随着大语言模型、生成式人工智能技术的快速发展,超长文本理解、长对话生成、长文档摘要等场景逐渐成为行业主流。而支撑这些场景的核心网络结构,就是Transformer模型的自注意力机制。自注意力机制具备强大的全局特征捕捉能力,是所有主流大模型的核心基石,但原生自注意力算法存在显存占用过高、运算效率低下的致命问题,严重限制了长序列模型的训练和推理效率。FlashAttention的出现,彻底解决了这一行业痛点,如今已经成为各大主流大模型训练与推理的标配底层技术。本文将从基础原理、硬件瓶颈、核心优化逻辑、前后向传播机制、版本迭代升级等多个维度,全方位通俗解读FlashAttention技术。
一、传统自注意力机制的核心原理
想要读懂FlashAttention的优化价值,首先需要吃透原生自注意力机制的运算逻辑。自注意力机制的核心作用,是让模型能够感知输入序列中每一个字符,也就是Token和所有字符之间的关联关系,精准捕捉文本的全局语义特征。其核心运算公式如下:
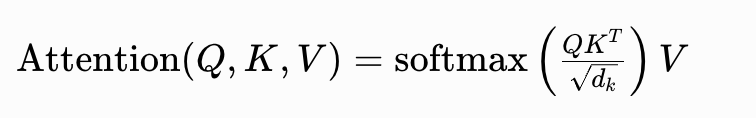
在这个公式中,Q代表查询矩阵,K代表键矩阵,V代表值矩阵,三个矩阵的形状均为序列长度N乘以头部特征维度d_k。简单来说,N指代输入文本的字符数量,d指代模型对单个字符提取的特征维度。整个运算过程可以分为三个基础步骤,也是原生注意力的三段式运算逻辑。
第一步是相似度计算,通过矩阵运算QK的转置,计算出序列中每一个字符和其余所有字符的语义关联程度,生成一个N乘以N的相似度矩阵。第二步是归一化处理,通过Softmax函数将无规律的相似度数值转化为总和为1的概率权重,同时引入√d_k缩放因子,避免数值过大导致运算饱和,保障计算的数值稳定性。第三步是特征加权融合,用归一化后的注意力权重矩阵和V矩阵相乘,加权整合所有字符的语义特征,最终得到自注意力层的输出结果。
从理论逻辑来看,自注意力的运算逻辑简洁高效,但在实际GPU运算落地过程中,却暴露了两大无法规避的致命缺陷,这也是后续FlashAttention优化的核心切入点。
二、传统自注意力的两大致命瓶颈
2.1 平方级显存占用,极易出现显存溢出
显存占用过高是传统自注意力最核心的问题。Q、K、V三个核心矩阵的空间复杂度仅为O(N),显存占用量相对可控。但运算过程中生成的相似度矩阵和归一化权重矩阵,均为N乘以N的方形矩阵,空间复杂度达到了恐怖的O(N²)。这就导致序列长度越长,显存占用就会呈平方级暴涨。
我们可以通过直观的数据对比理解这一问题,假设模型头部特征维度d_k为128,输入序列长度N达到8192的超长文本场景。此时单个Q、K、V矩阵的元素总量仅为1048576个,而中间生成的注意力方阵元素总量高达67108864个,中间矩阵的体量是原始矩阵的64倍。在GPU显存资源有限的情况下,超长序列运算会直接触发显存溢出报错,也就是行业常说的OOM错误,这也是传统模型无法支撑超长文本训练的根本原因。
2.2 内存读写频繁,GPU算力严重浪费
除了显存占用问题,传统自注意力的另一大弊端是忽略了GPU的硬件特性,造成了严重的算力浪费。绝大多数人会默认神经网络运算的瓶颈是浮点计算量,实则不然,GPU运算的真正瓶颈是内存数据的搬运速度,也就是IO读写效率。
GPU拥有两级核心内存架构,第一级是片上高速缓存SRAM,紧贴GPU计算核心,带宽极高、运算延迟极低,数据读取速度极快,但容量非常小,仅有几十KB到几MB,只能存放少量临时数据。第二级是板载显存HBM,容量可达几十GB甚至上百GB,能够存放模型所有参数和完整数据,但读写速度远远滞后于SRAM,数据搬运效率极低。
传统自注意力将完整运算流程拆分为三个独立的CUDA算子,每一步运算都需要重复完成显存读取、核心计算、显存写入的流程。先从HBM读取Q、K矩阵计算相似度,将超大N乘以N矩阵写回HBM,再重新读取该矩阵计算Softmax归一化,再次写回HBM,最后读取权重矩阵和V矩阵完成最终运算。全程需要多次反复搬运巨型矩阵,GPU的计算核心大部分时间都在等待数据加载,算力无法充分利用,整体运算效率极低。
三、传统优化方案的固有缺陷
在FlashAttention问世之前,行业内已经出现了多种自注意力优化方案,但所有方案都存在无法弥补的短板,始终无法实现通用性落地。主流优化方案主要分为两类,分别是近似注意力优化和普通算子融合优化。
