目录
[2. 3 个关键问题 / 特性](#2. 3 个关键问题 / 特性)
[2. 工作流程详解](#2. 工作流程详解)
一、主从复制:基础读写分离架构
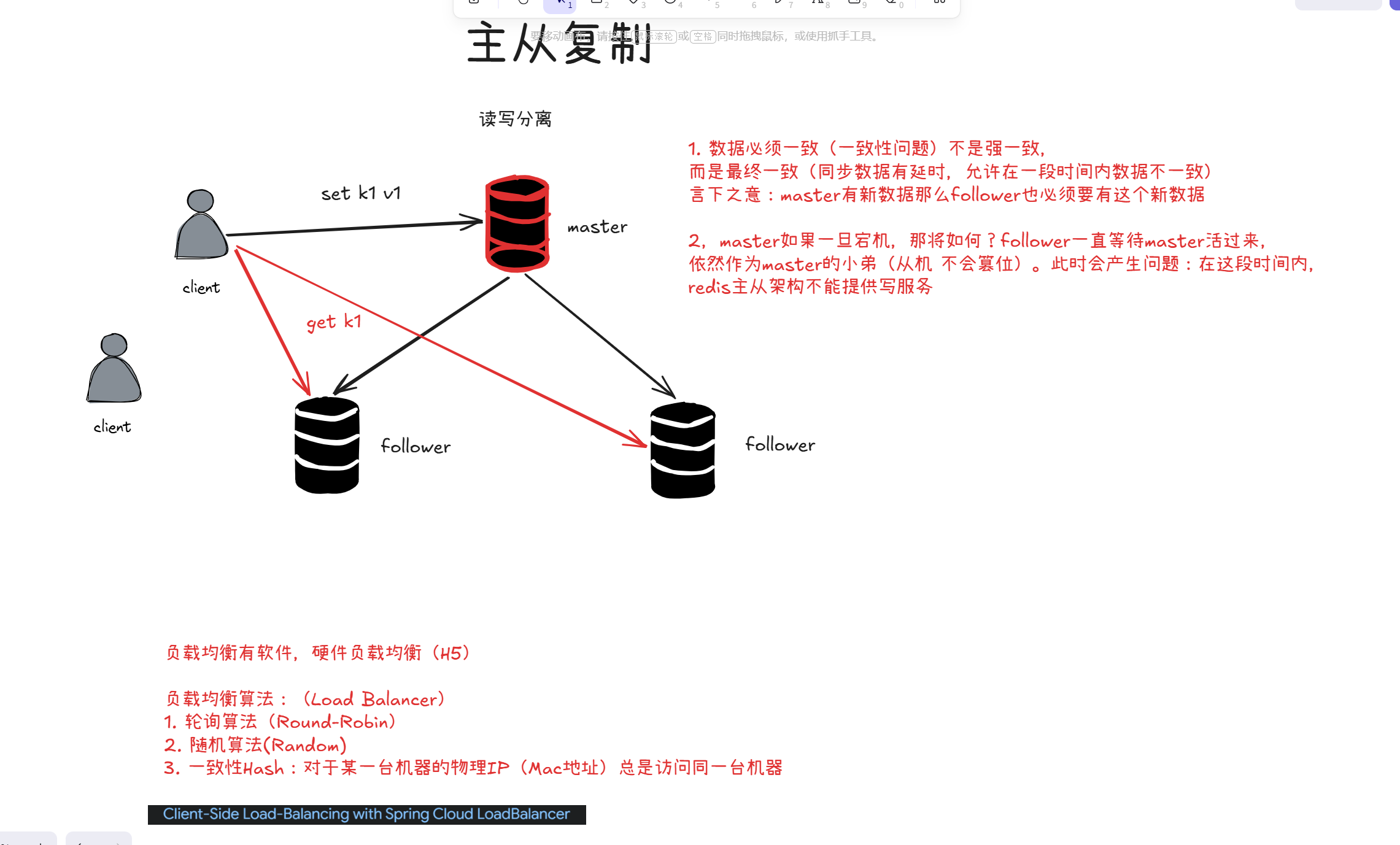
1.核心架构与流程
1.角色分工:
- master(主节点):只负责写操作(set k1 v1),接收客户端的写入请求。
- follower(从节点):只负责读操作(get k1),接收客户端的读取请求。
2.**数据同步:**主节点会把自己的数据异步同步给所有从节点,保证数据的复制。
3.客户端行为: 写请求发给主节点,读请求发给从节点,实现读写分离,分摊主节点的压力。
2. 3 个关键问题 / 特性
(1)数据一致性:最终一致,不是强一致
- 主节点写完数据后,需要把数据同步给从节点,这个过程有网络延迟。
- 这意味着:主节点刚写完的数据,从节点可能暂时读不到(短时间内数据不一致),但最终一定会同步完成,这叫最终一致性。
- 核心逻辑:只要主节点有新数据,所有从节点最终都必须同步到这份数据。
(2)主节点宕机的致命缺陷
- 一旦 master 挂了,整个架构就无法提供写服务了。
- 因为从节点不会主动 "篡位" 当新主节点,只会一直等原来的主节点恢复,这段时间写操作完全不可用,可用性极差。
(3)从节点的负载均衡
为了让多个从节点分摊读请求的压力,需要用负载均衡算法决定请求发给哪个从节点,常见的有:
- 轮询(Round-Robin):按顺序轮流把请求发给每个从节点,简单公平。
