文章目录
-
- [一、 启动 Redis 服务](#一、 启动 Redis 服务)
- [二、 安装 Python 依赖包](#二、 安装 Python 依赖包)
- [三、 基础连接方式(非线程池)](#三、 基础连接方式(非线程池))
-
- [1. 踩坑记录:返回值为 `bytes` 类型](#1. 踩坑记录:返回值为
bytes类型) - [2. 解决方案](#2. 解决方案)
-
- [方案一:自动解码(推荐 )](#方案一:自动解码(推荐 ))
- 方案二:手动解码
- [1. 踩坑记录:返回值为 `bytes` 类型](#1. 踩坑记录:返回值为
- [四、 进阶:Redis 连接池(Connection Pool)](#四、 进阶:Redis 连接池(Connection Pool))
-
- [1. 为什么要用连接池?](#1. 为什么要用连接池?)
- [2. 连接池的核心参数与核心原理](#2. 连接池的核心参数与核心原理)
- [3. 连接池的 Python 代码实现](#3. 连接池的 Python 代码实现)
- [五、 总结](#五、 总结)
在高性能的后端开发中,Redis 作为内存数据库被广泛应用。本文将带你从零开始,掌握如何在 Python 中使用 redis-py 库操作 Redis,并深入探讨如何通过连接池(Connection Pool)优化高并发场景下的性能。
一、 启动 Redis 服务
在操作之前,首先确保你的本地或服务器已经安装并启动了 Redis 服务。
bash
# 进入 Redis 安装目录(根据你的实际安装路径调整)
cd /usr/local/bin/
# 指定配置文件并以后台模式/常规模式启动服务
./redis-server ./redis.conf二、 安装 Python 依赖包
Python 操作 Redis 需要安装官方推荐的 redis 库:
bash
pip install redis三、 基础连接方式(非线程池)
最基础的连接方式是每次操作都直接创建一个 Redis 实例。
1. 踩坑记录:返回值为 bytes 类型
当我们使用默认配置连接并读取数据时,会发现返回的数据带有一个 b 前缀(即 bytes 字节流类型),这在业务处理中很不方便。
python
import redis
# 获取redis连接
conn = redis.Redis(host='localhost', port=6379, db=0)
conn.set('name', 'redis缓存技术')
result = conn.get('name')
print(result) # 输出: b'redis\xe7\xbc\x93\xe5\xad\x98\xe6\x8a\x80\xe6\x9c\xaf'2. 解决方案
方案一:自动解码(推荐 )
在实例化 Redis 对象时,传入 decode_responses=True 参数,库会自动帮我们将 bytes 转换为 str。
python
import redis
conn = redis.Redis(
host='localhost',
port=6379,
db=0,
decode_responses=True # 核心参数:自动把 bytes 转成字符串
)
conn.set('name', 'redis缓存技术')
result = conn.get('name')
print(result) # 输出:redis缓存技术方案二:手动解码
如果不修改连接参数,可以在获取到数据后,手动调用 .decode('utf-8')。
python
import redis
