这篇文章手把手教你如何用微软开发的 DoWhy 库做因果推断。很多时候我们会发现数据里的相关性很唬人,比如高级会员流失率反而高,但这并不代表因果。文章通过一个 SaaS 公司的客服案例,展示了如何通过"建模、识别、估计、证伪"这四步法,拨开数据迷雾,找到真正的业务驱动因素。如果你想让你的分析结论更有说服力,不再被"相关不代表因果"这句话堵死,这篇实战指南非常值得一读。
1 背景:当相关性不再够用
1.1 数据分析中的"直觉陷阱"
每个分析师都曾多次盯着仪表盘上看似清晰的模式发愁:高级客户流失更多、营销活动反而降低了收入、新功能降低了参与度。数字不会撒谎......还是说它们其实会?
这是数据分析中最大的问题之一:相关性无处不在,而因果性却很罕见。回归模型可以轻松返回系数,但如果没有明确的假设和对问题的清晰理解,它们无法告诉你某个效果的真正原因。为此,我们需要一种本质上不同的推理方式:因果推断。
1.2 从学术走向业务
几十年来,因果推断更多地存在于学术界而非商业环境中。幸运的是,这种情况正在改变。本文旨在涵盖因果推断实际应用的一个重要部分。我们将探索由微软研究院开发的 DoWhy 库。
DoWhy 是一个弥合因果理论与实际数据科学之间鸿沟的 Python 库。它提供了一个系统的四步框架来回答因果问题,其基础是朱迪亚·珀尔(Judea Pearl)的因果推断理论。DoWhy 的特别之处在于它强制我们保持透明。我们不能躲在黑箱模型或隐藏假设后面,必须对要解决的问题进行结构化思考。
2 案例:SaaS 公司的支持计划评估
2.1 模拟数据集构建
让我们从一个真实世界的场景开始。我们是一家成长中的 SaaS 公司的建模分析师。产品团队刚刚推出了一个新的"高级支持"等级,承诺更快地解决技术问题,当然需要额外收费。高管们想知道:"这个产品真的有效吗?"我们的任务就是回答它。
我们将使用以下模拟数据集。它由 1000 个近期的支持工单组成,包括解决时间、公司规模,以及客户是否购买了高级支持升级的标志。
python
import numpy as np
import pandas as pd
