k8s容器编排技术实践------OpenEuler的k8s高可用集群构建实战![]() https://blog.csdn.net/xiaochenXIHUA/article/details/161345015k8s容器编排技术实践------k8s的介绍及其整体运行架构
https://blog.csdn.net/xiaochenXIHUA/article/details/161345015k8s容器编排技术实践------k8s的介绍及其整体运行架构![]() https://coffeemilk.blog.csdn.net/article/details/161011629
https://coffeemilk.blog.csdn.net/article/details/161011629
一、Deployment简介
为满足不同业务场景,k8s开发了Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等多种Controller。Deployment 为Pod和ReplicaSet提供了一个声明式定义 (declarative) 方法,用来替代以前的 Replication Controller更方便的管理应用。Deployment作为最常用的Kubernetes对象,经常会用来创建 ReplicaSet和Pod,但不会直接在集群中使用ReplicaSet部署一个新的微服务(是因为ReplicaSet 的功能其实不够强大,一些常见的更新、扩容和缩容运维操作都不支持)Deployment的引入就是为了支持这些复杂的操作 。
1.1、Deployment是什么
Deployment 是 Kubernetes(K8s)最核心、使用最广泛的工作负载控制器 ,专门用于管理无状态应用的 Pod 集群。
K8s 不会让 Deployment 直接管理 Pod,而是采用多层封装 :Deployment → ReplicaSet(副本集) → Pod
| 核心层级关系 | 说明 |
|---|---|
| Deployment | 在上层管理 ReplicaSet,提供发布、回滚、更新、版本控制等高级能力,是面向开发者 / 运维的入口。 |
| ReplicaSet | 负责保证集群中始终运行指定数量的正常 Pod。 |
