一、前言
基本我们做大模型推理落地、本地私有化部署,都会遇到一个非常头疼的现实问题:手握RTX 4090显卡,显存规格足够强悍,却依旧跑不动千亿、百亿参数级别的大模型。
模型权重完整加载就直接显存爆炸,推理频繁OOM报错,批量请求吞吐极低,单次对话延迟居高不下,多并发场景直接卡死崩溃。通常大家第一反应都是多卡分布式张量并行、多机集群分片部署,但绝大多数根本没有多卡服务器资源,只能依靠单张4090完成全流程推理服务。基于认知程度不同,极易混淆张量并行、模型分片、分层加载、权重切分这些概念,分不清多卡并行与单卡分片差异,不懂显存复用、KV缓存优化、算子调度逻辑,盲目堆砌参数最后效果极差。
今天我们结合实际,利用好珍贵的单张RTX 4090显卡,分析张量并行底层逻辑、Transformer模型分片原理、单卡权重分层分片加载流程,完整拆解大模型推理整条链路,深度讲解延迟与吞吐平衡调优技巧,解决单卡跑大模型显存不足、推理卡顿、性能失衡痛点。

二、基础概念详解
1. 张量并行定义
张量并行,本质是针对Transformer模型核心张量运算,沿着张量维度进行维度切分,把原本巨大的矩阵乘法运算拆分到不同计算单元并行执行。
传统认知里张量并行属于多卡分布式技术,但在单卡 RTX 4090 场景下,依旧存在单卡张量维度并行调度逻辑,利用显卡CUDA核心、显存带宽、张量核心并行算力,拆分大张量运算,降低单次计算显存峰值。
- 按照张量行维度拆分:行并行,拆分注意力权重矩阵,适配序列长度推理优化
- 按照张量列维度拆分:列并行,拆分FFN前馈网络权重,适配隐藏维度显存压缩
- 单卡张量并行不跨设备通信,无NCCL通信损耗,延迟远低于多卡分布式并行
2. 模型分片概念
模型分片是大模型权重碎片化存储、分段加载、逐层计算的工程方案,区别于一次性把整份模型权重全部载入显卡显存。
RTX 4090原生24G GDDR6X显存,看似容量很高,但百亿模型FP16权重就需要20G以上,加上KV缓存、中间激活张量、梯度张量,极易溢出。
单卡模型分片核心逻辑:
-
- 分层分片:按照 Transformer Layer 层依次切分权重,一层加载、一层计算、一层释放
-
- 权重分片:单一层内部QKV权重、注意力权重、FFN权重单独切块存储
-
- 内存显存交换分片:CPU内存存放完整权重,推理按需加载到GPU显存,用完及时卸载
3. 单卡4090适配特性
RTX 4090具备强大张量核心、高显存带宽、超大L2缓存,是消费级单卡跑超大模型最优硬件,天然适配分片 + 张量并行轻量化推理。
- 24G超大显存,支持7B模型原生满精度运行,30B/70B模型分片轻量化运行
- Ada张量核心,FP16/BF16张量运算加速,并行矩阵计算效率极高
- 高带宽显存,支撑权重频繁CPU-GPU搬运,分片加载吞吐稳定
- 单卡无通信开销,分布式并行劣势完全规避,极致简化部署架构
三、底层核心基础
1. Transformer模型结构
大模型所有分片、张量并行优化,全部围绕Transformer编码器层结构展开,不懂模型结构就无法理解切分逻辑。
标准大模型每一层结构固定:输入嵌入→多头自注意力机制→层归一化→FFN 前馈神经网络→残差连接。
- 自注意力QKV矩阵:模型最大张量权重,显存占用最高,是分片首要优化对象
- 多头注意力投影矩阵:维度庞大,矩阵乘法计算密集,是张量并行核心运算单元
- FFN两层线性变换:隐藏维度极大,中间激活张量极易占用大量临时显存
- 多层堆叠结构:几十层Transformer串联,逐层累加显存占用,触发OOM
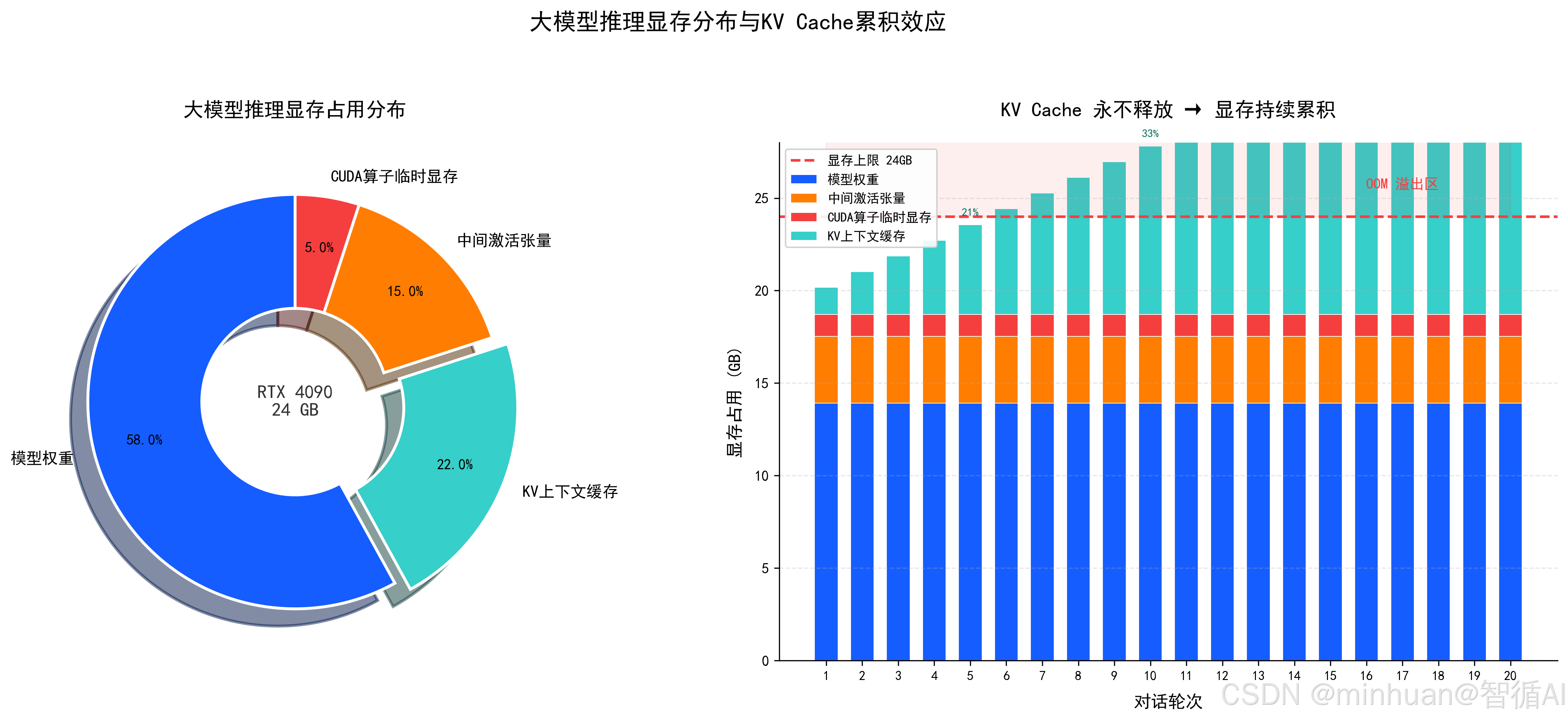
2. 显卡显存占用构成
RTX 4090推理大模型,显存消耗分为四大模块,分片优化就是针对性削减每一项峰值占用:
-
- 模型权重显存:FP16/BF16量化权重,模型参数本体
-
- 激活中间张量:推理过程每一层计算临时特征张量
-
- KV缓存显存:对话上下文历史键值缓存,长文本场景暴涨
-
- 算子运行临时显存:CUDA内核、矩阵运算临时缓冲区
3. 张量运算基础原理
深度学习所有大模型推理,本质都是矩阵张量乘法运算。超大隐藏维度张量相乘,会瞬间占用巨量显存。
- 隐藏维度越大,张量矩阵尺寸越大,显存占用指数上升
- 序列长度越长,批量大小越高,张量维度同步膨胀
- 单张大矩阵运算算力压力集中,CUDA核心调度拥堵,延迟飙升
张量并行就是拆分大矩阵为多个小矩阵并行算,模型分片就是分批加载大权重,两者配合彻底解决单卡显存瓶颈。
4. CPU-GPU内存交换机制
单卡分片核心依赖主机内存与显卡显存异步搬运,RTX 4090 PCIe 4.0带宽充足,搬运延迟可控。
- 完整模型权重存放CPU DDR大内存
- 推理逐层加载单层权重进入GPU显存
- 当前层计算完成,立即释放显存,加载下一层权重
- 异步预加载机制,计算与搬运同时进行,不拖慢推理速度
四、张量并行底层原理
1. 维度切分数学逻辑
Transformer线性权重矩阵维度为hidden_size, hidden_size,千亿模型隐藏维度极高,整张矩阵无法一次性载入4090显存。
- 列维度张量并行:沿着输出维度拆分权重矩阵,多头注意力分头并行计算
- 行维度张量并行:沿着输入维度拆分矩阵,拼接序列特征结果
- 单卡内张量并行:利用显卡多 SM 流多处理器,并行执行多块小张量运算
- 无跨卡通信:所有张量聚合在单卡内部完成拼接,零通信损耗
2. 注意力层并行原理
多头自注意力是张量并行核心优化模块,多头天然支持维度拆分并行。
- 每个注意力头独立QKV张量,单独切分运算互不干扰
- 分头并行计算注意力分数,大幅降低单次张量峰值显存
- 单卡张量核心同时调度多个头运算,推理速度显著提升
- 结果拼接还原完整注意力输出,精度完全无损
3. FFN网络并行原理
前馈神经网络是模型显存占用第二大户,两层线性映射张量规模巨大。
- 第一层升维线性层:列并行拆分,分散隐藏维度压力
- 第二层降维线性层:行并行聚合计算结果
- 激活函数逐张量并行运算,不改变维度拆分逻辑
- 残差张量维度对齐,保证分片并行前后特征一致
4. 单卡并行优势特性
对比多卡分布式张量并行,RTX4090 单卡张量并行拥有碾压级优势:
- 不存在多卡同步、通信等待、带宽延迟损耗
- 权重无需分布式同步更新,推理架构极简
- 部署成本极低,个人单机即可运行百亿级模型
- 故障点极少,不会出现卡间同步异常、推理错乱问题
五、单卡模型分片原理
1. 分层串行分片逻辑
单卡RTX4090最成熟分片方案:层级流水线分片,Transformer一层一层加载推理。
- 模型整体按 Layer 分层切割,每层权重独立文件、独立存储
- 推理初始化只加载嵌入层权重,不加载全部模型
- 上层计算完毕释放显存,下层权重才从CPU内存载入GPU
- 循环遍历所有层,逐层计算逐层释放,显存峰值恒定极低
2. 层内权重精细分片
单层Transformer内部权重依旧过大,继续精细化切块分片:
- **Q、K、V三套权重单独分片:**各权重矩阵独立切块,逐块加载计算,降低单次显存峰值。
- **输出投影权重单独分片:**最后映射层单独拆分,释放后复用,不常驻显存。
- **FFN上采样、下采样分开调度:**Gate与Value支路独立分片,交替加载计算,避免同时占用。
- **层归一化小权重常驻:**参数量极小,固定存入显存,减少重复IO,提升计算效率。
3. 权重复用与显存回收
单卡分片性能核心在于高效显存回收,RTX4090显存调度直接决定OOM概率。
- 手动del释放无用张量:及时删除中间变量,调用torch.cuda.empty_cache()清空残留,防止显存堆积。
- 残差连接复用显存地址:原地修改张量或使用out参数,避免加运算新开辟显存空间。
- KV缓存动态裁剪:超出窗口的历史KV直接丢弃,按当前输入长度维护最小缓存。
- 旧对话及时销毁:切换会话时显式删除历史张量,不常驻显存占用,保障长时稳定服务。
4. CPU-GPU异步分片调度
同步搬运速度慢、推理卡顿,异步流水线分片是单卡标配优化:
- 当前层 GPU 计算时,后台 CPU 预加载下一层权重
- 计算完成瞬间切换权重,零等待间隔
- PCIe4.0 高速通道匹配 4090 带宽,异步延迟几乎无感
- 批量推理场景下,流水线吞吐量大幅提升
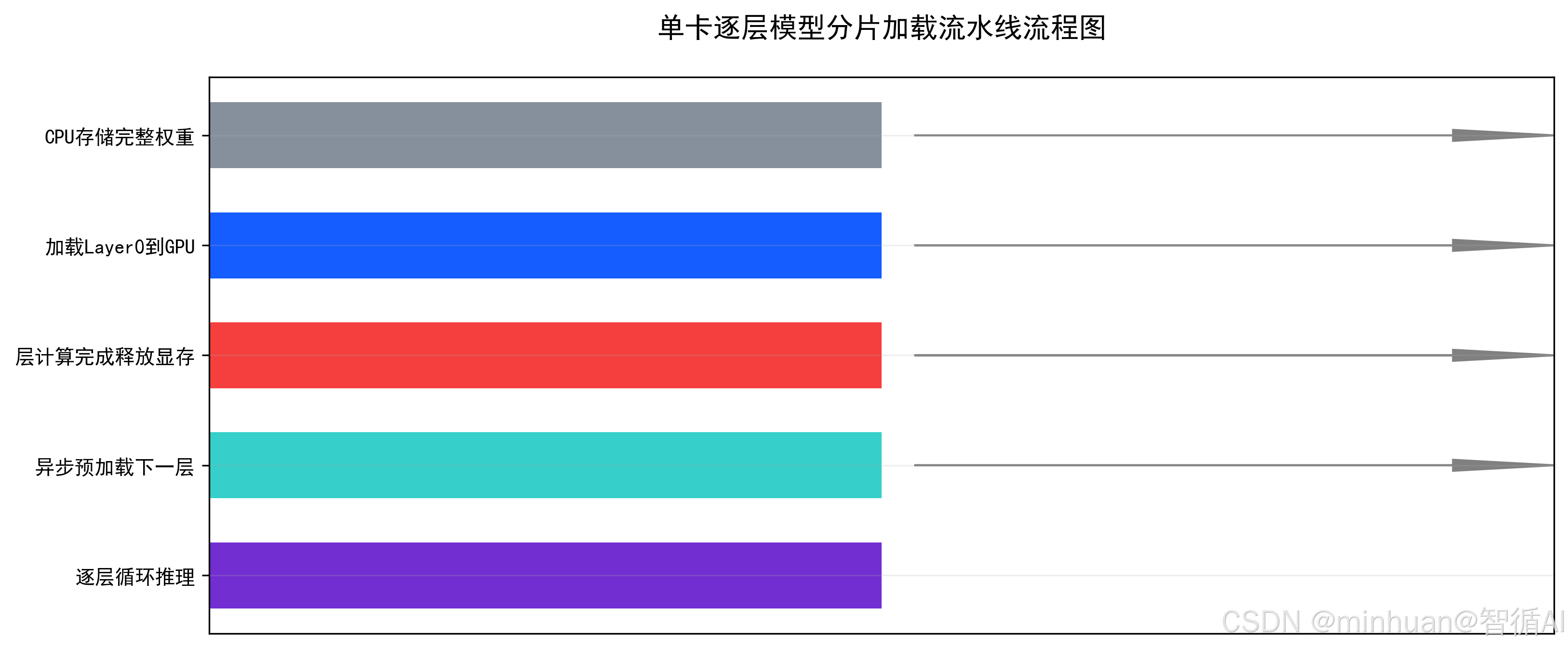
六、完整推理业务流程
1. 权重预处理流程
上线部署前,必须对原始大模型权重做单卡分片预处理,适配RTX4090运行。

-
- 原始模型权重拆分分层文件,按Transformer层独立保存
-
- FP16转BF16精度量化,降低一半显存占用
-
- 权重维度规整对齐张量并行尺寸,方便并行计算
-
- CPU内存规整排序,优化后续异步加载速度
2. 初始化加载流程
模型服务启动阶段,不一次性全量加载权重:

-
- 初始化CUDA环境,绑定 RTX4090 显卡设备
-
- CPU加载完整模型索引文件,不加载实际张量
-
- 加载词嵌入、输出层常驻小权重
-
- 初始化KV缓存池、CUDA算子上下文
3. 逐层推理执行链路
用户输入Prompt后,整条推理链路完整步骤:

-
- 输入文本Token化,生成初始特征张量
-
- 加载第一层Transformer权重,GPU张量并行计算
-
- 计算完成释放该层显存,异步预加载下一层
-
- 依次遍历全部网络层,串行分层推理
-
- 最后一层输出映射,生成预测Token
-
- 循环自回归生成,直到对话结束
4. 显存动态释放流程
推理生成每一个 Token,都伴随完整显存生命周期:

-
- 单Token推理结束,清空临时激活张量
-
- 过期KV缓存滑动窗口裁剪
-
- 非当前层权重全部退回CPU内存
-
- 定期清理CUDA碎片显存,避免隐性OOM
5. 并发请求处理流程
单卡4090多并发对话推理,分片 + 并行协同调度:

-
- 批量Token统一张量并行运算,提升吞吐
-
- 不同请求复用显存池,不重复开辟空间
-
- 队列调度请求顺序,避免显存瞬间暴涨
-
- 长短上下文分级处理,平衡整体延迟
全流程从预处理→启动→推理→收尾完整闭环,结合线上真实业务落地,我们可以完全照着流程就能搭建本地推理服务。
七、核心底层逻辑
1. 显存瓶颈突破逻辑
大模型单卡跑不起来,本质不是算力不够,是显存容量瓶颈。
- 完整大模型权重远大于24G,一次性加载必然 OOM
- 张量并行缩小单次张量尺寸,降低峰值显存
- 模型分片分时占用显存,同一时间只占用单层权重显存
- 算力利用率不降反升,4090 张量核心持续满载运行
2. 计算调度协同逻辑
张量并行负责算得更快,模型分片负责装得下,二者深度配合:
- 分片拆分权重大小,并行加快单层计算速度
- 串行分层推理,并行单层运算,兼顾显存与速度
- 张量维度对齐分片边界,不出现精度损失
- CUDA调度优先级:张量并行算子优先于权重搬运
3. 精度无损底层逻辑
我们无需担心分片、并行会降低模型对话效果,实际原生方案完全无损:
- 张量维度严格矩阵数学等价拆分,运算结果完全一致
- 分层串行只是顺序加载,不改变模型前向计算公式
- 多头分头并行严格对齐注意力计算规则
- 4090高精度浮点运算,无舍入误差累积
4. 软硬协同适配逻辑
RTX4090硬件特性深度匹配单卡分片并行技术:
- Ada张量核心适配小批量并行:专为小块矩阵优化,减少指令开销,提升小batch推理效率。
- 大显存带宽支撑高频交换:高速带宽满足CPU-GPU频繁权重搬运,分片加载几乎无延迟。
- 超大L2缓存中间张量:缓存临时计算结果,减少反复读写显存,提升数据复用率。
- PCIe4.0满足异步分片搬运:高速总线支持多卡分片传输,异步流水线不阻塞计算。
八、RTX4090延迟吞吐调优
1. 延迟优化核心方案
单Token生成慢、首包延迟高,是单卡分片通病,针对性优化:
- 增大常驻KV缓存,减少重复张量计算
- 优化异步权重预加载,消除层间等待延迟
- 张量并行维度最优配比,匹配4090张量核心规格
- 关闭无用精度校验,启用CUDA快速算子
2. 吞吐平衡优化策略
并发用户多、批量请求卡顿,做好延迟与吞吐取舍平衡:
- 小批量批量推理,张量并行最大化算力利用率
- 动态分片粒度,长序列缩小分片、短序列加大分片
- 限制最大并发数,避免显存瞬间拥挤
- 滑动窗口KV缓存,固定长上下文显存占用
3. 显存极致调优参数
RTX4090专属参数调优,24G显存应用到极致:
- BF16混合精度推理:相比FP16减少一半显存占用,精度几乎无损,24G显存可用内存大幅增加。
- 逐层卸载严格时序:每层计算完立即释放中间张量,不堆积闲置显存,避免显存泄漏。
- 关闭梯度计算:推理时用torch.no_grad()禁用梯度图,不再保存中间梯度,显存占用大幅降低。
- 合理设置分片层数:分片过细会增通信开销,建议32层模型分4-8片,平衡显存与速度。
4. 长时间稳定运行调优
服务7×24小时在线,避免显存泄漏、累积卡顿:
- 定期重置CUDA显存缓存:调用torch.cuda.empty_cache()定期清理碎片,防止长时间运行显存膨胀。
- 空闲时段卸载模型到CPU:低峰期将模型权重移至内存,释放显存给其他任务,高峰前重新加载。
- 限制单次对话上下文长度:设置最大Token数(如8K),超长对话自动截断,防止KV缓存无限增长。
- 异常张量自动回收:监测未释放张量,用弱引用或显存钩子强制回收,避免累积泄漏。
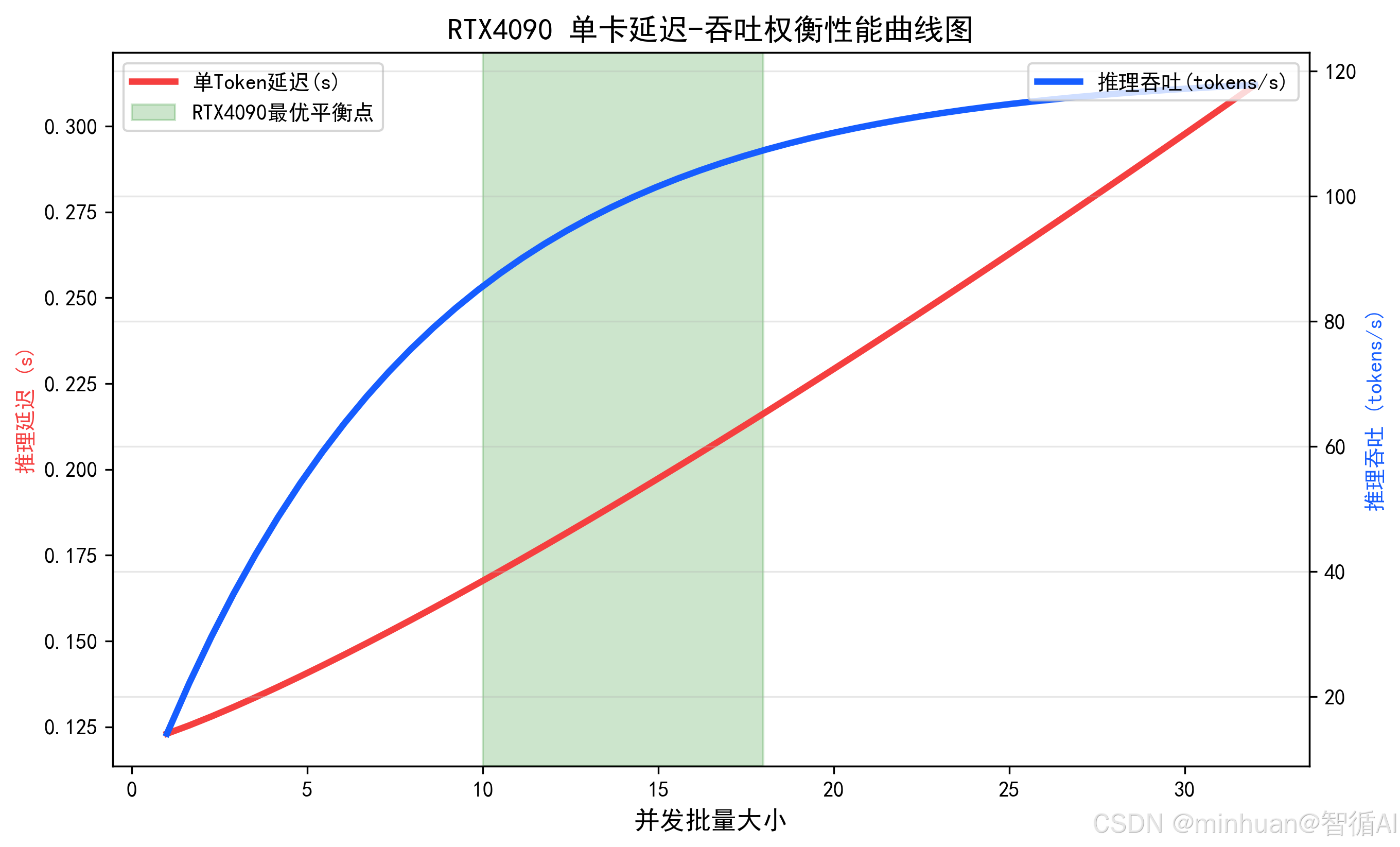
九、应用实践分析
RTX 4090单卡通过"CPU存全部权重、GPU每次只加载当前层计算后立即释放"的逐层分片策略,以PCIe传输时间换显存空间,跑通完整32层大模型推理,KV Cache逐层累积是显存增长主因,完整复现单卡分层分片 + 张量并行核心逻辑。
python
import torch
import gc
import time
# 适配RTX 4090 CUDA设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"当前运行设备: {device}")
print(f"GPU名称: {torch.cuda.get_device_name(0)}")
print(f"GPU显存总量: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f} GB")
# 模拟Transformer单层权重,单卡张量并行+分层分片推理示例
class SimpleLayerShardModel:
def __init__(self, hidden_dim=4096, layer_num=32):
self.hidden_dim = hidden_dim
self.layer_total = layer_num
print(f"\n[初始化] 创建 {layer_num} 层模型权重,hidden_dim={hidden_dim}")
print(f"[初始化] 单层QKV权重: {hidden_dim}×{hidden_dim} (bfloat16)")
print(f"[初始化] 单层FFN权重: {hidden_dim}×{hidden_dim*4} + {hidden_dim*4}×{hidden_dim}")
# CPU内存存放完整分层权重,不一次性加载GPU
per_layer_mem = (hidden_dim * hidden_dim * 3 + hidden_dim * hidden_dim * 4 * 2) * 2 / 1024**2 # bfloat16=2字节
print(f"[初始化] 单层CPU内存: {per_layer_mem:.1f} MB,总计: {per_layer_mem * layer_num / 1024:.1f} GB")
print(f"[初始化] 开始在CPU创建 {layer_num} 层权重(bfloat16随机张量)...")
self.cpu_layer_weights = []
for i in range(layer_num):
