PyTorch深度学习实战(55)------在Android上部署PyTorch模型
-
- [0. 前言](#0. 前言)
- [1. 在 Android 上部署 PyTorch 模型](#1. 在 Android 上部署 PyTorch 模型)
- [2. 将 PyTorch 模型转换为适合移动端的格式](#2. 将 PyTorch 模型转换为适合移动端的格式)
- [3. Android 应用开发环境配置](#3. Android 应用开发环境配置)
- [4. 在 Android 应用中调用手机摄像头拍摄图像](#4. 在 Android 应用中调用手机摄像头拍摄图像)
-
- [4.1 应用启动时启用摄像头](#4.1 应用启动时启用摄像头)
- [4.2 Android 摄像头权限处理逻辑](#4.2 Android 摄像头权限处理逻辑)
- [4.3 启用摄像头拍摄功能](#4.3 启用摄像头拍摄功能)
- [4.4 通过手机摄像头获取图像](#4.4 通过手机摄像头获取图像)
- [5. 对摄像头捕获图像运行 ML 模型推理](#5. 对摄像头捕获图像运行 ML 模型推理)
-
- [5.1 验证 ML 模型二进制文件路径](#5.1 验证 ML 模型二进制文件路径)
- [5.2 对摄像头拍摄的图像进行分类](#5.2 对摄像头拍摄的图像进行分类)
- [6. 在 Android 移动设备上启动应用](#6. 在 Android 移动设备上启动应用)
- 小结
- 系列链接
0. 前言
我们已经学习了如何将 PyTorch 模型作为生产系统服务进行部署。虽然将机器学习 (Machine Learning, ML) 模型部署为云端服务仍是最主流的 ML 部署方式,但在以下场景中,我们需要将模型部署到移动设备:
- 用户数据保护:移动端模型直接在数据采集地完成处理,无需第三方数据传输
- 降低延迟:节省云端网络
I/O时间 - 更好的用户体验:相比远程云端模型,移动端模型能以更低延迟实现实时交互
- 利用专用移动端
ML硬件/软件:如CoreML等专用框架
在本节中,我们将学习如何使用 PyTorch Mobile 将 PyTorch 模型部署到移动设备上。PyTorch Mobile 是专为移动和嵌入式平台设计的 PyTorch 子集,支持开发者在智能手机、平板电脑和物联网设备等边缘设备上运行 PyTorch 模型。其底层技术通过优化模型执行和内存使用,确保在移动及嵌入式硬件上实现高效快速的性能表现。
需要注意的是,在移动设备上运行机器学习模型面临着许多挑战,例如有限的计算能力、较低的内存容量和严格的能耗限制,与云端解决方案相比,这些限制要求必须对模型进行深度优化和轻量化架构改造。因此,针对设备端性能优化模型对保证应用响应速度和可持续性至关重要。
我们将使用 PyTorch Mobile 优化MNIST 手写数字识别模型,并将优化后的模型部署到 Android 系统上。在此过程中,我们还将学习如何在 Android 上构建基于摄像头的应用程序,该应用能够拍摄手写数字图像,并使用 PyTorch 模型进行实时预测。
1. 在 Android 上部署 PyTorch 模型
在本节中,我们将开发一个 Android 应用程序,该程序能够通过手机摄像头拍摄图像并对拍摄的图像进行预测(图像分类)。在之前的学习中,我们已经训练了一个MNIST 手写数字识别模型,并通过模型追踪方法将训练好的 MNIST 模型从原始 PyTorch 格式转换为中间表示格式。针对这个 Android 应用,我们将首先使用 PyTorch Mobile 对这个追踪后的 MNIST 模型进行优化,然后使用优化后的模型对拍摄的图像进行预测(手写数字分类)。
2. 将 PyTorch 模型转换为适合移动端的格式
PyTorch Mobile 提供了一个 optimize_for_mobile 函数,能够将追踪后的 PyTorch 模型对象转换为适合移动端的轻量级格式:
python
import torch
from torch.utils.mobile_optimizer import optimize_for_mobile
traced_model = torch.jit.load('./traced_convnet.pt')
optimized_traced_model = optimize_for_mobile(traced_model)
optimized_traced_model._save_for_lite_interpreter("./app/src/main/assets/optimized_for_mobile_traced_model.pt")上述代码首先加载追踪后的 PyTorch 模型,将其转换为移动端优化模型,并将优化后的模型保存至 assets 文件夹中。我们的 Android 应用将加载这个优化模型,对摄像头拍摄的图像进行预测。
PyTorch 中的 optimize_for_mobile 函数专为提升移动设备上的 ML 模型性能而设计。它通过一系列优化(例如减少模型大小、改善内存使用和提高执行速度)来实现这一目标,方法包括操作融合 (operation fusion) 和冗余组件剪枝等。这些优化确保模型能在移动设备有限的硬件资源上高效运行。接下来,我们开始构建 Android 应用。
