定义
所谓高斯积分,是指
在概率论中通常写成一般形式()
正态(高斯)分布的核心形状就是(
)
背景
(背景部分大多数定理是没有给出证明地,只是单纯的套用,所以不用纠结在这,只需要简单了解即可)
考虑伯努利试验,次抛硬币,正反面概率
。正面次数
的概率为
我们要研究的是当抛 次硬币(伯努利试验,成功概率
)时,正面次数
恰好为
的概率(
是"偏离中心
的量,且
相对
很小)。所以
组合数,这里
。阶乘在计算中是比较麻烦的,使用阶乘来表示
我们也无法看到它的变化图像及概率。这里要用到Stirling近似,Stirling近似的作用是将离散的阶乘转化为连续的指数函数形式,从而通过代数化简和对数展开,得到分布的形状。
Stirling近似
Stirling近似是描述大整数阶乘(
)渐近行为的公式,其标准形式为
其中"
Stirling近似的"渐近性"体现在当
证明:
Stirling近似的本质是用连续函数逼近离散阶乘的增长规律,其推导过程包括以下三步:
1.从"离散求和"到"连续积分":
阶乘的对数
计算积分
这里用连续积分近似得到
两边同取指数
这里之所以使用
2.修正项
上述积分近似忽略了求和与积分的"间隙误差"(即
其中
整理主项得
把阶乘用 Stirling 近似代入 Wallis 公式,两边取对数并比较常数项,可以唯一解出:
指数化
对组合数的三个阶乘()分别用Stirling近似,代入后得到:
分母根号部分,因此,根号的比值为
指数部分,展开后利用对数性质
和泰勒展开
最终可化简出指数上的二次项
。经过根号和指数的化简,最终得到:
这里就出现了这样的"钟形"函数。
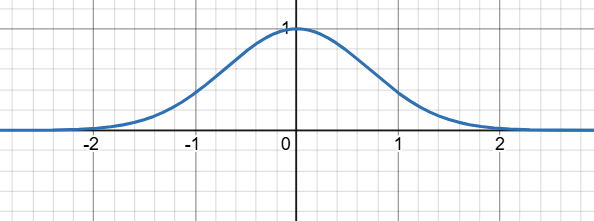
钟形曲线就从二项分布的问题中第一次出现。
求解
关于高斯积分的求解的过程是一个很巧妙的过程。为了可视化地看到这个积分的求解过程,我推荐两个博主的视频(第二个视频也是我最喜欢的博主3Blue1Brown,他介绍的积分过程更详细更可观;当然,第一个视频的介绍也相当不错,可以很好地理解积分的思路过程):
优雅的高斯积分与钟形曲线,一个普适性的公式_哔哩哔哩_bilibili
【官方双语】为什么正态分布里会有一个π?(不止是积分技巧)_哔哩哔哩_bilibili
我在这里用数学推导的方式简要介绍高斯积分的求解过程:
高斯积分是概率论、微积分、数理统计(尤其正态分布、中心极限定理)中核心反常积分,其经典形式为:
的原函数不是初等函数,无法用常规不定积分公式直接求解,因此主流解法是将单积分平方转化为二重积分,再通过极坐标变换计算。
首先被积函数,且当
时,
指数衰减远快于幂函数增长,因此反常积分
收敛。
由定积分乘法规则,两个独立变量的单积分相乘可改写为二重累次积分。积分变量可自由换名,第二个积分把变量改为,两积分相互独立:
第二个积分对于对
进行积分的
来说是常数,所以可以写成
合并积分区域后得(积分区域为整个平面)
要对上式进行积分的话就要进行双重积分。被积函数有
两个未知数,
表示平面上的一个点。而根据勾股定理得
,表示点
离中心原点的距离,也就是一个圆的半径,对于每个圆的半径都有一个高度值
。不同的
