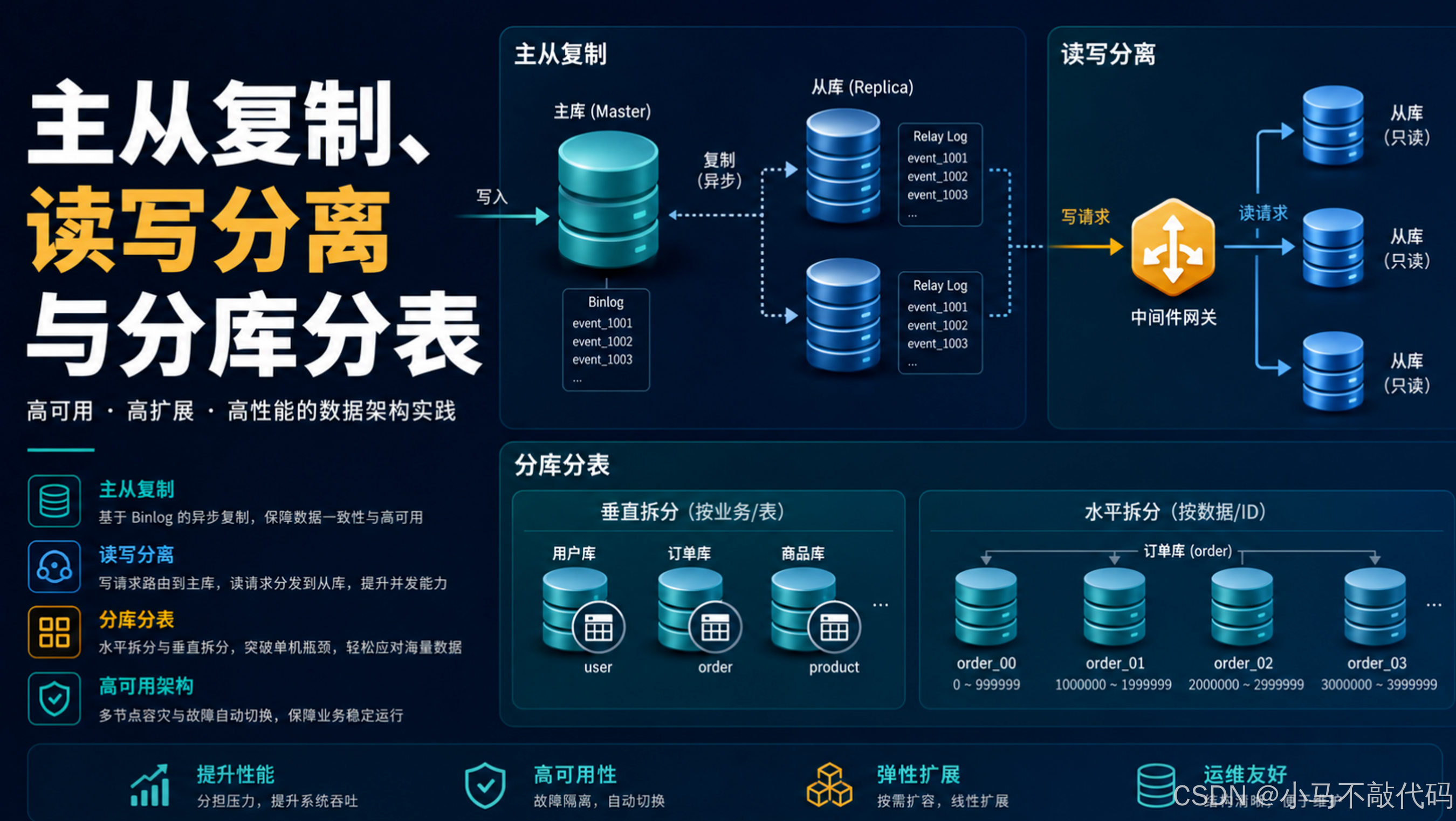
引言
当单库压力越来越大时,常见演进路线是:
- 主从复制 - 数据冗余和读扩展的基础
- 读写分离 - 缓解读请求对主库的压力
- 分库分表 - 解决单库、单表数据量和并发瓶颈
这三者解决的问题不同:
| 方案 | 主要解决什么 |
|---|---|
| 主从复制 | 数据冗余、读扩展、故障切换基础 |
| 读写分离 | 缓解读请求对主库的压力 |
| 分库分表 | 解决单库、单表数据量和并发瓶颈 |
一、主从复制的核心:binlog
MySQL 主从复制的核心是二进制日志(binlog)。binlog 记录 DDL 和 DML 语句,但不记录普通查询语句。
复制过程三步走
- 主库写 binlog:主库事务提交时,把数据变更写入 binlog
- 从库读 binlog:从库读取主库 binlog,并写入自己的 relay log
- 从库重放:从库重放 relay log 中的事件,把变更应用到自己的数据中
流程图更直观

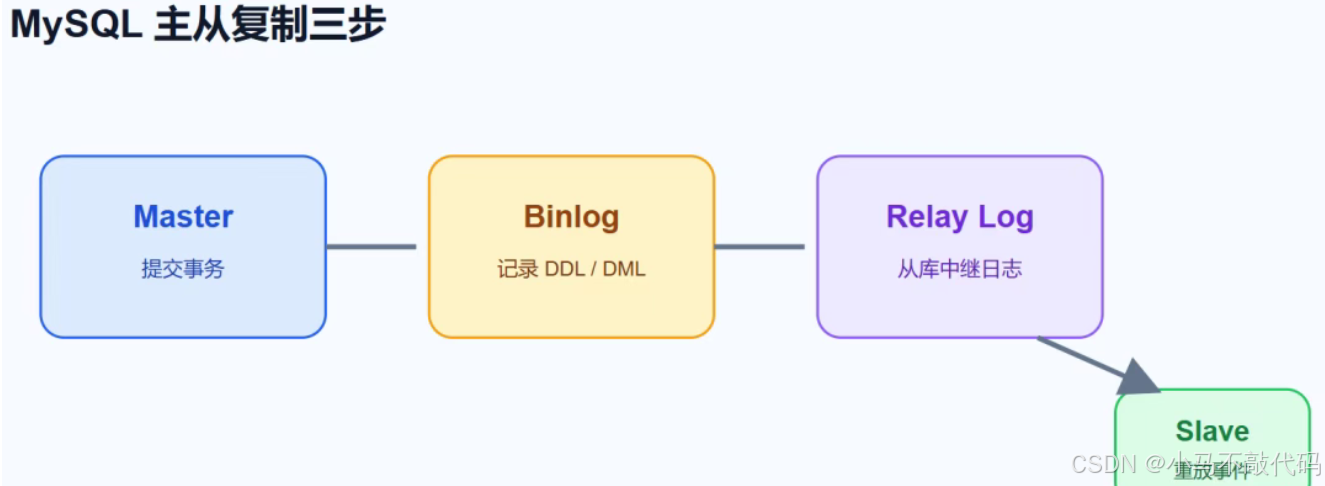
核心组件说明
| 组件 | 作用 |
|---|---|
| Master | 主库,负责写入并产生 binlog |
| Binlog | 主库记录数据变更的日志 |
| Relay Log | 从库拉取 binlog 后保存的中继日志 |
二、读写分离解决什么
如果业务读多写少,写操作可能影响查询效率。读写分离的思路是:写请求走主库,读请求走从库。
