👨⚕️ 主页: gis分享者
👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅!
👨⚕️ 收录于专栏:java 200道热门面试题
文章目录
- 一、🍀回答重点
-
- [1 ☘️数据怎么存的?](#1 ☘️数据怎么存的?)
- [2 ☘️节点之间怎么联系?](#2 ☘️节点之间怎么联系?)
- [3 ☘️客户端怎么找数据?](#3 ☘️客户端怎么找数据?)
- 二、🍀扩展知识
-
- [1. ☘️为什么哈希槽是 16384 个?](#1. ☘️为什么哈希槽是 16384 个?)
-
- [1.1 ☘️首先是消息大小的考虑](#1.1 ☘️首先是消息大小的考虑)
- [1.2 ☘️集群规模的考虑](#1.2 ☘️集群规模的考虑)
- [2. ☘️集群哈希槽分片原理](#2. ☘️集群哈希槽分片原理)
- [3. ☘️存储数据示例](#3. ☘️存储数据示例)
-
- [3.1 ☘️计算哈希槽](#3.1 ☘️计算哈希槽)
- [3.2 ☘️确定目标节点](#3.2 ☘️确定目标节点)
- [3.3 ☘️跨节点请求示例](#3.3 ☘️跨节点请求示例)
- [4. ☘️Gossip 协议](#4. ☘️Gossip 协议)
- 三、🍀面试官追问
一、🍀回答重点
Redis 集群主要解决了单机内存和并发的瓶颈,它通过多个 Redis 实例组成,每个实例存储不同的数据分片。
