原文Link
0. 名词表
| 名词 | 解释 |
|---|---|
| activation vector | 对某个具体输入 x x x, 神经网络这一层输出的向量, 如 h ( x ) = h 1 ( x ) , h 2 ( x ) , ... , h d ( x ) h(x)=h_1(x),h_2(x),\\dots,h_d(x) h(x)=h1(x),h2(x),...,hd(x) |
| representation | the vector space of a neural network layer's activations (activation vectors所在的向量空间, 即 h ( x ) ∈ representation space h(x)\in\text{representation space} h(x)∈representation space) |
| neurons | the dimensions of a representation with a privileged basis (其激活值是representation space上一个维度/坐标轴上的坐标值, h 1 h_1 h1对应neuron 1, h 2 h_2 h2对应neuron 2, ...) |
| features | independently understandable components of representation (representation space里有意义的方向, 可能和某个neuron对齐, 也可能是多个neurons的线性组合); 亦指一个可理解的概念/属性, 如"猫"、"狗" |
1. intro
replace the activation function with a softmax linear unit (SoLU) and show that this significantly increases the fraction of neurons in the MLP layers which appear to be "interpretable". But there is no free lunch, SoLU may be making some features more interpretable by "hiding" others and thus making them even more deeply uninterpretable. 真聪明!
3. background
if we want to understand transformers with MLP layers, it appears we must figure out how to understand what the activations of MLP layers encode.
The vector space of a neural network layer's activations is called the "representation", 这里的activations指的是MLP的输出, 而非激活函数。
对于低维的神经网络, 有可能可以直接可视化这样的空间, 但维度的增加带来维度的诅咒, 其空间的体积指数级递增。
因此, 想理解这样的"representation", 只能将其分解成independently understandable components, 称为features。
许多神经网络有representations with a privileged basis, 让默认的神经元坐标轴不再是任意的 (做rotate变换后不同)。比如接入ReLU这个非线性激活函数, 这会破坏旋转坐标系的对称性, 使这个specific basis成为unique basis的(where nonlinearity is applied)。This doesn't guarantee that features will align with the basis, but it makes it plausible.
我们将the dimensions of a representation with a privileged basis称为"neurons"。
有些neurons确实对应interpretable features, 这些features对决定哪些类型的interpretability research有效很重要。
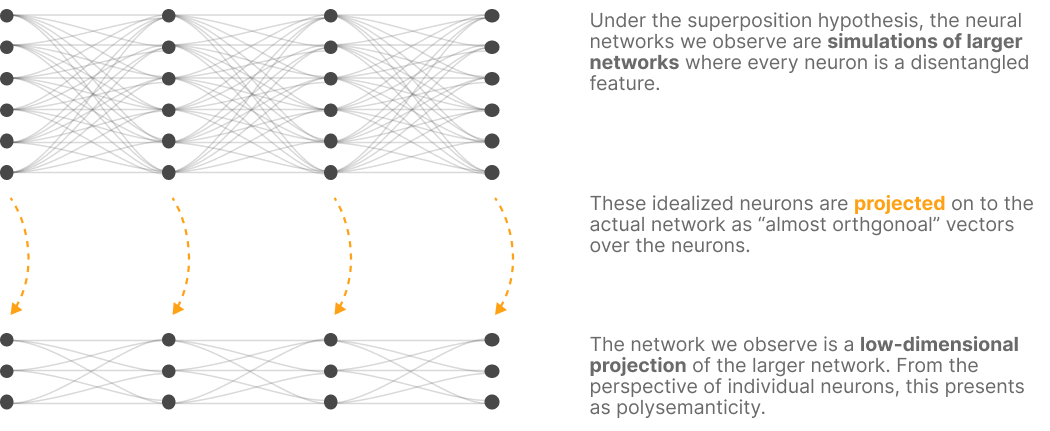
然也有许多neurons对应数个unrelated but individually understandable features, 我们称之为polysemantic neurons (polysemantic表示多个features被压缩后对应一个privileged basis, superposition hypothesis)。
3.4 The Superposition Hypothesis
如果superposition hypothesis是成立的, 那么寻找interpretable basis从框架上看是错误的。尽管重要的features可能有专用的neurons, 多数features和neurons并没有对齐。
intuitions about neural networks and features:
(1) feature表示为activation space里的方向。
(2) features的数量比neurons多得多。
(3) the most efficient way to encode many facts in parameters may not align with neurons, 即不一定要1个神经元对应1个feature
(4) features are sparse, 每次输入只会激活很少一部分feature。
(5) Almost Orthogonal Vectors: 虽然n维空间最多只能有n个orthogonal vectors, 但在高维空间里可以有很多"almost orthogonal" vectors (cosine similarity <ε)。神经网络可以在有限维空间里塞进很多差不多"almost orthogonal"的feature方向。
(6) Compressed sensing: 如果原始输入向量是稀疏的, 则将其投影到低维空间后, 有可能恢复到原始向量。
如果模型能表示更多features, 它的loss可能更低。能表示成正交方向的features的数量受neurons数的限制, 从'表示更多features'和'feature之间产生干扰'的trade-off来看, 把features表示成almost orthogonal的方向很划算 (且feature很稀疏, 很多features不会同时出现, 干扰不常发生)。
* 为什么我们需要orthogonal、"almost orthogonal"?
