级联式 WAM 系列的第八站。第 05 篇 TesserAct 把视频预测升级成了 4D,但它从 4D 场景里抠动作,靠的仍是传统的逐帧逆动力学模型。这一篇 MVISTA-4D 直指这套逐步 IDM 的命门------它本质上是"病态"的------并提出一个两步机制把它整个换掉:先在轨迹层面优化出一个潜变量、再用残差 IDM 精修。顺带,它还把 4D 世界模型从"单面视角"推向了"多视角几何一致"。
MVISTA-4D 在 WAM(World Action Model,世界动作模型,即"先在脑海里预演未来、再据此行动"的一类具身模型)里,属于级联式中的"像素空间 + 学习式动作提取"一支,是 TesserAct 这条 4D 路线的"接棒人"。它的全名是 View-consistent 4D world model with test-time action inference (视角一致的 4D 世界模型,配以测试时动作推断),两个关键词已经道破了它的两大贡献:视角一致 与测试时动作推断。
一、要解决什么问题:逐帧倒推动作,是个"病态问题"
先把级联式 WAM 的标准链路再过一遍:世界模型生成一段未来视频(或 4D 场景)当计划,再用**逆动力学模型(IDM,简单说就是"看前后两帧、倒推出中间该执行什么动作"的网络)**逐帧把动作抠出来。
问题出在"逐帧"这两个字上。传统 IDM 是**逐步(step-by-step)**工作的:拿相邻的两帧,独立地推一个动作;再拿下两帧,再推一个......每一步都把这一对帧当成孤立的小问题来解。
这套做法有个根本性的毛病------它是病态的(ill-posed) 。什么意思?打个比方:你看到桌上的杯子从 A 点挪到了 B 点,问中间手是怎么动的?答案根本不唯一------可以直着推过去,可以绕个弯,可以先抬起再放下......同一个"前后状态变化",可以由许许多多不同的动作来解释。尤其在以下两种情况下更糟:
- 部分可观测:相机看不全,遮挡、视角盲区让单帧信息本就不完整;
- 接触阶段:手和物体接触时,细微的力和位姿差异在画面上几乎看不出来,可对应的动作天差地别。
逐步 IDM 还有个软肋:它完全无视轨迹层面的时序结构和任务约束。它不知道"这一步动作要为下一步服务",也不知道"整条轨迹得连贯地完成一个任务",只是孤立地一帧一帧猜。结果就是动作抖动、漂移、累积误差。
MVISTA-4D 的出发点就是:别再逐帧孤立地猜动作了。把"提取动作"从一个个孤立的逆问题,变成一次着眼于整条轨迹的全局求解。
换个角度看这个"病态"问题会更清楚。逐步 IDM 干的活,是在求解一个"逆问题"------已知结果(前后两帧的变化),反推原因(动作)。逆问题在数学上常常是病态的,典型症状有三:解不唯一(多个动作对应同一变化)、解不稳定(输入一点点扰动,输出剧烈变化)、对噪声极其敏感。机器人画面里恰好这三样毛病全占了:遮挡让信息缺失(解不唯一)、生成视频本身带噪(不稳定)、接触瞬间的细微差异被像素淹没(对噪声敏感)。在这种情况下硬让网络逐帧回归,它学到的往往是某种"平均化"的妥协答案,既不精确、又在帧与帧之间缺乏连贯------这正是动作抖动和漂移的根源。MVISTA-4D 的两步机制,本质上就是给这个病态逆问题注入强先验、施加全局约束,把它从"无数解里盲猜"变成"在合理范围内精调"。
二、核心思想与直觉:两步走,先全局后局部
MVISTA-4D 有两条主线,我们先各用一句话点透:
- 世界模型这条线 :从单视角 RGBD 输入出发,"脑补"出其余视角、并融合成随时间演化的、多视角几何一致的完整 4D 场景。这是对 TesserAct"单面几何"短板的直接回应。
- 动作提取这条线 (全文最核心的创新):用一个两步机制 彻底取代传统逐步 IDM------第一步在轨迹层面 优化出一个潜变量,让世界模型据此"重演"出的未来最贴近它先前想象的未来;第二步用一个轻量的残差 IDM 对这个轨迹先验做局部精修。
