一、背景:为什么需要批流一体?
在 Flink 批流一体技术成熟之前,大数据架构经历了两个主要阶段:
- Lambda 架构:流处理用 Flink/Storm,批处理用 Spark/Hive。痛点:需维护两套代码,两套逻辑,极易出现"T+1数据与实时数据对不上"的口径不一致问题。
- Kappa 架构:全盘流化,用 Kafka 存储所有历史数据并用 Flink 重播。痛点:Kafka 等消息队列不适合海量历史数据的长期存储与高效批处理分析,成本高昂。
Flink 的批流一体不是简单地"用流引擎跑批",而是在统一的架构下,针对有界和无界数据分别做了执行优化。其核心设计理念是:一套代码、一套引擎,根据数据的有界/无界特性自动或手动选择最优执行策略。
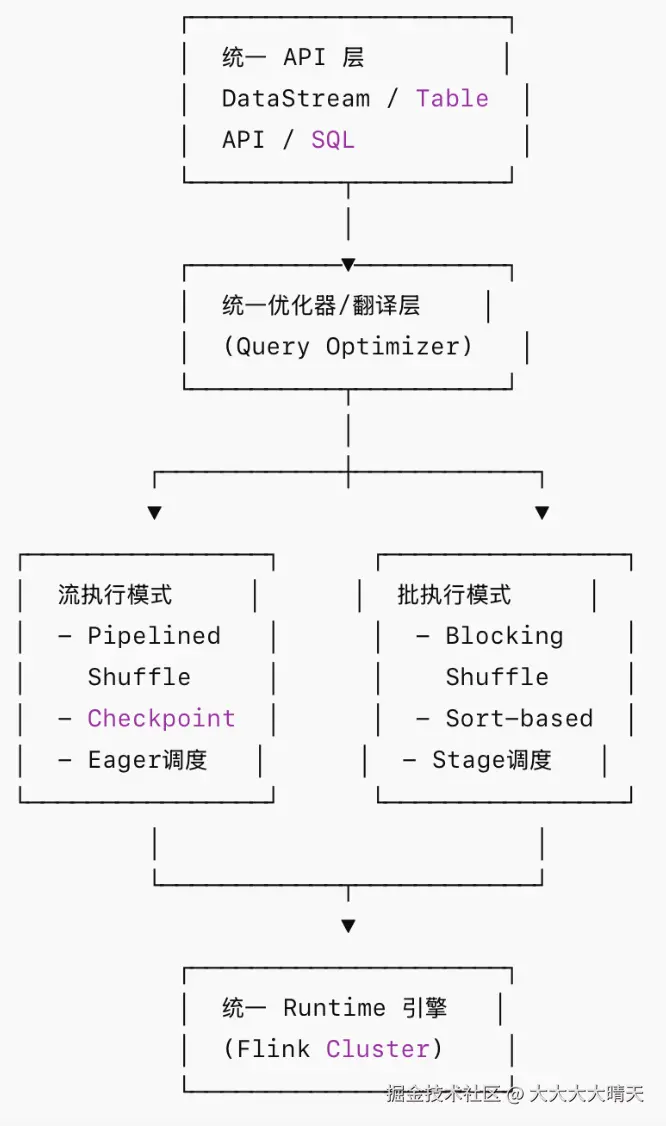
二、机制原理:Flink 如何实现批流统一?
