需不需要用向量数据库
普通的制造业企业是否需要向量数据库?该用什么向量数据库?
关于什么是向量数据库可以看一下这篇文章:一文搞清楚什么是向量数据库?向量数据库该怎么选?
首先我们来回答一下,普通的制造业企业需要向量数据库吗?
简单来说,以前确实可以不用向量数据库,只用传统的关系数据库,比如:Mysql、Sqlserver就够了,但是现在有了AI,而把AI融入到业务中是将来的必选项,就算你不想上AI,你的老板也会让你上AI,哈哈。
企业一般会选择私有化部署本地大模型,那就绕不开本地知识库RAG,而本地知识库是以向量数据库为底座的,所以,绝大多数制造企业确实需要向量数据库,但无需过度选型重型化方案。
接下来,说说该用什么向量数据库?
在企业常见的工单、配件、设备知识库场景中,核心痛点是文本口语化,大家在系统中录入内容的时候很随意,传统的关键词检索无法适配业务需求,而向量数据库恰好可以低成本解决售后效率低、维修经验无法复用、知识库落地难等核心问题。
我结合智能工单、维修工单、配件匹配和知识库RAG场景,来分析下,普通的制造业企业采用什么向量数据库比较好。
先梳理一下业务场景的数据特征:
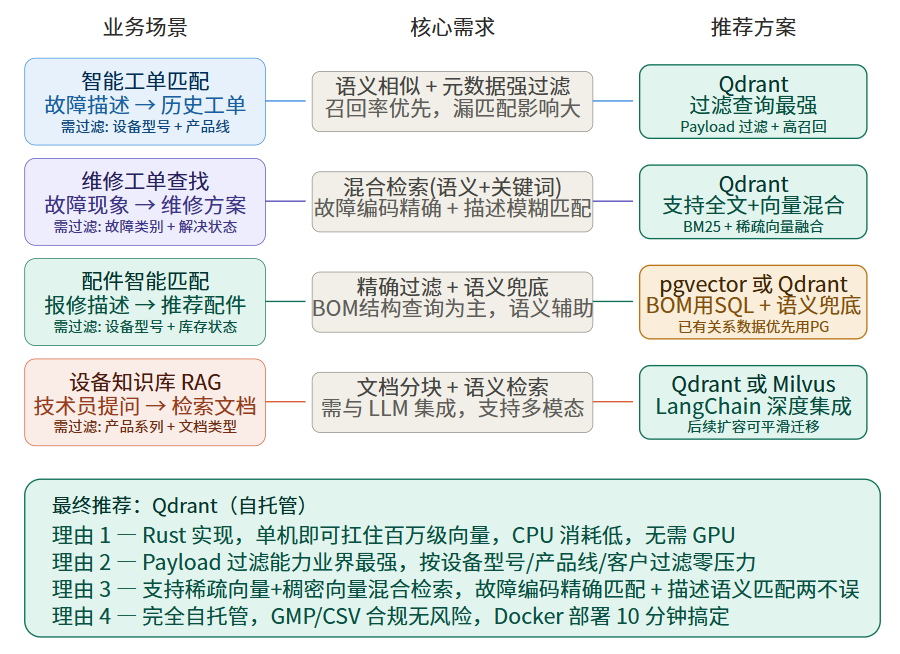
业务场景画像
| 场景 | 数据量级 | 查询频率 | 数据特征 |
|---|---|---|---|
| 智能工单匹配 | 10 万 - 100 万条工单 | 中等(每日数百次) | 故障描述文本 + 设备型号元数据 |
| 维修工单相似查找 | 10 万 - 100 万条 | 中等 | 维修记录、故障原因、解决方案 |
| 配件匹配 | 1 万 - 10 万种配件 | 高(每次报修都触发) | 配件名称、型号、适用设备、BOM 关系 |
| 设备知识库 RAG | 数万篇文档 | 中等 | 产品手册、维修指南、GMP 合规文档 |
关键特征:
- 数据量级整体在百万以下,属于中小规模
- 需要配合元数据过滤(按设备型号、产品线、客户等过滤)
- 查询量不大但要求准确率高(工单配错配件影响售后效率)
- 已有业务数据库(大概率是 MySQL/PostgreSQL)
- GMP/CSV 合规要求 → 数据不能上第三方云,倾向自托管
下面用一张场景-产品适配图来展示:
各场景逐一分析
场景一:智能工单匹配
业务逻辑:客户报修说"灌装机第3工位漏液",系统需要从历史工单中找到最相似的案例,推荐处理方案。
为什么不是传统搜索:
- "漏液" 和 "渗液" 和 "滴漏" 含义一样,关键词搜不全
- "第3工位" 可能被描述为 "三号工位"、"工位三"
- 不同售后工程师的描述习惯差异很大
向量搜索怎么做:
- 报修文本 → Embedding 模型 → 向量
- 在 Qdrant 中搜索 Top-5 相似工单,同时加过滤条件:
设备型号 == "XG-500" AND 产品线 == "灌装线" - 返回历史工单编号、故障原因、解决方案、耗时
场景二:维修工单相似查找
业务逻辑:售后工程师上门前,想参考"别人修过同类故障怎么搞的"。