第二条线的直觉可以这样理解:与其逐帧硬猜(病态、易错),不如先问一个全局问题------"到底是怎样一整条动作轨迹,才能产生我想象出的这整段未来视频?" 把答案先框定在一个合理的轨迹范围内(轨迹先验),再在这个靠谱的基础上做小幅修正(残差)。这就把一个"无数解"的病态难题,收敛成了"在好答案附近微调"的良态问题。
它属于 WAM 级联式的"像素空间 → 学习式动作提取"一类,与前作最关键的区别,正是这个轨迹级优化 + 残差 IDM 的两步动作提取范式。
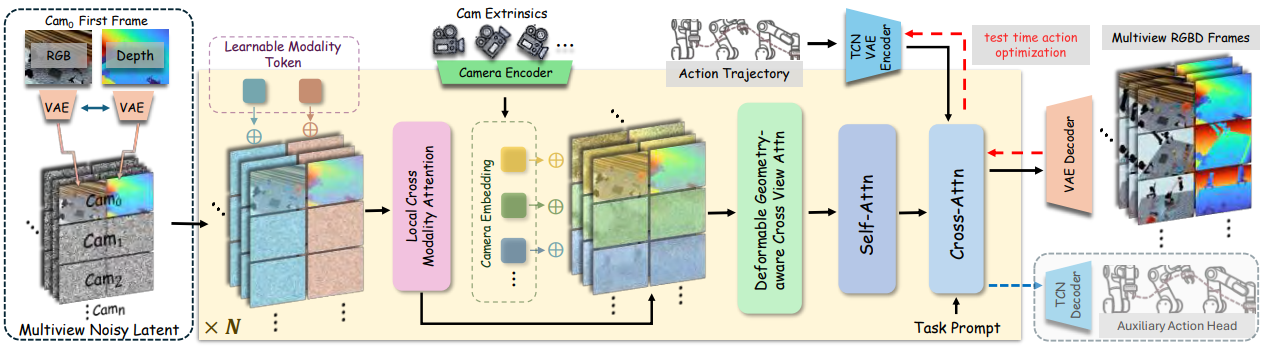
三、方法详解:从单视角到多视角,从轨迹到动作
3.1 世界模型:从单视角"想象"出多视角一致的 4D 场景
底座是 WAN2.2 TI2V(一个约 50 亿参数、基于流匹配的潜在视频扩散模型;"TI2V"即文本+图像到视频)。MVISTA-4D 要让它从单视角 RGBD 输入,生成几何一致的任意视角 RGBD,靠的是两套精心设计的注意力融合机制:
结构化的 token 排布:先把 RGB 和深度的潜变量在"宽度方向"拼接(同一视角内 RGB-D 并排),再把不同视角在"高度方向"叠起来------这种排布让模型能灵活处理可变数量的视角。
跨视角一致性------几何感知的可变形注意力 :要让多个视角拼起来不"打架",关键是让不同视角里对应的是同一个三维点。MVISTA-4D 利用已知的相机参数:对某个视角里的每个查询 token,沿其在其他视角里的**对极线(epipolar line,即同一三维点在另一视角中可能出现的那条直线)**采样 K 个候选位置,再用 MLP 预测偏移量做精调,最后只在这一小撮候选上做多头注意力。这样把原本 O(V²) 的暴力匹配压成了 O((V−1)·K),既高效又强制了多视角几何对齐。
跨模态融合------局部跨模态注意力 :让 RGB(外观)和深度(几何)两路特征在做标准自注意力之前先交换信息。它用可学习的"模态 token"区分两路,在邻域窗口内做对称注意力 (几何→外观、外观→几何双向),并用带可学习门控(γapp\gamma_{app}γapp、γgeo\gamma_{geo}γgeo)的残差更新------门控的作用是抑制噪声传递,只让有用的跨模态信息流过去。
3.2 动作提取第一步:轨迹级潜在优化
这是 MVISTA-4D 的灵魂。先看它怎么把动作"压缩":用一个预训练好的 TCN-VAE (时序卷积网络变分自编码器,把一整条动作序列编码进一个紧凑潜空间的模型),把整条动作轨迹编码成一个低维潜变量 z∈RS×32\mathbf{z} \in \mathbb{R}^{S \times 32}z∈RS×32。
测试时,世界模型已经"想象"出了一段未来 4D 场景 Vˉ\bar{V}Vˉ(此时它被冻结)。MVISTA-4D 求解这样一个优化问题:
z∗=argminz D(G(l,z),Vˉ)+λ∥z∥22\mathbf{z}^* = \arg\min_{\mathbf{z}} \; D\big(G(l, \mathbf{z}), \bar{V}\big) + \lambda \|\mathbf{z}\|_2^2z∗=argzminD(G(l,z),Vˉ)+λ∥z∥22
翻译成大白话:去找一个动作潜变量 z\mathbf{z}z,使得"以它为条件,让生成器 GGG(在指令 lll 下)重新生成出的未来"与"先前想象的那段未来 Vˉ\bar{V}Vˉ"尽可能接近 (后一项是防止 z\mathbf{z}z 过大的正则)。这个优化通过反向传播穿过冻结的生成器 迭代约 100 步完成。找到 z∗\mathbf{z}^*z∗ 后,再用 TCN 解码器把它还原成一条可执行的动作轨迹。
为什么这能破解"病态"?因为它不再逐帧孤立地问"这两帧之间是什么动作",而是整体地问"是哪一整条轨迹,能复现我想象的整段未来"。轨迹被当成一个连贯的整体在一个紧凑的潜空间里求解,时序结构和任务约束自然被纳入考量,多解的歧义被大大压缩。
一个训练上的小设计值得一提:动作潜变量的 dropout 概率从 0 渐增到 0.5------这让模型既能在"只有文本、没有动作"时也能生成视频,又保留了"以动作为条件"的能力,两种模式兼得。