它的实现原理,可以用三个关键词来概括:分片、Gossip 协议、去中心化。
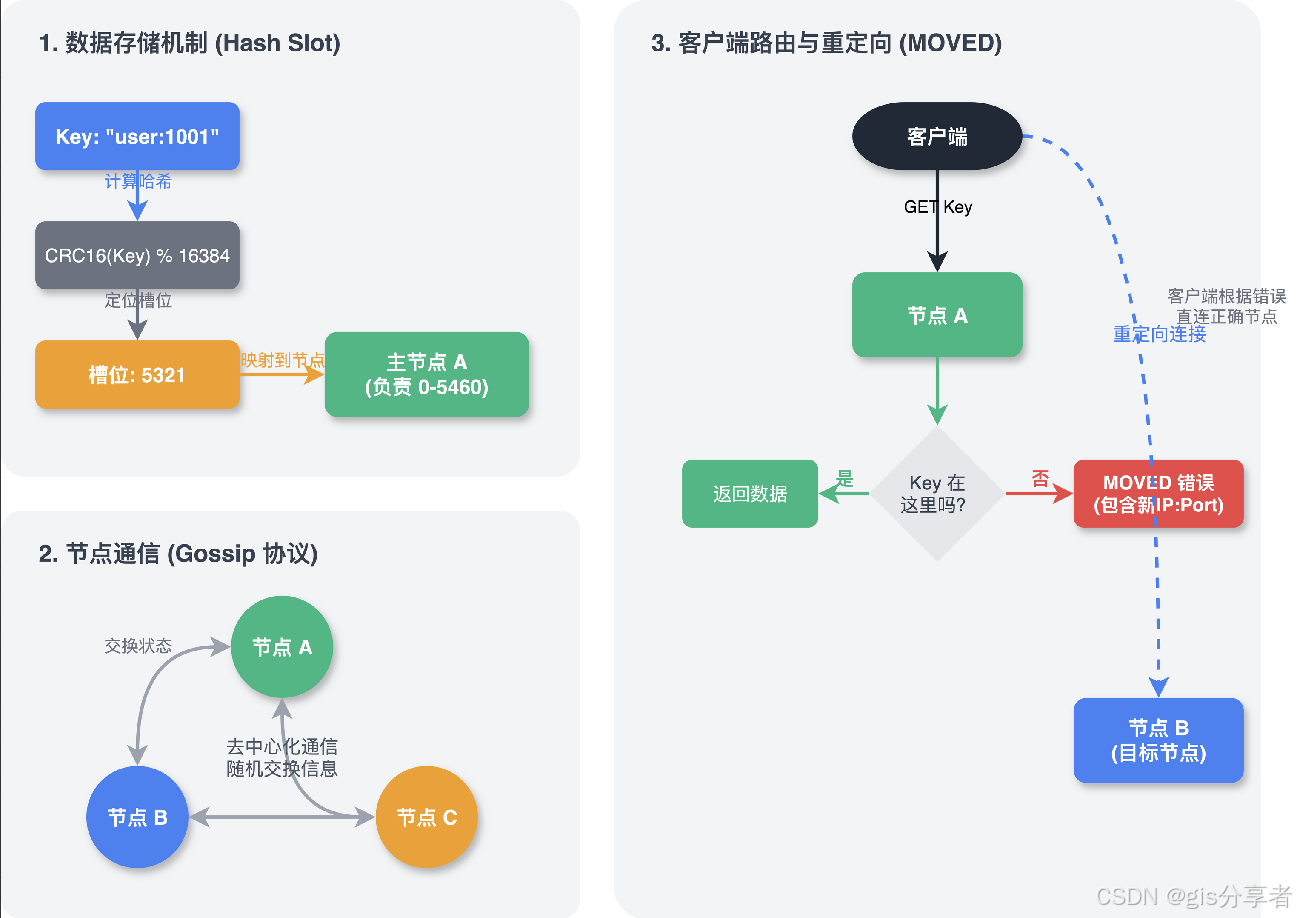
1 ☘️数据怎么存的?
Redis 集群引入了哈希槽的概念,把整个数据集群划分为 16384 个槽。集群里的每个主节点负责维护一部分槽。
存一个 Key 时,Redis 先对 Key 算一个 CRC16 值,然后对 16384 取模,算出它属于哪个槽,再把数据存到负责这个槽的节点上。
这样做的好处是扩容缩容非常方便。要加一个新节点,只需要把其他节点身上的一部分槽"过户"给新节点就行了,不需要像传统哈希那样重新计算所有数据的位置。
2 ☘️节点之间怎么联系?
集群里的节点是去中心化的,没有所谓的"中心大脑"。它们之间通过 Gossip 协议互相通信。
每个节点定期随机选几个邻居,交换彼此的状态信息,比如"我负责哪些槽"、"我是否还活着"。这样只需要很短的时间,集群的所有节点就能达成一致,知道整个集群的拓扑结构。
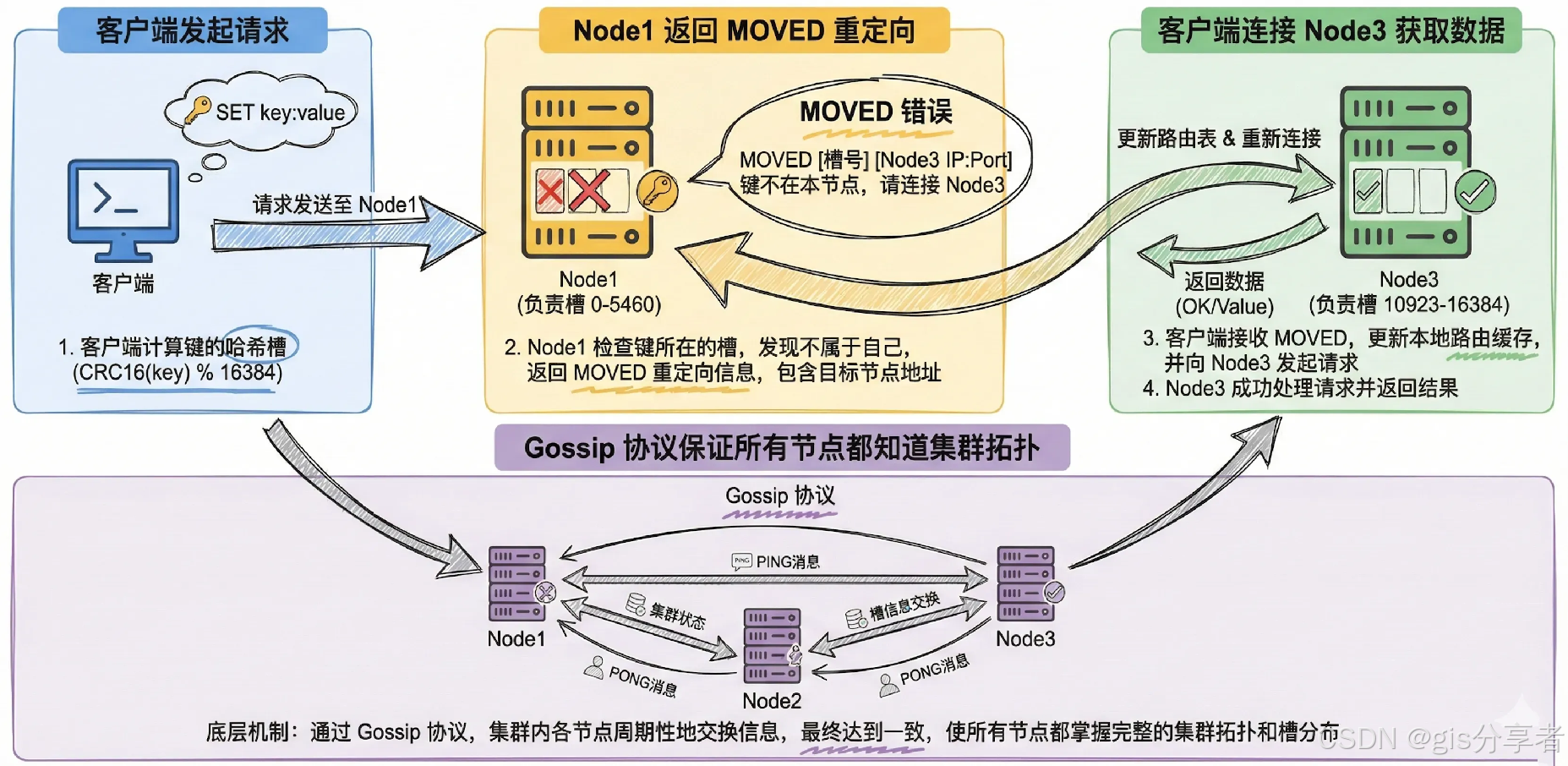
3 ☘️客户端怎么找数据?
客户端可以连接集群的任意一个节点。如果客户端要找的 Key 刚好在这个节点上,那就直接返回;如果不在,这个节点不会充当代理去转发请求,而是会返回一个 MOVED 错误,告诉客户端:"这个 Key 不归我管,你去连 IP:Port 这个节点吧。"
