上一篇我们回到 Swin 补上了它的二维 RPE 方案,用紧凑偏置表实现了高效的二维相对位置编码。
至此,从 Shaw 的加法型、Transformer-XL 的四项重构式、再到 T5 的偏置型,Swin 的二维扩展,每种方案都在尝试不同的方法来实现 RPE。
最终,在 NLP 这个 RPE 的"原产地",酝酿出了一种新的范式:
有没有一种位置编码,既不修改注意力公式,也不引入额外参数,却能让 QK 点积本身就"感知"到相对位置?
2021 年的论文:RoFormer: Enhanced Transformer with Rotary Position Embedding 给出了答案。
它不仅解决了这个问题,还直接奠定了现代大模型中位置编码的事实标准,今天几乎所有主流开源大模型(LLaMA、Mistral、Qwen、GLM......)都在使用它。
这套方案就是 旋转位置编码 RoPE(Rotary Position Embedding)。
1. RoPE 的核心思路#
我们再再再看一遍标准的自注意力:
Attention(Q,K,V)=softmax(QKTd)V
这里 QKT 中的每个元素 qi⋅kj ,衡量的就是 token i 和 j 的内容相关性。
一直以来的问题都是:这个点积本身不知道任何位置信息。 比如同一个词出现在位置 1 和位置 100,只要内容相同,点积结果就完全相同。
而之前提到过的 RPE 方案都是在"补救"这个问题,它们的共同特点是:
位置信息是通过种种逻辑"后加"到注意力分数上的,Q、K本身的语义仍然不变。
RoPE 的想法刚好相反:
不在注意力公式上做任何加法,而是让 Q 和 K 的向量表示本身就携带位置信息。
具体怎么做的?就是旋转。
假设现在有一个 2 维向量 q=(q1,q2),我们让它绕原点旋转一个角度 θ:
q1′q2′\]=\[cosθ−sinθsinθcosθ\]\[q1q2
这就是一个标准的二维旋转矩阵 R(θ),现在,我们定义一个函数,用这个矩阵对二维向量进行旋转,那就是:
f(q)=R(θ)q
在这个基础上,我们再加入位置参数,看看如果我们对位置 m 的 Q 旋转 mθ,对位置 n 的 K 旋转 nθ,它们的点积会是什么?
f(q,m)=R(mθ)q,f(k,n)best.xqsyb.com=R(nθ)k
f(q,m)Tf(k,n)=qTR(mθ)TR(nθ)k
根据正交矩阵的转置等于逆和三角函数性质,我们得到:
R(mθ)TR(nθ)=R(−mθ)R(nθ)=R((n−m)θ)
最终结果如下:
f(q,m)Tf(k,n)=qTR((n−zixun.xqsyb.com m)θ)k
你会发现:点积结果只依赖于 n−m,即相对位置。
这一段推导下来说明的是什么?