假设这一层有3个neuron: h = h 1 , h 2 , h 3 h=h_1,h_2,h_3 h=h1,h2,h3, "猫"这个feature所代表的方向是 v cat = 0.6 , 0.3 , 0.7 v_{\text{cat}}=0.6,0.3,0.7 vcat=0.6,0.3,0.7
下一层某个neuron的计算为 w ⋅ h + b w\cdot h+b w⋅h+b, 如果这个neuron想检测"猫"这个feature, 它的权重 w w w可能就会对齐到 v cat v_{\text{cat}} vcat ( w ≈ v cat w\approx v_{\text{cat}} w≈vcat)。如果 h ( x ) = h 1 ( x ) , h 2 ( x ) , h 3 ( x ) = a 1 v cat + a 2 v 2 + a 3 v 3 + ⋯ h(x)=h_1(x),h_2(x),h_3(x)=a_1v_{\text{cat}}+a_2v_2+a_3v_3+\cdots h(x)=h1(x),h2(x),h3(x)=a1vcat+a2v2+a3v3+⋯里的其他feature v 2 , v 3 , ... v_2,v_3,\dots v2,v3,...和 v cat v_{\text{cat}} vcat是orthogonal的, 那么 h ⋅ w h\cdot w h⋅w后就只保存有"猫"这个feature的activation a 1 ∥ v cat ∥ 2 + b = a 1 + b a_1\lVert v_{\text{cat}}\rVert^2+b=a_1+b a1∥vcat∥2+b=a1+b。
也就是说, 需要orthogonal是为了下一层在读某个feature的时候不被其他feature污染。
如果我们确信superposition hypothesis, what should we do if we want to understand models?
(1) Create models with less superposition, 这是SoLU的选择
(2) Find a way to understand representations with superposition
4. SoLU: Designing for Interpretability
how can we create a neural network architecture which will encourage features to align with neurons, and discourage polysemanticity?
4.1 Properties that May Reduce Polysemanticity
(1) Activation Sparsity
一个polysemantic的neuron激活的时候,需要其他neurons一起激活来消除歧义。feature是稀疏的, 但根据superposition, feature被叠加到neurons空间里 (almost orthogonal), 可能需要比出现的feature数量更多的neurons一起激活来表示和消歧。
\^: superposition requires a gap between the sparsity of the underlying features and the sparsity of the neurons representing them.
那么, 如果能把neuron激活也变得稀疏, 这个gap变小, superposition就更难, polysemantic也可能减少。
(2) Lateral Inhibition / Co-Occurrence Sparsity
设计像softmax这样 (1个neuron活动会导致其他活动neurons的数量减少, neurons间形成竞争关系) 的激活函数是有可能的。要仔细设计lateral inhibition的机制, 确保真的产生少数neurons"赢"的稀疏结构, 而不是所有neurons互相压制, 最后都只有small activations。
(3) Weight Sparsity
如果两个feature在一个神经网络的相邻层, 自然地认为它们之间存在一些"ideal weight" (feature A出现时应多大程度激活feature B?)。如果feature和神经元对齐, 那么feature之间的关系可以由少数几个权重表达, 权重矩阵稀疏;如果feature是polysemantic的, 那么关系会分散到很多小权重上。因此鼓励权重稀疏可能减少polysemantic。但这个方法只有在输入输出坐标轴都是privileged basis才make sense, 而transformer的residual stream通常不是这种privileged basis, 所以标准transformer里不太适合直接用权重稀疏来解决多义性。
(4) Superlinear Activation Functions
一个superlinear激活函数是指输入越大, 输出增长越快且快于线性增长的激活函数, 如 ReLU ( x ) 2 \text{ReLU}(x)^2 ReLU(x)2, softmax ( x ) ∗ x \text{softmax}(x)*x softmax(x)∗x和 exp ( x ) \exp(x) exp(x)。假设一个feature原本集中在一个neuron上: x , 0 , 0 , 0 x,0,0,0 x,0,0,0, 用 f ( x ) = x 2 f(x)=x^2 f(x)=x2, 输出强度是 f ( x ) = x 2 f(x)=x^2 f(x)=x2; 将其分散到 N N N个neurons上, 为了保持整体向量长度不变, 每个neuron只能分到大概 x N \frac{x}{\sqrt{N}} N x, f ( x N ) = x N 2 f(\frac{x}{\sqrt{N}})=\frac{x}{N^2} f(N x)=N2x, 经过激活函数后的向量长度是不分散的 1 N \frac{1}{\sqrt{N}} N 1, 也就是说, 分散后的feature强度小于集中的。如果想要保持原有的强度, 需要更大的activations或更大的输出权重, 使得分散的feature更难与集中的feature共存。这也会惩罚共用一个neuron的两个feature同时出现的情况, 因为 f ( a + b ) > f ( a ) + f ( b ) f(a+b)>f(a)+f(b) f(a+b)>f(a)+f(b), 产生额外的干扰项。
(5) Change Neurons per FLOP / param
根据superposition hypothesis, polysemanticity是因为neurons的数量不足以直接表达所有features, naive的想法是把模型做大些, 但more capable models may want to represent more features。那增加模型的neurons数量呢, some architectural approaches may allow for this。
4.2 The SoLU Activation Function
现代transformers使用GeLU ≈ sigmoid ( 1.7 x ) ∗ x \approx\text{sigmoid}(1.7x)*x ≈sigmoid(1.7x)∗x作为激活函数。本文提出新的激活函数SoLU: SoLU ( x ) = x ∗ softmax ( x ) \text{SoLU}(x)=x*\text{softmax}(x) SoLU(x)=x∗softmax(x)。
为何SoLU能抑制polysemanticity和superposition?