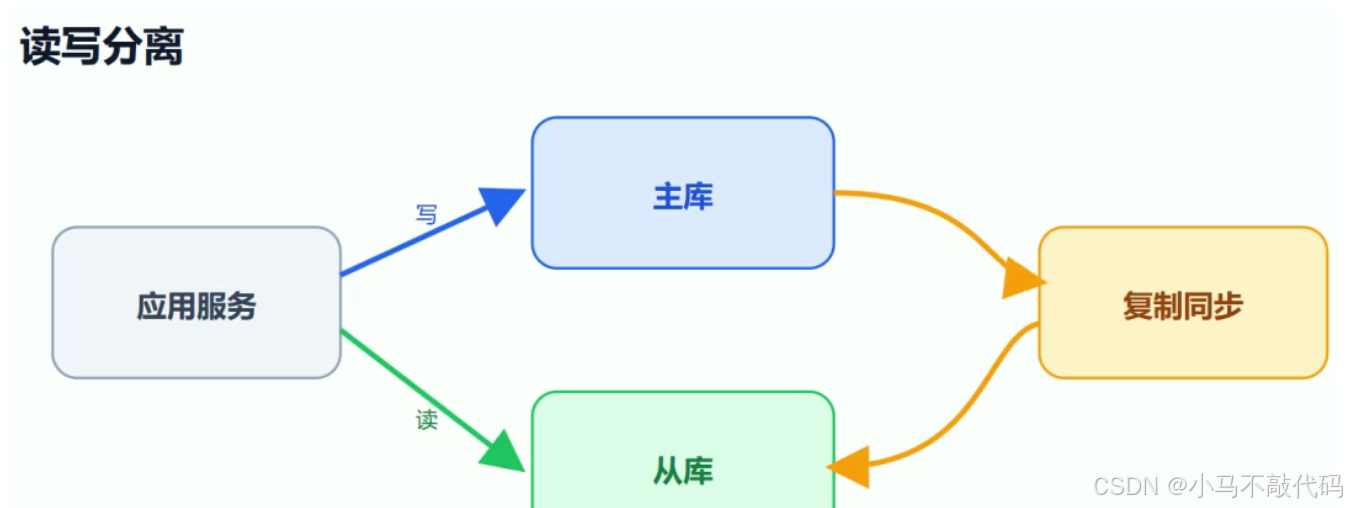
典型执行路径
- 应用或数据库代理识别 SQL 类型
INSERT、UPDATE、DELETE发到主库SELECT发到从库- 主库通过复制把变更同步给从库

主从延迟问题
读写分离能分担访问压力,但也带来一个常见问题:主从延迟。刚写入的数据,立刻去从库查,可能暂时查不到。
解决方案包括:
- 强制读主库(特定业务场景)
- 延迟敏感业务不走从库
- 根据复制延迟动态路由
- 使用半同步复制减少延迟
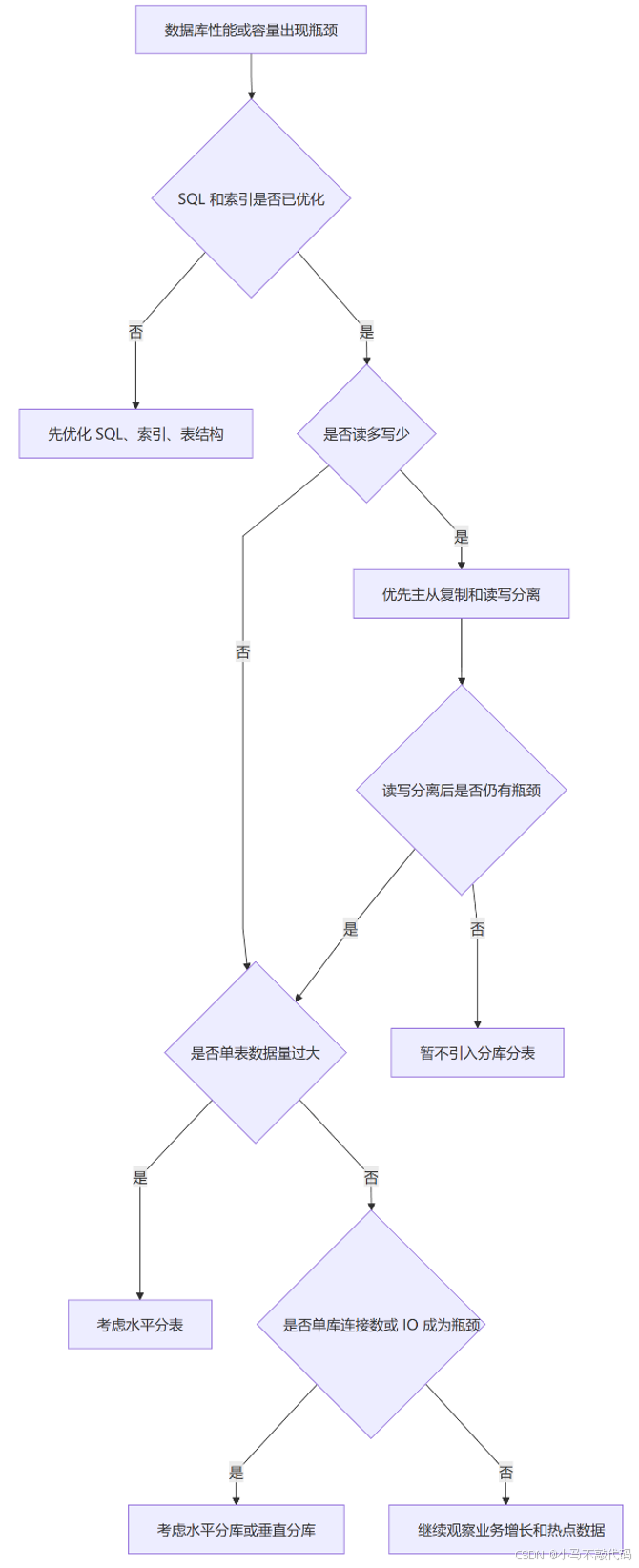
三、什么时候考虑分库分表
分库分表不是一开始就要做。它会显著增加系统复杂度,应该在常规优化已经不足时再考虑。
常见信号
- ✅ 业务数据持续增长,单表已经非常大
- ✅ 索引、SQL、缓存、读写分离等优化后仍无法满足性能
- ✅ 出现磁盘 IO、网络 IO、CPU 或连接数瓶颈
- ✅ 单表数据量达到千万级,或者单表文件非常大
分库分表解决的是更底层的问题:单库容量、单表性能、写入并发、IO 争抢。
决策流程图
是否要走到分库分表,可以先用这张决策图压一压复杂度:
四、垂直拆分
垂直拆分是按业务或字段拆。
4.1 垂直分库
垂直分库以表为依据,根据业务边界把不同表拆到不同库。
例如:
| 库 | 表 |
|---|---|
| 用户库 | 用户、账号、权限 |
| 订单库 | 订单、支付、售后 |
| 商品库 | 商品、库存、类目 |
好处:
- 按业务独立管理、维护和扩展
- 减少单库连接数和 IO 压力
4.2 垂直分表
垂直分表以字段为依据,把一个表中的字段拆到不同表。
常见规则:
- 把不常用字段拆出去
- 把
TEXT、BLOB等大字段拆到附表 - 做冷热数据分离,减少主表 IO
例如:
- 用户主表:保留高频字段(ID、用户名、手机号、邮箱)
- 用户详情表:保存低频字段(头像、简介、扩展配置)
五、水平拆分
水平拆分是按数据行拆。表结构通常相同,只是数据被分散到多个库或多张表。

5.1 水平分库
水平分库是把同一类数据拆到多个库中。
例如按用户 ID 取模:
sql
user_id % 3 == 0 -> db_0
user_id % 3 == 1 -> db_1
user_id % 3 == 2 -> db_2优点:
- 解决单库数据量和高并发瓶颈
- 提高系统稳定性和可用性
5.2 水平分表
水平分表是把同一张表的数据拆到多张表中,可以在同一个库内,也可以跨库。
例如:
order_0000
order_0001
order_0002
...主要解决:
- 单表过大导致的查询、写入性能问题
- 索引维护和锁竞争问题
六、分库分表带来的新问题
拆分后性能瓶颈缓解了,但复杂度会上来。
| 问题 | 说明 |
|---|---|
| 分布式事务 | 一次业务操作可能跨多个库 |
| 跨节点关联查询 | JOIN 不再像单库中那么自然 |
| 跨节点分页排序 | 需要汇总多节点结果再排序 |
| 全局主键 | 多节点生成 ID 需要避免冲突 |
