简述:ResNet34/ResNet50及SENet改进模型
原理、准确率与实战选型
在深度学习计算机视觉领域,卷积神经网络(CNN)始终是图像分类、目标检测、图像分割等任务的核心骨干网络。传统深度CNN随着层数加深,会出现梯度消失、网络退化、特征表征能力不足等致命问题,严重限制了模型性能上限。
2015年ResNet(残差网络)的问世彻底打破了深层网络的训练瓶颈,凭借残差连接的核心设计,实现了超深网络的稳定训练。其中ResNet34、ResNet50作为轻量与通用型的代表模型,被广泛应用于工业落地、科研实验、轻量化部署等各类场景。而SENet(挤压激励网络)的出现,为ResNet系列模型提供了全新的优化方向,通过通道注意力机制大幅提升模型特征提取精度。
本文将从零拆解ResNet34、ResNet50的核心原理、参数差异、准确率表现,深入讲解SE-ResNet34、SE-ResNet50的改进逻辑与性能提升效果,最后结合实战场景给出模型选型与优化建议,帮助大家彻底吃透这两组经典骨干网络。
一、ResNet核心底层原理:解决深层网络的核心痛点
在正式讲解ResNet34与ResNet50之前,首先要明确ResNet的核心创新------残差连接(Residual Connection)。传统卷积网络的学习逻辑是逐层拟合恒等映射,层数越多,梯度反向传播时衰减越严重,最终导致浅层网络参数无法更新,出现网络退化问题,即层数增加、准确率反而下降。
ResNet摒弃了传统的恒等映射学习逻辑,转而学习残差映射。其核心结构由「主分支卷积层」和「捷径连接(Shortcut)」组成:主分支负责拟合输入与输出之间的残差特征,捷径连接直接跳过部分卷积层,将原始特征直接传递到后续层。
这种设计让梯度可以通过捷径连接无损反向传播,彻底解决了深层网络梯度消失、网络退化的问题,让数百层的深度神经网络可以稳定训练收敛,同时保留浅层基础特征与深层高级语义特征。根据基础模块的不同,ResNet分为基础块(BasicBlock)和瓶颈块(Bottleneck),这也是ResNet34与ResNet50最核心的结构差异。
二、ResNet34与ResNet50详细对比:原理、参数与准确率
2.1 结构原理差异
ResNet34属于浅层经典残差网络,全程采用BasicBlock基础残差模块,网络总计34层可训练卷积层。单个基础模块由两个3×3卷积层串联组成,结构简洁、计算逻辑简单,专注于提取图像的基础空间特征、纹理特征与边缘特征。模块无维度压缩与升维操作,特征图尺寸与通道数变化平缓,适配轻量化特征提取场景。
ResNet50是工业界最常用的通用型残差网络,共50层卷积层,全部采用Bottleneck瓶颈残差模块。单个瓶颈模块采用「1×1卷积降维+3×3卷积特征提取+1×1卷积升维」的三段式结构。其中1×1卷积负责压缩通道数、降低计算量,3×3卷积完成核心特征学习,最后通过1×1卷积恢复通道维度。