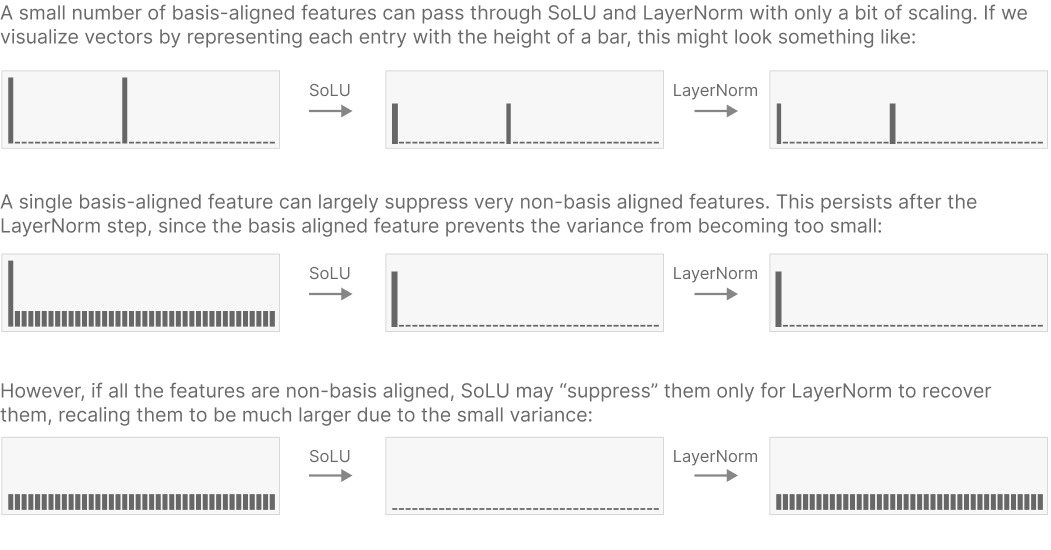
(1) when SoLU is applied to a vector of large and small values, the large values will suppress smaller values
SoLU ( 4 , 1 , 4 , 1 ) ≈ ( 2 , 0 , 2 , 0 ) \text{SoLU}(4,1,4,1)\approx(2,0,2,0) SoLU(4,1,4,1)≈(2,0,2,0)
Lateral Inhibition / Co-Occurrence Sparsity, 引入竞争关系
(2) large basis aligned vectors are preserved, while a feature spread across many dimensions will be suppressed to a smaller magnitude
SoLU ( 4 , 0 , 0 , 0 ) ≈ ( 4 , 0 , 0 , 0 ) \text{SoLU}(4,0,0,0)\approx(4,0,0,0) SoLU(4,0,0,0)≈(4,0,0,0), SoLU ( 1 , 1 , 1 , 1 ) ≈ ( 1 4 , 1 4 , 1 4 , 1 4 ) \text{SoLU}(1,1,1,1)\approx(\frac{1}{4},\frac{1}{4},\frac{1}{4},\frac{1}{4}) SoLU(1,1,1,1)≈(41,41,41,41)
Superlinear Activation Functions, 抑制了feature的分散, 但不足以证明抑制了overlapping features吧?
4.3 LayerNorm
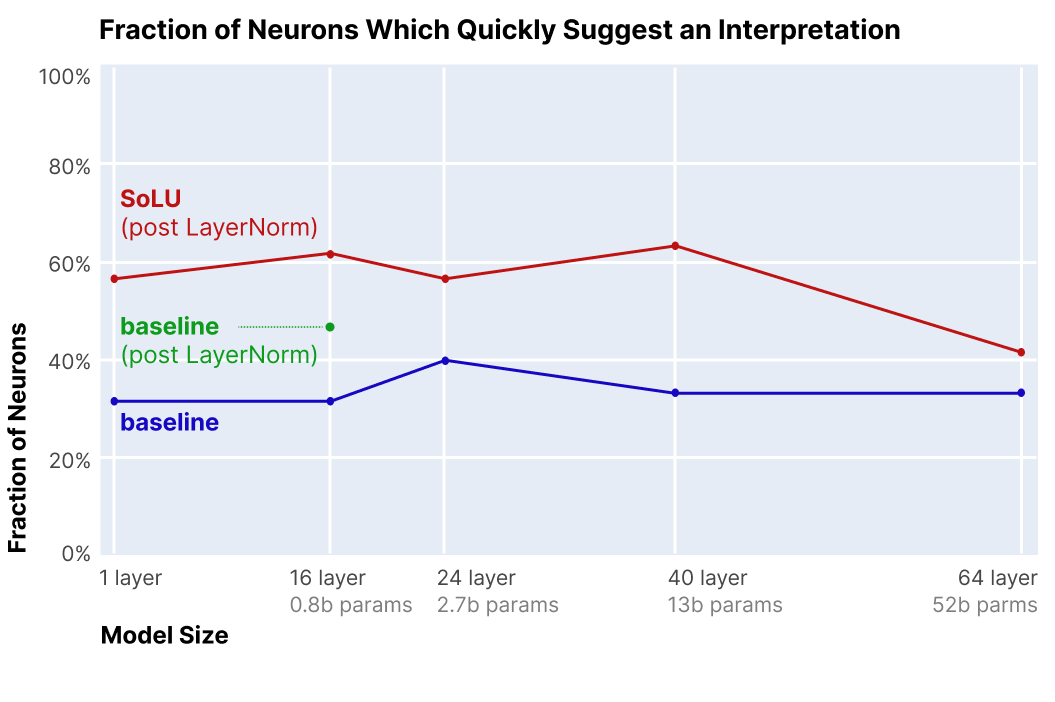
\^: SoLU models without any other changes had performance equivalent to a model 30-50% smaller than their actual size, with larger models being affected more.
