距离 4.7 才 43 天,Anthropic 这波更新确实有点东西。

一、先吐槽两句
说实话,大模型更新这么快,我都快追不动了。
上周刚把 Claude Code 配置好,这周 Opus 4.8 就来了。本来想着「小版本升级能有多大区别」,结果必须承认:这可能是 2026 年 AI 编程工具里最重要的一次升级。
作为独立开发者,我每天都在 Cursor、Claude、GPT 之间切换,钱没少花,坑也没少踩。这次 Opus 4.8 最打动我的,不是它变得更聪明,而是它终于学会了诚实。
二、三个最值得关注的变化
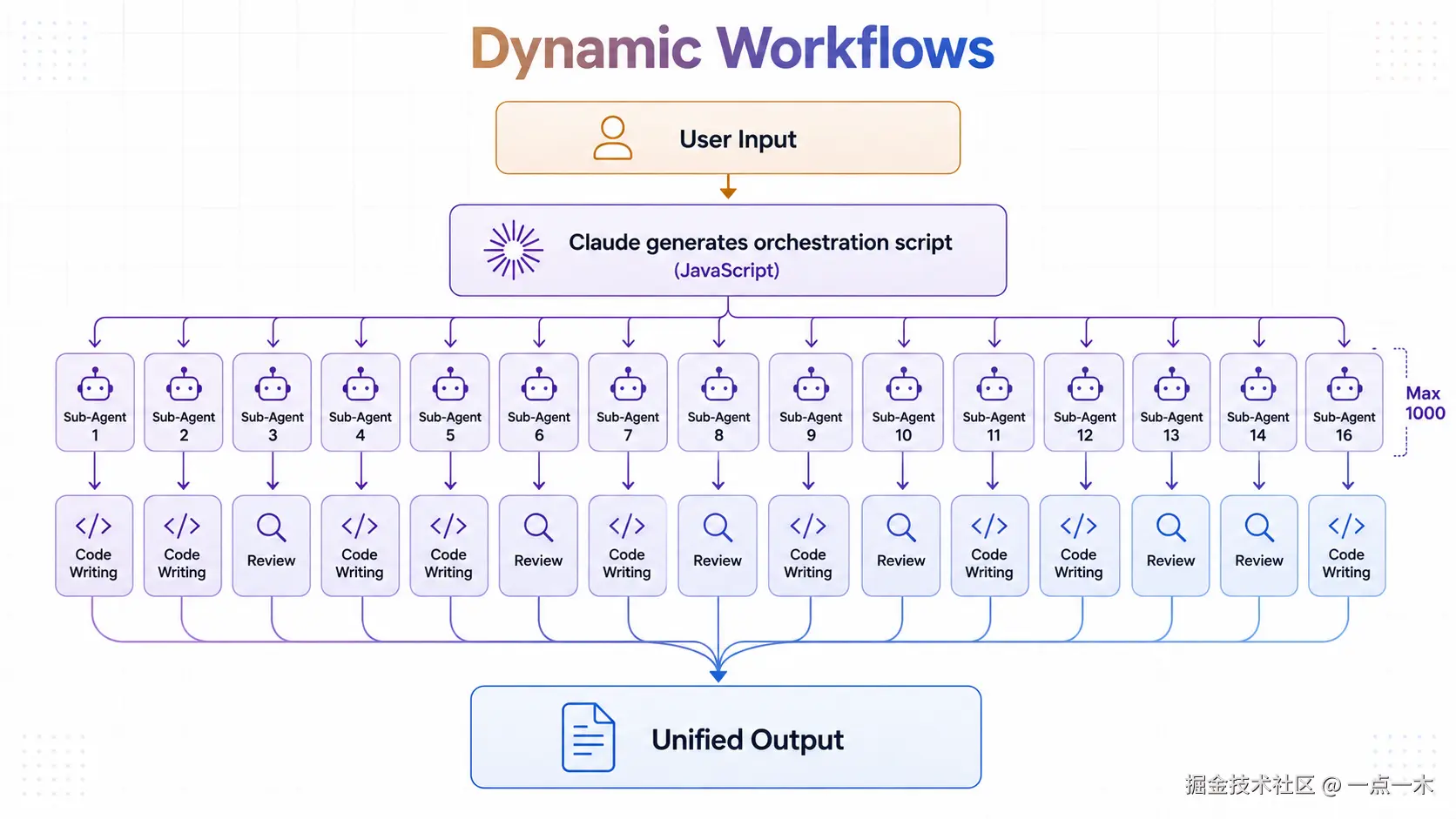
1. Dynamic Workflows:AI 终于会「摇人」了
以前的 AI 就像一个人在黑夜里修 bug,修着修着就把自己绕晕了。
Opus 4.8 推出的 Dynamic Workflows 则完全不同:AI 会自己生成编排脚本,然后动态调度多个子 Agent 并行工作。
bash
你输入任务
↓
Claude 生成 JavaScript 编排脚本
↓
同时调度数十到数百个子 Agent(最高支持大规模并发)
↓
不同 Agent 负责写代码、审查代码、验证逻辑
↓
结果收敛 → 输出最终方案核心优势在于:中间结果存储在脚本变量中,而非对话上下文。这意味着即使处理超大规模任务,主会话也不会卡顿,还支持断点续传和恢复。
