作者:来自 Elastic Jonas Kunz
随时查询任意百分位。Elasticsearch 原生存储 OTel exponential histograms,并允许你在 ES|QL 中分析分布数据,而无需固定桶或有损转换。
Elasticsearch 在 ES|QL 中为 OpenTelemetry 指数直方图提供原生支持。与固定桶直方图不同,指数直方图会根据你的数据动态适应 ------ 在查询时提供更准确的百分位估计(median、中位数,p99,以及你想要的任意 percentile),并带有可保证的误差边界。不再需要预先定义桶,也不再需要有损转换。只需将你的 OpenTelemetry metrics 发送到 Elasticsearch 的 OTLP/HTTP endpoint,它们就会使用新的 exponential_histogram 类型存储,并可立即查询。如果你已经有存储在经典直方图类型中的历史数据?在 ES|QL 查询中使用简单的 ::exponential_histogram cast 即可透明迁移。如果你已经在使用 downsampling?现在两种直方图字段类型都已完全支持。
直方图指标
在处理 metrics(例如在 OpenTelemetry 或 Prometheus 中)时,计数器和仪表是最常见的指标类型。仪表允许你监控会上升或下降的值(例如 CPU 利用率)。计数器用于计数,例如你的服务正在处理的 HTTP 请求总数。计数器通常只会递增,只有在某些情况下会重置,比如服务器重启时。
对于计数器,你还可以额外收集一个用于记录 HTTP 响应时间总和的计数器,从而通过 "总和/请求数" 计算平均响应时间。然而,平均响应时间对数据分布和系统行为的洞察非常有限。更好的洞察来自对指标分布的分析,例如 median 和 percentile 计算,而这正是计数器的短板。
过去,人们采用过一些替代方案:例如经典 Prometheus 风格的直方图通过一组计数器来近似分布。通过定义固定桶(例如 [0s, 1s)、[1s, 4s) 等区间),并为每个桶设置一个计数器,我们至少可以粗略估计百分位数。但关键问题在于,我们必须提前知道数据分布才能正确定义这些桶。