这一定程度上可以证明superposition hypothesis是正确的。我们可以减少polysemanticity, 这样做的代价是损害了网络的ML performance。
不过只要在SoLU外面套一层LayerNorm, 这样的performance penalty就可以被修复, 即 f ( x ) = LN ( SoLU ( x ) ) = LN ( x ∗ softmax ( x ) ) f(x)=\text{LN}(\text{SoLU}(x))=\text{LN}(x*\text{softmax}(x)) f(x)=LN(SoLU(x))=LN(x∗softmax(x))。
加入LayerNorm是因为觉得LayerNorm能把SoLU的activations重新标准化到一个比较稳定的尺度 ('fix issues with activation scale and improve optimization')。后来认为performance improved的原因是LayerNorm把被SoLU压小的 (分散的feature的) activations重新放大。即便加了LayerNorm, softmax上的竞争机制依然存在, 有些feature会因为大的activations被推到单个neuron上, 允许在和superposition共存的情况下提高interpretability。
因为LayerNorm, 所以softmax的分母对模型的最终behavior并无影响, 即 LN ( SoLU ( x ) ) = LN ( x exp ( x ) ∑ i exp ( x i ) ) = LN ( x ∗ exp ( x ) ) \text{LN}(\text{SoLU}(x))=\text{LN}(x\frac{\exp(x)}{\sum_i\exp(x_i)})=\text{LN}(x*\exp(x)) LN(SoLU(x))=LN(x∑iexp(xi)exp(x))=LN(x∗exp(x))。
5. Results on Performance
train transformer language models with and without SoLU for a range of different sizes, and evaluate both the loss and the performance on the following downstream NLP tasks: Lambada, ARC, OpenBookQA, TriviaQA, arithmetic, MMLU, and HellaSwag