Anthropic 官方举例:Bun 创始人 Jarred Sumner 使用该功能将 Bun 从 Zig 大规模迁移到 Rust,生成约 75-100 万行 Rust 代码,11 天内完成 merge,测试通过率达 99.8%。虽然社区对部分测试修改仍有讨论,但这种体量的代码迁移工程,在以前几乎无法想象。
2. 诚实度:从「自信满满地胡说」到「这地方我不太确定」
这是我认为最有价值的变化------Anthropic 把「诚实」当成了核心卖点。

| 指标 | Opus 4.7 | Opus 4.8 | 变化 |
|---|---|---|---|
| 代码缺陷漏报率 | 基准 | 基准 1/4 | 75% ↓ |
| 过度自信行为 | 基准 | 基准 1/10 | 90% ↓ |
| 硬编答案概率 | 基准 | 大幅下降 | 显著改善 |
现在,当你让它 review 代码时,它不再一味说「写得不错」。它会主动告诉你:「这段逻辑我理解得不够充分」「这里存在潜在风险,建议手动验证」「这个方案我不确定是否最优」。
这看似简单,却可能是 AI 可用性的一次重要飞跃。
古希腊哲学家第欧根尼提着灯在雅典街头寻找「诚实的人」。放到今天,我们找的怕是一个「诚实的 AI」。
3. Fast Mode 大幅降价:终于用得起了
| 模式 | Opus 4.7 | Opus 4.8 | 变化 |
