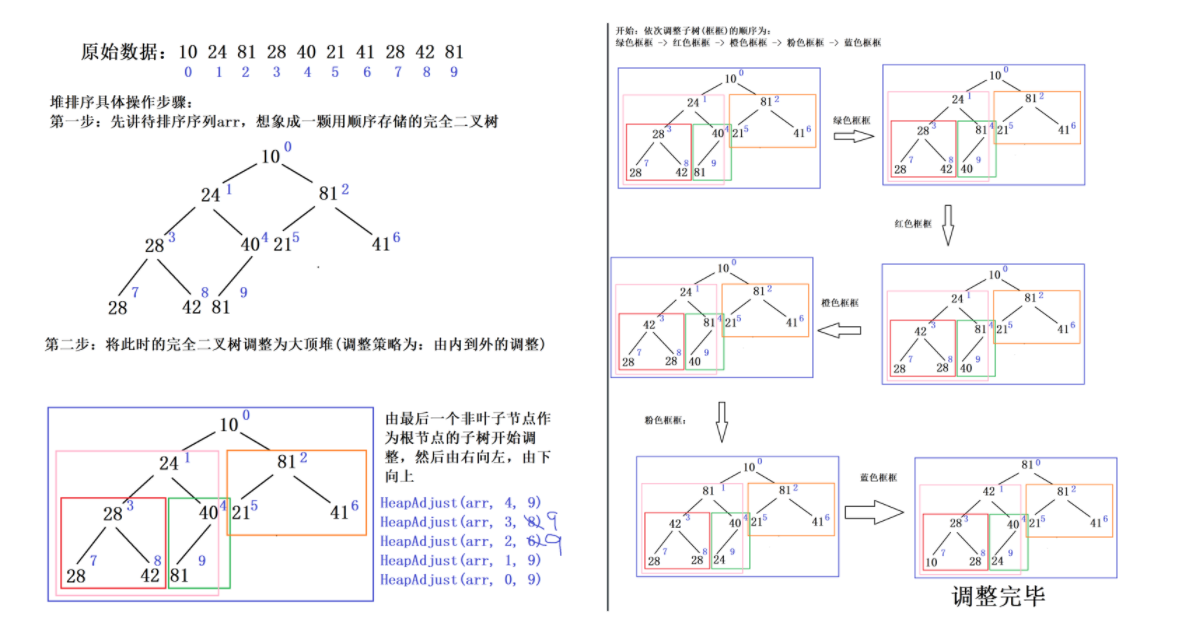
5.4 完整代码实现(标准堆排序)
以下为标准堆排序完整可运行代码(大顶堆实现)。
cpp
//堆排序的单次调整函数(单次调整一个框框)
// start:框框(子树)里面第一个值(根节点)下标 end:框框(子树)的结尾标记(一般用最后一个值作为标记)
void HeapAdjust(int arr[], int start, int end)
{
//1.将此时框框里面的根节点值取出来给到tmp
int tmp = arr[start];
//2.找到当前空白格子的较大孩子
int maxchild = start * 2 + 1;//maxchild默认都是指向空白格子的左边
//当前节点有孩子
while (maxchild <= end)
{
//进一步确定空白格子是否有右孩子,且右孩子的值是否还大于左孩子
if (maxchild + 1 <= end && arr[maxchild + 1] > arr[maxchild])
{
maxchild++;
}
//3.用这个较大孩子和tmp比较,如果大于tmp,则上移一位
if (arr[maxchild] > tmp)
{
//4.较大孩子上移之后,出现一个新的空白格子,再次让start指向这个新的空白格
// 子,然后继续观察有没有较大孩子,如果还有,则重复上面逻辑,如果没有,则
// 认为触底,可以将值放回去了,结束即可
arr[start] = arr[maxchild];
start = maxchild;
maxchild = start * 2 + 1;
}
//5.如果较大孩子并没有比tmp大,则此时也可以将tmp挪回去了,结束即可
else
{
break;
}
}
//6.此时while进不去,说明maxchild保存的新的空白格子的左孩子不存在,当然右孩子更不存在,则其触底了,可以将值放回去了
arr[start] = tmp;
}
void Heap_Sort(int arr[], int len)
{
//i节点的孩子:2i+1,2i+2; i节点的父亲:(i-1)/2
//第一步:由内到外的调整,将数组调整为大顶堆
for(int i = (len-1-1) / 2; i>=0; i--)
HeapAdjust(arr, i, len - 1);
//第二步:头尾交换,断开尾节点连接,然后重新调整为大顶堆
for (int j = len-1; j >= 1; j--)
{
int t = arr[0];
arr[0] = arr[j];
arr[j] = t;
//第三步:重复第二步,直到大顶堆里面只剩一个节点为止
HeapAdjust(arr, 0, j-1);
}