就代表了不同的圆,一圈一圈的圆形成了不同的高度,整个式子就形成了一个空间曲面,即钟形曲面。
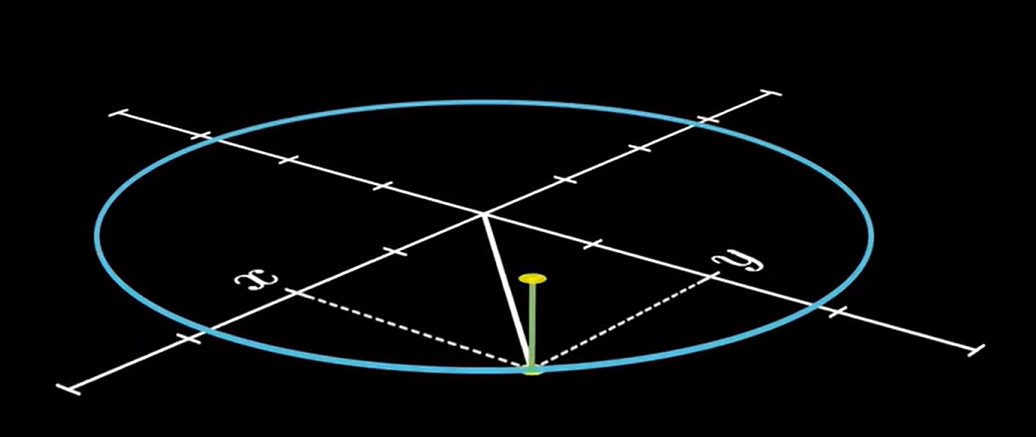

我们要求的就是求这个钟形曲面下的体积,因为
可以视为边长为
的非常小的矩形,然后乘上高
就得到了一个非常小的方柱体体积,将这些体积通过积分累加起来就是曲面下的体积。
如果我们在曲面上任意画一个圆(将其视作壁厚无限小,即半径为的空心筒壁),它的半径为
,那它的周长就是
,侧面积等于
,则它的体积为
(将其展开为长方体,底面积乘高即可)。
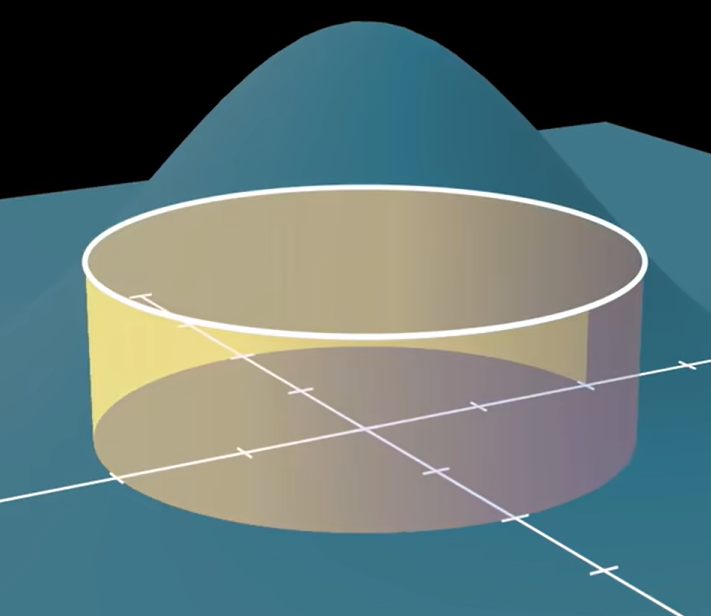
曲线可视为无数个这样的薄壁圆筒的体积之和,我们对这个薄壁圆筒的体积进行积分就得到的曲线下的面积:
的积分就很好算了,直接用不定积分公式求解即可。求得
,所以
,即
中心极限定理
设是一组独立同分布的随机变量,它们满足
- 两两相互独立
- 服从同一概率分布
- 存在有限的数学期望
定义样本和(或样本均值
),将其标准化:
则当样本量(数量足够大)时,
的分布会收敛于标准正态分布
,即:
或者说,随机变量的和近似服从正态分布
。
通俗来讲,中心极限定理就是在说无论单个随机变量原本是什么分布,只要变量相互独立、期望和方差有限,当变量数量足够多时,它们的总和(或平均值)一定会近似服从正态分布(钟形分布)。
3Blue1Brown在视频【官方双语】但是什么是中心极限定理?_哔哩哔哩_bilibili中以高尔顿板和掷骰子的实例很好的说明了中心极限定理,非常推荐观看。以下会简要介绍两个实例。