为此 OpenTelemetry 社区提出了更好的方案:exponential histograms。exponential histograms 与经典 Prometheus 风格直方图一样,将采集到的值分配到桶中。关键区别在于这些桶会根据采集数据动态变化。"exponential" 这个名称来自桶大小呈指数增长:小值使用更细粒度的桶,大值使用更宽的桶。你可以在 OpenTelemetry exponential histograms 介绍中找到非常好的说明。
需要注意的是,除了经典直方图之外,Prometheus 也引入了 native histograms,它直接映射到 OTel exponential histograms。native histograms 有自己对应的 PromQL 语法。我们正在积极为 Elasticsearch 的 PromQL 实现添加对该语法的支持,以便你可以直接用 PromQL 查询 exponential histograms。
演示设置
我们先开始采集一些直方图指标,展示它们如何在 Elasticsearch 中使用 ES|QL 进行存储与分析。
这里我们关注一个 Java JVM 指标:垃圾回收(GC)耗时。OpenTelemetry 定义了 jvm.gc.duration,这是一个 histogram 类型指标。OpenTelemetry Java agent 原生支持采集这个指标。
我们将启动一个运行 Renaissance 基准测试的 JVM 来对其施加压力。启动该 JVM 时会附加标准的 OpenTelemetry Java agent,并让它直接把指标发送到 Elasticsearch。
你可以在这里找到可直接运行的 Docker Compose 文件。你只需要在 docker-compose.yml 中填入你的 Elasticsearch OTLP/HTTP endpoint 和 API key。
OTEL_EXPORTER_OTLP_ENDPOINT: https://<elasticsearch url>/_otlp
OTEL_EXPORTER_OTLP_HEADERS: "Authorization=ApiKey <base64 API key>"注意,你不一定需要使用这个演示环境。我们甚至鼓励你用自己的应用来尝试。下面是该 demo 已经包含的其他重要 OpenTelemetry agent 配置,如果你在自己的应用中接入,也应一并加入:
OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE: delta
OTEL_EXPORTER_OTLP_METRICS_DEFAULT_HISTOGRAM_AGGREGATION: BASE2_EXPONENTIAL_BUCKET_HISTOGRAM