np.random.seed(42)
num_users = 1000
company_size = np.random.randint(10, 5000, num_users)
size_norm = (company_size - company_size.mean()) / company_size.std()
p_buy = 1 / (1 + np.exp(-(size_norm + 0.5)))
premium_support = np.random.binomial(1, p_buy)
resolution_time = 10 + (0.005 * company_size) - (5 * premium_support) \
+ np.random.normal(0, 1, num_users)
df = pd.DataFrame({ 'company_size': company_size,
'premium_support': premium_support,
'resolution_time': resolution_time })使用模拟数据的最大好处是我们已经知道答案:公司规模驱动了高级支持的购买(大公司更倾向于购买),同时公司规模也会因为复杂性增加解决时间。我们知道,"上帝视角"下,高级支持程序本身能减少 5 小时的解决时间。
2.2 数据直接对比的存在问题
如果我们像往常一样直接对比两组客户的平均解决时间,会发现支付了高级支持的客户等待时间反而更长。如果直接汇报这个结果,决策将是显而易见的:终止高级支持计划。
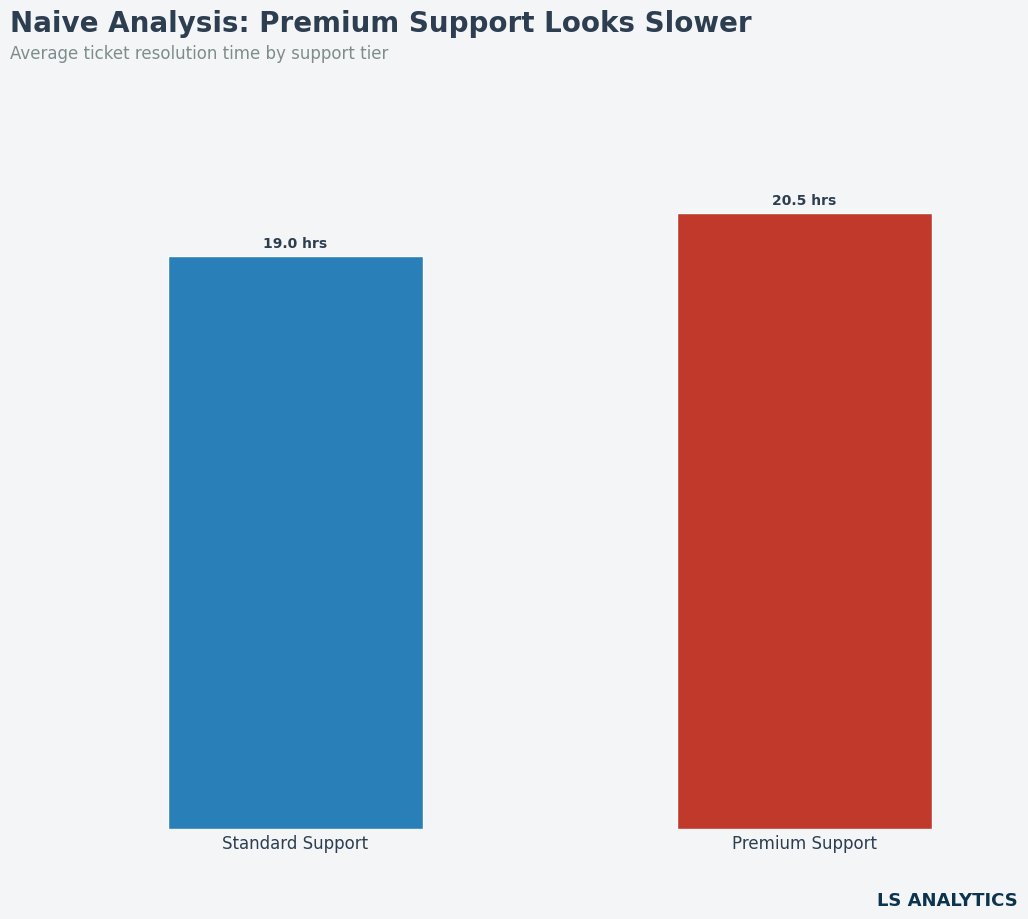
但深入思考就会发现,只有预算充足的大公司才会购买它,而大公司本身解决时间就长。这是一个典型的混杂变量(Confounder),它同时影响了"处理"(是否购买)和"结果"(解决时间)。如果我们直接对比,就是在拿两组完全不具备可比性的群体做比较。
3 核心:DoWhy 框架四步走
3.1 建模(Model):绘制因果图
DoWhy 强迫我们停止计算并开始建模。它引入了一个严谨的四步框架:
- 建模(Model):用有向无环图(DAG)编码我们的因果假设。
- 识别(Identify):确定因果效应是否可以从现有数据中估算。
- 估计(Estimate):计算效应。
- 证伪(Refute):测试结论的稳健性。
在我们的案例中,DAG 包含三个节点:公司规模、高级支持和解决时间。
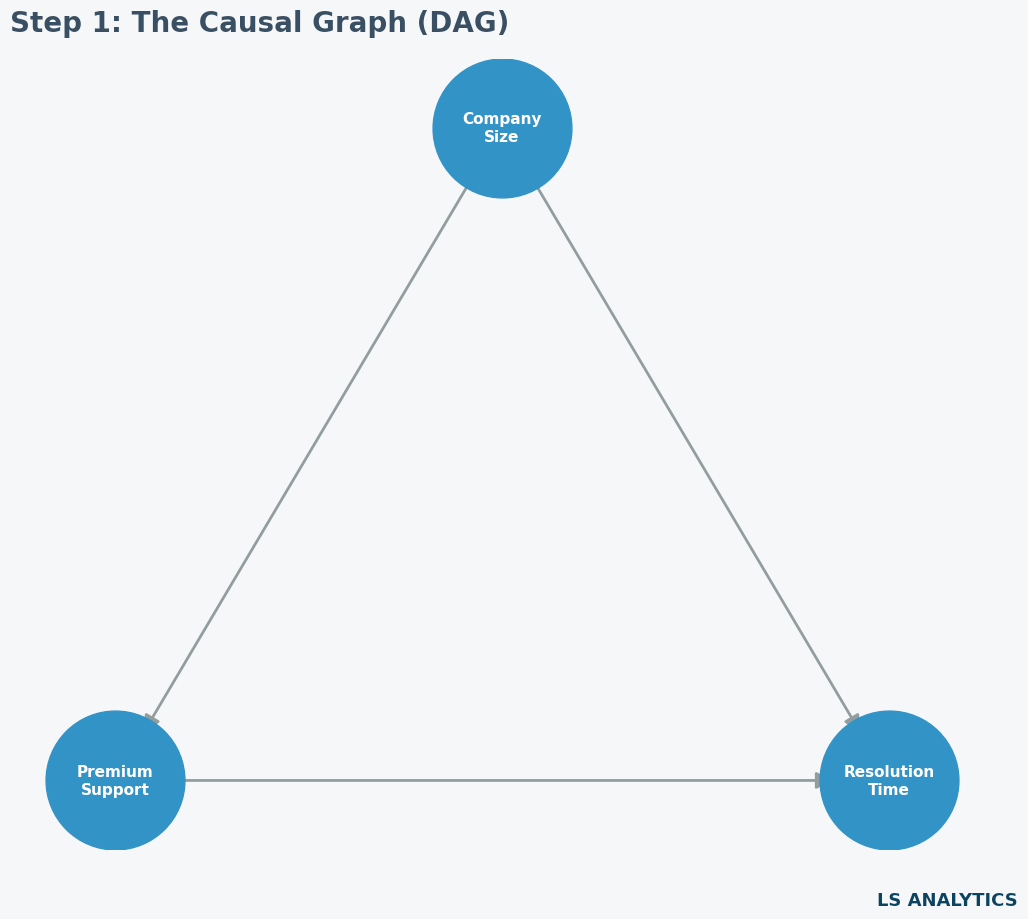
代码实现非常简洁:
python
from dowhy import CausalModel
model = CausalModel(
data=df,
treatment='premium_support',
outcome='resolution_time',
common_causes=['company_size']
)3.2 识别(Identify):寻找后门路径
在进行统计分析前,DoWhy 会检查因果效应是否可识别。在我们的图中,存在一条通过"公司规模"的"后门路径"。为了消除这种非因果关联,我们需要应用后门准则,即通过控制"公司规模"来切断这条路径。
python
identified_estimand = model.identify_effect(proceed_when_unidentifiable=True)DoWhy 会自动分析图结构并告诉我们:是的,通过控制公司规模,我们可以得到纯粹的因果效应。
4 实战:估计效应与压力测试
4.1 效应估计(Estimate)
识别告诉我们要算什么,估计则是具体怎么算。最简单的方法是线性回归:
python
estimate = model.estimate_effect( identified_estimand, method_name="backdoor.linear_regression" )
print(f"Causal Estimate: {estimate.value:.2f} hours")输出结果显示约为 -4.93 小时。这意味着高级支持程序实际上节省了近 5 小时的解决时间。这与我们模拟数据时的设定完全吻合!
