学习笔记:详述 RAG 系统中多路召回的原理与实现,以及索引层、查询层、召回层、重排序层的四层检索优化框架
目录
- 为什么需要多路召回
- 多路召回原理
- 三路召回详解
- [第一路:向量检索(Dense Retrieval)](#第一路:向量检索(Dense Retrieval))
- [第二路:BM25 关键词检索(Sparse Retrieval)](#第二路:BM25 关键词检索(Sparse Retrieval))
- [第三路:多 Query 扩展召回](#第三路:多 Query 扩展召回)
- 召回方式对比
- [结果融合:RRF 算法](#结果融合:RRF 算法)
- 四层检索优化框架
- 四层组合策略
- 高级优化技术
- 参考资料
为什么需要多路召回
RAG 系统中,LLM 只能根据送入的 context 回答,检索召回的内容就是系统的天花板。生成层优化属于锦上添花,检索层优化才是从根本上提升能力上限的环节。
单路检索(如纯向量检索)存在固有盲区------对精确词语(产品型号、专有名词、数字)召回效果差。调大 top-K 会引入大量无关 chunk,稀释 LLM 注意力,且向量相似度排序尾部趋于平坦,无法解决根本问题。
多路召回的核心思路:同时采用多种检索方式捞取候选内容,再合并排序,让不同检索方式互相补盲。
多路召回原理
什么是多路召回
多路召回即同时使用多种不同检索方式捞取候选内容,合并排序后交给 LLM 生成答案。与之对应的是单路召回(只用一种检索方式,典型为纯向量检索)。
没有任何一种检索方式是全能的,向量检索有盲区,BM25 也有盲区,组合起来互相补盲才能提升总召回质量。
单路召回的局限
向量检索的短板:对精确词语召回效果差。例如用户问「M4 Pro 芯片的性能参数」,「M4 Pro」作为专有名词,向量模型可能将其与「苹果最新处理器」拉近,但精确匹配更可靠。这是向量检索"只看语义、不看字面"的固有局限,换模型也解决不了。
BM25 的短板:对同义词和不同表达无能为力。例如用户问「怎么退货」,文档写的是「申请售后」,词没重叠则完全召不回。