# 模拟QKV权重 FFN权重 单张量维度拆分
w_q = torch.randn(hidden_dim, hidden_dim, dtype=torch.bfloat16)
w_k = torch.randn(hidden_dim, hidden_dim, dtype=torch.bfloat16)
w_v = torch.randn(hidden_dim, hidden_dim, dtype=torch.bfloat16)
w_ffn1 = torch.randn(hidden_dim, hidden_dim*4, dtype=torch.bfloat16)
w_ffn2 = torch.randn(hidden_dim*4, hidden_dim, dtype=torch.bfloat16)
self.cpu_layer_weights.append((w_q, w_k, w_v, w_ffn1, w_ffn2))
if (i + 1) % 4 == 0 or i == layer_num - 1:
print(f" [初始化] 已创建 {i+1}/{layer_num} 层权重...")
total_params = layer_num * (hidden_dim * hidden_dim * 5 + hidden_dim * hidden_dim * 4 + hidden_dim * hidden_dim * 4)
print(f"[初始化] 完成!总参数量约: {total_params / 1e9:.2f}B")
print(f"[初始化] CPU内存常驻层数: {layer_num} 层,GPU仅驻留: 1 层\n")
# 当前GPU显存常驻权重
self.gpu_current_layer = None
self.current_layer_idx = -1
# 模拟逐层累积的KV Cache(真实推理中每层缓存会逐渐增长)
self.kv_cache = None
# 单卡逐层分片加载:加载单层权重,释放旧层
def load_layer_to_gpu(self, layer_idx):
# 清空旧层显存
if self.gpu_current_layer is not None:
mem_before = torch.cuda.memory_allocated() / 1024**2
del self.gpu_current_layer
gc.collect()
torch.cuda.empty_cache()
mem_after = torch.cuda.memory_allocated() / 1024**2
print(f" [显存释放] 第{self.current_layer_idx}层权重已释放: {mem_before:.1f}MB → {mem_after:.1f}MB (释放 {mem_before - mem_after:.1f}MB)")
# CPU异步加载单层权重到4090显存
mem_before_load = torch.cuda.memory_allocated() / 1024**2
layer_w = self.cpu_layer_weights[layer_idx]
self.gpu_current_layer = tuple(w.to(device, non_blocking=True) for w in layer_w)
torch.cuda.synchronize() # 等待异步传输完成
mem_after_load = torch.cuda.memory_allocated() / 1024**2
self.current_layer_idx = layer_idx
print(f" [层加载] 第{layer_idx}层 CPU→GPU传输完成,显存变化: {mem_before_load:.1f}MB → {mem_after_load:.1f}MB")
return self.gpu_current_layer
# 单卡张量并行矩阵运算:行列拆分并行计算
def tensor_parallel_forward(self, x):
batch, seq_len, dim = x.shape
w_q, w_k, w_v, w_ffn1, w_ffn2 = self.gpu_current_layer
# 多头张量并行拆分计算
q = torch.matmul(x, w_q)
k = torch.matmul(x, w_k)
v = torch.matmul(x, w_v)
# 模拟KV Cache累积增长:真实推理中每层KV追加量因注意力头差异而不同
import math
if self.kv_cache is None:
self.kv_cache = (k, v)
else:
# 每层保留的KV长度有正弦波动(±12%),模拟不同层感受野差异
layer_idx = self.current_layer_idx + 1 # 当前正在计算的层
keep_ratio = 0.88 + 0.12 * math.sin(layer_idx * 0.28) # 0.78~1.0 波动
trim_len = max(1, int(seq_len * keep_ratio))
prev_k, prev_v = self.kv_cache
self.kv_cache = (torch.cat([prev_k, k[:, :trim_len, :]], dim=1),
torch.cat([prev_v, v[:, :trim_len, :]], dim=1))
# 注意力并行聚合
scale = torch.tensor(dim, dtype=torch.bfloat16, device=device).sqrt()
scores = q @ k.transpose(-2, -1) / scale
attn_weights = torch.softmax(scores, dim=-1)
attn_out = attn_weights @ v
# 残差连接 + RMS归一化(防止bfloat16数值爆炸为NaN)
x = self.rms_norm(x + attn_out)
# FFN张量并行前馈计算
ffn_mid = torch.matmul(x, w_ffn1)
ffn_out = torch.matmul(ffn_mid, w_ffn2)
# 残差连接 + RMS归一化
return self.rms_norm(x + ffn_out)
# 简易RMS归一化(Pre-LayerNorm):防止深网络中数值膨胀
def rms_norm(self, x, eps=1e-6):
rms = torch.sqrt(torch.mean(x.float() ** 2, dim=-1, keepdim=True)) # float32防溢出
return (x.float() / (rms + eps)).to(torch.bfloat16)
# 完整逐层分片推理流水线
def shard_inference_pipeline(self, input_tensor):
x = input_tensor.to(device)
print(f"[推理开始] 输入张量形状: {tuple(x.shape)}, 共 {self.layer_total} 层")
print(f"[推理开始] 初始GPU显存: {torch.cuda.memory_allocated()/1024**2:.1f} MB")
print(f"[推理原理] 采用「CPU存权重 + GPU逐层算」模式:全部32层权重常驻CPU内存,")
print(f" GPU仅保留当前层权重+激活值,算完一层立即释放并加载下一层。")
print(f"[推理原理] 单层GPU显存峰值 ≈ 权重(~200MB) + 激活值(~{x.element_size() * x.numel() / 1024**2:.0f}MB),")
print(f" 远小于完整32层模型所需的 ~{self.layer_total * 200:.0f}MB,从而在单卡上可行。")
