
在现代 C++ 中,除了基于虚函数的运行时多态,还有一种被称为"奇异递归模板模式"(Curiously Recurring Template Pattern,CRTP)的静态多态(调用目标在编译期确定),被广泛应用于 Chromium、V8、LLVM、UE 等大型项目当中。
1. 一个具体的例子
下面先给出一个我们最熟悉不过的基于虚函数的运行时多态的例子:
C++
#include <iostream>
class Animal {
public:
virtual void Speak() = 0;
};
class Cat : public Animal {
public:
void Speak() override {
std::cout << "meow" << std::endl;
}
};
class Dog : public Animal {
public:
void Speak() override {
std::cout << "woof" << std::endl;
}
};
int main() {
auto* dog = new Dog();
auto* cat = new Cat();
dog->Speak();
cat->Speak();
}很显然,在编译器无法对目标函数去虚化时,调用虚函数是需要付出查vtable等额外开销的:
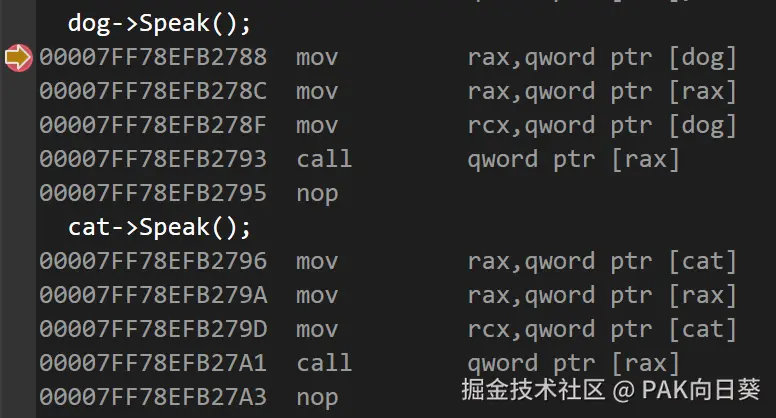
下面我们再来看怎么用 CRTP 重构上面的代码:
C++
#include <iostream>
template <typename D>
class Animal {
public:
void Speak() {
// 将 this 指针显式下行转换为派生类类型,
// 从而调用派生类的 SpeakImpl() 方法。
static_cast<D*>(this)->SpeakImpl();
