摘要
多版本控制是分布式系统中用于解决并发冲突、数据一致性、服务兼容与变更可追溯的通用架构模式。本文以 MySQL InnoDB MVCC 为基础,按数据库内核、业务设计、微服务、大数据、运维发布五个层级展开,给出各层级多版本控制的实现机制、工程约束与选型依据,构建从原理到落地的完整技术体系。
一、引言:多版本控制的定位与价值
在分布式高并发系统中,多客户端并发修改会引发数据丢失、状态不一致等问题。锁机制通过阻塞实现串行化控制,但会降低系统吞吐量并提升响应延迟。版本控制是一类非阻塞并发控制方案,通过版本号标识数据状态,实现原子更新或历史追溯。
根据设计目标不同,版本控制可分为乐观锁版本控制 与多版本快照控制 两类模式:前者通过原地更新与版本校验实现无锁并发安全,后者通过追加写保留全量历史版本以支持回溯与审计。
二、内核层:MySQL MVCC 多版本并发控制
MVCC(Multi-Version Concurrency Control)是 MySQL InnoDB 实现高并发事务的核心机制,也是所有多版本设计的思想源头。它通过Undo Log 版本链 + ReadView 可见性规则 ,实现了读不加锁、读写不冲突的并发控制。
2.1 MVCC 事务链路核心流程
下面这张图完整展示了 RR 隔离级别下,MVCC 的执行链路与关键规则:
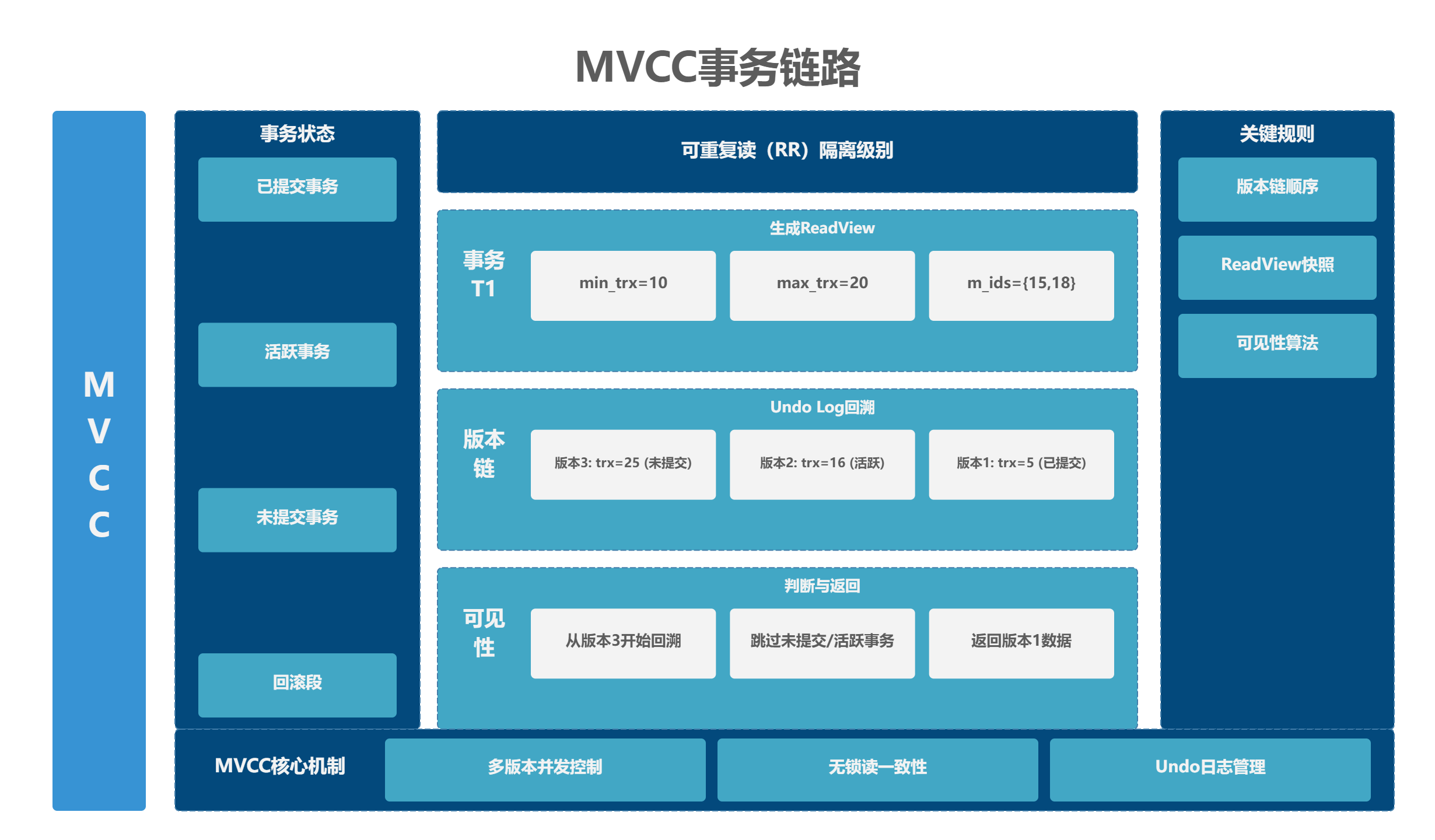
2.2 核心组件拆解
1. 数据行隐式字段
InnoDB 为每条数据行添加了三个隐式字段,支撑版本控制:
- DB_TRX_ID:生成当前版本的事务 ID
- DB_ROLL_PTR:回滚指针,指向 Undo Log 中的上一版本
- DB_ROW_ID:隐含的行 ID,当表无主键时使用
2. Undo Log 版本链
当数据被修改时,InnoDB 不会直接覆盖原数据,而是将旧版本写入 Undo Log,通过DB_ROLL_PTR形成一条版本链。例如:
当前版本(trx_id=25,未提交) ← 历史版本(trx_id=16,活跃) ← 初始版本(trx_id=5,已提交)
版本链遵循只追加、不修改 的原则,历史版本永久不可变。
3. ReadView 可见性视图
ReadView 是事务执行时生成的一致性视图,包含四个核心字段:
- m_ids:当前活跃未提交的事务 ID 列表
- min_trx_id:活跃事务中的最小 ID
- max_trx_id:下一个将分配的事务 ID
- creator_trx_id:当前事务 ID
4. 可见性判断规则
事务读取数据时,会从版本链的最新版本开始回溯,根据 ReadView 判断每个版本是否可见:
- 若版本的trx_id == creator_trx_id:当前事务修改的版本,可见
- 若版本的trx_id < min_trx_id:已提交事务修改的版本,可见
- 若版本的trx_id >= max_trx_id:未来事务修改的版本,不可见
- 若版本的trx_id在m_ids中:活跃事务修改的版本,不可见
