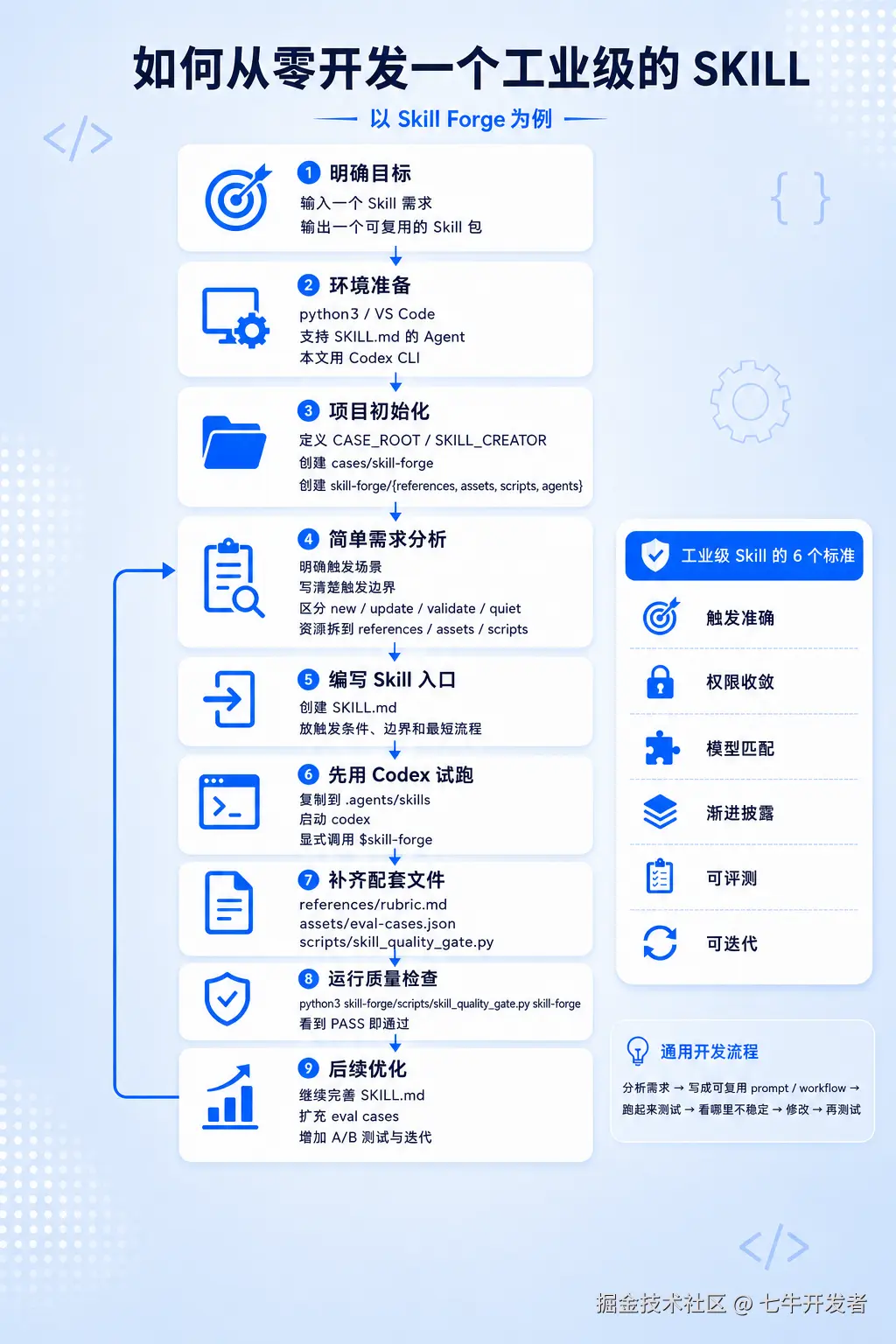
可能大家都听过 skill 这个东西,可能也用过。但是自己从未动手开发过一个 skill,本文主要是带你从一个空目录开始,做出一个可以被验证的 Skill 包。
我们要做的 Skill 叫 Skill Forge。它的用途不是处理某个具体业务任务,而是帮助我们创建、改进和检查其他 Skill。
你可以把它理解成一个"Skill 开发助手":当你想做一个新的 Skill,比如"会议记录转项目周报 Skill"时,Skill Forge 会帮助你明确触发条件、工作流程、参考材料、检查规则和评估方式。
工业级 SKILL 是什么
为什么管 Skill Forge 叫工业级 skill 呢?我们来说下工业级的标准:
-
触发准确:该用时再触发
-
权限收敛:只给必要权限
-
模型匹配:任务匹配模型
-
渐进披露:材料按需读取
-
可评测:能做验证测试
-
可迭代:能持续改进
简单来说,就是把一个好用的提示词,进一步做成可触发、可执行、可检查、可持续修改的工作流包。
实践流程
在开始之前,我们先过下一个通用的 skill 的常见开发流程。如下图所示:
Plain
分析需求 → 写成可复用 prompt/workflow → 跑起来测试 → 看哪里不稳定 → 修改 → 再测试简单来说,就是明确具体需求之后,写成可复用的 prompt 或者是 workflow,再通过支持 skill 功能的 agent 运行,看这个 skill 是否满足需求。再进一步迭代,优化。
下面,开始今天的实践:
具体实践过程
环境准备
你需要有:
-
一台能运行
python3的电脑;本文实践环境为:Python 3.14.5; -
一个可以编辑文件的工具,比如 VS Code;
-
一个可以运行 Skill 的 Agent 环境,比如 Claude Code、Codex,或其他支持
SKILL.md的 Agent;本文用的 Agent 为 Codex CLI; -
一个准备放实验文件的目录。
项目初始化
定义路径变量