3.3 动作提取第二步:残差 IDM 精修
轨迹级优化给出的是一个轨迹先验 ------方向对、大体靠谱,但未必精确到能直接执行。第二步用一个轻量的、基于 PointNet 的残差 IDM 来"打补丁":
- 输入:相邻帧的点云对,外加上一步解码出的轨迹先验;
- 输出:对每一步动作的修正量 Δat\Delta \mathbf{a}_tΔat;
- 训练:用 ℓ2\ell_2ℓ2 损失监督残差 Δat∗=at∗−atprior\Delta \mathbf{a}_t^* = \mathbf{a}_t^* - \mathbf{a}_t^{prior}Δat∗=at∗−atprior。
关键在于,它只负责"执行层面的对齐",而不必从零重建整个动作。因为有了轨迹先验当锚点,残差 IDM 要做的只是在这个好答案附近做小修小补------这就是论文说的"把预测锚定在合理的轨迹先验周围,从而降低不适定性"。一个原本病态的回归问题,被这个先验"驯化"成了良态的微调问题。
核心公式与逻辑梳理
把 MVISTA-4D 的整套方法压成一条逻辑链:单视角 RGBD + 指令 → 跨模态门控注意力让外观与几何互通 → 跨视角可变形注意力(沿对极线采样)补全多视角一致的 4D 场景 → 流匹配损失训练世界模型 → 把整条动作轨迹编码进 TCN-VAE 潜空间 → 测试时反向传播穿过冻结生成器、优化轨迹潜变量 → 残差 IDM 在轨迹先验上做局部精修。下面拆开几个核心式子。
(1) 流匹配训练目标。 这是世界模型的扩散主干所学的目标:
Ldiff=Et, z0, ϵ ∥ vΘ(zt, t)−(ϵ−z0) ∥22 ,zt=(1−t)z0+tϵ\mathcal{L}{\text{diff}} = \mathbb{E}{t,\,\mathbf{z}_0,\,\boldsymbol{\epsilon}}\Big\\,\\big\\\|\\,v_\\Theta(\\mathbf{z}_t,\\,t) - (\\boldsymbol{\\epsilon}-\\mathbf{z}_0)\\,\\big\\\|_2\^2\\,\\Big,\quad \mathbf{z}_t = (1-t)\mathbf{z}_0 + t\boldsymbol{\epsilon}Ldiff=Et,z0,ϵ vΘ(zt,t)−(ϵ−z0) 22,zt=(1−t)z0+tϵ
符号说明 :z0\mathbf{z}_0z0 是真实视频潜变量;ϵ∼N(0,I)\boldsymbol{\epsilon}\sim\mathcal{N}(0,\mathbf{I})ϵ∼N(0,I) 是噪声;t∈0,1t\in0,1t∈0,1 是流匹配时间步;zt\mathbf{z}tzt 是两者沿直线插值得到的中间点;vΘv\ThetavΘ 是参数化的速度场;ϵ−z0\boldsymbol{\epsilon}-\mathbf{z}_0ϵ−z0 是从数据点指向噪声端的"参考速度"。这条式子在做什么:和 Vidar 一脉相承,让模型学到一条平直的"噪声到数据"流形路径,无论站在路径上的哪一点都能稳定预测前进方向。底座 WAN2.2 TI2V 就是用这套损失继续训练的。
(2) 跨模态门控融合。 让外观(RGB)和几何(深度)特征互相补充:
x^iapp=x~iapp+γapp⋅yia←g,x^igeo=x~igeo+γgeo⋅yig←a\hat{\mathbf{x}}_i^{\text{app}} = \tilde{\mathbf{x}}i^{\text{app}} + \gamma{\text{app}}\cdot y_i^{a\leftarrow g},\qquad \hat{\mathbf{x}}_i^{\text{geo}} = \tilde{\mathbf{x}}i^{\text{geo}} + \gamma{\text{geo}}\cdot y_i^{g\leftarrow a}x^iapp=x~iapp+γapp⋅yia←g,x^igeo=x~igeo+γgeo⋅yig←a