如果我们用一个和位置相关的旋转函数对两个位置的 q 和 k 进行旋转,那么二者的点积结果,也就是注意力分数就会受到它们之间的相对位置影响。
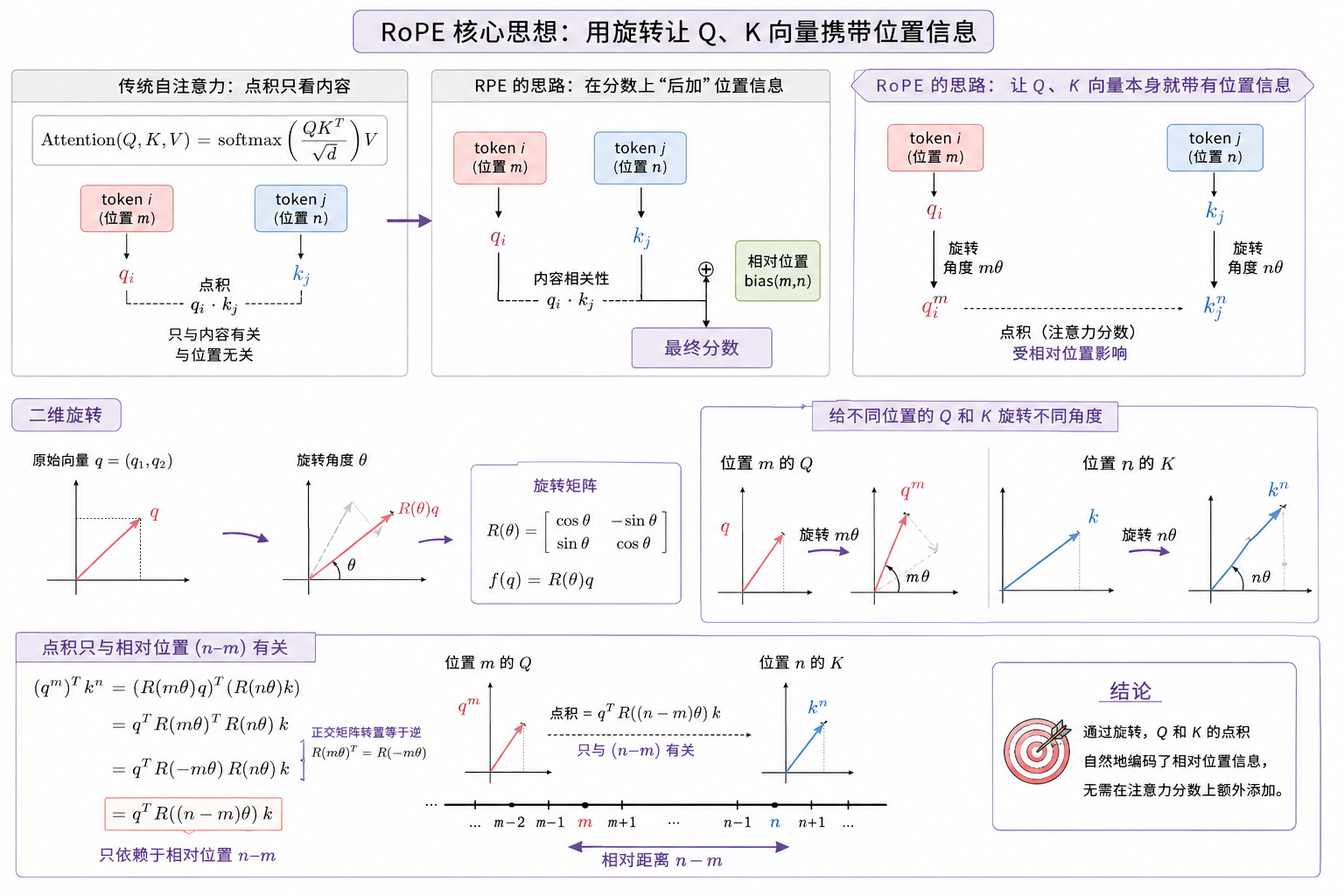
这便是 RoPE 的核心思路。
2. RoPE 的具体逻辑#
2.1 高维空间推广问题#
二维旋转给了我们启发,但实际中向量维度 d 通常几百上千。
现在,一个很自然的想法就是:
直接对整个高维向量做一次整体旋转。
但这里会带来一个严重问题:
整体旋转造成大规模的信息耦合,导致优化困难。
首先,训练后,无论是词向量,还是经过线性变换后的 Q 和 K,本质上都已经处于一个训练好的高维特征空间中。
虽然我们很难精确说:"第几维一定表示什么语义"。但模型已经通过大量训练,学会了不同维度间的语义关系、结构。
如果此时用一个矩阵直接对整个高维向量进行一次全局旋转,那么新的每个维度都是由所有原始维度大规模混合得到,破坏了原有的语义结构。
例如:
q1′=0.3q1+0.7q18−wenku.xqsyb.com 0.2q93+...