这种瓶颈结构看似增加了网络层数,实则通过通道压缩大幅降低了整体计算冗余,同时能够挖掘更细腻的高级语义特征,特征表征能力远优于ResNet34,也是深层ResNet模型性能跃升的关键原因。
2.2 参数量与计算资源差异
参数量直接决定模型的训练成本、推理速度与硬件适配性,两者参数差距十分明显:
ResNet34的参数由卷积层与全连接层构成,整体参数量约2180万,其中卷积层参数占绝对主体,全连接层参数约170万。模型结构轻量化,训练所需显存、算力资源更少,收敛速度更快。
ResNet50整体参数量约2563万,略高于ResNet34。其参数主要集中在堆叠的瓶颈残差模块中,仅残差模块参数就约2002万,占总参数的78%以上。得益于瓶颈结构的优化,ResNet50在参数小幅增加的前提下,实现了特征提取维度的全面升级,性价比极高。
2.3 基准数据集准确率表现(ImageNet)
在ImageNet大规模图像分类数据集上,两者的基准性能差异清晰体现了结构优势:
ResNet34:Top-1准确率约73.3%,Top-5准确率约91.4%。模型优势是收敛速度快、推理延迟低,在小规模数据集、算力有限的场景下泛化稳定性较好,但对细粒度特征、复杂场景特征的捕捉能力有限,准确率上限较低。
ResNet50:Top-1准确率约77.1%,Top-5准确率约93.5%。相较于ResNet34,Top-1精度提升近4个百分点,Top-5精度提升2.1个百分点。虽然训练耗时略有增加,但高级语义特征提取能力更强,对复杂图像、相似目标的区分效果更好,是绝大多数视觉任务的默认骨干网络。
三、SENet改进模型:SE-ResNet34与SE-ResNet50核心解析
ResNet系列模型通过残差连接解决了网络深度不足的问题,但存在一个固有缺陷:卷积操作对所有通道特征平等对待,无法区分不同通道特征的重要性。对于冗余通道、无效噪声通道,模型会浪费算力进行无效学习,同时压制关键特征通道的权重,限制模型精度上限。
SENet(挤压激励网络)针对性提出通道注意力机制,通过SE模块对特征通道进行自适应权重校准,嵌入ResNet后形成的SE-ResNet34、SE-ResNet50,能够在小幅增加参数的前提下,显著提升模型特征筛选能力与分类准确率。
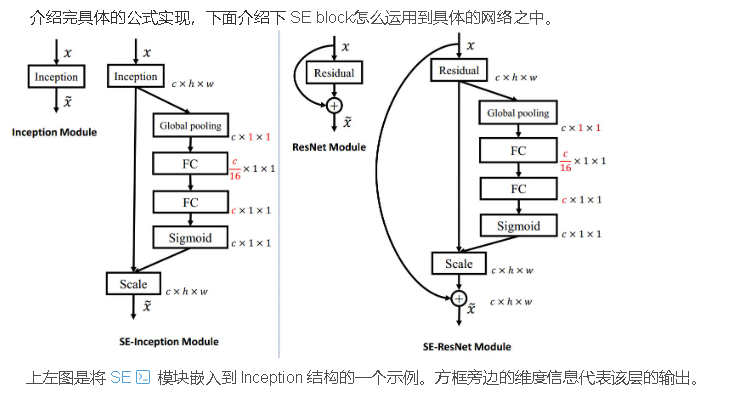
3.1 SENet核心模块原理(SE模块)
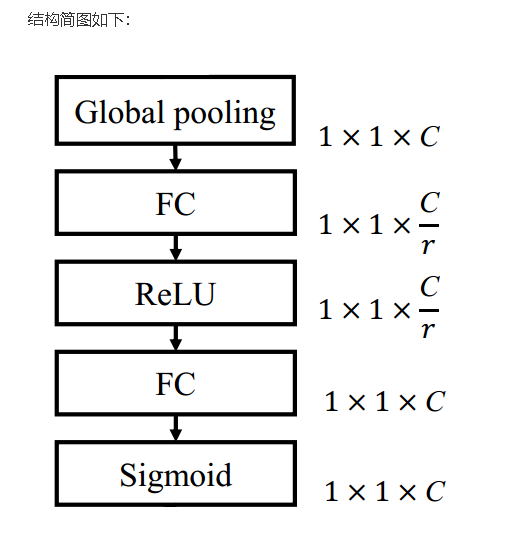
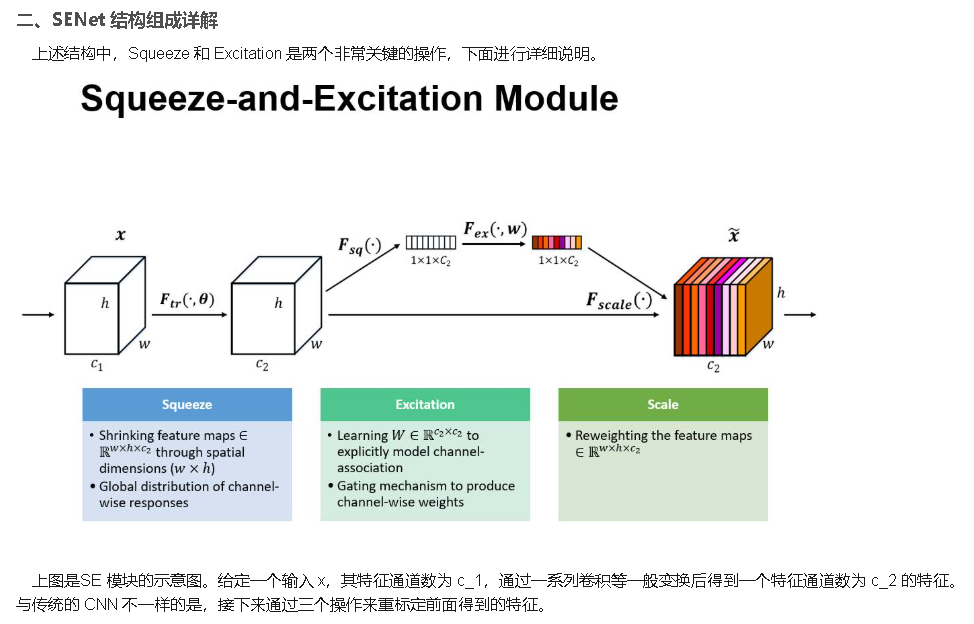