2.3 隔离级别与 ReadView 生成时机对比
|----------|-------------------|-------------------|-------------------|
| 隔离级别 | ReadView 生成时机 | 核心效果 | 适用场景 |
| 读已提交(RC) | 每次查询生成新视图 | 可读到其他事务已提交的最新数据 | 大部分业务场景 |
| 可重复读(RR) | 事务内首次查询生成一次 | 事务内数据始终一致,避免不可重复读 | 高并发事务、数据一致性要求高的场景 |
三、业务设计层:版本控制工程实践(乐观锁 + 快照双模式)
业务层版本控制分为两类:乐观锁(原地更新)用于防并发覆盖;多版本快照(追加写入)用于历史追溯、审计与回滚。两类模式目标、实现、约束存在明确边界。
3.1 两类版本核心定义
3.1.1 乐观锁版本控制(原地更新)
目标 :解决高并发更新覆盖,不保留历史。
机制 :更新时携带版本号,匹配成功则执行修改并自增版本。
sql
UPDATE product
SET price = #{newPrice}, version = version + 1
WHERE id = #{id} AND version = #{version}特征 :原地 UPDATE、无历史存储、冲突返回 0 行、轻量高效。
3.1.2 多版本快照控制(追加写入)
目标 :保留全量历史,支持快照、回滚、审计。
机制 :每次变更 INSERT 新记录,版本号单调递增,不执行 UPDATE。
特征 :历史不可变、存储冗余、查询需定位最新版本。
3.2 业务层四种版本方案对比
|-------------|--------|--------|---------------|---------|-----------|-------------|
| 方案 | 分类 | 模式 | 写入方式 | 锁竞争 | 高并发适配 | 适用场景 |
| 单version乐观锁 | 乐观锁 | 原地更新 | UPDATE | 无 | ✅ 适合 | 订单、库存、状态流转 |
| 双version观锁 | 乐观锁 | 原地更新 | UPDATE | 无 | ✅ 适合 | 系统 + 人工并行编辑 |
| LAST 标记版本 | 多版本快照 | 快照 | INSERT+UPDATE | 高 | ❌ 不适合 | 低并发配置、读多写少 |
| 单version快照 | 多版本快照 | 快照 | INSERT | 无 | ✅ 适合 | 商品、主数据、审计 |
3.3 关键方案伪代码实现
3.3.1 单version乐观锁
sql
-- 表结构
CREATE TABLE product_stock (
id BIGINT PRIMARY KEY,
stock INT,
version INT NOT NULL DEFAULT 0
);
-- 更新逻辑(带版本校验)
UPDATE product_stock
