🔥2026年即插即用模块目录:🔥2026年即插即用模块目录 | 卷积模块、注意力模块、特征融合模块、Mamba模块、时间序列预测模块等CV和NLP任务通用、覆盖机器学习、深度学习等支持各类人工智能相关任务,万能通用模块持续更新中!
本文目录
1.🔥论文介绍:
🔥CVPR 2025 顶会🔥

论文题目:DarkIR: Robust Low-Light Image Restoration
中文题目:DarkIR:稳健的弱光图像恢复
所属单位:沃尔茨堡大学
摘要:夜间或低光环境下的摄影通常会因环境昏暗和长时间曝光的普遍使用而面临噪点、低光和模糊等问题。虽然去模糊和低光图像增强(LLIE)在这些条件下存在关联,但大多数图像修复方法都是分别处理这两个任务。本文提出了一种高效且鲁棒的多任务低光图像修复神经网络。我们摒弃了当前基于Transformer模型的流行趋势,创新性地引入注意力机制来增强高效卷积神经网络的感受野。与先前方法相比,我们的方法在参数和MAC运算方面显著降低了计算成本。我们的模型DarkIR在LOLBlur、LOLv2和Real-LOLBlur等主流数据集上取得了新的前沿成果,能够对真实世界的夜间和暗光图像进行泛化处理。

先前的弱光图像增强(LLIE)与修复方法对模糊和光照变化不够稳健。我们的多任务模型能够在不同光照、噪声和模糊条件下还原真实的弱光图像。
2.🔥论文创新点:
这篇论文提出了一个名为DarkIR的多任务低光图像增强和恢复模型,主要贡献如下:
-
多任务图像恢复:该模型不仅解决低光图像增强(LLIE)问题,还联合解决去噪和去模糊任务,针对低光、噪声和模糊的图像进行联合恢复。传统方法通常分开处理这些任务,而DarkIR通过结合它们,显著提高了恢复性能和效率。
-
创新的网络设计:
-
频率和空间域注意力机制 :该模型结合了空间和频率域信息,通过频率注意力机制 改善低光条件,并利用大视野空间注意力机制提升去模糊效果。
-
编码器-解码器架构:模型的编码器专注于低光图像的频率域增强,解码器则在空间域中减小模糊并提高图像清晰度。这样的设计不仅保证了高效性能,还降低了计算量。
-
-
性能提升 :DarkIR在多个基准数据集(如LOLBlur、LOLv2、Real-LOLBlur)上取得了最新的最先进结果,相较于现有方法,PSNR提高了1dB,LPIPS值也显著降低。相比其他模型,DarkIR具有更低的计算成本和更少的参数,适用于资源受限的设备。
-
效率与轻量化:该模型在保持高性能的同时,减少了55%的参数数量,相较于LEDNet模型,计算操作减少了4倍,相比Restormer则减少了约20倍,适合在低计算资源的设备上部署。
-
实用性和扩展性:论文还展示了该模型在真实场景中的表现,并在多个实际应用数据集(如Real-LOLBlur和LSRW)中测试了其稳健性,表明其对现实世界的低光模糊图像具有良好的适应性。
总的来说,DarkIR在低光图像恢复和增强领域提供了一种高效、强大且适应性广泛的解决方案,尤其适合低光、噪声和模糊条件下的图像处理。
3.🔥方法描述:
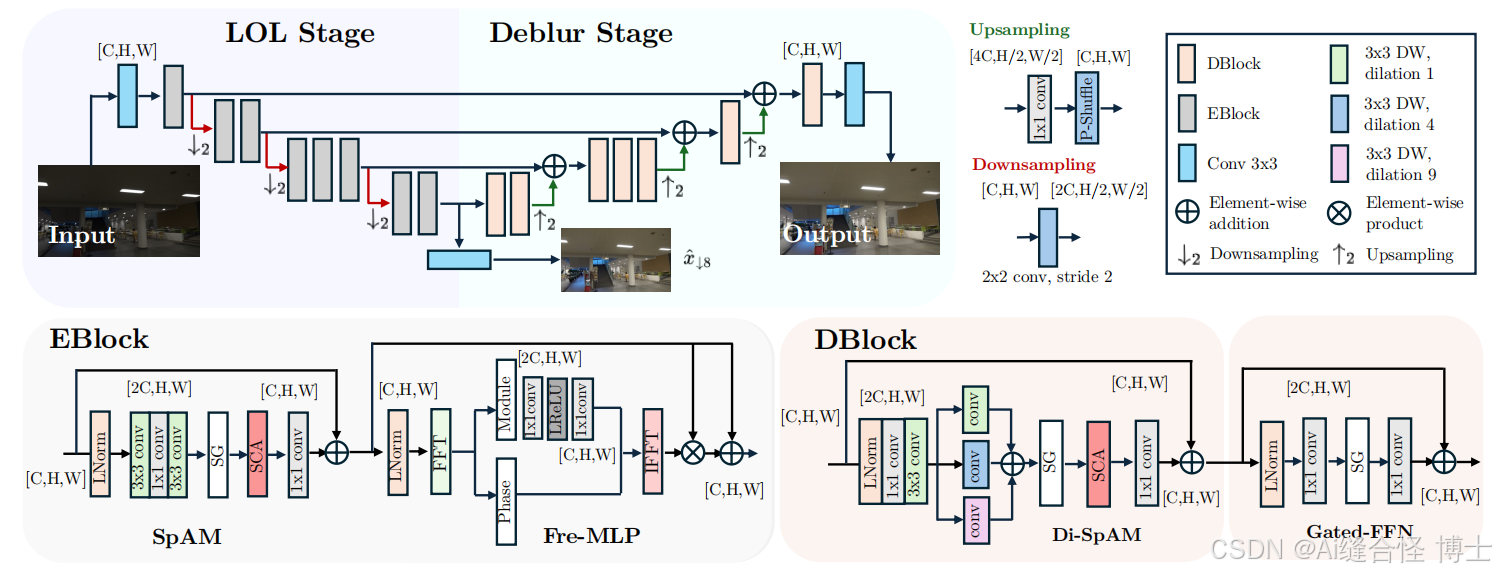
DarkIR系统架构示意图。该神经网络采用编码器-解码器架构,其编码与解码模块分别基于Metaformer结构65。编码器通过傅里叶信息处理低光照场景,生成光照校正后的低分辨率重建图像 。解码器则利用增强光照特征进行图像放大和去模糊处理,通过大感受野空间注意力机制实现这一目标。这种设计使我们的轻量级模型在参数量和浮点运算量上均优于传统方法。