- 随机(Random):随机选择一个从节点,实现简单。
- **一致性哈希:**同一个客户端 IP / 请求,始终发给同一个从节点,适合有会话粘性的场景。
二、哨兵模式:解决主从复制的单点故障问题
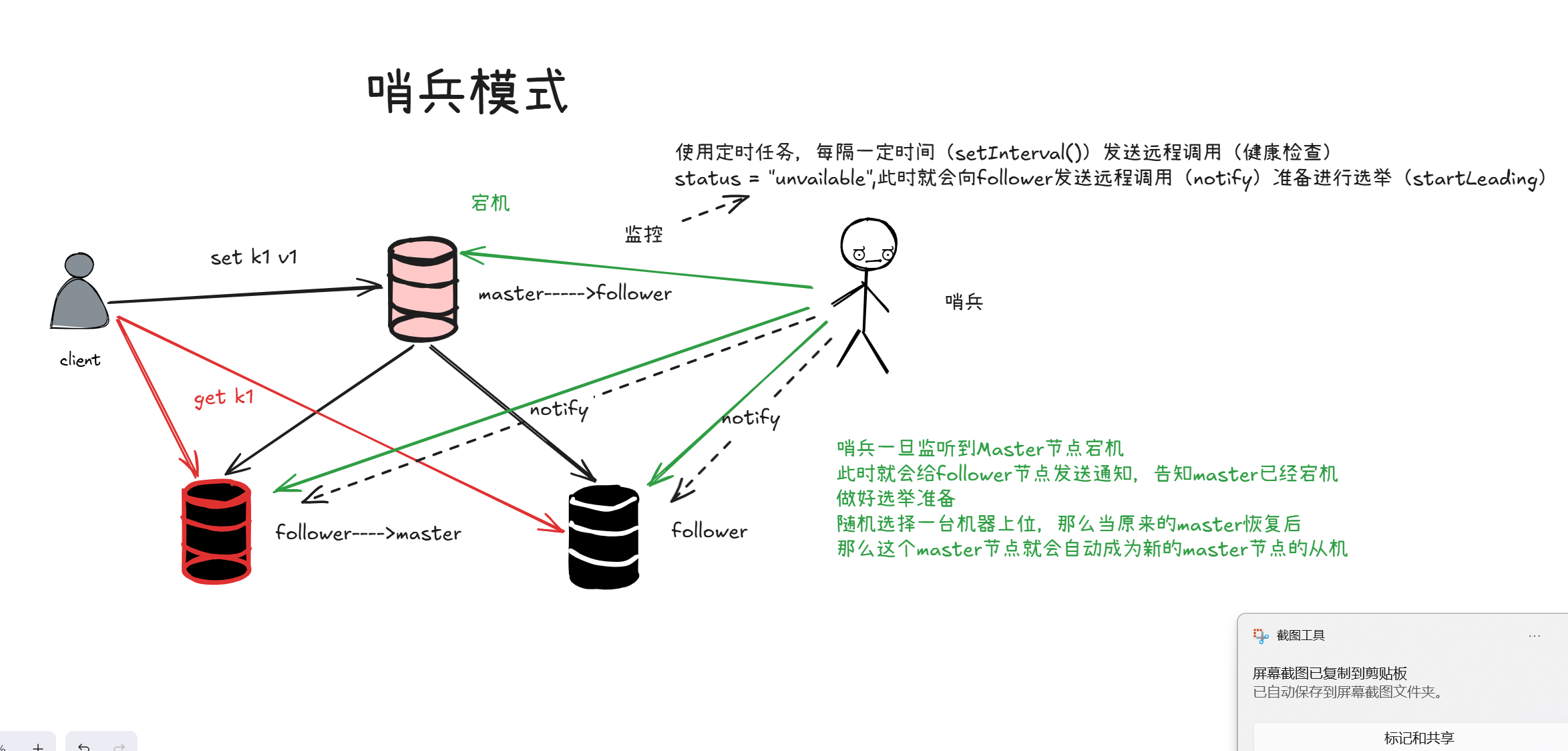
哨兵模式是在主从复制的基础上,加了一层哨兵(Sentinel) 角色,专门解决主节点宕机后无法自动恢复写服务的问题。
1.核心角色
- 原来的 master + follower 主从集群不变。
- 新增 哨兵(Sentinel):一个独立的监控进程,负责健康检查、故障发现、自动选注。
2. 工作流程详解
(1)日常监控阶段
- 哨兵会定时(类似 setInterval)向主节点和从节点发送心跳检测,做健康检查。
- 它会持续监控主节点的状态,同时也会监控从节点的状态,知道所有节点的存活情况。
(2)主节点宕机后的故障转移流程
1.哨兵发现主节点宕机:
当哨兵检测到主节点心跳超时,标记主节点为 unavailable(不可用)。
2.通知从节点准备选举:
哨兵会向所有从节点发送通知(notify),告知主节点已经挂了,让从节点准备参与 "新主节点" 的选举。
3.从节点选举新主节点:
哨兵会根据规则(比如数据最新、优先级最高)从所有从节点中选出一个,升级为新的 master。
4.其他从节点切换主从关系:
剩下的从节点会自动把自己的主节点改成这个新的 master,开始同步新主节点的数据。