1.统一的编程模型
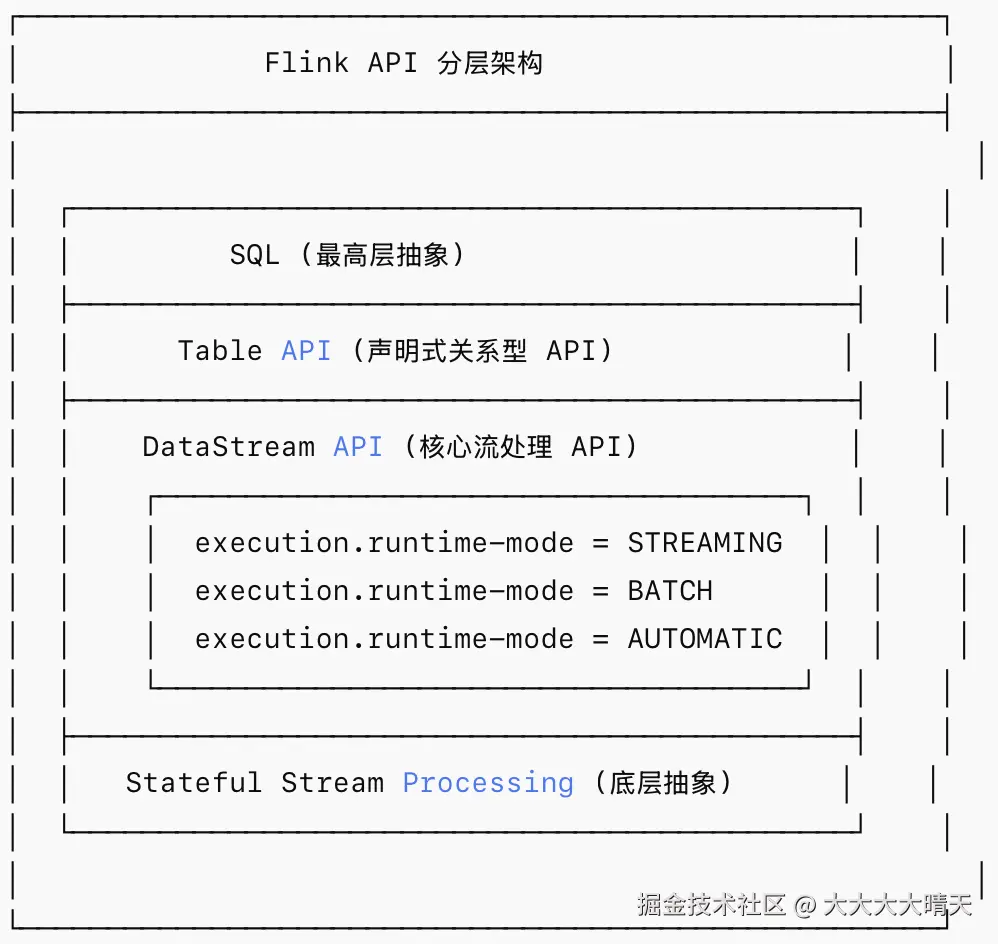
自 Flink 1.12 起,传统的 DataSet API 被废弃,DataStream API 承担起了统揽全局的任务。
ini
// 同一段代码,通过配置切换批/流模式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 方式一:代码中设置(不推荐用于生产)
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 方式二:提交时通过命令行指定(推荐)
// flink run -Dexecution.runtime-mode=BATCH ...
DataStream<String> source = env.readFile(...); // 有界源
DataStream<Tuple2<String, Integer>> result = source
.flatMap(new Tokenizer())
.keyBy(t -> t.f0)
.sum(1);
result.print();
env.execute("Unified WordCount");其中执行模式有三种可选:
| 模式 | 说明 | 适用场景 |
|---|---|---|
| STREAMING | 默认模式,所有数据作为无界流处理 | 实时数据流 |
| BATCH | 针对有界数据优化的批执行模式(所有 Source 必须有界,否则会抛出异常。) | 有界数据集、历史回刷 |
| AUTOMATIC | 根据数据源有界性自动选择 | 混合场景(需谨慎使用) |
2.调度策略差异
虽然代码是一套,但在底层 DAG(有向无环图)的执行上,Flink 做了精准的区别对待。
STREAMING 模式 - Eager 调度:
- 所有 Task 同时部署启动
- 数据通过网络 Buffer 实时传输(Pipelined)
- 需要同时占用所有 Task 的 Slot 资源
BATCH 模式 - Stage 调度:
- 按照 Shuffle 边界将 Job 划分为多个 Stage
- 上游 Stage 完成后,数据落盘,再启动下游 Stage
- 可以复用 Slot,降低资源峰值需求
3.Shuffle 机制差异
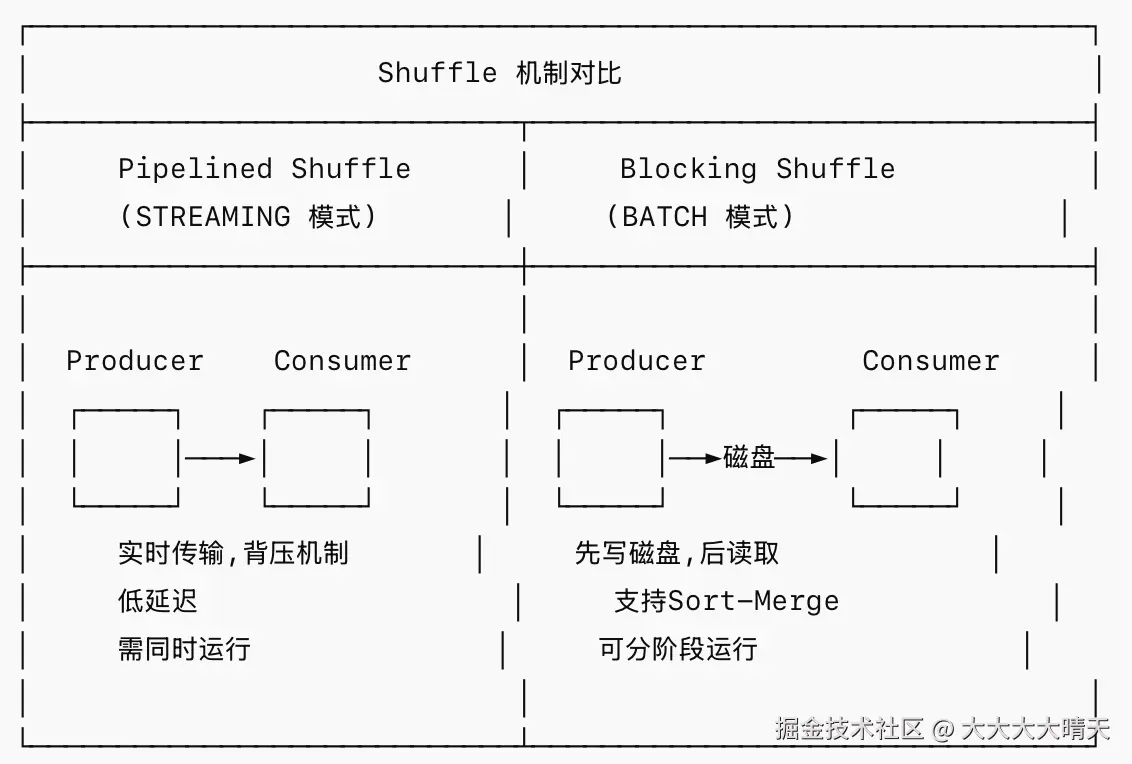
BATCH 模式下的 Shuffle 实现:
- Hash Shuffle:每个上游 SubTask 为每个下游 SubTask 创建一个文件,并发度高时文件数爆炸(M×N 个文件)
- Sort-Merge Shuffle(默认启用):上游 SubTask 将所有下游分区的数据排序后写入单个文件,大幅减少文件数和随机 IO
4.状态管理与容错差异
| 维度 | STREAMING 模式 | BATCH 模式 |
|---|---|---|
