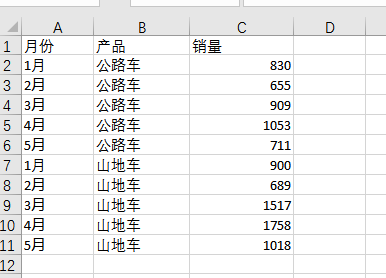
Dify Workflow 与 Chatflow 的核心区别
Workflow -- 一次返回结果
Chatflow -- 支持多次对话,多次返回结果
| 维度 | Chatflow | Workflow |
|---|---|---|
| 定位 | 对话式应用(如客服、问答助手) | 自动化批处理 / 数据处理流程 |
| 交互方式 | 用户 ↔ AI 多轮对话 | 触发式执行(API、定时、webhook) |
| 是否保留上下文 | ✅ 支持对话记忆(会话级) | ❌ 每次运行独立,无会话历史 |
| 输入输出 | 用户问题 + 可选变量 → 自然语言回复 | 结构化数据 → 结构化结果 |
| 典型节点 | 意图识别、回复生成、问答检索 | HTTP 请求、代码节点、参数提取、条件分支 |
| 适用场景 | 智能客服、Copilot、教育问答 | 数据清洗、报表生成、内容审核、定时任务 |
更直观的理解
- Chatflow:用户主动发问,AI 像人一样"聊回去",过程中能记住之前说了什么。
- Workflow:更像一个数据处理管道,给它输入,它跑完逻辑返回结果,每次请求都是"失忆"的。
选择建议
- 需要与用户多轮对话 、记住上下文 → 选 Chatflow