这部分主要是为了统一后面命令中会反复用到的路径,少写长路径,也减少复制命令时出错的概率。
打开终端,先执行:
Bash
export CASE_ROOT="./cases/skill-forge"CASE_ROOT是这次实践的根目录。后面我们创建的 Skill 包、测试结果、评分文件,都会放在这个目录下面。
你可以把它理解成一个"快捷地址":一个指向这次实践的工作区。只要这个变量配置对了,后面的命令基本就能直接复制执行。
友情提醒:如果你关闭了终端,后面重新打开了终端,需要先重新执行一次
export CASE_ROOT="./cases/skill-forge"。
实操参考图:
创建实验目录
现在,来创建下本次实践要用到目录:
Bash
mkdir -p "$CASE_ROOT"
cd "$CASE_ROOT"现在你的目录大概是:
Plain
cases/
skill-forge/后面我们会在这个目录下面放文章记录、测试结果和真正的 Skill 包。
实操参考图:
命令执行参考图:

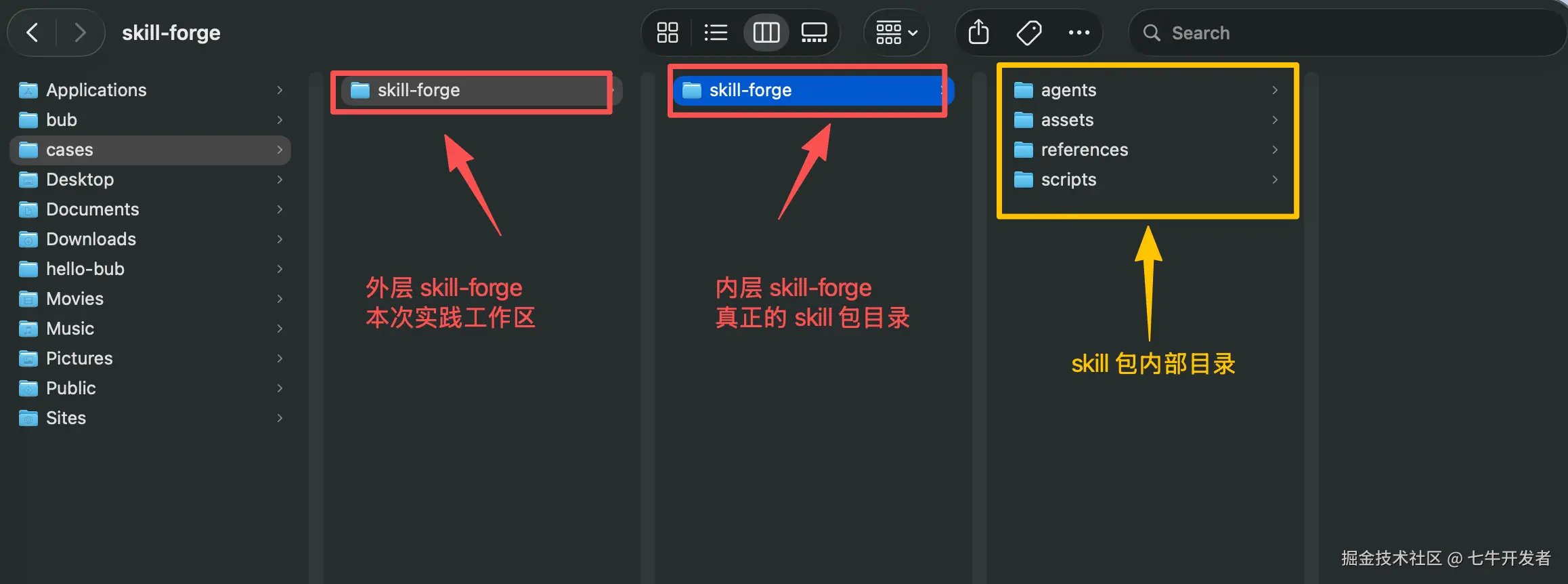
文件目录参考图:(由于我是在本地的根目录下执行的命令,所以就在用户目录下见到"cases"文件)
创建 Skill 包目录
来创建下真正的 Skill 包目录,在你当前所在的 skill-forge 目录下执行下面命令:
Bash
mkdir -p skill-forge/{references,assets,scripts,agents} 创建完成后,目录应该长这样:
Plain
cases/
skill-forge/ # 外层:这次实践的工作区
article.md # 可选:文章记录,目前没有这个文件
eval/ # 可选:测试结果,目前没有这个目录
skill-forge/ # 内层:真正的 Skill 包
references/
assets/
scripts/
agents/注意,里面这个最下面的这个 skill-forge/ 才是真正的 Skill 包;外层的 cases/skill-forge/ 是这次实验的工作区,可以放文章、测试记录和其他临时材料。