| 状态后端 | RocksDB / HashMapStateBackend | 内部优化的批状态管理 |
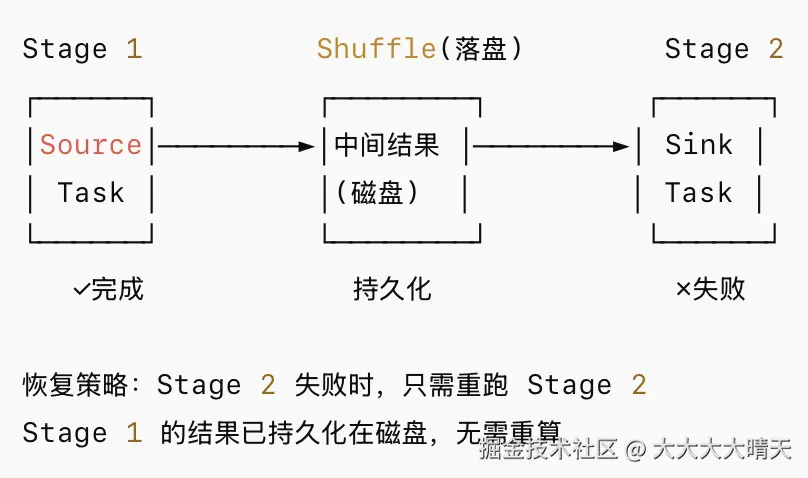
| 容错机制 | Checkpoint(周期性快照) | 无 Checkpoint,失败后从上一个 Shuffle 边界重算 |
| Exactly-Once | 通过 Checkpoint + 两阶段提交 | 通过输出的原子性保证(任务级别重试) |
| 水位线 | 持续推进 | 有界数据结束时发送 MAX_WATERMARK |
| 定时器 | 按事件时间/处理时间触发 | 在输入结束时统一触发 |
BATCH 模式容错原理如下:
5.Table API / SQL 层的批流一体
Table API 和 SQL 是 Flink 批流一体最自然的体现层,同一段 SELECT ... GROUP BY 语句,既可以处理 Kafka 的无界流(输出 Retract/Update 流),也可以处理 HDFS/数据湖的有界文件(输出最终结果)。
sql
-- 同一段 SQL,可以跑在流模式或批模式下
-- 通过 TableEnvironment 的配置决定执行模式
SET 'execution.runtime-mode' = 'batch';
SELECT
user_id,
COUNT(*) AS order_count,
SUM(amount) AS total_amount
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY user_id;在 Table/SQL 层,Flink 的 Planner会根据执行模式生成不同的物理执行计划:
- 流模式:生成增量计算的算子(如
GroupAggregate带状态更新和回撤流) - 批模式:生成全量计算的算子(如
HashAggregate/SortAggregate,无需维护状态)
三、批流一体优势与不足
核心优势:
- 统一技术栈:一套 API、一套引擎,降低学习和维护成本
- 逻辑一致性:同一份业务代码在批和流模式下语义一致,避免结果不一致
- 统一运维:一套集群、一套监控、一套部署流程
- 灵活切换:开发时用流模式实时调试,回刷历史时切换批模式提升效率
存在的不足:
- 批处理成熟度:相比 Spark,Flink 的批处理在某些场景(如超大规模 Shuffle、复杂 Join 优化)仍有差距
- 生态兼容:部分 Connector /流特有算子 对 BATCH 模式支持不完善
四、批流一体核心配置
yaml
# ============================================
# Flink 批流一体核心配置
# ============================================
# 1. 执行模式(最核心配置)
execution.runtime-mode: BATCH # STREAMING | BATCH | AUTOMATIC