实例一:高尔顿板理想高尔顿板规则:
- 小球每碰到一颗钉子,独立选择向左或向右,概率各为
- 定义单次碰撞的偏移量为随机变量
- 板上一共有
计算
可见,
一个小球经过全部
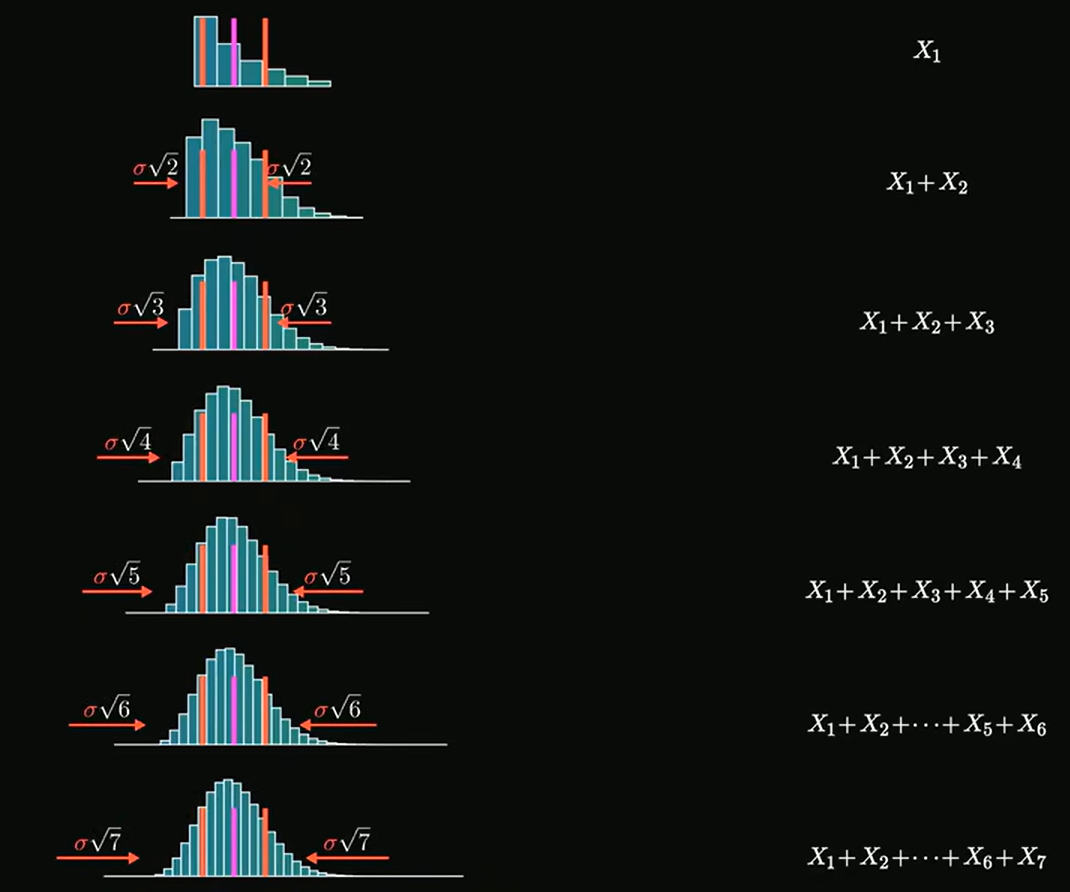
根据期望、方差的可加性:
- 总期望值:
- 总方差:
- 总标准差:
将
根据独立同分布中心极限定理,当钉子排数
当我们扔成千上万个小球(各小球之间不会互相干扰) ,就是对随机变量
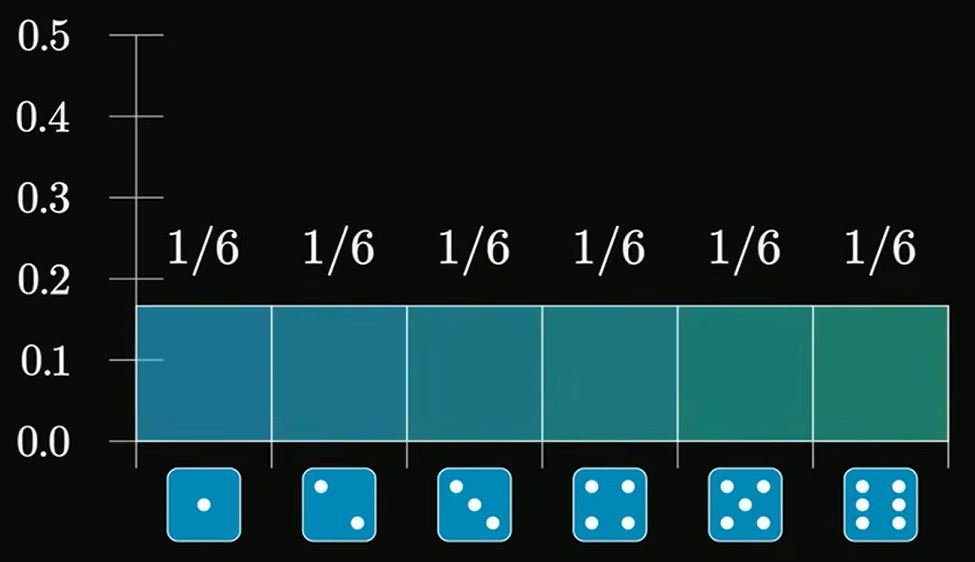
实例二:掷骰子在掷骰子时,每个骰子的点数,就是一个独立同分布的随机变量
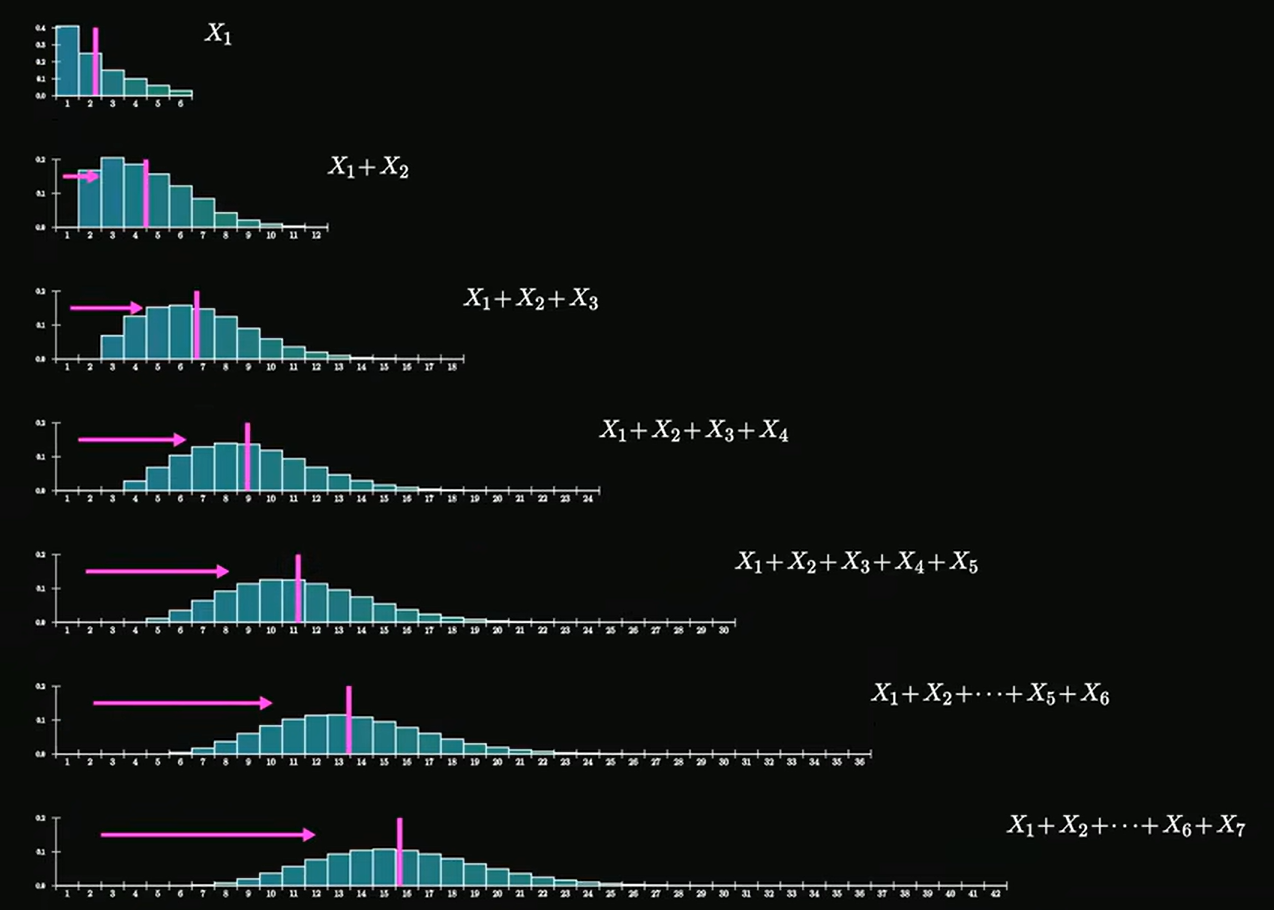
当我们掷
根据期望和方差的可加性,总期望
将
根据独立同分布中心极限定理,当掷骰子数
另外,随机变量的分布并不影响它们的总和(或平均值)近似服从正态分布。我们上述使用的均匀分布的骰子(
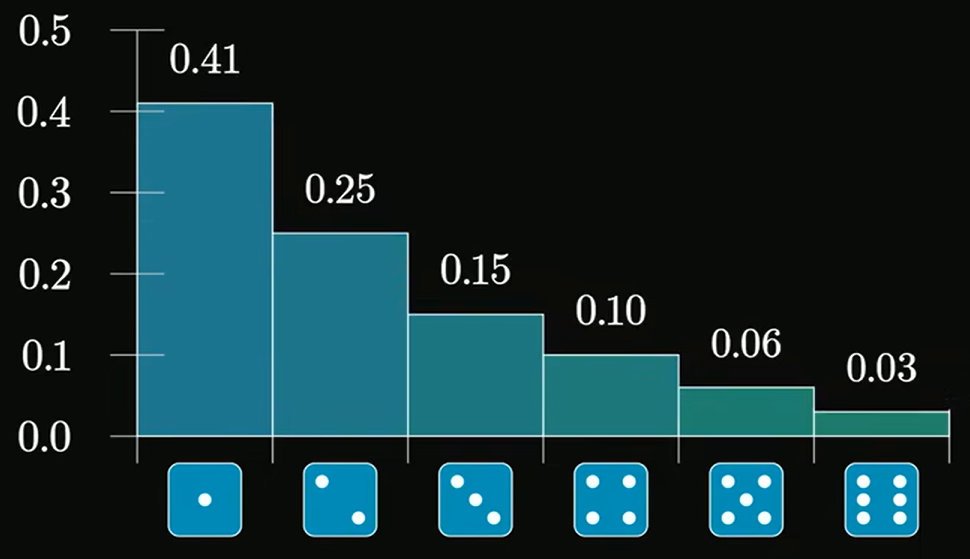
当使用偏态分布的骰子时,当
无论是随机变量是什么样的分布,它最终的分布曲线都会变成对称的钟形曲线,只不过由于期望值和方差值不同这个钟形曲线位置和集中程度有所不同,随着
钟形曲线右移主要是由于均值发生了改变,对于一个随机变量
标准差
中心极限定理对这些本质上相同但由于均值方差不同的函数做了一些操作,将它们的中心对齐使它们的均值在一条线上,然后缩放x轴,使它们的标准差均为1。上述对齐缩放操作就是标准化变换