baseline model uses an architecture similar to GPT-3 and Gopher
train models ranging from 1 layer to 64 layers (approximately 50 billion parameters), 这些模型的参数量是按大约 4 倍的间隔逐步增大的
Our SoLU models have all the same hyperparameters and architectural details as our baselines and differ only in using the SoLU activation function.
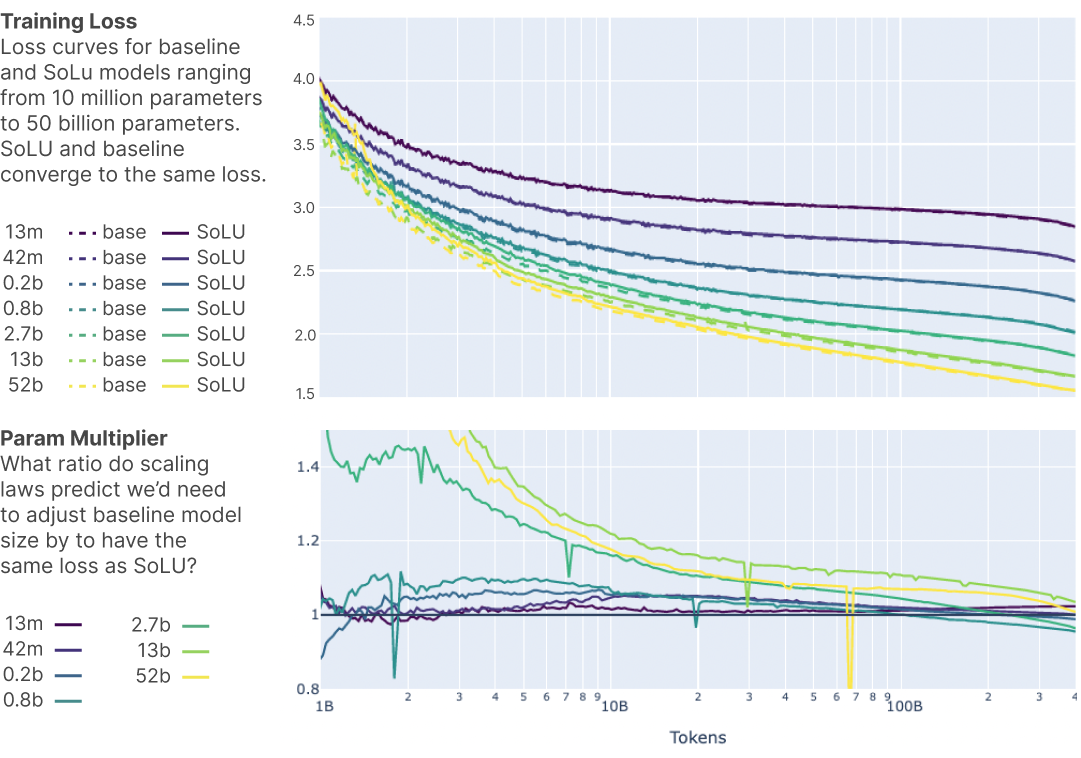
Param Multiplier表示为了达到SoLU模型同样的loss, baseline模型需要把参数量乘以多少倍。大部分曲线后期都接近1, SoLU相比baseline没有明显ML性能损失,也没有明显参数效率提升。
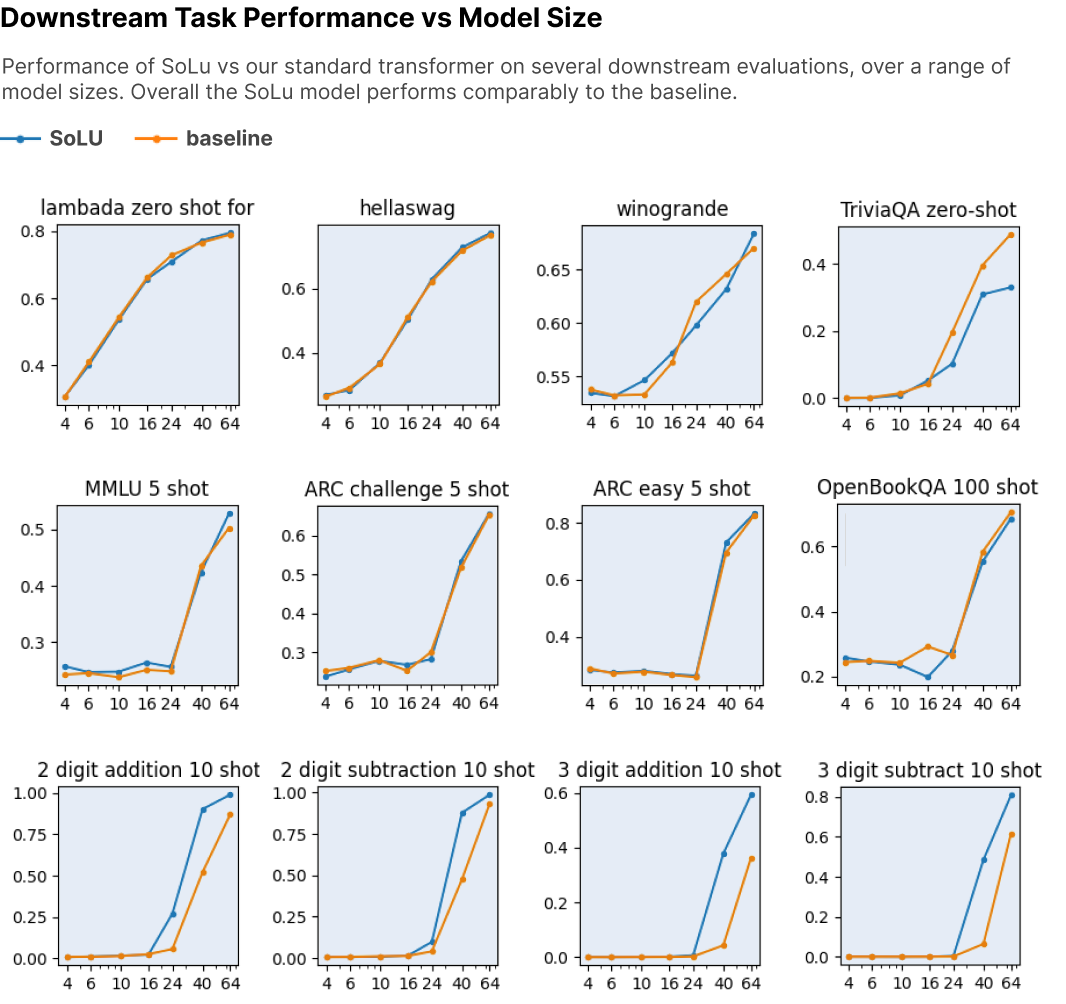
总体来看SoLU和baseline表现差不多
6. Results on Interpretability
使用较为宽松的指标测量neuron是否可解释 (easily interpretable): whether a given neuron suggests a plausible interpretation given a small amount of human attention (人稍微看一下这个neuron的激活例子,能不能比较快地想出一个合理解释)。这样的指标会导致假阳性和假阴性的产生。

红色荧光的深浅和activation的程度正相关。评估者尝试在1-2分钟内解释每个neuron激活的理由。
6.3 Qualitative Exploration of SoLU Models
介绍一些在训练SoLU模型之后发现的interpretable features
(1) One-Layer Model Neurons