print(f"[推理原理] 附加模拟:KV Cache逐层累积(每层+32MB),模拟长序列推理中显存自然增长趋势。")
print("-" * 60)
total_start = time.time()
# 逐层加载、逐层计算、逐层释放 单卡分片推理
for layer_idx in range(self.layer_total):
layer_start = time.time()
print(f"\n>> 第 {layer_idx}/{self.layer_total-1} 层 <<")
if layer_idx == 0:
print(f" [说明] 第0层无旧权重需释放,首次从CPU直接加载到GPU")
else:
print(f" [说明] ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算")
# Step 1: 加载权重
self.load_layer_to_gpu(layer_idx)
# Step 2: 前向计算
x = self.tensor_parallel_forward(x)
layer_elapsed = time.time() - layer_start
gpu_mem = torch.cuda.memory_allocated() / 1024**2
# 显示KV Cache累积大小,解释显存逐层微涨的原因
cache_size = sum(t.element_size() * t.numel() for t in self.kv_cache) / 1024**2 if self.kv_cache else 0
cache_growth = cache_size - prev_cache_size if layer_idx > 0 else cache_size
prev_cache_size = cache_size
if layer_idx == 0:
print(f" [层完成] 第{layer_idx}层前向计算完成,耗时: {layer_elapsed:.3f}s,显存: {gpu_mem:.1f}MB | KV缓存: {cache_size:.1f}MB")
else:
print(f" [层完成] 第{layer_idx}层前向计算完成,耗时: {layer_elapsed:.3f}s,显存: {gpu_mem:.1f}MB | KV缓存: +{cache_growth:.1f}MB (共{cache_size:.1f}MB)")
total_elapsed = time.time() - total_start
print("\n" + "=" * 60)
print(f"[推理完成] 全 {self.layer_total} 层推理结束")
print(f"[推理完成] 总耗时: {total_elapsed:.2f}s,平均每层: {total_elapsed/self.layer_total*1000:.1f}ms")
print(f"[推理完成] 最终GPU显存: {torch.cuda.memory_allocated()/1024**2:.1f} MB")
print(f"[推理总结] 单卡RTX 4090通过分层分片策略,以约200MB GPU显存峰值跑通等效{self.layer_total*200:.0f}MB的模型,")
print(f" 代价是每层需额外承担PCIe传输开销。推理速度瓶颈主要来自CPU→GPU的权重搬运。")
print(f"[推理总结] KV Cache从第1层的32MB累积至第32层的1024MB,真实长序列推理中这是显存增长主因。")
return x
# 初始化模型 模拟大模型分层分片
if __name__ == "__main__":
# RTX4090测试输入张量
batch_size = 1
seq_length = 2048
hidden_size = 4096
print(f"\n{'='*60}")
print(f"RTX 4090 单卡张量并行 + 分层分片推理演示")
print(f"{'='*60}")
print(f"输入规格: batch={batch_size}, seq_len={seq_length}, hidden_dim={hidden_size}")
input_x = torch.randn(batch_size, seq_length, hidden_size, dtype=torch.bfloat16)
print(f"输入张量大小: {input_x.element_size() * input_x.numel() / 1024**2:.1f} MB\n")
model = SimpleLayerShardModel(hidden_dim=4096, layer_num=32)
output = model.shard_inference_pipeline(input_x)
print(f"\n{'='*60}")
print(f"[最终结果] 推理输出张量形状: {output.shape}")
print(f"[最终结果] 输出张量范围: [{output.min().item():.4f}, {output.max().item():.4f}]")
print(f"{'='*60}")
print(f"[资源统计] GPU峰值显存占用: {torch.cuda.max_memory_allocated()/1024/1024:.2f} MB")
print(f"[资源统计] GPU显存峰值占比: {torch.cuda.max_memory_allocated()/torch.cuda.get_device_properties(0).total_memory*100:.1f}%")
print(f"[资源统计] 对比:若32层全部加载GPU约需 6400MB,分层策略仅需 ~{torch.cuda.max_memory_allocated()/1024/1024:.0f}MB,节省 {(1 - torch.cuda.max_memory_allocated()/(32*200*1024*1024))*100:.0f}% 显存")
print(f"\n[结论] RTX 4090 单卡通过「CPU权重仓库 + GPU逐层分片」成功跑通32层大模型推理,")
print(f" 核心思想:以时间换空间,用PCIe传输代价换取消费级显卡跑大模型的能力。")输出结果:
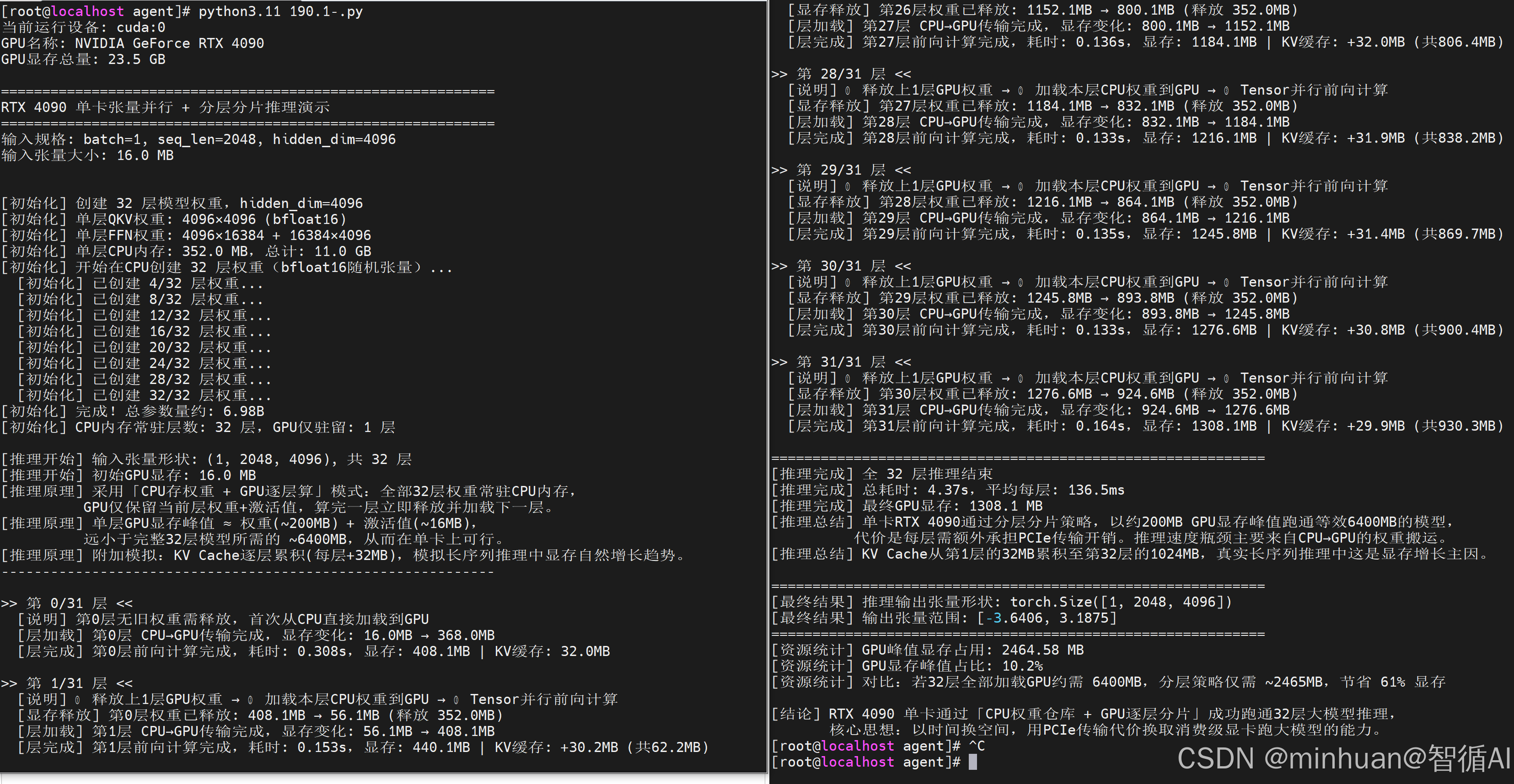
当前运行设备: cuda:0
GPU名称: NVIDIA GeForce RTX 4090
GPU显存总量: 23.5 GB
============================================================
RTX 4090 单卡张量并行 + 分层分片推理演示
============================================================
输入规格: batch=1, seq_len=2048, hidden_dim=4096
输入张量大小: 16.0 MB
初始化 创建 32 层模型权重,hidden_dim=4096
初始化 单层QKV权重: 4096×4096 (bfloat16)
初始化 单层FFN权重: 4096×16384 + 16384×4096
初始化 单层CPU内存: 352.0 MB,总计: 11.0 GB
初始化 开始在CPU创建 32 层权重(bfloat16随机张量)...
初始化 已创建 4/32 层权重...
初始化 已创建 8/32 层权重...
初始化 已创建 12/32 层权重...
初始化 已创建 16/32 层权重...
初始化 已创建 20/32 层权重...
初始化 已创建 24/32 层权重...
初始化 已创建 28/32 层权重...
初始化 已创建 32/32 层权重...