两种方式的盲区恰好互补,这便是多路召回的出发点。
典型三路召回架构
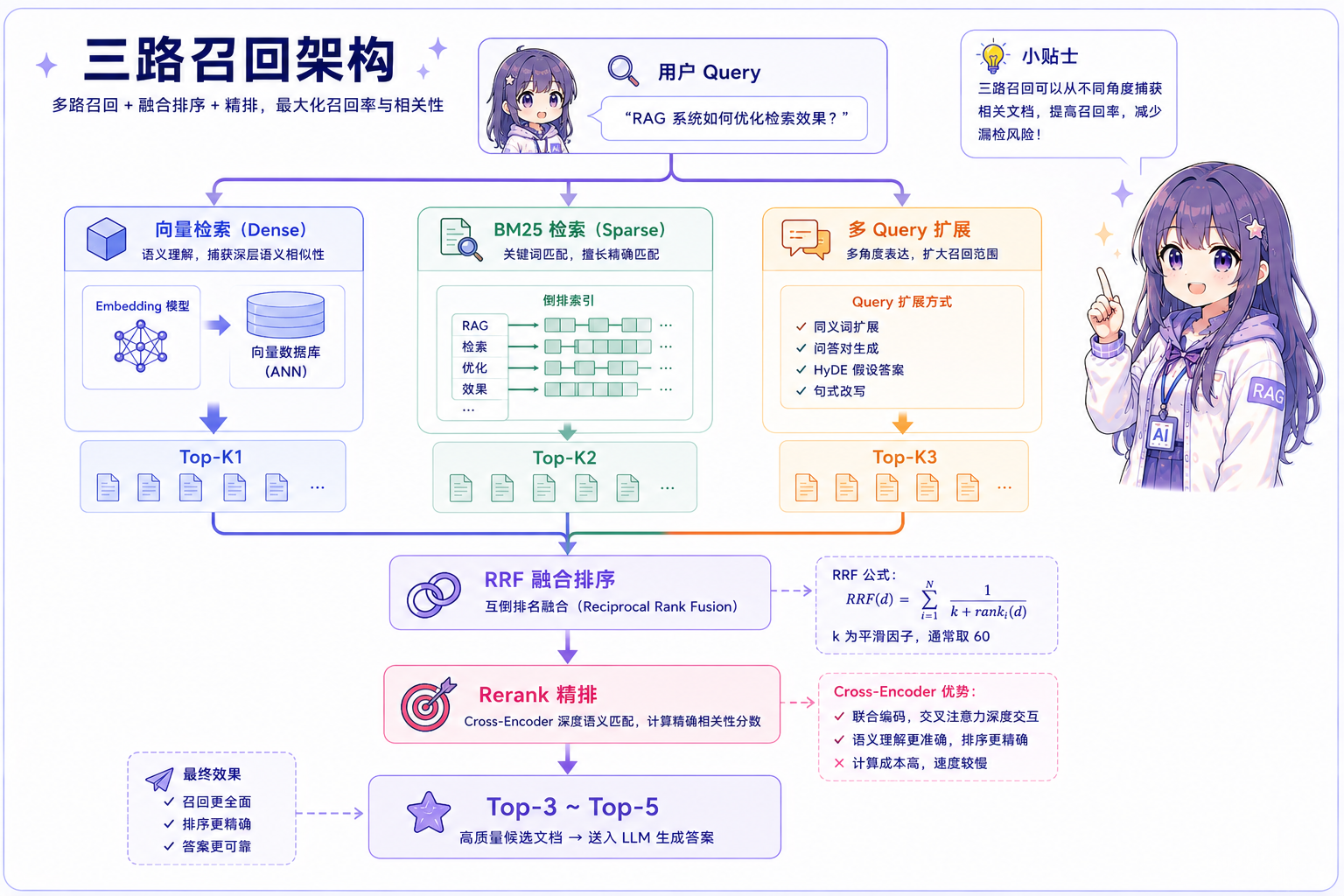
三路召回详解
第一路:向量检索(Dense Retrieval)
核心做法:将文档和用户问题用 Embedding 模型转成向量,用余弦相似度在向量库中找最近的 top-K 个 chunk。
- 擅长:语义匹配、同义词覆盖、不同表达方式
- 短板:对精确词语(产品型号、缩写、数字)效果不佳
第二路:BM25 关键词检索(Sparse Retrieval)
BM25 是 TF-IDF 的改进版,根据词频和文档频率给每个词打分。核心逻辑:一个词在某文档中出现频率高(词频高),但在整个知识库中出现频率低(区分度高),则该词对此文档代表性强、权重高。
中文场景需先分词(如 jieba),再对分词后的词列表建索引和检索。
- 擅长:精确词语、数字、专有名词召回
- 短板:不理解语义
第三路:多 Query 扩展召回
存在的原因:用户提问角度与文档表述角度可能完全不同(非同义词问题)。例如用户问「产品多久能送到」vs 文档写「配送时效说明」,向量相似度不高,BM25 也匹配不到。
做法:用 LLM 将原始问题改写为 3~5 个不同角度版本,分别检索,合并去重。只要有一个改写版本与文档表述对上,就能召回正确内容。
原始问题:"这个东西咋退货"
│
├── 改写 1:"退货流程和操作步骤"
├── 改写 2:"如何申请退款"
├── 改写 3:"售后服务政策"
└── 改写 4:"商品退换货规定"
每个改写版本独立检索 → 合并去重 → 覆盖率提升 10%~20%代价:多了几次 LLM 调用,但在提问风格多变的场景下收益明显。
注意:原始问题必须保留在检索列表中,因为改写可能丢失细节。
召回方式对比
| 召回方式 | 擅长 | 短板 | 适合场景 |
|---|---|---|---|
| 向量检索 | 语义相似、同义词、不同表达 | 精确词语、数字、专有名词 | 通用语义检索 |
| BM25 关键词 | 精确词匹配、专有名词 | 同义词、语义相关但词不重叠 | 有大量精确词语的知识库 |