近似注意力包含稀疏注意力、线性注意力、局部注意力等多种形式,核心优化思路是舍弃完整的N乘以N注意力矩阵,只计算部分字符之间的关联关系,将运算复杂度从O(N²)降至O(N)。这种方式虽然能够降低显存占用和运算耗时,但属于有损优化,会人为丢失文本全局语义信息,直接导致模型精度下降,无法适用于翻译、精密语义理解等高精度场景。
普通算子融合的优化思路,是将三步独立运算合并为一个算子,减少部分内存读写次数。但这种方案治标不治本,依旧需要在SRAM中存放完整的N乘以N注意力矩阵,受限于SRAM的小容量特性,超长序列场景下依然会出现显存溢出问题,无法从根本上解决痛点。
四、FlashAttention的核心优化原理
FlashAttention是斯坦福团队推出的IO感知型底层优化算子,也是目前唯一能够同时实现高速运算、低显存占用、零精度损失的自注意力优化方案。它的核心设计理念不再聚焦于减少浮点计算量,而是贴合GPU硬件特性,极致优化内存读写效率,通过算子融合、矩阵分块、在线迭代Softmax三大核心技术,彻底解决了传统自注意力的所有痛点。
4.1 算子融合,减少无效内存读写
FlashAttention首先完成的核心优化就是算子融合,将QK转置运算、Softmax归一化、权重矩阵乘V矩阵三步独立运算,融合为单个CUDA算子。传统运算中需要反复写入、读取的N乘以N巨型中间矩阵,在FlashAttention的运算流程中全程驻留于高速SRAM中,无需写入慢速HBM显存。这一优化直接砍掉了绝大部分无效的巨型矩阵读写操作,将整体内存访问次数从8次大幅缩减至2次,极大提升了运算效率。
4.2 矩阵分块,适配GPU硬件容量
单纯的算子融合无法解决SRAM容量不足的问题,无法支撑超长序列运算,因此FlashAttention搭配了矩阵分块的核心策略。它会将完整的Q、K、V大矩阵,均匀切分为多个尺寸较小的矩阵块,所有小块尺寸都严格控制在SRAM可容纳的范围内。
运算过程中,GPU只会逐次将少量小块数据从HBM加载到SRAM,完成单块的全部运算后,丢弃中间数据,再加载下一批小块数据持续运算。全程不会生成和保存完整的N乘以N注意力矩阵,直接将自注意力的显存空间复杂度从O(N²)降至O(N),从根源上杜绝了显存溢出问题,让超长序列模型训练成为可能。
4.3 分块在线Softmax,保障计算精度
矩阵分块运算解决了显存和速度问题,却带来了全新的数学难题。传统Softmax归一化需要依赖单行所有数据的全局最大值和全局指数和,才能完成精准的概率转换。矩阵分块后,单行注意力权重被拆分为多个独立小块,无法直接获取全局统计信息,直接计算会出现数值溢出、计算结果失真的问题。
为了解决这一问题,FlashAttention设计了迭代式在线Softmax算法。算法会初始化每一行的最大值和指数和两个核心统计标量,逐块读取数据完成局部运算,同时动态更新全局最大值和累加和,通过数值偏移修正局部运算结果,最终完成整行的精准归一化计算。这种迭代计算方式,全程仅保存两个标量统计数据,几乎不占用额外显存,同时能够保证最终计算结果和传统全局Softmax完全一致,实现了无损精准计算。
五、FlashAttention版本迭代:V1与V2核心差异
FlashAttention包含V1和V2两个主流版本,两个版本的核心优化逻辑一致,最大的区别在于循环遍历顺序的调整,这一细微优化让V2版本的硬件并行度和读写效率实现了再次跃升,也是目前工业界通用的主流版本。
5.1 FlashAttention V1循环逻辑
V1版本采用外循环遍历K、V矩阵块,内循环遍历Q矩阵块的运算逻辑。固定一组K、V小块后,依次和所有Q小块完成注意力运算,分次累加输出矩阵的结果。这种方式的缺陷十分明显,输出矩阵的每一行结果需要分多次累加更新,每完成一轮运算就必须将中间结果写回HBM显存,下一轮运算需要重新读取,依然存在频繁的显存读写开销,硬件并行调度效率也相对有限。
5.2 FlashAttention V2循环逻辑
V2版本彻底优化了循环顺序,将内外循环对调,采用外循环遍历Q矩阵块,内循环遍历K、V矩阵块的逻辑。固定单个Q小块后,依次遍历所有K、V小块,一次性计算出输出矩阵对应的完整行结果。整行数据在SRAM中完成全部累加运算后,再统一写入HBM显存,彻底消除了输出矩阵的反复读写开销。同时这种循环逻辑更贴合CUDA线程的硬件调度规则,大幅提升了GPU并行计算利用率,相比V1版本速度提升30%以上,长序列场景下的优化效果尤为显著。