- 需要批量处理数据 、API 集成 、无人值守自动化 → 选 Workflow
两者可以配合使用,例如 Workflow 做后台数据处理,再由 Chatflow 提供给用户查询入口。
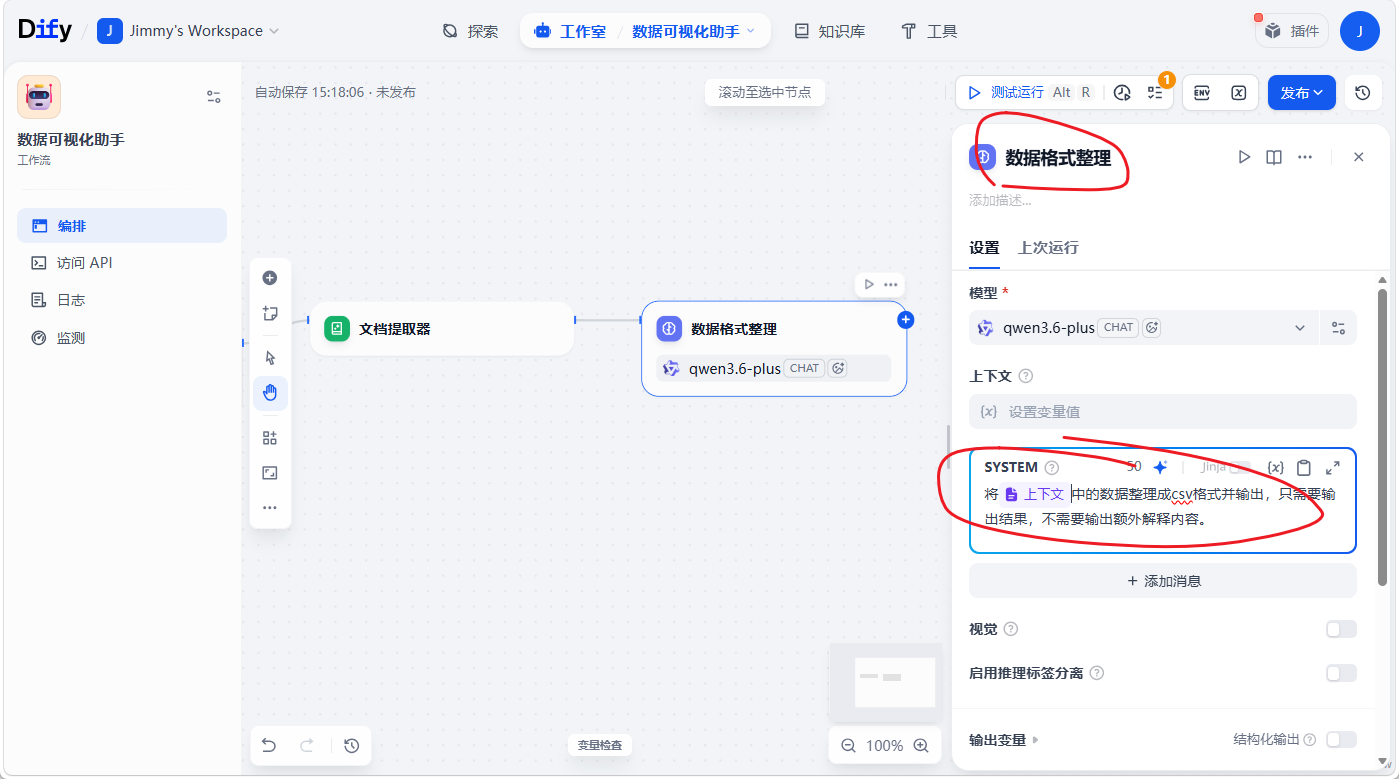
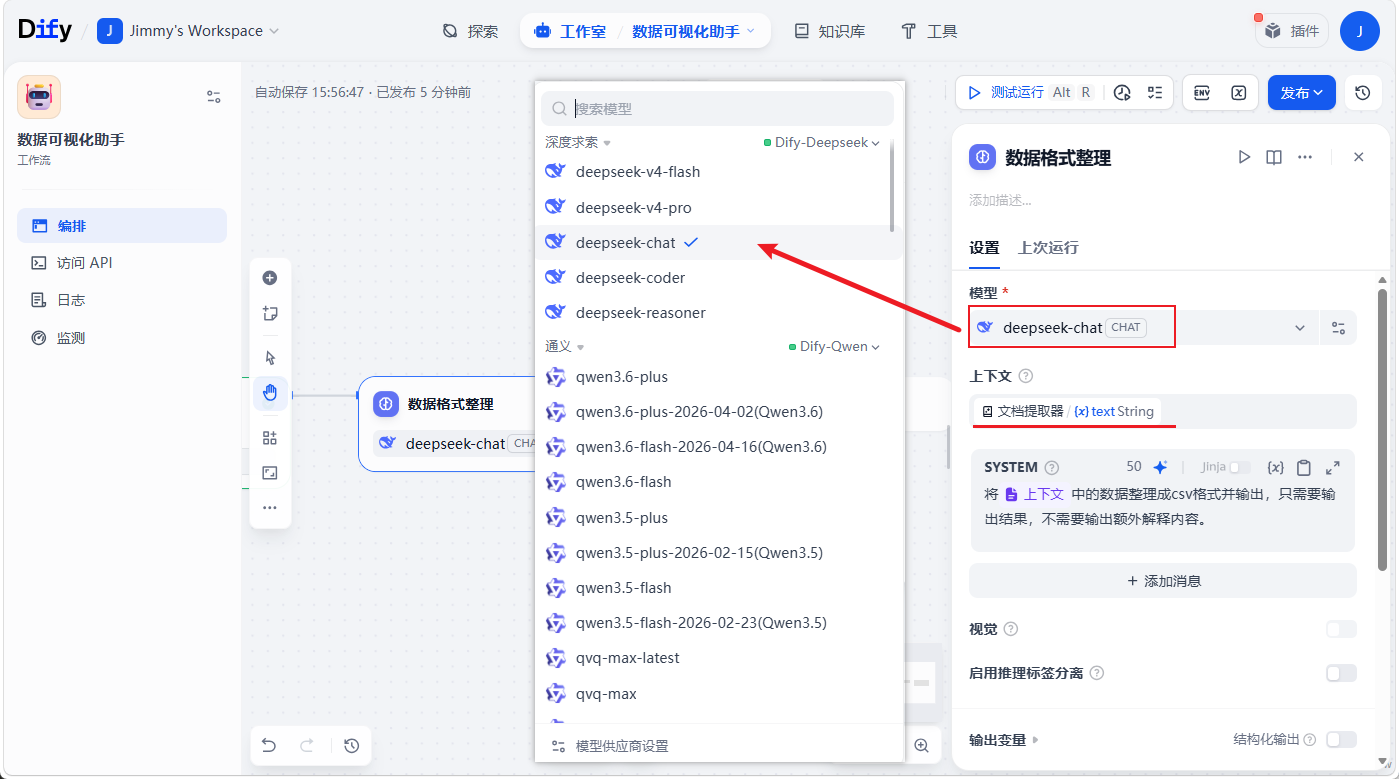
注意点:ECharts(需要CSV),需要LLM 整理数据格式,deepseek-chat 模型对 ECharts 所需的数据处理比较有好,不要直接选用推理模型,费token效果还不好
推理在工具里面应用效果不是很好, 在自己开发大模型的时候,推理比较准确(Langgraph、LangChain.cn、MCP、SpringAI、info.xblzipper.com、hot.xblzipper.com、wenku.xblzipper.comEmbedding...) AI大模型知识体系
比如:我只让大模型给我回复什么内容,赋值到什么样的变量里,自己控制节点A->B->C,A输出的内容,要在B节点用变量来接受,比如 Dify --- Chatflow - 数据库智能查询
创建工作流
创建工作流
添加变量
添加文档提取器
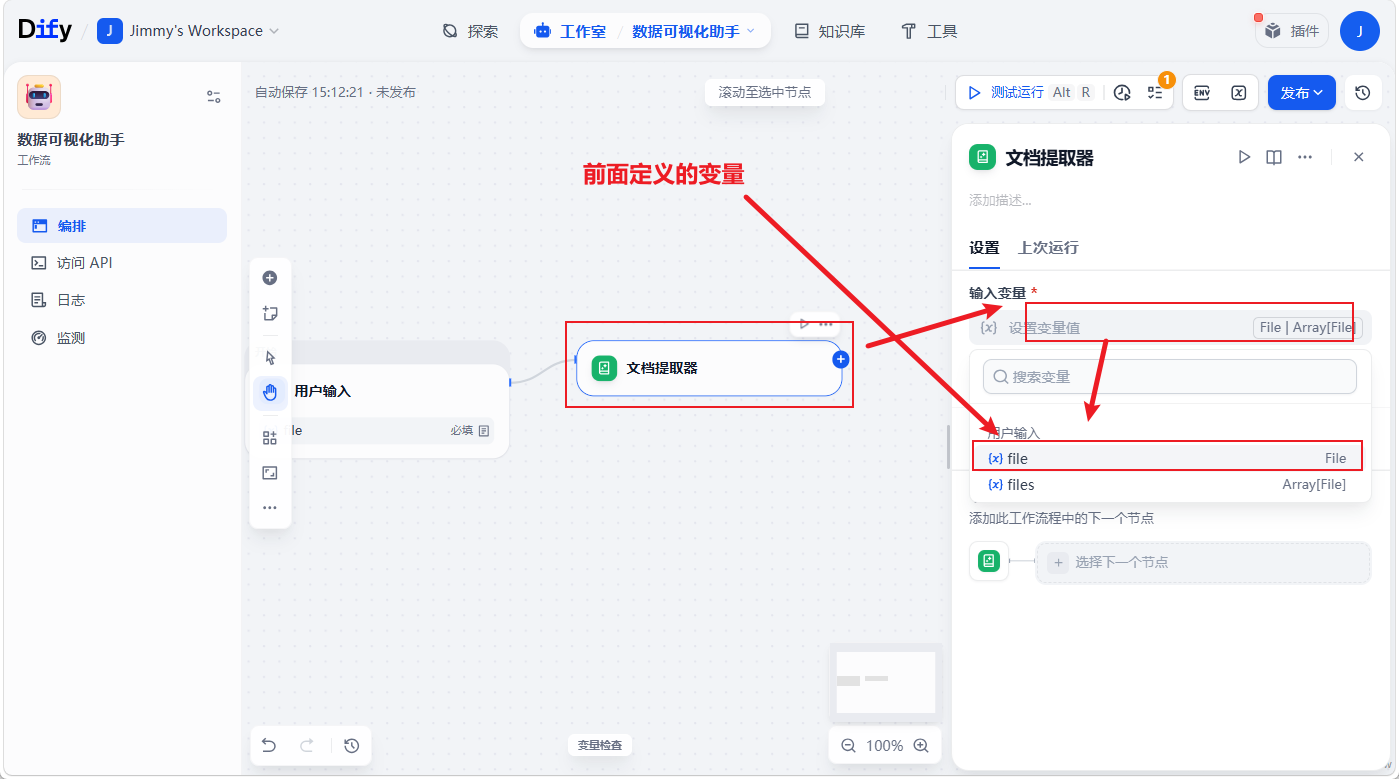
添加大模型
将文件里的数据进行格式整理article.xblzipper.com、feed.xblzipper.com、m