5.原主节点恢复后的处理:
原来的主节点恢复后,会自动降级为新主节点的从节点,加入集群继续工作。
(3)客户端的变化
- 客户端还是正常发 set 到主节点、get 到从节点,但不再直接写死主节点的地址。
- 客户端会先向哨兵询问 "当前的主节点是谁",再去连接,这样即使主节点变了,客户端也能自动找到新主节点。
三、两者的核心对比
| 特性 | 主从复制 | 哨兵模式 |
|---|---|---|
| 核心目标 | 读写分离,分摊读压力 | 主从复制 + 自动故障转移,提升可用性 |
| 主节点单点故障 | 无法解决,宕机后写服务完全不可用 | 自动选主,秒级恢复写服务 |
| 一致性模型 | 最终一致 | 最终一致(和主从复制一致) |
| 额外组件 | 无 | 哨兵进程(可多哨兵集群避免单点) |
| 适用场景 | 对可用性要求不高,读多写少的场景 | 对可用性有要求,需要自动故障恢复 |
四、补充:哨兵模式的小细节
- **哨兵本身也可以集群部署:**如果只有一个哨兵,哨兵自己挂了也会导致故障转移无法执行,所以生产环境通常会部署多个哨兵,通过投票来决定主节点是否真的宕机,避免误判。
- **选主规则:**哨兵选主时,会优先选 "数据最新" 的从节点(和原主节点同步延迟最小),其次是配置的优先级,最后是节点 ID。
- **故障转移不是瞬间完成的:**从哨兵发现主节点宕机,到选出新主节点、其他从节点切换主从关系,需要几十毫秒到几秒的时间,这段时间写服务还是不可用的,只是时间比人工恢复短得多。