}5.5 常见错误
-
越界陷阱:堆化未判断子节点范围:堆化左右子节点时,未判断下标是否小于堆有效长度,访问越界内存,导致程序崩溃、排序错乱。
-
建堆陷阱:起点错误:从0或叶子节点开始建堆,导致建堆逻辑失效、堆结构不成立,后续排序完全错误。
-
排序陷阱:未缩小堆有效区间:每轮交换堆顶后,未缩减堆的遍历范围,已排序的末尾元素会被重新堆化,破坏已有有序结果。
-
逻辑陷阱:混淆大小顶堆规则:升序排序误用小顶堆逻辑,堆化判断条件颠倒,导致整体排序逆序。
-
递归陷阱:递归堆化深度过大:大数据量下递归堆化存在栈溢出风险,工程中建议使用迭代堆化。
5.6 复杂度、稳定性分析
-
时间复杂度 :最好/最坏/平均均为 O(n log n),建堆O(n),后续n次堆化每次O(log n)
-
空间复杂度 :O(1),纯原地排序,无额外空间开销
-
稳定性 :不稳定排序
不稳定根本原因 :堆排序存在长距离元素交换 ,会打乱相等元素的相对顺序。例如数组 [5a,8,5b],堆顶交换后两个5的相对位置会被颠倒。
5.7 优缺点对比与工程、刷题适用场景
|----------|-------------------------------------------------------------------------------------------------------------------------------|
| 核心优点 | 1. 严格原地排序,空间复杂度 O(1),无额外内存开销; 2. 全程稳定 O(n log n) 复杂度,无任何性能退化场景; 3. 无递归栈依赖,迭代实现可适配超大数据量,稳定性极强; 4. 适合动态极值获取,支持实时插入、删除、查询最大/最小值。 |
| 核心缺点 | 1. 排序不稳定,无法保留相等元素相对顺序; 2. 数据访问跳跃性强,CPU缓存命中率低,常数开销大,整体速度慢于快排; 3. 手写堆化、建堆、边界逻辑复杂,极易出错; 4. 不适合需要稳定保序的业务场景。 |
适用场景
-
内存受限设备排序:嵌入式、底层开发、移动端内存紧张场景,零额外空间开销;
-
优先队列/任务调度:操作系统进程调度、线程池任务优先级排序、定时器任务排序;
-
海量数据TopK筛选:热搜排行、高频词汇统计、海量日志极值筛选;
-
不允许递归的工程场景:服务端高并发场景,规避递归栈溢出风险。
5.8 高频面试题
问1:简述堆排序完整执行流程?
答:分为两大核心步骤:①初始化建堆 :从最后一个非叶子节点向前遍历,逐个堆化,将无序数组构建为大顶堆;②调整堆:交换堆顶最大值与数组末尾元素,将最大值固定在有序位置,缩小堆的有效范围,重新堆化根节点,循环往复直至数组完全有序。
问2:为什么建堆要从 n/2-1 位置开始,而不是从0开始?
