凌晨两点,某大厂测试组的老张盯着那条又红了的流水线。这个订单创建接口的断言失败了,原因是他半个月前写的那个校验逻辑------后端返回的status字段从数字变成了字符串枚举。他熟练地打开代码,改了四行断言,重新提交。同一个接口,三个月内改了第六次。
他已经开始怀疑自己每天写的到底是自动化脚本,还是一条条永远在维护的"债务"。
不只是他。很多人已经开始感觉到:接口自动化测试这个领域,正在陷入一种低水平的内卷。写得越多,维护越累,覆盖率上去了,缺陷发现率却没怎么动。更让人焦虑的是,身边开始出现一些"怪事":隔壁组的AI编程助手半小时生成了300条用例,新人用自然语言描述一下业务场景,工具就自动跑完了全流程。
有人说是AI要取代测试了。但一线干过的人都明白,问题根本不是AI能不能写代码,而是------我们至今没有教会机器"这个接口到底该怎么测"。
目录
一、脚本堆积不等于测试能力
二、从"执行指令"到"理解意图"
三、让AI学会"如何测":三层机制拆解
四、一个真实的对比:登录接口的两种写法
五、工程落地:你的框架还差哪一环
六、一个留给你的问题
一、脚本堆积不等于测试能力
先看一个现象。大部分团队的接口自动化现状是这样:
-
每个接口对应一套脚本,脚本里塞满了硬编码的断言、写死的测试数据、复杂的JSONPath取值
-
业务一改,脚本跟着改。改完还不算,上下游依赖的调用链也要同步修
-
新人接手一个老模块,光是理解那些散落在几十个文件里的前置条件,就需要两周
这不是自动化,这是另一种形式的手工测试------只是把手工点鼠标换成了手工维护代码。
本质问题是什么?是我们一直在教机器"这一步做什么,下一步做什么",但从来没有告诉它"这个接口的正确性意味着什么"。脚本记录的是动作序列,而测试需要的是一套可推理的判断逻辑。
当业务快速迭代、接口语义发生变化时,纯脚本体系必然崩盘。因为你维护的是动作,不是意图。
二、从"执行指令"到"理解意图"
这个变化的核心,是测试范式的转换。
传统脚本模式下,测试工程师的角色是"翻译官"------把业务需求翻译成机器可执行的步骤序列。接口的入参是什么、预期返回值是什么、先调A再调B,全部写死。
AI参与的Skills模式下,工程师的角色变成了"定义规则和边界"------告诉AI这个接口的契约是什么、哪些字段有约束、业务规则有哪些例外,然后让AI自己组合出合适的测试行为。
这两者的差异,本质上是编程范式从"命令式"向"声明式"的迁移。就像SQL让你声明查询结果而不是遍历过程,AI测试Skills让你声明校验逻辑而不是每一条请求。
观点句:测试工程师的价值不再是你写了多少行脚本,而是你定义了多少个"如何测"的规则。
这个转变解决了一个长期被忽视的问题:测试知识的沉淀。脚本只能沉淀动作,而Skills可以沉淀业务规则、数据约束、异常场景的分类方法。这些才是真正的测试资产。
三、让AI学会"如何测":三层机制拆解
一线落地的时候,不能把AI当黑盒。我们需要搞清楚,一个能理解"如何测"的AI系统,内部是怎么运转的。
下面是三层核心机制:
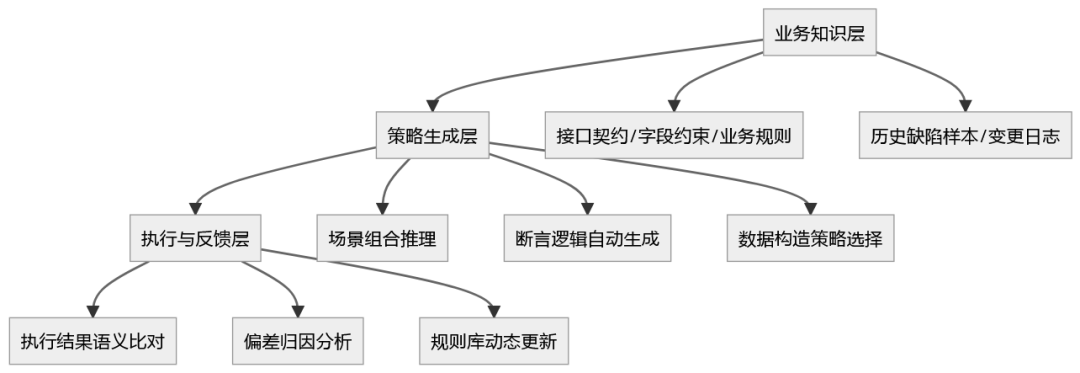
第一层:业务知识层。这不是传统的接口文档,而是把接口的约束条件、字段间的依赖关系、业务状态机的转换规则,用一种AI可理解的结构化方式存储。比如"订单金额大于0"、"优惠券只能在支付前使用",这些不是写在断言里的字符串,而是作为元数据被管理。
第二层:策略生成层。AI拿到一个测试任务,不是去翻脚本库,而是基于业务知识层的信息,动态推理出需要覆盖哪些场景。正向流程怎么走、边界值怎么选、异常情况怎么构造,全部由AI根据规则实时组合。这意味着你新增一个接口,只要补充好知识层的描述,测试场景自动生成。