conn = redis.Redis(host='localhost', port=6379, db=0)
conn.set('name', 'redis缓存技术')
result = conn.get('name')
# 手动解码
print(result.decode('utf-8')) # 输出:redis缓存技术四、 进阶:Redis 连接池(Connection Pool)
图解
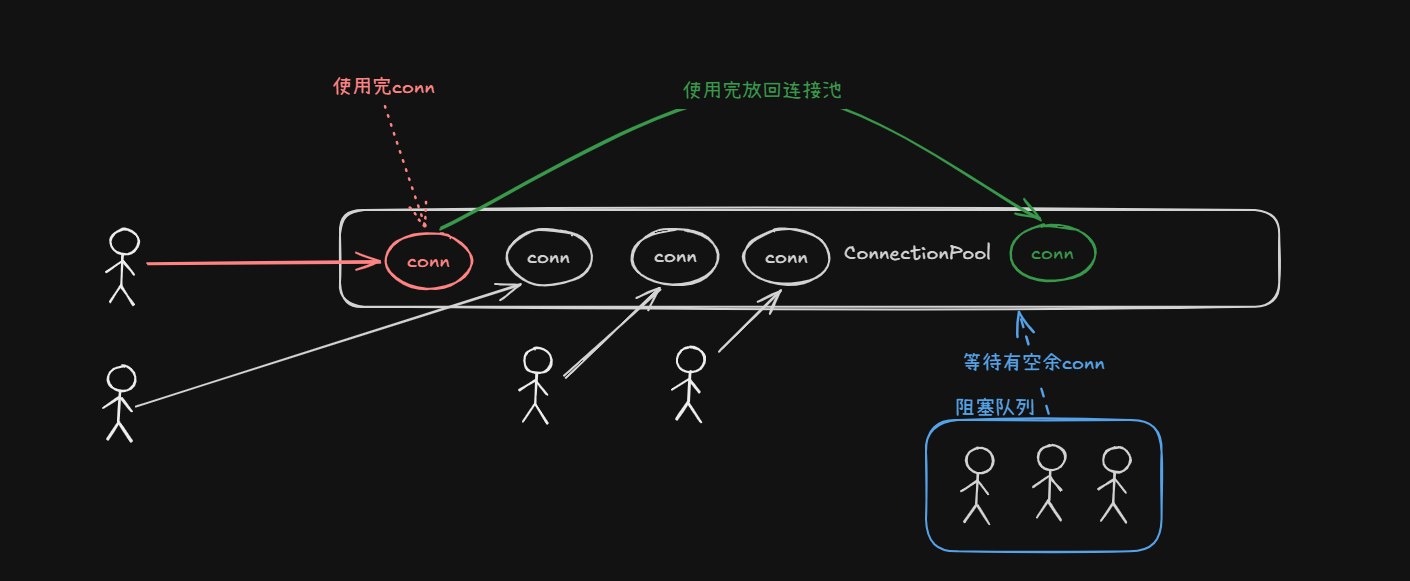
1. 为什么要用连接池?
在非线程池模式下,每次执行命令都会经历"创建连接 -> 发送命令 -> 释放连接"的过程。在高并发场景下,频繁地创建和销毁 TCP 连接会带来巨大的性能开销(如 CPU 占用高、延迟增加)。
连接池的核心作用是"复用":
- 预先创建好一批连接放入"池子"(底层通常由队列实现)。
- 线程需要时,从队列头部获取一个可用连接。
- 命令执行完毕后,连接并不会被真正销毁,而是被放回队列的末尾,供下一个线程复用。
2. 连接池的核心参数与核心原理
在高级连接池的设计中,通常包含两个关键参数:
init_connection(初始化连接数):连接池启动时默认创建的连接数量。max_connections(最大连接数):连接池允许存在的最大连接上限。
滑动窗口与动态增长机制
连接池中的连接数并不是一启动就直接膨胀到最大值的,而是采用动态按比例增长的算法:
- 当并发量低时,保持基础的初始化连接数。
- 当并发量突增,现有连接不够用时,连接池会根据算法动态创建新连接,直到达到
max_connections。 - 阻塞队列机制 :当连接池中的连接已被全部占满(达到最大连接数),后续的线程请求将会进入阻塞队列进行等待,直到有其他线程释放连接放回池中。
3. 连接池的 Python 代码实现
在 redis-py 中,我们需要先创建一个 ConnectionPool,然后将其作为参数传递给 Redis 实例。通常,连接池在全局应该是一个单例。
python
import redis
# 1. 创建全局连接池(内部已实现了线程安全和连接复用)
# max_connections: 限制最大连接数
pool = redis.ConnectionPool(
host='localhost',
port=6379,
db=0,
decode_responses=True,
max_connections=20 # 设置最大连接数
)
# 2. 从连接池中获取连接实例
# 注意:此时的 r 并不是一个单一连接,而是从 pool 中获取连接的代理对象
r = redis.Redis(connection_pool=pool)
# 3. 业务操作
r.set('pool_test', '连接池测试成功')
print(r.get('pool_test')) # 输出:连接池测试成功
# 提示:在 redis-py 中,当命令执行完毕后,内部会自动将连接放回 pool,无需手动 close。五、 总结
| 连接方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 单连接模式 | 简单直观,适合编写简单的测试脚本。 | 高并发下频繁建连销毁,性能损耗大。 | 本地开发、小工具、单线程脚本。 |
| 连接池模式 | 资源复用,避免频繁建连,高并发下性能优异,支持阻塞等待。 | 需要额外维护连接池对象(建议单例模式)。 | 生产环境、Web 后端服务、高并发并发场景。 |
在生产环境中,强烈建议使用连接池模式 ,并开启 decode_responses=True,这样既能保证程序的高性能,又能提升代码的可读性。