文章目录
-
- [IV. 性能分析](#IV. 性能分析)
-
- [A. 需要训练的参数数量](#A. 需要训练的参数数量)
- [B. 计算复杂性](#B. 计算复杂性)
- [V. 仿真](#V. 仿真)
-
- [A. 深度神经网络拓扑](#A. 深度神经网络拓扑)
- [B. 训练过程和优化超参数](#B. 训练过程和优化超参数)
- [C. 训练效率比较](#C. 训练效率比较)
- [D. DOA估计精度比较](#D. DOA估计精度比较)
- [E. 角分辨率比较](#E. 角分辨率比较)
- [F. 多个源的估计性能](#F. 多个源的估计性能)
- [G. 计算时间比较](#G. 计算时间比较)
- [H. 不同层数网络的比较](#H. 不同层数网络的比较)
- [I. 不同源数量的适配](#I. 不同源数量的适配)
- [J. 对非理想条件的适应](#J. 对非理想条件的适应)
- [VI. 结论](#VI. 结论)
- [附录 A. 反向传播步骤的导数](#附录 A. 反向传播步骤的导数)
- [附录 B. Tucker 秩选择过程的细节](#附录 B. Tucker 秩选择过程的细节)
IV. 性能分析
A. 需要训练的参数数量
如第 III-A 小节所述,基于矩阵的神经网络将矢量化隐藏状态 h l − 1 ∈ R ∏ h = 1 5 I l − 1 , h \mathbf{h}{l-1}\in\mathbb{R}^{\prod{h=1}^{5}I_{l-1,h}} hl−1∈R∏h=15Il−1,h 与参数矩阵 G l − 1 ∈ R ∏ h = 1 5 I l , h × ∏ h = 1 5 I l − 1 , h \mathbf{G}{l-1}\in\mathbb{R}^{\prod{h=1}^{5}I_{l,h}\times\prod_{h=1}^{5}I_{l-1,h}} Gl−1∈R∏h=15Il,h×∏h=15Il−1,h 相乘,得到 h l ∈ R ∏ h = 1 5 I l , h \mathbf{h}{l}\in\mathbb{R}^{\prod{h=1}^{5}I_{l,h}} hl∈R∏h=15Il,h,其中 l = 2 , 3 , ⋯ , L l=2,3,\cdots,L l=2,3,⋯,L。此外,第 L L L 个隐藏状态 h L \mathbf{h}{L} hL 还需与参数矩阵 W ∈ R 2 K × ∏ h = 1 5 I L , h \mathbf{W}\in\mathbb{R}^{2K\times\prod{h=1}^{5}I_{L,h}} W∈R2K×∏h=15IL,h 相乘以输出角度向量。因此,参数矩阵 { G 0 , G 1 , ⋯ , G L − 1 } \{\mathbf{G}{0},\mathbf{G}{1},\cdots,\mathbf{G}_{L-1}\} {G0,G1,⋯,GL−1} 和 W \mathbf{W} W 中需要训练的参数总数为
P M N N = 2 M 2 N 2 ∏ h = 1 5 I 1 , h + ∑ l = 2 L ∏ h = 1 5 I l − 1 , h I l , h + 2 K ∏ h = 1 5 I L , h . (27) P_{\mathrm{MNN}} =2M^{2}N^{2}\prod_{h=1}^{5}I_{1,h} +\sum_{l=2}^{L}\prod_{h=1}^{5}I_{l-1,h}I_{l,h} +2K\prod_{h=1}^{5}I_{L,h}. \tag{27} PMNN=2M2N2h=1∏5I1,h+l=2∑Lh=1∏5Il−1,hIl,h+2Kh=1∏5IL,h.(27)
相比之下,所提出的张量化神经层用逆 Tucker 因子的紧凑形式表示参数。具体而言,逆 Tucker 因子矩阵 { V 0 , h † , V 1 , h † , ⋯ , V L − 1 , h † , h = 1 , 2 , ⋯ , 5 } \{\mathbf{V}^{\dagger}{0,h},\mathbf{V}^{\dagger}{1,h},\cdots,\mathbf{V}^{\dagger}_{L-1,h},\,h=1,2,\cdots,5\} {V0,h†,V1,h†,⋯,VL−1,h†,h=1,2,⋯,5} 与输出层权重张量 W \boldsymbol{\mathcal{W}} W 中的参数总数为
P T N N = M I 1 , 1 + N I 1 , 2 + M I 1 , 3 + N I 1 , 4 + 2 I 1 , 5 + ∑ l = 2 L ∑ h = 1 5 I l − 1 , h I l , h + 2 K ∏ h = 1 5 I L , h . (28) P_{\mathrm{TNN}} =MI_{1,1}+NI_{1,2}+MI_{1,3}+NI_{1,4}+2I_{1,5} +\sum_{l=2}^{L}\sum_{h=1}^{5}I_{l-1,h}I_{l,h} +2K\prod_{h=1}^{5}I_{L,h}. \tag{28} PTNN=MI1,1+NI1,2+MI1,3+NI1,4+2I1,5+l=2∑Lh=1∑5Il−1,hIl,h+2Kh=1∏5IL,h.(28)
显然,式 (28) 将式 (27) 中的若干乘积项替换为求和项,从而得到 P T N N ≪ P M N N P_{\mathrm{TNN}}\ll P_{\mathrm{MNN}} PTNN≪PMNN。因此,张量化神经网络能够以更少参数提升训练效率并降低系统成本。
B. 计算复杂性
按照第 III-C 小节完成训练后,DOA 估计只需要执行前馈计算。所提出算法的实现包含协方差张量计算和张量化前馈计算;其中协方差张量计算复杂度为 T M 2 N 2 TM^{2}N^{2} TM2N2。由于隐藏状态张量尺寸 { I l , 1 , I l , 2 , I l , 3 , I l , 4 } \{I_{l,1},I_{l,2},I_{l,3},I_{l,4}\} {Il,1,Il,2,Il,3,Il,4} 小于输入协方差张量尺寸 { M , N , M , N } \{M,N,M,N\} {M,N,M,N},所提出算法的总体复杂度可写为
C T N N = O ( ( T + I 1 , 1 ) M 2 N 2 ) . C_{\mathrm{TNN}} =O\!\left((T+I_{1,1})M^{2}N^{2}\right). CTNN=O((T+I1,1)M2N2).
类似地,基于矩阵的神经网络 17 包括协方差矩阵计算与前馈计算,其复杂度可衡量为
C M N N = O ( ( T + ∏ h = 1 5 I 1 , h ) M 2 N 2 ) . C_{\mathrm{MNN}} =O\!\left(\left(T+\prod_{h=1}^{5}I_{1,h}\right)M^{2}N^{2}\right). CMNN=O((T+h=1∏5I1,h)M2N2).
