
「10秒3D重建、0.19秒/帧生成」
目录
[01 理解这项工作的价值需要先理解它所要缝合的那道裂痕](#01 理解这项工作的价值需要先理解它所要缝合的那道裂痕)
[1. 纯重建路线:精准但"死板",无法突破观测边界](#1. 纯重建路线:精准但“死板”,无法突破观测边界)
[2. 纯生成路线:灵活但"不稳",缺乏物理与几何约束](#2. 纯生成路线:灵活但“不稳”,缺乏物理与几何约束)
[3. 浅层混合路线:"拼接"而非"融合",协同价值未释放](#3. 浅层混合路线:“拼接”而非“融合”,协同价值未释放)
[02 与其余车企的世界模型相比真正的差异在哪?](#02 与其余车企的世界模型相比真正的差异在哪?)
[03 小米世界模型的核心三大组件协同的一体化闭环](#03 小米世界模型的核心三大组件协同的一体化闭环)
[1. WorldRec:稀疏查询驱动的前馈重建,10秒完成高保真3D高斯建模](#1. WorldRec:稀疏查询驱动的前馈重建,10秒完成高保真3D高斯建模)
[2. WorldGen:双向预训练+因果微调,4步去噪实现长时序稳定生成](#2. WorldGen:双向预训练+因果微调,4步去噪实现长时序稳定生成)
[3. Joint World Model:深度耦合,实现1+1>2的协同增益](#3. Joint World Model:深度耦合,实现1+1>2的协同增益)
[04 实际应用如何?](#04 实际应用如何?)
小米的又一篇智驾世界模型来了。
最近,小米官宣发布Xiaomi Auto World Model,首次将三维重建与视频生成做成了深度耦合的一体化架构。
在Waymo和nuScenes上全面SOTA,而且已经在小米汽车的合成数据、仿真测试、智能座舱三大场景完成业务落地。
在后来者里,小米这步跑得算快的了。

▲ Xiaomi Auto World Model 效果展示
01 理解这项工作的价值需要先理解它所要缝合的那道裂痕
众所周知,自动驾驶世界模型的核心使命,是让车辆具备对物理世界的"理解+预测"能力,支撑闭环仿真、长尾场景数据合成、端到端策略优化。
围绕这一目标,行业长期形成了两条泾渭分明的技术路线「重建 」、「生成」,各自存在难以突破的瓶颈:
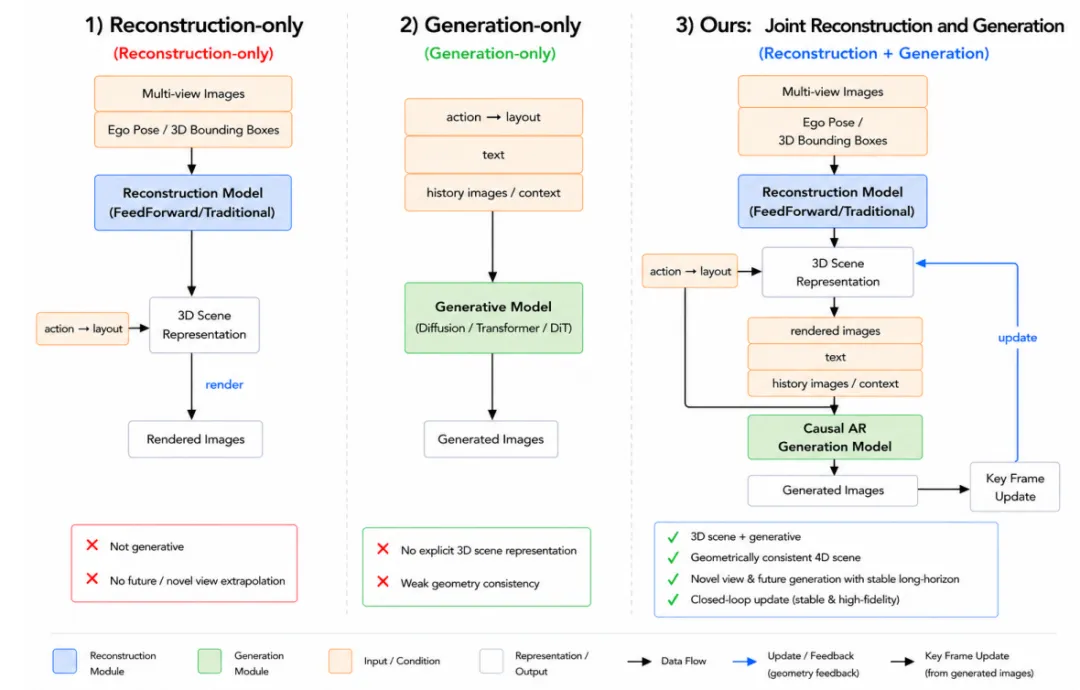