OTEL_INSTRUMENTATION_RUNTIME_TELEMETRY_ENABLED: "true"我们逐项来看:
- Temporality preference(时间性偏好):OpenTelemetry 同时支持 cumulative(累积型)和 delta(增量型)直方图。cumulative 表示直方图只有在应用重启时才会清空,而 delta 则在每次导出后清空。目前 Elasticsearch 只支持 histogram 的 delta 时间性。我们也在积极支持 cumulative histograms。
- Default Histogram Aggregation(默认直方图聚合):默认情况下,OpenTelemetry 会以 Prometheus 风格的固定桶格式导出直方图。由于我们希望使用 exponential histograms 的优势,需要在 agent 中显式指定使用该格式。
- Runtime Telemetry enabled(运行时遥测开启):该配置用于让 agent 实际采集详细的 JVM 指标,其中包括 jvm.gc.duration。
现在我们已经准备好了!我们将让应用在后台运行,然后切换到 Kibana 来分析 GC 指标。
使用 ES|QL 查询
现在我们打开 Kibana 并进入 "Discover"。在那里切换到 ES|QL 模式,然后开始查询已采集的数据:
TS metrics-* | STATS COUNT(jvm.gc.duration)作为结果,你现在会看到下面所示的指标面板。如果没有看到任何数据,请务必检查 Kibana 的时间范围过滤器是否正确设置。
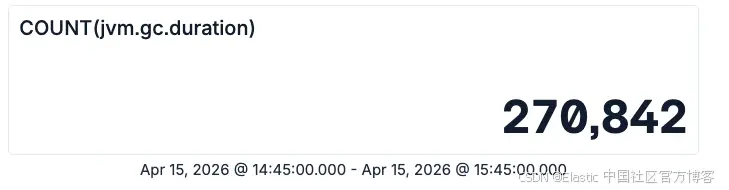
这个数字表示在所选时间范围内,你的测试应用中发生的垃圾回收(GC)操作总次数。
同样地,我们也可以查询这些垃圾回收操作所花费的总时间:
TS metrics-* | STATS SUM(jvm.gc.duration)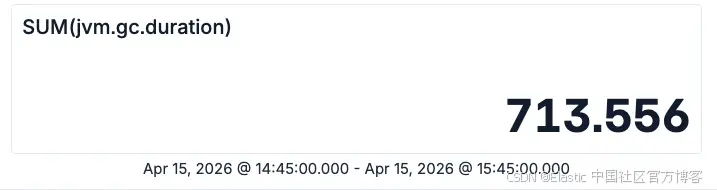
所以我们大约有 27 万次垃圾回收,总共耗时 713 秒。根据这两个数字,如果你还记得小学数学,就可以计算出平均值。如果不记得,也可以直接让 ES|QL 帮你完成计算:
TS metrics-* | STATS AVG(jvm.gc.duration)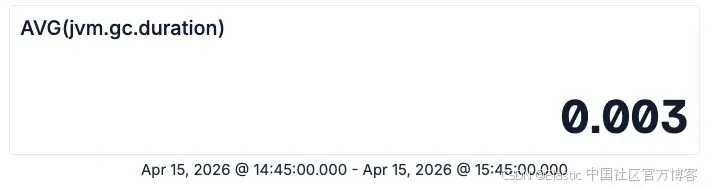
现在我们知道平均一次垃圾回收操作大约耗时 3 毫秒。然而,Java 专家可能知道,实际上会发生不同类型的垃圾回收,而它们的停顿时间可能差异很大。幸运的是,OpenTelemetry 指标带有 attributes,这使我们可以按不同维度对数据进行切分分析:
TS metrics-* | STATS AVG(jvm.gc.duration) BY jvm.gc.action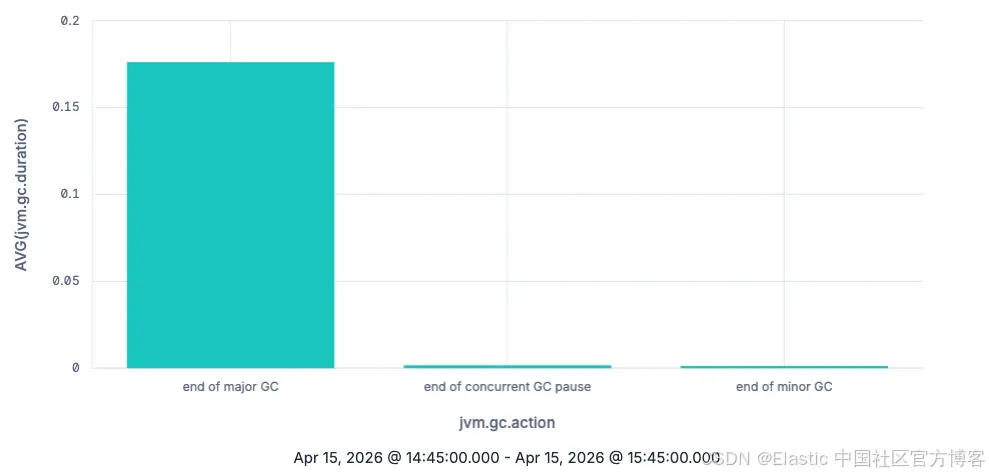
正如预期,major garbage collections(主要垃圾回收)在每次操作的平均耗时上,明显比 minor garbage collections 更高。
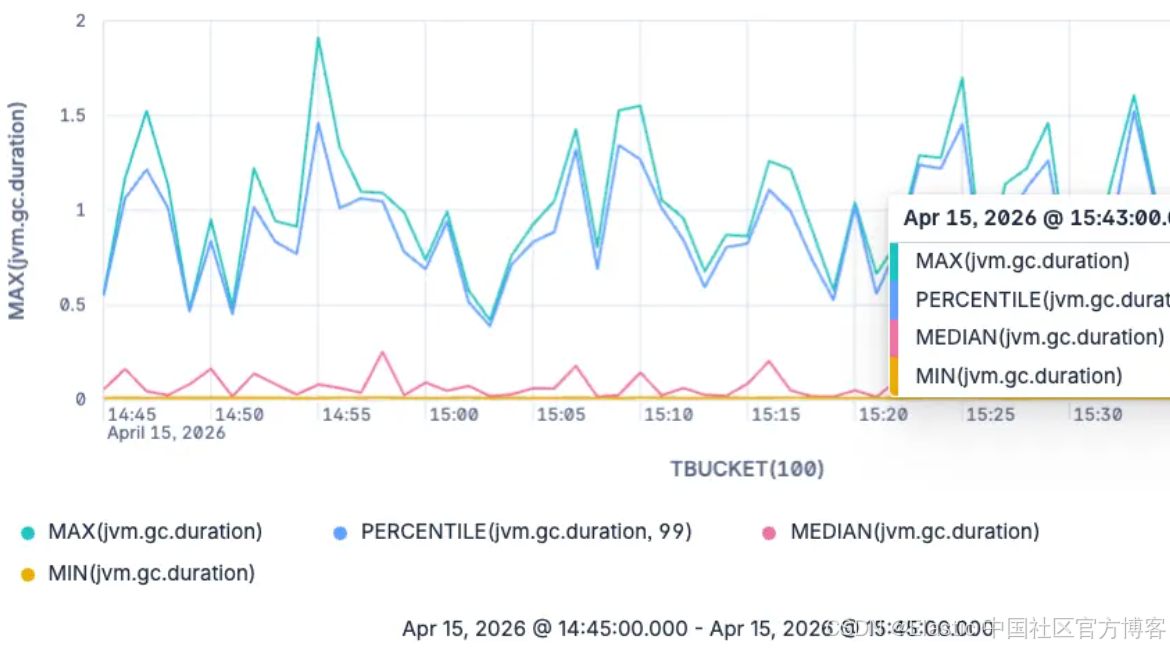
到目前为止,我们做的事情,其实都可以仅通过 counters 实现。但接下来,我们将使用 histograms 来理解 GC latency 的真实分布情况。我们会按时间对数据进行分组(使用 TBUCKET),并重点分析 major garbage collections:
TS metrics-*
| WHERE jvm.gc.action == "end of major GC"
| STATS MAX(jvm.gc.duration),
PERCENTILE(jvm.gc.duration, 99),
MEDIAN(jvm.gc.duration),
MIN(jvm.gc.duration)
BY TBUCKET(100)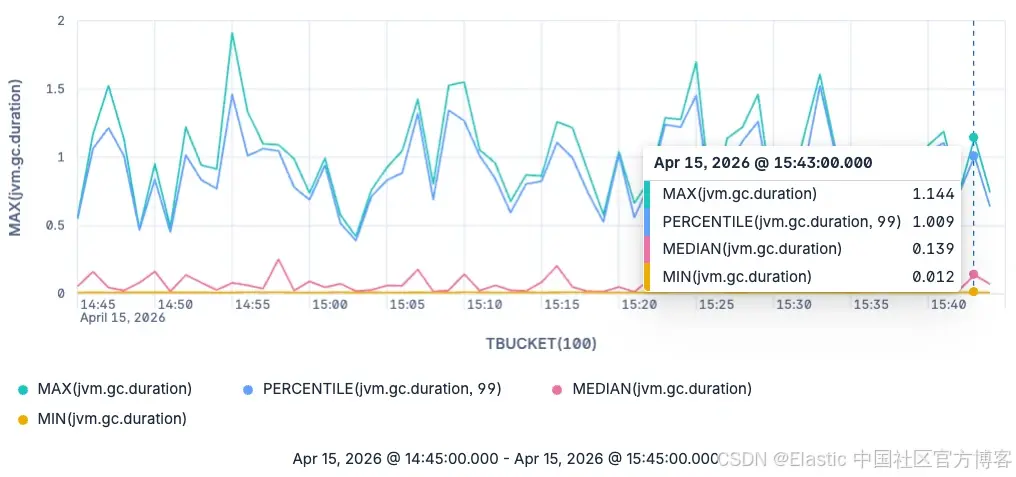
现在这张图展示了 major garbage collections 的最小值、最大值、中位数以及第 99 百分位数。注意,我们并不局限于只查询 median 和 99th percentile。任何你想看的 percentile 都可以查询,因为这些指标是在查询时从原始 exponential histograms 中估算出来的。
关于向后兼容性
到目前为止,我们已经展示了如何在 Elasticsearch 和 ES|QL 中使用这个 "新玩具" ------ exponential histograms。然而,由于它刚刚在 9.4 版本中达到 GA(正式发布),那历史数据怎么办?