与此同时,基于模型的 MUSIC 7、ESPRIT 8 和 CPD 方法 27 在二维 DOA 估计中的计算复杂度分别为 O ( M 3 N 3 + M N ( M N − K ) I S S ) O(M^{3}N^{3}+MN(MN-K)I_{\mathrm{SS}}) O(M3N3+MN(MN−K)ISS)、 O ( M 3 N 3 K ) O(M^{3}N^{3}K) O(M3N3K) 和 O ( T M 2 N 2 + K M 2 N 2 I C P D ) O(TM^{2}N^{2}+KM^{2}N^{2}I_{\mathrm{CPD}}) O(TM2N2+KM2N2ICPD),其中 I S S I_{\mathrm{SS}} ISS 与 I C P D I_{\mathrm{CPD}} ICPD 分别表示谱搜索网格点数和求解 CPD 优化问题的迭代次数。与这些基于模型的方法相比,张量化神经网络用高效前馈计算替代了耗时的信号子空间处理和 CPD 优化;相较基于矩阵的神经网络,多线性张量-矩阵乘积也需要更少乘法。
V. 仿真
在仿真中,本文考虑 M = 10 M=10 M=10、 N = 10 N=10 N=10 的 URA S \mathcal{S} S。所提出的深度张量二维 DOA 估计算法使用 PyTorch 实现,Tucker 秩选择通过贝叶斯优化工具完成 44。神经网络在配备 AMD Epyc 7543 CPU、128 GB RAM 和 NVIDIA RTX 3090 GPU 的平台上训练;训练完成后,各测试方法在配备 Intel i7-6700 CPU 和 16 GB RAM 的计算机上比较。Huber 损失函数 F ( Θ ) F(\boldsymbol{\Theta}) F(Θ)(式 (15))中的切换阈值设置为 γ = 1 \gamma=1 γ=1。除非另有说明,本文考虑 K = 2 K=2 K=2 个源,固定快拍数 T = 200 T=200 T=200,并将仿真场景中的 SNR 设为 − 5 d B -5\,\mathrm{dB} −5dB。每个场景运行 I M C = 3000 I_{\mathrm{MC}}=3000 IMC=3000 次蒙特卡洛试验。
A. 深度神经网络拓扑
首先构造一个张量化深度神经网络(TDNN)作为基准,该网络包含 L = 3 L=3 L=3 个隐藏层,并采用预定义 Tucker 秩。具体而言,协方差张量 Y ∈ R 10 × 10 × 10 × 10 × 2 \boldsymbol{\mathcal{Y}}\in\mathbb{R}^{10\times10\times10\times10\times2} Y∈R10×10×10×10×2 被传播到第一个隐藏状态张量 H 1 ∈ R 7 × 7 × 7 × 7 × 2 \boldsymbol{\mathcal{H}}1\in\mathbb{R}^{7\times7\times7\times7\times2} H1∈R7×7×7×7×2。相应的逆 Tucker 因子矩阵为 V 0 , 1 † , V 0 , 2 † , V 0 , 3 † , V 0 , 4 † ∈ R 10 × 7 \mathbf{V}^{\dagger}{0,1},\mathbf{V}^{\dagger}{0,2},\mathbf{V}^{\dagger}{0,3},\mathbf{V}^{\dagger}{0,4}\in\mathbb{R}^{10\times7} V0,1†,V0,2†,V0,3†,V0,4†∈R10×7 和 V 0 , 5 † ∈ R 2 × 2 \mathbf{V}^{\dagger}{0,5}\in\mathbb{R}^{2\times2} V0,5†∈R2×2。随后两个隐藏状态张量分别为 H 2 ∈ R 5 × 5 × 5 × 5 × 1 \boldsymbol{\mathcal{H}}2\in\mathbb{R}^{5\times5\times5\times5\times1} H2∈R5×5×5×5×1 与 H 3 ∈ R 3 × 3 × 3 × 3 × 1 \boldsymbol{\mathcal{H}}3\in\mathbb{R}^{3\times3\times3\times3\times1} H3∈R3×3×3×3×1,对应的逆 Tucker 因子矩阵为 V 1 , 1 † , ... , V 1 , 4 † ∈ R 7 × 5 \mathbf{V}^{\dagger}{1,1},\ldots,\mathbf{V}^{\dagger}{1,4}\in\mathbb{R}^{7\times5} V1,1†,...,V1,4†∈R7×5、 V 1 , 5 † ∈ R 2 × 1 \mathbf{V}^{\dagger}{1,5}\in\mathbb{R}^{2\times1} V1,5†∈R2×1、 V 2 , 1 † , ... , V 2 , 4 † ∈ R 5 × 3 \mathbf{V}^{\dagger}{2,1},\ldots,\mathbf{V}^{\dagger}{2,4}\in\mathbb{R}^{5\times3} V2,1†,...,V2,4†∈R5×3 和 V 2 , 5 † ∈ R 1 × 1 \mathbf{V}^{\dagger}{2,5}\in\mathbb{R}^{1\times1} V2,5†∈R1×1。输出层权重张量为 W ∈ R 3 × 3 × 3 × 3 × 1 × 4 \boldsymbol{\mathcal{W}}\in\mathbb{R}^{3\times3\times3\times3\times1\times4} W∈R3×3×3×3×1×4。三个隐藏层的非线性激活函数分别选为 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅)、 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅) 和 Leaky ReLU ( ⋅ ) (\cdot) (⋅)。该 TDNN 拓扑记为 ( 10 , 10 , 10 , 10 , 2 ) − ( 7 , 7 , 7 , 7 , 2 ) − ( 5 , 5 , 5 , 5 , 1 ) − ( 3 , 3 , 3 , 3 , 1 ) − 4 (10,10,10,10,2)-(7,7,7,7,2)-(5,5,5,5,1)-(3,3,3,3,1)-4 (10,10,10,10,2)−(7,7,7,7,2)−(5,5,5,5,1)−(3,3,3,3,1)−4。