| Pod | K8s 最小运行单元,真正运行业务的容器。 |
可简单理解为:Deployment 是 Pod 集群的「大管家」,帮你批量管理、运维一组功能完全相同的应用实例。
1.2、Deployment有啥用
Deployment几乎覆盖了线上无状态服务的全生命周期运维,核心能力如下:
| Deployment核心作用 | 说明 |
|---|---|
| ✅副本保活 & 故障自愈 | 通过 replicas 字段指定期望运行的 Pod 副本数量(比如 3 个)。 * 若 Pod 崩溃、容器异常、所在节点宕机; * Deployment 会通过 ReplicaSet 自动新建 Pod 补足数量; 从根源上解决单实例单点故障,保障服务高可用。 |
| ✅应用扩缩容 | * 手动扩缩 :直接修改 replicas 数值,即可快速增加 / 减少实例数,应对流量变化; * 自动扩缩 :无缝对接 K8s HPA(水平Pod自动扩缩器),根据 CPU、内存、QPS 等指标自动增减副本,适配流量峰谷(如电商大促、活动流量)。 |
| ✅零停机滚动更新(最核心) | 默认使用 RollingUpdate(滚动更新) 策略发布新版本:逐步销毁旧版本 Pod、同时创建新版本 Pod,整个发布过程服务不中断。 还可精细控制更新节奏: * maxUnavailable:更新过程中允许最大不可用 Pod 数; * maxSurge:更新过程中允许临时多出的 Pod 数。 另有 Recreate 策略(先删全部旧 Pod,再建新 Pod),会造成服务中断,仅测试环境使用。 |
| ✅版本记录 & 一键回滚 | Deployment 会自动记录每一次配置 / 镜像变更,生成历史版本(Revision): * 新版本上线出现 Bug、性能问题、报错时; * 可一键回滚到任意历史稳定版本,快速止损,降低线上故障影响。 |
| ✅发布暂停 / 恢复 | 支持临时暂停发布,批量修改配置、镜像、环境变量后再统一生效,避免多次触发更新。 |
| ✅标签解耦管理 | 依靠 Label(标签)和 Selector(选择器)关联 Pod,控制器与 Pod 完全解耦,调度、运维更加灵活。 |
1.3、Deployment的适用场景与不适用场景
