全双工通话的"静默"革命:破解近距离啸叫难题
在楼宇对讲与车载蓝牙系统的设计中,工程师们常面临一个棘手的声学困境:为了追求设备的小型化与美观,扬声器与麦克风往往被压缩在极近的距离内。这种布局极易引发严重的声学反馈,导致通话中出现刺耳的啸叫,或者迫使系统进入半双工模式(即一方说话时另一方必须静音),严重牺牲了沟通的自然度与效率。特别是在医院呼叫系统或停车场自助终端等嘈杂环境中,如何在高音量下实现流畅的全双工通话,成为了衡量产品竞争力的关键指标。AU-60 语音处理模组的出现,正是为了解决这一核心痛点,其集成的 100dB 回声消除(AEC)能力与低至 100ms 的处理延迟,为复杂声学环境下的清晰通话提供了坚实的硬件基础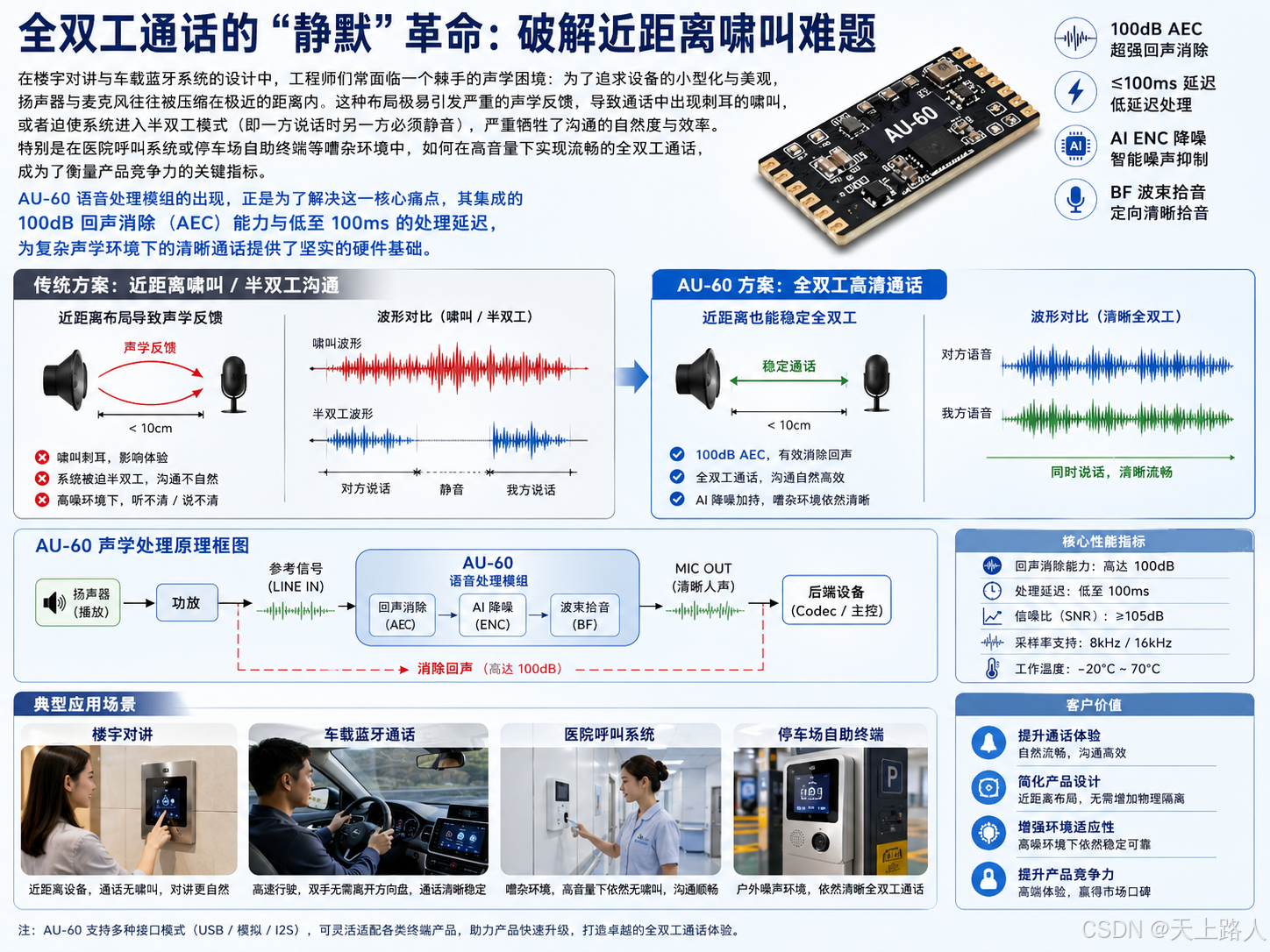
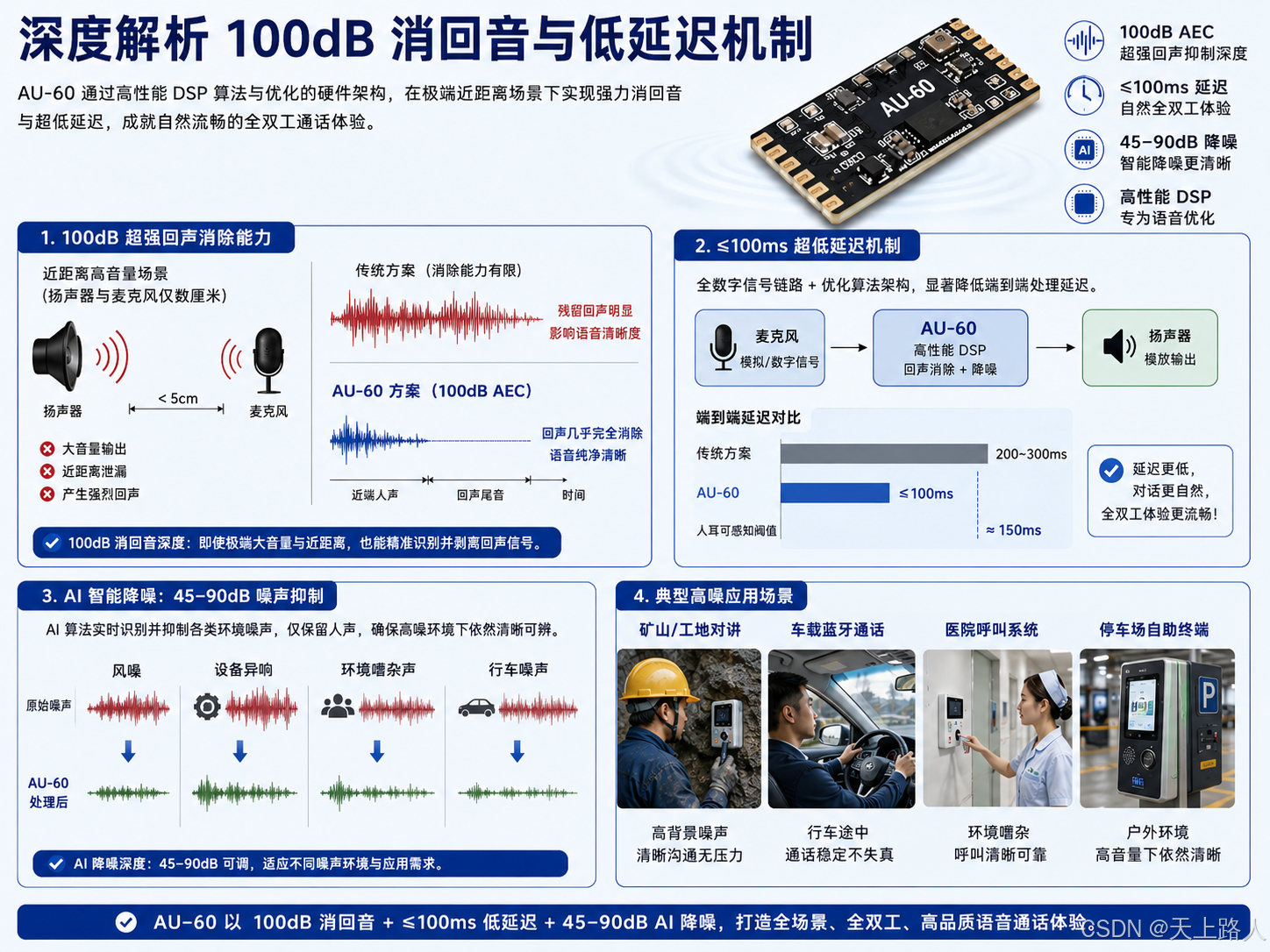
深度解析 100dB 消回音与低延迟机制