为保证公平比较,对应的基于矩阵的深度神经网络(MDNN)采用相同的三个隐藏层。输入向量 y \mathbf{y} y 的大小为 2 ⋅ 10 4 = 20000 2\cdot10^4=20000 2⋅104=20000,向量化隐藏状态大小分别为 2 ⋅ 7 4 = 4802 2\cdot7^4=4802 2⋅74=4802、 5 4 = 625 5^4=625 54=625 和 3 4 = 81 3^4=81 34=81。相应参数矩阵为 G 0 ∈ R 4802 × 20000 \mathbf{G}_0\in\mathbb{R}^{4802\times20000} G0∈R4802×20000、 G 1 ∈ R 625 × 4802 \mathbf{G}_1\in\mathbb{R}^{625\times4802} G1∈R625×4802、 G 2 ∈ R 81 × 625 \mathbf{G}_2\in\mathbb{R}^{81\times625} G2∈R81×625 和 W ∈ R 4 × 81 \mathbf{W}\in\mathbb{R}^{4\times81} W∈R4×81,激活函数与 TDNN 相同。该 MDNN 拓扑记为 20000 − 4802 − 625 − 81 − 4 20000-4802-625-81-4 20000−4802−625−81−4。
注:
MDNN 的含义。 MDNN 是 Matrix-based Deep Neural Network,即基于矩阵的深度神经网络。它是本文用于对照 TDNN 的普通 DNN 基线:先把协方差矩阵或协方差张量对应的信息向量化成很长的输入向量 y \mathbf{y} y,再通过大参数矩阵 G 0 , G 1 , G 2 \mathbf{G}_0,\mathbf{G}_1,\mathbf{G}_2 G0,G1,G2 和输出矩阵 W \mathbf{W} W 做全连接传播。
隐藏层数量。 本节中的基准 TDNN 和 MDNN 都假设 L = 3 L=3 L=3 个隐藏层,对应 H 1 , H 2 , H 3 \boldsymbol{\mathcal{H}}_1,\boldsymbol{\mathcal{H}}_2,\boldsymbol{\mathcal{H}}_3 H1,H2,H3;最后的角度输出层不计入 hidden layer。因此拓扑写成 input- H 1 \mathcal{H}_1 H1- H 2 \mathcal{H}_2 H2- H 3 \mathcal{H}_3 H3-output。后文第 V-H 小节还比较了 5 个隐藏层的网络,并说明后续仿真采用优化秩的 5 层 TDNN。
激活函数设置的依据。 这里论文只说明三个隐藏层的激活函数分别取 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅)、 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅) 和 Leaky ReLU ( ⋅ ) (\cdot) (⋅),并没有进一步解释为什么采用这种组合,也没有给出关于激活函数选择的消融实验。后文 5 层网络同样只是说明前两层用 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅)、后三层用 Leaky ReLU ( ⋅ ) (\cdot) (⋅)。因此,若说 Leaky ReLU 相比 tanh \tanh tanh 更不容易完全饱和、对梯度传播更友好,这是基于常见深度学习经验的推断,而不是本文明确给出的论证。
和 TDNN 的核心区别。 MDNN 的计算形式是"向量输入 + 大矩阵乘法 + 非线性激活",因此参数量随向量维度迅速增大;TDNN 则保留协方差的 5D 张量结构,用多个逆 Tucker 因子矩阵替代大矩阵,从而显著减少可训练参数。本文后面比较的 99 , 092 , 199 99,092,199 99,092,199 个参数,就是这个 3 层 MDNN 拓扑带来的矩阵参数量。
如第 III-D 小节所述,张量化神经层的 Tucker 秩序列可通过贝叶斯优化微调,得到优化后的 Tucker 秩序列 ( 11 , 15 , 11 , 15 , 2 ) (11,15,11,15,2) (11,15,11,15,2)、 ( 3 , 9 , 3 , 9 , 2 ) (3,9,3,9,2) (3,9,3,9,2) 和 ( 3 , 5 , 3 , 5 , 1 ) (3,5,3,5,1) (3,5,3,5,1)。因此,优化后的 TDNN 拓扑可记为 ( 10 , 10 , 10 , 10 , 2 ) − ( 11 , 15 , 11 , 15 , 2 ) − ( 3 , 9 , 3 , 9 , 2 ) − ( 3 , 5 , 3 , 5 , 1 ) − 4 (10,10,10,10,2)-(11,15,11,15,2)-(3,9,3,9,2)-(3,5,3,5,1)-4 (10,10,10,10,2)−(11,15,11,15,2)−(3,9,3,9,2)−(3,5,3,5,1)−4。
B. 训练过程和优化超参数
本文生成 P = 19200 P=19200 P=19200 个协方差张量 { Y p , p = 1 , 2 , ... , 19200 } \{\boldsymbol{\mathcal{Y}}p,\;p=1,2,\ldots,19200\} {Yp,p=1,2,...,19200},并将其划分为大小相同的批次 B B B 输入到张量化深度神经网络。对每个样本,源的方位角和俯仰角均在 0 ∘ , 90 ∘ 0\^\\circ,90\^\\circ 0∘,90∘ 范围内按正态分布随机生成;源信号 SNR 从集合 { − 15 d B , − 10 d B , − 5 d B , 0 d B } \{-15\,\mathrm{dB},-10\,\mathrm{dB},-5\,\mathrm{dB},0\,\mathrm{dB}\} {−15dB,−10dB,−5dB,0dB} 中随机选择;快拍数固定为 T = 200 T=200 T=200。噪声功率 σ n 2 \sigma_n^2 σn2 标准化为 1,信号功率相应计算为 σ k 2 = 10 S N R / 10 \sigma_k^2=10^{\mathrm{SNR}/10} σk2=10SNR/10。这里使用不同 SNR 的仿真信号生成训练样本,以覆盖低信号功率场景。在实际应用中,既可以继续使用仿真样本,也可以使用真实数据集;若使用真实数据集,需要在噪声环境中收集接收信号以尽可能覆盖多种场景,但不需要知道信号和噪声功率。参数集合 { V 0 , h † , V 1 , h † , V 2 , h † , W , h = 1 , 2 , ... , 5 } \{\mathbf{V}^{\dagger}{0,h},\mathbf{V}^{\dagger}{1,h},\mathbf{V}^{\dagger}{2,h},\boldsymbol{\mathcal{W}},h=1,2,\ldots,5\} {V0,h†,V1,h†,V2,h†,W,h=1,2,...,5} 按文献 45 的方法初始化。