在 exponential histograms 引入之前,Elasticsearch 已经能够通过 histogram 字段类型存储 OpenTelemetry histograms。实现方式是将其转换为 histogram 字段类型所支持的另一种数据结构:T-Digest。T-Digest 在极端百分位(例如 99th percentile)上具有较好的精度,但在分布中间区域(例如 median)精度较差。相比之下,exponential histograms 为所有百分位提供了相对误差的上界保证。由于任何转换都会引入误差,我们很高兴现在拥有了原生的 exponential histograms 支持,从而可以端到端采集和分析指标,而无需不必要的转换。
但问题是,如果你已经有历史数据并且仍然想查询它,该怎么办?借助 ES|QL union types,这其实很简单:你只需要在查询中的 histogram 指标后面加上 ::exponential_histogram 后缀即可:
TS metrics-* | STATS AVG(jvm.gc.duration::exponential_histogram)当该查询遇到 histogram 字段时,它会尝试将其转换为 exponential histograms。当操作对象本身已经是 exponential_histogram 字段时,::exponential_histogram 强制转换不会产生任何影响。需要注意的是,这在混合数据集场景下同样适用:如果你的底层索引同时包含两种类型,查询会自动处理并给出正确结果。
因此,如果你正在构建可能运行在 pre-9.4 版本数据上的查询或仪表板,我们建议你直接添加 ::exponential_histogram 转换。
总结
Elasticsearch 对 OpenTelemetry exponential histograms 的原生支持,让你在 ES|QL 中获得更高的指标保真度以及更灵活的分析能力。在这篇博客中,我们展示了如何使用 ES|QL 通过多种聚合方式轻松接入并分析直方图指标,以及 exponential histograms 带来的影响。
Exponential histograms 已在 Elasticsearch 9.4.0 版本中作为 Basic 级别正式可用。它们将在 Elastic Cloud Serverless 中于 9.4.0 发布后的几周内提供,届时 mOTLP(托管可观测性 OTLP 接入)将切换为使用 Elasticsearch OTLP endpoint。相关更新会在发布后同步到本博客及 Elastic Cloud Serverless 的 release notes。
常见问题(Frequently asked questions)
如何在 Elasticsearch 中查询 OpenTelemetry histogram 指标?
Elasticsearch 9.4 原生支持 OpenTelemetry exponential histograms,并可在 ES|QL 中直接查询。你可以在 Kibana Discover 中使用 AVG、SUM、COUNT、PERCENTILE、MEDIAN、MIN、MAX 等标准聚合函数对 histogram 字段进行分析。只需将 OTel metrics 发送到 Elasticsearch OTLP/HTTP endpoint,即可直接查询。
exponential histograms 和经典 Prometheus 风格 histograms 有什么区别?
经典 Prometheus histogram 需要预先定义固定 bucket,这意味着必须提前知道数据分布。exponential histograms 会根据采集数据动态调整 bucket 边界,从而在无需配置的情况下提供更准确的 percentile 估计,更适合真实变化的工作负载。
为什么 exponential histograms 比 T-Digest 更好?
在 9.4 之前,Elasticsearch 会将 OTel histogram 转换为 T-Digest 存储。T-Digest 在极端百分位(如 p99)表现较好,但在中间百分位(如 median)精度较差。exponential histograms 为所有 percentile 提供相对误差上界保证,并消除了中间转换带来的数据损失,同时 T-Digest 也不支持 cumulative temporality。
升级到 Elasticsearch 9.4 后还能查询历史 histogram 数据吗?
可以。如果历史数据存储在 classic histogram field type 中,只需在 ES|QL 查询中添加 ::exponential_histogram 转换即可与新数据一起查询。ES|QL union types 会自动处理转换,即使跨索引混合数据也适用。
如何将 OpenTelemetry exponential histograms 发送到 Elasticsearch?
配置 OpenTelemetry SDK 或 agent 使用 delta temporality(OTEL_EXPORTER_OTLP_METRICS_TEMPORALITY_PREFERENCE: delta)以及 exponential bucket histograms(OTEL_EXPORTER_OTLP_METRICS_DEFAULT_HISTOGRAM_AGGREGATION: BASE2_EXPONENTIAL_BUCKET_HISTOGRAM)。然后将 OTLP exporter 指向 Elasticsearch OTLP/HTTP endpoint 即可。
Elasticsearch 是否支持 histogram metrics 的 downsampling?
支持。从 Elasticsearch 9.4 开始,exponential_histogram 和 classic histogram 都支持 time series data stream downsampling,从而在降低存储成本的同时保留长期可查询的 percentile 能力。
Elasticsearch 的 histogram 能力与其他可观测平台相比如何?
多数平台要么依赖固定 bucket(牺牲精度),要么在写入时转换为 sketch(丢失原始分布信息)。Elasticsearch 9.4 原生存储 OTel exponential histograms,并允许在 ES|QL 中在查询时计算任意 percentile,无需预定义 bucket 或中间转换,因此在灵活性与精度上更有优势。
原文:https://www.elastic.co/observability-labs/blog/otel-histogram-metrics-esql