明确前提:Deployment 主打「无状态应用」 (无状态应用:Pod 之间完全等价、无身份区分,不依赖本地磁盘存储数据,销毁 / 重建 Pod 不会影响业务,数据统一存放在外部组件(MySQL、Redis、对象存储等))
| Deployment的适用场景 | 说明 |
|---|---|
| ✅Web / 微服务 / API 接口(最主流) | 如 SpringBoot/Dubbo 微服务、Nginx 反向代理、前端静态服务、网关、RESTful API 等。这类服务多副本负载均衡、迭代频繁,是 Deployment 标准使用场景。 |
| ✅需要 7×24 在线、零停机发布的业务 | 互联网核心业务、C 端用户服务,不允许停机维护,依赖滚动更新实现无感发布。 |
| ✅流量波动大、需要弹性伸缩的服务 | 活动页面、秒杀接口、推送服务等,搭配 HPA(Horizontal Pod Autoscaler,Pod 水平自动扩缩器) 实现自动扩缩容,节约资源同时扛住峰值流量。 |
| ✅无状态中间件 & 消费端 | 如 MQ 消费端、日志转发程序、监控采集客户端、无状态 Redis 节点等。 |
| ✅测试 / 演示环境批量部署 | 快速拉起多套测试实例,一键重建、销毁,提升测试效率。 |
| 绝对不推荐使用 Deployment 的场景 | 说明 |
|---|---|
| ❌有状态应用(核心禁区) | 如 MySQL、PostgreSQL、MongoDB、ZooKeeper、etcd、主从架构组件。 特点:Pod 有固定身份、有序启停、需要稳定域名 / 网络标识、依赖本地持久化存储。 替代方案:StatefulSet。 |
| ❌节点级守护进程 | 要求每个集群节点上必须运行一个 Pod,如日志采集器 Filebeat、节点监控 Agent、网络组件。 替代方案:DaemonSet。 |
| ❌一次性定时 / 离线批处理任务 | 如数据备份、离线计算、脚本任务(任务跑完就主动退出)。 Deployment 会不断重启已完成任务的 Pod,造成资源浪费。 替代方案:Job(一次性任务)、CronJob(定时任务)。 |
| ❌需要主从选主、固定角色的集群 | 所有 Pod 完全等价,无法区分主节点、备节点,不适合集群选主架构。 |