| 多 Query 扩展 | 覆盖不同表述角度 | 增加 LLM 调用开销 | 用户提问风格多变的场景 |
结果融合:RRF 算法
三路结果分数单位不同(余弦相似度 vs BM25 分数),无法直接加权平均。归一化效果也不稳定。
RRF(Reciprocal Rank Fusion,倒数排名融合) 不看原始分数,只看排名:
RRF_score(d) = Σ 1 / (k + rank_r(d))
其中:
rank_r(d) = 文档 d 在第 r 路检索结果中的排名
k = 平滑参数,通常取 60(防止排名第 1 的文档权重过大)核心特点:
- 只用排名不用原始分数,绕开分数不可比问题
- 文档在多路检索中都排名靠前,则综合分高
- 不需要训练、计算量极小、工程落地成本低
- RRF 本质上是粗排,适合在 Rerank 之前做候选集合并
代码实现:
python
def reciprocal_rank_fusion(results_list, k=60):
"""
results_list: 多路检索结果,每路是一个 [doc_id, ...] 的有序列表
k: 平滑参数,通常取 60
"""
scores = {}
for results in results_list:
for rank, doc_id in enumerate(results):
if doc_id not in scores:
scores[doc_id] = 0
scores[doc_id] += 1 / (rank + k)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
# 三路召回示例
vector_results = ["doc_a", "doc_b", "doc_c", "doc_d"]
bm25_results = ["doc_b", "doc_d", "doc_a", "doc_e"]
query_expanded = ["doc_c", "doc_a", "doc_f", "doc_b"]
