似然函数
概率用于在已知一些参数的情况下,预测接下来在观测上所得到的结果。而似然性则是用于在已知某些观测所得到的结果时,对有关事物之性质的参数进行估值。
似然函数是对参数的函数,其定义为在给定参数值的条件下,观察到某个特定数据的概率。换句话说,似然函数是一个关于参数的函数,而不是关于数据的函数。
如果我们有一个参数化的概率模型P(X|θ),其中X是观测数据,θ是模型参数,似然函数L(θ|X)定义为:
L(θ|X)=P(X|θ)
这里,P(X|θ) 表示在参数为θ的情况下,观察到数据X的概率。
设有一组独立同分布的观测数据X=(x1,x2,...,xnx_1, x_2, \dots, x_nx1,x2,...,xn),并且这些数据服从某个分布(例如正态分布、二项分布等),比如服从参数为θ的某个分布,那么似然函数可以写作:
L(θ∣X)=P(X∣θ)=∏i=1nP(xi∣θ)L(\theta \mid X) = P(X \mid \theta) = \prod_{i=1}^{n} P(x_i \mid \theta)L(θ∣X)=P(X∣θ)=∏i=1nP(xi∣θ)
针对其中存在的乘法,可以使对数函数将其转化为加法:
logL(θ∣X)=log∏i=1nP(xi∣θ)=∑i=1nlogP(xi∣θ)\log L(\theta \mid X) = \log \prod_{i=1}^{n} P(x_i \mid \theta) = \sum_{i=1}^{n} \log P(x_i \mid \theta)logL(θ∣X)=log∏i=1nP(xi∣θ)=∑i=1nlogP(xi∣θ)
什么是极大似然估计
极大似然估计,也叫最大似然估计,英文名称统一为:" Maximum Likelihood Estimation",简称 (MLE)。
一句话总结:最大似然估计,就是找一组参数,让「当前已经发生的样本」出现的概率最大。
似然函数常用于极大似然估计。我们希望找到使似然函数最大化的参数θ。这意味着在给定观测数据的情况下,选择最可能生成这些数据的参数值。
例如,掷硬币3次,2次正面1次背面,能否依据此结果逆推出正面的概率;正面概率为0.5的概率为多少、正面概率为0.6的概率为多少;最有可能的正面概率是多少?
此处的:正面概率为0.5的概率为多少,这个问题是什么意思呢,这里的0.5指的是假设每次抛掷,正面朝上的概率为0.5,在此情况下,掷硬币3次,2次正面1次背面的概率是多少。
同理,正面概率为0.6的概率为多少,是说的,假设每次抛掷,正面朝上的概率为0.6,在此情况下,掷硬币3次,2次正面1次背面的概率是多少。
我们用θ 代表硬币正面朝上的概率,用X 代表2次正面1次背面的结果
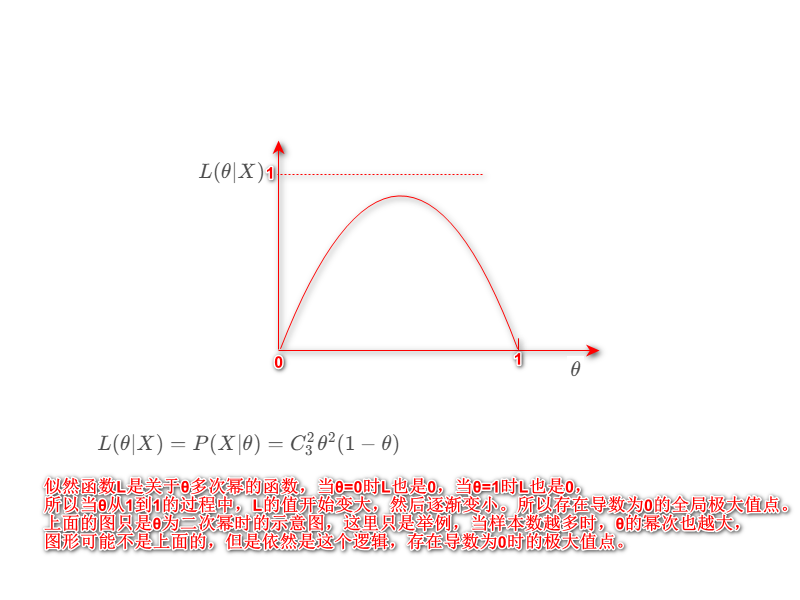
L(θ∣X)=P(X∣θ)=C32θ2(1−θ)L(\theta|X)=P(X|\theta)=C_3^2\theta^2(1-\theta)L(θ∣X)=P(X∣θ)=C32θ2(1−θ)
当正面概率为0.5时:P(X∣θ=0.5)=C32×0.52×(1−0.5)=0.375P(X|\theta=0.5)=C_3^2 \times 0.5^2 \times (1-0.5)=0.375P(X∣θ=0.5)=C32×0.52×(1−0.5)=0.375
当正面概率为0.6时:P(X∣θ=0.6)=C32×0.62×(1−0.6)=0.432P(X|\theta=0.6)=C_3^2 \times 0.6^2 \times (1-0.6)=0.432P(X∣θ=0.6)=C32×0.62×(1−0.6)=0.432
2次正面1次背面对应的已发生的样本可能有三种情况:正面,正面,背面,正面,背面,正面,背面,正面,正面。这三种情况,每一种的情况的概率,也就是联合概率,都是θ2(1−θ)\theta^2(1-\theta)θ2(1−θ)。所以要加上组合数C32C_3^2C32。
