绪论
要搞懂机器学习是一个什么样的学科?首先要搞懂科学、技术、工程、应用的区别:
科学:是什么、为什么
技术:怎么做
工程:怎么样做的多快好省
应用:怎么实际产生价值
机器学习主要涉及科学、技术部分,工程涉及很少,应用几乎不涉及。
机器学习到底在做什么
机器学习有坚实的理论基础
机器学习的理论基础PAC模型


概率近似正确模型(PAC) :P(|f(x) - y| ≤ ε) ≥ 1 - δ第一个表达式是目标,第二个表达式是资源,经过第一个表达式推导得到。
1.x就是问题本身。
2.f就是模型本身。
3.y就是真实结果。
4.|f(x) - y| < ε , ε越小就说明越逼近真实结果。
5.P就是说得到|f(x) - y| < ε 结果的概率,表现形式为多次输入得到理想结果的概率。
6.δ越小则代表多次输入得到理想结果的概率越大,模型越稳定。
这里我们要提出几个问题
1.为什么 ε不能为0?只能近似为0。
2.为什么得到的结果是概率的,而不是绝对的?
要回答上面的问题,我们就需要了解机器学习要解决的是什么样的问题?
从问题的形式 :机器学习要解决的是不知道如何解决的问题,无法通过数学函数的排列组合得到精确结论的问题,这也是我们生活中比较常见的一类问题。
问题的性质(计算量) :P =? NP,机器学习要解决的问题往往超过了np问题,即给出你一个解,在多项式时间内,你也无法验证当前解是否是最优解。如果我们要求ε为0,P = 1,那就反向证明了P=NP,但是目前我们无法证明,并且主流学界认为P!=NP。
综上所述,我们无法要求 ε = 0 , P = 1。所以我们只能退而求其次,只能追求"概率近似正确"。
P =? NP的理解
P:能在多项式时间内找到最优解的问题。(能快速找到最优解的问题)
NP:是否能在得到最优解的前提下在多项式时间证明当前解是最优解。(能快速验证答案是否正确的问题,反推出描述问题的方程)
目前结论 :未解决(千禧年难题),多数科学家猜测 P ≠ NP。一眼看出答案对不对 ≠ 能轻松算出答案。现实世界大多数答案其实不过是一个局部最优解,并且无法根据答案推导出过程。
问题的分类:
什么是多项式时间?
核心概念是问题规模随解决问题的的时间是指数级增长还是线下增长(近似)。
多项式:变量(问题规模)在底数位置而不是指数位置。
机器学习基本术语
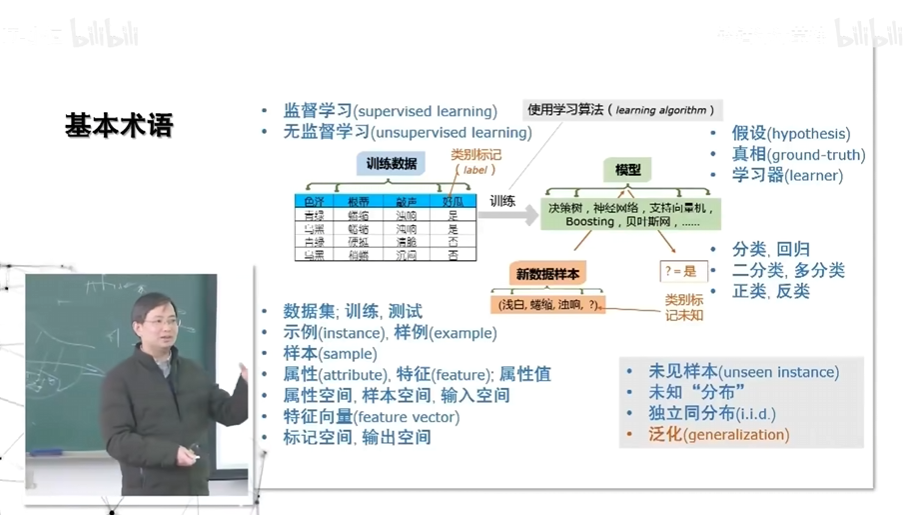
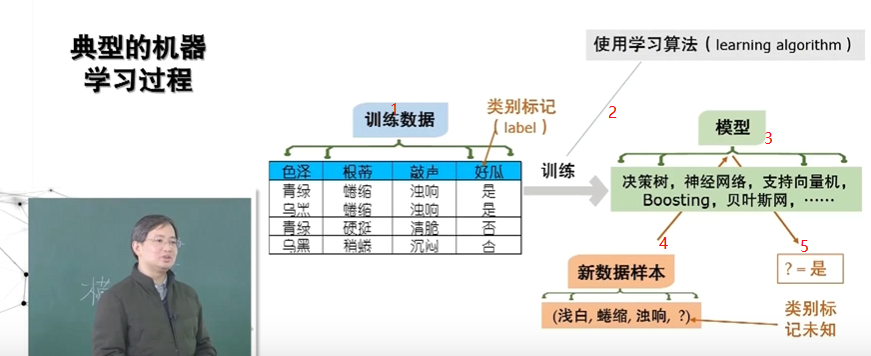
训练数据层面
数据集
- 训练集(高考前学习的内容)
-
用途:用于训练模型,让模型学习特征与标签之间的映射关系。
-
比例 :通常占全部数据的 50%~80%(取决于总数据量和具体任务)。
-
注意:训练集应尽可能覆盖真实场景的各种情况,避免偏差。
- 验证集(模拟考试卷子)