SET stock = #{newStock}, version = version + 1
WHERE id = #{id} AND version = #{version}3.3.2 双 version 乐观锁 (字段级隔离冲突)
java
public class VersionedEntity {
private String bizKey;
// 系统字段组
private Long systemVersion; // 版本号一
private String systemData;
// 人工字段组
private Long manualVersion; // 版本号二
private String manualData;
}3.3.3 LAST 标记快照
sql
CREATE TABLE biz_config (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
biz_key VARCHAR(64) NOT NULL,
data JSON NOT NULL,
is_latest TINYINT DEFAULT 0,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 1. 插入新版本
INSERT INTO biz_config (biz_key, data, version, is_latest)
VALUES (#{key}, #{data}, #{version}, 1);
-- 2. 将旧版本置为非最新(高并发下锁开销大)
UPDATE biz_config
SET is_latest = 0
WHERE biz_key = #{key} AND latest = 1;3.3.4 单版本快照
sql
-- 表结构:只INSERT,不UPDATE
CREATE TABLE biz_snapshot (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
biz_key VARCHAR(64) NOT NULL,
data JSON NOT NULL,
version INT NOT NULL,
create_time DATETIME DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY uk_biz_key_version (biz_key, version)
);
-- 查询最新版本
SELECT t1.* FROM biz_snapshot t1
JOIN (
SELECT biz_key, MAX(version) AS latest_version
FROM biz_snapshot
WHERE biz_key = #{bizKey}
) t2 ON t1.biz_key = t2.biz_key AND t1.version = t2.latest_version;四、微服务与 API 层:多版本支撑服务平滑演进