merged = reciprocal_rank_fusion([vector_results, bm25_results, query_expanded])
# doc_a、doc_b 在多路中都排名靠前,综合分最高RRF 计算示例:
| 文档 | 向量排名 | BM25 排名 | 扩展排名 | RRF 分数 |
|---|---|---|---|---|
| Doc A | 1 | 3 | 2 | 1/61 + 1/63 + 1/62 = 0.0486 |
| Doc B | 2 | 1 | 4 | 1/62 + 1/61 + 1/64 = 0.0484 |
| Doc C | 3 | 4 | 1 | 1/63 + 1/64 + 1/61 = 0.0477 |
四层检索优化框架
框架全景
检索优化不是换个模型调调参数,需要系统性的分层思维。四层为递进关系:
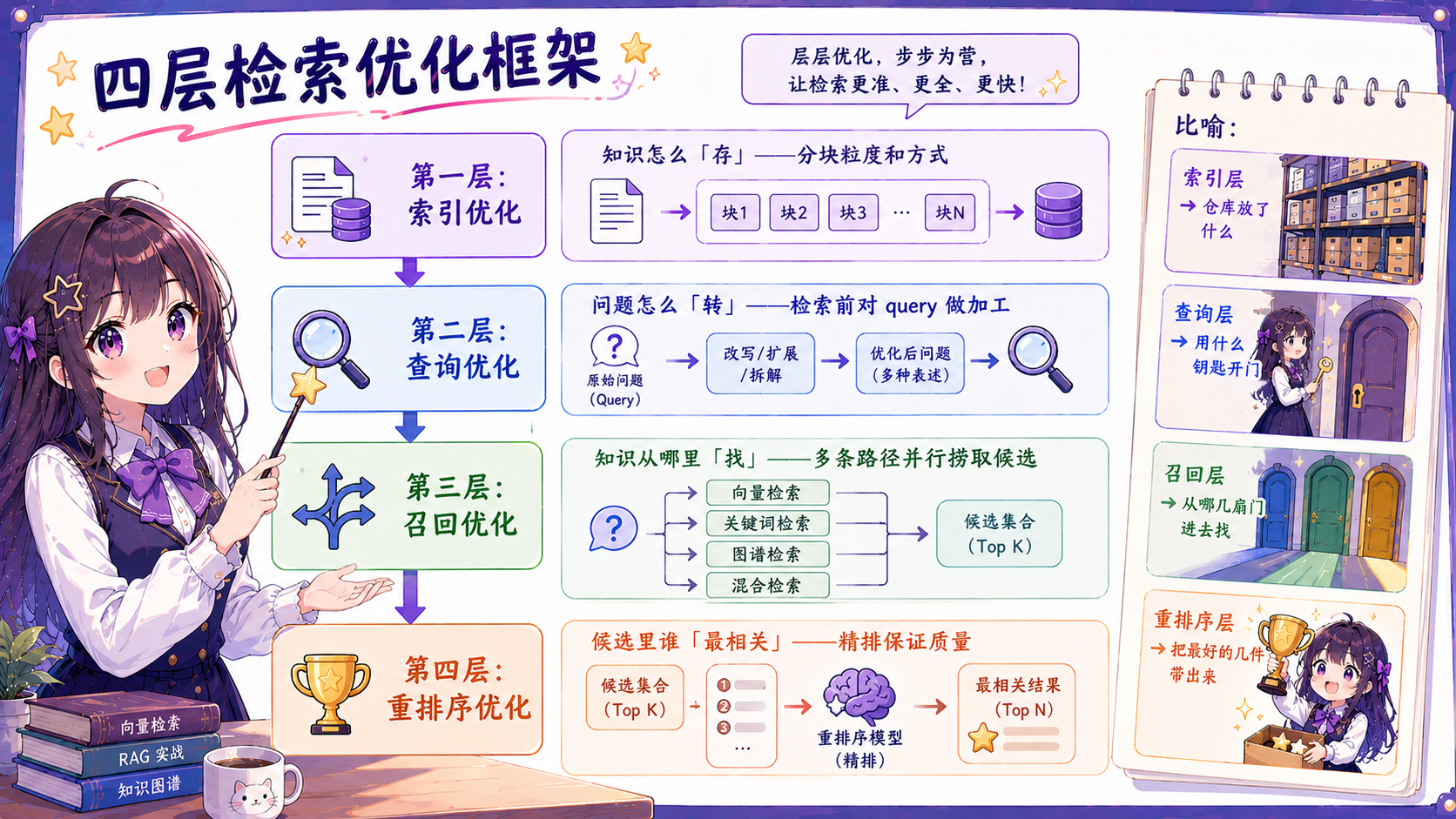
| 层次 | 解决的核心问题 | 推荐程度 |
|---|---|---|
| 索引优化(Parent-Child) | 检索粒度 vs 上下文完整性的矛盾 | 推荐,效果稳定 |
| 查询优化(Multi-Query/HyDE) | 用户提问和知识库表达不对齐 | 视场景,提问质量差时必做 |
| 多路召回(向量+BM25) | 单路检索漏召 | 推荐,低成本高收益 |
| Rerank 精排 | 粗召精度不足 | 强烈推荐,提升精度最直接 |
四层记忆口诀:
- 索引层保证存进去的知识可以被找到
- 查询层保证搜索的姿势是对的
- 召回层保证不漏掉该找到的内容
- Rerank 层保证送进 LLM 的是真正有用的内容
第一层:索引优化
核心矛盾:检索用的粒度和 LLM 读的粒度天然矛盾。
Chunk 承担两个角色:
- 被检索找到:需要小粒度,语义聚焦
- 被 LLM 读懂:需要大粒度,上下文完整
小 chunk 检索准但内容碎片化;大 chunk 内容完整但语义稀释。
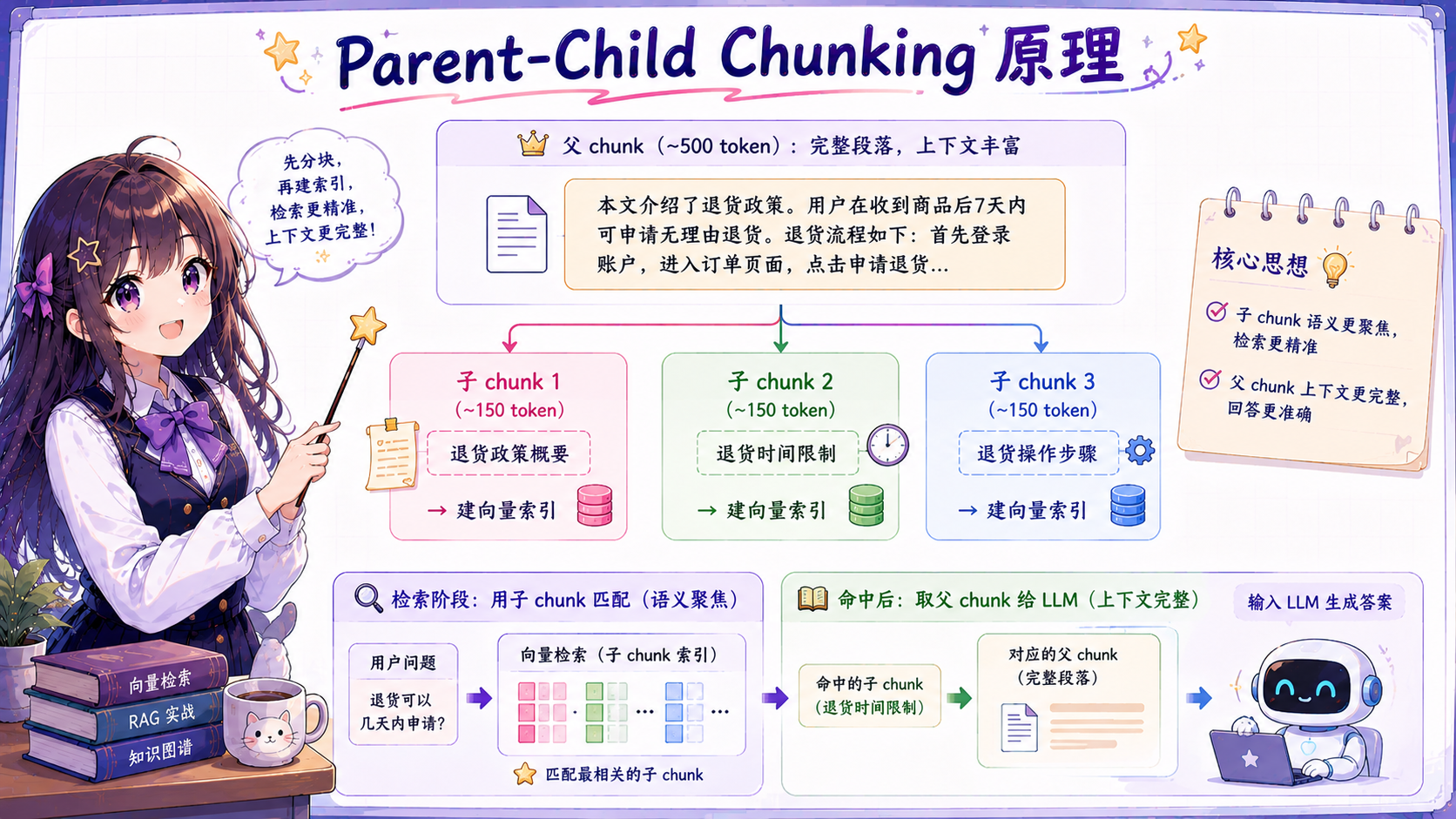
解决思路:Small-to-Big(小块检索、大块使用),三种实现方式:
1. Parent-Child Chunking
把文档切成两个版本:细粒度子 chunk(约 150 token)和粗粒度父 chunk(约 500 token)。每个子 chunk 通过 parent_id 关联父 chunk。入库时只给子 chunk 建向量索引,检索用子 chunk 向量匹配,命中后取出父 chunk 给 LLM 阅读。
2. 摘要索引(Summary Index)
让 LLM 为每段内容生成摘要,用摘要建向量索引。摘要是核心意思的提炼,语义更聚焦,在向量空间中与用户问题更接近。检索用摘要匹配,命中后把原始段落给 LLM。
3. 多粒度分层索引
同时建章节级、段落级、句子级三层索引。不同类型问题选不同粒度:宽泛概念性问题用章节级,细节性问题用句子级,系统根据问题类型自动选择。
第二层:查询优化
解决用户提问方式和知识库表述方式之间的鸿沟。
例:用户问「苹果手机咋截图」vs 知识库写「iPhone 截图操作方法」------口语与书面语的 Embedding 距离比直觉以为的更远,尤其短文本场景。
1. Query 改写
用 LLM 把口语化、有歧义的 query 转为正式精准的书面表达。如把含指代不明的「它为什么这么贵」结合对话历史改写为具体产品定价问题。
原始:"这个东西咋用啊"
改写:"产品使用方法和操作步骤"2. 多 Query 扩展(Multi-Query)
用户提问角度和文档描述角度对不上时,用 LLM 把一个问题扩展成 3~5 个不同角度的问法,每种单独检索,结果合并去重。比喻为"撒网捕鱼"。
注意:原始问题必须保留在检索列表中,因为改写可能丢失细节。
3. HyDE(假设文档嵌入)
先让 LLM 根据问题生成假设答案,用假设答案的向量去检索。假设答案和文档都是陈述性文字,风格更接近,向量距离更近。
风险:假设答案方向错会带偏检索,适合知识库领域明确的场景。
用户查询:"RAG 系统怎么优化检索效果"
│
▼
LLM 生成假设答案:
"RAG 系统优化检索效果的方法包括:
1. 使用混合检索策略...
2. 引入 Rerank 模型..."