与 Tucker 秩调节过程类似,本文也采用贝叶斯优化调节其他超参数。学习率 η \eta η 与批大小 B B B 的搜索范围分别预设为 10 − 5 , 10 − 1 10\^{-5},10\^{-1} 10−5,10−1 和 { 16 , 32 , 64 , 128 } \{16,32,64,128\} {16,32,64,128}。随后根据第 III-D 小节,最小化关于 ( η , B ) (\eta,B) (η,B) 的度量函数 Ξ ( η , B ) \Xi(\eta,B) Ξ(η,B),并与 Tucker 秩序列一起优化。基于矩阵的深度神经网络也采用相同方法训练。最终,张量化深度神经网络的超参数优化为 η = 8.317 ⋅ 10 − 3 \eta=8.317\cdot10^{-3} η=8.317⋅10−3、 B = 32 B=32 B=32;基于矩阵的深度神经网络优化为 η = 0.273 ⋅ 10 − 3 \eta=0.273\cdot10^{-3} η=0.273⋅10−3、 B = 32 B=32 B=32。
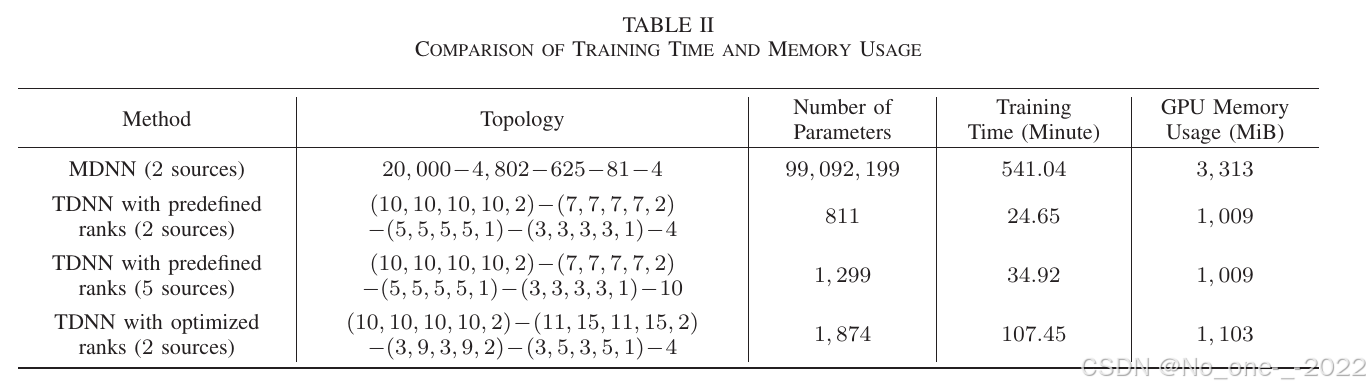
TABLE II. 训练时间和内存使用比较。
C. 训练效率比较
为了验证所提出网络的训练效率,本文在表 II 中将其训练时间和 GPU 内存使用量与基于矩阵的神经网络进行比较。根据式 (28) 和式 (27),MDNN 需要训练的参数总数为 99,092,199,而 TDNN 仅为 811;因此,训练参数数量可减少超过 122,000 倍,从而加快训练过程并降低内存使用。具体而言,MDNN 的训练时间为 541.04 分钟,而由于张量化神经层设计,所提出网络仅需 24.65 分钟。TDNN 的 GPU 内存使用量为 1,009 MiB,低于 MDNN 的 3,313 MiB。此外,当有 5 个源时,对应 TDNN 仍能显著降低训练成本,训练时间为 34.92 分钟,GPU 内存使用量为 1,009 MiB。
对于优化 Tucker 秩的 TDNN,其训练时间和内存使用量相比预定义 Tucker 秩的 TDNN 有所增加;尽管如此,二者仍远低于 MDNN。值得注意的是,拓扑为 20000 − 54450 − 1458 − 225 − 4 20000-54450-1458-225-4 20000−54450−1458−225−4 的 MDNN 会在配备 Intel i7-6700 CPU 和 16 GB RAM 的计算机上导致内存耗尽,因此无法使用。所提出的张量化神经网络设计使实际 DOA 估计中采用资源效率更高的网络,或可能采用更大规模的网络成为可能。
D. DOA估计精度比较
在 DOA 估计精度方面,我们将所提出的张量化神经网络与若干基于模型的方法(即 MUSIC 7、ESPRIT 8、CPD 方法 27)以及传统的基于矩阵的神经网络方法 17 进行比较。图 3 给出了评估方法在不同 SNR(图 3(a))与不同快拍数(图 3(b))下的均方根误差(RMSE):
R M S E = 1 2 K I M C ∑ i M C = 1 I M C ∥ ϑ ^ i M C − ϑ i M C ∥ 2 2 . (29) \mathrm{RMSE} =\sqrt{ \frac{1}{2KI_{\mathrm{MC}}} \sum_{i_{\mathrm{MC}}=1}^{I_{\mathrm{MC}}} \left\| \widehat{\boldsymbol{\vartheta}}{i{\mathrm{MC}}} -\boldsymbol{\vartheta}{i{\mathrm{MC}}} \right\|_{2}^{2} }. \tag{29} RMSE=2KIMC1iMC=1∑IMC ϑ iMC−ϑiMC 22 .(29)
其中 ϑ ^ i M C \widehat{\boldsymbol{\vartheta}}{i{\mathrm{MC}}} ϑ iMC 和 ϑ i M C \boldsymbol{\vartheta}{i{\mathrm{MC}}} ϑiMC 分别是第 i M C i_{\mathrm{MC}} iMC 次试验的估计 DOA 和真实 DOA。每次试验的源方位角和仰角均按照正态分布在 0 ∘ , 90 ∘ 0\^\\circ,90\^\\circ 0∘,90∘ 范围内随机生成。MUSIC 和 ESPRIT 对协方差矩阵 R = E { x ( t ) x H ( t ) } \mathbf{R}=\mathbb{E}\{\mathbf{x}(t)\mathbf{x}^{H}(t)\} R=E{x(t)xH(t)} 执行子空间分解。它们不需要任何训练过程,但依赖于从信号协方差中提取的信号子空间的可靠性。同样,CPD 方法不训练协方差张量 R = E { X ( t ) ∘ X ∗ ( t ) } \boldsymbol{\mathcal{R}}=\mathbb{E}\{\mathbf{X}(t)\circ\mathbf{X}^{*}(t)\} R=E{X(t)∘X∗(t)},而是直接分解其样本版本 R ^ \widehat{\boldsymbol{\mathcal{R}}} R ,以检索角度因子 μ k \mu_k μk 和 ν k \nu_k νk。注意,CPD 方法直接将 CPD 应用于 R ^ \widehat{\boldsymbol{\mathcal{R}}} R ,其典范多元秩称为源数。
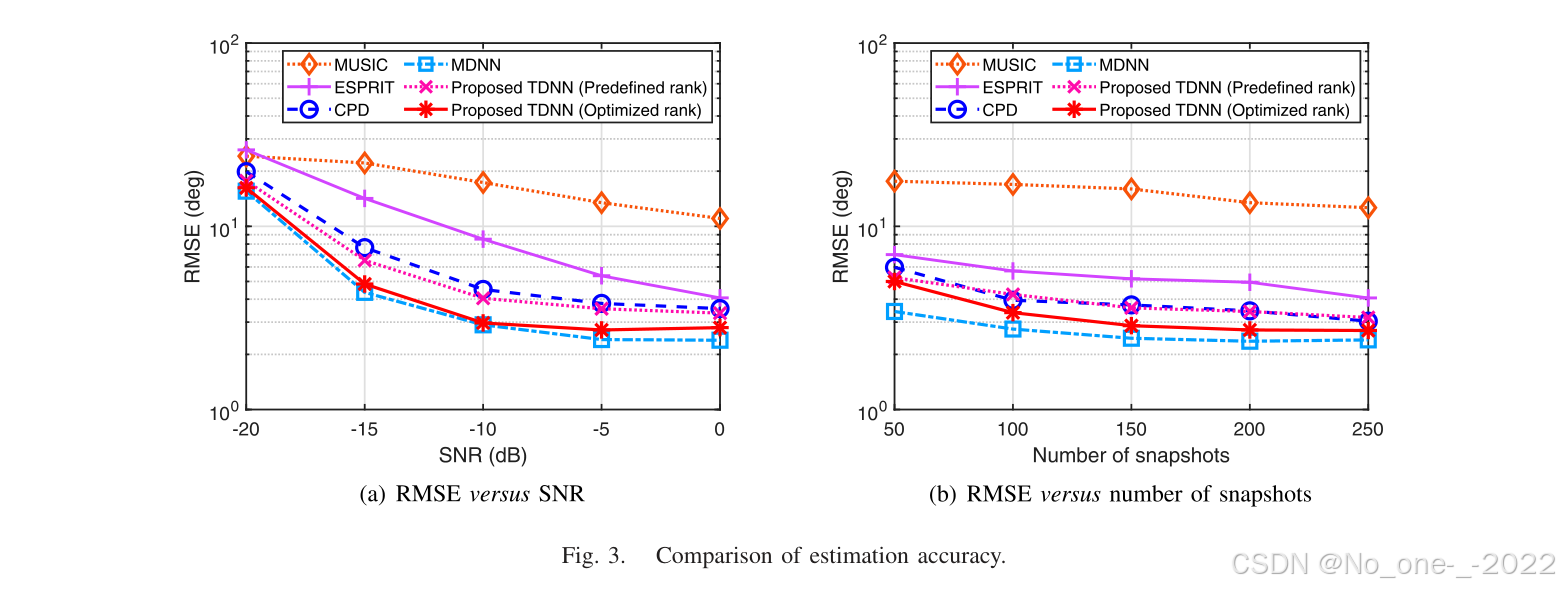
图 3. 估计精度比较。
然而,神经网络不需要针对特定受污染信号统计量建立固定模型;经过充分训练后,它通常能在噪声环境中表现出灵活性。因此,与本文评估的基于模型方法相比,神经网络对偏离理想模型的信号统计具有更好的适应性,前述文献 19-21 也给出了类似结论。