AU-60 的核心优势在于其强大的数字信号处理能力,能够应对极端条件下的回声干扰。传统方案在处理大音量回声时,往往因动态范围不足而导致消除不彻底,残留的尾音会严重影响语音清晰度。AU-60 通过内置的高性能 DSP 算法,实现了高达 100dB 的回声抑制深度。这意味着,即使扬声器输出音量极大,且麦克风距离扬声器仅几厘米,模组也能精准识别并剥离从扬声器泄漏到麦克风的回声信号,确保远端听不到自己的声音重复。
更为关键的是其低延迟特性。在全双工通话中,过长的处理延迟会导致对话出现明显的"卡顿"感,打断交流节奏。AU-60 将回声消除的算法延迟控制在 100ms 以内,这一数值远低于人耳对延迟的敏感阈值,使得双向同时讲话时的交互体验如同面对面交谈般自然。配合 45--90dB 的 AI 智能降噪功能,该模组不仅能消除回声,还能同步抑制风噪、设备运行异响及环境背景音,确保在矿山、车间或行车途中等高噪场景下,人声依然清晰可辨。
参考信号采集:前端与后端的电路抉择
实现高效回声消除的前提,是模组必须获取准确的参考信号(Reference Signal),即扬声器即将播放或正在播放的声音信号。在电路设计阶段,工程师需要在功放前端与后端之间做出选择,这两种方式各有优劣,需根据具体应用场景权衡。