图| 仅重建、仅生成与本文联合世界模型的对比
1. 纯重建路线:精准但"死板",无法突破观测边界
以3D Gaussian Splatting为代表的重建方法,能从多视角图像中还原出几何一致、渲染保真的3D场景,是仿真与评估的优质底座。
但传统方案存在两大致命缺陷:
- 效率瓶颈:逐场景优化需数小时训练,无法支撑大规模量产数据处理;
- 泛化缺陷:前馈式稠密预测依赖像素对齐高斯输出,拼接后易出现鬼影、表面重复,且高斯数量爆炸导致渲染开销极大;
- 能力局限:只能还原已观测内容,无法预测未来、补全遮挡区域,不具备"想象"能力。
2. 纯生成路线:灵活但"不稳",缺乏物理与几何约束
以扩散模型、DiT为代表的生成方法,可直接合成未来驾驶视频、生成长尾危险场景,解决真实数据稀缺问题。
但同样存在三大短板:
- 几何失准:无显式3D表征,生成内容易出现物体错位、透视失真;
- 时序漂移:自回归生成的暴露偏差问题,导致长视频内容逐渐失真;
- 效率低下:推理需数十至上百步去噪,难以满足实时仿真与车载部署需求。
3. 浅层混合路线:"拼接"而非"融合",协同价值未释放
两种范式各有优势,但彼此割裂。
行业常见的做法,没错,就是------"并行"。
近年NeoVerse等工作尝试结合重建与生成,但仍停留在模块拼接层面。既未解决多相机几何对齐、自车运动感知等自动驾驶专属问题,也无法实现稳定性、一致性、保真度的协同提升

图| 不同世界建模范式的对比
正是这些长期未解决的矛盾,构成了小米Auto World Model的创新出发点:用深度耦合替代浅层串联,用稀疏表征替代稠密冗余,用两阶段训练替代从头训练,让重建与生成互相赋能、互为约束。
也就是说,小米将这种"并行"改为了"耦合",实现了"首次将三维重建与视频生成深度耦合的一体化架构"。
02 与其余车企的世界模型相比真正的差异在哪?
截至 2026 年 5 月,全球主流自动驾驶厂商(特斯拉、华为、小米、小鹏、蔚来等)几乎已全部转向世界模型技术路线。
也意味着,全球自动驾驶行业已形成共识:世界模型是实现 L4 及以上自动驾驶的必要条件。
当前各家路线均有不同,只是都叫"世界模型"。
可以阅读这篇文章:++2026 世界模型四大路线10篇代表性工作全盘点!谁是真王者?++