3. Android 应用开发环境配置
为了构建 Android 应用,我们需要下载 Android Studio。Android Studio 是官方的 Android 应用集成开发环境 (Integrated Development Environment, IDE),由 Google 开发,具有强大且用户友好的界面。Android Studio 提供了用于设计、编码、测试和调试 Android 应用的工具和功能。
在 Android Studio 中,我们需要使用 Android 文件夹作为项目路径新建工程。需要注意的是,Android SDK 需要 Java,因此需要安装 Java 开发工具包 (Java Development Kit, JDK)。
项目名称使用 MNISTApp。这个名称是通过 settings.gradle 文件配置的,该文件包含以下代码:
shell
include ':app'
rootProject.name='MNISTApp'上述配置代码主要实现两个功能:定义 Android 应用(或项目)的名称,指定位于 app 文件夹内的 Android 应用源代码路径。
Gradle 是一个开源的构建自动化工具,用于构建、自动化和管理软件项目的构建过程。它在 Java 和 Android 开发社区中广受欢迎,同时它也可以用于构建其他编程语言的项目。
build.gradle 文件作为构建脚本(类似 MakeFile),包含了应用程序的所有构建指令。文件内容如下:
shell
apply plugin: 'com.android.application'
android {
compileSdkVersion 28
buildToolsVersion "29.0.2"
defaultConfig {
applicationId "org.pytorch.mnist"
minSdkVersion 21
targetSdkVersion 28
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
}
}
}
dependencies {
implementation 'androidx.appcompat:appcompat:1.1.0'
implementation 'org.pytorch:pytorch_android_lite:1.12.2'
implementation 'org.pytorch:pytorch_android_torchvision_lite:1.12.2'
}如上所示,文件中包含了各种配置信息,如 Android 应用的名称和版本,最小支持的 SDK 版本( API 级别)和目标 SDK 版本,以及不同的依赖项(应用程序运行所需的库)。可以看到,PyTorch Android 被列为依赖项之一(与 AndroidX 并列)。其中 org.pytorch:pytorch_android_lite 是主要的 PyTorch Android API 依赖项,包含了适用于 Android 的 libtorch 原生库;而 org.pytorch:pytorch_android_torchvision 则提供了将 Android 应用程序捕获的图像( android.media.Image 和 android.graphics.Bitmap 等格式)转换为张量的功能。
AndroidX 是一个开源的 Android 软件库和开发平台,提供了一套库、工具和架构组件,旨在简化 Android 应用开发。它是 Android Support Library 的现代替代品,具有多项增强功能和额外特性。
优化后的 MNIST 模型文件放置在 assets 文件夹下。虽然我们已经有了机器学习模型,但仍需要构建以下两个组件来完成 Android 应用程序:
- 相机拍摄功能
- 利用拍摄的图像进行
ML模型推理
在讨论如何对拍摄的图像运行模型推理之前,我们将介绍如何使我们的应用能够使用手机摄像头拍摄图像,并渲染所拍摄的图像以供后续使用。
4. 在 Android 应用中调用手机摄像头拍摄图像
当我们构建一个 Android 应用时,需要决定我们的应用需要访问手机硬件和软件的哪些方开发 Android 应用时,我们需要明确应用需要访问手机的哪些硬件和软件功能。在编写任何应用代码之前,首先需要在位于 app/src/main/ 子目录下的 AndroidManifest.xml 文件中声明这些访问权限。我们的清单文件配置如下:
xml
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="org.pytorch.mnist">
<application
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/AppTheme">
<activity android:name=".MainActivity">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
<uses-permission android:name="android.permission.CAMERA" />
<uses-feature android:name="android.hardware.camera" />