实操参考图:
命令执行参考图:
文件目录参考图:
简单的需求分析
在正式写 SKILL.md 之前,我们要先把 Skill Forge 的需求拆一下。
这次要做的 Skill Forge,不是用来处理某个具体业务任务的。它接收的是一个 Skill 需求,比如"帮我做一个会议记录转项目周报的 Skill";它要产出的,是一个新的、可复用的 Skill 包。
所以它至少要回答几个问题:
-
用户提出什么请求时,应该触发 Skill Forge;
-
用户只是做普通总结、写作或代码任务时,不应该触发它;
-
触发之后,先判断任务类型,再决定是创建、更新、验证,还是保持安静;
-
详细评分规则、测试样例和检查脚本,不全部塞进
SKILL.md,而是拆到 references、assets 和 scripts 里。
把这些想清楚之后,再去写 SKILL.md,就不会把它写成一大段混在一起的提示词。
编写 Skill 入口:SKILL.md
下面,我们来创建下 SKILL.md 文件。它是 Skill 的入口文件,主要放触发条件、边界和最短工作流;详细规则、样例、评分标准不一定都放这里。
在终端的当前目录(外层的 skill-forge)下继续执行下如下命令:
Plain
touch skill-forge/SKILL.md现在,用 VS Code 打开上面的 SKILL.md 文件,先写入一个最小版本,并保存文件:
YAML
---
name: skill-forge
description: Use when the user asks to create, improve, validate, or evaluate an agent skill package. Do not use for general writing, generic summarization, ordinary coding tasks, or requests to perform the business task directly.