其中 yia←g=Attn(x~iappWQapp, X~Nr(i)geoWKgeo, X~Nr(i)geoWVgeo)y_i^{a\leftarrow g} = \mathrm{Attn}\big(\tilde{\mathbf{x}}i^{\text{app}}W_Q^{\text{app}},\;\tilde{\mathbf{X}}{\mathcal{N}r(i)}^{\text{geo}}W_K^{\text{geo}},\;\tilde{\mathbf{X}}{\mathcal{N}_r(i)}^{\text{geo}}W_V^{\text{geo}}\big)yia←g=Attn(x~iappWQapp,X~Nr(i)geoWKgeo,X~Nr(i)geoWVgeo)。
符号说明 :x~iapp\tilde{\mathbf{x}}_i^{\text{app}}x~iapp、x~igeo\tilde{\mathbf{x}}i^{\text{geo}}x~igeo 是位置 iii 处的外观与几何特征;Nr(i)\mathcal{N}r(i)Nr(i) 是以 iii 为中心、半径 rrr 的邻域窗口;WQ,WK,WVW_Q,W_K,W_VWQ,WK,WV 是注意力权重;yia←gy_i^{a\leftarrow g}yia←g 是"几何告知外观"方向的注意力输出(反方向同理);γapp\gamma{\text{app}}γapp、γgeo\gamma{\text{geo}}γgeo 是可学习的逐通道门控 。这条式子在做什么 :让外观特征"看一眼"邻域里的几何特征再更新,反之亦然。门控 γ\gammaγ 的妙处在于:当跨模态信号有用时把门开大,当对方噪声大时把门关小------避免无脑融合污染了原本干净的单模态特征。这是把"几何"与"外观"两路信息可控地耦合起来的关键。
(3) 跨视角可变形注意力(对极线约束)。 让多视角拼起来时不"打架":
Δpi,ku=clip (MLPoffqiv, fi,ku,0, si,ku, pmax),pi,ku=pi,ku,0+Δpi,ku\Delta p_{i,k}^{u} = \mathrm{clip}\!\left(\mathrm{MLP}{\text{off}}\bigq_i\^v,\\,f_{i,k}\^{u,0},\\,s_{i,k}\^u\\big,\,p{\max}\right),\qquad p_{i,k}^u = p_{i,k}^{u,0} + \Delta p_{i,k}^uΔpi,ku=clip(MLPoffqiv,fi,ku,0,si,ku,pmax),pi,ku=pi,ku,0+Δpi,ku
符号说明 :qivq_i^vqiv 是视角 vvv 里位置 iii 的查询 token;pi,ku,0p_{i,k}^{u,0}pi,ku,0 是在另一视角 uuu 的对极线 上初始采样的第 kkk 个候选位置(对极线即:同一三维点投影到视角 uuu 时的可能轨迹);fi,ku,0f_{i,k}^{u,0}fi,ku,0 是该位置初始采样的 key 特征;si,kus_{i,k}^usi,ku 是查询和候选的余弦相似度;MLPoff\mathrm{MLP}{\text{off}}MLPoff 预测一个偏移量 Δpi,ku\Delta p{i,k}^uΔpi,ku 做精调;clip(⋅,pmax)\mathrm{clip}(\cdot,p_{\max})clip(⋅,pmax) 把偏移限制在合理范围内。这条式子在做什么 :用相机标定提供的对极几何,把跨视角匹配的搜索范围从"整张图"压成"一条线上的 KKK 个点"------既把 O(V2)O(V^2)O(V2) 的暴力代价降到 O((V−1)⋅K)O((V-1)\cdot K)O((V−1)⋅K),又强制让对应关系符合多视角几何。"可变形"则给注意力一点灵活度(在对极线附近允许小偏移),缓解相机标定误差和遮挡的影响。这是 MVISTA-4D 修补 TesserAct"单面几何"短板的核心机制。
(4) TCN-VAE 与动作潜空间。 把整条动作轨迹压成一个紧凑潜变量:
z=EncTCN(a1:L),a^1:L=DecTCN(z)\mathbf{z} = \mathrm{Enc}{\text{TCN}}(\mathbf{a}{1:L}),\qquad \hat{\mathbf{a}}{1:L} = \mathrm{Dec}{\text{TCN}}(\mathbf{z})z=EncTCN(a1:L),a^1:L=DecTCN(z)
LVAE=Eqϕ(z∣a)∥a−a\^∥22+β KL(qϕ(z∣a) ∥ p(z))\mathcal{L}{\text{VAE}} = \mathbb{E}{q_\phi(\mathbf{z}|\mathbf{a})}\big\\\|\\mathbf{a}-\\hat{\\mathbf{a}}\\\|_2\^2\\big + \beta\,\mathrm{KL}\big(q_\phi(\mathbf{z}|\mathbf{a})\,\|\,p(\mathbf{z})\big)LVAE=Eqϕ(z∣a)∥a−a\^∥22+βKL(qϕ(z∣a)∥p(z))
符号说明 :a1:L\mathbf{a}{1:L}a1:L 是长度为 LLL 的真实动作序列;z∈RS×32\mathbf{z}\in\mathbb{R}^{S\times 32}z∈RS×32 是其潜变量(SSS 个"风格 token",本文 S=32S=32S=32);EncTCN\mathrm{Enc}{\text{TCN}}EncTCN、DecTCN\mathrm{Dec}{\text{TCN}}DecTCN 是时序卷积编码器与解码器;qϕq\phiqϕ 是编码器分布;p(z)p(\mathbf{z})p(z) 是标准高斯先验;β\betaβ 是 KL 权重。这条式子在做什么 :经典 VAE------重建项保证 z\mathbf{z}z 还原得回原轨迹,KL 项把后验拉向标准高斯,保证潜空间紧凑可优化。一整条动作被压成一个低维矢量后,"求一条好动作"就变成"在潜空间里找一个好点"------这是下一步轨迹级优化能成立的前提。
(5) 轨迹级潜在优化(全文灵魂公式)。 测试时不前馈、而是"现求"动作:
z⋆=argminz D(G(l, z), Vˉ)+λ ∥z∥22\mathbf{z}^\star = \arg\min_{\mathbf{z}}\;D\big(G(l,\,\mathbf{z}),\,\bar{V}\big) + \lambda\,\|\mathbf{z}\|_2^2z⋆=argzminD(G(l,z),Vˉ)+λ∥z∥22
符号说明 :Vˉ\bar{V}Vˉ 是世界模型先前"想象"出的一段未来 4D 场景(这一阶段被冻结当作目标);G(l,z)G(l,\mathbf{z})G(l,z) 是以指令 lll 和动作潜变量 z\mathbf{z}z 为条件、由同一个生成器重新生成的视频;D(⋅,⋅)D(\cdot,\cdot)D(⋅,⋅) 是 ℓ2\ell_2ℓ2 距离;λ∥z∥22\lambda\|\mathbf{z}\|_2^2λ∥z∥22 是正则项防止 z\mathbf{z}z 漂得太远;z⋆\mathbf{z}^\starz⋆ 是最优解(迭代约 100 步,通过反向传播穿过冻结生成器)。这条式子在做什么 :把"提取动作"从逐帧的病态逆问题,重新表述为一个全局优化 ------找到一条动作轨迹(以 z\mathbf{z}z 编码),使得"以它为剧本重演一遍未来"和"先前的想象"最接近。直觉上就是问:"到底是怎样一整条动作,才能复现出我脑海里这段未来? "这种"以想象为目标、反推动作"的设定,本身就是对级联式 WAM 中"耦合式动作生成"理念最极致的诠释。把 z⋆\mathbf{z}^\starz⋆ 解码就得到一条轨迹先验 aprior\mathbf{a}^{\text{prior}}aprior。
(6) 残差 IDM 精修。 在轨迹先验上做局部小修:
at=atprior+Δat,Lres=∥Δat−(at⋆−atprior)∥22\mathbf{a}_t = \mathbf{a}_t^{\text{prior}} + \Delta \mathbf{a}t,\qquad \mathcal{L}{\text{res}} = \big\|\Delta\mathbf{a}_t - (\mathbf{a}_t^\star - \mathbf{a}_t^{\text{prior}})\big\|_2^2at=atprior+Δat,Lres= Δat−(at⋆−atprior) 22
符号说明 :atprior\mathbf{a}_t^{\text{prior}}atprior 是上一步解码得到的轨迹先验中第 ttt 步动作;at⋆\mathbf{a}_t^\starat⋆ 是真实示范动作;Δat\Delta\mathbf{a}_tΔat 是残差 IDM(基于 PointNet)从相邻点云对预测出的修正量;监督目标就是真实残差 at⋆−atprior\mathbf{a}_t^\star - \mathbf{a}_t^{\text{prior}}at⋆−atprior。这条式子在做什么 :把一个原本病态的"从零回归整条动作"问题,驯化成一个良态的"在好答案附近做小修正"问题。直觉上就像写论文先有个初稿(轨迹先验)、再做精修(残差),而不是空白页上一笔成文。消融实验里去掉这一步 RLBench 成功率从 72.6% 跌到 69.0%,说明这一层精修虽小却扛事------它把"全局好但执行层面略糙"的轨迹先验,对齐到机器人具身可执行的精度上。
四、实验怎么做·结果说明了什么
4.1 数据与基准
- RLBench:8000+ 条轨迹、10 个任务;
- RoboTwin2:10000+ 条轨迹、10 个任务;
- 真机:AgileX Piper 机械臂 + 4 个 Orbbec 相机,14 个操作任务。
训练上用随机掩码让模型见识不同的信息密度,扩散主干以 10−510^{-5}10−5 学习率、AdamW、1000 步预热来训。
4.2 4D 生成质量:多视角融合带来更准的几何
在 RoboTwin 上与 TesserAct 比,世界模型本身的质量就更高:
| 指标 | MVISTA-4D | TesserAct |
|---|---|---|
| PSNR(越高越好) | 22.91 | 22.65 |
| Chamfer 距离(越低越好) | 6.51 | 7.11 |
| δ₁ 深度精度(越高越好) | 97.4% | 97.3% |
几何质量的领先(尤其 Chamfer 距离)正是"多视角一致性融合"的功劳------想得更立体、更几何自洽。
4.3 操作成功率:全面超越 TesserAct
| 基准 | MVISTA-4D | TesserAct | 模仿学习基线 |
|---|---|---|---|
| RLBench | 72.6% | 67.3% | 60.4%(点云 ACT) |
| RoboTwin | 43.0% | 33.9% | --- |
在真机(AgileX Piper,6 个任务)上,MVISTA-4D 相比 TesserAct 平均提升约 8 个百分点 ,个别任务差距悬殊(例如"开抽屉"56% 对 37%)。这组数字说明:更准的 4D 想象 + 更靠谱的两步动作提取,叠加起来在真实机器人上是实打实的增益。
4.4 消融:每个组件都"扛事"
- 去掉跨视角融合:RoboTwin 成功率从 43.0% 跌到 38.0%;
- 去掉跨模态融合:跌到 42.8%;
- 去掉轨迹级潜在优化(换成普通 Act-Head):RLBench 上 72.5% 对完整版 72.6%------在简单基准上几乎打平;
- 去掉残差 IDM 精修:RLBench 上从 72.6% 跌到 69.0%。
这里有个值得细读的地方:在相对简单的 RLBench 上,轨迹级优化相比普通动作头的优势并不明显(72.5 vs 72.6),但残差 IDM 的贡献清晰可见(+3.6)。两步机制是协同的------轨迹优化给"好答案",残差 IDM 把它"修准"。
4.5 效率与一个实用技巧