暂且不考虑LayerNorm带来的复杂性,每个neuron的activation对最终logits有线性影响 a i W out , i W U a_iW_{\text{out},i}W_U aiWout,iWU。因此把该neuron的输出权重向量乘上unembedding matrix, 就能直接看到该neuron激活时会提高哪些token的logits及提高的程度。

这是一个base64 neuron, 因为它在乱码上激活, 且激活时提高了乱码的logits。
(2) Early Layer Neurons in Larger Models ("de-tokenization")
发现网络中early/middle/late层的neurons起不同的作用。
许多early neurons把tokenizer切出来的碎片token重新组合/映射成更自然的语义单位。比如一个early neuron会在看到token序列前面是'Trend', 后面跟着'ing'的时候激活, 把'Trend'和'ing'这两个token映射成有意义的词'Trending'。

许多early neurons会根据上下文判断某个token属于哪种语言/语境。比如, 发现3个early layer neurons在'die'出现在德语/荷兰语/南非语语境中时激活, 且不对英语语境中的'die'激活。

(3) Late Layer Neurons in Larger Models ("re-tokenization")
late layer neurons把前面形成的完整词重新转换成token序列。
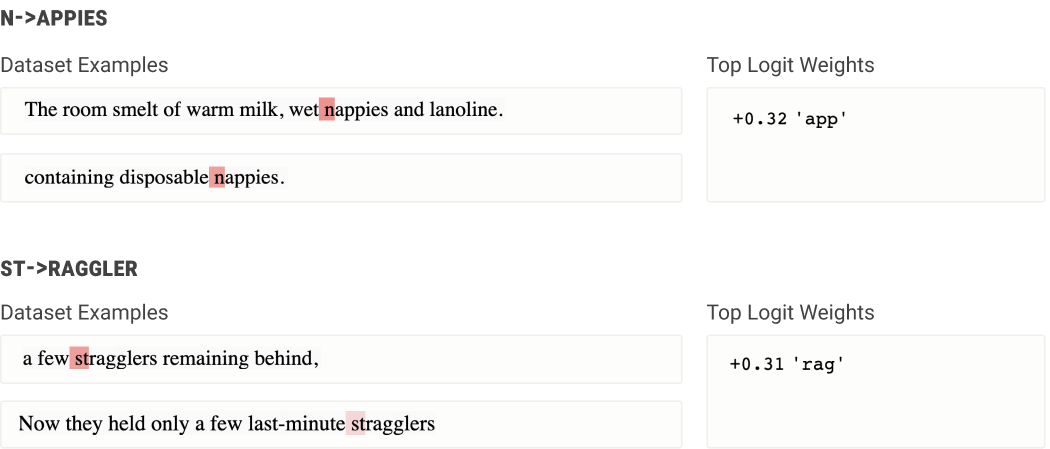
这个neuron在先前tokens满足特定的条件下, 且当前token是'st'时激活, 增加'rag'的logits, 从而把'stragglers'展开成输出词表所需的逐token序列。
(4) Middle Layer Neurons in Larger Models
middle layer neurons表示更加复杂的概念。比如这个neuron只对数字表示人数时激活:

还有其他不同的类型:

总的来说, early neurons把离散的tokens映射为具体的语义, middle neurons处理更抽象的语义, late neurons把具体的语义重新拆成输出所需的tokens。
(5) Abstract Patterns
Neuron Splitting: 小模型里一个neuron承担了一个比较宽泛、混杂的功能; 大模型里这个功能被多个更专门的neurons分担。比如小模型里一个neuron负责十六进制数, 到了大模型中一个neuron可能只负责某个特定的十六进制数字。