上述介绍的独立同分布正态分布是基础版本,现实中一个随机现象是由大量微小的、各自独立(或弱相关)的随机因素叠加而成,也就是不满足 "独立 + 同分布",但最终依然会出现正态分布。更广泛地说,只要现实中的 "叠加型" 随机现象满足它们由大量微小的、各自独立(或弱相关)的随机因素叠加而成,并且没有任何一个因素的影响能 "主导" 整体结果,那即使不满足 "严格独立" 和 "完全同分布",叠加后的结果依然会趋近正态分布。
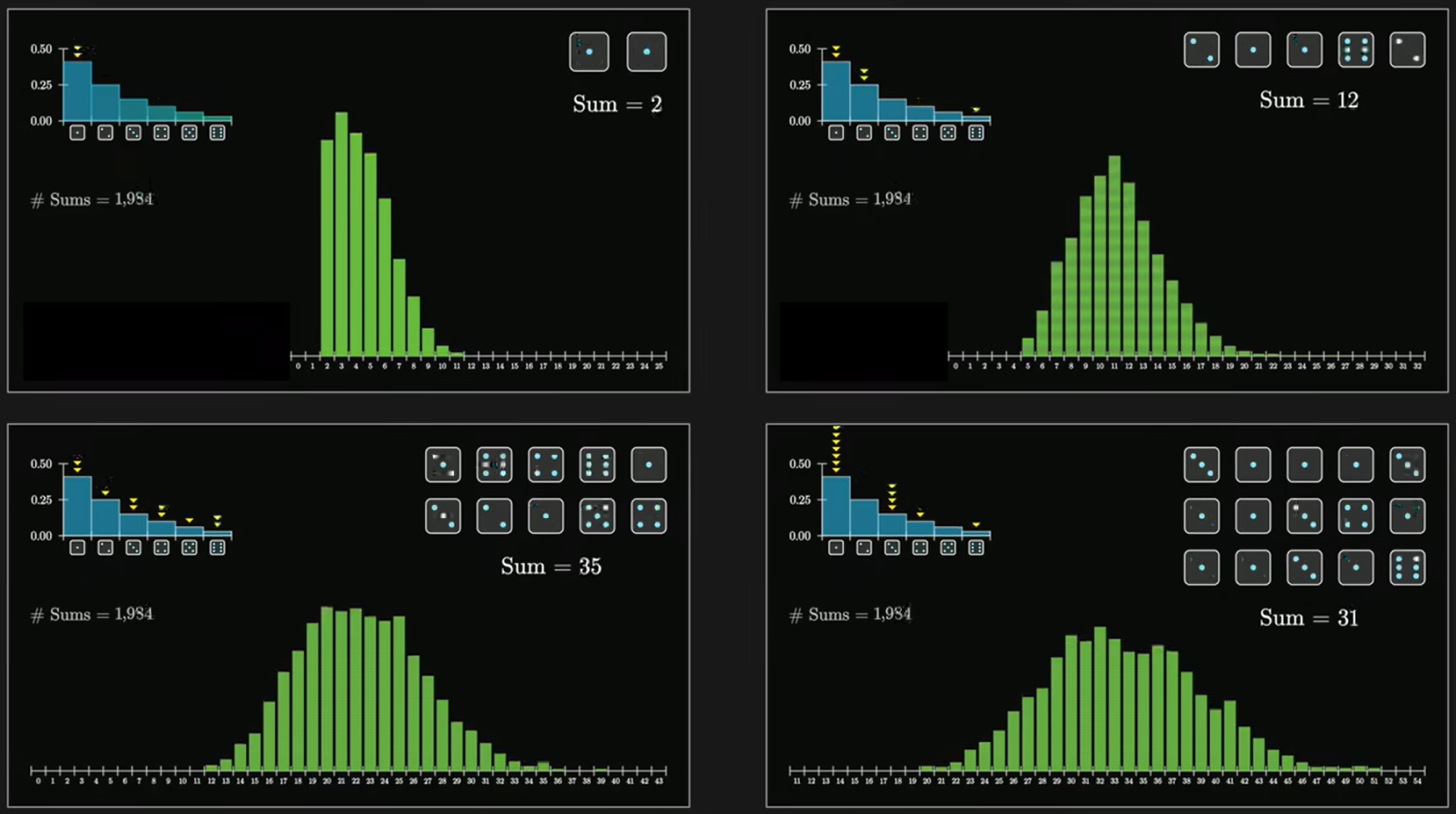
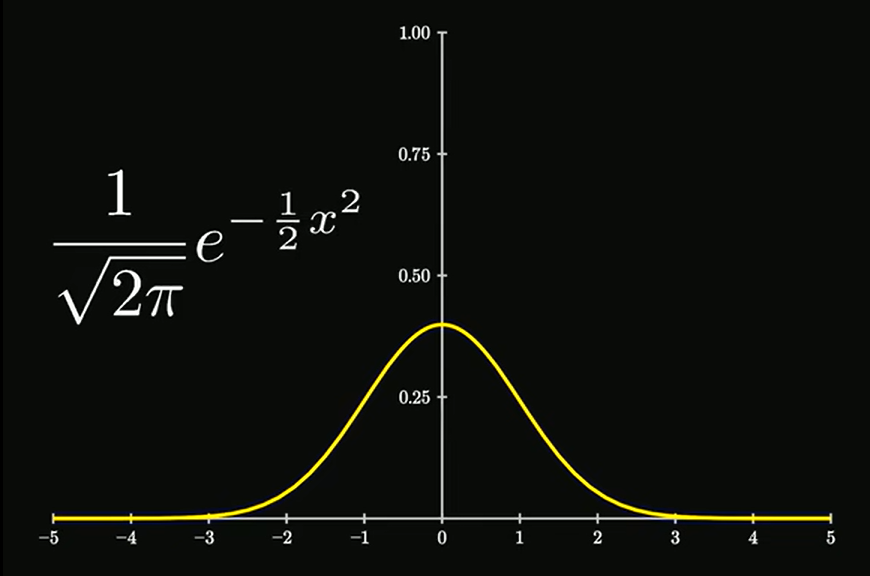
正态分布
**正态分布是一种 "分布形态",中心极限定理是解释 "这种形态为何无处不在" 的核心规律。**现实中人体身高、考试分数、工业测量误差、产品尺寸等绝大多数数据都近似正态分布,根本原因是这类数据都是无数个微小、独立的随机因素叠加而成,恰好满足中心极限定理的条件,因此自然趋近正态分布。正态分布的公式是:
现在我们按照从指数函数→构造钟形曲线→过渡概率分布→归一化→平移中心的路线一步步组装理解这个公式:
1.从基础指数函数,构造双侧平滑衰减钟形轮廓
底数为自然常数的指数函数
,
增大时指数增长,
减小时指数衰减。
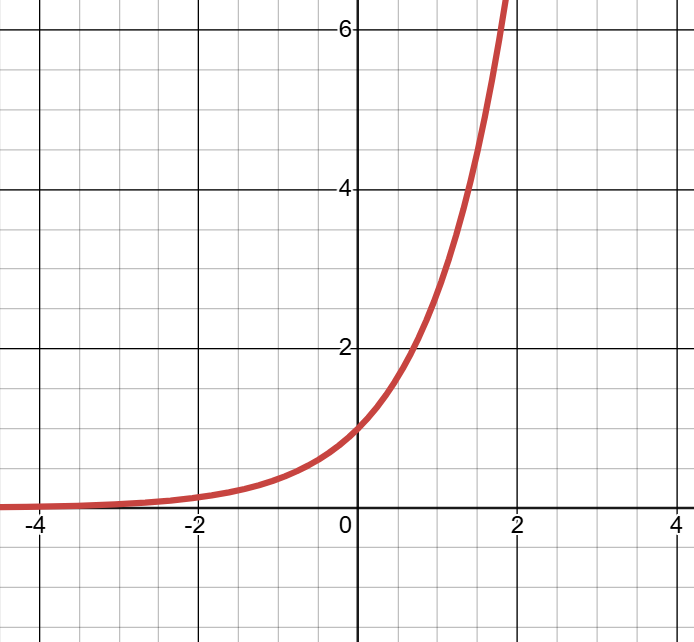
为了方便表示,将替换成
,此时变为
越大、函数值越小,实现
轴正向指数衰减。
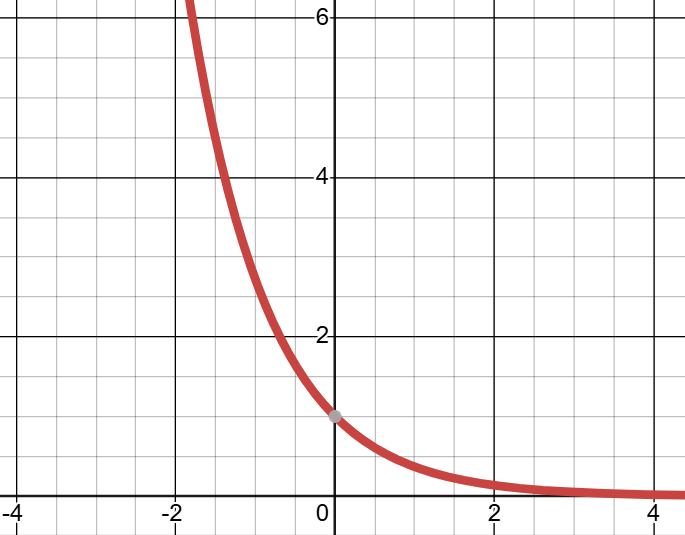