微服务版本控制用于解决接口兼容、灰度发布、滚动升级问题,通过版本标识实现新旧服务并行运行与流量可控切换。
4.1 接口版本实现方式对比
|----------|------------------------------|----------|--------|----------------|
| 方案 | 实现方式 | 优点 | 缺点 | 适用场景 |
| URL 路径版本 | /api/v1/resource | 直观、易缓存 | URL 冗余 | 对外 RESTful API |
| 请求头版本 | Accept-Version: v1 | 无 URL 污染 | 客户端需配置 | 内部服务调用 |
| 服务版本路由 | Dubbo/GRPC version | 服务级隔离 | 依赖注册中心 | 微服务内部通信 |
| 语义化版本 | 主版本号 . 次版本号 . 补丁版本号(例:2.1.5) | 规范兼容约定 | 需团队协同 | SDK、组件发布 |
4.2 接口版本路由示例(Spring Boot)
java
@RestController
@RequestMapping("/api/v1/order")
public class OrderControllerV1 {
@GetMapping("/{id}")
public OrderDTO getOrder(@PathVariable Long id) { /* v1逻辑 */ }
}
@RestController
@RequestMapping("/api/v2/order")
public class OrderControllerV2 {
@GetMapping("/{id}")
public OrderDTO getOrder(@PathVariable Long id) { /* v2兼容逻辑 */ }
}五、大数据层:多版本保障流批一体一致性
大数据场景通过版本控制解决乱序、重复、口径不一致问题,实现快照读取与时间旅行回溯。
5.1 核心实现方式概览
大数据多版本控制的核心目标,是在流式计算、批量计算与数据存储之间建立统一的数据视图,确保不同计算引擎对同一份数据的读取结果一致。
|-------------|----------------------------------------------------------------|---------------------|-------------|
| 实现方式 | 核心机制 | 解决问题 | 典型场景 |
| 时间戳版本 | 基于 Flink 的 Event Time/Processing Time/Ingestion Time 为数据打上时间版本 | 数据乱序、延迟到达 | 实时流处理、窗口计算 |
| CDC 版本链 | 基于数据库 Binlog/CDC 捕获全量变更,形成数据版本链 | 数据同步、变更审计、主数据管理 | 实时数仓、数据中台 |