DarkIR方法主要通过以下几个关键设计来实现低光图像恢复和增强:
-
多任务联合恢复:DarkIR结合了低光图像增强(LLIE)、去噪和去模糊任务,通过一个统一的框架处理这些问题,提升了图像恢复的效果。这种多任务学习方法能更好地利用各任务之间的关联,从而提高整体性能。
-
编码器-解码器架构:
-
编码器:采用频率域增强来改善低光条件,利用频域的全局信息提升图像的亮度和对比度。通过Fast Fourier Transform(FFT)增强图像的幅度,再通过Inverse FFT(IFFT)转换回空间域。
-
解码器:专注于空间域,减少图像的模糊并提升细节。解码器使用大视野空间注意力机制来增强图像的锐度和清晰度。
-
-
大视野空间注意力机制 :解码器使用Dilated-Spatial Attention Module (Di-SpAM),该模块通过多尺度深度卷积,利用扩展卷积核来处理不同尺度的特征,进一步提升去模糊效果,同时减少计算量。
-
频率注意力机制:在编码器中,利用频率注意力机制提升低光图像的幅度部分,特别是通过频率域中的全局信息来优化光照增强,避免在空间域进行复杂的运算,从而提升效率。
-
轻量化设计:采用高效的卷积设计和注意力机制,减少模型的参数和计算量。相比于其他现有方法,DarkIR的参数数量和计算操作大幅减少(例如,减少55%的参数和4倍的计算量),使其适合在低计算资源的设备上运行。
-
损失函数 :DarkIR使用结合像素级损失(L1损失) 、感知损失(LPIPS)和边缘损失(Ledge)的复合损失函数,确保图像恢复的高质量,特别是提升图像的细节和感知质量。
-
数据集与评估:DarkIR在多个公共数据集上进行了测试,包括LOLBlur、LOLv2、Real-LOLBlur等,取得了显著的性能提升,并在实际的夜间和低光环境中展示了强大的适应能力。
DarkIR方法通过创新的编码器-解码器架构,结合频率和空间注意力。
4.🔥EBlock即插即用模块作用和实现:
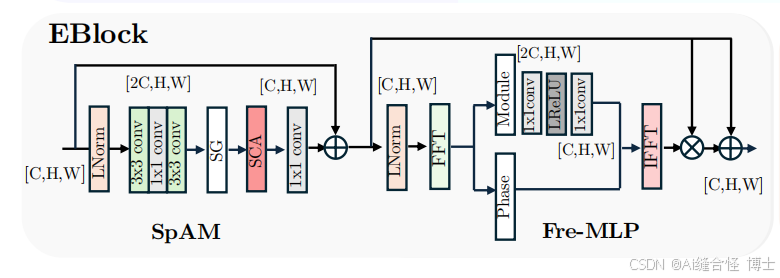
作用:
EBlock的主要作用是通过频率域增强 和空间注意力机制,提高图像的亮度和对比度,使图像在低光条件下表现更加清晰。它专注于改善图像的光照条件,同时减少噪声和模糊。
实现:
-
空间注意力模块(SpAM):SpAM类似于NAFNet中的模块,通过反向残差块和简化的通道注意力(SCA)来增强空间域中的重要特征。与传统的激活函数不同,SpAM使用了一个简单的门控机制,使模型能够选择性地提取与光照增强相关的空间特征。
-
频率域处理(Fre-MLP):
-
在频率域,EBlock通过**快速傅里叶变换(FFT)**对图像进行转换,只操作图像的幅度部分。低光图像的光照信息通常集中在频率域的幅度部分,因此,EBlock通过增强这些部分来改善图像亮度。
-
频率信息增强后,EBlock通过**逆快速傅里叶变换(IFFT)**将增强的幅度部分转换回空间域,以恢复图像。
-
-
下采样与特征提取:编码器使用步长卷积来对特征进行下采样,每次下采样时,图像的空间分辨率减少一半。这样,EBlock能够提取多尺度的特征,同时保持计算效率。
-