你可能会问:
通过反向传播,我们训练出来的语义空间本身不就是适应旋转操作的语义空间吗?
这句话本身是完全没有问题的,但是这时:一个维度会依赖大量其它维度、局部修改会影响整体结构、特征分工会变得困难、梯度传播会更加复杂。
因此,这种全局耦合会让优化会变得非常困难。
因此,问题就变成了:
如何最小入侵式地把位置信息注入到语义空间中?
RoPE 的答案是:
不对整个高维向量做一次整体旋转,而是把高维向量拆成多个二维子空间,每两个维度组成一组,在各自的小平面内独立旋转。
例如对于一个向量:
q=(q1,q2,q3,q4,q5,hot.xqsyb.com q6)
RoPE 会拆成:
(q1,q2),(q3,info.xqsyb.com q4),(q5,q6)
然后分别进行二维旋转:
R(θ1),R(θ2),R(θ3)
于是整个变换过程可以写成:
RoPE(q,m)=R(mθ1 tag.xqsyb.com)000R(mθ2)000R(mθ3)q
这样:每个二维旋转块,只会影响自己对应的两个维度。
例如 (q1,q2) 只会在自身内部发生变化:
q1′q2′\]=R(θ)\[q1q2
具体展开就是这样:
q1′=q1cosθ−q2sinθ
q2′=q1sinθ+q2cosθ
现在, 特征只会在两个维度间进行局部混合,不会像之前一样发生全局混合。
这样,原本的大尺度语义结构仍然保留,特征之间的稳定关系就不会被整体破坏,优化也更容易进行。
值得一提的是,为了合理应用 RoPE topic.xqsyb.com和其他相关技术,我们会刻意设计模型输入维度为偶数,如果出现了奇数情况,那么最后一维不旋转。
除此之外,旋转本身还有一个极其重要的性质:
旋转矩阵是正交矩阵,应用只会改变向量方向,而不会改变长度。
这相比之前的直接修改特征值或额外叠加位置特征,RoPE search.xqsyb.com更接近在原有语义结构上,施加一种轻量级的几何变化。