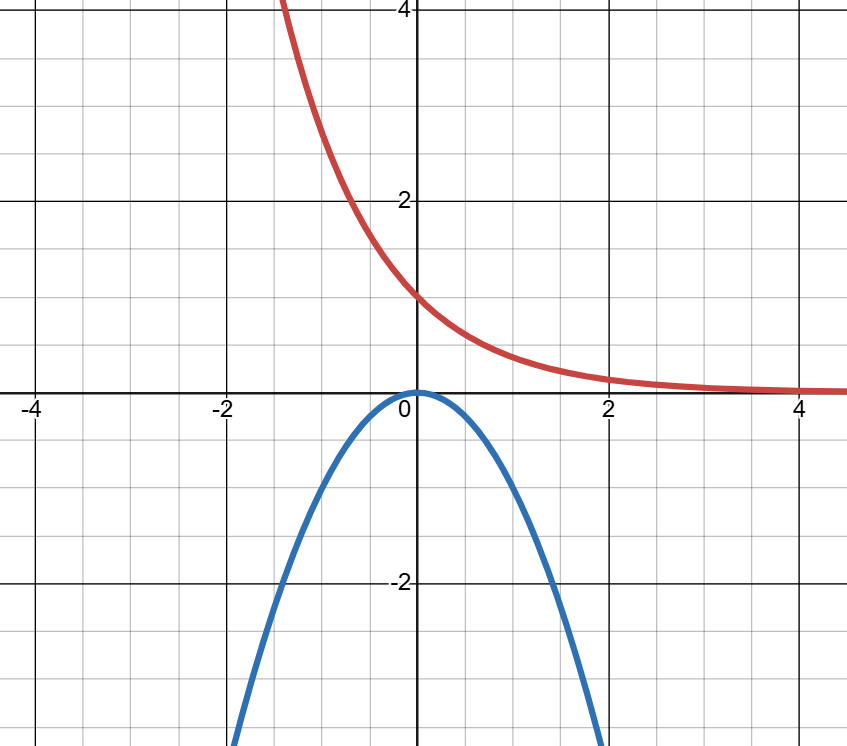
为了让它在正负方向上均衰减(凑钟形)。第一个想到的函数是
,虽然这个函数可以实现向两侧衰减,但是在
处会出现一个尖刺,这不符合钟形。
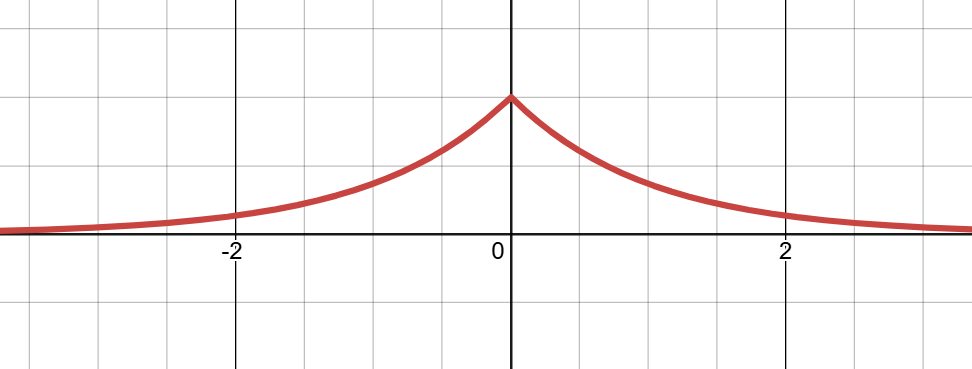
向两侧衰减并且极值处过渡平滑的函数,最简单的函数就是,但是
会无限衰减到
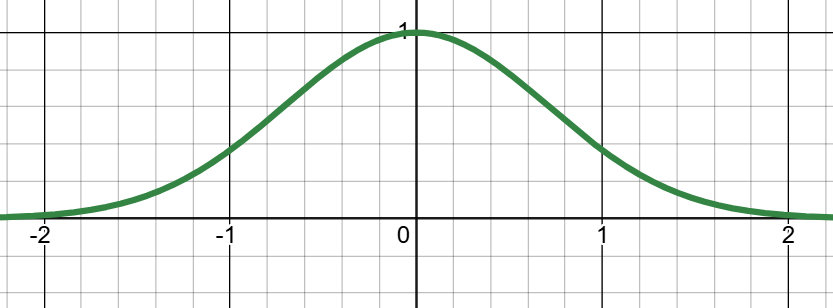
,我们需要的是使它无限衰减到0,而上述的指数函数恰好满足这个性质,所以就有了钟形函数的雏形函数(图像如下图二所示):
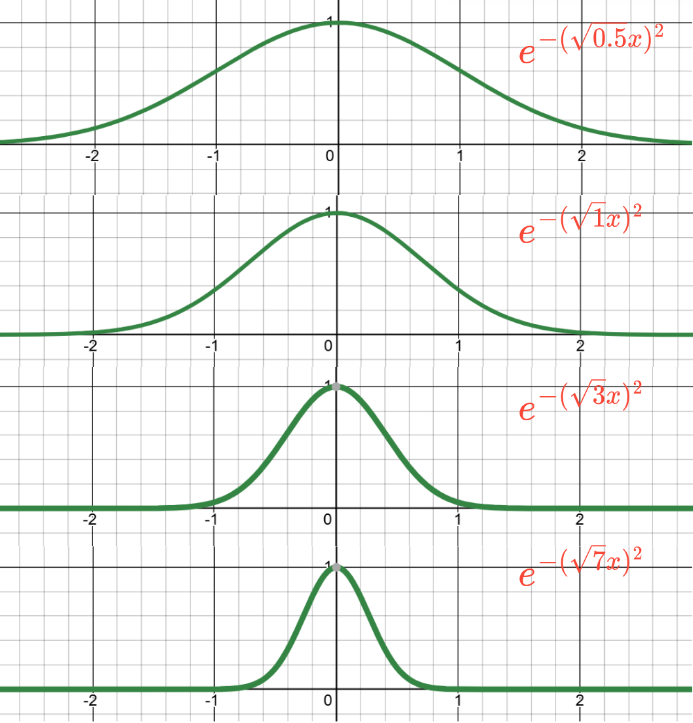
我们在的指数上加上一个常数
,即
,通过改变常数
就可以在水平方向上收缩钟形曲线,如下图所示。
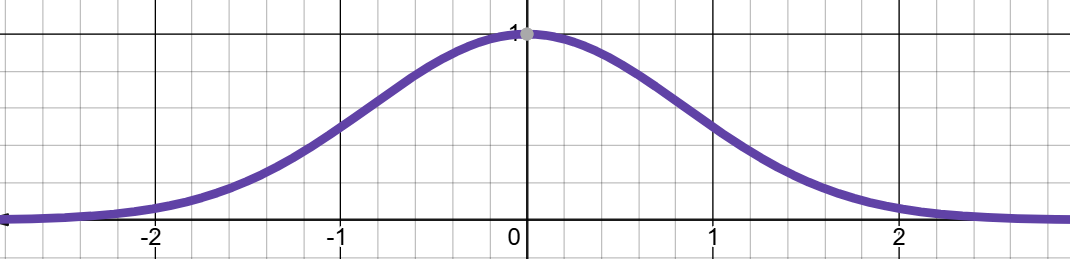
事实上,上述的指数并没有什么特殊含义,换成其他底数也能实现同样的效果,例如
,图像如下,也是一个钟形曲线。事实上上式
也可以写成
,
作为一个整体,改变常数
的值就可以实现底数的改变,从而改变钟形曲线的收缩程度。之所以使用
而不选择其他常数一方面是任意底数都可以转换为指数(
),另一方面
的导数、积分、微分运算更简单,因此数学、统计学统一选用自然底数
。
2.换参数,使之更符合概率分布
将,
。
只是用来缩放曲线的抽象常数,是纯数学参数,无实际意义,而
是统计学定义的标准差,有明确物理和统计含义,表征数据的离散程度。这里仅是一个参数替换,