从功放前端取值是较为常见的方案。此时参考信号未经功率放大,电平较低且波形纯净,直接接入 AU-60 的参考输入端即可。这种方式的优势在于电路简单,无需额外的衰减网络,且信号失真小,有利于算法快速收敛。然而,若功放本身存在较大的非线性失真,前端参考信号可能无法完全代表最终发出的声音,从而影响消回音效果。
相比之下,从功放后端 取值能更真实地反映扬声器发出的实际声波,包含了功放环节产生的所有失真特性,理论上能获得更佳的对消效果。但挑战在于,功放输出的电压幅度通常远高于模组的输入承受范围。例如,车载或工业功放的输出可能达到十几伏甚至更高,而 AU-60 的模拟输入通常限制在毫伏至伏特级。因此,后端取值必须设计精密的阻容分压电路,将高压信号线性衰减至安全范围,同时需注意阻抗匹配,避免负载效应影响功放性能。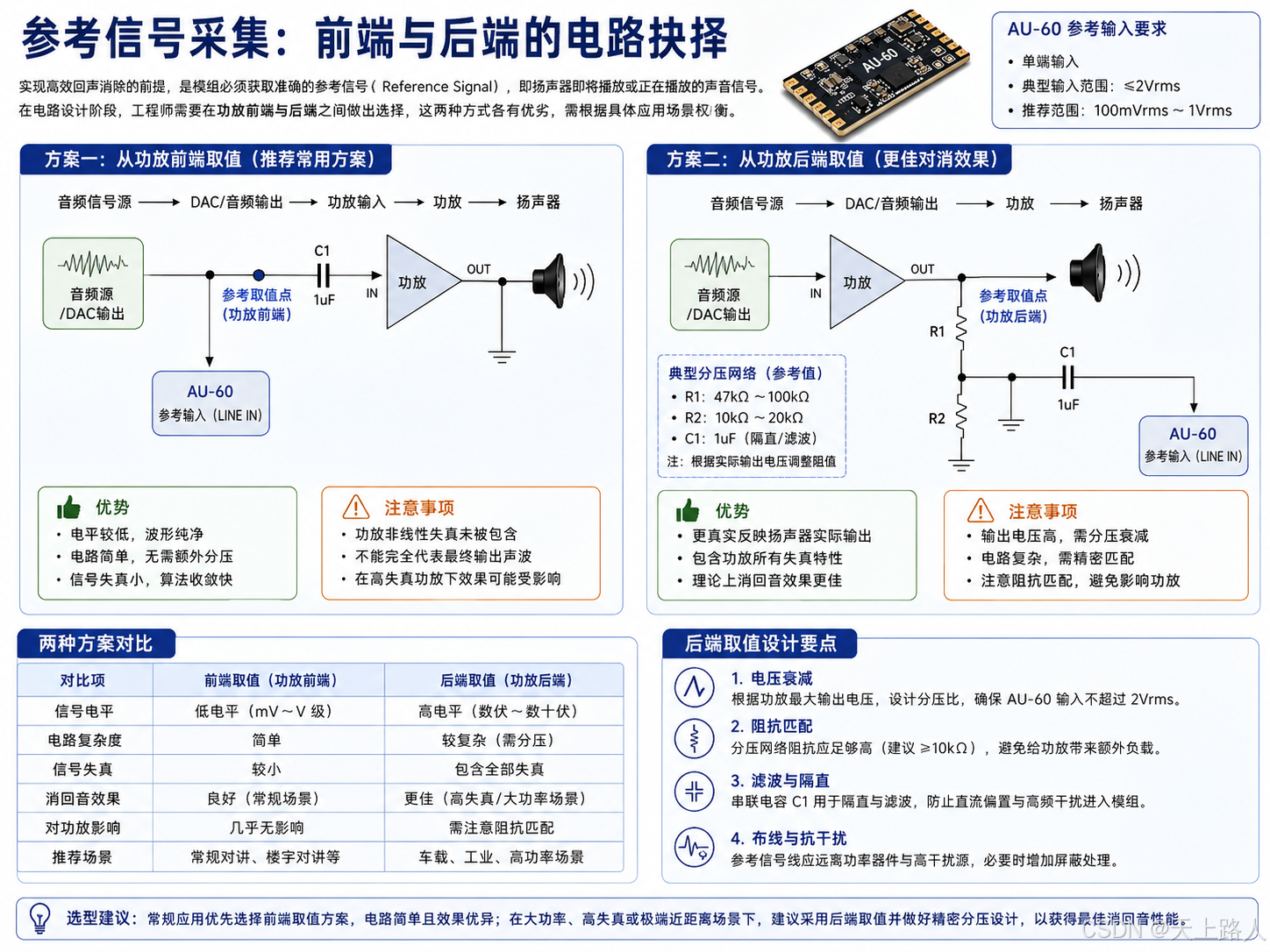
阻抗匹配与分压网络的实战计算
在高音量全双工应用中,模拟输出接口的阻抗匹配与信号幅度控制至关重要。若信号幅度过大,会导致 AU-60 内部 ADC 削波失真,不仅无法消除回声,反而会引入新的噪声;若信号过小,则信噪比下降,算法难以捕捉有效参考信息。