很明显,在整个仿真的 SNR 和快拍数范围内,所提出网络相较 MUSIC 和 ESPRIT 均提高了估计精度。这种改进来自其从足量训练样本中学习高阶张量信号特征的能力。采用预定义 Tucker 秩的张量化神经网络与 CPD 方法精度相当,而采用优化 Tucker 秩的张量化神经网络表现出性能优势。同时,张量化神经网络的估计精度接近基于矩阵的神经网络,但仍存在一定退化。在特定场景下(例如 SNR 位于 − 20 d B -20\,\mathrm{dB} −20dB 到 − 10 d B -10\,\mathrm{dB} −10dB 范围内),优化秩 TDNN 与 MDNN 的 RMSE 曲线几乎重合。然而,张量化神经网络的参数数量仍显著小于基于矩阵的神经网络,即 1 , 874 ≪ 99 , 092 , 199 1,874\ll99,092,199 1,874≪99,092,199。总体而言,所提出网络的性能接近但不能超过基于矩阵的神经网络。这说明该网络优先追求训练效率,代价是不可避免的精度下降,而 Tucker 秩序列优化可尽量减小这种下降。
E. 角分辨率比较
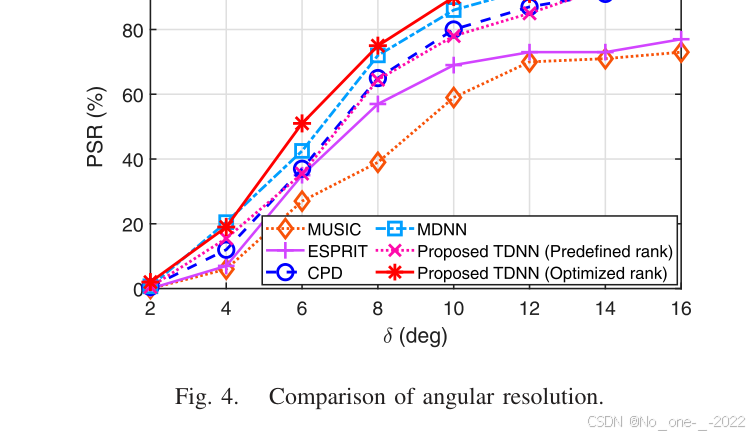
图 4. 角分辨率比较。
在图 4 中,本文比较了所有测试方法的角分辨率,其中两个源来自相近方向 ( θ 1 , ϕ 1 ) (\theta_1,\phi_1) (θ1,ϕ1) 和 ( θ 2 , ϕ 2 ) (\theta_2,\phi_2) (θ2,ϕ2)。这里, θ 1 \theta_1 θ1 和 ϕ 1 \phi_1 ϕ1 在每次试验中都按正态分布从 0 ∘ , 90 ∘ 0\^\\circ,90\^\\circ 0∘,90∘ 范围内随机生成;随后计算 ( θ 2 , ϕ 2 ) (\theta_2,\phi_2) (θ2,ϕ2),使其与 ( θ 1 , ϕ 1 ) (\theta_1,\phi_1) (θ1,ϕ1) 保持角间距 δ \delta δ,即
∣ θ 2 − θ 1 ∣ 2 + ∣ ϕ 2 − ϕ 1 ∣ 2 = δ . \sqrt{|\theta_2-\theta_1|^2+|\phi_2-\phi_1|^2}=\delta. ∣θ2−θ1∣2+∣ϕ2−ϕ1∣2 =δ.
若每次试验中对每个源都满足
∣ θ ^ k − θ k ∣ 2 + ∣ ϕ ^ k − ϕ k ∣ 2 < δ , \sqrt{|\widehat{\theta}_k-\theta_k|^2+|\widehat{\phi}_k-\phi_k|^2}<\delta, ∣θ k−θk∣2+∣ϕ k−ϕk∣2 <δ,
则认为测试方法成功分辨了这些源的 DOA。成功分辨概率(PSR)定义为成功试验所占百分比。与第 V-D 小节中的观察类似,所提出的深度张量二维 DOA 估计算法相较基于模型的方法具有更好的角分辨率。更重要的是,与基于矩阵的神经网络相比,采用优化 Tucker 秩的张量化神经网络显示出更强的分辨能力。这表明,即使资源消耗较少,所提出的网络也可以提供令人满意的角分辨率性能。
F. 多个源的估计性能
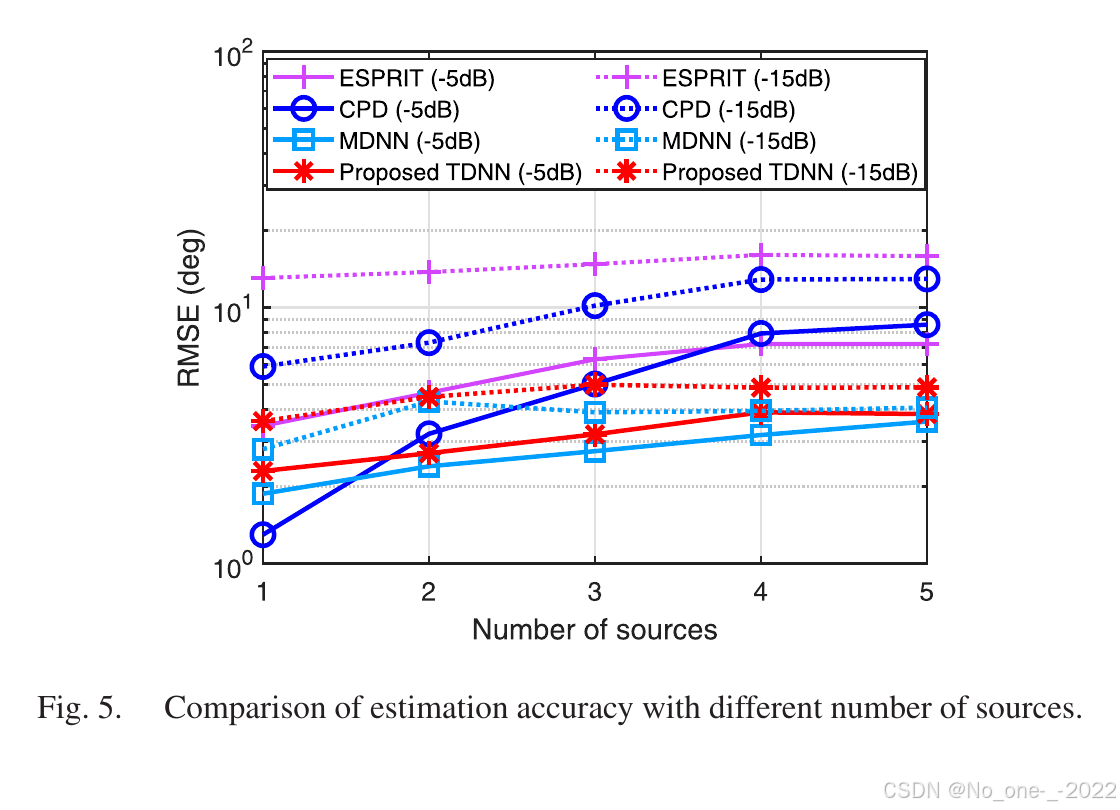
图 5. 不同源数量下的估计精度比较。
我们通过改变输出的大小进一步评估不同源数量场景中的 DOA 估计性能。如图5所示,随着源数量的增加,ESPRIT和CPD方法的估计精度明显下降。相比之下,所提出的张量化神经网络和传统神经网络都保持了更稳定的性能。
G. 计算时间比较
为了验证所提出的张量化神经网络的计算效率,我们在图 6(a)和 6(b)中根据源数量和快照数量的增加来比较所有测试方法的计算时间。显然,所提出的网络在计算上比基于模型的方法更快。这是因为张量神经网络用高效的前馈计算取代了复杂的子空间提取、谱搜索和优化。 CPD 方法的计算复杂度随着源数量的增加而急剧增加,而所提出网络始终表现出较低复杂度。同时,与基于矩阵的神经网络相比,所提出网络还具有更快计算速度;例如在 K = 1 K=1 K=1、 S N R = − 5 d B \mathrm{SNR}=-5\,\mathrm{dB} SNR=−5dB、 T = 100 T=100 T=100 时,MDNN 用时 0.0081 s 0.0081\,\mathrm{s} 0.0081s,TDNN 用时 0.0073 s 0.0073\,\mathrm{s} 0.0073s。这得益于第 IV-B 小节所述多线性张量-矩阵乘积在信号特征传播中的高效计算。
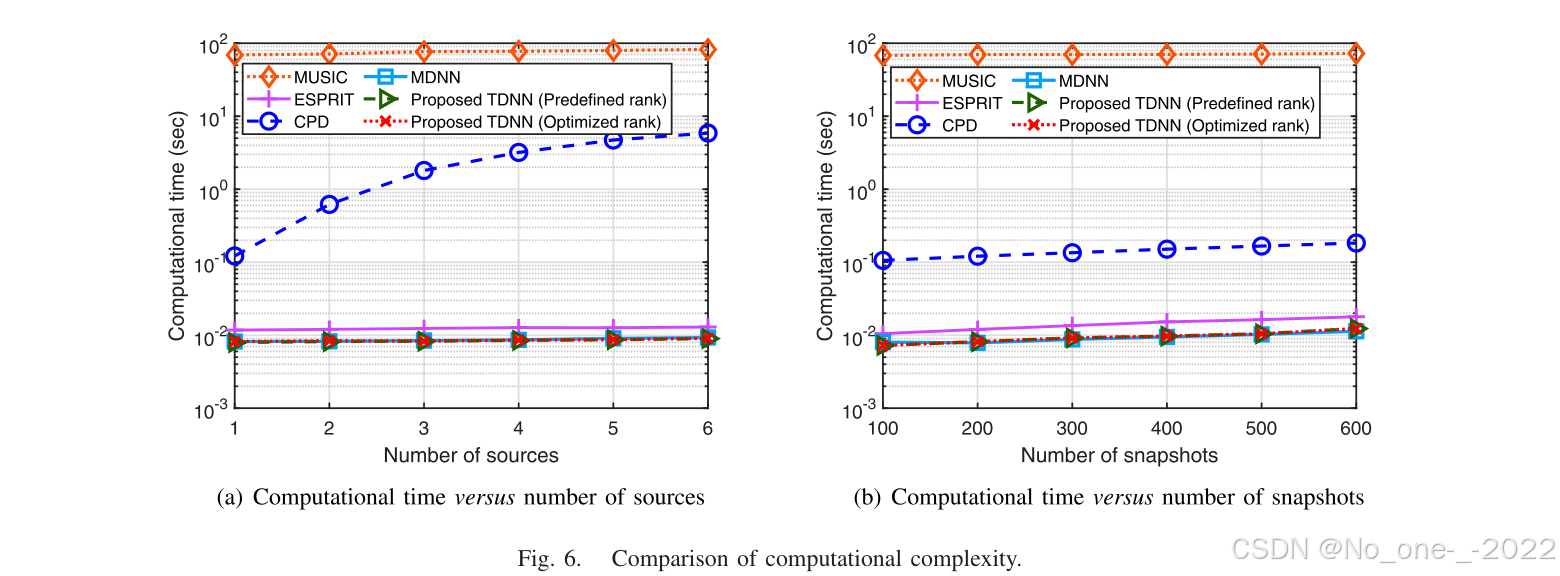
图 6. 计算复杂度比较。
H. 不同层数网络的比较
本小节进一步评估所提出张量化神经网络在增加层数时的性能。具体而言,本文部署另一个 5 层基于矩阵的深度神经网络,其拓扑记为 20000 − 8192 − 2592 − 625 − 256 − 81 − 4 20000-8192-2592-625-256-81-4 20000−8192−2592−625−256−81−4。相应地,可部署一个具有预定义秩的 5 层张量化深度神经网络,拓扑为 ( 10 , 10 , 10 , 10 , 2 ) − ( 8 , 8 , 8 , 8 , 2 ) − ( 6 , 6 , 6 , 6 , 2 ) − ( 5 , 5 , 5 , 5 , 1 ) − ( 4 , 4 , 4 , 4 , 1 ) − ( 3 , 3 , 3 , 3 , 1 ) − 4 (10,10,10,10,2)-(8,8,8,8,2)-(6,6,6,6,2)-(5,5,5,5,1)-(4,4,4,4,1)-(3,3,3,3,1)-4 (10,10,10,10,2)−(8,8,8,8,2)−(6,6,6,6,2)−(5,5,5,5,1)−(4,4,4,4,1)−(3,3,3,3,1)−4。此外,5 层张量化深度神经网络的 Tucker 秩序列可进一步优化,得到最优拓扑 ( 10 , 10 , 10 , 10 , 2 ) − ( 14 , 10 , 14 , 10 , 2 ) − ( 6 , 11 , 6 , 11 , 2 ) − ( 8 , 2 , 8 , 2 , 1 ) − ( 8 , 8 , 8 , 1 ) − ( 5 , 3 , 5 , 3 , 1 ) − 4 (10,10,10,10,2)-(14,10,14,10,2)-(6,11,6,11,2)-(8,2,8,2,1)-(8,8,8,1)-(5,3,5,3,1)-4 (10,10,10,10,2)−(14,10,14,10,2)−(6,11,6,11,2)−(8,2,8,2,1)−(8,8,8,1)−(5,3,5,3,1)−4。