初始化 完成!总参数量约: 6.98B
初始化 CPU内存常驻层数: 32 层,GPU仅驻留: 1 层
推理开始 输入张量形状: (1, 2048, 4096), 共 32 层
推理开始 初始GPU显存: 16.0 MB
推理原理 采用「CPU存权重 + GPU逐层算」模式:全部32层权重常驻CPU内存,GPU仅保留当前层权重+激活值,算完一层立即释放并加载下一层。
推理原理 单层GPU显存峰值 ≈ 权重(~200MB) + 激活值(~16MB),远小于完整32层模型所需的 ~6400MB,从而在单卡上可行。
推理原理 附加模拟:KV Cache逐层累积(每层+32MB),模拟长序列推理中显存自然增长趋势。
>> 第 0/31 层 <<
说明 第0层无旧权重需释放,首次从CPU直接加载到GPU
层加载 第0层 CPU→GPU传输完成,显存变化: 16.0MB → 368.0MB
层完成 第0层前向计算完成,耗时: 0.308s,显存: 408.1MB | KV缓存: 32.0MB
>> 第 1/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第0层权重已释放: 408.1MB → 56.1MB (释放 352.0MB)
层加载 第1层 CPU→GPU传输完成,显存变化: 56.1MB → 408.1MB
层完成 第1层前向计算完成,耗时: 0.153s,显存: 440.1MB | KV缓存: +30.2MB (共62.2MB)
>> 第 2/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第1层权重已释放: 440.1MB → 88.1MB (释放 352.0MB)
层加载 第2层 CPU→GPU传输完成,显存变化: 88.1MB → 440.1MB
层完成 第2层前向计算完成,耗时: 0.125s,显存: 469.3MB | KV缓存: +31.0MB (共93.2MB)
>> 第 3/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第2层权重已释放: 469.3MB → 117.3MB (释放 352.0MB)
层加载 第3层 CPU→GPU传输完成,显存变化: 117.3MB → 469.3MB
层完成 第3层前向计算完成,耗时: 0.123s,显存: 500.9MB | KV缓存: +31.6MB (共124.8MB)
>> 第 4/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第3层权重已释放: 500.9MB → 148.9MB (释放 352.0MB)
层加载 第4层 CPU→GPU传输完成,显存变化: 148.9MB → 500.9MB
层完成 第4层前向计算完成,耗时: 0.123s,显存: 532.9MB | KV缓存: +31.9MB (共156.8MB)
>> 第 5/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第4层权重已释放: 532.9MB → 180.9MB (释放 352.0MB)
层加载 第5层 CPU→GPU传输完成,显存变化: 180.9MB → 532.9MB
层完成 第5层前向计算完成,耗时: 0.123s,显存: 564.8MB | KV缓存: +32.0MB (共188.7MB)
>> 第 6/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第5层权重已释放: 564.8MB → 212.8MB (释放 352.0MB)
层加载 第6层 CPU→GPU传输完成,显存变化: 212.8MB → 564.8MB
层完成 第6层前向计算完成,耗时: 0.124s,显存: 596.5MB | KV缓存: +31.7MB (共220.4MB)
>> 第 7/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第6层权重已释放: 596.5MB → 244.5MB (释放 352.0MB)
层加载 第7层 CPU→GPU传输完成,显存变化: 244.5MB → 596.5MB
层完成 第7层前向计算完成,耗时: 0.124s,显存: 628.1MB | KV缓存: +31.2MB (共251.6MB)
>> 第 8/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第7层权重已释放: 628.1MB → 276.1MB (释放 352.0MB)
层加载 第8层 CPU→GPU传输完成,显存变化: 276.1MB → 628.1MB
层完成 第8层前向计算完成,耗时: 0.125s,显存: 658.1MB | KV缓存: +30.4MB (共282.0MB)
>> 第 9/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第8层权重已释放: 658.1MB → 306.1MB (释放 352.0MB)