低分辨率重建:EBlock将处理后的图像转化为低分辨率的图像(相比原图缩小8倍),并通过卷积层对其进行组合。这个低分辨率的图像表示了增强后的光照效果,并将其作为输入传递给解码器以进行进一步处理。
5.🔥适用任务场景:
EBlock模块的适用计算机视觉任务:
-
低光图像增强(LLIE):EBlock专注于低光环境下的图像增强,通过频率域处理提升图像的亮度和对比度,适用于夜间或低光条件下的图像增强。
-
图像去噪:通过增强频率域中的幅度信息,EBlock可以有效减少低光图像中的噪声,尤其是光照不足或图像质量较差的情况。
-
图像去模糊:在低光环境下,由于曝光时间较长,图像可能出现模糊。EBlock通过空间注意力和频率域增强处理,能够帮助减少或消除图像模糊,提升图像的清晰度。
-
图像恢复:EBlock在图像恢复任务中表现出色,能够通过低光增强、去噪和去模糊等多重处理,恢复被损坏或低质量的图像,尤其适用于低分辨率或受损图像。
-
夜间摄影图像处理:EBlock特别适用于夜间或暗光条件下的图像恢复,能够提高暗部细节,改善图像整体质量,使其更符合人眼感知。
-
图像增强与增强现实(AR):在增强现实应用中,尤其是夜间或光线不足的环境下,EBlock能够提高图像质量,使AR体验更加流畅和逼真。
-
医学影像分析:对于低光或噪声较多的医学图像(如X光、CT图像等),EBlock能够有效提升图像质量,帮助医生更准确地分析和诊断。
6.🔥即插即用模块代码:
python
import torch
import torch.nn as nn
class SimpleGate(nn.Module):
def forward(self, x):
x1, x2 = x.chunk(2, dim=1)
return x1 * x2
class FreMLP(nn.Module):
def __init__(self, nc, expand=2):
super(FreMLP, self).__init__()
self.process1 = nn.Sequential(
nn.Conv2d(nc, expand * nc, 1, 1, 0),
nn.LeakyReLU(0.1, inplace=True),
nn.Conv2d(expand * nc, nc, 1, 1, 0))
def forward(self, x):
_, _, H, W = x.shape
x_freq = torch.fft.rfft2(x, norm='backward')
mag = torch.abs(x_freq) #分离出频域数据的 幅度(magnitude)
pha = torch.angle(x_freq) #分离出频域数据的 相位(phase)
mag = self.process1(mag)
real = mag * torch.cos(pha)
imag = mag * torch.sin(pha)
x_out = torch.complex(real, imag)
x_out = torch.fft.irfft2(x_out, s=(H, W), norm='backward')
return x_out
class Branch(nn.Module):
'''
Branch that lasts lonly the dilated convolutions AI缝合怪-独家复现整理、顶会顶刊即插即用模块!