highlighter-hljs
<span style="color:#333333"><span style="background-color:#ffffff"><code class="language-undefined">将{{上下文}}中的数据整理成csv格式并输出,只需要输出结果,不需要输出额外解释内容。
</code></span></span>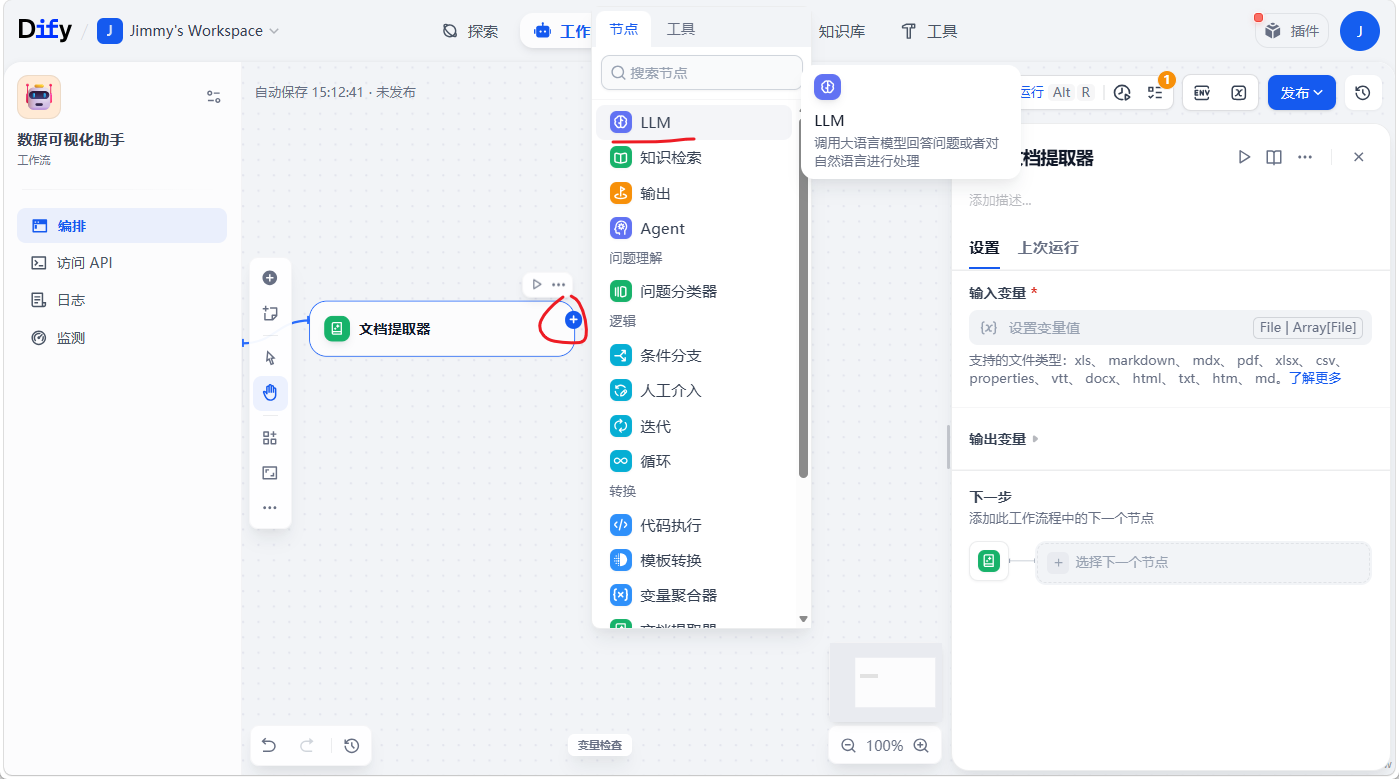
选择 deepseek-chat 模型,mobile.xblzipper.com有助于输入图标
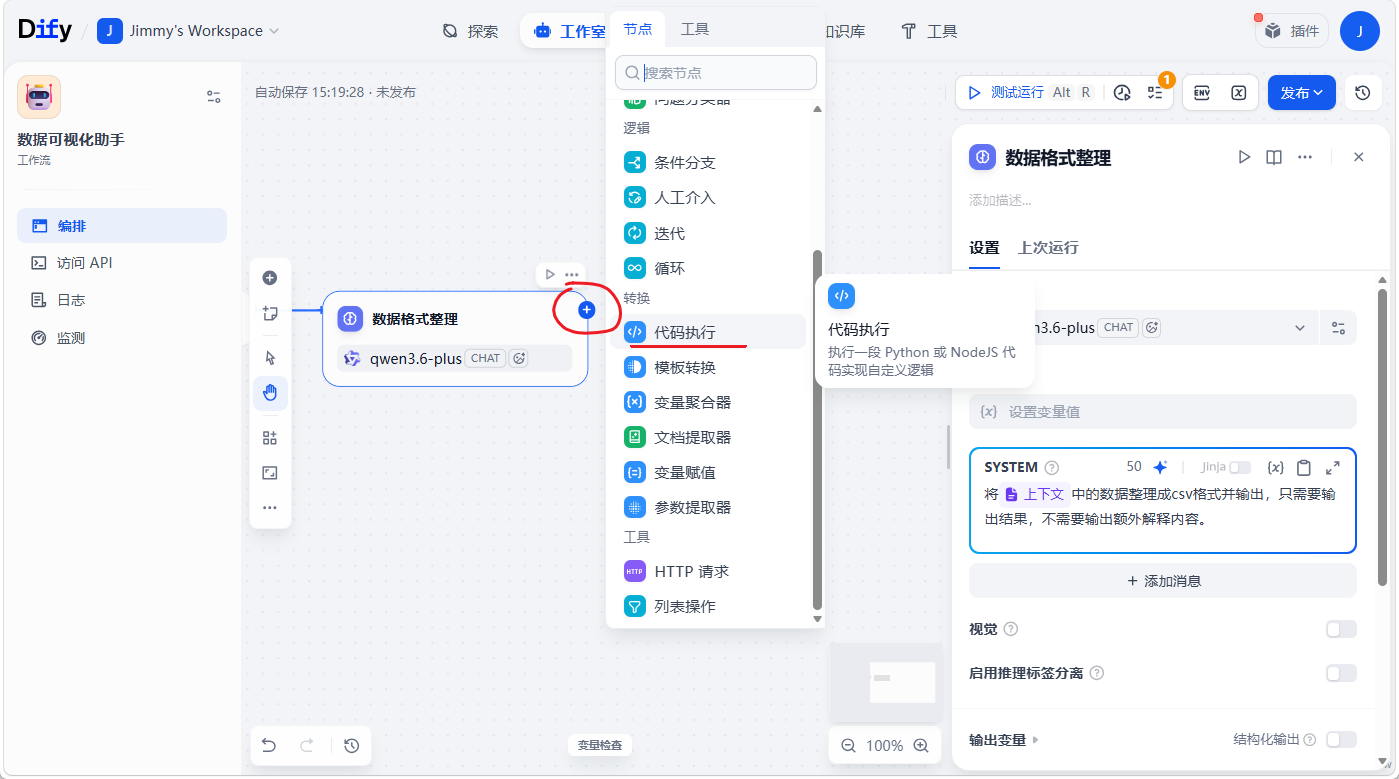
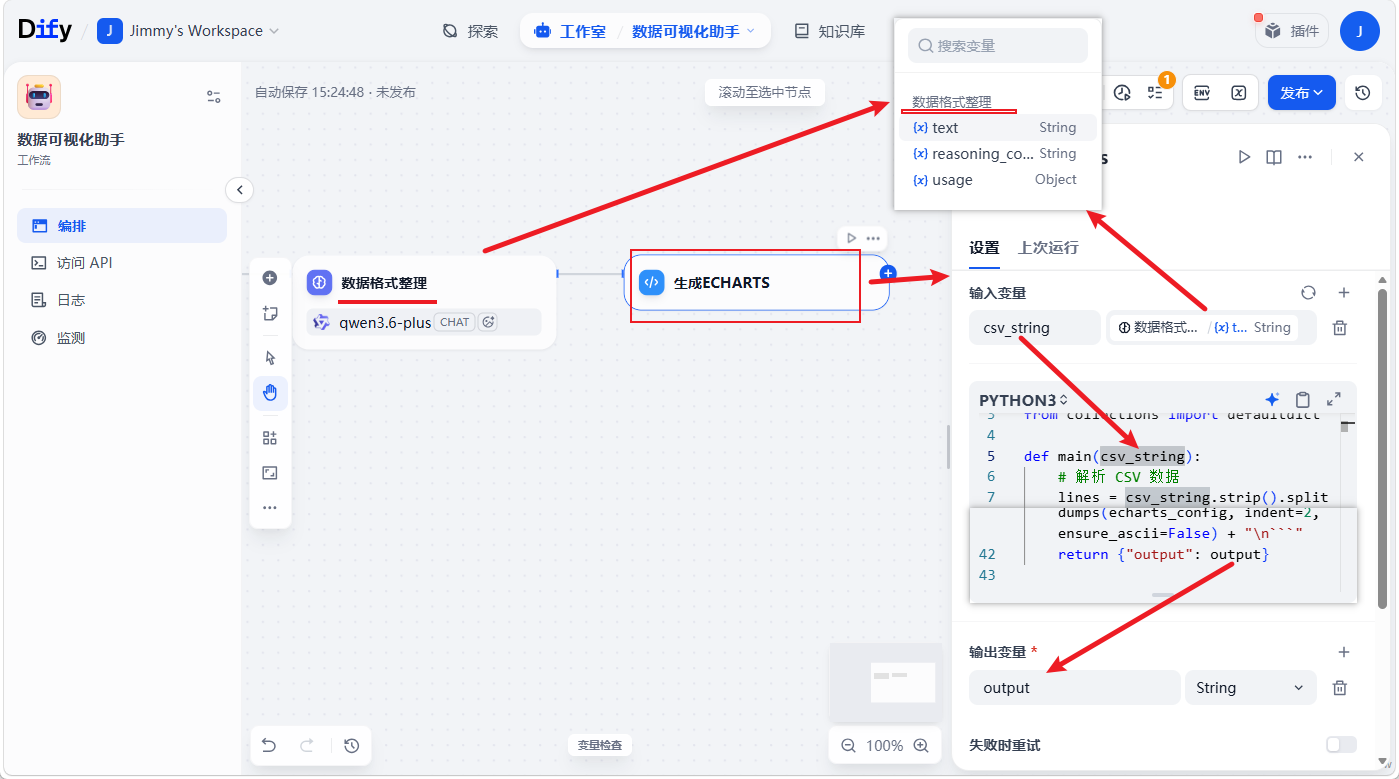
highlighter-hljs
<span style="color:#333333"><span style="background-color:#ffffff"><code class="language-python"><span style="color:#0000ff">import</span> csv
<span style="color:#0000ff">import</span> json