1.4、Deployment的优缺点
| Deployment的优点 | 说明 |
|---|---|
| ✅上手简单、生态成熟 | 配置语法简洁,是 K8s 入门首选控制器,社区工具、监控、CI/CD 流水线均深度适配。 |
| ✅高可用 & 自愈能力强 | 容器、节点故障自动重建 Pod,从底层规避单点故障,大幅降低运维压力。 |
| ✅发布体验优秀 | 原生支持零停机滚动更新 + 版本回滚,线上发布、故障应急流程标准化。 |
| ✅弹性能力完善 | 原生支持手动扩缩,无缝对接 HPA 实现全自动弹性,适配各类流量场景。 |
| ✅资源复用性高 | 应用模板可在开发、测试、生产多环境复用,统一部署规范。 |
| ✅调度灵活 | 基于标签管理 Pod,配合节点亲和、污点、容忍等调度策略,灵活分配资源。 |
| Deployment的缺点 | 说明 |
|---|---|
| ❌仅支持无状态应用 | 天生不具备有状态服务所需的能力:无法提供固定主机名、稳定网络标识、有序启停、Pod 与存储一对一绑定,不能用于数据库、集群类有状态组件。 |
| ❌所有 Pod 身份完全一致 | 无法区分主 / 备、不同角色的实例,不适合需要节点角色划分的架构。 |
| ❌存储绑定能力弱 | Pod 重建后可能被调度到其他节点,无法固定 Pod 与本地存储 / 磁盘的对应关系,容易造成数据丢失。 |
| ❌复杂灰度发布能力不足 | 原生仅支持标准滚动更新,金丝雀发布、按比例流量灰度、地域灰度等复杂发布,需要额外配合 Service、Ingress、流量网关实现。 |
| ❌滚动更新存在小幅流量波动 | 更新过程中 Pod 数量动态变化,副本数极少时可能出现短暂负载不均;且发布耗时长于蓝绿发布。 |
| ❌历史版本有上限 | 默认最多保留 10 个历史 Revision,版本过多会占用集群 etcd 存储,需要手动清理或调整保留数量。 |
| ❌不适合短生命周期任务 | 一旦 Pod 正常执行完毕退出,Deployment 会反复重启 Pod,资源利用率极低。 |
二、Deployment
2.1、Deployment的执行状态解析
| Deployment执行状态 | 说明 |
|---|---|
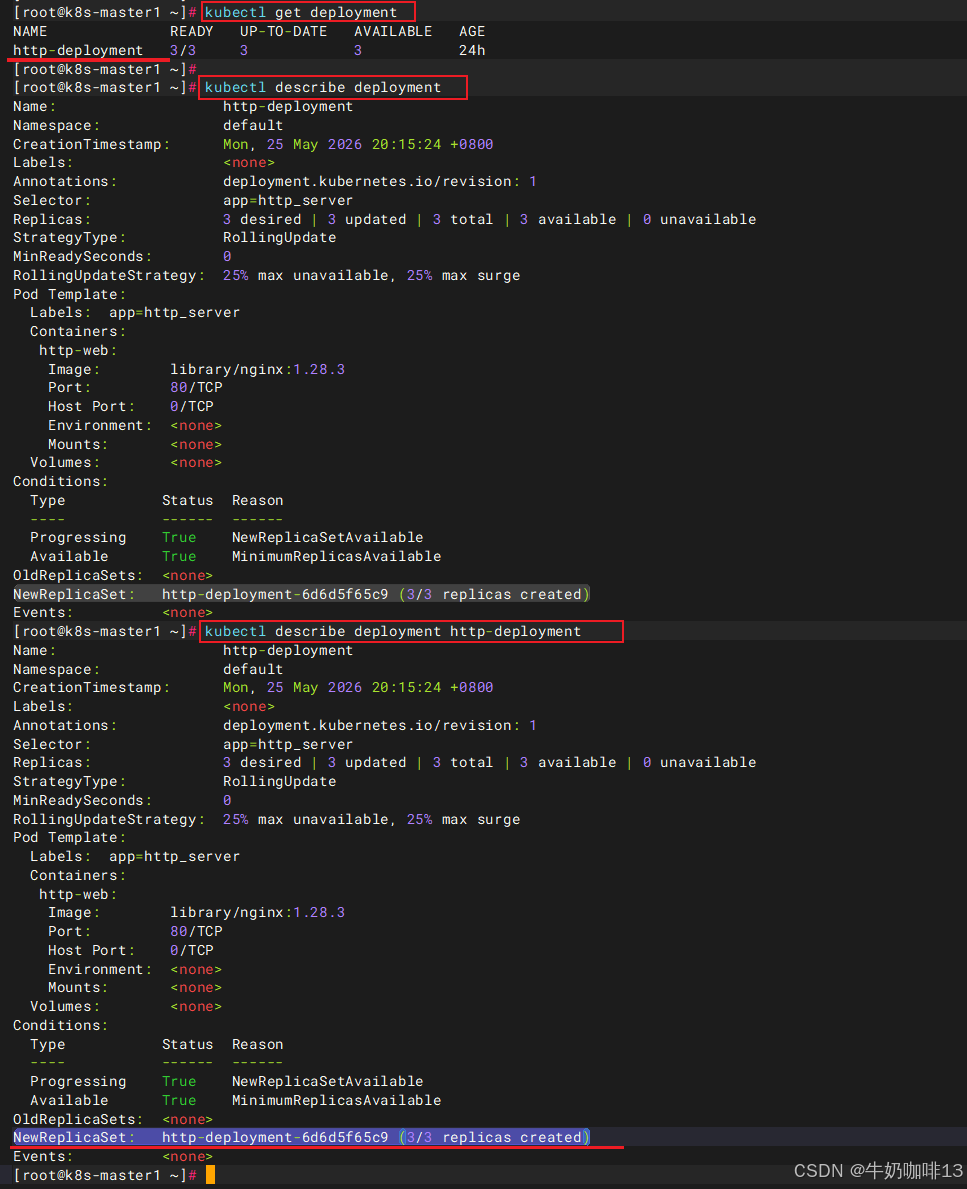