二、🍀扩展知识
1. ☘️为什么哈希槽是 16384 个?
1.1 ☘️首先是消息大小的考虑
正常的心跳包需要带上节点完整配置数据,心跳还是比较频繁的,所以需要考虑数据包的大小。用 16384 数据包只要 2KB,用 65535 则需要 8KB。
槽位信息用一个长度为 16384 位的数组来表示,节点拥有哪个槽位,就将对应位置设为 1,否则为 0。
心跳数据包就包含槽位信息如下图所示:
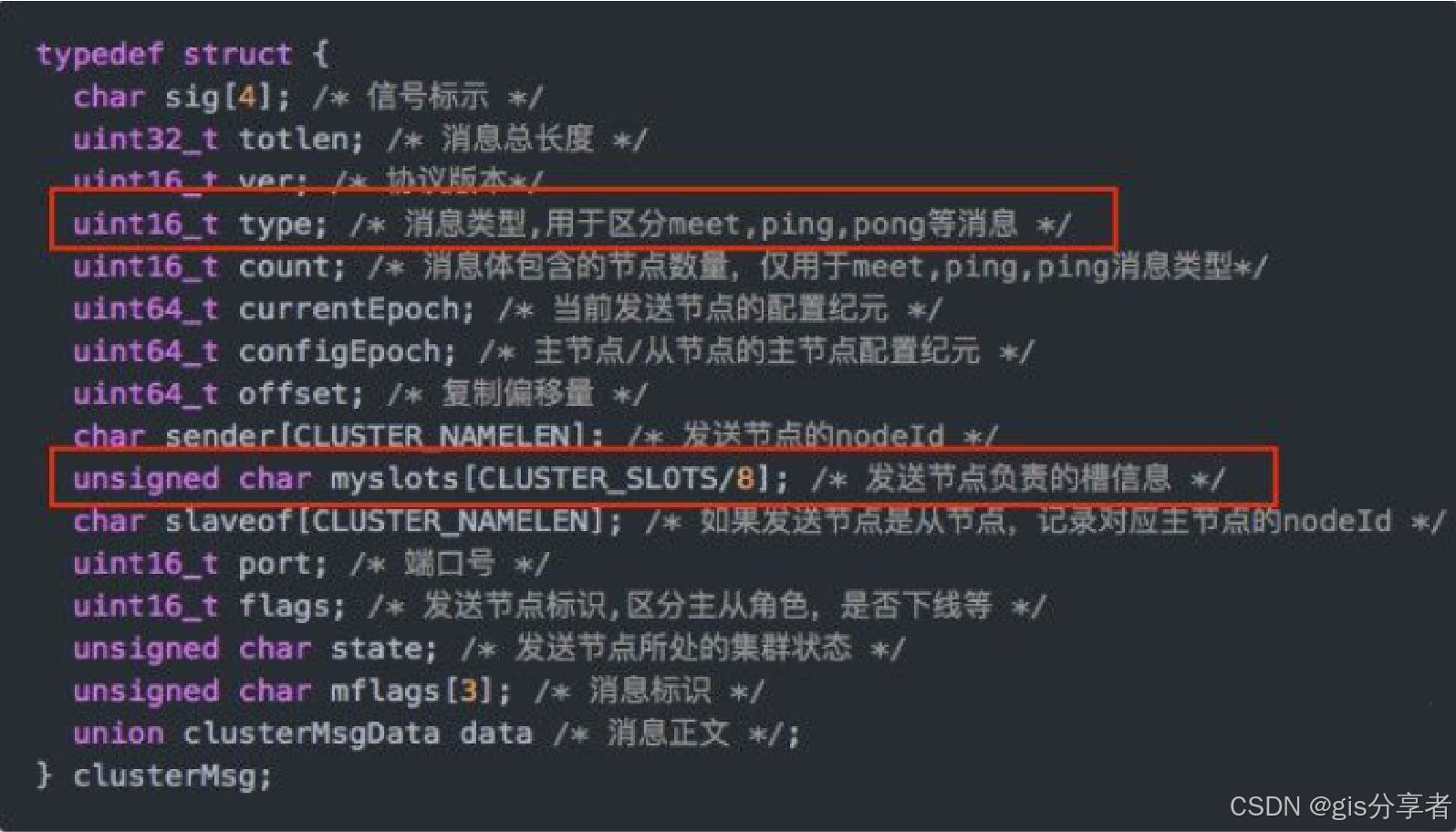
消息头中最占空间的是 myslotsCLUSTER_SLOTS/8:
- 槽位为 65536 时,大小是 65536÷8÷1024=8KB
- 槽位为 16384 时,大小是 16384÷8÷1024=2KB
如果槽位为 65536,ping 消息的消息头就太大了,浪费带宽。
1.2 ☘️集群规模的考虑
集群不太可能会扩展超过 1000 个节点,16384 够用且使得每个分片下的槽又不会太少。
2. ☘️集群哈希槽分片原理
Redis 集群会将数据分散到 16384 个哈希槽中,集群中的每个节点负责一定范围的哈希槽,使用 CRC16 哈希算法计算键的哈希槽,以确定该键应存储在哪个节点。
集群哈希槽分片如下图所示:
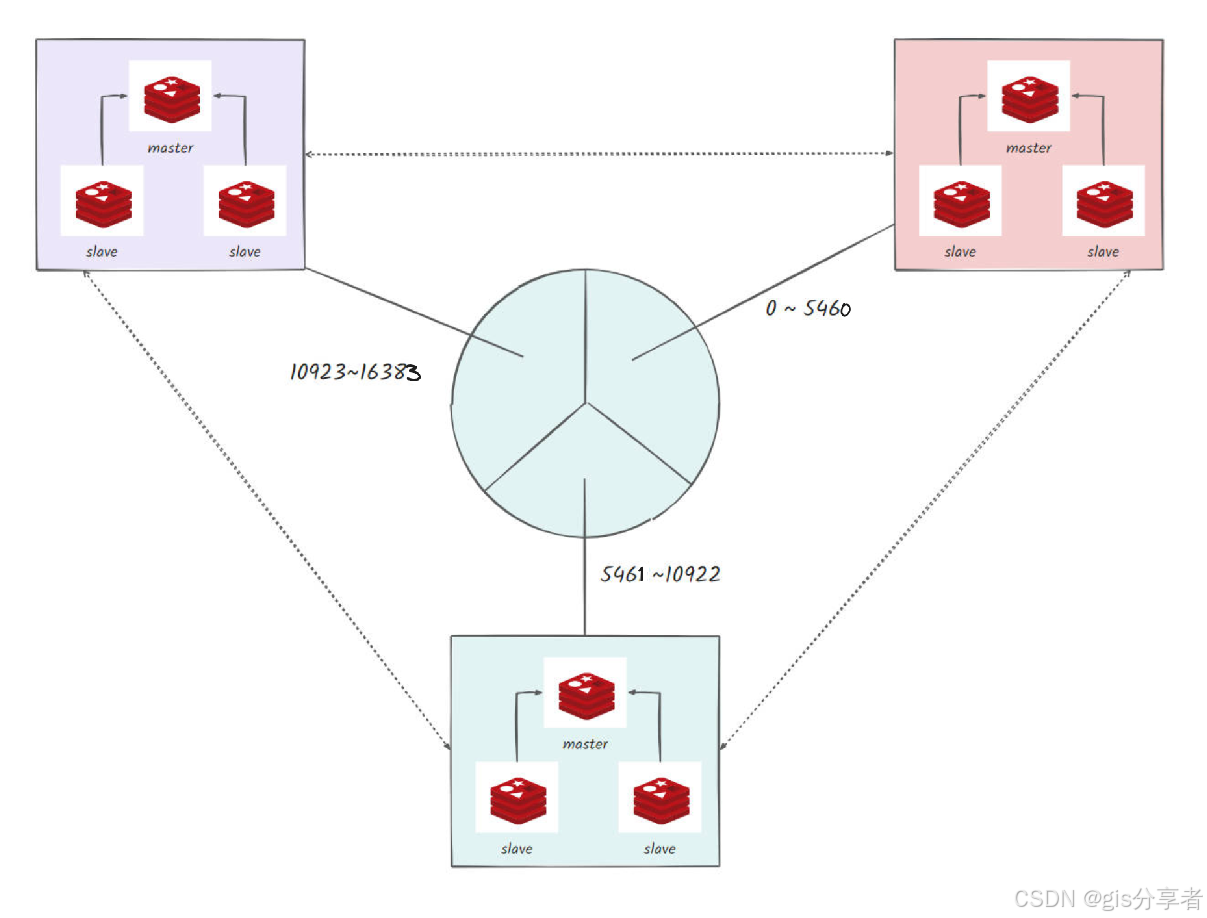