三视角生成 + 后处理的耗时约为 RLBench 58 秒、RoboTwin 98 秒。轨迹级优化默认要迭代约 100 步,偏慢;作者的提速招数是用动作头的输出来初始化 z\mathbf{z}z ,把优化步数压到 10--15 步,耗时降到 47 秒 / 84 秒,而且成功率不降反升(RLBench 76.5%、RoboTwin 46.6%)。这说明一个好的初始化,能让轨迹级优化又快又好。
五、亮点与为什么重要
- 直击逐步 IDM 的病态本质 :MVISTA-4D 最大的理论贡献,是把"动作提取"重新表述为一个轨迹级的全局问题,而非逐帧的孤立逆问题。这是对级联式 WAM 中长期被忽视的"动作提取不适定性"的正面回应。
- 轨迹级潜在优化 + 残差 IDM 的两步范式:先全局求一个轨迹先验、再局部残差精修------"先定方向、再修细节"的分而治之,把病态问题驯化成良态问题。这套机制有望被推广到其他级联式 WAM 上。
- 多视角几何一致的 4D 世界模型:用几何感知可变形注意力 + 对极线约束,高效地从单视角想象出多视角一致的场景,正面补上了 TesserAct"单面几何"的短板。
- 测试时动作推断(test-time):动作是在推理时通过优化"现求"出来的,而非纯前馈回归------这给了它一种"针对当前想象的未来量身定制动作"的灵活性。
六、局限与未解
- 测试时优化的开销:轨迹级潜在优化要反向传播穿过冻结的大生成器、迭代上百步,天然偏慢。虽然好初始化能压到 10--15 步,但相比纯前馈 IDM 仍重,离高频实时控制有距离。
- 强依赖世界模型保真度:轨迹级优化的目标是"重现想象的未来",可若那段想象本身就不准,优化得再好也只是忠实地复现了一个错误目标。
- TCN-VAE 动作潜空间的表达力上限:把整条轨迹压进一个紧凑潜变量,可能损失对极精细、长程动作的刻画能力。
- 简单任务上轨迹优化增益有限:消融显示在 RLBench 上轨迹级优化相比普通动作头优势微弱,其价值可能更多体现在更难、更长程、更富接触的任务上------而这类任务的系统验证仍有待加强。
七、在 WAM 谱系中的位置
MVISTA-4D 与 UniPi、TesserAct、Vidar、Gen2Act 同属"级联式 → 像素空间 → 学习式动作提取"一类。它的坐标非常清晰------是 TesserAct(第 05 篇)这条 4D 路线的直接延续与升级:
- TesserAct 解决了"想象要不要立体"(RGB → RGB-DN),但仍是单面视角、且沿用传统逐步 IDM;
- MVISTA-4D 接力回答了两个 TesserAct 遗留的问题:一是"立体的想象要不要多视角一致"(单面 → 多视角融合),二是"从立体想象里抠动作,还能不能更好"(逐步 IDM → 轨迹级优化 + 残差 IDM)。
把这两篇连起来读,正好勾勒出级联式 4D WAM 的一条清晰演进脉络:先让世界模型想得更立体(TesserAct),再让它想得更完整、并让动作提取摆脱逐帧的病态(MVISTA-4D)。 而它"测试时优化动作"的思路,也与 WAM 大图景里那些强调"用世界模型指导甚至验证动作"的方向暗合------动作不是被动地一次性回归出来,而是围绕想象的未来反复求解、精修出来的。
八、参考
- 论文:MVISTA-4D: View-Consistent 4D World Model with Test-Time Action Inference for Robotic Manipulation(Jiaxu Wang, Yicheng Jiang, Tianlun He, Jingkai Sun, Qiang Zhang, Junhao He, Jiahang Cao, Zesen Gan, Mingyuan Sun, Qiming Shao, Xiangyu Yue, 2026)
- arXiv:https://arxiv.org/abs/2602.09878
- 评测:仿真 RLBench、RoboTwin2;真机 AgileX Piper
注:本文为基于该论文公开信息的学习性解读,方法、数据集与基准名称保留英文原名以便检索;具体数字以原论文为准。