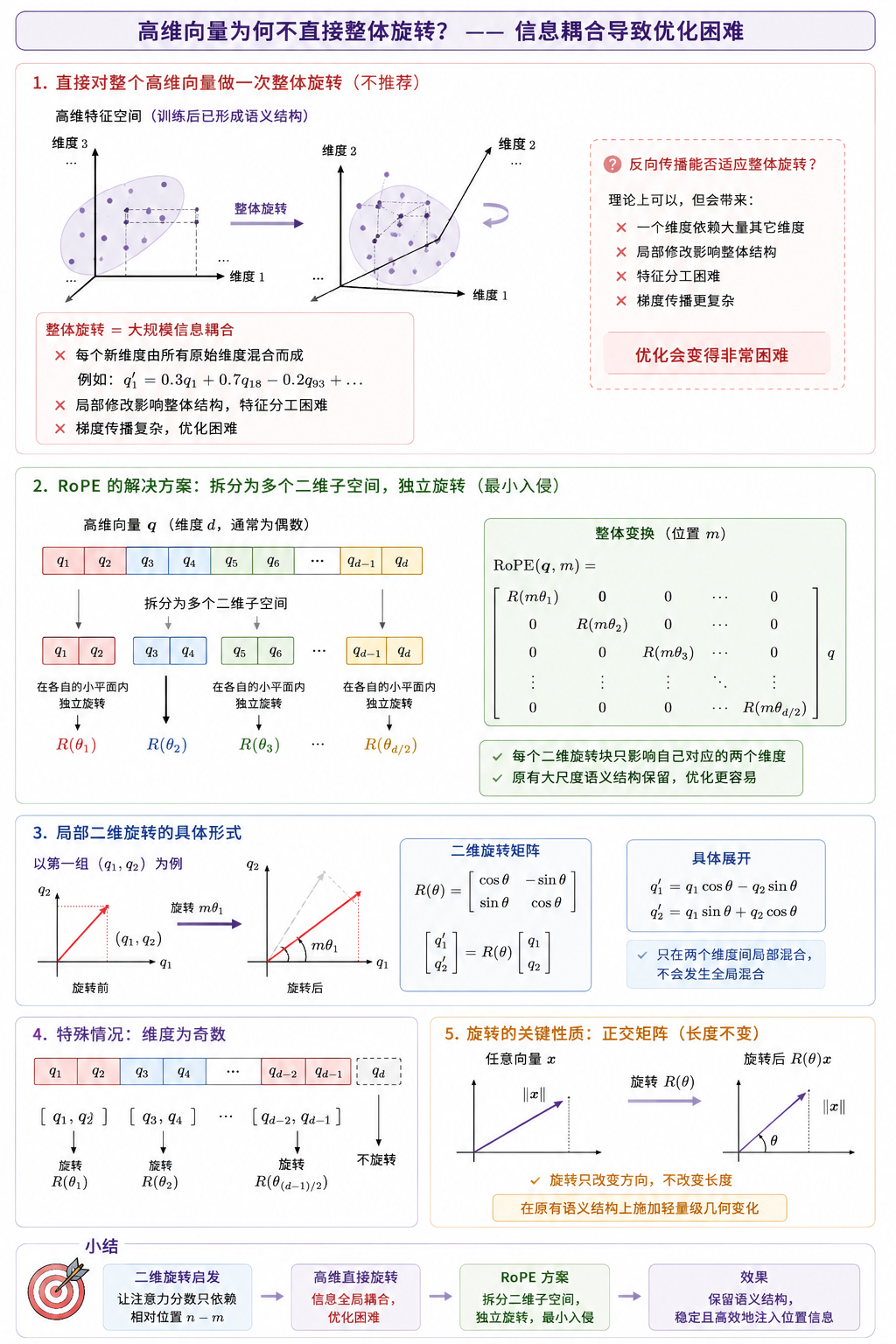
到这里,我们先初步解决了高维向量的旋转带来的优化问题,下面才是旋转在语义逻辑中的真实应用。
2.2 不同频率的旋转#
在之前的 T5 中,我们就提到过可学习编码相对固定编码的优势:适应能力 ,但这也让其失去了外推能力。
而 RoPE 以一种及其巧妙的方式几乎实现了二者兼得,我们来具体展开:
首先,如果所有二维子空间都使用同一个角度 θ 旋转,那么位置 m 的旋转就是:
R(mθ)
你会发现这时位置 m 所在 token 的所有维度都会以完全同步 的方式旋转。这会导致一个严重问题:整个高维空间实际上只拥有一种位置变化模式。
这样模型能够表达的位置关系非常有限。 因为不同的距离会被混在同一种旋转节奏中,很容易出现 "不同 token 间:我正好比你多转一个周期,咱们俩是一样的" 这种情况,这就会混淆模型对近距离和远距离的感知。
所以,RoPE feed.xqsyb.com同样给出了解决方案:
不同二维子空间使用不同旋转频率。
即不同维度拥有不同的 θi,通常定义为:
θi=10000−2id
这样,低维部分更高频,对位置变化更敏感,高维部分更低频,更适合远距离关系。
我们举一个简单的实例,假设现在只有两个二维子空间:
,,θ1=1,θ2=0.01
对于位置m=1 :
,,1×θ1=1,1×θ2=0.01
而当位置变成 m=100 时:
,,100×1=100,100×0.01=1
你会发现:
- 高频部分疯狂旋转,相邻 token 的差异会被迅速放大,它更适合编码近距离关系。
- 低频部分变化缓慢,即使位置跨度很大,角度差异仍然保持稳定,它更适合编码长距离关系。
这样即使某一个频率"绕了一圈",其它频率通常仍然不会同步重复。多个频率共同组合后,模型就能够唯一地区分大量不同位置。
现在,我们就可以回到开始的问题:
为什么说 RoPE 同时具备"固定编码"和"可学习编码"的优点?