像特斯拉的世界模型是决策系统的一部分(坚持纯生成式、端到端路线),而小米的世界模型是训练系统的一部分(采用重建+生成结合路线)。
但归根结底,在自动驾驶领域,世界模型的核心价值在于解决两个根本性问题:
- 观测不完备性:传感器存在视野遮挡、距离限制和噪声,无法完整感知当前场。
- 未来不确定性:自动驾驶需要预测交通参与者的未来行为,以做出安全决策。
小米打的算盘,是用重建派的"物理锚点"去约束生成派的"想象力",用生成派的"想象力"去补齐重建派的"观察边界"。
这套逻辑,让它在Waymo、nuScenes等主流评测中,全面刷到了SOTA(当前最佳)。
重建质量的PSNR指标达到28.48,超越此前最佳方法;预测质量的FVD指标达到64.97,同样技压群雄。
但要注意的是,这些指标,都是在干净、标准的公开数据集上跑出来的,所以不能完全代表真刀真枪的真实路况结果。
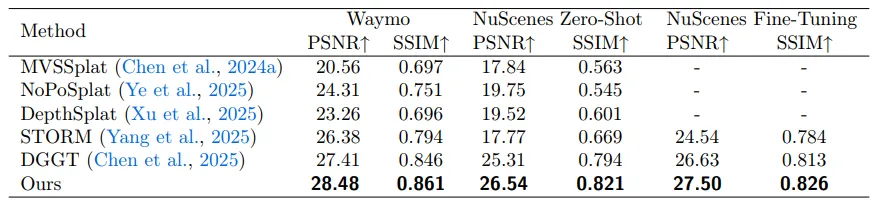
图|Waymo 与 nuScenes 数据集上的定量结果
03 小米世界模型的核心三大组件协同的一体化闭环
小米Auto World Model 由WorldRec(场景重建)、WorldGen(视频生成)、Joint World Model(联合融合)三大核心组件构成。
三者形成"重建提供几何锚点、生成拓展预测边界、联合实现闭环协同"的完整体系
1. WorldRec:稀疏查询驱动的前馈重建,10秒完成高保真3D高斯建模
WorldRec的核心突破,是用稀疏3D查询替代像素对齐稠密高斯,从根源解决传统重建的效率低、冗余高、鬼影重问题,将单片段重建时间从小时级压缩至约10秒。
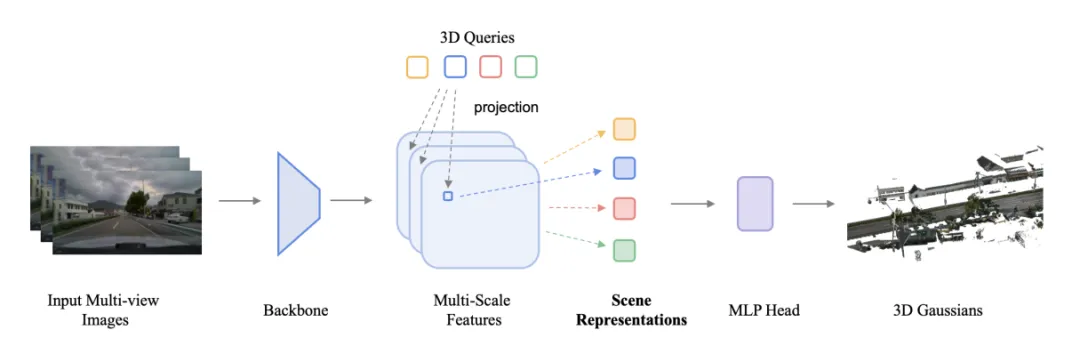
图| WorldRec 网络架构
其流程可概括为四步:
- 多尺度特征提取:共享视觉主干处理多相机、多时域图像,输出兼顾细节与语义的多尺度特征图;
- 3D查询初始化与投影采样:在世界空间初始化N个稀疏3D查询,通过相机内外参投影到各视角特征图,双线性插值提取局部特征;
- 跨视角跨时域特征聚合:通过可见性感知加权模块,融合多视角、多时域特征,自动强调高可信观测、抑制遮挡噪声,保证空间一致性;
- 高斯属性解码与渲染监督:MLP头将聚合特征解码为3D高斯完整属性,通过可微分光栅化渲染,联合像素损失与感知损失监督训练,确保跨视角几何与外观对齐。