'''
def __init__(self, c, DW_Expand, dilation=1):
super().__init__()
self.dw_channel = DW_Expand * c
self.branch = nn.Sequential(
nn.Conv2d(in_channels=self.dw_channel, out_channels=self.dw_channel, kernel_size=3, padding=dilation,
stride=1, groups=self.dw_channel,
bias=True, dilation=dilation) # the dconv
)
def forward(self, input):
return self.branch(input)
class LayerNormFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, weight, bias, eps):
ctx.eps = eps
N, C, H, W = x.size()
mu = x.mean(1, keepdim=True)
var = (x - mu).pow(2).mean(1, keepdim=True)
y = (x - mu) / (var + eps).sqrt()
ctx.save_for_backward(y, var, weight)
y = weight.view(1, C, 1, 1) * y + bias.view(1, C, 1, 1)
return y
@staticmethod
def backward(ctx, grad_output):
eps = ctx.eps
N, C, H, W = grad_output.size()
y, var, weight = ctx.saved_variables
g = grad_output * weight.view(1, C, 1, 1)
mean_g = g.mean(dim=1, keepdim=True)
mean_gy = (g * y).mean(dim=1, keepdim=True)
gx = 1. / torch.sqrt(var + eps) * (g - y * mean_gy - mean_g)
return gx, (grad_output * y).sum(dim=3).sum(dim=2).sum(dim=0), grad_output.sum(dim=3).sum(dim=2).sum(
dim=0), None
class LayerNorm2d(nn.Module):
def __init__(self, channels, eps=1e-6):
super(LayerNorm2d, self).__init__()
self.register_parameter('weight', nn.Parameter(torch.ones(channels)))
self.register_parameter('bias', nn.Parameter(torch.zeros(channels)))
self.eps = eps
def forward(self, x):
return LayerNormFunction.apply(x, self.weight, self.bias, self.eps)
class EBlock(nn.Module):
'''
Change this block using Branch AI缝合怪-独家复现整理、顶会顶刊即插即用模块!
'''
def __init__(self, c, DW_Expand=2, dilations=[1, 4, 9], extra_depth_wise=True):
super().__init__()
# we define the 2 branches
self.dw_channel = DW_Expand * c
self.extra_conv = nn.Conv2d(c, c, kernel_size=3, padding=1, stride=1, groups=c, bias=True,
dilation=1) if extra_depth_wise else nn.Identity() # optional extra dw
self.conv1 = nn.Conv2d(in_channels=c, out_channels=self.dw_channel, kernel_size=1, padding=0, stride=1,
groups=1, bias=True, dilation=1)
self.branches = nn.ModuleList()
for dilation in dilations:
self.branches.append(Branch(c, DW_Expand, dilation=dilation))
assert len(dilations) == len(self.branches)
self.dw_channel = DW_Expand * c
self.sca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=self.dw_channel // 2, kernel_size=1, padding=0,
stride=1,
groups=1, bias=True, dilation=1),
)
self.sg1 = SimpleGate()
self.conv3 = nn.Conv2d(in_channels=self.dw_channel // 2, out_channels=c, kernel_size=1, padding=0, stride=1,
groups=1, bias=True, dilation=1)
# second step AI缝合怪-独家复现整理、顶会顶刊即插即用模块!
self.norm1 = LayerNorm2d(c)
self.norm2 = LayerNorm2d(c)
self.freq = FreMLP(nc=c, expand=2)
self.gamma = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
self.beta = nn.Parameter(torch.zeros((1, c, 1, 1)), requires_grad=True)
def forward(self, inp):
y = inp
x = self.norm1(inp)
x = self.conv1(self.extra_conv(x))
z = 0
for branch in self.branches:
z += branch(x)
z = self.sg1(z)
x = self.sca(z) * z
x = self.conv3(x)
y = inp + self.beta * x
# second step
x_step2 = self.norm2(y) # size [B, 2*C, H, W]
x_freq = self.freq(x_step2) # size [B, C, H, W]
x = y * x_freq
x = y + x * self.gamma
return x
# 测试代码
if __name__ == "__main__":
# 模型实例化
model =EBlock(c=64)
# 随机输入
input_tensor = torch.randn(1, 64, 128, 128) # Batch size: 1, Channels: 64, Height: 128, Width: 128
# 前向传播
output_tensor = model(input_tensor)
print("AI缝合怪-独家复现整理、顶会顶刊即插即用模块!")
print("输入特征层维度:", input_tensor.shape)
print("输出特征层维度:", output_tensor.shape)