│
▼
假设答案 → Embedding → 向量 → 检索
(与真实文档语义空间更接近,命中率更高)4. Step-back Prompting(后退提问)
问题太具体但知识库只有通用背景时,先将具体问题往上抽象一层,生成更通用的背景问题去检索,再结合背景知识回答具体问题。
原始问题:"GPT-4 Turbo 的 token 上限是多少"
后退问题:"大语言模型的上下文窗口发展趋势"
→ 检索到更全面的背景知识,再结合回答具体问题第三层:召回优化
从检索路径角度优化。单一向量检索的根本局限:只擅长语义相似,精确词语匹配效果差。
关键词检索(BM25)的盲区:只数词频不理解语义。「怎么退货」vs「申请售后」词不重叠,BM25 召不到,但向量检索能处理。
两种方式盲区互补,出发点是多路召回。典型三路并行检索(向量 + BM25 + 多 Query 扩展),结果通过 RRF 融合。
(详见前文"多路召回原理"和"RRF 算法"章节)
第四层:重排序优化
多路召回后候选可能有 20~30 个,混入不相关内容会导致:
- token 消耗暴涨
- LLM 出现 "Lost in the Middle" 现象(只关注开头和结尾,忽略中间)
需要精排从 20~30 个候选中挑出最相关的 3~5 个。
两种模型结构对比:
| Bi-Encoder(向量检索) | Cross-Encoder(Rerank) | |
|---|---|---|
| 原理 | query 和 chunk 各自独立编码成向量,算余弦相似度 | query+chunk 拼成一对输入,模型整体看相关性 |
| 优点 | 速度快,chunk 向量可提前计算存库 | 能看到 query 每个词对 chunk 的影响,精度远高于 Bi-Encoder |
| 缺点 | 分开编码,无法看到具体词语关联 | 每个候选单独跑一次,速度慢,只适合小规模精排 |
比喻:Bi-Encoder 像只看两人简历判断合作可能性,Cross-Encoder 像把两人放一个房间观察实际交流配合。
Rerank 流程:多路召回得 20~30 个候选 → Cross-Encoder 逐一对 (query, chunk) 对打分 → 按分数降序 → 取 top-3 到 top-5 拼入 prompt。
常用 Rerank 模型:
| 模型 | 来源 | 特点 |
|---|---|---|
| bge-reranker-v2-m3 | BAAI | 中英双语效果好,开源 |
| BCE-Reranker | 网易 | 中文场景表现好 |
| Cohere Rerank | Cohere | 商业 API,效果优秀 |
| Jina Reranker | Jina | 多语言支持 |
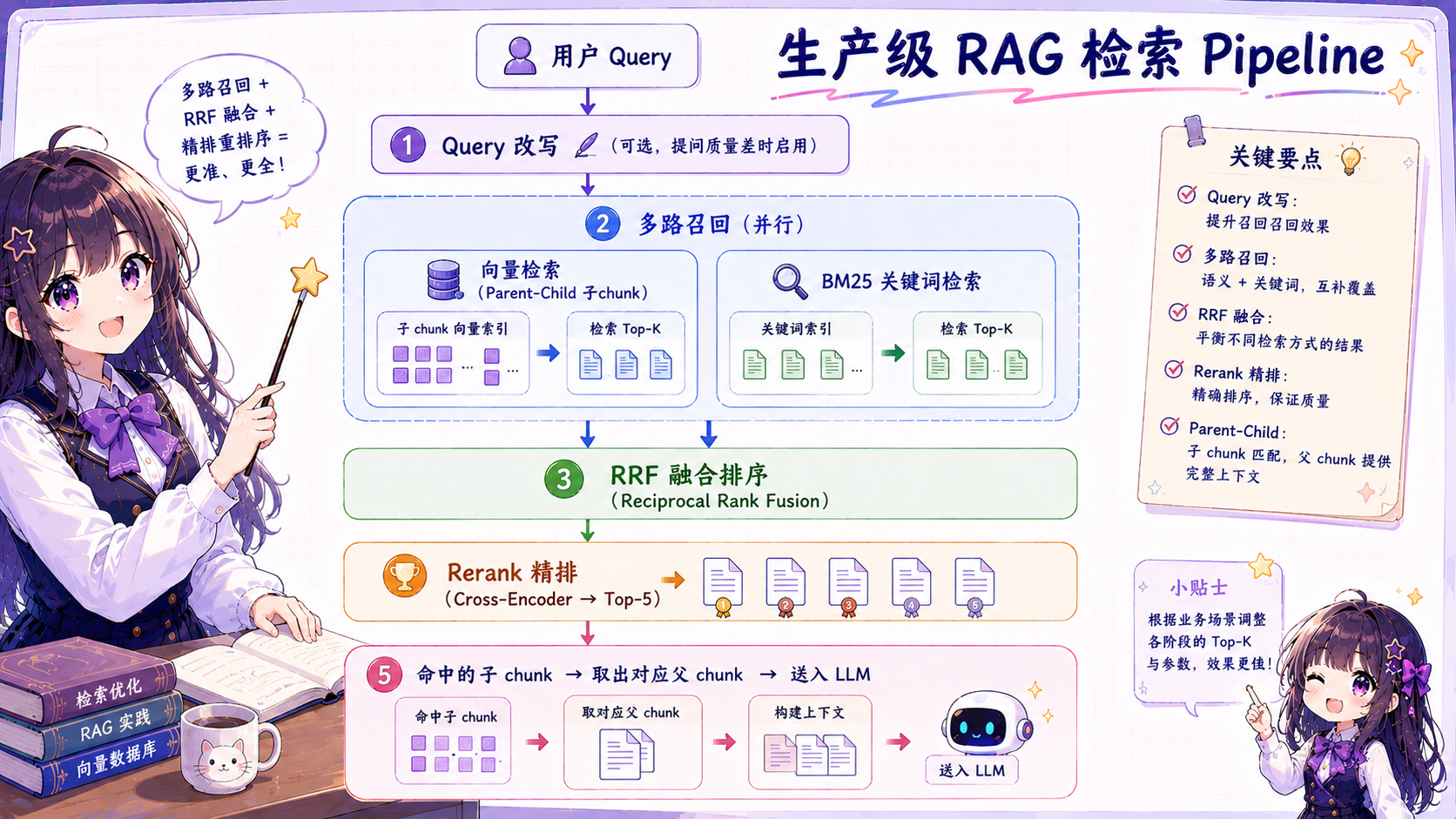
四层组合策略
典型生产级搭配