答:n/2-1是数组最后一个非叶子节点,其后所有节点都是叶子节点,叶子节点天然满足堆特性 ,无需堆化;从非叶子节点向前堆化,可保证所有子树先有序,逐层向上构建全局堆,避免无效运算。
问3:堆排序是不稳定排序的根本原因?
答:排序过程中存在堆顶与末尾元素的长距离跳跃交换,会直接打乱相等元素的原始相对位置,且堆化过程无法还原顺序,因此天生不稳定,不能用于二次排序场景。
问4:堆排序最坏复杂度稳定O(n log n),为什么工业极少使用?
答:堆排序元素访问跳跃性强,CPU缓存命中率极低;常数级堆化开销远大于快排,整体运行效率低于优化后快速排序,仅适合内存受限、极值查询等特殊场景。
问5:堆排序和优先队列(堆)的区别?
答:①堆排序:静态全排序,一次性对完整数组排序,输出有序序列;②优先队列:动态数据结构,支持实时插入、删除、查询极值,无需全排序,多用于TopK、任务调度、数据流极值场景。
优先队列是一种基于大/小顶堆实现的动态优先级数据结构,不保证整体有序,只保证队首永远是最大值/最小值,支持动态插入、删除、获取极值,是堆在工程中的核心应用。
问6:大顶堆和小顶堆的适用场景区别?
答:大顶堆:用于数组升序全排序;小顶堆:多用于TopK问题,快速筛选前K大/前K小元素,筛选效率更高。
问7:堆排序的核心优势?
答:唯一同时满足原地排序O(1)空间、最坏稳定O(n log n)复杂度的排序算法,无递归栈溢出风险,内存开销极致可控。
5.9 📌 推荐练习题目
-
LeetCode 912(排序数组):堆排序代码落地
-
LeetCode 215(数组中的第K个最大元素):小顶堆经典解法
-
LeetCode 347(前K个高频元素):堆排序高频应用
六、非比较型排序:基数排序(Radix Sort)
6.1 核心区别:不比较大小,按位分配与收集
归并、快排、堆排序均为比较型排序 ,依赖元素大小比较完成排序,理论下界为O(n log n)。而基数排序是典型的非比较型排序 ,不进行任何元素大小对比,通过「按位分配、按位收集」的方式实现排序,可突破O(n log n)限制,达到线性时间复杂度。
6.2 原理详解
基数排序核心思想为低位优先排序(LSD),也是算法刷题、面试的主流实现方式,整体逻辑为:从数字最低位(个位)开始,逐位向高位(十位、百位、千位......)进行排序,每一轮排序都基于上一轮的有序结果,逐位规整,最终实现整体数组完全有序。
核心设计逻辑:局部有序累积为全局有序。每一位的排序都是稳定排序,低位排序完成后,高位排序不会破坏低位已有的有序关系,多轮按位排序叠加后,数组整体自然有序。
算法依赖桶排序思路,数字每一位的取值范围为0-9,因此固定设置10个桶,分别对应0-9十个数字,完成每一轮的元素分配与回收。
6.3 完整执行流程(实例拆解)
以无序数组 [53, 3, 542, 748, 214, 19, 82] 为例,完整复现LSD基数排序全过程:
第一步:确定最大位数
数组中最大值为748,为三位数,因此总共需要执行三轮排序(个位、十位、百位)。
第二轮:按个位排序
提取所有数字个位:3、3、2、8、4、9、2,按个位大小入桶回收,得到数组:[542, 82, 53, 3, 214, 748, 19]
第二轮:按十位排序
基于上一轮结果,提取所有数字十位:4、8、5、0、1、4、1,按十位稳定排序后回收,得到数组:[3, 214, 542, 748, 53, 19, 82]
第三轮:按百位排序
基于十位有序结果,提取百位数字,完成最后一轮排序,最终得到完整有序数组:[3, 19, 53, 82, 214, 542, 748]
核心关键点:每一轮排序必须保证稳定性,否则低位有序结果会被打乱,最终排序失效。
6.4 完整C++代码实现
cpp
//基数排序
//获取当前数组最大值的位数
int Get_MaxNum_figure(int arr[], int len)
{
int max = arr[0];
for (int i = 1; i < len; i++)
{
if (max < arr[i])
max = arr[i];
}
if (max == 0)
return 1;
int count = 0;
while (max != 0)
{