SE模块结构极简、通用性极强,可无缝嵌入任意ResNet残差模块,核心分为Squeeze(挤压)、Excitation(激励)、Scale(权重重标定)三个步骤:
- Squeeze挤压操作:通过全局平均池化,将每个二维特征图压缩为一个一维特征数值,聚合单通道全局空间信息,生成通道描述符,解决单通道特征空间信息碎片化的问题。
- Excitation激励操作:通过两层全连接层+Sigmoid激活函数,学习通道之间的非线性依赖关系,为每个通道生成0-1之间的权重系数,自动判别各通道特征的重要程度。
- Scale重标定操作:将学习到的通道权重与原始特征图逐通道相乘,强化有效特征通道、抑制冗余噪声通道,完成特征自适应优化。
整个SE模块计算量极小,几乎不增加推理延迟,却能让模型自主聚焦核心特征,是轻量化提升模型性能的经典改进方案。
Squeeze-and-Excitation Networks(简称 SENet)是 Momenta 胡杰团队(WMW)提出的新的网络结构,利用SENet,一举取得最后一届 ImageNet 2017 竞赛 Image Classification 任务的冠军,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
3.2 SE-ResNet34:轻量模型的精度升级
改进逻辑:将SE模块逐一嵌入ResNet34的每一个BasicBlock基础残差模块末端,在基础卷积特征提取完成后,增加通道注意力校准环节。
性能与参数变化:SE-ResNet34仅比原生ResNet34增加约5%的参数量,算力开销几乎可忽略。在ImageNet数据集上,Top-1准确率从73.3%提升至75.8%,Top-5准确率提升至92.6%。
核心优势:保留了ResNet34轻量化、低延迟、易训练的特点,同时弥补了其特征筛选能力弱的短板,在移动端部署、实时检测、小规模数据集任务中,性价比远超原生ResNet34。
3.3 SE-ResNet50:通用模型的性能天花板提升
改进逻辑:将SE模块嵌入ResNet50的所有Bottleneck瓶颈模块中,针对瓶颈结构提取的多维度高级特征进行通道权重优化,适配复杂语义特征的筛选与强化。
性能与参数变化:SE-ResNet50参数量小幅提升至2800万左右,计算增量可控。在ImageNet数据集上,Top-1准确率从77.1%提升至79.7%,Top-5准确率达到94.8%,是ResNet50的高效升级版。
核心优势:解决了原生ResNet50对细粒度特征、相似特征区分度不足的问题,在图像分类、目标检测、语义分割、场景识别等复杂任务中,泛化能力与鲁棒性显著提升,是工业界高精度任务的首选骨干网络之一。
四、四类模型综合性能对比汇总