<uses-feature android:name="android.hardware.camera.autofocus" />
</manifest>在文件开头部分,我们声明了 Android 应用的名称和版本信息;而在文件末尾处,我们申请了使本应用正常运行所需的摄像头访问权限。除权限声明外,文件还标明了应用需要调用的额外手机功能------在本节中,即手机摄像头及其自动对焦功能。
完成清单文件的权限设置后,接下来我们需要处理 Android 应用源代码的主文件------MainActivity.java。该文件位于 src/main/java/org/pytorch/mnist 目录下,其包含的所有逻辑代码都在 MainActivity 类中运行,如下所示:
java
package org.pytorch.mnist;
import android.content.Context;
import android.Manifest;
import android.content.Intent;
import android.content.pm.PackageManager;
import android.graphics.Bitmap;
import android.os.Bundle;
import android.provider.MediaStore;
import android.util.Log;
import android.widget.ImageView;
import android.widget.TextView;
import androidx.annotation.NonNull;
import androidx.appcompat.app.AppCompatActivity;
import androidx.core.app.ActivityCompat;
import androidx.core.content.ContextCompat;
import org.pytorch.IValue;
import org.pytorch.LiteModuleLoader;
import org.pytorch.Module;
import org.pytorch.Tensor;
import org.pytorch.torchvision.TensorImageUtils;
import org.pytorch.MemoryFormat;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import android.widget.Button;
import android.view.View;
import android.widget.Toast;
public class MainActivity extends AppCompatActivity {
private static final int CAMERA_PERMISSION_CODE = 101;
private static final int CAMERA_REQUEST_CODE = 10;
private Module module;
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
// ...
}
@Override
protected void onCreate(Bundle savedInstanceState) {
// ...
}
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
// ...
}
private void openCamera() {
// ...
}
private void processImage(Bitmap bitmap) {
// ...
}
// Helper method to get asset file path
private String assetFilePath(Context context, String assetName) throws IOException {
// ...
}
}代码起始部分首先声明了应用包名 (package),随后导入了必要的依赖模块(如 android.content.Context 和 android.Manifest)。接着定义了 MainActivity 类,该类会先初始化若干常量,再通过一系列方法实现 Android 应用的核心功能。接下来,我们将重点解析与摄像头拍摄功能相关的关键方法。
4.1 应用启动时启用摄像头
当应用启动时,我们需要检测是否已获取手机摄像头的访问权限。若权限已获取,应用将直接开启摄像头并立即显示图像拍摄界面(如 onCreate 方法所示):
java
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// Check for camera permission
if (ContextCompat.checkSelfPermission(this, Manifest.permission.CAMERA) != PackageManager.PERMISSION_GRANTED) {