Neuron Families: 指一组相似的neurons, 具体的形式是"token X in language Y", 比如前面的'die'。这些neurons可以看成一个家族, 由token X和语言 Y这两个因素决定。研究这种家族可能帮助我们发现语言模型内部更抽象的对称性,比如模型如何在不同语言之间复用相似机制。
Duality Between Early and Late Layers: 对偶性, early layers和late layers在模型的输入端和输出端做了方向相反的事。
Similarities to CLIP Neurons: 发现有些neurons会对名人和地理区域激活。比如multimodal-neurons (Link) 中Person Neurons提到的"Donald Trump Neuron"对川普在各种情境下图片反应强烈, 包括多种艺术媒介呈现的肖像与讽刺画, 对曾与他密切合作的人士也有较弱的反应, 对他的政治符号与口号 (e.g., 边境墙, 'MAGA') 也会产生反应。
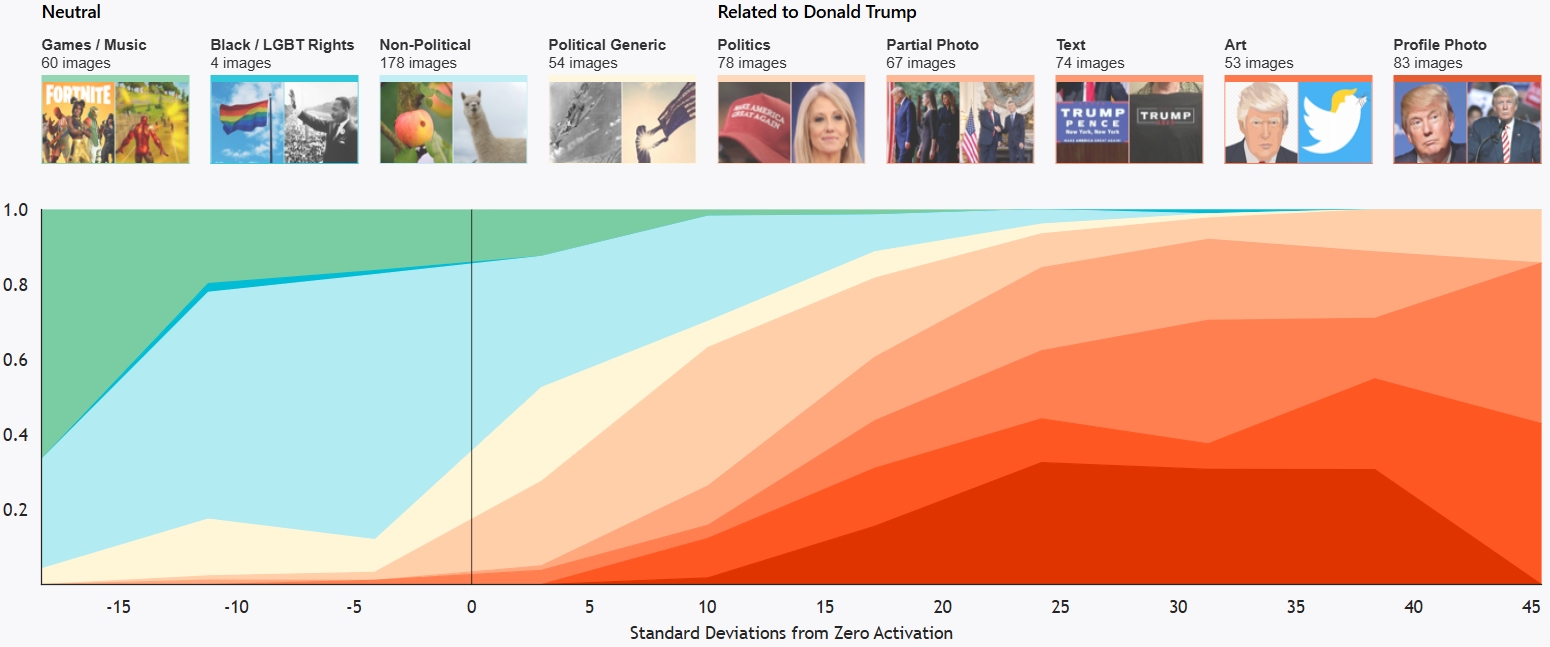
横轴是该neuron的激活强度, 指标是距离0激活多少个标准差, 越往左表示负激活/低激活, 中间0表示普通水平, 越往右表示强正激活。纵轴是在横坐标的激活强度下, 图片属于各类标签的概率 (堆叠图)。可以看出激活强度的越高, 图片属于和川普相关的类型的概率越高。
multimodal-neurons (Link) 中的Region Neurons会对某个地区相关很多不同模态和方面激活, 比如国家和城市的名字, 建筑, 人脸/族群外观特征, 民族服饰, 动物和当地文字等。即使在没有字的世界地图上, 这些neurons也可能根据地图上的形状、相对位置、轮廓等视觉信息, 对相应地区产生选择性激活。
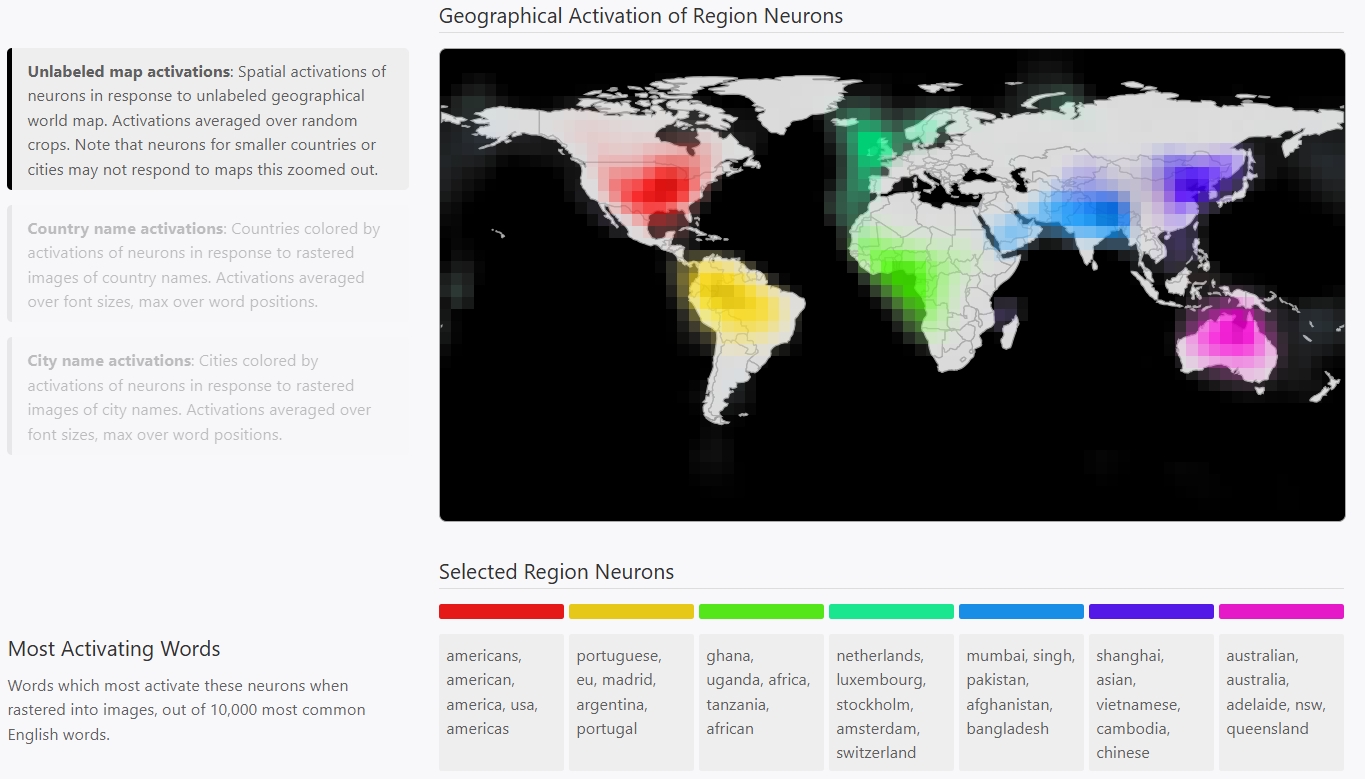
在上图对相应地区轮廓激活的neurons, 也会对下图中同颜色的词语激活。
扯远了, 总之因为CLIP要把图像和文字的表示对齐, 所以它会把图像的表示组织成更像语言的形式。
作者认为SoLU中有些neurons对名人和地区激活, might be seen as a kind of cross-modality universality (可能被视为某种跨模态的普遍性, 即不同模态的模型虽然输入形式不同,但它们可能都会学出某些相似的高层语义特征)。