为方便直观对比,整理ImageNet数据集下四类模型核心指标如下:
模型 核心模块 参数量 Top-1准确率 Top-5准确率 核心特点
ResNet34 BasicBlock 2180万 73.3% 91.4% 轻量化、低延迟、精度一般
SE-ResNet34 BasicBlock+SE注意力 2290万 75.8% 92.6% 轻量高效、精度大幅提升
ResNet50 Bottleneck 2563万 77.1% 93.5% 通用均衡、性能稳定
SE-ResNet50 Bottleneck+SE注意力 2800万 79.7% 94.8% 高精度、强泛化、适配复杂场景
五、实战场景模型选型与优化建议
5.1 场景选型指南
- 算力有限、实时性要求高场景(移动端部署、嵌入式设备、实时视频识别):优先选择SE-ResNet34。相较于原生ResNet34,精度提升明显,且保留轻量化优势,兼顾速度与精度平衡,性价比远超原生模型。
- 通用工业场景、常规视觉任务(通用图像分类、普通目标检测):原生ResNet50足够使用,模型成熟、部署成本低、不易过拟合,适配大多数基础任务需求。
- 高精度需求场景(细粒度分类、医疗影像识别、复杂场景检测):首选SE-ResNet50。小幅算力代价换取显著精度提升,能有效捕捉细微特征差异,适配高精度业务需求。
5.2 通用模型优化技巧 - 合理控制训练周期:增加epochs可稳步提升模型收敛精度,但需监控验证集准确率,避免过度训练导致过拟合,可搭配早停策略锁定最优模型。
- 数据增强辅助:通过随机裁剪、翻转、缩放、色域变换等数据增强方式,扩充数据集多样性,提升模型泛化能力,尤其适配SE改进模型的特征学习。
- 正则化优化:搭配L2正则、Dropout策略,抑制模型过拟合,让注意力机制更专注于有效特征学习,进一步放大SENet改进的性能优势。
六、总结
ResNet34与ResNet50凭借残差连接的核心设计,奠定了深层视觉骨干网络的基础,分别适配轻量化与通用型视觉任务。而SENet通道注意力机制的嵌入,打破了原生ResNet的性能瓶颈,在几乎不增加算力负担的前提下,实现了模型精度的跨越式提升。
SE-ResNet34、SE-ResNet50兼顾了轻量化、高精度、强泛化三大优势,解决了原生模型特征筛选能力弱、细粒度识别差的问题。在实际项目落地中,根据算力资源、实时性要求、精度需求灵活选型原生模型与SE改进模型,搭配合理的训练优化策略,可最大化发挥模型性能,适配各类计算机视觉实战场景。
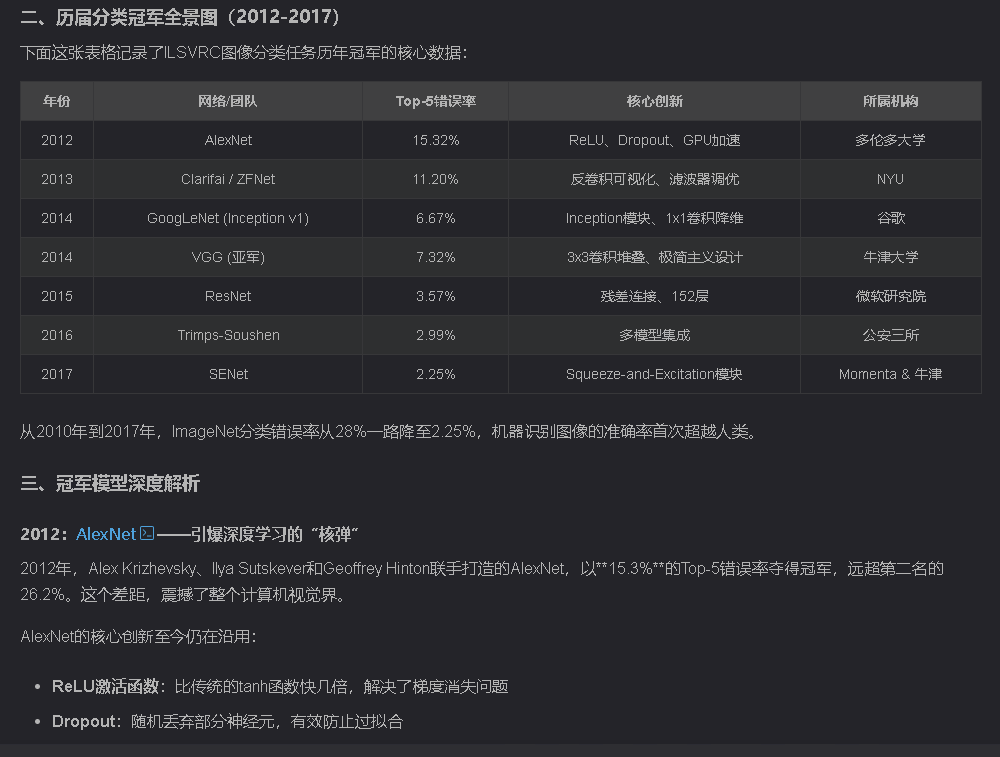
附历届分类冠军全景图(2012-2017)
 2018年后续
2018年后续

本blog地址:https://blog.csdn.net/hsg77