这一设计的核心优势:
- 无鬼影、低冗余:稀疏查询跨视角聚合,避免逐帧独立预测导致的拼接伪影,高斯数量大幅减少;
- 极致高效:前馈推理单片段仅需10秒,相比传统优化方案提速超百倍;
- 泛化性强:从大规模数据学习通用先验,可快速适配新视角、新场景。
在Waymo、nuScenes基准上,WorldRec的PSNR、SSIM指标全面超越STORM、DGGT等SOTA方案,验证了稀疏查询架构的优越性。

▲ 驾驶视角重建效果展示
2. WorldGen:双向预训练+因果微调,4步去噪实现长时序稳定生成
WorldGen以DiT为骨干,针对生成模型"训练难、推理慢、长时序飘"的痛点,设计双向预训练→渐进式因果微调的两阶段训练流程,将去噪步骤从50步压缩至4步,推理提速约12倍,实现0.19秒/帧的实时生成,支持最长1分钟稳定视频。
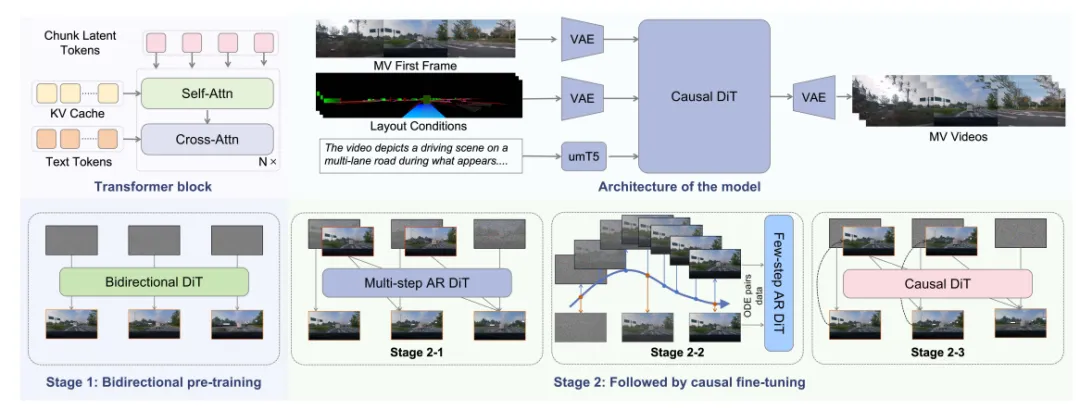
图| WorldGen 架构与两阶段训练框架
阶段1:双向预训练------建立强时空先验
采用全双向时序注意力,模型可自由访问全部时序上下文,学习驾驶场景全局时空分布,基于整流流目标训练,高效建立高质量生成先验,避免从头训练因果扩散模型的优化困难。
阶段2:三级因果微调------适配在线推理、解决暴露偏差
- Teacher Forcing:引入因果注意力掩码,用真实历史帧作为上下文,快速适配因果生成,解决训练稳定性问题;
- ODE蒸馏:利用ODE求解器轨迹一致性,让4步学生模型匹配50步教师模型质量,实现极致推理加速;
- DMD分布匹配蒸馏:用模型自身生成帧替代真实帧作为上下文,缩小训练与推理分布差异,彻底解决暴露偏差导致的长时序漂移。
最终WorldGen实现:
- 极快推理:单视图0.19秒/帧,三视图0.46秒/帧,满足实时仿真需求;
- 超长时序:支持81帧、最长1分钟视频生成,远超同类方案的8-16帧;
- 优质可控:可生成动物闯入、极端天气等长尾场景,FID、FVD指标超越所有对比方案。

▲ 极端天气长尾场景生成
3. Joint World Model:深度耦合,实现1+1>2的协同增益
这是整个工作最具独创性的部分------并非简单串联,而是架构级双向适配与闭环交互,让重建的几何确定性抑制生成漂移,让生成的想象力补全重建盲区。