| 数据湖快照 | 数据湖框架自动维护数据历史版本,支持按时间 / 版本读取快照 | 流批口径不一致、数据误删 / 修改回滚 | 流批一体数仓、数据仓库 |
5.2 CDC 版本链:全量变更的版本化捕获
5.2.1 核心原理
CDC(Change Data Capture,变更数据捕获)通过监听数据库的 Binlog 日志,将数据的每一次 INSERT/UPDATE/DELETE 操作捕获为独立的变更事件,并按时间顺序形成一条数据版本链 。
其核心逻辑与 MySQL MVCC 的 Undo Log 版本链高度相似:
- 每次数据变更都会生成一个新版本,不覆盖旧数据
- 版本链按变更时间顺序排列,保留数据的完整生命周期
- 下游系统可按需消费任意版本的数据,实现数据同步与回溯
5.2.2 典型实现链路
CDC 版本链的完整实现链路,可分为数据源层、采集与分发层、流处理层、存储与消费层 四大阶段,每一层都为数据打上版本标识,形成完整的变更链路。其架构如下图所示:
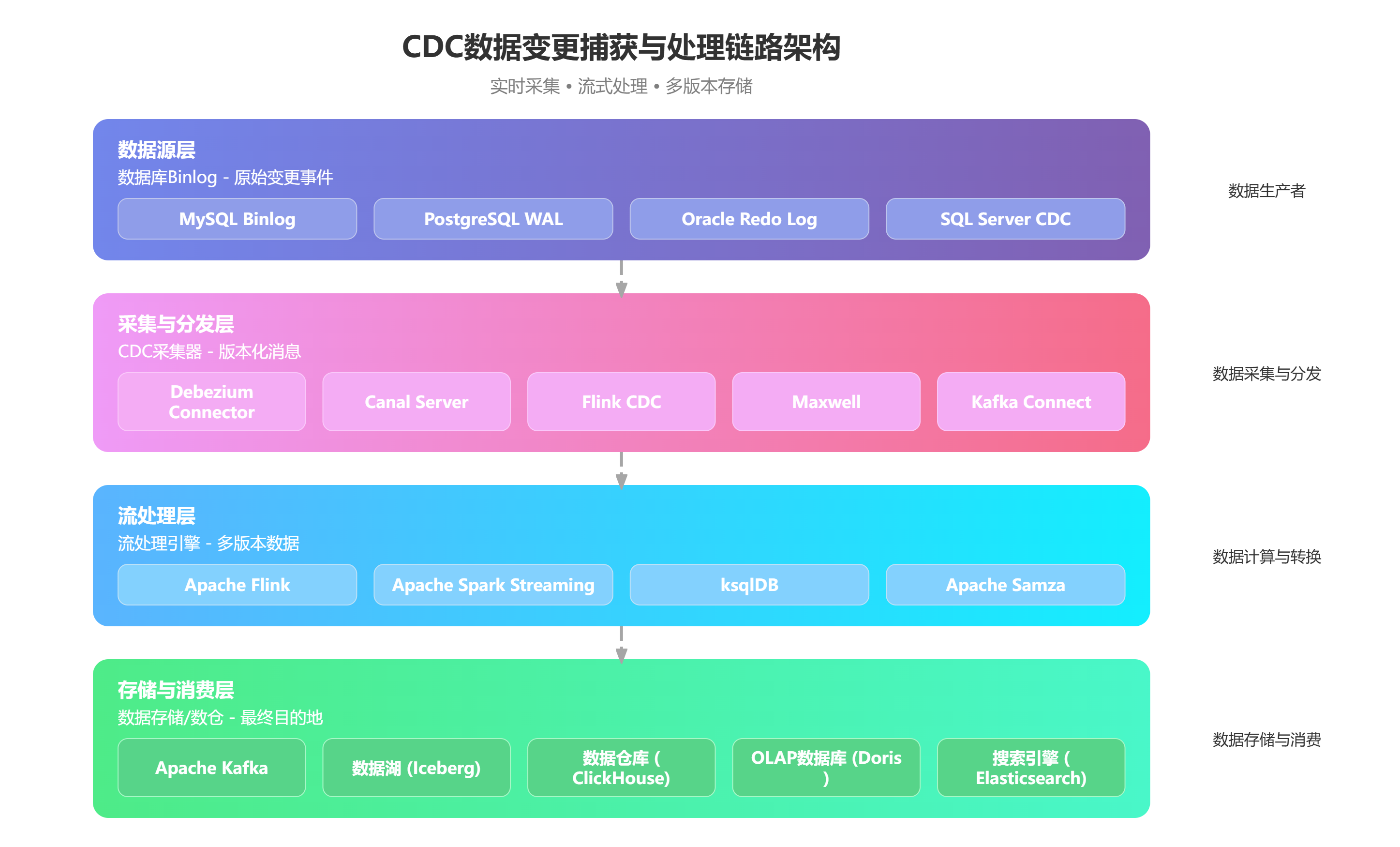
- 数据源层 :数据库 Binlog/WAL 作为原始变更事件,是版本链的源头;
- 采集与分发层 :CDC 采集器(如 Debezium、Canal)将变更事件转换为版本化消息,实现无侵入式数据捕获;
- 流处理层 :Flink/Spark 等流引擎消费版本化消息,构建多版本数据;
- 存储与消费层 :数据湖(Iceberg)、数仓等系统存储多版本数据,支持后续的查询与回溯。
5.2.3 数据示例
以订单表为例,CDC 捕获的版本链如下:
|--------|----------|-----------|--------|--------|---------------------|----------|
| 版本 | 操作类型 | 订单 ID | 状态 | 金额 | 变更时间 | 版本标识 |
| 1 | INSERT | 1001 | 待支付 | 100.00 | 2026-05-20 10:00:00 | GTID-001 |
| 2 | UPDATE | 1001 | 已支付 | 100.00 | 2026-05-20 10:01:00 | GTID-002 |
| 3 | UPDATE | 1001 | 已发货 | 100.00 | 2026-05-20 10:05:00 | GTID-003 |
| 4 | UPDATE | 1001 | 已完成 | 100.00 | 2026-05-20 10:20:00 | GTID-004 |
下游系统可通过消费指定版本的 CDC 事件,还原任意时刻的订单状态,实现数据审计与问题排查。
5.3 数据湖快照:流批一体的一致性保障
数据湖(如 Iceberg、Hudi、Delta Lake)通过自动维护数据的历史版本快照,实现时间旅行查询(Time Travel) ,是流批一体架构中保障数据一致性的核心技术。
5.3.1 核心原理
数据湖的快照机制与 MySQL MVCC 的 ReadView 可见性规则异曲同工:
- 每次数据写入 / 更新都会生成一个新的快照版本
- 快照包含当前数据文件的完整元数据信息
- 流处理引擎与批处理引擎可通过指定快照版本,读取同一时刻的一致性数据视图
- 历史快照可长期保留,支持数据回滚与审计
5.3.2 数据湖版本快照流程
数据湖的快照机制,通过写入、读取、存储三个阶段的协同,实现了与 MySQL MVCC 类似的一致性读与历史回溯能力,其完整流程如下图所示:
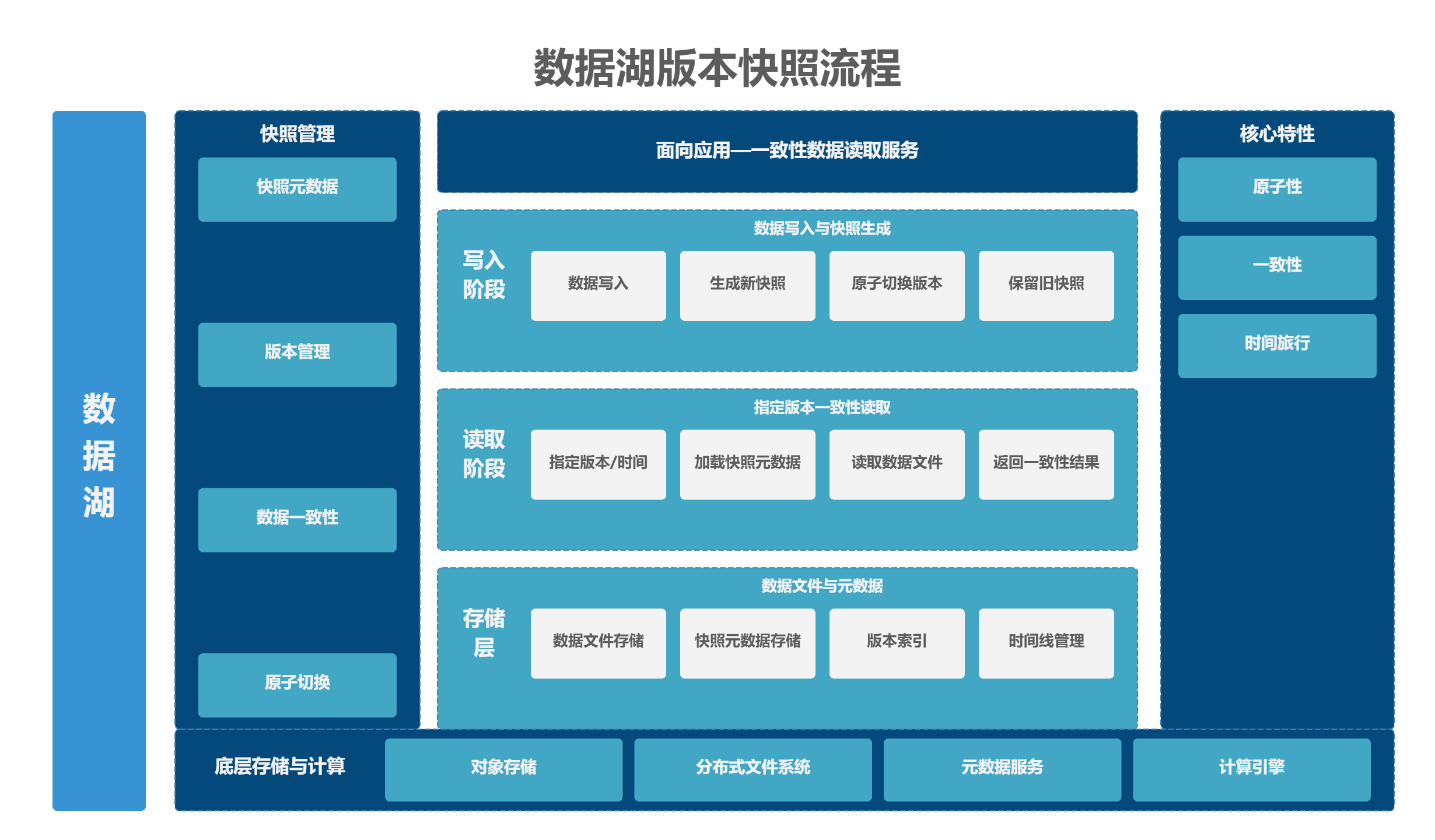
- 写入阶段 :数据写入后生成新快照,通过原子切换版本确保写入不影响读,同时保留旧快照;
- 读取阶段 :通过指定版本或时间戳,加载对应快照的元数据,读取一致性数据;
- 存储层 :数据文件与快照元数据分离存储,通过版本索引和时间线管理,支持高效的历史回溯;
- 其核心特性(原子性、一致性、时间旅行)保障了流批一体架构下的数据视图统一。
5.3.3 数据湖快照查询示例
sql
-- 查询指定时间的历史快照(时间旅行)
SELECT * FROM orders
AS OF TIMESTAMP '2026-05-20 10:00:00';
-- 查询表的所有历史版本
SELECT * FROM orders.history;
-- 回滚到指定版本(数据修复)
ALTER TABLE orders ROLLBACK TO VERSION 100;六、运维发布层:版本化降低发布风险
发布与配置场景通过版本化实现变更可追溯、可回滚,提升系统稳定性。
6.1 发布版本策略对比
|--------|-------------|---------|----------|
| 策略 | 核心机制 | 优势 | 适用场景 |
| 蓝绿部署 | 新旧版本并行,流量切换 | 切换快、回滚易 | 无状态服务 |
| 金丝雀发布 | 小流量验证后全量 | 风险低、影响小 | 核心高并发服务 |
| 配置版本管理 | 配置历史存档、一键回滚 | 变更可追溯 | 配置频繁变更系统 |
七、核心复习要点
- MVCC 由隐式字段、Undo Log 版本链、ReadView 构成,RR 隔离级别全程复用同一视图,实现事务级一致。
- 版本控制分两类 :乐观锁为原地 UPDATE+version 自增,用于防覆盖;多版本快照为 INSERT 追加,用于历史追溯。
- 业务层选型 :高并发写优先无状态快照;系统 + 人工并行编辑用双版本号;低并发配置可用 LAST 标记;状态更新用乐观锁。
- 微服务版本 :对外用 URL 路径,内部用请求头 / 服务版本,SDK 使用 SemVer 语义化版本。
- 大数据与运维 :时间戳版本解决乱序;数据湖支持时间旅行;发布版本化实现可回滚、低风险变更。
- 统一范式 :版本用于并发控制与历史追溯,核心是在一致性、吞吐、存储间做工程权衡。
结尾:你在实际项目中用过哪些版本控制方案?欢迎在评论区留言!
📚 我的技术博客导航:点击进入一站式查看所有干货