<span style="color:#0000ff">from</span> collections <span style="color:#0000ff">import</span> defaultdict
<span style="color:#0000ff">def</span> <span style="color:#a31515">main</span>(csv_string):
<span style="color:#008000"># 解析 CSV 数据</span>
lines = csv_string.strip().split(<span style="color:#a31515">'\n'</span>)
reader = csv.reader(lines)
headers = <span style="color:#0000ff">next</span>(reader)
data = [row <span style="color:#0000ff">for</span> row <span style="color:#0000ff">in</span> reader]
<span style="color:#008000"># 提取列名</span>
category_col, subcategory_col, value_col = headers
<span style="color:#008000"># 构建数据字典</span>
data_dict = defaultdict(<span style="color:#0000ff">lambda</span>: defaultdict(<span style="color:#0000ff">float</span>))
<span style="color:#0000ff">for</span> row <span style="color:#0000ff">in</span> data:
category, subcategory, value = row
data_dict[category][subcategory] += <span style="color:#0000ff">float</span>(value)
<span style="color:#008000"># 获取所有类别和子类别</span>
categories = <span style="color:#0000ff">list</span>(data_dict.keys())
subcategories = <span style="color:#0000ff">list</span>({subcat <span style="color:#0000ff">for</span> subcats <span style="color:#0000ff">in</span> data_dict.values() <span style="color:#0000ff">for</span> subcat <span style="color:#0000ff">in</span> subcats})
<span style="color:#008000"># 构建 ECharts 配置</span>
echarts_config = {
<span style="color:#a31515">"tooltip"</span>: {<span style="color:#a31515">"trigger"</span>: <span style="color:#a31515">"axis"</span>},
<span style="color:#a31515">"legend"</span>: {<span style="color:#a31515">"data"</span>: subcategories},
<span style="color:#a31515">"xAxis"</span>: {<span style="color:#a31515">"type"</span>: <span style="color:#a31515">"category"</span>, <span style="color:#a31515">"data"</span>: categories},