---
# Skill Forge
Use this skill to help create, improve, validate, or evaluate agent skills.
This skill does not perform the target business task directly. For example, if the user asks for a meeting-notes skill, create or improve the skill package instead of summarizing the meeting notes.
## Task types
Classify the request into one of four types:
- new: the user wants to create a new skill.
- update: the user wants to improve an existing skill.
- validate: the user wants to check whether a skill is usable.
- quiet: the request is a general writing, summarization, coding, or business-task request and should not trigger this skill.
## Minimal workflow
1. Identify the task type.
2. Check whether the request should trigger this skill.
3. If creating or improving a skill, define the skill contract first.
4. Keep SKILL.md short.
5. Put detailed scoring rules in references/rubric.md.
6. Put eval cases in assets/eval-cases.json.
7. Use scripts/skill_quality_gate.py for repeatable checks.
## Output requirements
When creating or improving a skill, produce:
- skill name
- description with positive and negative trigger rules
- minimal workflow
- required references
- required assets
- validation plan这一步先不要追求完美。后面,我们可以慢慢迭代。
先用 Codex 试跑一次
写完 SKILL.md 之后,我们先不要急着补评分规则和测试脚本。我们可以先用 Codex 跑一次 SKILL.md,看看这个入口文件是否已经能被 Agent 理解。
这里我用 Codex CLI 来做这环节的验证工具。
我们先来确认下,终端目前所在的目录是否是如预期的:
Plain
pwd
# 如果输出类似结果,说明位置正确;注意,这里的 user 是你当前的电脑用户名
/Users/user/cases/skill-forge实操参考图:

Codex 在项目里通常会从 .agents/skills 目录读取 Skills,所以我们先把刚才写好的 Skill 包复制过去:
Plain
mkdir -p .agents/skills
cp -R skill-forge .agents/skills/然后启动 Codex:
Plain
codex到这里看下实操图:
进入 Codex 后,可以先显式调用一次:
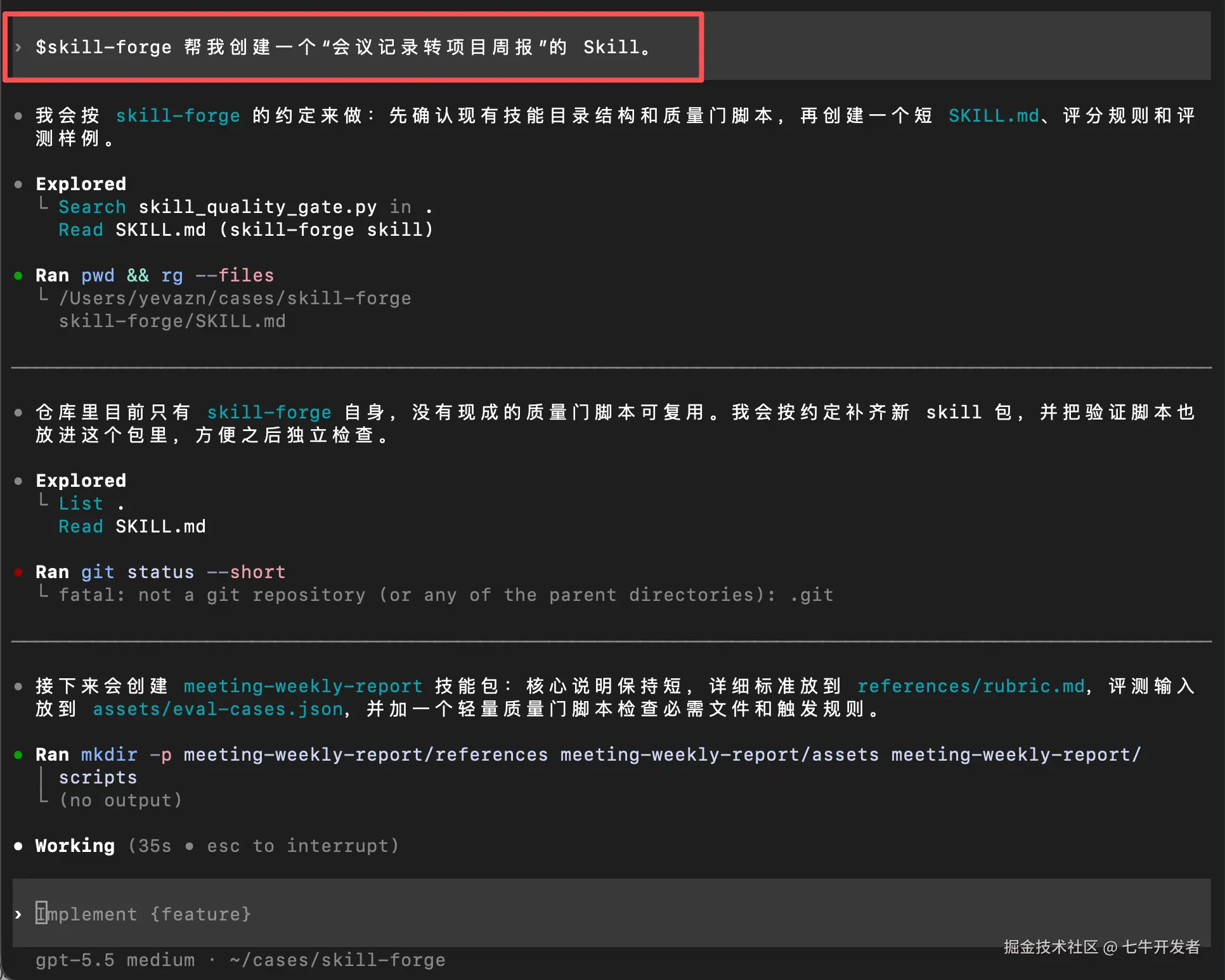
Plain
$skill-forge 帮我创建一个"会议记录转项目周报"的 Skill。这一步主要看它有没有做到几件事:
-
把任务识别成创建新 Skill;
-
先写触发条件和非触发边界;
-
没有直接去总结会议记录;
-
知道把规则、样例、脚本拆到不同目录。
如果这一步能跑通,说明这个最小版 SKILL.md 已经能作为入口文件继续往下扩展。接下来再补 rubric.md、eval-cases.json 和质量门禁脚本。
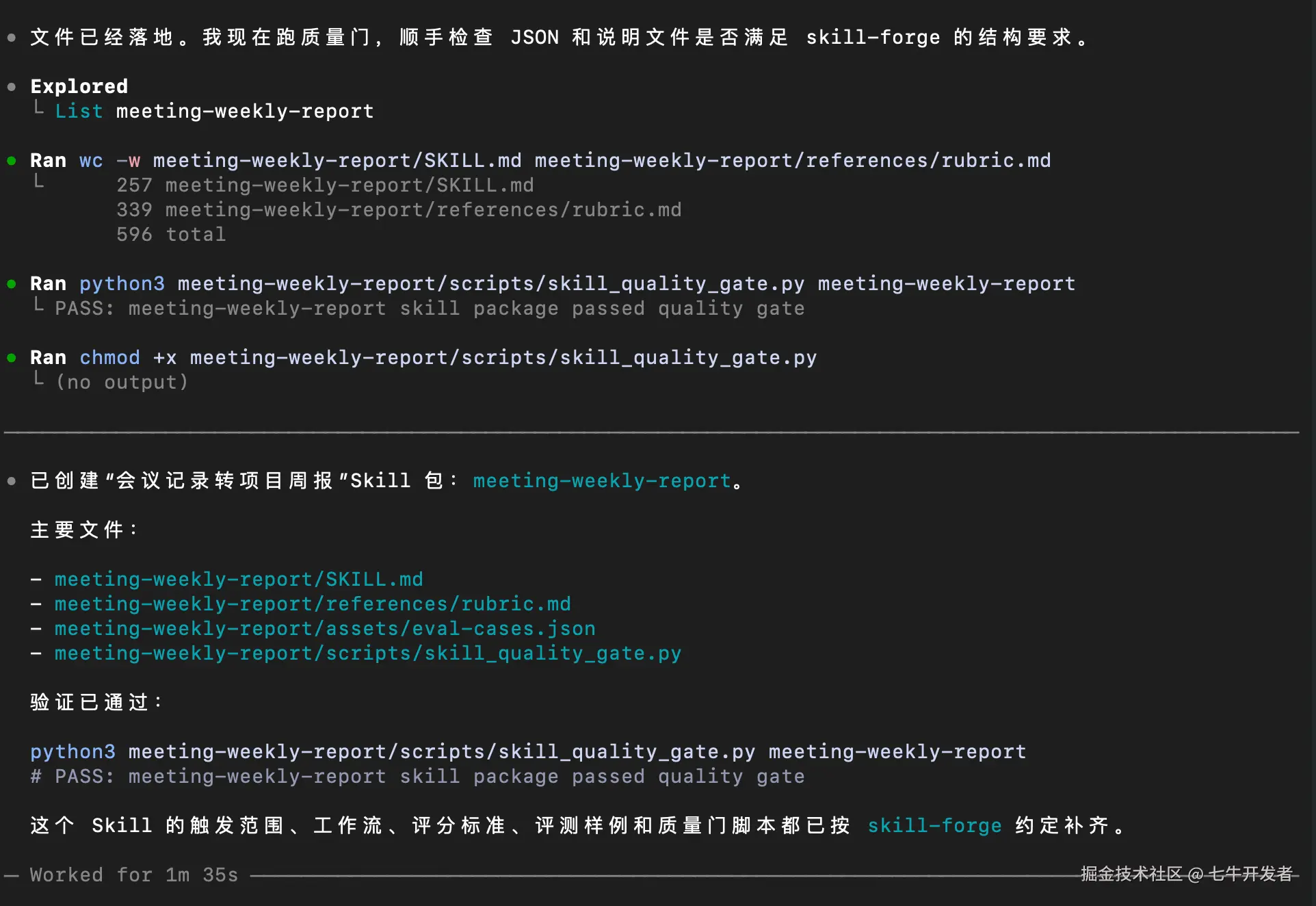
实操截图:(由于过程有些长,所以这里就放了 Codex 执行命令后的输出,以及最终跑完的结果图)
优化 Skill