ActivityCompat.requestPermissions(this, new String[]{Manifest.permission.CAMERA}, CAMERA_PERMISSION_CODE);
} else {
openCamera();
}
}若应用未获得摄像头访问权限,上述方法会向用户发起权限申请(如下图所示)。
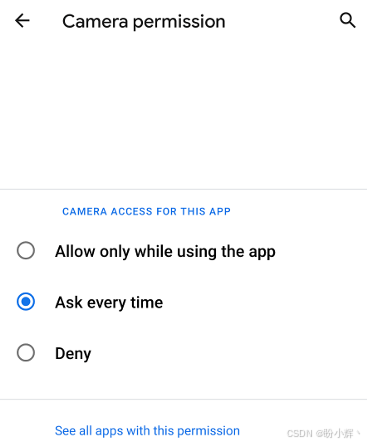
如果用户在使用应用时允许调用摄像头,则下次启动应用时不会再次弹出该权限请求窗口。但若用户选择"每次询问"选项,则每次启动应用时都会显示此弹窗。而如果用户选择"拒绝",应用将无法正常运行,并显示"无法连接摄像头"等错误提示。接下来我们将分析代码中另一个关键方法,该方法用于处理用户对上图所示权限弹窗的响应。
4.2 Android 摄像头权限处理逻辑
当用户做出如上图所示的权限选择后,我们需要通过 onRequestPermissionsResult 方法处理用户响应:
java
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions, @NonNull int[] grantResults) {
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
if (requestCode == CAMERA_PERMISSION_CODE) {
if (grantResults.length > 0 && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
openCamera();
} else {
// Permission denied, handle accordingly
Toast.makeText(this, "Camera permission denied. Cannot open the camera.", Toast.LENGTH_SHORT).show();
}
}
}当用户授予摄像头访问权限时,我们会立即启动摄像头;反之则向用户显示"无法开启摄像头"的错误提示。
4.3 启用摄像头拍摄功能
当应用确认已获取手机摄像头权限后,将通过以下方法启动应用内摄像模块以实现图像拍摄功能:
java
private void openCamera() {
Intent cameraIntent = new Intent(MediaStore.ACTION_IMAGE_CAPTURE);
if (cameraIntent.resolveActivity(getPackageManager()) != null) {
startActivityForResult(cameraIntent, CAMERA_REQUEST_CODE);
}
}拍摄界面如下图所示:

图像捕获界面允许用户拍摄一张图片,并将其传递给 ML 模型进行推理。如上图所示,当摄像头对准手写数字时,拍摄后的图像将由 MNIST 手写数字识别模型进行分析处理。接下来,我们将解析代码中最后一个与摄像头相关的方法,该方法处理用户在图像拍摄界面点击拍照后的情况。
4.4 通过手机摄像头获取图像
当用户通过上图所示界面拍摄照片后,我们需要将捕获的图像存储为图像对象。在 Android 开发中,该对象即 android.graphics.Bitmap。以下方法负责将摄像头拍摄的图像转换为 Bitmap 对象:
java
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
if (requestCode == CAMERA_REQUEST_CODE && resultCode == RESULT_OK) {
if (data != null && data.getExtras() != null) {
Bitmap capturedBitmap = (Bitmap) data.getExtras().get("data");
if (capturedBitmap != null) {
processImage(capturedBitmap);
}
}
}
}以上代码首先会检测图像采集是否返回了非空数据流。若存在有效数据流,则将其转换为 Bitmap 对象------即 capturedBitmap。最终当该对象非空时,图像将被传入 processImage 方法执行模型推理。下一节我们将详细讨论移动端 ML 模型推理的具体实现。
5. 对摄像头捕获图像运行 ML 模型推理
本节将重点探讨如何在 Android 应用中获取 ML 模型预测结果(假设已通过手机摄像头完成图像采集)。我们需要确保项目代码中正确放置了 ML 模型文件,加载该模型后,最终对捕获图像进行处理以生成模型预测。
5.1 验证 ML 模型二进制文件路径
在深入讨论执行模型推理的 processImage 方法之前,让我们先回溯到应用启动时检查摄像头权限的 onCreate 方法。除了检查摄像头访问权限外,该方法还会确认移动端优化后的 ML 模型二进制文件是否存在于 src/main/assets 文件夹中:
java
@Override
protected void onCreate(Bundle savedInstanceState) {
// ...