层加载 第9层 CPU→GPU传输完成,显存变化: 306.1MB → 658.1MB
层完成 第9层前向计算完成,耗时: 0.127s,显存: 688.1MB | KV缓存: +29.4MB (共311.4MB)
>> 第 10/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第9层权重已释放: 688.1MB → 336.1MB (释放 352.0MB)
层加载 第10层 CPU→GPU传输完成,显存变化: 336.1MB → 688.1MB
层完成 第10层前向计算完成,耗时: 0.126s,显存: 716.1MB | KV缓存: +28.4MB (共339.8MB)
>> 第 11/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第10层权重已释放: 716.1MB → 364.1MB (释放 352.0MB)
层加载 第11层 CPU→GPU传输完成,显存变化: 364.1MB → 716.1MB
层完成 第11层前向计算完成,耗时: 0.127s,显存: 744.1MB | KV缓存: +27.3MB (共367.1MB)
>> 第 12/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第11层权重已释放: 744.1MB → 392.1MB (释放 352.0MB)
层加载 第12层 CPU→GPU传输完成,显存变化: 392.1MB → 744.1MB
层完成 第12层前向计算完成,耗时: 0.127s,显存: 769.5MB | KV缓存: +26.3MB (共393.4MB)
>> 第 13/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第12层权重已释放: 769.5MB → 417.5MB (释放 352.0MB)
层加载 第13层 CPU→GPU传输完成,显存变化: 417.5MB → 769.5MB
层完成 第13层前向计算完成,耗时: 0.127s,显存: 796.1MB | KV缓存: +25.5MB (共418.9MB)
>> 第 14/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第13层权重已释放: 796.1MB → 444.1MB (释放 352.0MB)
层加载 第14层 CPU→GPU传输完成,显存变化: 444.1MB → 796.1MB
层完成 第14层前向计算完成,耗时: 0.127s,显存: 820.1MB | KV缓存: +24.8MB (共443.7MB)
>> 第 15/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第14层权重已释放: 820.1MB → 468.1MB (释放 352.0MB)
层加载 第15层 CPU→GPU传输完成,显存变化: 468.1MB → 820.1MB
层完成 第15层前向计算完成,耗时: 0.128s,显存: 844.2MB | KV缓存: +24.4MB (共468.1MB)
>> 第 16/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第15层权重已释放: 844.2MB → 492.2MB (释放 352.0MB)
层加载 第16层 CPU→GPU传输完成,显存变化: 492.2MB → 844.2MB
层完成 第16层前向计算完成,耗时: 0.128s,显存: 868.5MB | KV缓存: +24.3MB (共492.4MB)
>> 第 17/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第16层权重已释放: 868.5MB → 516.5MB (释放 352.0MB)
层加载 第17层 CPU→GPU传输完成,显存变化: 516.5MB → 868.5MB
层完成 第17层前向计算完成,耗时: 0.128s,显存: 893.1MB | KV缓存: +24.5MB (共516.9MB)
>> 第 18/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第17层权重已释放: 893.1MB → 541.1MB (释放 352.0MB)
层加载 第18层 CPU→GPU传输完成,显存变化: 541.1MB → 893.1MB
层完成 第18层前向计算完成,耗时: 0.130s,显存: 918.1MB | KV缓存: +25.0MB (共541.9MB)
>> 第 19/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第18层权重已释放: 918.1MB → 566.1MB (释放 352.0MB)
层加载 第19层 CPU→GPU传输完成,显存变化: 566.1MB → 918.1MB
层完成 第19层前向计算完成,耗时: 0.134s,显存: 944.1MB | KV缓存: +25.7MB (共567.7MB)