上面这一步证明 skill-forge 已经能跑起来了,下面我们回到 skill-forge 本身,把它补齐成更完整的版本:依次补 rubric.md、eval-cases.json 和 skill_quality_gate.py。
创建评分标准文件:rubric.md
这个文件的作用是:当 Agent 需要判断一个 Skill 好不好时,可以按这里的标准来评估。
如果你目前处于 Codex 对话窗口,执行下面命令退出 Codex:
Plain
# 退出 Codex
/quit回到 skill-forge 目录下之后,终端继续执行下面命令:
Plain
# 创建 rubric.md 文件
touch skill-forge/references/rubric.md现在,用 VS Code 打开上面的 rubric.md 文件,先写入一个最小版本,并保存文件:
Markdown
# Skill Quality Rubric
A good skill should be evaluated on these dimensions:
## 1. Trigger accuracy
The skill should clearly describe when it should be used and when it should not be used.
## 2. Minimal entry file
SKILL.md should stay short. Long rules, examples, templates, and eval cases should be moved into separate files.
## 3. Progressive disclosure
The agent should only read detailed references when needed.
## 4. Permission boundary
The skill should not ask for unnecessary permissions or unsafe actions.
## 5. Testability
The skill should include positive cases, negative cases, boundary cases, and output quality checks.