count++;
max /= 10;
}
return count;
}
//获取一个值对应的digit位
int Get_Num_Digit(int num, int digit)
{
for (int i = 0; i < digit; i++)
num /= 10;
return num % 10;
}
//按照i进行单次处理
#include<queue>
void Radix(int arr[], int len, int i)
{
//1. 申请10个队列
std::queue<int> qu_Arr[10];
//2.将arr中len个值,按照对应位的大小入队
for (int j = 0; j < len; j++)
{
int num = Get_Num_Digit(arr[j], i);
qu_Arr[num].push(arr[j]);
}
//3.按照队的顺序,从0号队开始,将队中的元素取出,放回原arr数组
int idx = 0;
for (int i = 0; i < 10; i++)
{
while (!qu_Arr[i].empty())
{
arr[idx++] = qu_Arr[i].front(); //获取对头元素
qu_Arr[i].pop(); //队头元素出队
}
}
}
void Radix_Sort(int arr[], int len)
{
//1. 获取最大值的位数
int fig = Get_MaxNum_figure(arr, len);
//2. 进入for循环
for (int i = 0; i < fig; i++)
{
//3. 按照i进行单次处理
//i = 0:代表个位处理
//i = 1:代表十位处理
//......
Radix(arr, len, i);
}
}6.4.1 代码核心说
-
最大元素位数:遍历找到数组中最大的值,求取其位数,一便后面对每一位取处理
-
依次对每一个数进行处理,按照指定位去计算该数属于哪一个队列,令其入对
-
稳定性保障:元素入队、出队均遵循先进先出规则,严格保证排序稳定性
-
将所有数据处理完后按照从小到大的队列顺序,另每一个队中的元素出队,再赋值给原数组
-
在对后续位进行操作时都是基于前一位有序的条件下
6.5 常见错误
-
计数陷阱:桶计数未重置:每一轮位数排序前,未清空桶内元素计数,导致多轮排序元素叠加、数据错乱,是最高频手写错误。
-
位数陷阱:遍历终止条件错误:未以最大位数作为循环终止条件,提前终止排序或多余循环,导致排序不完整、效率低下。
-
稳定性陷阱:出桶顺序混乱:回收桶内元素时未遵循先进先出,破坏排序稳定性,导致整体有序性失效。
-
数据陷阱:不支持负数/浮点数:基础版基数排序无法处理负数、浮点数,未做偏移处理直接排序会出现越界、乱序。
6.6 算法复杂度与稳定性深度分析
-
时间复杂度 :最好/最坏/平均均为 O(d * n) 。n为数组元素个数,d为数字最大位数。固定位数数据下,d为常数,复杂度等价于O(n)线性级别。
-
空间复杂度 :O(n + 10),需要额外桶空间存储元素,属于非原地排序
-
稳定性 :稳定排序,入桶出桶遵循先进先出,相等元素相对顺序完全保留
6.7 核心优缺点与适用场景
|------|--------------------------------------------------------------------------------------------------|
| 核心优点 | 1. 唯一线性时间复杂度高阶排序,海量固定位数数据排序效率碾压所有O(n log n)排序 2. 排序稳定,无元素相对顺序错乱问题 3. 逻辑简单,无复杂递归、分区、堆化逻辑,机器执行效率极高 |
| 核心缺点 | 1. 数据类型局限性强:仅适用于整数、字符串等可按位拆分的数据,无法直接排序浮点数 2. 额外空间开销大,依赖桶空间存储元素 3. 数据位数不统一时效率下降,位数越大,循环排序次数越多 |
适用场景
-
海量固定位数整数排序(手机号、身份证号、学号等)
-
需要稳定线性排序的业务场景
-
多关键字二次排序场景
6.8 高频面试考点
问1:基数排序为什么能突破比较排序O(n log n)的下界?