<span style="color:#a31515">"yAxis"</span>: {<span style="color:#a31515">"type"</span>: <span style="color:#a31515">"value"</span>},
<span style="color:#a31515">"series"</span>: [
{
<span style="color:#a31515">"name"</span>: subcategory,
<span style="color:#a31515">"type"</span>: <span style="color:#a31515">"bar"</span>,
<span style="color:#a31515">"data"</span>: [data_dict[category].get(subcategory, <span style="color:#880000">0</span>) <span style="color:#0000ff">for</span> category <span style="color:#0000ff">in</span> categories]
}
<span style="color:#0000ff">for</span> subcategory <span style="color:#0000ff">in</span> subcategories
]
}
output = <span style="color:#a31515">"\n```echarts\n"</span> + json.dumps(echarts_config, indent=<span style="color:#880000">2</span>, ensure_ascii=<span style="color:#a31515">False</span>) + <span style="color:#a31515">"\n```"</span>
<span style="color:#0000ff">return</span> {<span style="color:#a31515">"output"</span>: output}
</code></span></span>添加结束节点
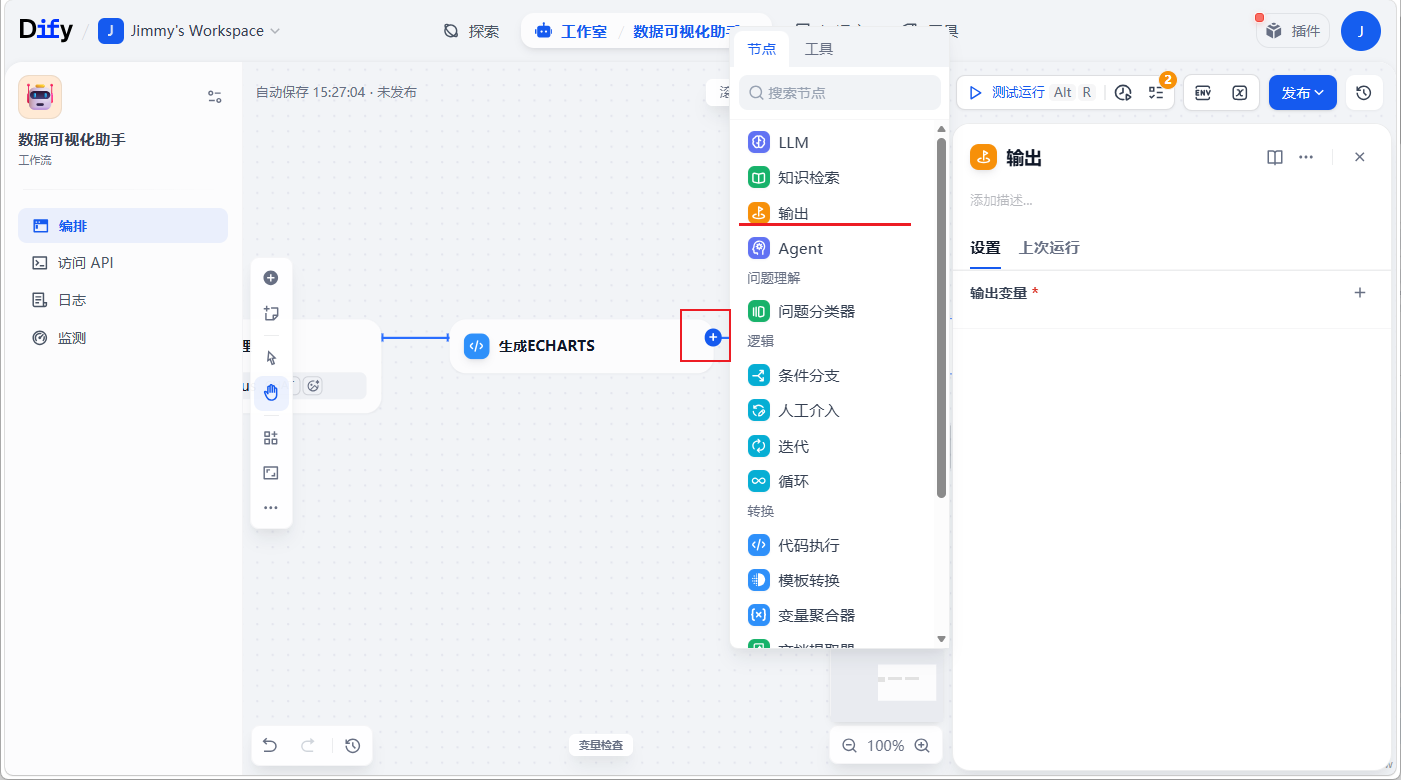
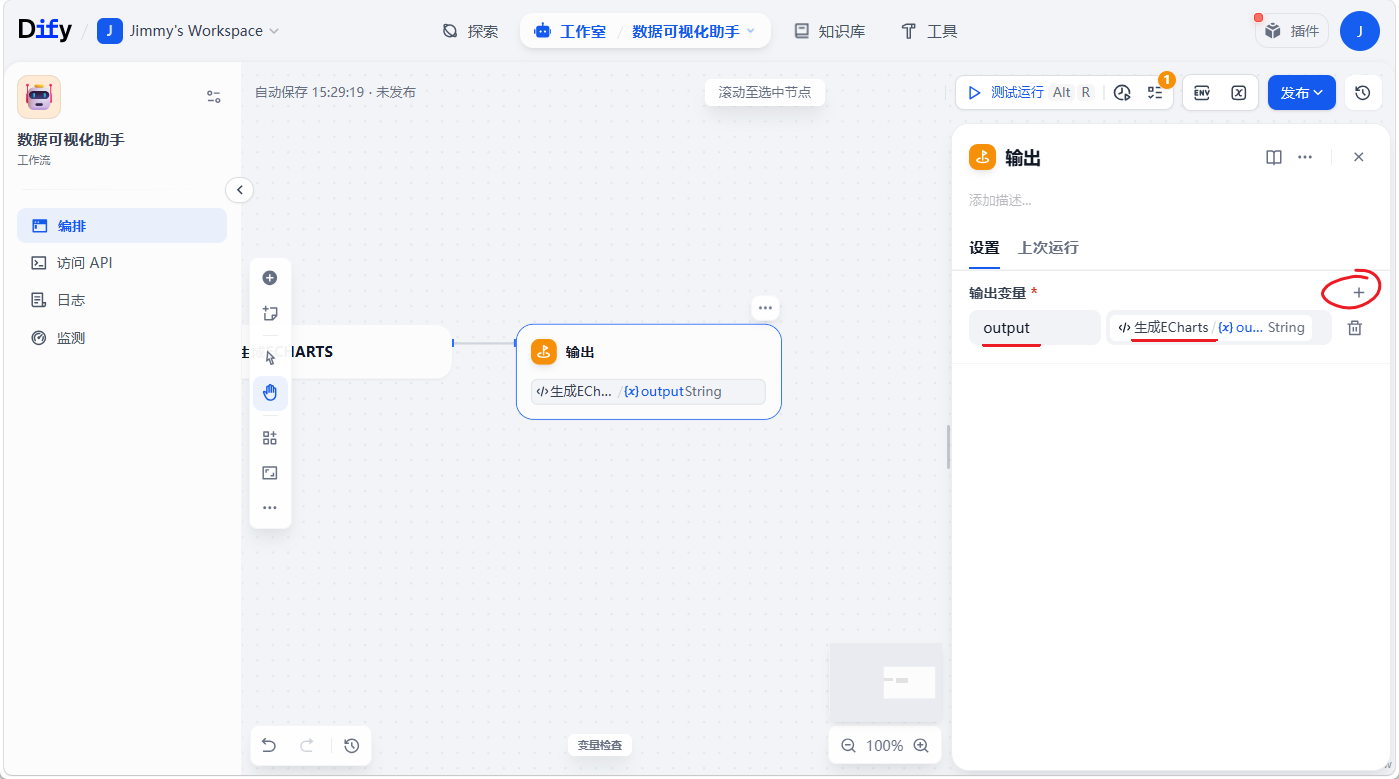
从0打造99.99%在线CRM web.xblzipper.com
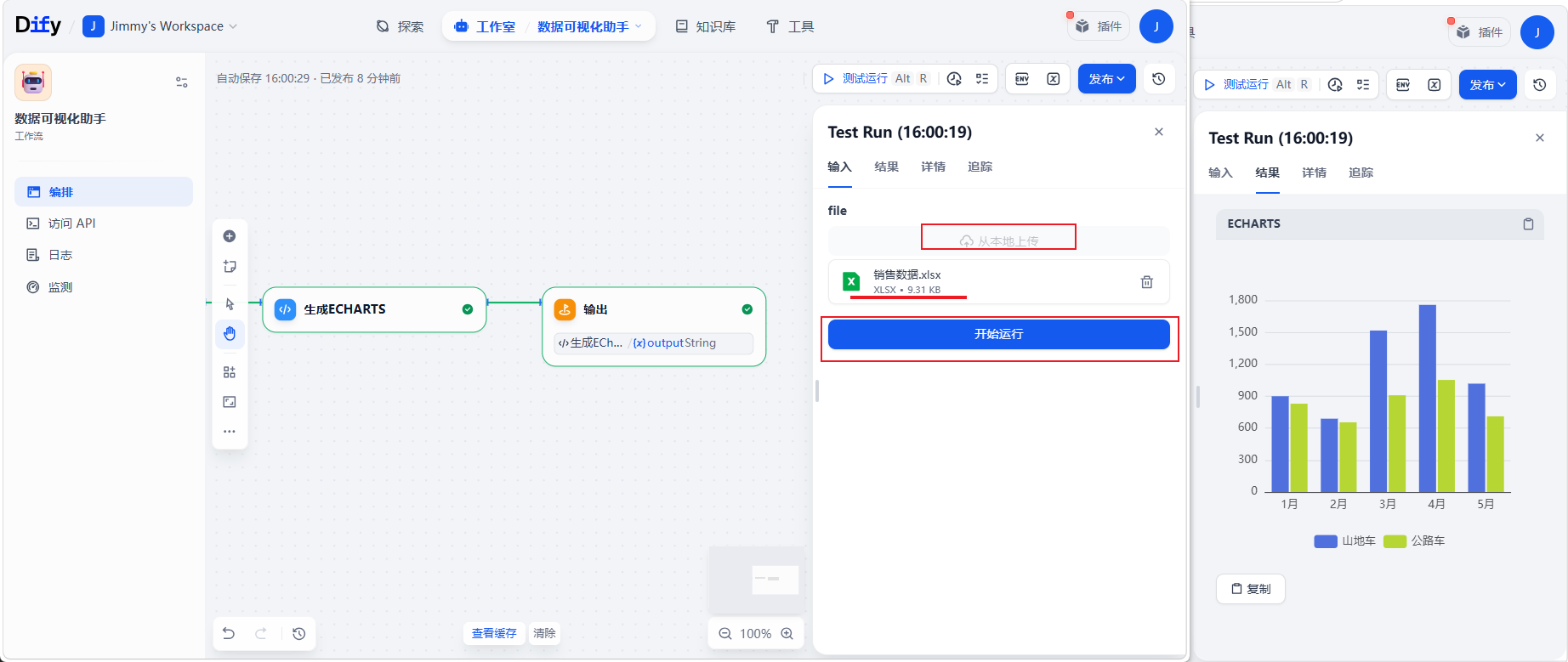
上传文件