为了找出极大似然估计,对似然函数取对数并求导,使其等于0
logL(θ∣X)=logC32⋅θ2(1−θ)=log3+2logθ+log(1−θ)\log L(\theta|X)=\log\leftC_3\^2 \\cdot \\theta\^2(1-\\theta)\\right=\log 3+2\log\theta+\log(1-\theta)logL(θ∣X)=logC32⋅θ2(1−θ)=log3+2logθ+log(1−θ)
dlogL(θ∣X)dθ=2θ−11−θ=0\frac{d\log L(\theta|X)}{d\theta}=\frac{2}{\theta}-\frac{1}{1-\theta}=0dθdlogL(θ∣X)=θ2−1−θ1=0
解得θ =23\frac{2}{3}32,意味着当掷硬币3次,出现2次正面1次背面的结果时,硬币正面朝上的概率最有可能为23\frac{2}{3}32。如何确定这个点是极大值点,而不是极小值点,需要通过求二阶导数,将θ 值带进去,判断此处二阶导数的值,进而判断是极大值还是极小值,在这里就没有再求,因为只有一个极值点,
根据经验判断,必然是极大值点,如果求出多个极值点,必须要进行二阶导数判断。
P(X∣θ=23)P(X|\theta= \frac{2}{3})P(X∣θ=32)的值要和P(X∣θ=0)P(X|\theta= 0)P(X∣θ=0),以及P(X∣θ=1)P(X|\theta= 1)P(X∣θ=1)的比较,谁求出的似然函数的值大,最合适的那个θ
logL(θ∣X)\log L(\theta|X)logL(θ∣X) 没有底数?
一句话总结:上面logL(θ∣X)\log L(\theta|X)logL(θ∣X) ,默认指的就是 lnL(θ∣X)\ln L(\theta|X)lnL(θ∣X)
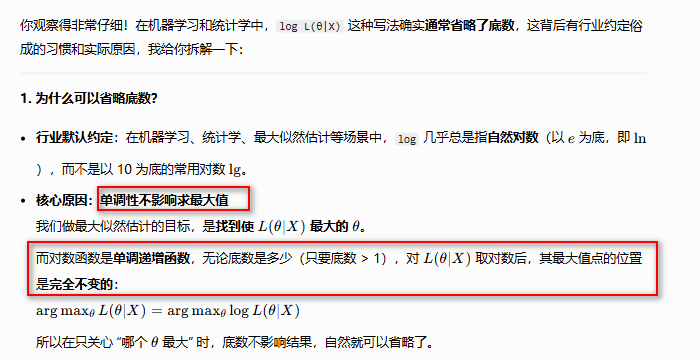
y=lnxy = \ln xy=lnx函数特点是单调递增的,此处的yyy= L(θ∣X)L(\theta|X)L(θ∣X),xxx = C32θ2(1−θ)C_3^2\theta^2(1-\theta)C32θ2(1−θ),这是一个对数复合函数,也就是当θ\thetaθ取什么值时,使x值最大(即C32θ2(1−θ)x值最大(即C_3^2\theta^2(1-\theta)x值最大(即C32θ2(1−θ)的值最大),同时也就是使y最大,也即L(θ∣X)y最大,也即L(\theta|X)y最大,也即L(θ∣X)的值最大。这也就说明了两边取对数后,求导,使导数为0,其极值点的位置,也就是对应的θ\thetaθ值是不变的。
也就是使L(θ∣X)L(\theta|X)L(θ∣X)取得极大值的点和使lnL(θ∣X)\ln L(\theta|X)lnL(θ∣X)取得极大值的点的θ\thetaθ是同一个。


样本的独立同分布怎么理解




似然函数 = 所有样本联合概率,也就是X1,X2,...,XnX_1, X_2, \\dots, X_nX1,X2,...,Xn中,每一个样本元素同时发生的概率。
其中的X1X_1X1是第一次抛硬币时的情况,X2X_2X2是第二次抛硬币时的情况,依次类推,它们可能是正面,也可能时反面,但是一旦发生了,样本固定了,它就只能时其中一个中情况。而我们之前说的抛硬币3次,2次正面,一次背面,其实这里是3种样本的情况,然后把每种样本发生的概率都加起来求和。(因为只要有一个样本发生就满足了条件)。正面, 正面, 反面 + 正面, 反面, 正面+反面, 正面, 正面 这三种概率(每种样本内是求联合概率)的情况之和就是要求的似然函数值。
如果仅仅是为了求待估参数,可以省略掉组合数,因为其是常数,不影响求导,如果是要求似然函数的真是值,则必然要带着组合数。