Parent-Child 索引 + 向量 BM25 多路召回 + Rerank 精排,覆盖大多数场景。用户提问质量差时额外加 Query 改写。
场景化建议
| 场景 | 建议方案 |
|---|---|
| 大量专有名词、型号、数字(电商、IT 文档) | 向量 + BM25 双路 |
| 用户提问方式多变(客服问答) | 双路 + 多 Query 扩展,覆盖率提升 10%~20% |
| 召回质量要求极高 | 三路全上 + Rerank 精排 |
| 知识库领域明确 | 可加 HyDE 假设文档嵌入 |
| 用户问题过于具体 | 可加 Step-back Prompting |
高级优化技术
Self-RAG
LLM 自判断是否需要检索、检索结果是否有用。模型在生成过程中自主决定何时调用检索器,而非每次都检索。
Corrective RAG(CRAG)
检索后评估文档质量,不足时触发 web 搜索作为补充。先对检索结果做相关性评分,低分结果丢弃,转而从外部搜索获取信息。
Lost in the Middle
LLM 对长上下文的注意力分布不均匀------开头和结尾的内容关注度高,中间内容容易被忽略。
应对策略:将最相关文档放在开头和结尾,中间放次相关文档。
Prompt 中文档排列:
[1] 最相关 ← LLM 注意力高
[2] 次相关
[3] 次相关 ← LLM 注意力低(Lost in the Middle)
[4] 次相关
[5] 最相关 ← LLM 注意力高上下文压缩
检索到的 chunk 可能包含大量与问题无关的内容,占用宝贵的 context window。使用 LMLingua 等工具压缩检索到的上下文,保留关键信息,减少 token 消耗。
参考资料
-
多路召回详解
-
检索优化策略详解
-
HyDE 论文:Precise Zero-Shot Dense Retrieval without Relevance Labels
-
RRF 论文:Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods
-
Self-RAG 论文:Learning to Retrieve, Generate, and Critique through Self-Reflection
-
CRAG 论文:Corrective Retrieval Augmented Generation
-
Lost in the Middle 论文:How Language Models Use Long Contexts
-
BGE Reranker(BAAI)
-
LMLingua 上下文压缩
-
LangChain RAG 实践文档
-
LlamaIndex 检索与重排序
https://docs.llamaindex.ai/en/stable/module_guides/querying/