特殊需求------混合检索:
- 语义部分:故障现象描述的模糊匹配
- 关键词部分:故障编码(如 "ERR-E023")必须精确匹配
- Qdrant 的优势:支持稀疏向量(BM25/SPLADE)+ 稠密向量融合打分,一行请求同时搞定
场景三:配件智能匹配
这个场景比较特殊,我建议用组合方案:
| 查询类型 | 方式 | 工具 |
|---|---|---|
| BOM 结构精确查询 | 设备型号 → 标准配件清单 | 关系数据库 SQL |
| 模糊描述兜底 | "那个密封圈" → 语义匹配配件名 | Qdrant 向量搜索 |
| 库存状态校验 | 匹配到的配件 → 查库存 | 关系数据库 SQL |
配件匹配以 BOM 精确查询为主(确定性高),语义搜索为辅(处理口语化描述)。如果你们的配件库已经 PG 里了,用 pgvector 做语义兜底也能跑,数据量才几万条,完全够用。
场景四:设备知识库 RAG
业务逻辑:技术员在手机上问"XG-500 换膜步骤是什么",系统从产品手册、维修指南、GMP 操作规范中检索相关段落,喂给 LLM 生成回答。
推荐 Qdrant 的理由:
- 与 LangChain / LlamaIndex 集成最好
- 支持文档分块 + 元数据过滤(按产品系列、文档类型过滤)
- 后续如果知识库膨胀到千万级,可以无缝迁移到集群模式
场景选型总结
| 场景 | 首选 | 备选 | 理由 |
|---|---|---|---|
| 智能工单匹配 | Qdrant | pgvector | 过滤+召回强,百万级无压力 |
| 维修工单查找 | Qdrant | Milvus | 混合检索是刚需 |
| 配件匹配 | pgvector | Qdrant | 数据量小,PG 已有表结构 |
| 知识库 RAG | Qdrant | Milvus | 生态集成好,易上手 |
统一用 Qdrant 是最省心的选择------一个数据库覆盖四个场景,Docker 部署,运维成本极低。配件匹配如果已经在 PG 里有完善的 BOM 表,pgvector 做语义兜底也行,两个可以共存不冲突。
对绝大多数普通制造企业而言,统一部署Qdrant是最优解:单容器Docker即可完成生产部署,一般服务器的基础配置即可满足全场景需求,一套架构可同时覆盖工单匹配、维修检索、配件兜底、知识库RAG四大核心场景,架构统一、运维极简、成本还低(低成本老板最喜欢~)。
最后
从选型逻辑来看,一般的制造业企业数据量基本在百万级以内,针对中小规模、内网自托管、低运维等核心需求,Qdrant是适配制造业全场景的最优通用方案,兼顾性能、稳定性、扩展性与低成本;对于已有成熟PostgreSQL架构、仅需少量配件语义兜底的企业,pgvector可作为轻量化零成本备选。而Milvus等重型向量数据库,运维成本高、资源消耗大,普通制造企业无海量数据、高并发场景需求,无需盲目部署,步子迈大了,效果却没提升,就不好收场了。
最后总结一下,整体落地核心原则为:拒绝过度工程化,追求轻量化、简单运维、低成本,还能配合AI赋能落地,首选Qdrant 。