try {
module = LiteModuleLoader.load(assetFilePath(this, "optimized_for_mobile_traced_model.pt"));
} catch (IOException e) {
Log.e("MNIST", "Error reading assets", e);
finish();
}
}ML 模型加载到 module 变量中。上述代码使用了一个辅助函数 assetFilePath,该函数同样定义在 MainActivity.java 文件中:
java
// Helper method to get asset file path
private String assetFilePath(Context context, String assetName) throws IOException {
File file = new File(context.getFilesDir(), assetName);
if (!file.exists()) {
try (InputStream is = context.getAssets().open(assetName)) {
try (OutputStream os = new FileOutputStream(file)) {
byte[] buffer = new byte[4 * 1024];
int read;
while ((read = is.read(buffer)) != -1) {
os.write(buffer, 0, read);
}
os.flush();
}
}
}
return file.getAbsolutePath();
}确认 ML 模型已存放在指定路径后,我们便可对手机摄像头捕获的图像进行处理,以获取 MNIST 手写数字识别模型的预测结果。
5.2 对摄像头拍摄的图像进行分类
现在我们将进入 Android 应用源代码中最关键的部分------通过 processImage 方法实现对捕获图像执行 ML 模型预测的功能:
java
private void processImage(Bitmap bitmap) {
// Resize the input image to 28x28 pixels
Bitmap resizedBitmap = Bitmap.createScaledBitmap(bitmap, 28, 28, true);
ImageView imageView = findViewById(R.id.image);
imageView.setImageBitmap(resizedBitmap);
final float[] mean = {0.1302f, 0.1302f, 0.1302f};
final float[] std = {0.3069f, 0.3069f, 0.3069f};
final Tensor inputTensor = TensorImageUtils.bitmapToFloat32Tensor(resizedBitmap, mean, std,
MemoryFormat.CHANNELS_LAST);
final Tensor outputTensor = module.forward(IValue.from(inputTensor)).toTensor();
final float[] scores = outputTensor.getDataAsFloatArray();
// Log the raw scores
Log.d("Raw Scores", "Scores:");
for (int i = 0; i < scores.length; i++) {
Log.d("Raw Scores", "Score[" + i + "]: " + scores[i]);
}
float maxScore = -Float.MAX_VALUE;
int maxScoreIdx = -1;
for (int i = 0; i < scores.length; i++) {
if (scores[i] > maxScore) {
maxScore = scores[i];
maxScoreIdx = i;
}
}
String className = String.valueOf(maxScoreIdx);
TextView textView = findViewById(R.id.text);
textView.setText(className);
// Add "Retake Photo" button logic here
Button retakeButton = findViewById(R.id.retake_button);
retakeButton.setVisibility(View.VISIBLE); // Show the retake button
retakeButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
openCamera(); // Call the openCamera method again to capture a new image
}
});
}该方法包含三个关键环节:
- 将捕获图像(
Bitmap对象)预处理为张量:首先将位图尺寸调整为28×28像素,根据MNIST数据集RGB通道的均值与标准差对像素值进行归一化处理,随后将归一化后的Bitmap对象转换为Float32类型张量 - 对图像张量执行
ML模型推理:将生成的张量输入已加载的ML模型进行推理,模型将输出0至9共10个数字类别的逻辑回归值 (logits)。系统会显示逻辑值最高的数字类别作为图像识别结果,同时记录所有类别的逻辑值用于调试 - 提示用户重拍照片进行再次预测:当模型完成预测后,屏幕底部将弹出重新拍照按钮。用户点击该按钮后,应用将重新启动相机并返回图像拍摄界面