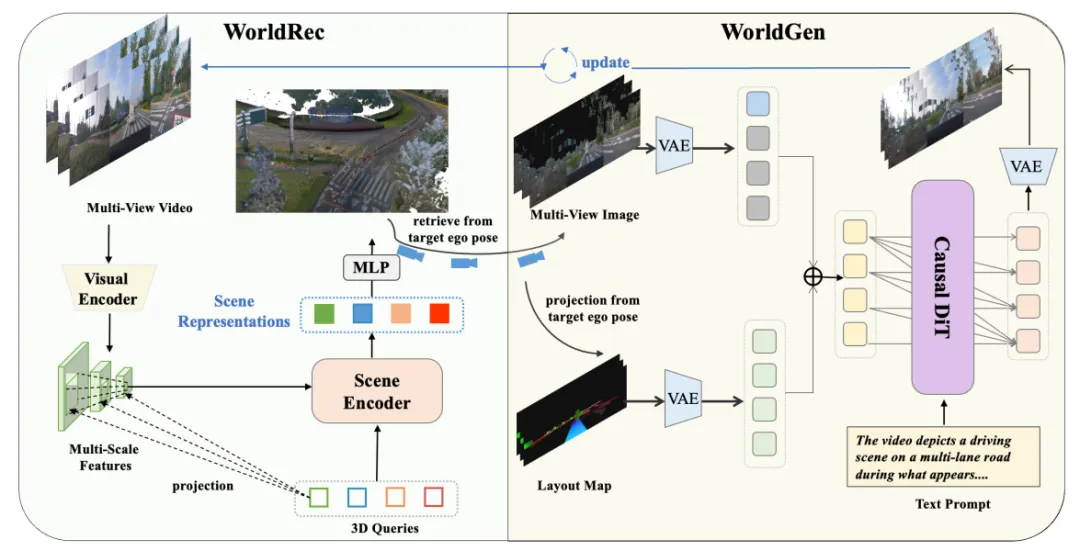
图| 联合世界模型架构
双向适配改造
- WorldRec增量重建:新增场景融合机制,可将新观测帧与缓存场景令牌融合,持续扩展全局一致的4D高斯表征,适配自动驾驶长距离行驶场景;
- WorldGen渲染先验 conditioning:将WorldRec的3D高斯渲染为目标视角图像,作为额外条件输入DiT,为未观测区域提供几何骨架,保证已观测区域的光度一致性。
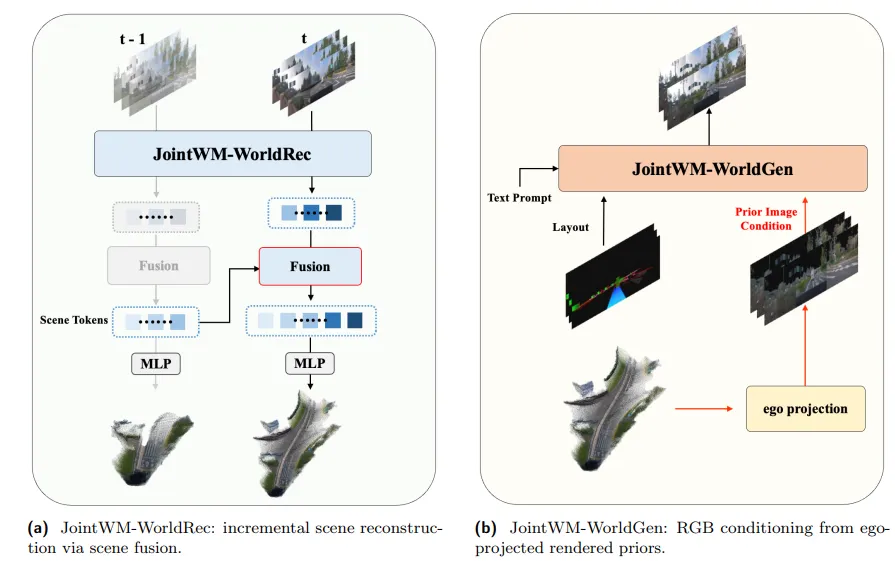
图| 面向联合世界模型的 WorldRec 与 WorldGen 适配改造
三大协同效果
- 高稳定性:WorldRec的几何约束彻底抑制长时序生成的误差累积与内容漂移;
- 高一致性:4D场景表征作为跨帧共享内存,保证多视角、多时域下物体位置、光照、纹理全局对齐;
- 高保真度:生成结合重建的真实观测监督,大幅缩小仿真与真实域差距。
这一闭环架构,首次让自动驾驶世界模型同时具备"精准还原"与"合理想象"双重能力,为闭环仿真、合成数据、端到端训练提供坚实底座。
04 实际应用如何?
世界模型到底该走重建路线还是生成路线,行业吵了不是一天两天。
回顾整篇论文,小米直接用一套深度耦合的架构给出了另一种解法:重建提供几何锚点,生成拓展预测边界,二者在训练和推理里互相约束。
WorldRec把重建时间从小时级压到10秒,WorldGen用4步去噪做到0.19秒/帧,这两项效率指标让"重建+生成一体化"从学术概念变成了可落地的工程方案。
目前已经接入了合成数据、仿真测试和智能座舱三大场景。
但小米世界模型目前主要服务于三大场景,一定程度上都绕开了最核心、最危险的"实时决策"。
因此对于小米汽车而言,这项技术目前最大的价值可能是降本增效,而非直接保障驾驶安全。
对自动驾驶世界模型来说,其技术仍然处于发展的早期阶段。
世界模型也可能不是唯一的答案,但确实是一条值得跟进的路线。
Ref
论文:Xiaomi Auto World Model: A Joint World Model Integrating Reconstruction and Generation for Autonomous Driving