# 2. Shuffle 相关配置
# Batch 模式下的 Shuffle 类型
taskmanager.network.sort-shuffle.min-parallelism: 200
# 当并行度 >= 该值时自动启用 Sort-Merge Shuffle
# 默认值:1(即始终启用,Flink 1.15+)
# Shuffle 数据压缩(推荐开启)
taskmanager.network.blocking-shuffle.compression.enabled: true
# Sort-Merge Shuffle 写缓冲区
taskmanager.network.sort-shuffle.min-buffers: 512
# 3. 调度相关
jobmanager.scheduler: AdaptiveBatch
# Flink 1.15+ 支持自适应批调度器
# 可根据数据量动态决定下游并行度
# 自适应批调度器配置
jobmanager.adaptive-batch-scheduler.min-parallelism: 1
jobmanager.adaptive-batch-scheduler.max-parallelism: 512
jobmanager.adaptive-batch-scheduler.avg-data-volume-per-task: 128mb
# 每个 Task 处理的目标数据量
# 4. 网络缓冲区
taskmanager.network.memory.fraction: 0.1
taskmanager.network.memory.min: 64mb
taskmanager.network.memory.max: 1gb
# 5. 批模式下的资源配置
# 由于分阶段执行,可以使用更少的 Slot
taskmanager.numberOfTaskSlots: 4
# 6. 执行链优化
pipeline.operator-chaining: true # 默认开启五、实践与总结
在实际推进批流一体落地时,建议遵循以下实践经验:
- 优先使用 Flink SQL:相比 DataStream API,SQL 层面的批流一体屏蔽了更多的底层细节,引擎层面的自动优化(如 Join 策略选择)更加成熟。
- 正确选择 Source/Sink Connector:并非所有的 Connector 都支持批流一体。例如使用 Kafka 时,若要用 BATCH 模式跑,必须明确指定
scan.bounded.mode(如指定结束的 offset 或 timestamp),否则 Flink 会将其视为无界流而无法进入 BATCH 执行模式。 - 基于监控做好作业配置优化:Flink在批处理场景的表现与性能需在实践中不断积累与迭代,投产前做好充分测试。
随着Flink技术的不断迭代演进,在当下AI爆发式发展的大浪潮下,未来可能不再有"批处理"与"流处理"的边界,用户开发只需关注业务逻辑,引擎会智能地在延迟、吞吐与成本之间寻求全局最优解。