每个节点会拥有一部分槽位,对应的键值会根据其本身的 key 映射到一个哈希槽中,主要流程:
- 根据键值的 key,按照 CRC16 算法计算一个 16 bit 的值,然后对 16384 取余,得到一个对应的哈希槽编号
- 根据每个节点分配的哈希槽区间,对应编号落在哪个区间上,就能找到对应的分片实例
以三个节点为例:
还有一点需要强调,redis 客户端可以访问集群中任意一台实例,正常情况下这个实例包含这个数据。
但如果槽被转移了,客户端还未来得及更新槽的信息,当前实例没有这个数据,则返回 MOVED 响应给客户端,将其重定向到对应的实例(因 Gossip 集群内每个节点都会保存集群的完整拓扑信息)
3. ☘️存储数据示例
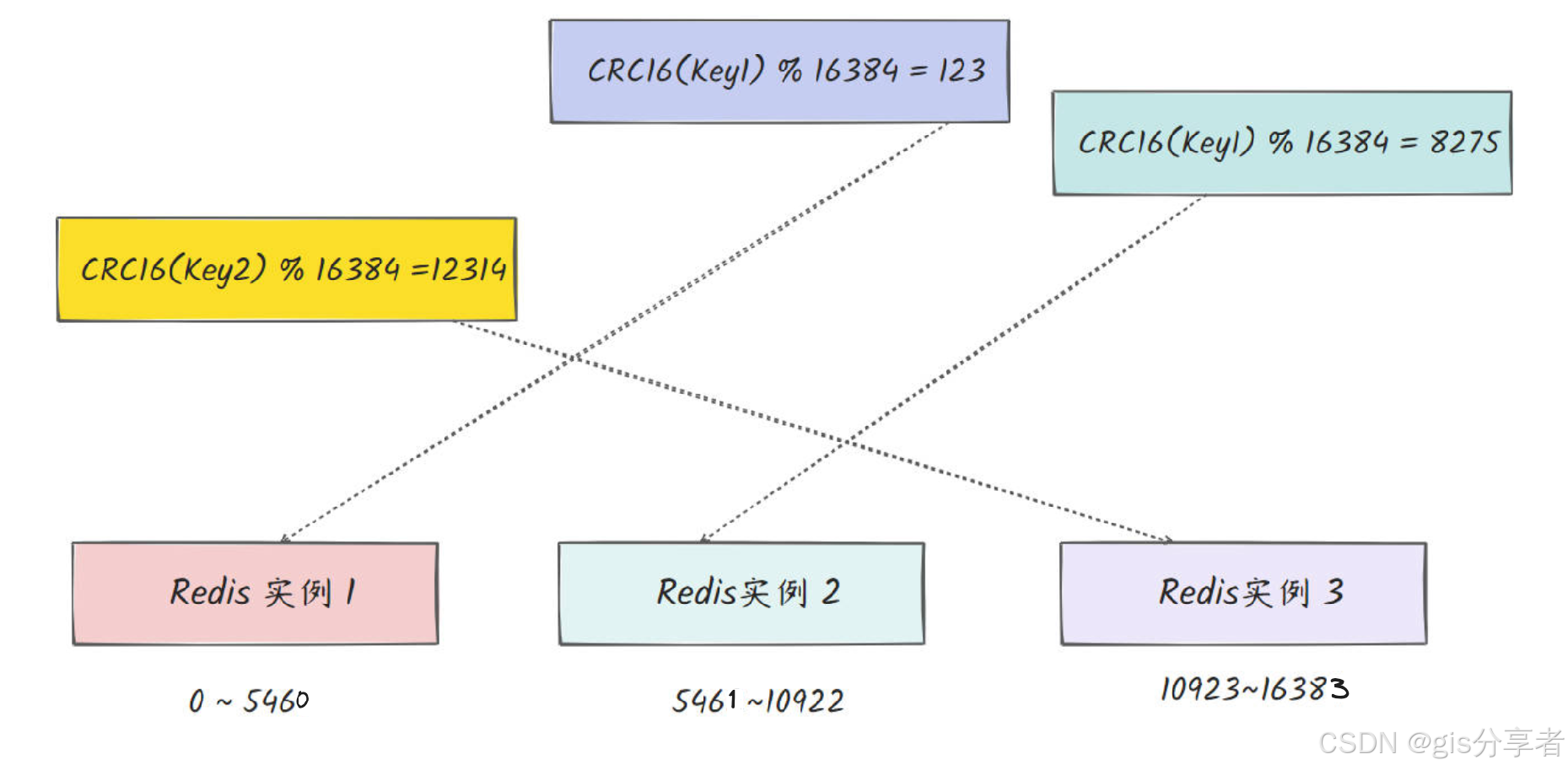
假设有一个 Redis 集群,包含三个主节点,它们分别负责以下哈希槽:
- Node1: 哈希槽 0-5460
- Node2: 哈希槽 5461-10922
- Node3: 哈希槽 10923-16383
现在要存储一个键为 user:1001 的数据。
3.1 ☘️计算哈希槽
使用 CRC16 哈希算法计算 user:1001 的 CRC16 值 2)假设计算结果为 12345 3)计算该值对应的哈希槽 = 12345 % 16384 = 12345
3.2 ☘️确定目标节点