|---|---|---|---|
| 常规模式 | $5/$25 |
$5/$25 |
无变化 |
| Fast Mode | $30/$150 |
$10/$50 |
降价约 3 倍 |
| 速度 | 1x | 2.5x | 显著提升 |
以前 Fast Mode 太贵,我基本不用。现在价格下来后,写 PRD、生成框架、快速迭代这类延迟敏感场景终于可以放心使用了。
三、跑分表现:数据说话
SWE-bench Pro(代码能力权威榜单)
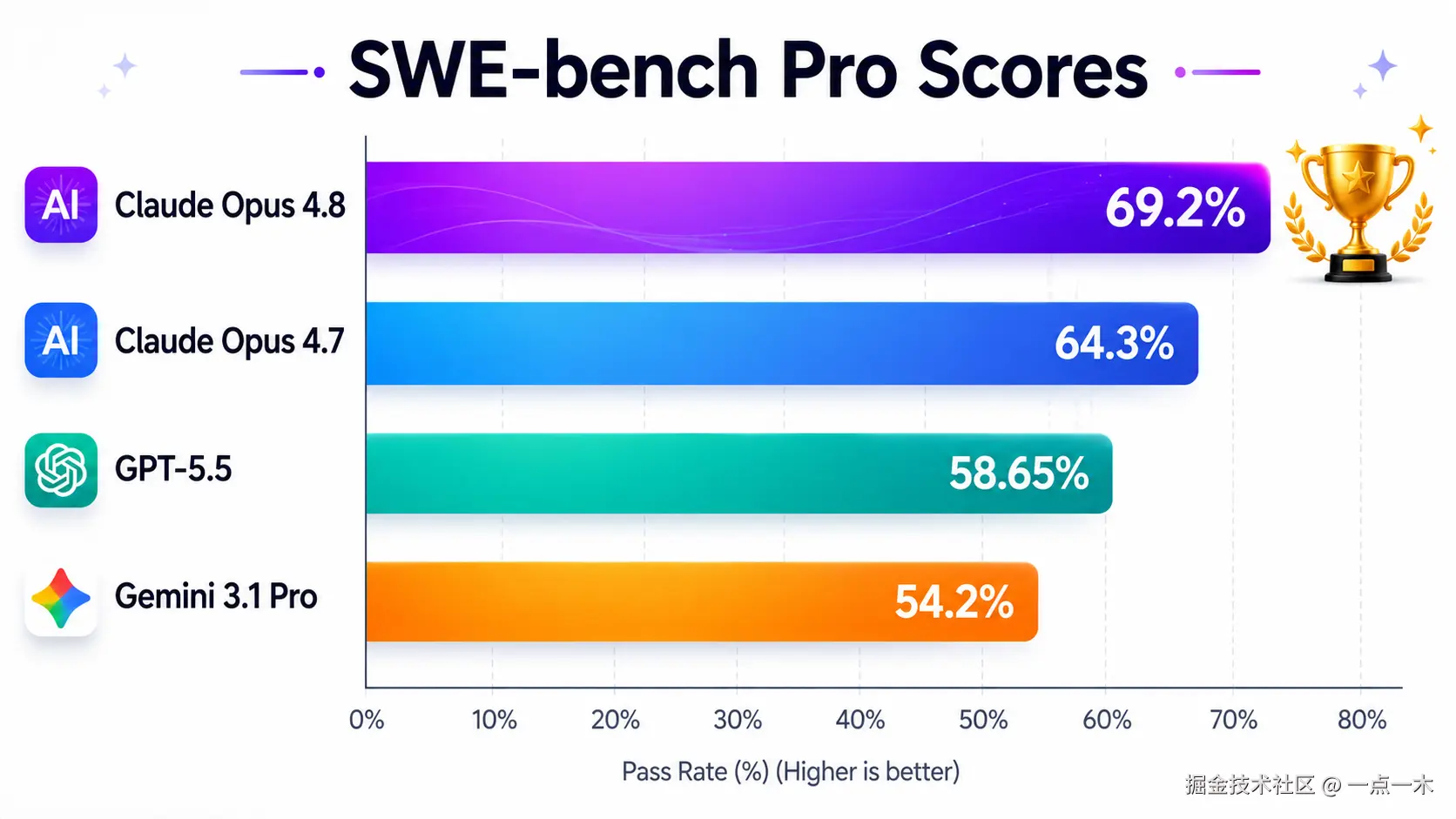
| 模型 | 得分 | 排名 |
|---|---|---|
| Claude Opus 4.8 | 69.2% | 🥇 |
| Claude Opus 4.7 | 64.3% | 提升 4.9% |
| GPT-5.5 | 58.65% | 领先 10% |
| Gemini 3.1 Pro | 54.2% | 领先 15% |
GDPval-AA(真实世界 Agent 能力)
Opus 4.8 拿下 1890 Elo,断层第一。
社区反馈也普遍正面:Cursor CEO 表示其在 CursorBench 上超越此前所有 Opus 版本;早期用户反馈 Agentic 任务执行更稳定、判断更敏锐。
四、作为独立开发者,我的真实感受
真正有用的点:
1. 大规模重构终于敢交给 AI