首先,RoPE article.xqsyb.com的旋转规律是固定的,因此它保留了数学连续性,从而确保了外推能力。
于此同时,真正承载语义信息的 Q 或 K 仍然是自适应的,以 Q 为例:
Q=XWQ
中的 WQ 仍然是可学习的,于是模型会主动学习哪些特征适合高频旋转、哪些特征适合低频旋转、如何组织语义空间去适应旋转结构等逻辑,而这就确保了其同时拥有一定的适应能力。
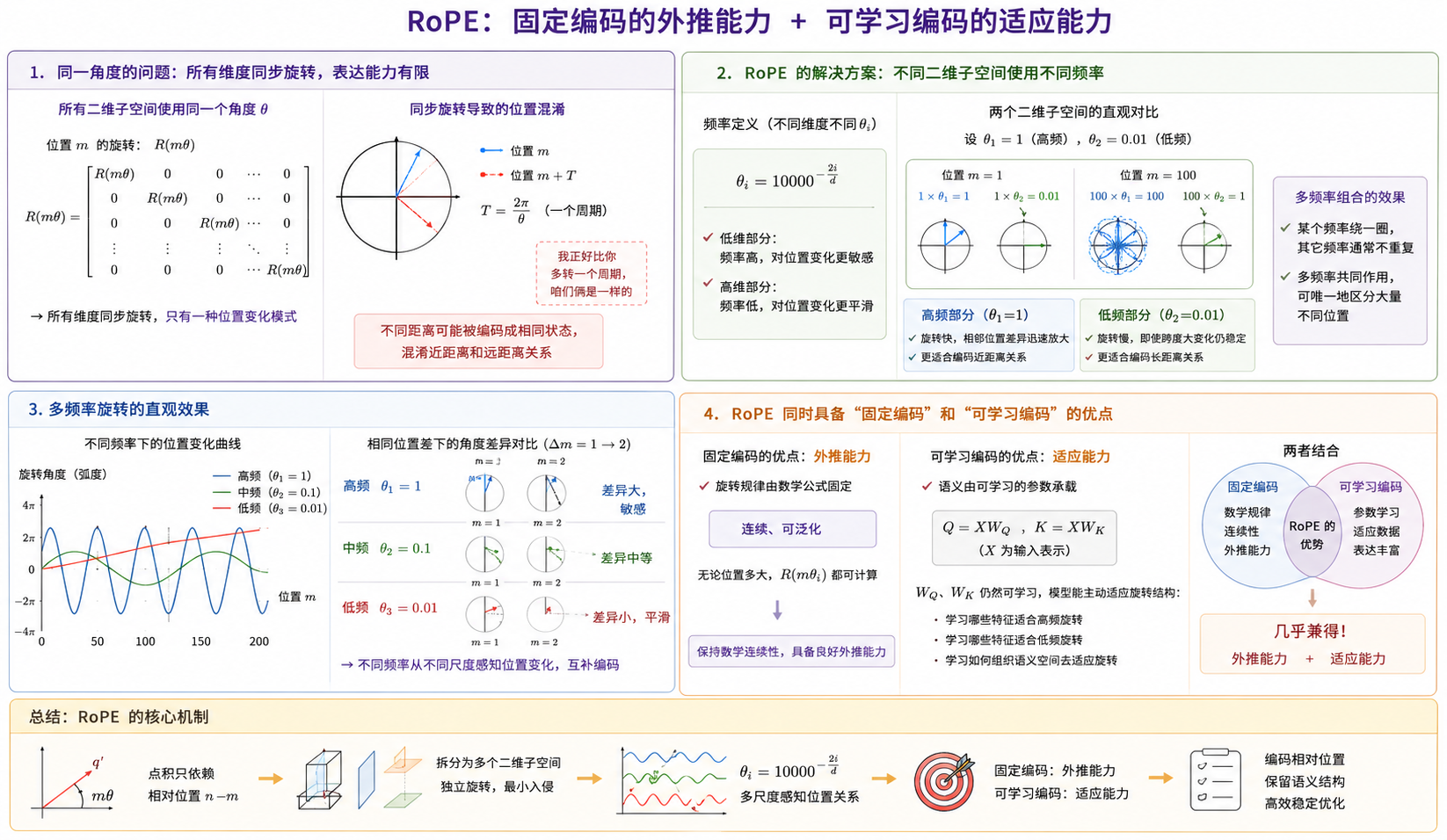
3. RoPE 的优势所在#
最终,RoPE没有修改 Attention 公式,没有增加额外 Bias,没有显式位置表,只是对 Q,K 做了一个几何变换,就让其天然变成了与相对位置相关的注意力机制。
在实现中,整个 RoPE post.xqsyb.com操作只是逐对执行:
RoPE(q,m)=mobile.xqsyb.comq1cos(mθ0)−q2sin(mθ0)q1sin(mθ0)+q2cos(mθ0)q3cos(mθ1)−q4sin(mθ1)q3sin(mθ1)+q4cos(mθ1)⋮
这意味着整个操作复杂度是 O(d),和 Q/K 本身的线性变换完全同量级。 连额外计算开销都几乎没有。
此外,值得一提的是,在 RoPE 的框架下,两个距离很远的 token 的 QK 点积上界会自然变小。
可以理解为:不同频率的旋转角度随着 |i−j| 增大会产生不同程度的累积。高频维度在远距离时旋转了太多圈,两个向量的方向越来越难对齐,于是点积上界自然降低。
而这种位置越远的 token,对当前 token 的影响上限越低,这恰好是语言模型需要的一种归纳偏置。
再结合 Cache 等工程优化,从 2023 年开始,RoPE 几乎成了开源大语言模型位置编码的标准答案:
| 模型系列 | 备注 |
|---|---|