(6) Partial Mitigation of Interpretability Illusions
Bolukbasi et al. (link) 的"interpretability illusion"指出: Activations of individual neurons in the network may spuriously appear to encode a single, simple concept, when in fact they are encoding something far more complex, 研究者可能看了几个neurons的高激活样本就脑补出一个合理但错误的解释。
本文部分缓解interpretability illusion的方法是: 测试样本集和训练集同分布; 修改样本, 看activation的变化; 看不同activation强度的样本; 做定制实验, 如comparing a hexadecimal text neuron to a regular expression
6.4 Implications of LayerNorm
一开始引入LayerNorm是为了恢复performance, 然LayerNorm使polysemanticity和superposition的事更复杂了。
假设neuron-aligned features主导activations的大小, non-neuron-aligned features只在无neuron-aligned features出现时产生较大影响。为证实此假设, 对比经过LayerNorm之前和之后的使neuron (不同水平)激活的样本。发现对neurons which seemed interpretable, 经过LayerNorm后, neuron的激活样本和它本应响应的feature不一致, 即LayerNorm使先前对neuron的解释不太准确。
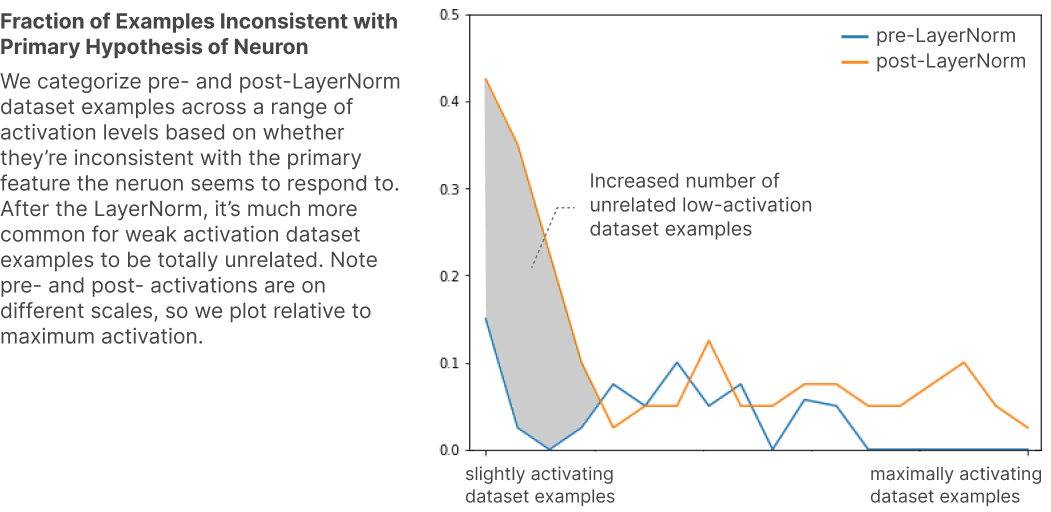
以一个看起来interpretable的、响应 (形容身体部位的) 'left'和'right'的neuron为例, 发现在低激活样本里, post-LayerNorm的不相关样本比例更高。这就和4.3说到的一样, LayerNorm可能把一些原本被SoLU压低的、非neuron-aligned feature的激活值重新放大。