}
};
class Cat : public Animal<Cat> {
public:
void SpeakImpl() {
std::cout << "meow" << std::endl;
}
};
class Dog : public Animal<Dog> {
public:
void SpeakImpl() {
std::cout << "woof" << std::endl;
}
};
int main() {
auto* dog = new Dog();
auto* cat = new Cat();
dog->Speak();
cat->Speak();
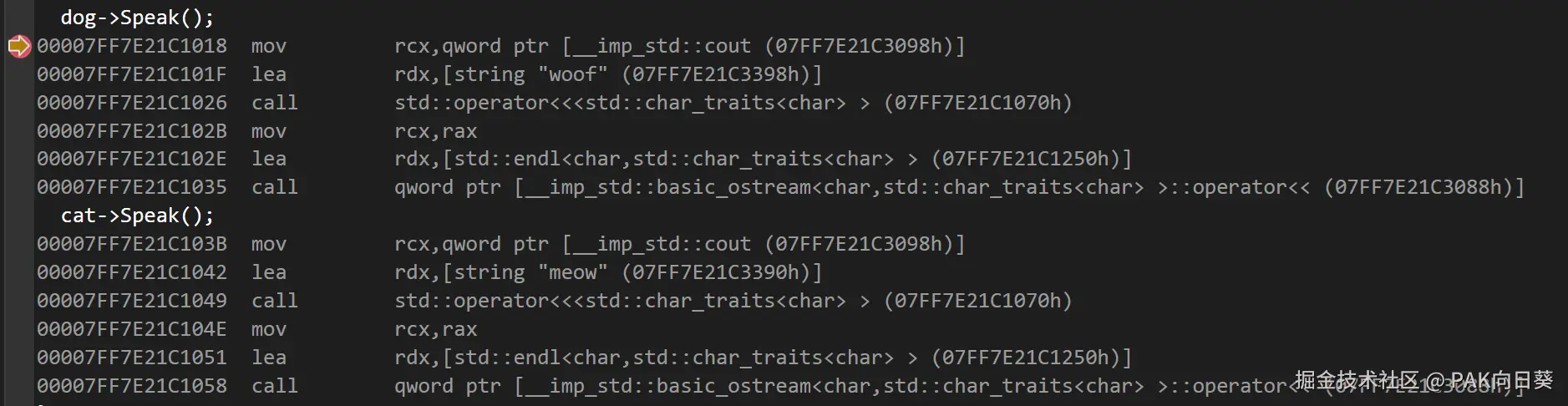
}分析这段代码的反汇编代码(debug版本),可以看到在编译阶段会为Animal<Cat>和Animal<Dog>分别生成一个 C++ 函数,而在执行 dog->Speak() 和 cat->Speak() 时,只需直接分别调用Animal<Cat>::Speak()和Animal<Dog>::Speak()即可。也就是说整个代码的行为在编译阶段是可以被完全确定下来的。
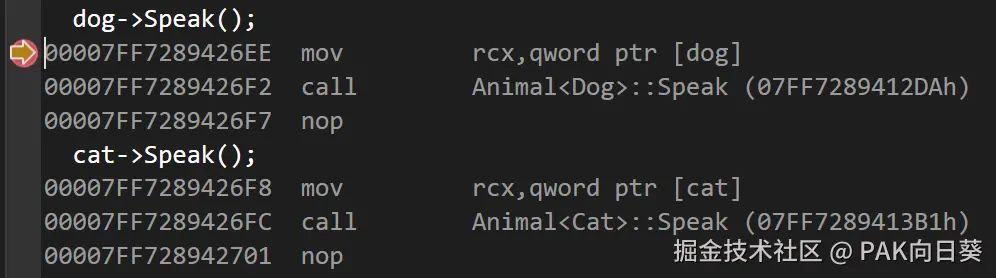
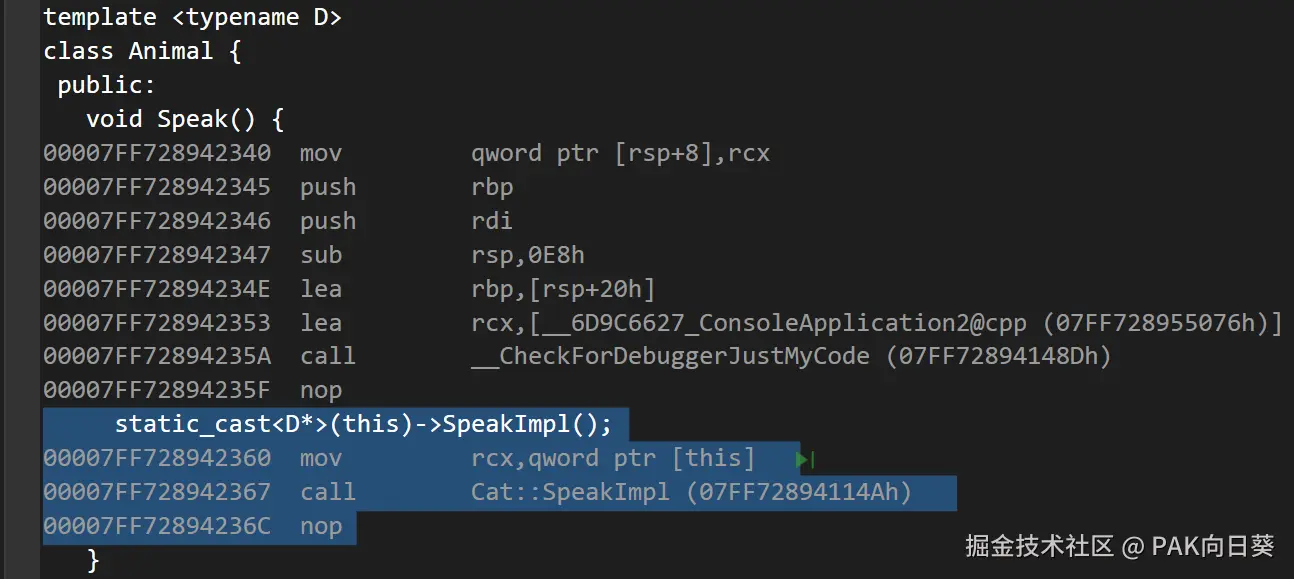
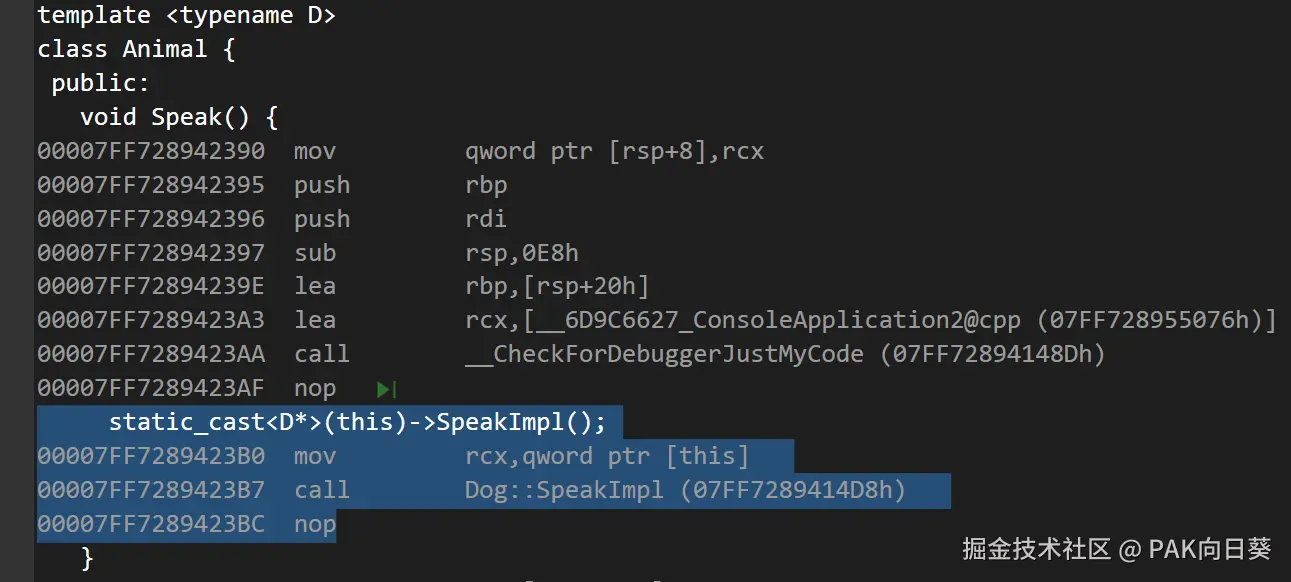
由于 CRTP 写法中代码的行为并不是在运行时才确定的,因此编译器在 release 模式下可以很容易地直接对 dog->Speak() 和 cat->Speak() 这两处操作进行内联展开:
2. 为啥 CRTP 的代码可以通过编译
初学 CRTP 时,很多同学会有一个疑问:
C++
class Cat : public Animal<Cat> {