第三层:执行与反馈层。这是最容易被忽视的一环。传统测试只管"过"或"没过",而Skill系统会把失败结果反向传播回知识层。比如断言失败不是因为代码bug,而是接口契约本身发生了变化,系统会标记出对应的字段约束需要更新。
这个闭环才是核心。AI不是在执行你给的死命令,而是在每一次运行中修正自己对"如何测"的理解。
观点句:不是AI在测,是你定义的那套"测法"在运行,AI只是执行体。
四、一个真实的对比:登录接口的两种写法
拿一个登录接口来对比,更直观。
传统脚本的做法:
def test_login_success():
body = {"username": "test", "password": "123456"}
resp = requests.post("/login", json=body)
assert resp.status_code == 200
assert resp.json()["code"] == 0
assert "token" in resp.json()["data"]问题很明显:所有断言都是写死的。改一天接口返回结构,改一天密码策略,改一天token格式------脚本跟着改一遍又一遍。
Skills模式的做法,不是写脚本,而是定义一套规则:
接口: /login
契约:
- 请求: username(非空, 长度4-20), password(非空, 长度6-20)
- 成功响应: code=0, data.token存在, token格式为JWT
业务规则:
- 连续错误5次锁定账号5分钟
- 密码错误时不暴露具体字段错误
测试策略:
- 边界: username长度4/20, 21
- 异常: 错误密码连续5次, 第6次验证锁定
- 变更感知: 如果响应中token字段名变更, 自动标记规则过时AI拿到这套规则后,自己能组合出几十个测试场景,并且当接口行为发生变化时,它能判断是代码bug还是规则本身需要更新。
后者维护的不是脚本,是知识。代码只是知识的副产品。
五、工程落地:你的框架还差哪一环
回到现实。大多数团队不可能从零搞一套AI测试系统,但可以在现有框架上逐步补齐能力。三件事可以从下周开始做:
第一,把硬编码断言抽离成规则配置。不要在每个脚本里写assert resp["code"] == 0,用规则引擎或者简单的JSON Schema来描述期望。这一步不需要AI,先把测试意图和数据分离。
第二,建立接口的变更感知机制。你的CI/CD流水线上,每次后端接口变更(比如Swagger更新)应该能自动触发一次规则校验:已有的测试规则是否还匹配新契约?不匹配的地方自动标记出来。
第三,引入LLM做场景补全。不需要复杂训练,用提示词工程就可以。把接口的规则配置丢给LLM,让它生成遗漏的边界场景或异常组合。这是目前投入产出比最高的切入点。
落地过程中最容易被忽视的一点:反馈闭环。很多团队做完前两步就停了,但Skill系统的精髓在于执行结果能不能反向修正规则。建议在测试报告中单独列一个"规则漂移"板块,把那些断言失败但代码逻辑正确的情况归因到规则过期。
观点句:没有反馈闭环的AI测试,只是把脚本换了个写法。
对于中级工程师,这是方法论升级的机会。不必把自己定位成"写脚本的人",而是"定义测试规则的架构师"。你设计的这套规则体系,会被AI反复使用和验证,杠杆效应完全不一样。
对于在校生和初级工程师,现在正是理解这套新范式的好时机。不要只学某个测试框架的API,去理解什么是"测试意图的声明式表达",什么是"可执行的契约"。这些东西五年后会成为基础能力。
六、一个留给你的问题
接口自动化的下一个十年,脚本不会消失,但它的地位会从"主要载体"退化成"AI的输出物之一"。真正的资产是那套让AI学会"如何测"的规则和知识。
回头看你现在维护的测试代码------如果明天所有脚本都被删了,只留下你的测试设计文档和业务规则,你能在多长时间里让AI重新生成出一套可用的测试集?
你现在的系统,具备反馈闭环吗?