12345 落在 Node3 的负责范围 10923-16383,因此 user:1001 会被存储在 Node3 中。
3.3 ☘️跨节点请求示例
如果客户端连接的是 Node1,但需要访问存储在 Node3 的键 user:1001,查询过程如下:
1)客户端使用 CRC16 算法计算 user:1001 的哈希值 12345,计算哈希槽:12345 % 16384 = 12345 2)因为客户端连接的是 Node1,所以发送 GET user:1001 到 Node1
3)Node1 检测到这个键属于 Node3,返回一个 MOVED 错误,里面带着 Node3 的 IP 和端口
4)客户端根据返回的目标节点信息,建立与 Node3 的连接
5)客户端向 Node3 发送 GET user:1001 6)Node3 查询到值并返回结果
4. ☘️Gossip 协议
Gossip 协议是一种非常像"八卦传播"一样的分布式系统通信协议。
核心思想就是:像人传闲话一样,随机找几个节点聊聊天,把消息扩散出去,最后整个集群都会知道这个消息。
想象一下一个村子里有人发现了八卦,他不会挨家挨户去通知所有人,那样太慢太累了。他只告诉了 3 个朋友,这 3 个朋友又各自告诉另外 3 个朋友......没几轮,整个村子就都知道了。
三种常见模式
1)Push 模式:节点 A 知道了新消息,就随机挑几个节点把消息直接推过去。被推的节点再随机推给其他人,像病毒一样主动传播。