...
};在这个地方,类Cat还没完成定义,为什么就可以让它直接依赖Animal<Cat>呢?
首先,这些同学的困惑并不是没有道理的:在编译器眼中,类在定义完成之前,是一个不完整类型(Incomplete Type)。
然而需要指出的是,对于不完整类型,你不能用它来声明变量、不能求它的 sizeof、也不能访问它的成员,但是,你可以定义指向它的指针或引用,也可以把它当作模板参数传进去。
编译器在处理这个地方的代码时,大致发生了如下的事情:
- 编译器看到了
class Cat,此时Cat这个类型的名字就已经注册在案了。 - 编译器接着看到
Animal<Cat>,于是试图去实例化Animal<Cat>这个类。 - 编译器回头去看
Animal模板的定义,发现Animal内部:- 没有定义
Cat的成员变量(不需要知道Cat的大小)。 - 没有调用
Cat的构造/析构函数。 - 唯一用到
Cat的地方是Cat*(指针)。
- 没有定义
在特定的系统架构下,任何指针的大小都是固定的(例如 64 位系统下是 8 字节)。编译器不需要知道 Derived 里面有什么,就能轻松算出来 Animal<Cat> 的大小和内存布局。
因此,编译器愉快地完成了 Animal<Cat> 的实例化,并将其作为 Cat 的基类。
另外,可能还会有同学进一步追问下面的这个问题:
C++
template <typename D>
class Animal {
public:
void Speak() {
static_cast<D*>(this)->SpeakImpl();
}
};在编译器实例化Animal<Cat>时,Animal<Cat> 里明明用了 Cat 的方法(Cat::SpeakImpl()),但这个时候类Cat明明还未完成定义(换句话说,编译器压根不知道是否存在Cat::SpeakImpl()方法),为什么编译器不会停下来报错?