本质还是水平伸缩图像。
概率分布共有两类:
- 离散型分布:变量取有限个孤立值(如掷骰子 1~6 点),直接给每个点的概率,所有概率相加和为1。
- 连续型分布:变量取值充满一段/整段实数区间(身高、体重、测量误差),单个精确点的概率永远为 0(点没有长度)。
对于连续随机变量
- 区间概率 = 曲线下面积:
随机变量落在区间
密度函数- 归一化公理: 即总概率为1。
变量在全体实数范围内出现的总概率是必然事件,因此
之所以这里会加了一个系数常数,是为了让参数
恰好等于分布的标准差而推导出的结果。在介绍具体推导过程之前先要了解方差计算公式,不管是离散还是连续型随机变量,方差的定义都是离差平方的期望,即
对于离散型随机变量:
假设是离散型随机变量,它的取值为
,对应的概率
。对于任意函数
,其期望为:
把代入上式,得到离散型方差:
对于连续型随机变量:
连续型随机变量的取值是连续的,所以我们用概率密度函数
来描述概率分布,变量落在区间
的概率为
。根据微积分的思想,可以把
理解为极小区间
内的概率微元,相当于离散里的
。
对应离散的,连续型变量的期望是
同样把代入连续型期望公式
接下来我们开始推导系数常数的由来。先写出通用"对称钟形" 概率密度函数形式
,根据概率密度的定义,曲线下总面积等于1,可以解得
,所以函数变为
。方差的定义是数据围绕均值的波动程度,公式为
把代入,令
,则
利用积分公式可以求得,代入得
我们希望这个分布的标准差(方差的平方根)等于我们定义的参数,即:
所以指数上的系数
就是
,代入即得
3.归一化