2)Pull 模式:节点定期互相打招呼:"喂,你最近有什么新八卦吗?"如果对方有自己没有的消息,就拉过来。像大家定期聚会交换小道消息。
3)Push+Pull 混合模式:既主动推也定期拉,传播速度最快,也最可靠。这是最常用的模式。
优缺点对比
| 方面 | 表现 | 说明 |
|---|---|---|
| 去中心化 | 极强 | 无单点故障,所有节点对等 |
| 容错能力 | 极强 | 节点批量宕机、网络分区、抖动都不影响最终收敛 |
| 可扩展性 | 线性扩展 | 从 10 台到 10000 台都不需要改架构 |
| 传播延迟 | 中等 | 几秒到几十秒收敛,不适合毫秒级强一致性场景 |
| 消息冗余 | 较高 | 同一条更新会被多次传播,带宽利用率不是最优 |
| 一致性强度 | 最终一致性 | 不提供强一致性保证,不能用于扣款、分布式锁等场景 |
三、🍀面试官追问
提问:集群扩容的时候,数据迁移会不会影响线上读写?
回答:会有一定影响,但 Redis 做了优化。扩容时槽处于 MIGRATING 状态,这时候如果客户端访问正在迁移的 key,源节点会返回 ASK 重定向,告诉客户端去新节点取数据。和 MOVED 不同的是,ASK 只是临时重定向,不会更新客户端的槽映射缓存。整个迁移过程中数据是可读可写的,只是可能会多一次重定向开销。