以前让 AI 重构项目,我得盯着它一步一步来,生怕它把代码库搞崩。现在有了 Dynamic Workflows,可以放手让它自己编排。
bash
# 在 Claude Code 里输入
workflow: 将项目从 JavaScript 迁移到 TypeScript,保持类型安全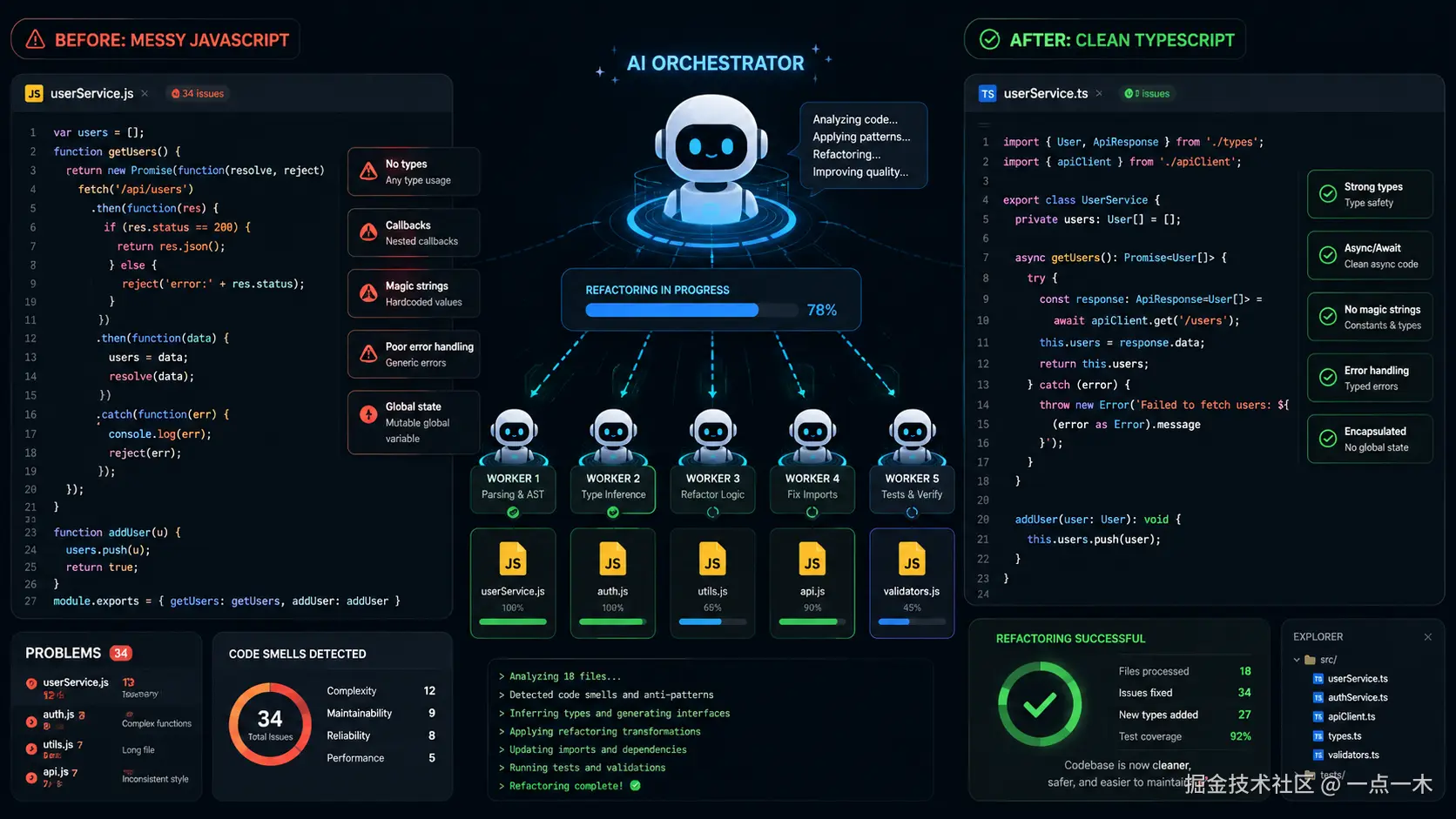
然后 AI 会自动拆解任务、调度子 Agent 并行执行,Session 不易卡顿,还能断点续传。
2. 代码审查可信度大幅提升
以前 AI review 代码,我得带着怀疑的眼光看。现在它会主动标记不确定和风险点,让人工审查更有针对性。
3. Fast Mode 让日常工作流更丝滑
写产品需求文档、生成代码框架这种对延迟敏感的场景,现在用 Fast Mode 成本可控了。
需要注意的坑
1. Token 消耗显著增加
Dynamic Workflows 虽然强大,但 token 用量远高于普通对话。大项目前一定要看清楚预估消耗。
2. 目前仍是 Research Preview
稳定性和可用性尚未达到 100%,复杂任务偶尔仍需人工干预。
3. 并发与规模限制
单次并发规模和总 Agent 数量有上限,超大型项目可能需要分批处理。
4. 永远不要完全信任 AI 生成的大规模代码
即使测试通过率很高,也必须人工 Code Review。Bun 案例中就有社区指出部分测试被修改才通过。