这就是 C++ 模板的 懒惰特性(Lazy) 和 两阶段查找(Two-Phase Lookup) 在起作用了
- 第一阶段(模板定义时): 编译器看到
Animal模板,由于D是一个未知的模板参数,编译器只做最基础的语法检查(比如括号有没有闭合、分号有没有漏掉)。它现在不会,也没办法去检查D内部有没有SpeakImpl()函数。 - 第二阶段(模板函数实例化时):C++ 模板的成员函数只有在被调用时才会进行实例化 。如果你仅仅是定义了
Animal和Cat这两个类,从来没有调用过Animal<Cat>::Speak(),编译器甚至永远都不会去生成Animal<Cat>::Speak()内部的代码。
当你真正去调用它时:
C++
auto* cat = new Cat();
cat->Speak(); // 编译器看到有代码调用 Animal<Cat>::Speak(),此时才会被动进行这个函数的实例化在这个时间点,Cat 类的整个大括号已经闭合,它的定义已经彻底完整了。编译器回头一查,发现 Cat 确实有 Speak() 函数,于是编译通过!
3. CRTP 的局限性
由于 CRTP 的类型关系在编译期确定,因此不适合需要运行时动态分派的场景。
比如下面这个例子:
C++
void LetAllAnimalsSpeak(const std::vector<Animal*>& animals) {
for (const auto& animal : animals) {
animal->Speak();
}
}
int main() {
std::vector<Animal*> animals;
animals.emplace_back(new Dog());
animals.emplace_back(new Cat());
LetAllAnimalsSpeak(animals);
}由于在编译阶段我们只知道 LetAllAnimalsSpeak() 接收到的对象都是 Animal 的派生类,因此其中的 animal->Speak() 操作只能在运行时通过基于虚函数的多态动态完成派发。这种场景下 CRTP 就没有用武之地了。
4. CRTP 在工业级项目中的实践
4.1. Chromium base::RefCounted<T>:侵入式引用计数
这是 Chromium 里非常经典的 CRTP 用法。
典型写法:
C++
class MyFoo : public base::RefCounted<MyFoo> {
private:
friend class base::RefCounted<MyFoo>;
~MyFoo();
};Chromium 的 RefCounted<T> 文档示例正是这种形式,并要求析构函数非 public,避免外部在仍有引用时误删对象;同时要求把 base::RefCounted<MyFoo> 声明为 friend,让引用计数归零时由基类负责销毁对象。
核心逻辑大致是:
C++
template <class T>
class RefCounted : public subtle::RefCountedBase {
public:
void AddRef() const {
subtle::RefCountedBase::AddRef();
}
void Release() const {
if (subtle::RefCountedBase::Release()) {
Traits::Destruct(static_cast<const T*>(this));
}
}
};关键点在这里:
C++
static_cast<const T*>(this)Traits::Destruct(static_cast<const T*>(this))这行代码表明,通过传入的模板参数,RefCounted<MyFoo> 在引用数归零时知道真正要删除的是一个 MyFoo 类型的对象。
它解决的问题是:
把引用计数逻辑统一写在基类里,但删除对象时仍然使用派生类的真实类型。
这类 CRTP 的重点不是"多态调用",而是 基类获得派生类类型信息。
4.2. V8 ParserBase<Impl>:Parser / PreParser 共用语法逻辑
V8 的 JavaScript 解析器里有一个非常经典的 CRTP:ParserBase<Impl>:
C++
template <typename Impl>
class ParserBase {
public:
Impl* impl() {
return static_cast<Impl*>(this);
}
const Impl* impl() const {
return static_cast<const Impl*>(this);
}
...
};
class Parser : public ParserBase<Parser> {
friend class ParserBase<Parser>;
...
};
class PreParser : public ParserBase<PreParser> {
friend class ParserBase<PreParser>;
...