| LLaMA / LLaMA 2 / LLaMA 3 | RoPE + Position Interpolation 扩展 |
| Mistral / Mixtral | 滑动窗口 + RoPE |
| Qwen 系列 | RoPE + NTK-aware 扩展 |
| GLM 系列 | RoPE |
| Gemma | RoPE |
| DeepSeek web.xqsyb.com | 改进版 RoPE |
4. 二维 RPE 现状#
需要强调的是:RoPE 虽然成为了现代 NLP 的 RPE 范式,但其在二维数据中却并不能很好地直接迁移。
其根本原因可以总结为:
RoPE 建模的是"序列距离关系",而视觉更依赖"空间几何关系"。
在 NLP 中,token 的位置天然是一条线性序列,而图像中的位置却是二维坐标:
虽然可以简单地将两个方向分别做 RoPE 旋转,但这种方式本质上只是两个一维编码的拼接,难以真正表达二维空间中的方向性、几何结构、局部纹理关系等视觉信息。
此外,RoPE 还有我们上面提到的: "距离越远,相关性更容易衰减。" 的逻辑。但在视觉任务中:两个距离很远的 patch 仍然可能高度相关,例如天空纹理等。
因此,目前二维位置编码仍然没有像 NLP 中的 RoPE 那样的统一标准答案。
当前主流方案主要包括:
| 方向 | 本质目标 |
|---|---|
| Relative Bias news.xqsyb.com | 显式建模二维距离 |
| 2D RoPE | 尝试保留 RoPE 的相对位置性质 |
| LePE / Conv PE | 补充局部纹理与方向归纳偏置 |
| Hybrid 方法 | 同时结合全局 Attention 与局部几何结构 |
其大致趋势仍然是在 Attention 的二维位置建模中引入图像数据的几何归纳偏置。