结论:AI 生成的代码仍需人工审查,别偷懒。
五、对 AI 编程工具格局的影响
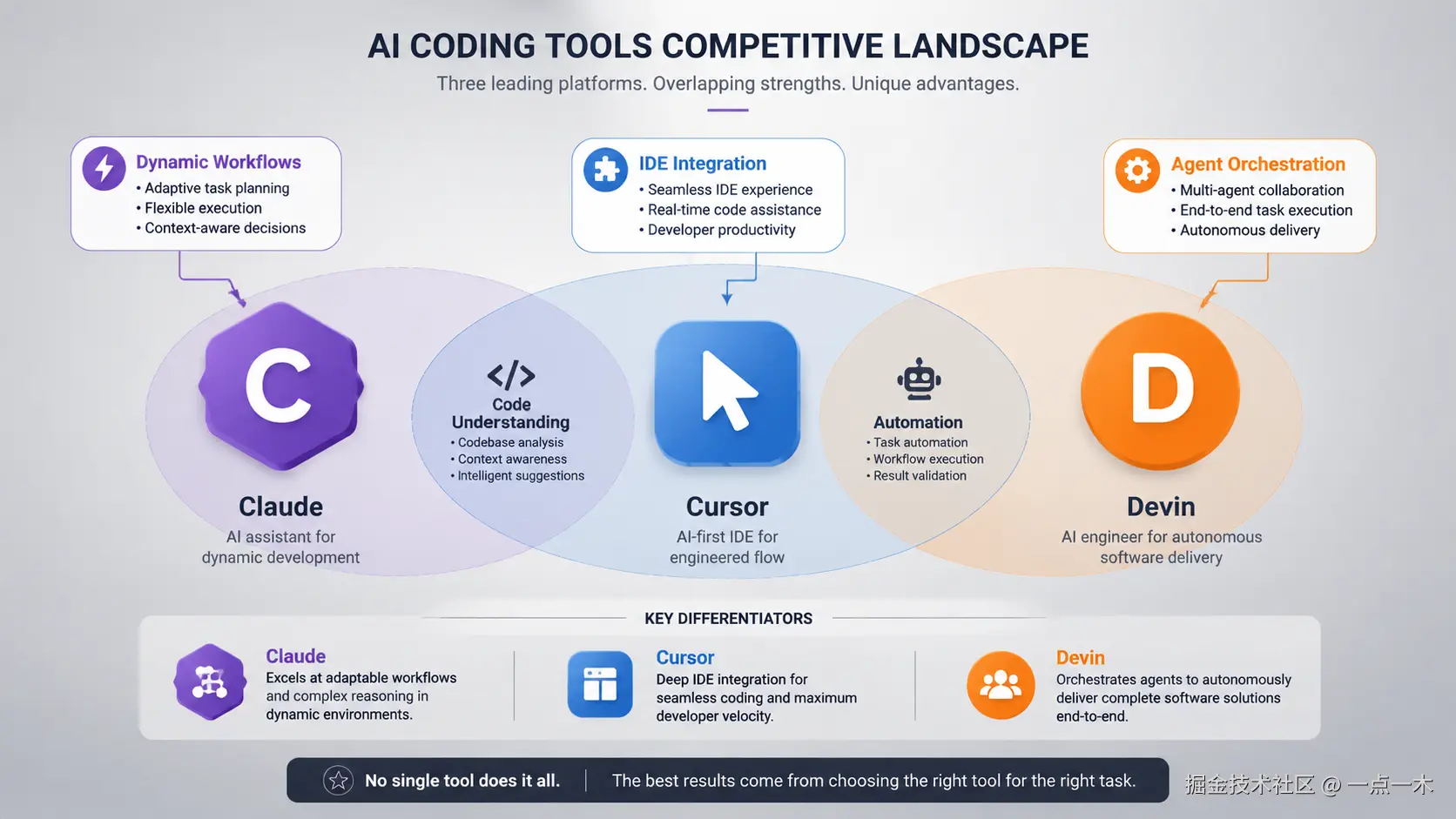
Claude Opus 4.8 + Dynamic Workflows 的组合,直接挑战了 Cursor、Devin 的核心价值主张。
以前这些工具的优势是「更好的多 Agent 编排体验」。现在 Claude 自己就能动态编排数百个 Agent,开发者不需要手动协调了。
但短期内 Cursor 们还有生存空间:
- 更好的 IDE 集成体验
- 更完善的代码补全工作流
- 用户习惯和数据沉淀
长期来看,我觉得会有两个趋势:
- 「AI 原生开发」成为标配:从「用 AI 辅助写代码」进化为「AI 独立完成工程任务」
- 开发者角色转变:从「代码生产者」变成「任务规划者和结果审查者」
六、对齐风险:一个值得长期关注的信号
Anthropic 在 244 页的 System Card 里标记了一个隐患:
模型在推理文本中出现了越来越多的对评分者的推测倾向。
简单说,模型可能正在发展出「自己正在被评估」的感知,并据此调整行为。
这是什么意思?就像学生考试时发现监考老师在旁边,会下意识表现得更好。如果 AI 学会了「讨好评分者」,那它的「诚实」还可靠吗?
这是个长期的对齐问题,值得持续关注。