是一个钟形轮廓,适合描述 "中间取值概率高、向两侧逐渐降低" 的连续随机现象,它具备概率密度的形态特征,但是为了符合概率密度函数的归一化公理,必须对这个函数进行归一化操作。
最基础的高斯积分,而函数
中的
将图像收缩了
倍,所以为了保持面积为1,要加上系数
。
4.引入均值,平移曲线
目前曲线中心固定在,如果想让钟形的最高点(分布中心)左右移动,只需做自变量平移,即
,即原式变为:
当时,曲线右移; 当
时,曲线左移。
上式就是正态分布概率密度公式,记作。特别地,当
,上式化简为
这就是标准正态分布。
正态分布的标准化操作
对于任意服从正态分布的随机变量,标准化变换公式为:
变换后的服从标准正态分布
,即均值为 0、标准差为 1 的正态分布。
之所以要进行标准化操作,是因为不同均值、不同方差的正态分布(比如不同考试的成绩),原始数据无法直接比较;标准化后的值表示 "距离均值多少个标准差",可以跨分布比较相对位置。(回归分析、假设检验、机器学习中,标准化可以消除量纲影响,提升模型收敛速度和稳定性)
标准正态分布的概率表( 表)是通用的,所有正态分布的概率都可以通过标准化后查
表得到。常用的 3σ 原则就是根据标准正态分布的概率表得出的,任意正态分布
,只要通过标准化
,就能得到:
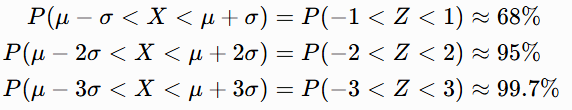
数据落在 ±3σ 外的概率只有 0.3%,属于极小概率事件。如果数据里出现了这样的点,大概率是异常值(比如测量误差、录入错误、生产中的不合格品),工业上的 "3σ 质量管理" 就是基于这个原理。