};ParserBase 中的 Impl 代表实际的 parser 或 pre-parser 类,遵循 CRTP。
很容易理解,ParserBase 负责"纯解析逻辑",而继承自 ParserBase 的具体实现类负责 AST 生成、早期错误检测、预解析等差异行为。
这意味着 V8 可以把 ECMAScript 语法递归下降解析流程写一份,同时让 Parser 和 PreParser 在编译期替换不同的数据结构和行为。
如果用虚函数做这件事,解析器内部大量小函数调用会产生运行时分派成本,也更难内联。CRTP 让解析器主流程共享,同时让具体行为在编译期确定。
4.3. V8 ElementsAccessorBase<Subclass, Traits>:数组元素访问器优化
这是 V8 里非常"性能导向"的 CRTP。
V8 的 src/elements.cc 中有:
C++
// CRTP to guarantee aggressive compile time optimizations (i.e. inlining and
// specialization of SomeElementsAccessor methods).
template <typename Subclass, typename ElementsTraitsParam>
class ElementsAccessorBase : public ElementsAccessor {
// ...
};这里的源码注释明确说:此处的 CRTP 用来保证 aggressive compile-time optimizations,也就是更激进的编译期优化,包括内联和特化具体 SomeElementsAccessor 方法。
V8 中 JavaScript 数组有很多元素种类,例如:
- packed smi elements
- holey smi elements
- packed object elements
- double elements
- dictionary elements
- typed array elements
这些元素类型有大量共同逻辑,但又有局部差异。V8 用 CRTP 写成类似:
C++
class FastPackedSmiElementsAccessor
: public ElementsAccessorBase<
FastPackedSmiElementsAccessor,
ElementsKindTraits<PACKED_SMI_ELEMENTS>> {
// ...
};基类 ElementsAccessorBase<Subclass, ElementsTraitsParam> 的方法中会这样调用子类特化逻辑:
C++
Subclass::HasElementImpl(...);
Subclass::CopyElementsImpl(...);
Subclass::GetImpl(...);
Subclass::SetImpl(...);这个应用非常典型:同一套数组操作框架,针对不同元素布局生成不同机器码,避免虚调用,并让热点路径充分内联。
这比单纯的教学例子更能体现 CRTP 的工业价值。
4.4. LLVM InstVisitor<SubClass, RetTy>
这是 LLVM IR 分析里最经典的 CRTP 之一。
典型写法:
C++
struct CountAllocaVisitor
: public llvm::InstVisitor<CountAllocaVisitor> {
unsigned Count = 0;
void visitAllocaInst(llvm::AllocaInst &AI) {
++Count;
}
};InstVisitor 用于在不同指令类型上执行不同动作,避免用户代码里写大量 cast 和 switch;自定义 visitor 时,需要让自己的类继承 InstVisitor。
它内部的分发核心类似:
C++
#define DELEGATE(CLASS_TO_VISIT) \
return static_cast<SubClass*>(this)-> \
visit##CLASS_TO_VISIT(static_cast<CLASS_TO_VISIT&>(I))也就是说,基类 InstVisitor<SubClass> 根据 LLVM IR 指令类型做统一分发,然后通过 static_cast<SubClass*>(this) 调用用户 visitor 中的 visitXXX。LLVM 源码注释还明确说,这个类设计成模板是为了避免虚函数调用开销,效率接近自己手写 opcode switch。
工程意义:
LLVM IR pass 经常要遍历大量指令,
InstVisitor让用户写出面向类型的访问逻辑,同时保持接近手写 switch 的性能。
4.5. UE TCommands<CommandContextType>:Editor 命令系统
这是 UE Editor 扩展里非常常见的 CRTP。
TCommands是"一组命令的基类",用户通过继承它来定义自己的命令集合。它还提供静态函数 Get()、Register()、Unregister() 等。下面是一个具体的例子:
C++
class FMyEditorCommands
: public TCommands<FMyEditorCommands> {
public:
FMyEditorCommands()
: TCommands<FMyEditorCommands>(
TEXT("MyEditorCommands"),
NSLOCTEXT("Contexts", "MyEditorCommands", "My Editor Commands"),
NAME_None,
FAppStyle::GetAppStyleSetName()) {}
virtual void RegisterCommands() override;
TSharedPtr<FUICommandInfo> MyCommand;
};TCommands<CommandContextType> 的 CRTP 价值在于:基类 TCommands 能为每个具体命令集合维护独立的静态 singleton、注册状态和 binding context。
这类代码通常有这样的接口:
C++
FMyEditorCommands::Register();
const FMyEditorCommands& Commands = FMyEditorCommands::Get();如果不用 CRTP,而是只用普通基类,就很难让 Get() 静态返回"具体命令类"的引用。