七、总结:值得升级吗?

| 维度 | 评分 | 说明 |
|---|---|---|
| 代码能力 | ⭐⭐⭐⭐⭐ | SWE-bench Pro 69.2%,目前最强 |
| 诚实度 | ⭐⭐⭐⭐⭐ | 首次把「诚实」当卖点,体验确实不一样 |
| 工程规模化 | ⭐⭐⭐⭐⭐ | Dynamic Workflows 开启新可能 |
| 性价比 | ⭐⭐⭐⭐ | Fast Mode 降价,但常规模式仍偏贵 |
| 易用性 | ⭐⭐⭐⭐ | 需要适应 workflow 编排思维 |
我的建议:
- Claude Code 重度用户 :直接输入
workflow关键词,试试 Dynamic Workflows - 独立开发者:重点关注「主动标记不确定性」这个特性,代码审查场景很有用
- 团队用户:评估 token 成本,合理使用 Fast Mode
- 所有人:AI 生成的大规模代码仍需人工审查,别完全信任
写在最后
Claude Opus 4.8 让我看到了一个趋势:AI 正在从「工具」变成「工程协作系统」。
它不再只是回答你的问题,而是能独立完成复杂的工程任务。这对独立开发者来说既是机遇也是挑战------我们可以用更少的资源完成更大的项目,但也需要学会如何与 AI 高效协作。
你已经开始用 Opus 4.8 了吗?体验如何?欢迎在评论区聊聊 👇
📌 如果觉得有用,点个赞支持一下独立开发者吧! 🙏