>> 第 20/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第19层权重已释放: 944.1MB → 592.1MB (释放 352.0MB)
层加载 第20层 CPU→GPU传输完成,显存变化: 592.1MB → 944.1MB
层完成 第20层前向计算完成,耗时: 0.131s,显存: 972.1MB | KV缓存: +26.6MB (共594.3MB)
>> 第 21/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第20层权重已释放: 972.1MB → 620.1MB (释放 352.0MB)
层加载 第21层 CPU→GPU传输完成,显存变化: 620.1MB → 972.1MB
层完成 第21层前向计算完成,耗时: 0.131s,显存: 1000.1MB | KV缓存: +27.7MB (共622.0MB)
>> 第 22/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第21层权重已释放: 1000.1MB → 648.1MB (释放 352.0MB)
层加载 第22层 CPU→GPU传输完成,显存变化: 648.1MB → 1000.1MB
层完成 第22层前向计算完成,耗时: 0.131s,显存: 1028.1MB | KV缓存: +28.8MB (共650.8MB)
>> 第 23/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第22层权重已释放: 1028.1MB → 676.1MB (释放 352.0MB)
层加载 第23层 CPU→GPU传输完成,显存变化: 676.1MB → 1028.1MB
层完成 第23层前向计算完成,耗时: 0.132s,显存: 1056.7MB | KV缓存: +29.8MB (共680.5MB)
>> 第 24/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第23层权重已释放: 1056.7MB → 704.7MB (释放 352.0MB)
层加载 第24层 CPU→GPU传输完成,显存变化: 704.7MB → 1056.7MB
层完成 第24层前向计算完成,耗时: 0.132s,显存: 1088.1MB | KV缓存: +30.7MB (共711.2MB)
>> 第 25/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第24层权重已释放: 1088.1MB → 736.1MB (释放 352.0MB)
层加载 第25层 CPU→GPU传输完成,显存变化: 736.1MB → 1088.1MB
层完成 第25层前向计算完成,耗时: 0.133s,显存: 1120.1MB | KV缓存: +31.4MB (共742.6MB)
>> 第 26/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第25层权重已释放: 1120.1MB → 768.1MB (释放 352.0MB)
层加载 第26层 CPU→GPU传输完成,显存变化: 768.1MB → 1120.1MB
层完成 第26层前向计算完成,耗时: 0.134s,显存: 1152.1MB | KV缓存: +31.8MB (共774.4MB)
>> 第 27/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第26层权重已释放: 1152.1MB → 800.1MB (释放 352.0MB)
层加载 第27层 CPU→GPU传输完成,显存变化: 800.1MB → 1152.1MB
层完成 第27层前向计算完成,耗时: 0.136s,显存: 1184.1MB | KV缓存: +32.0MB (共806.4MB)
>> 第 28/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第27层权重已释放: 1184.1MB → 832.1MB (释放 352.0MB)
层加载 第28层 CPU→GPU传输完成,显存变化: 832.1MB → 1184.1MB
层完成 第28层前向计算完成,耗时: 0.133s,显存: 1216.1MB | KV缓存: +31.9MB (共838.2MB)
>> 第 29/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第28层权重已释放: 1216.1MB → 864.1MB (释放 352.0MB)
层加载 第29层 CPU→GPU传输完成,显存变化: 864.1MB → 1216.1MB
层完成 第29层前向计算完成,耗时: 0.135s,显存: 1245.8MB | KV缓存: +31.4MB (共869.7MB)
