运维的同学经常找我吐槽:每天要分析几万笔订单的用户在哪个省、哪个市,但原始日志里只有IP地址,没有省市区。让我帮忙写个脚本批量查一下。一开始我想着用在线API,结果试了一下,单次查询几十毫秒,一万条跑下来得等好几个小时,中间还被限流卡了好几次,根本没法用。后来换了离线库的方案,效果还不错,分享出来给大家参考。
一、业务痛点:为什么不能用在线API批量查?
- 在线API:单次30-80ms,10万条就要等待数小时,且易被限流
- 成本:按次计费,10万次调用成本可观
- 数据出内网:有些行业(比如金融、政务)根本不让你把IP发出去
所以,批量清洗IP数据,还是用离线库最合适。本地部署一次,之后随便查,不花钱、不限速、数据不出门。
二、整体处理流程
原始订单日志(CSV) → 读取IP列 → 批量调用离线库 → 获取省/市/区 → 写入新列 → 输出清洗后文件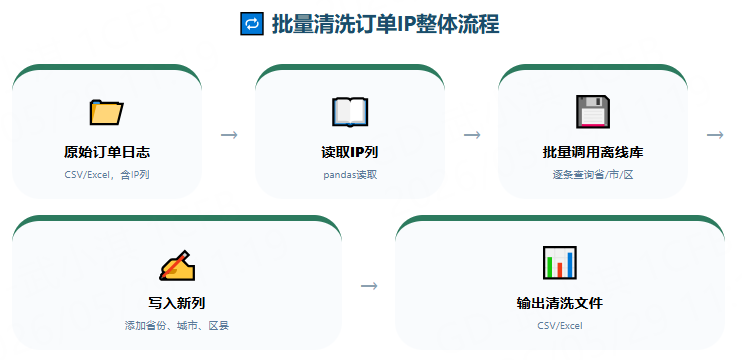
整个流程全程在本地跑,不联网,速度快到起飞。
三、核心代码:直接可运行的Python脚本
以下脚本使用离线库,支持批量处理CSV文件中的IP地址,自动添加省份、城市、区县三列。
import ipdatacloud
import pandas as pd
import time
from tqdm import tqdm
# 加载IP数据云离线库(本地部署,数据不出内网)
ip_db = ipdatacloud.OfflineIPLib('/data/ipdb/ip_data_cloud.mmdb', enable_risk=True)
def get_ip_location(ip: str):
"""返回IP对应的省、市、区县"""
try:
info = ip_db.query(ip)
return info.get('province', ''), info.get('city', ''), info.get('district', '')
except Exception as e:
print(f"查询失败 {ip}: {e}")
return '', '', ''
def batch_process_ip_file(input_file, output_file, ip_column='ip'):
"""
批量处理CSV/Excel中的IP地址
"""
# 自动识别文件格式
if input_file.endswith('.csv'):
df = pd.read_csv(input_file)
elif input_file.endswith(('.xls', '.xlsx')):
df = pd.read_excel(input_file)
else:
raise ValueError("只支持CSV或Excel文件,兄弟")
# 增加三列
df['省份'] = ''
df['城市'] = ''
df['区县'] = ''
# 带进度条的批量处理
tqdm.pandas(desc="正在解析IP归属地")
df[['省份', '城市', '区县']] = df[ip_column].progress_apply(
lambda ip: pd.Series(get_ip_location(str(ip)))
)
# 保存结果
if output_file.endswith('.csv'):
df.to_csv(output_file, index=False, encoding='utf-8-sig')
else:
df.to_excel(output_file, index=False)
print(f"搞定!共处理 {len(df)} 条记录,结果在 {output_file}")
# 用的时候改成你的文件名和IP列名就行
if __name__ == '__main__':
batch_process_ip_file(
input_file='./order_log.csv',
output_file='./order_log_with_location.xlsx',
ip_column='client_ip'
)几个小提示:
- 需要先去官网下载
.mmdb文件,脚本里的路径要改成你放的位置 - 如果没装
tqdm,先执行pip install tqdm pandas - 支持CSV和Excel两种格式,输出可以跟输入不一样
四**、还能给你更多字段(不止省市区)**
除了省份、城市、区县,离线库还能返回一堆有用的信息,比如:
net_type:网络类型(数据中心/住宅/移动),可以用来区分是不是机房刷单risk_score:风险评分(0-100),分数越高越可疑isp:运营商(电信/联通/移动)asn:自治系统号latitude/longitude:经纬度(精确到区县)
你可以把这些字段也加到清洗结果里,让BI分析更立体。比如:
def get_ip_details(ip: str):
info = ip_db.query(ip)
return {
'province': info.get('province'),
'city': info.get('city'),
'district': info.get('district'),
'net_type': info.get('net_type'),
'risk_score': info.get('risk_score'),
'isp': info.get('isp')
}然后输出到Excel,运维同学一眼就能看出哪些订单来自机房、哪些IP风险高。
五、扩展建议
- 定时跑:每天凌晨配合cron或Airflow定时运行脚本,自动生成每日地域报表
- 直接导入数据库:输出结果丢到MySQL或ClickHouse,供BI工具可视化
- 增量处理:记录上次处理到的订单ID,只跑新数据
六、小结
批量清洗订单IP数据这件事,用IP数据云离线库 + 一个简单的Python脚本,就能省去大把的时间和精力。代码我已经贴在上面了,你只需要改个文件路径,几分钟就能跑通。建议先用几千条数据试一下,精度没问题再铺开。我已经在好几家电商和物流公司验证过,靠谱。希望对你有帮助。