## 6. Iterability
The evaluation result should help locate what to improve next.实操参考图(后面操作类似,省略相关实操截图):

创建测试用例文件:eval-cases.json
再来整点测试用例。一个 Skill 写得好不好,不只看它什么时候会被用,还要看它什么时候能不乱入。
我们先来创建文件:
Plain
touch skill-forge/assets/eval-cases.json现在,用 VS Code 打开上面的 eval-cases.json 文件,先写入一个最小版本,并保存文件:
JSON
{
"positive_cases": [
{
"id": "positive-001",
"input": "帮我做一个会议记录转项目周报的 Skill",
"expected": "should_trigger"
},
{
"id": "positive-002",
"input": "检查一下这个 Skill 的 description 有没有触发边界问题",
"expected": "should_trigger"
}
],
"negative_cases": [
{
"id": "negative-001",
"input": "帮我把这段会议记录总结一下",
"expected": "should_not_trigger"
},
{
"id": "negative-002",
"input": "帮我写一篇项目周报",
"expected": "should_not_trigger"
}
],
"eval_cases": [
{
"id": "eval-001",
"input": "帮我创建一个处理客服工单的 Skill",
"checks": [
"includes positive trigger rules",
"includes negative trigger rules",
"keeps SKILL.md short",
"separates references and assets",
"includes validation plan"
]
}
]
}这里要注意:负例很重要。
创建质量门禁脚本
这个脚本先做最基础的检查:
-
SKILL.md是否存在; -
是否有元信息区;
-
name是否正确; -
description是否写了触发条件; -
是否写了非触发边界;
-
入口文件是否太长;
-
评分标准和测试用例是否存在。
创建文件:
Plain
touch skill-forge/scripts/skill_quality_gate.py现在,用 VS Code 打开上面的 skill_quality_gate.py 文件,先写入一个最小版本,并保存文件:
Python
#!/usr/bin/env python3
import json
import sys
from pathlib import Path
def fail(message):
print(f"FAIL: {message}")
sys.exit(1)
def ok(message):
print(f"OK: {message}")
def main():
if len(sys.argv) < 2:
fail("Usage: skill_quality_gate.py <skill_dir>")
skill_dir = Path(sys.argv[1])
skill_file = skill_dir / "SKILL.md"
rubric_file = skill_dir / "references" / "rubric.md"
eval_file = skill_dir / "assets" / "eval-cases.json"
if not skill_file.exists():
fail("SKILL.md is missing")
ok("SKILL.md exists")
content = skill_file.read_text(encoding="utf-8")
if not content.startswith("---"):
fail("SKILL.md must start with frontmatter")
ok("SKILL.md has frontmatter")
if "name: skill-forge" not in content:
fail("name must be skill-forge")