设计分压网络时,假设功放后端输出电压峰值为 VoutV_{out}Vout,AU-60 参考输入端的最佳工作电压峰值为 VinV_{in}Vin(通常建议控制在 500mV~1V 之间,具体需查阅数据手册)。我们需要构建一个由电阻 R1R_1R1 和 R2R_2R2 组成的分压器。根据分压公式 Vin=Vout×R2R1+R2V_{in} = V_{out} \times \frac{R_2}{R_1 + R_2}Vin=Vout×R1+R2R2,可推算出电阻比例。例如,若功放输出为 10V,目标输入为 0.5V,则分压比需为 1:20。
在实际布线中,建议在分压电阻后串联一个小容量电容(如 10nF~100nF)进行高频滤波,滤除功放可能引入的高频开关噪声。同时,需注意 AU-60 模拟输入端的阻抗特性,确保分压网络的输出阻抗远小于模组输入阻抗,以保证信号传输效率。对于差分信号输入的应用场景,还需保持正负通道的电阻精度一致,以维持良好的共模抑制比,进一步提升抗干扰能力。

从医院呼叫到停车场终端的实施路径
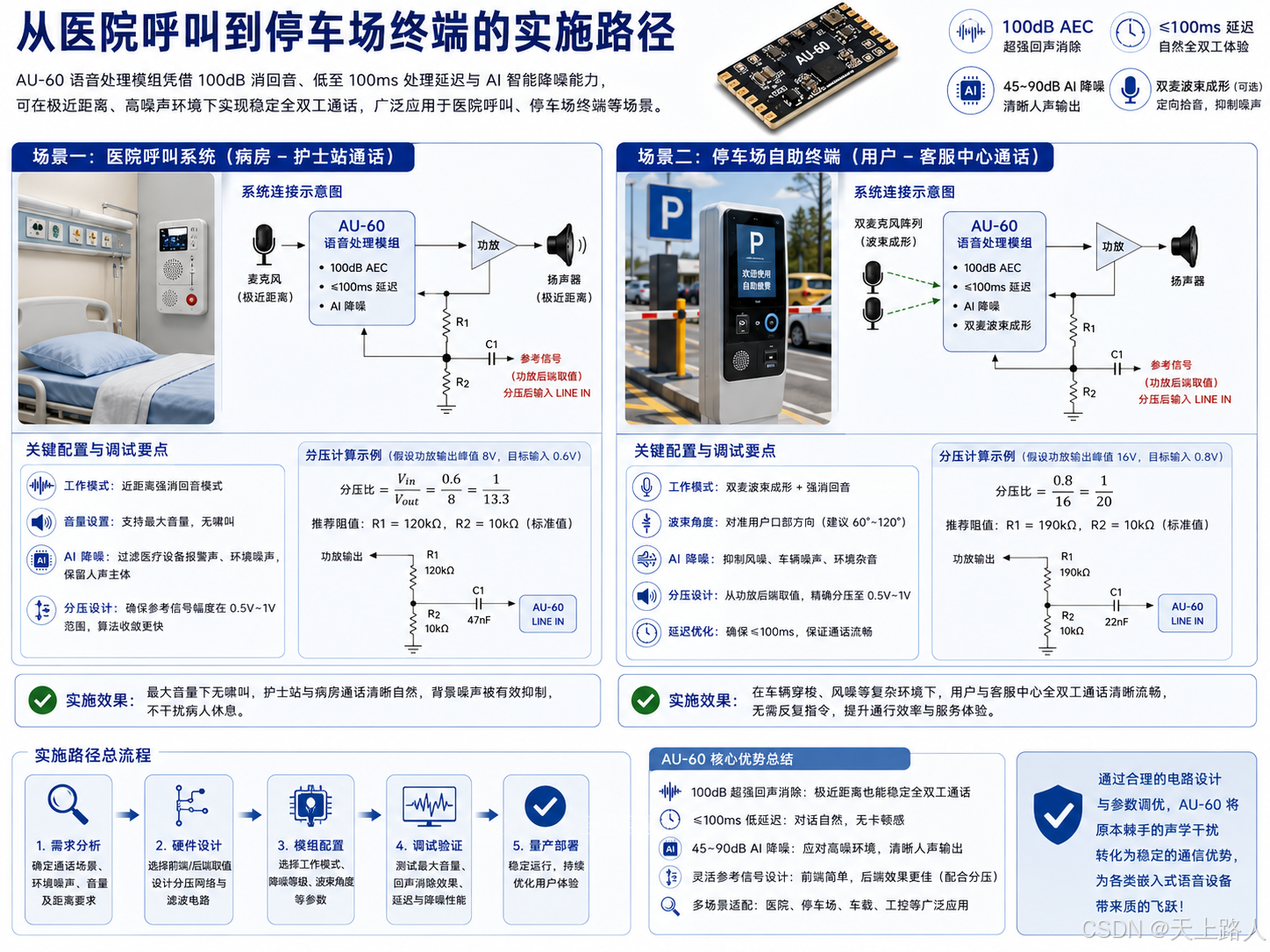
理论设计最终需落地于具体场景。以医院呼叫系统为例,病房环境要求极高的语音清晰度且不能有啸叫干扰病人休息。采用 AU-60 方案时,可将模组部署在床头主机内,麦克风与扬声器间距极近。调试阶段,首先配置为"近距离强消回音"模式,利用其 100dB 的消除能力压制潜在的声反馈。通过调整分压网络,确保护士站与病房双向通话时,即使音量调至最大,也不会出现鸣叫,且背景中的医疗设备报警声能被 AI 降噪算法有效过滤,保留人声主体。
在停车场自助终端场景中,环境噪声复杂且存在风噪干扰。此时应启用 AU-60 的双麦波束成形功能(若硬件支持双麦),将拾音波束对准用户口部方向,抑制来自四周的车辆噪音。参考信号取自内部功放后端,经过精确分压后输入模组。实测表明,在该配置下,即便在车辆穿梭的嘈杂环境中,用户也能与客服中心进行流畅的全双工沟通,无需反复重复指令,显著提升了通行效率与服务体验。
通过合理的电路设计与参数调优,AU-60 能够将原本棘手的声学干扰转化为稳定的通信优势,为各类嵌入式语音设备带来质的飞跃。