| 路由规则 | 应用要知道数据在哪个库、哪张表 |
常见中间件:
- ShardingSphere - Apache 开源项目,功能全面
- MyCat - 老牌分库分表中间件
⚠️ 注意:中间件可以帮助处理路由、分片、读写分离等问题,但不能消除架构复杂度。
七、面试回答模板
可以这样回答:
MySQL 主从复制依赖 binlog。主库提交事务时写 binlog,从库读取 binlog 写入 relay log,再重放 relay log 完成数据同步。
读写分离是在主从复制基础上,把写请求发到主库,读请求发到从库,用来缓解读压力,但要注意主从延迟。
当单库单表数据量或并发继续增长,普通优化已经解决不了 IO、CPU、连接数和单表性能问题时,可以考虑分库分表。
分库分表分为垂直分库、垂直分表、水平分库、水平分表,但会带来分布式事务、跨节点查询、分页排序和主键避重等新问题。
八、小结
主从复制、读写分离和分库分表是一条逐步升级的路线:
- 主从复制 - 解决数据同步和读扩展基础
- 读写分离 - 缓解读压力
- 分库分表 - 处理更大的容量和并发问题
越往后收益越大,复杂度也越高,设计时一定要先确认瓶颈是否真的到了这一步。
📌 关键要点总结
| 阶段 | 核心目标 | 适用场景 | 复杂度 |
|---|---|---|---|
| 主从复制 | 数据冗余、读扩展 | 读多写少,需要备份 | 低 |
| 读写分离 | 分担读压力 | 读请求远大于写请求 | 中 |
| 分库分表 | 解决容量和并发瓶颈 | 单表千万级,高并发 | 高 |