-
用途 :用于模型选择 和超参数调优。在训练过程中多次使用,评估不同模型结构或超参数下的泛化能力,防止过拟合。
-
比例 :通常占 10%~25%。
-
注意:验证集不参与梯度更新,只用于监控和决策(如早停、选择学习率)。
- 测试集(真正的高考)
-
用途 :用于最终评估模型的泛化性能。只有在模型完全训练和选定后,才使用一次,得到客观的最终指标。
-
比例 :通常占 10%~20%。
-
重要原则 :测试集绝对不能用于训练或调参,否则会导致信息泄露,评估结果过于乐观。
示例(instance)
只有feature没有label
样例(example)
有feature有label
样本(sample)
比较含糊,样例有时候是sample,数据集有时候也叫sample,需要根据上下文分析。
属性(attribute)/特征(feature)
西瓜的颜色,声音,根蒂都叫属性
属性值(attribute)/特征值(feature)
比如青绿色,卷缩,灵等
属性空间 or 样本空间 or 输入空间
属性空间是由一个示例的所有属性(特征)作为维度张成的多维空间。
特征向量
某一个样例在属性空间中的向量
标记空间 or 输出空间
输出在多维坐标系上构成的空间
模型层面
模型就是固定下来的规律,模型可能是显式(快排算法)的也可能是隐式(LLM)的,大部分神经网络模型都是隐式的。
模型一定是正确的吗?
不一定。它本质上是一种概率假设。概率近似正确。
假设(hypothesis)
在模型场景下,模型等于假设。模型每一次产出的结果都是一种假设。
真相(ground-truth)
与假设对应,有假设才有真相。
学习器
训练好的具体模型。
模型输出
分类
二分类,多分类,最基础的是二分类。
回归
指分析和预测连续数值的过程。(拟合一个连续曲线,用于预测后续发展)
常用场景:房价预测、股票价格预测、温度预测、销售额预测等一切需要输出"一个具体的数"的地方。
正类、反类
学习类型
监督学习:预测,回归
无监督学习:离散聚类,密度估计
模型输入
未见样本
模型输入是未来的新数据。
未知分布
我们假设我们拿到的所有数据都来自同一个潜在分布。所有的数据都是符合这个分布的(规律),训练数据也是从这个分布中抽取出来的,因为未见样本也属于这个潜在分布,所以可以泛化。
独立同分布(重要)
所有数据都是独立的(互不影响),都属于某一个潜在分布。
为什么需要满足独立同分布
独立同分布告诉我们可以使用频率推断概率。如果两点任一不满足,都说明我们的推断存在一定的理论缺陷。
现实世界中真的所有事件都是独立的吗?
不一定,你去淘宝买了个帽子然后再推荐朋友去买一顶就不是独立的。但是当前大部分机器学习任务假设所有事件是独立同分布的。
怎么突破独立同分布的约束是当今机器学习研究前沿
泛化(generalization)
对未见样本的处理效果。