ok("name is valid")
if "description: Use when" not in content:
fail("description should start with Use when")
ok("description starts with Use when")
if "Do not use" not in content:
fail("description should include Do not use boundary")
ok("description includes negative trigger boundary")
if "TODO" in content:
fail("SKILL.md still contains TODO")
ok("SKILL.md has no TODO")
line_count = len(content.splitlines())
if line_count > 120:
fail(f"SKILL.md is too long: {line_count} lines")
ok(f"SKILL.md length is acceptable: {line_count} lines")
if not rubric_file.exists():
fail("references/rubric.md is missing")
ok("references/rubric.md exists")
if not eval_file.exists():
fail("assets/eval-cases.json is missing")
ok("assets/eval-cases.json exists")
data = json.loads(eval_file.read_text(encoding="utf-8"))
for key in ["positive_cases", "negative_cases", "eval_cases"]:
if key not in data or not data[key]:
fail(f"{key} is missing or empty")
ok(f"{key} exists")
print("PASS: skill quality gate passed")
if __name__ == "__main__":
main()运行第一次质量检查
回到外层实验目录:
Bash
cd "$CASE_ROOT"然后执行:
Bash
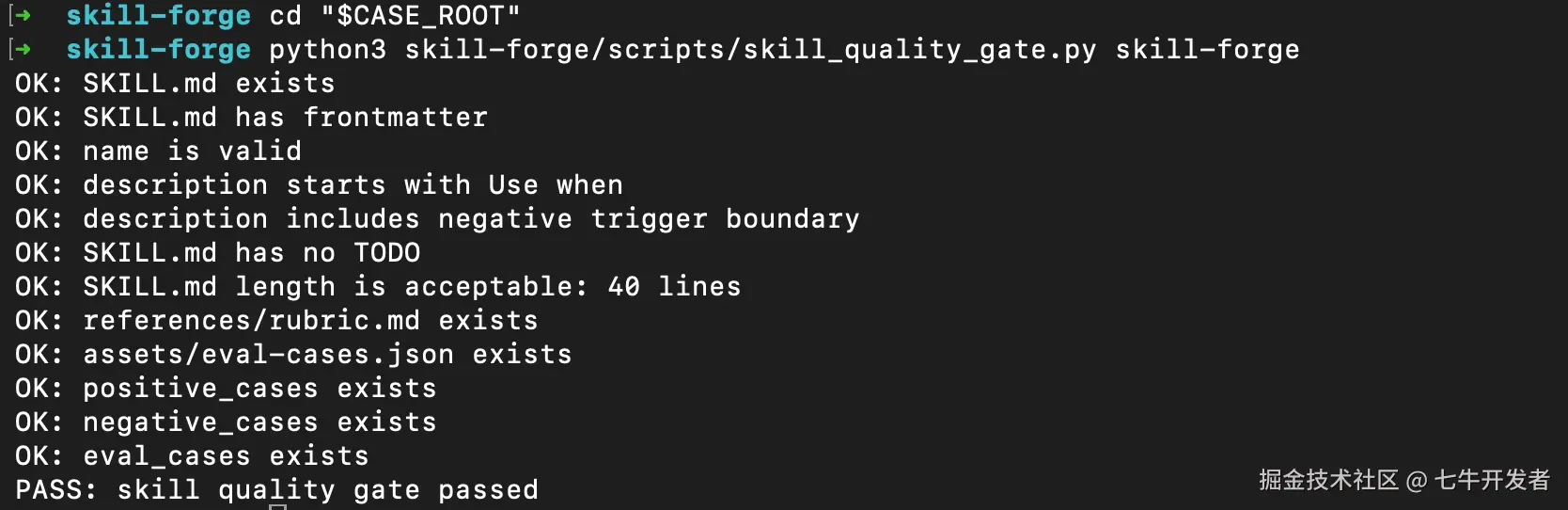
python3 skill-forge/scripts/skill_quality_gate.py skill-forge如果成功,你应该看到类似结果:
Plain
OK: SKILL.md exists
OK: SKILL.md has frontmatter
OK: name is valid
OK: description starts with Use when
OK: description includes negative trigger boundary
OK: SKILL.md has no TODO
OK: SKILL.md length is acceptable
OK: references/rubric.md exists
OK: assets/eval-cases.json exists
OK: positive_cases exists
OK: negative_cases exists
OK: eval_cases exists
PASS: skill quality gate passed看到 PASS,就说明这个最小 Skill 包已经能通过结构检查。
实操参考图:
后续优化
到这里,我们只是做出了一个最小可运行版本。
接下来要继续补三件事:
-
完善
SKILL.md,让它能更准确地区分new、update、validate、quiet四类任务; -
扩充
eval-cases.json,加入更多正例、负例和边界样例; -
增加 A/B 测试记录,比较普通 prompt 和启用 Skill 之后的效果。
可以先用三个问题检查它:
-
用户怎么说时,这个 Skill 应该出现?
-
用户怎么说时,这个 Skill 应该保持安静?
-
它是否能通过脚本检查,而不只是看起来写得不错?
如果这三点都能回答清楚,这个 Skill 就已经从一个长提示词,开始变成一个可维护的工作流包。
一图解本文