答:比较排序必须通过元素大小对比确定顺序,理论下界为O(n log n);而基数排序是非比较排序,不进行任何元素大小比对,通过按位分桶、稳定收集实现有序,因此可以达到线性O(n)复杂度。
问2:简述LSD低位优先基数排序执行流程?
答:先获取数组最大值确定最大位数,从最低位(个位)开始,逐位向高位遍历;每一轮按当前位数值将元素分配到0-9对应桶中,再按桶顺序稳定回收元素;多轮按位排序后,低位有序叠加高位有序,最终全局有序。
问3:基数排序为什么是稳定排序?
答:元素入桶、出桶遵循先进先出规则,同一桶内的相等元素会严格保留原始相对顺序,每一轮按位排序都是稳定排序,叠加后整体稳定。
问4:基数排序、计数排序、桶排序三者区别与选型?
答:①基数排序:按数位分桶,适配固定位数整数 (手机号、身份证),稳定线性排序;②计数排序:统计数值频次,适配数值范围小、数据密集 场景;③桶排序:区间分桶,适配数据均匀分布场景,通用性最强。
问5:基数排序的局限性是什么?
答:仅支持可按位拆分的离散数据(整数、字符串),无法直接排序浮点数;数据位数过长时,循环次数剧增,效率大幅下降;需要额外桶空间,非原地排序。
问6:LSD和MSD的区别?各自适用场景?
答:LSD低位优先:从低到高排序,逻辑简单、代码易实现,适合刷题、通用整数排序;MSD高位优先:从高到低递归排序,适合字符串、不定长数据排序,实现复杂。
问7:基数排序如何处理负数?
答:通过数据偏移法,找到数组最小值,将所有元素整体偏移为非负数,排序完成后再还原偏移量,即可兼容负数数组。
6.9 📌 推荐练习题目
-
LeetCode 912(排序数组):基数排序代码落地验证
-
LeetCode 164(最大间距):基数排序经典压轴应用题
-
牛客网:海量手机号排序场景模拟题
七、四大高阶排序算法总复盘与面试对比汇总
7.1 核心参数对照表(面试必背)
|------|------------|------------|----------|------|-----|
| 排序算法 | 平均复杂度 | 最坏复杂度 | 空间复杂度 | 原地排序 | 稳定性 |
| 归并排序 | O(n log n) | O(n log n) | O(n) | 否 | 稳定 |
| 快速排序 | O(n log n) | O(n²) | O(log n) | 是 | 不稳定 |
| 堆排序 | O(n log n) | O(n log n) | O(1) | 是 | 不稳定 |
| 基数排序 | O(d*n) | O(d*n) | O(n) | 否 | 稳定 |
7.2 场景选型终极口诀
-
通用场景、追求极致速度:优先选择优化后快速排序
-
要求排序稳定、链表排序:唯一选择归并排序
-
内存受限、无额外空间:唯一选择堆排序
-
海量固定位数整数数据:优先选择基数排序
-
存在大量重复元素:优先选择三路快排
八、总结
四大高阶排序是数据结构与算法的核心分水岭,区别于简单排序的暴力遍历,归并、快排依托分治思想,堆排序依托树形结构,基数排序突破比较排序限制,从不同维度优化排序效率。
在刷题与面试中,无需盲目追求所有算法最优解,重点掌握:快排的优化、归并的稳定性、堆排的原地特性、基数的线性效率,根据业务场景灵活选型,即可应对绝大多数算法考察与工程开发场景。