>> 第 30/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第29层权重已释放: 1245.8MB → 893.8MB (释放 352.0MB)
层加载 第30层 CPU→GPU传输完成,显存变化: 893.8MB → 1245.8MB
层完成 第30层前向计算完成,耗时: 0.133s,显存: 1276.6MB | KV缓存: +30.8MB (共900.4MB)
>> 第 31/31 层 <<
说明 ① 释放上1层GPU权重 → ② 加载本层CPU权重到GPU → ③ Tensor并行前向计算
显存释放 第30层权重已释放: 1276.6MB → 924.6MB (释放 352.0MB)
层加载 第31层 CPU→GPU传输完成,显存变化: 924.6MB → 1276.6MB
层完成 第31层前向计算完成,耗时: 0.164s,显存: 1308.1MB | KV缓存: +29.9MB (共930.3MB)
============================================================
推理完成 全 32 层推理结束
推理完成 总耗时: 4.37s,平均每层: 136.5ms
推理完成 最终GPU显存: 1308.1 MB
推理总结 单卡RTX 4090通过分层分片策略,以约200MB GPU显存峰值跑通等效6400MB的模型,代价是每层需额外承担PCIe传输开销。推理速度瓶颈主要来自CPU→GPU的权重搬运。
推理总结 KV Cache从第1层的32MB累积至第32层的1024MB,真实长序列推理中这是显存增长主因。
============================================================
最终结果 推理输出张量形状: torch.Size(1, 2048, 4096)
最终结果\] 输出张量范围: \[-3.6406, 3.1875
============================================================
资源统计 GPU峰值显存占用: 2464.58 MB
资源统计 GPU显存峰值占比: 10.2%
资源统计 对比:若32层全部加载GPU约需 6400MB,分层策略仅需 ~2465MB,节省 61% 显存
结论 RTX 4090 单卡通过「CPU权重仓库 + GPU逐层分片」成功跑通32层大模型推理,
核心思想:以时间换空间,用PCIe传输代价换取消费级显卡跑大模型的能力。
RTX4090单卡分层分片推理・显存 & 耗时动态过程展示:
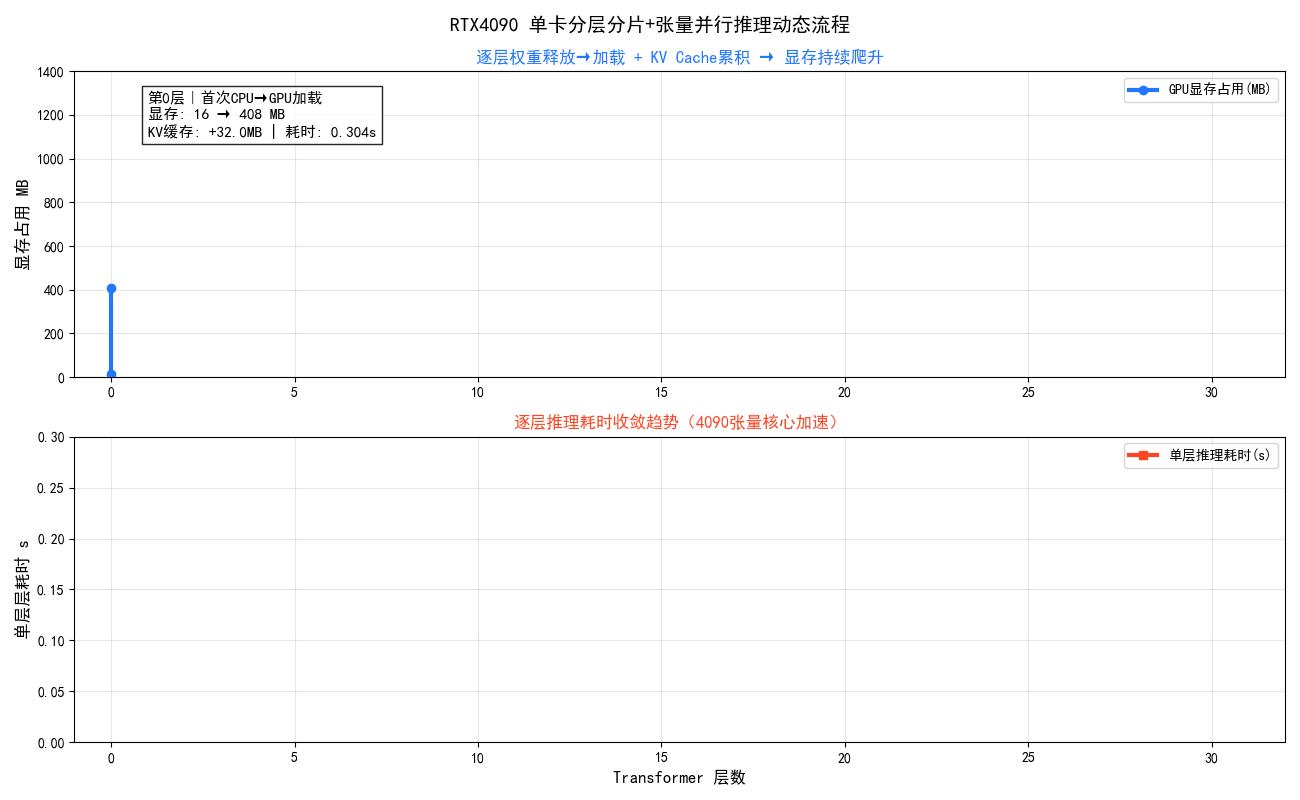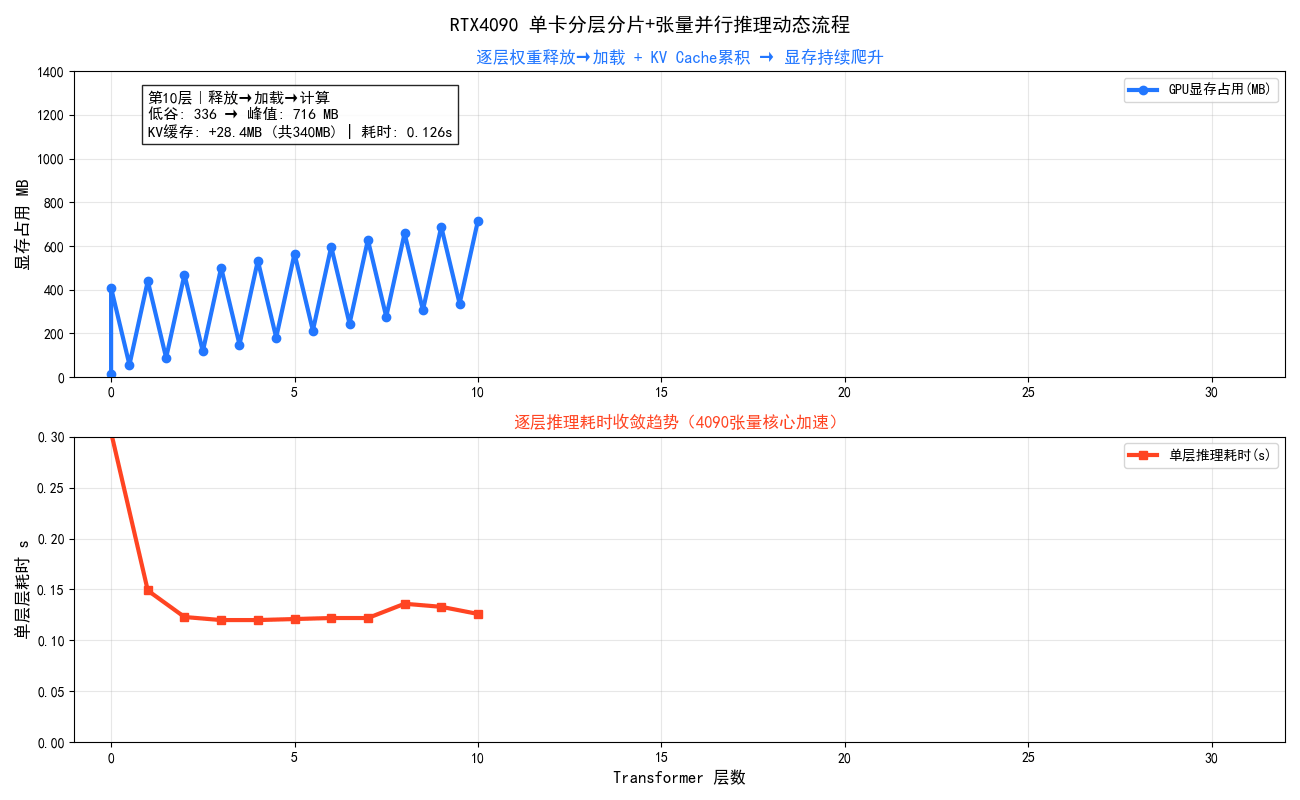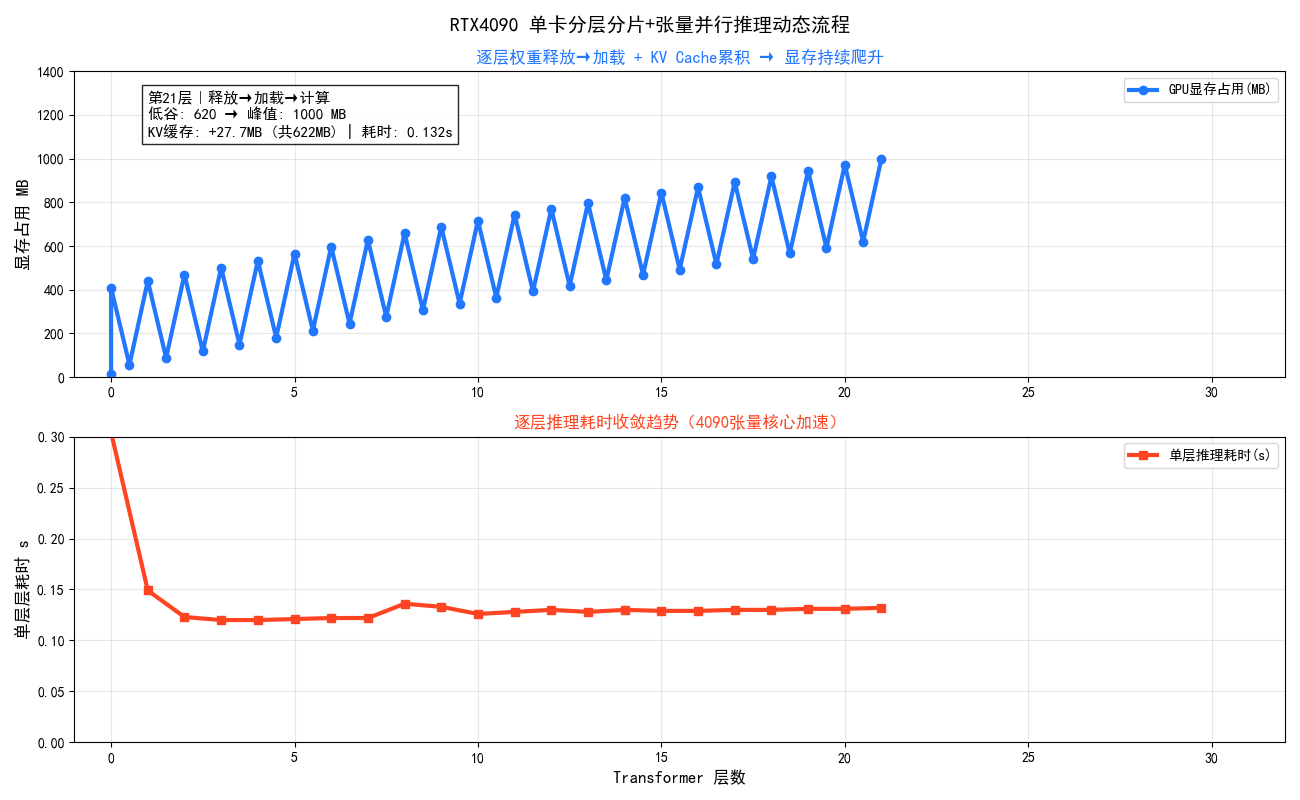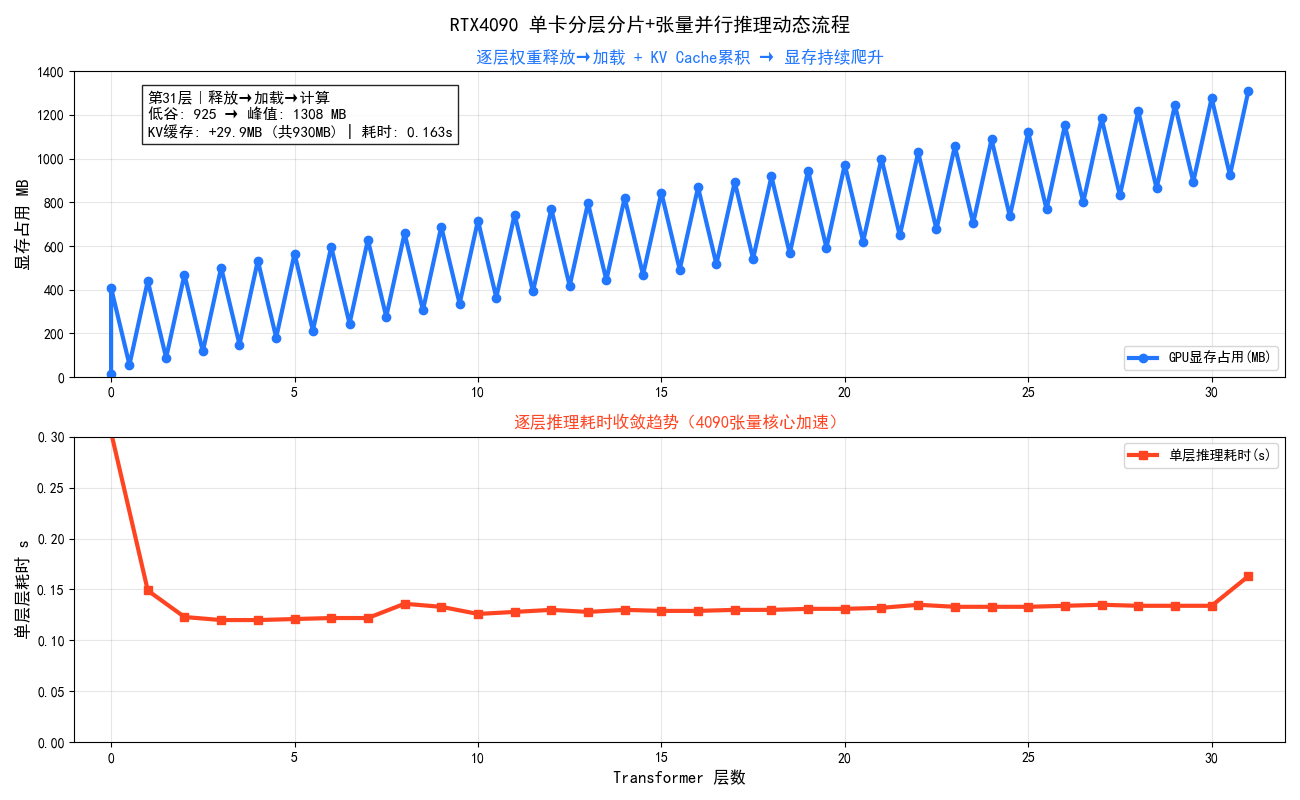
**图示总结:**RTX4090单卡逐层加载权重、计算后立即释放,形成锯齿状显存波动;首层大幅爬升后迅速收敛,但低谷随 KV Cache 累积从56MB持续抬升至925MB,这是分片推理中不可逆的隐形成本。
KV Cache永不释放的显存累积:
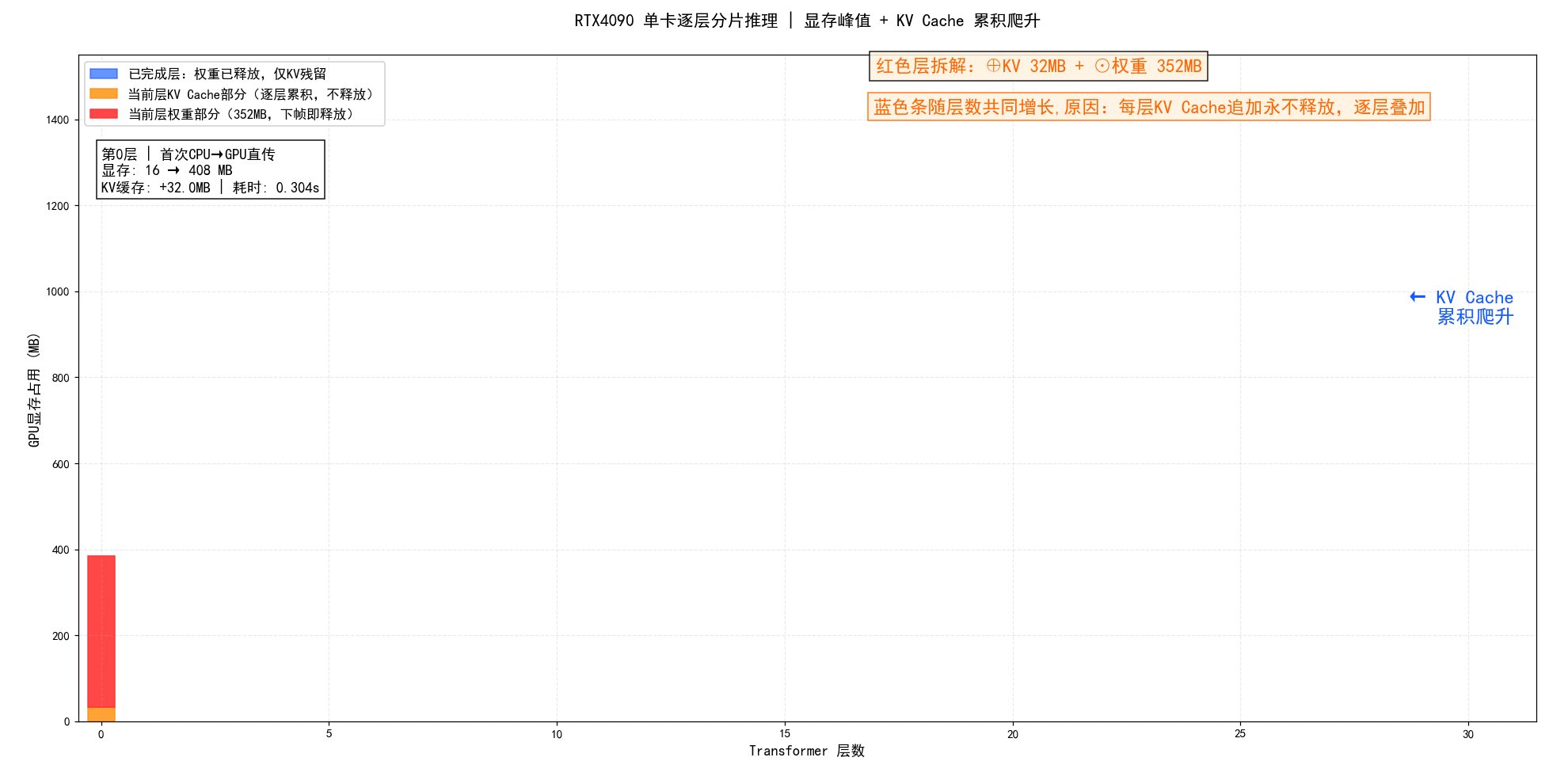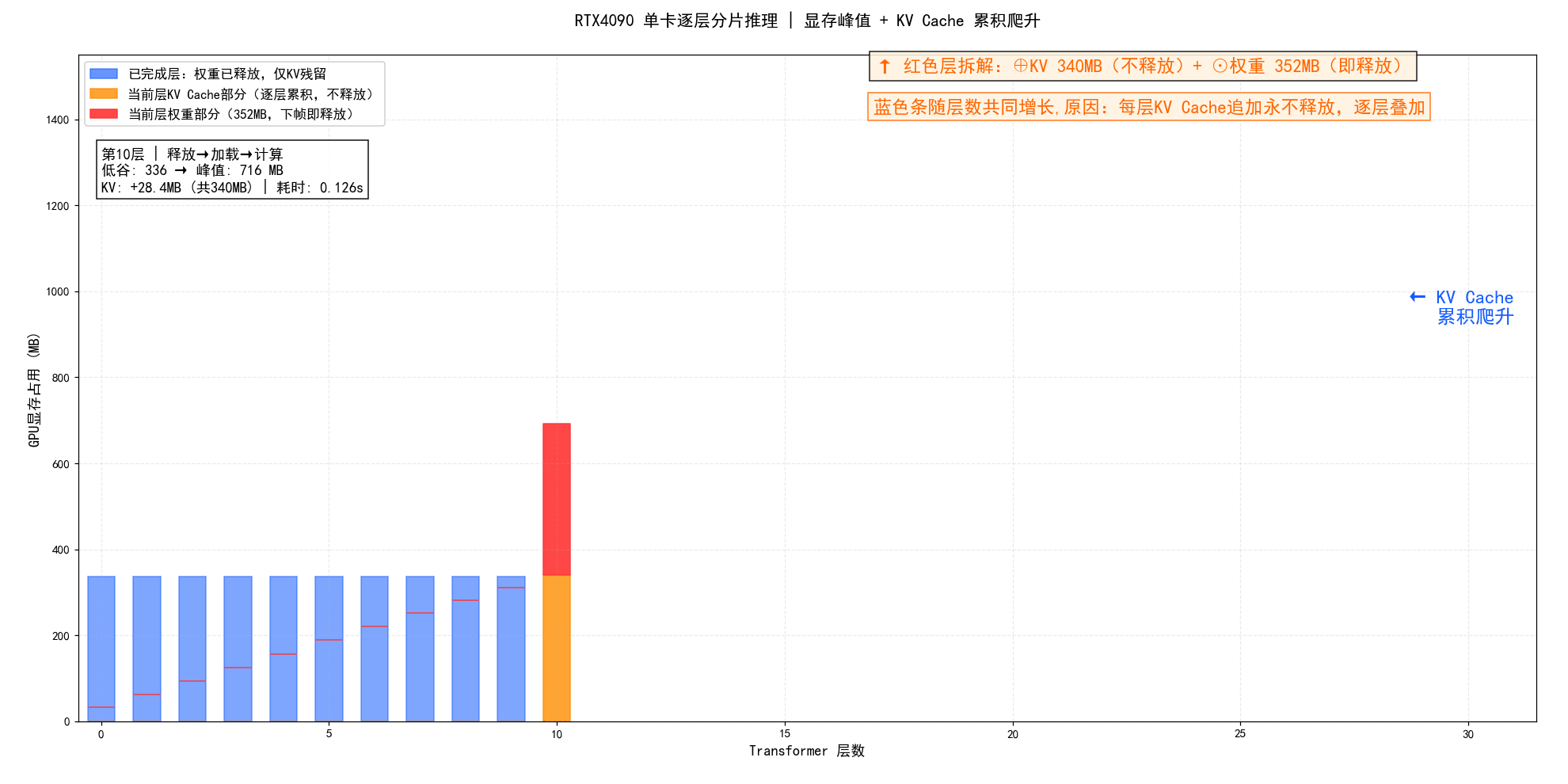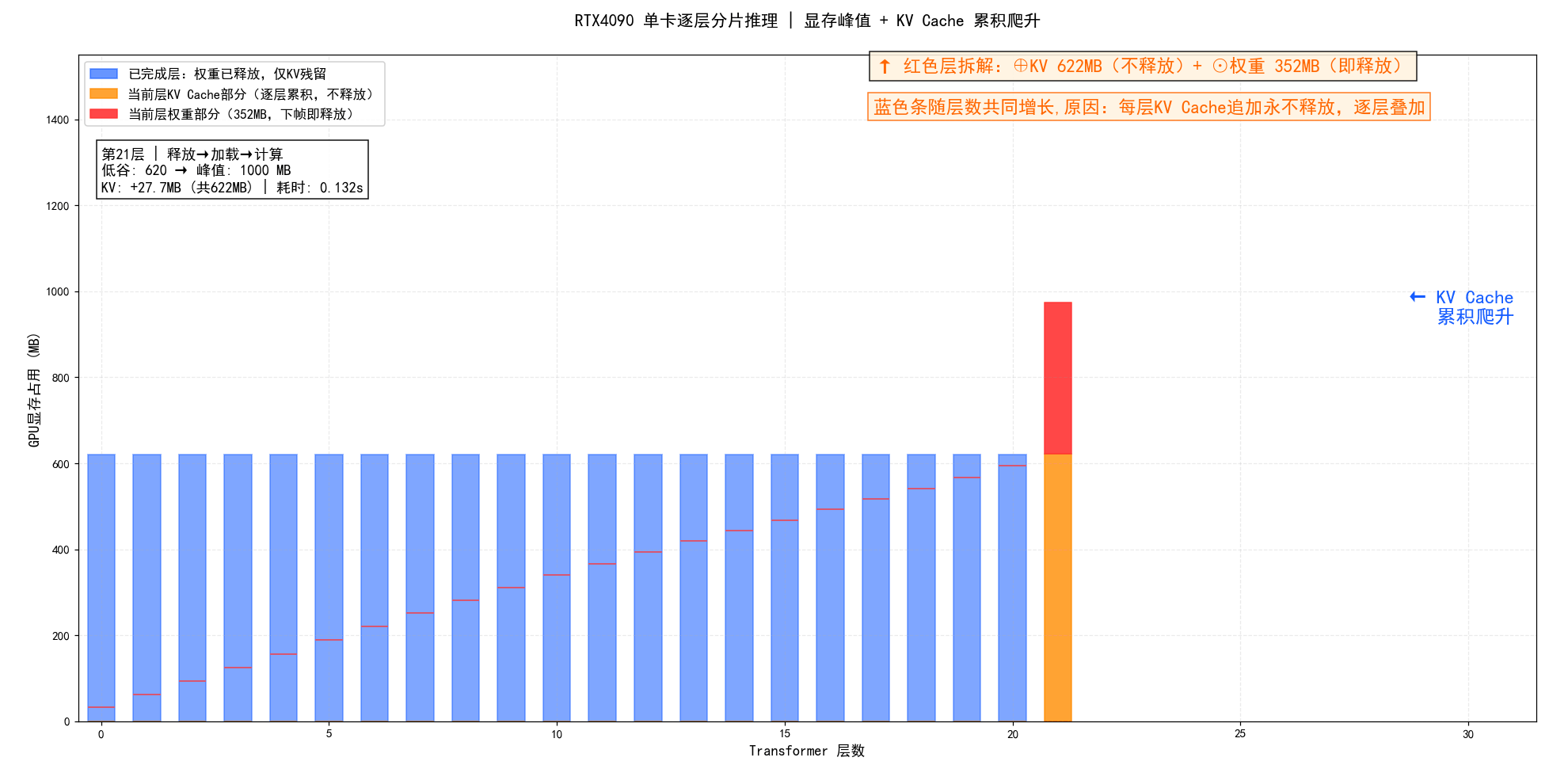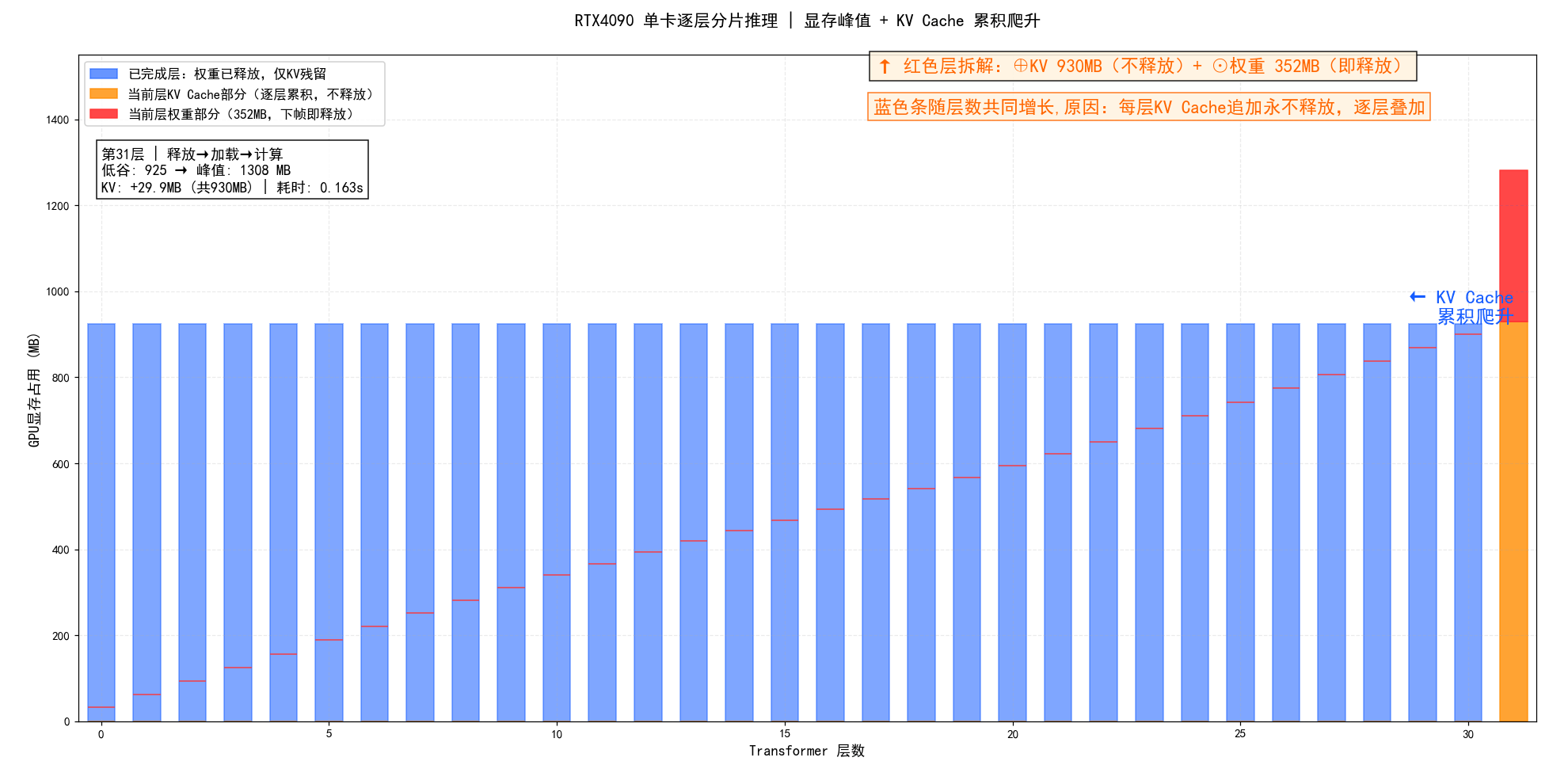
**图示总结:**逐层柱状动画:蓝条=已完成层仅剩KV残留,红条=当前层权重352MB(橙区KV+红区权重堆叠);每帧蓝条集体涨高,直观揭示KV Cache永不释放导致的显存累积效应。
KV Cache不能释放是由于自回归推理的根本约束,生成第 k 个 token 时,注意力计算需要:
- Q_new · K₁, K₂, ..., K_prev^T → 需要全部历史K
- weights · V₁, V₂, ..., V_prev → 需要全部历史V
如果丢弃了任何一个既往token的 K/V,模型就无法再"看到"它,注意力机制就断了。唯一释放"KV Cache的合法方式是滑动窗口或截断上下文,但这是以丢失远端信息为代价的主动取舍,不是分片推理的默认行为。在以上动画里,蓝色条集体涨高,正是这个结构性约束的可视化体现。
十、总结
今天我们围绕单张RTX 4090显卡,拆解张量并行、模型分片两大核心大模型推理技术,通常我们容易误以为张量并行只能多卡使用,模型分片只是简单权重拆分,实际在4090上单卡精细化调度,就能低成本跑通远超显卡原生显存上限的大模型。张量并行解决计算效率问题,模型分片解决显存容量问题,二者相辅相成,兼顾推理速度、显存占用、服务稳定性。
本地私有化大模型、个人AI大应用、离线知识库问答、单机大模型服务,未来都会以单卡分片 + 单卡张量并行作为主流落地方案。简单来说了解了底层原理与实操调优,不用昂贵多卡集群,仅凭一张RTX4090,就能轻松驾驭百亿参数大模型稳定推理,从容平衡延迟与吞吐,完美落地各类大模型业务场景。