提问:Redis 集群能保证强一致性吗?数据会不会丢?
回答:保证不了强一致性,数据确实可能丢。Redis 集群用的是异步复制,主节点写完就返回成功,不等从节点确认。如果主节点刚写完就挂了,从节点还没收到数据就被选为新主,那这部分数据就丢了。想要更强的一致性,可以开启 WAIT 命令等待指定数量的从节点同步完成,但这会牺牲性能。金融级别的场景,Redis 集群真不太合适。
提问:集群模式下,Lua 脚本和 MGET 这种多 key 操作还能用吗?
回答:能用,但有限制。多个 key 必须落在同一个槽里,否则会报 CROSSSLOT 错误。解决办法是用 Hash Tag,比如 {user}:1001 和 {user}:1002,Redis 只会对花括号里的 user 计算哈希,这样就能保证它们落在同一个槽。实际开发中,需要批量操作的 key 最好在设计 key 命名规则时就考虑好这个问题。
提问:16384 个槽,如果集群有 1000 个节点,平均每个节点才 16 个槽,这不会影响性能吗?
回答:理论上不会。槽的数量影响的是管理粒度和消息大小,不影响查找性能。key 找槽是 O(1) 的 CRC16 计算,槽找节点也是 O(1) 的数组查找。不过 1000 节点的集群已经很大了,实际上 Redis 官方建议集群规模控制在 1000 以内,因为节点越多,Gossip 消息的数量会增加,对网络带宽和 CPU 都有压力。