六、前向传播与反向传播的完整运行机制
想要完整理解FlashAttention的落地价值,必须结合神经网络的前向传播和反向传播机制。神经网络的完整运行流程分为训练和推理两个阶段,前向传播贯穿全场景,反向传播仅用于模型训练,二者相辅相成,构成了模型学习优化的完整闭环。
6.1 前向传播机制
前向传播是模型的正向运算过程,无论是模型训练还是线上推理,都需要执行这一流程。简单来说,就是输入文本数据,经过模型各层网络的权重运算、激活函数计算,逐层传递特征信息,最终输出模型预测结果的过程,全程不会修改模型的任何参数权重。
在Transformer自注意力层中,前向传播就是完整的注意力运算流程。传统前向传播依赖三段式独立算子,存在严重的IO浪费,而FlashAttention的前向传播通过分块、融合、迭代计算,在高速SRAM中完成全部运算,在不改变计算结果的前提下,实现了高速、低显存消耗的正向运算。日常使用大模型对话、生成文本、翻译等操作,都是单纯执行前向传播的过程。
6.2 反向传播机制
反向传播是模型专属的训练优化流程,推理阶段无需执行,核心作用是修正模型参数,降低预测误差。模型前向传播得出预测结果后,会通过损失函数计算预测值和真实标签之间的误差,随后误差从模型最后一层反向回溯,依靠链式求导法则逐层计算每一层参数的误差梯度,最终通过优化器更新模型权重,让模型的预测结果越来越精准。
传统自注意力前向运算会保存大量中间矩阵,供反向传播计算梯度使用,显存占用极大。而FlashAttention前向运算为了节省显存,丢弃了几乎所有中间数据,为此专门设计了两套反向传播策略。
第一套是重计算策略,也是工业界主流方案。前向运算过程中仅保留少量核心统计量,不保存任何巨型中间矩阵,反向传播需要计算梯度时,重新执行一次前向分块运算,临时生成所需中间数据,完成梯度求解。该策略以极小的额外计算开销,换取了极大的显存节省,是超长序列大模型训练的核心方案。第二套是缓存策略,前向运算缓存小块中间结果和统计数据,反向传播直接读取数据计算梯度,运算速度更快,但显存占用更高,仅适用于短序列、小模型场景。
值得一提的是,FlashAttention的反向传播同样采用分块运算逻辑,不会生成巨型梯度矩阵,全程控制显存占用,完美适配长序列训练场景。
七、FlashAttention的适配能力与性能优势
7.1 全方位场景适配能力
FlashAttention并非单一的运算优化工具,具备极强的场景适配能力,能够兼容Transformer模型的各类核心机制。它原生支持GPT模型的因果掩码机制,能够精准屏蔽未来位置的无效语义信息,适配自回归生成模型。同时兼容各类注意力偏置运算、FP16、BF16等大模型主流低精度浮点运算,在提升速度的同时,保障低精度运算的数值稳定性,杜绝溢出和精度丢失问题。
7.2 核心性能优势
经过大量工程实测,FlashAttention的优化效果十分显著。显存占用相比传统自注意力降低50%至90%,序列越长,优化效果越明显。运算速度方面,短序列场景下速度提升1.2至1.8倍,长序列场景下提速可达2至4倍。最重要的是,FlashAttention属于精确优化算法,计算结果和传统自注意力完全一致,零精度损失,区别于所有有损近似优化方案。
7.3 适用场景与局限性
FlashAttention的最优适用场景集中在大模型训练、超长文本处理、显存资源受限的GPU部署场景,是目前LLaMA、Qwen、GPT等主流大模型的标配底层技术。同时它也存在一定局限性,原生版本主要适配NVIDIA CUDA架构GPU,其他品牌硬件需要单独移植适配。极短序列场景下,分块和循环调度的少量开销会抵消部分提速效果,优化优势不够明显。
八、总结
FlashAttention的成功,本质上是硬件感知优化思维的胜利。它没有颠覆传统自注意力的数学运算逻辑,也没有设计全新的网络结构,而是精准抓住了传统算法忽略硬件特性、过度浪费IO资源的核心痛点。通过算子融合消灭无效读写,通过矩阵分块解决显存爆炸难题,通过迭代Softmax保证计算精度,通过循环顺序迭代压榨GPU硬件性能。
在前向传播和反向传播的全链路优化加持下,FlashAttention彻底打破了大模型长序列训练的显存和速度瓶颈,让超长文本语义理解、超长对话生成等落地场景成为现实。如今这项技术已经深度融入各大AI框架,成为支撑大模型技术迭代和产业落地的核心底层基石,也是人工智能工程化优化的经典案例。