这三个网络的学习率分别调为 0.438 ⋅ 10 − 3 0.438\cdot10^{-3} 0.438⋅10−3、 3.095 ⋅ 10 − 3 3.095\cdot10^{-3} 3.095⋅10−3 和 7.705 ⋅ 10 − 3 7.705\cdot10^{-3} 7.705⋅10−3,且 B = 32 B=32 B=32。对每个网络,前两层非线性激活函数设为 tanh ( ⋅ ) \tanh(\cdot) tanh(⋅),后三层设为 Leaky ReLU ( ⋅ ) (\cdot) (⋅)。5 层 MDNN 的参数数量为 186,874,724;具有预定义秩和优化秩的 5 层 TDNN 参数数量分别降至 1,090 和 2,208。图 7 给出了这些网络在 K = 2 K=2 K=2 个源场景中的 DOA 估计结果。结果表明,随着神经层数增加,部署网络的 DOA 估计性能得到增强;更重要的是,所提出 TDNN 仍能表现出接近资源开销很大的 MDNN 的性能,在部分场景中二者 RMSE 曲线几乎重合。后续仿真采用 5 层 MDNN 和优化秩的 5 层 TDNN。
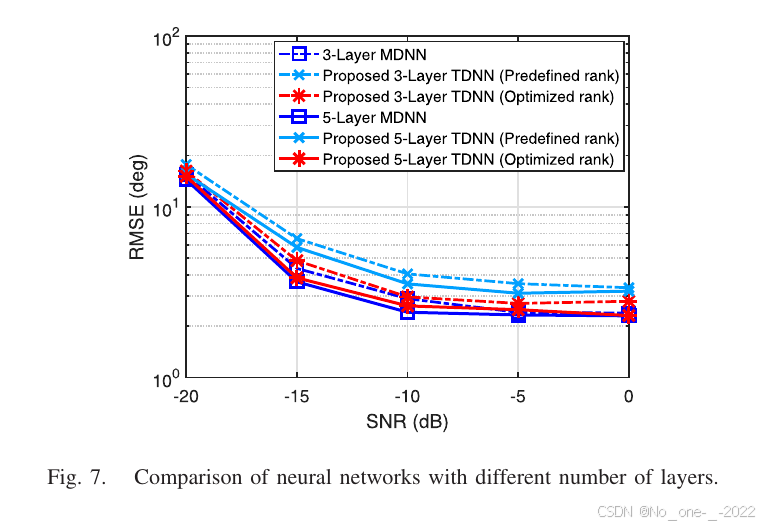
图 7. 不同层数神经网络的比较。
I. 不同源数量的适配
对于设计的回归网络,输出大小通常固定。为适应不同源数,可将输出数量扩展为 2 K max 2K_{\max} 2Kmax,并始终提取前 2 K 2K 2K 个输出作为估计 DOA。然后,通过重新构造训练数据集,使其包含不同源数量的样本,并用该数据集训练部署的神经网络,网络即可适配不同源数。
在该仿真中,设置 K max = 6 K_{\max}=6 Kmax=6,因此输出大小为 12。随后生成训练样本,其对应源数从 { 1 , 2 , 3 } \{1,2,3\} {1,2,3} 中随机选择,其余设置与前述仿真保持一致。对于 K = 1 K=1 K=1 到 K = 3 K=3 K=3 的不同源数量,训练后神经网络的性能如图 8 所示,其中给出了 10 次试验的结果,每次试验包含 32 个测试样本。SNR 和快拍数分别设为 0 d B 0\,\mathrm{dB} 0dB 和 T = 200 T=200 T=200。可以看出,张量化神经网络能够估计不同数量的源,且性能接近基于矩阵的神经网络。通过进一步扩展训练数据集并进行充分离线训练,神经网络可对更多源表现出更高适应性。
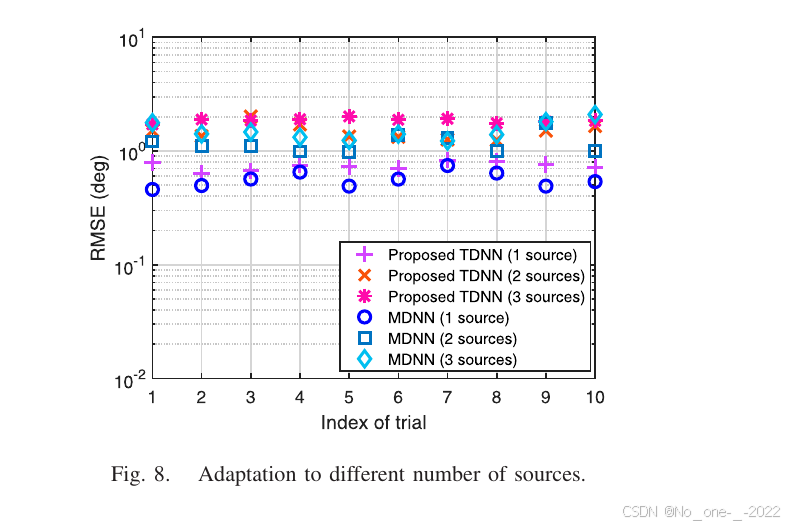
图 8. 对不同源数量的适应性。
J. 对非理想条件的适应
为验证张量化神经网络的鲁棒性,本文进行三个案例研究,分别模拟非高斯噪声/有色信号、阵列误差、相干信号/紧密间隔源场景。神经网络按照第 V-B 小节所述,使用不含这些非理想条件的样本训练,并在非理想条件下评估其泛化能力。
1)非高斯噪声和有色信号:在声学和通信等应用中,加性噪声可能不服从高斯分布,从而形成非高斯脉冲噪声(IN)。在该场景中,噪声向量 n ( t ) \mathbf{n}(t) n(t) 或噪声矩阵 N ( t ) \mathbf{N}(t) N(t) 被设为服从 α \alpha α-稳定分布 46。该分布的特征指数、对称性指数、位置参数和离散参数分别设为 1、0.5、0 和 1。此外,当信号频谱向某一侧衰减时,信号波形表现为有色而非白色。本文生成粉红色信号(PS)并评估各比较方法性能。图 9 表明,在这两种情况下,所提出 TDNN 和 MDNN 均表现出相近性能,并优于基于模型的 ESPRIT 和 CPD 方法。
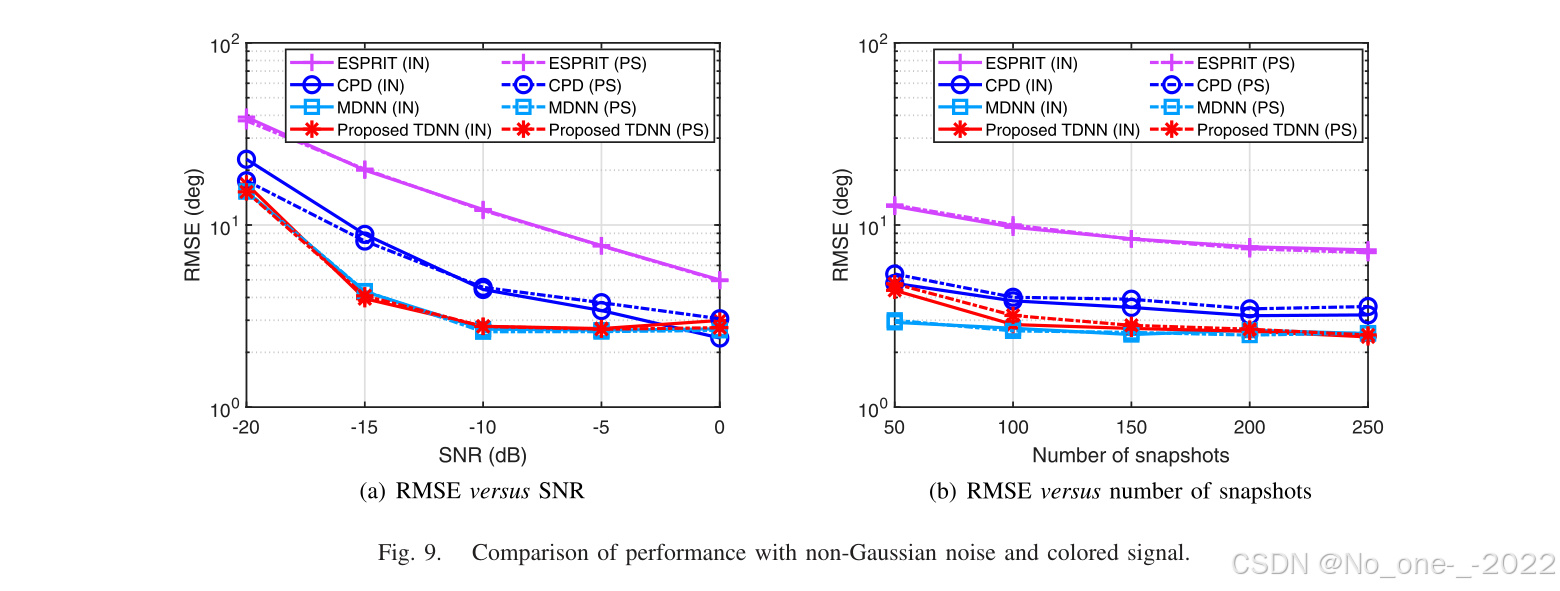
图 9. 非高斯噪声和有色信号下的性能比较。
2)阵列误差:进一步地,本文评估传感器位置偏差(SPD)和传感器故障(SF)等阵列误差下的 DOA 估计性能。在 SPD 场景中,每个传感器在 x x x 轴位置 x S x_{\mathcal{S}} xS 上都会在 ι ∈ 0 , 0.4 d \iota\in0,0.4d ι∈0,0.4d 范围内随机偏移。在 SF 场景中,每次试验中部署 URA S \mathcal{S} S 的 5 个随机选定传感器会发生损坏。两种场景的结果如图 10 所示。由于 ESPRIT 和 CPD 方法依赖精确信号协方差模型,阵列误差会造成显著相位和增益偏差,从而导致性能明显恶化。相比之下,训练后的神经网络对阵列误差引起的非理想信号统计表现出更强适应性和灵活性,这是神经网络用于二维 DOA 估计的显著优势。
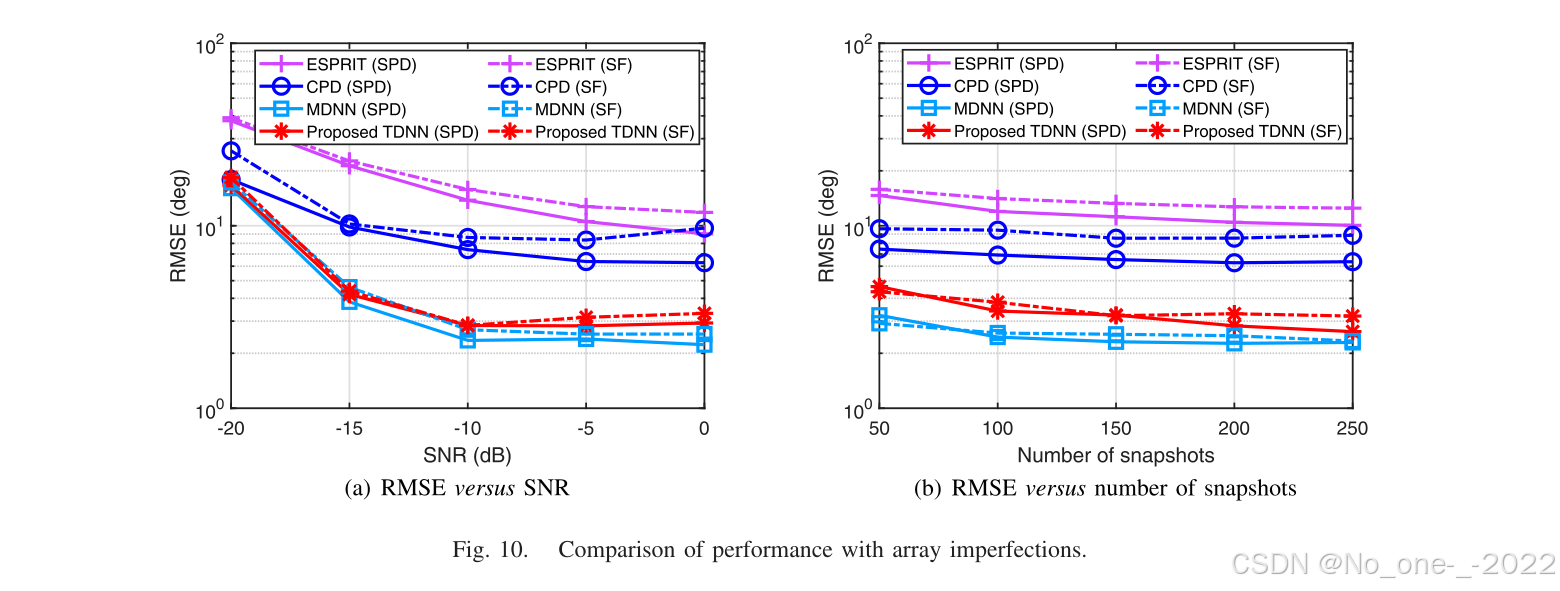
图 10. 阵列误差下的性能比较。
3)相干信号和紧密间隔源:本文模拟相干信号(CH)和紧密间隔源(CS)的存在,以进一步评估所提出网络的适应性。具体而言,在多径环境中,来自同一源的两个信号 s 1 s_1 s1 和 s 2 s_2 s2 表现出统计相干性,因此 s 2 s_2 s2 等于 s 1 s_1 s1 乘以随机生成的相干系数。此外,本文模拟两个源间隔很近的场景,将两个源之间的方位角和俯仰角间距均设为 2 ∘ 2^\circ 2∘。两种场景的结果如图 11 所示。与前述结论类似,所提出 TDNN 能够泛化到非理想信号传播条件,并相较评估的基于模型方法呈现明显性能改进。
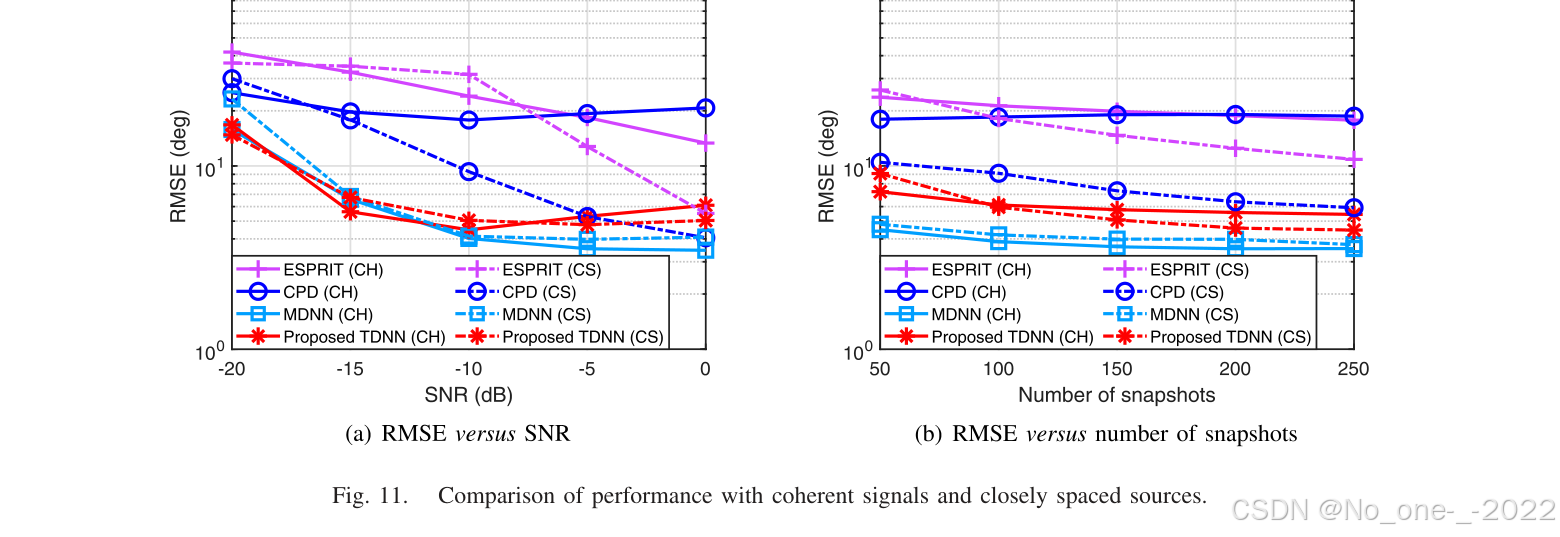
图 11. 相干信号和紧密间隔源下的性能比较。
VI. 结论
本文通过设计资源高效的张量化深度神经网络,提出一种深度张量二维 DOA 估计算法。为提高训练效率和计算效率,本文将从协方差张量到隐藏状态张量的变换表述为逆 Tucker 分解,从而压缩可训练参数。对于 10 × 10 10\times10 10×10 URA 和 2 个源,张量化深度神经网络的参数数量相比基于矩阵的深度神经网络减少超过 122,000 倍,使训练时间减少 22 倍,GPU 内存使用量减少 3 倍。尽管所提出网络显著降低了系统成本,但相较评估的基于模型方法,它仍提供了更好的 DOA 估计精度和角分辨率。
与基于矩阵的深度神经网络相比,所提出网络性能略差,因为它以不可避免的精度下降为代价优先保证网络效率。尽管如此,所提出的基于张量模型的神经网络仍能适应不同 SNR、快拍数和源数量的场景。此外,张量化深度神经网络也能处理非理想条件,包括非高斯噪声、有色信号、阵列误差、相干信号和紧密间隔源。不过,它的适应性通常受训练样本特征影响。在某些极端情况下,例如快拍数很少、源数量过多等 47, 48,如果不扩展数据集(例如加入为相应场景采集或仿真的训练样本),或不引入额外深度学习机制(例如在线学习或强化学习),张量化神经网络可能失去最佳性能。这种常见现象称为分布偏移。面向分布变化鲁棒性的网络校准是一个独立研究主题,超出了本文范围。
附录 A. 反向传播步骤的导数