下图展示了从用户拍摄确认图像,到 ML 模型返回数字识别结果,最后应用询问用户是否重拍的完整流程。

在上图最右侧的界面中,当 ML 模型被触发时,类别逻辑值 (logits) 会显示在 Android Studio IDE 底部日志窗口。以数字8的识别为例,日志输出如下所示:
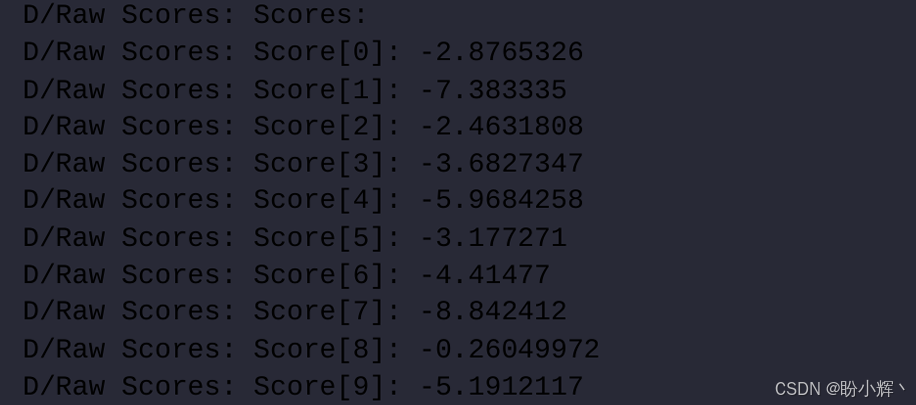
如图所示,数字 8 对应的的 logit 值最高,因此被显示为模型的预测结果。逻辑值越高表示该类别概率越大,反之亦然。
完成对 MainActivity.java 文件中所有必要方法的解析后,我们可以开始在真实设备上实时运行这个应用。
6. 在 Android 移动设备上启动应用
在本节中,我们将在 Android 设备上运行该应用程序。需要通过 USB 数据线将 Android 设备连接到计算机上,并在设备设置中启用"开发者选项"。
当 Android 设备连接成功后,可在 Android Studio 的可用设备下拉菜单中选中目标设备,选择设备后点击运行按钮。
当应用在设备上成功启动后,将看到应用启动界面。若是首次运行该应用,系统可能会弹出摄像头权限请求界面。应用程序启动后,会安装在手机上,即使手机与计算机断开连接也可以访问。
该应用需要摄像头权限,并会在会话期间以缓存形式存储拍摄的图像数据。值得注意的是,该模型能够适应多种色彩组合的识别------无论是黑色墨水、白色墨水、黄色墨水、黑色背景还是白色背景。但在某些边界案例中,模型仍会出现误判。
小结
在本节中,我们首先介绍了 PyTorch Mobile 及其功能------如何将基于追踪的 PyTorch 模型文件转换为可在移动设备上运行的优化模型对象。接着,我们逐步构建了一个 Android 应用,利用 PyTorch Mobile 加载预训练的 MNIST 模型,对手机摄像头拍摄的手写数字图像进行分类。
系列链接
PyTorch深度学习实战(1)------神经网络与模型训练过程详解
PyTorch深度学习实战(2)------PyTorch基础
PyTorch深度学习实战(3)------使用PyTorch构建神经网络
PyTorch深度学习实战(4)------常用激活函数和损失函数详解
PyTorch深度学习实战(6)------神经网络性能优化技术
PyTorch深度学习实战(7)------批大小对神经网络训练的影响
PyTorch深度学习实战(10)------过拟合及其解决方法
PyTorch深度学习实战(13)------可视化神经网络中间层输出
PyTorch深度学习实战(16)------面部关键点检测
PyTorch深度学习实战(19)------从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)------从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)------从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)------从零开始实现YOLO目标检测
PyTorch深度学习实战(23)------从零开始实现SSD目标检测
PyTorch深度学习实战(24)------使用U-Net架构进行图像分割
PyTorch深度学习实战(25)------从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)------多对象实例分割
PyTorch深度学习实战(27)------自编码器(Autoencoder)
PyTorch深度学习实战(28)------卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)------变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)------对抗攻击(Adversarial Attack)
PyTorch深度学习实战(32)------Deepfakes
PyTorch深度学习实战(33)------生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)------DCGAN详解与实现
PyTorch深度学习实战(35)------条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)------Pix2Pix详解与实现
PyTorch深度学习实战(37)------CycleGAN详解与实现
PyTorch深度学习实战(38)------StyleGAN详解与实现
PyTorch深度学习实战(39)------少样本学习(Few-shot Learning)
PyTorch深度学习实战(40)------零样本学习(Zero-Shot Learning)
PyTorch深度学习实战(41)------循环神经网络与长短期记忆网络
PyTorch深度学习实战(44)------基于 DETR 实现目标检测
PyTorch深度学习实战(47)------使用PyTorch构建Transformer模型
PyTorch深度学习实战(48)------基于Transformer实现机器翻译
PyTorch深度学习实战(49)------扩散模型(Diffusion Model)详解与实现
PyTorch深度学习实战(50)------PyTorch分布式训练
PyTorch深度学习实战(51)------自动混合精度训练
PyTorch深度学习实战(52)------PyTorch深度学习模型部署