下图直观地展示了这一点:在任何公司规模水平下,使用高级支持的解决时间都更低。
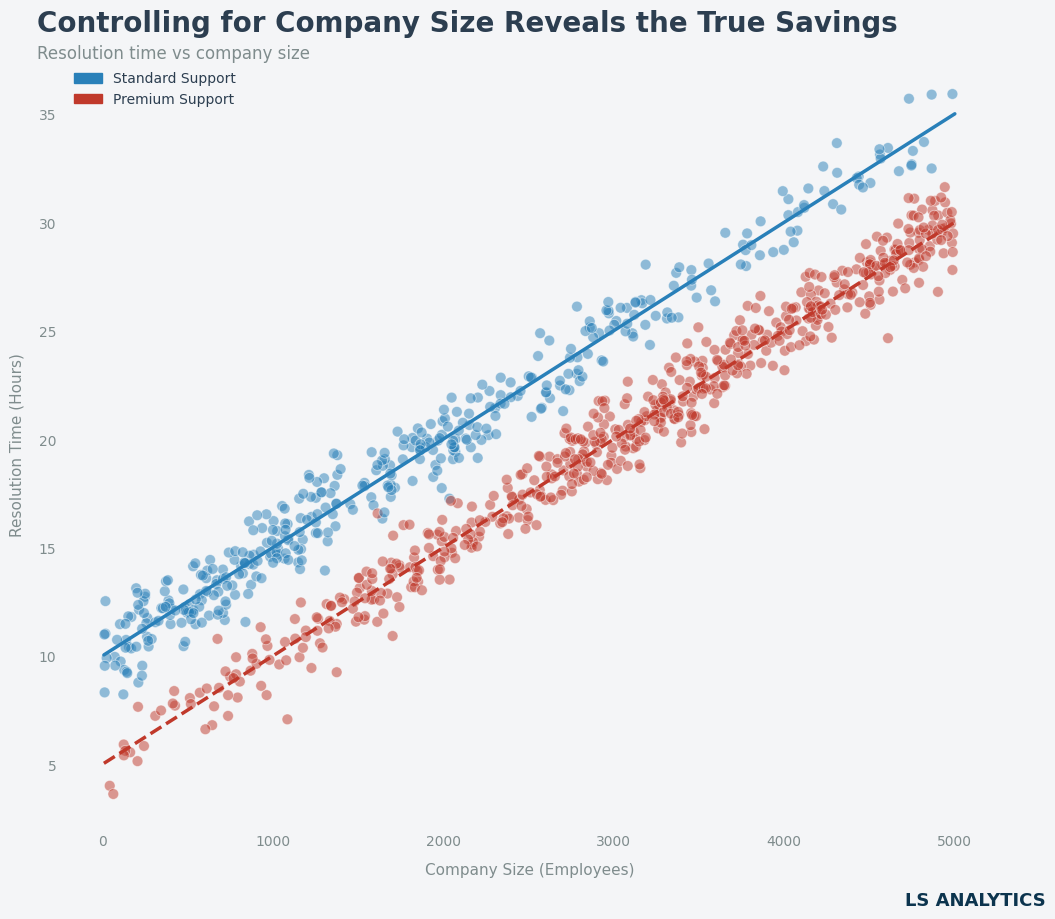
4.2 证伪检验(Refute):让结论更稳固
DoWhy 不会止步于估算。它提供了一系列测试来挑战我们的结论:
- 安慰剂测试(Placebo Test):将真正的"处理"替换为随机变量。如果结论依然显著,说明原来的结论是靠运气得来的。
- 随机共同原因测试(Random Common Cause Test):加入一个随机变量作为共同原因,理想情况下它不应改变原有的估算结果。
- 敏感性分析(Sensitivity Analysis):测试如果存在一个未被观测到的强大混杂变量,我们的结论是否会崩塌。
python
# 安慰剂测试示例
refutation = model.refute_estimate(
identified_estimand,
estimate,
method_name="placebo_treatment_refuter",
num_simulations=20
)
print(refutation)在我们的案例中,这些测试都顺利通过,证明了结论的稳健性。
5 总结与展望
大多数数据科学库只给你一个函数和一个结果,而 DoWhy 给了你一套思维框架。它强制你画出因果图,让所有的假设无处遁形,从而可以被阅读、质疑和修改。
DoWhy 的核心价值在于:
- 透明性:因果假设必须显式声明。
- 严谨性:通过四步框架避免由于混杂因素导致的错误结论。
- 稳健性:内置证伪测试确保结论经得起推敲。
这篇文章只是揭开了 DoWhy 的冰山一角。通过将数据科学工具与因果思维结合,我们可以真正理解数据背后的"为什么",从而做出更好的业务决策。
参考文献
- Pearl, J. (2009). Causality: Models, Reasoning, and Inference. Cambridge University Press.
- DoWhy Documentation
- Causal Inference for the Brave and True