基于式 (22) 中的局部梯度 ∇ H L F ( Θ ) \nabla_{\boldsymbol{\mathcal{H}}{L}}F(\boldsymbol{\Theta}) ∇HLF(Θ),用于更新式 (23) 中逆 Tucker 因子矩阵 { V L − 1 , h † , h = 1 , 2 , ⋯ , 5 } \{\mathbf{V}^{\dagger}{L-1,h},h=1,2,\cdots,5\} {VL−1,h†,h=1,2,⋯,5} 的导数可写为
∂ F ( Θ ) ∂ V L − 1 , h † = ∂ F ( Θ ) ∂ H L ∂ H L ∂ V L − 1 , h † = ∇ H L F ( Θ ) × 1 , 2 , 3 , 4 , 5 f L ′ ( H L − 1 × 1 V L − 1 , 1 † × 2 V L − 1 , 2 † ⋯ × 5 V L − 1 , 5 † ) ⋅ H L − 1 × 1 V L − 1 , 1 † ⋯ × h − 1 V L − 1 , h − 1 † × h + 1 V L − 1 , h + 1 † ⋯ × 5 V L − 1 , 5 † . (30) \begin{aligned} \frac{\partial F(\boldsymbol{\Theta})}{\partial \mathbf{V}^{\dagger}{L-1,h}} &= \frac{\partial F(\boldsymbol{\Theta})}{\partial \boldsymbol{\mathcal{H}}{L}} \frac{\partial \boldsymbol{\mathcal{H}}{L}}{\partial \mathbf{V}^{\dagger}{L-1,h}} \\ &= \left \\nabla_{\\boldsymbol{\\mathcal{H}}_{L}}F(\\boldsymbol{\\Theta}) \\times_{1,2,3,4,5} f'_L\\!\\left( \\boldsymbol{\\mathcal{H}}_{L-1} \\times_1\\mathbf{V}\^{\\dagger}_{L-1,1} \\times_2\\mathbf{V}\^{\\dagger}_{L-1,2} \\cdots \\times_5\\mathbf{V}\^{\\dagger}_{L-1,5} \\right) \\right \\ &\quad\cdot \boldsymbol{\mathcal{H}}{L-1} \times_1\mathbf{V}^{\dagger}{L-1,1} \cdots \times_{h-1}\mathbf{V}^{\dagger}{L-1,h-1} \times{h+1}\mathbf{V}^{\dagger}{L-1,h+1} \cdots \times_5\mathbf{V}^{\dagger}{L-1,5}. \end{aligned} \tag{30} ∂VL−1,h†∂F(Θ)=∂HL∂F(Θ)∂VL−1,h†∂HL=∇HLF(Θ)×1,2,3,4,5fL′(HL−1×1VL−1,1†×2VL−1,2†⋯×5VL−1,5†)⋅HL−1×1VL−1,1†⋯×h−1VL−1,h−1†×h+1VL−1,h+1†⋯×5VL−1,5†.(30)
局部梯度张量 ∇ H l − 1 F ( Θ ) \nabla_{\boldsymbol{\mathcal{H}}{l-1}}F(\boldsymbol{\Theta}) ∇Hl−1F(Θ), l = L , L − 1 , ⋯ , 2 l=L,L-1,\cdots,2 l=L,L−1,⋯,2,及其相应导数 ∂ F ( Θ ) / ∂ V l − 2 , h † \partial F(\boldsymbol{\Theta})/\partial\mathbf{V}^{\dagger}{l-2,h} ∂F(Θ)/∂Vl−2,h† 分别由
∂ F ( Θ ) ∂ H l − 1 = ∂ F ( Θ ) ∂ H l ∂ H l ∂ H l − 1 = f l ′ ( H l − 1 × 1 V l − 1 , 1 † × 2 V l − 1 , 2 † ⋯ × 5 V l − 1 , 5 † ) ∘ ∇ H l F ( Θ ) × 1 V l − 1 , 1 † × 2 V l − 1 , 2 † ⋯ × 5 V l − 1 , 5 † , (31) \begin{aligned} \frac{\partial F(\boldsymbol{\Theta})}{\partial \boldsymbol{\mathcal{H}}{l-1}} &= \frac{\partial F(\boldsymbol{\Theta})}{\partial \boldsymbol{\mathcal{H}}{l}} \frac{\partial \boldsymbol{\mathcal{H}}{l}}{\partial \boldsymbol{\mathcal{H}}{l-1}} \\ &= f'l\!\left( \boldsymbol{\mathcal{H}}{l-1} \times_1\mathbf{V}^{\dagger}{l-1,1} \times_2\mathbf{V}^{\dagger}{l-1,2} \cdots \times_5\mathbf{V}^{\dagger}_{l-1,5} \right) \circ \left \\nabla_{\\boldsymbol{\\mathcal{H}}_{l}}F(\\boldsymbol{\\Theta}) \\times_1\\mathbf{V}\^{\\dagger}_{l-1,1} \\times_2\\mathbf{V}\^{\\dagger}_{l-1,2} \\cdots \\times_5\\mathbf{V}\^{\\dagger}_{l-1,5} \\right, \end{aligned} \tag{31} ∂Hl−1∂F(Θ)=∂Hl∂F(Θ)∂Hl−1∂Hl=fl′(Hl−1×1Vl−1,1†×2Vl−1,2†⋯×5Vl−1,5†)∘∇HlF(Θ)×1Vl−1,1†×2Vl−1,2†⋯×5Vl−1,5†,(31)
以及
∂ F ( Θ ) ∂ V l − 2 , h † = ( H l − 2 × 1 V l − 2 , 1 † ⋯ × h − 1 V l − 2 , h − 1 † × h + 1 V l − 2 , h + 1 † ⋯ × 5 V l − 2 , 5 † ) × 1 , ⋯ , h − 1 , h + 1 , ⋯ , 5 f l − 1 ′ ( H l − 2 × 1 V l − 2 , 1 † × 2 V l − 2 , 2 † ⋯ × 5 V l − 2 , 5 † ) ∘ ∇ H l − 1 F ( Θ ) . (32) \begin{aligned} \frac{\partial F(\boldsymbol{\Theta})}{\partial \mathbf{V}^{\dagger}{l-2,h}} &= \left( \boldsymbol{\mathcal{H}}{l-2} \times_1\mathbf{V}^{\dagger}{l-2,1} \cdots \times{h-1}\mathbf{V}^{\dagger}{l-2,h-1} \times{h+1}\mathbf{V}^{\dagger}{l-2,h+1} \cdots \times_5\mathbf{V}^{\dagger}{l-2,5} \right) \\ &\quad\times_{1,\cdots,h-1,h+1,\cdots,5} \left f'_{l-1}\\!\\left( \\boldsymbol{\\mathcal{H}}_{l-2} \\times_1\\mathbf{V}\^{\\dagger}_{l-2,1} \\times_2\\mathbf{V}\^{\\dagger}_{l-2,2} \\cdots \\times_5\\mathbf{V}\^{\\dagger}_{l-2,5} \\right) \\circ \\nabla_{\\boldsymbol{\\mathcal{H}}_{l-1}}F(\\boldsymbol{\\Theta}) \\right. \end{aligned} \tag{32} ∂Vl−2,h†∂F(Θ)=(Hl−2×1Vl−2,1†⋯×h−1Vl−2,h−1†×h+1Vl−2,h+1†⋯×5Vl−2,5†)×1,⋯,h−1,h+1,⋯,5fl−1′(Hl−2×1Vl−2,1†×2Vl−2,2†⋯×5Vl−2,5†)∘∇Hl−1F(Θ).(32)
附录 B. Tucker 秩选择过程的细节
为了计算度量函数 Ξ ( χ T u c k e r ) \Xi(\chi_{\mathrm{Tucker}}) Ξ(χTucker),将 P P P 个训练样本均等划分为若干折(例如五折)。前四折用作初始化张量化深度神经网络的训练集,训练 60 个 epoch;最后一折作为验证集,用于评估训练后网络的 DOA 估计性能。输出角度向量与真实值之间的均方误差为
M S E = ∥ ϑ − ϑ ^ ∥ 2 2 2 K . (33) \mathrm{MSE} =\frac{\left\|\boldsymbol{\vartheta}-\widehat{\boldsymbol{\vartheta}}\right\|_{2}^{2}}{2K}. \tag{33} MSE=2K ϑ−ϑ 22.(33)
将每一折都作为一次验证集后,得到对应的 M S E w , w = 1 , 2 , ⋯ , 5 \mathrm{MSE}_{w},w=1,2,\cdots,5 MSEw,w=1,2,⋯,5,并取平均值
Ξ = 1 5 ∑ w = 1 5 M S E w \Xi =\frac{1}{5}\sum_{w=1}^{5}\mathrm{MSE}_{w} Ξ=51w=1∑5MSEw
作为网络整体性能指标。该指标被视为关于未知 Tucker 秩序列 χ T u c k e r \chi_{\mathrm{Tucker}} χTucker 的目标函数,并通过最小化它来获得 χ T u c k e r \chi_{\mathrm{Tucker}} χTucker 的最优值,即求解式 (26)。
为了解决上述问题,需要建立关于 χ T u c k e r \chi_{\mathrm{Tucker}} χTucker 分布的先验知识。由于典型高斯过程具有灵活性和易处理性, Ξ ( χ T u c k e r ) \Xi(\chi_{\mathrm{Tucker}}) Ξ(χTucker) 的先验可表示为
Ξ ( χ T u c k e r ) ∼ G P ( μ ( χ T u c k e r ) , Σ ( χ T u c k e r , χ T u c k e r H ) ) , (34) \Xi(\chi_{\mathrm{Tucker}}) \sim \mathcal{GP}\!\left( \mu(\chi_{\mathrm{Tucker}}), \Sigma(\chi_{\mathrm{Tucker}},\chi_{\mathrm{Tucker}}^{H}) \right), \tag{34} Ξ(χTucker)∼GP(μ(χTucker),Σ(χTucker,χTuckerH)),(34)
其中 μ ( χ T u c k e r ) \mu(\chi_{\mathrm{Tucker}}) μ(χTucker) 和 Σ ( χ T u c k e r , χ T u c k e r H ) \Sigma(\chi_{\mathrm{Tucker}},\chi_{\mathrm{Tucker}}^{H}) Σ(χTucker,χTuckerH) 分别表示均值函数和协方差函数。基于式 (34) 中定义的先验分布,新采样 Tucker 秩序列 χ ˉ T u c k e r \bar{\chi}_{\mathrm{Tucker}} χˉTucker 上的预测分布(即后验)为
P ( Ξ ( χ ˉ T u c k e r ) ∣ χ T u c k e r , χ ˉ T u c k e r , Ξ ( χ T u c k e r ) ) = N ( μ ˉ , Σ ˉ ) , (35) P\!\left( \Xi(\bar{\chi}{\mathrm{Tucker}}) \mid \chi{\mathrm{Tucker}}, \bar{\chi}{\mathrm{Tucker}}, \Xi(\chi{\mathrm{Tucker}}) \right) =\mathcal{N}(\bar{\mu},\bar{\Sigma}), \tag{35} P(Ξ(χˉTucker)∣χTucker,χˉTucker,Ξ(χTucker))=N(μˉ,Σˉ),(35)
其中 μ ˉ \bar{\mu} μˉ 和 Σ ˉ \bar{\Sigma} Σˉ 分别为关于 χ ˉ T u c k e r \bar{\chi}{\mathrm{Tucker}} χˉTucker 的预测后验分布均值和方差。随后定义并最大化采集函数,以决定 Ξ ( χ T u c k e r ) \Xi(\chi{\mathrm{Tucker}}) Ξ(χTucker) 的下一个搜索点,直至获得最优值。