| 查看deployment状态 | kubectl get deployment 该命令可查看到k8s集群中的所有deployment内容,且可知道每个deployment的副本情况(即:共指定了几个副本,几个副本在线,几个副本可用) |
| 查看指定deployment的详情 | kubectl describe deployment http-deployment 该命令可直接查看名为【http-deployment】内容的详情,在命令倒数第二行可以看到【NewReplicaSet: http-deployment-6d6d5f65c9 (3/3 replicas created)】内容,因此可以知道Deployment是通过 ReplicaSet 来管理 Pod 的 |
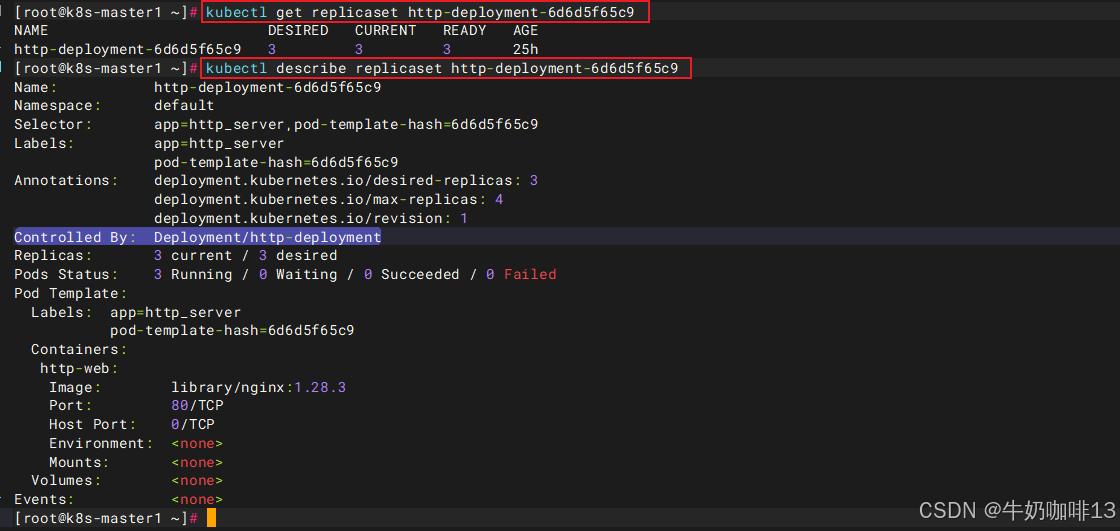
| 查看指定ReplicaSet状态 | kubectl get replicaset http-deployment-6d6d5f65c9 该命令可直接查看名为【http-deployment-6d6d5f65c9】的replicaset的状态信息 |
| 查看指定ReplicaSet的详情 | kubectl describe replicaset http-deployment-6d6d5f65c9 该命令可直接查看名为【http-deployment-6d6d5f65c9】的replicaset的详细信息,从输出可以看出,Controlled By指明此 ReplicaSet 是由 Deployment http-deployment创建。Events记录了3个副本 Pod的创建。 |
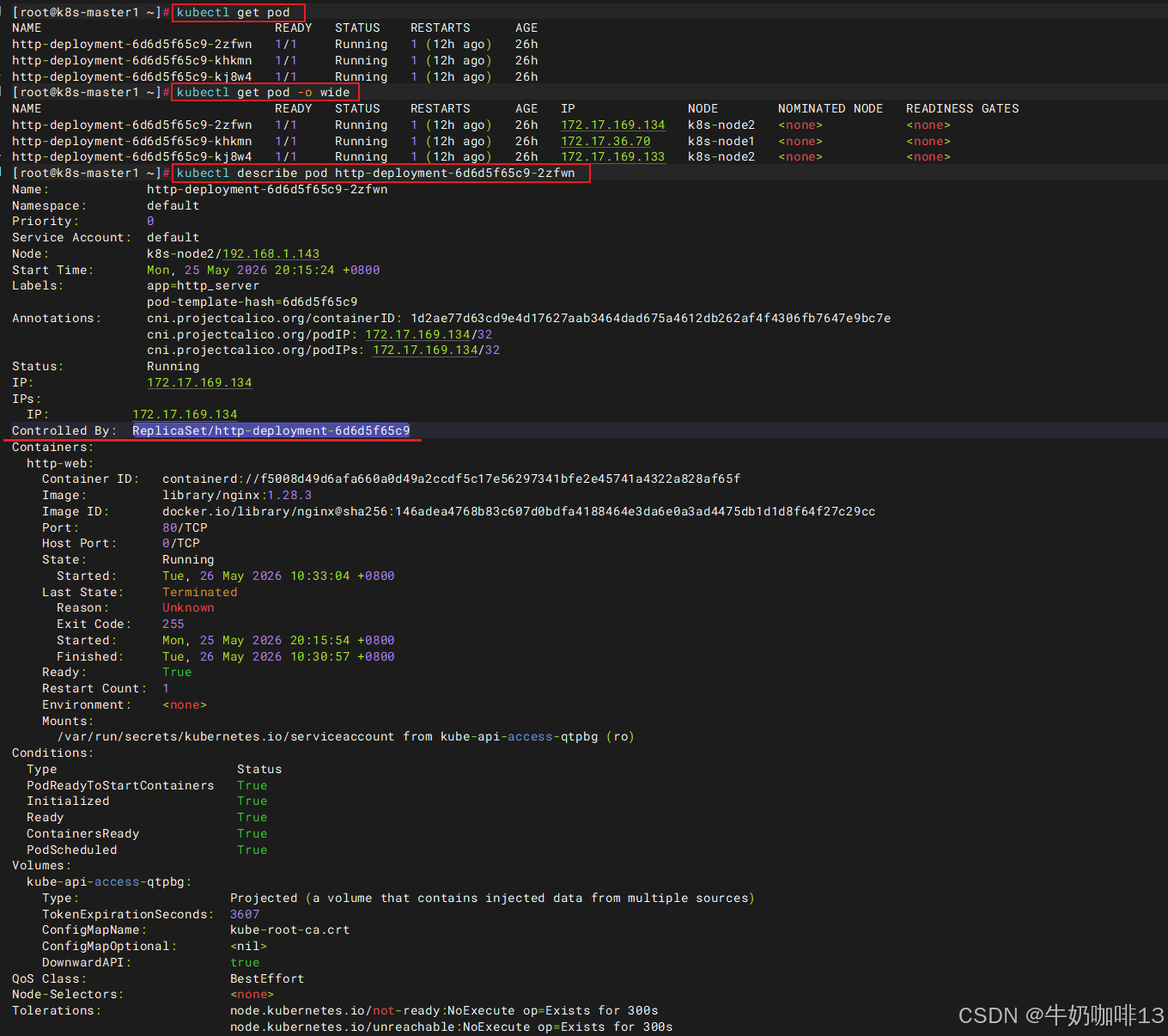
| 查看pod的状态 | kubectl get pod 该命令可查看到所有pod节点及其相应的基础状态信息 kubectl get pod -o wide 该命令可查看到所有pod节点及其相应的详细状态信息 |
| 查看指定pod的详情 | kubectl describe pod http-deployment-6d6d5f65c9-2zfwn 该命令可查看到指定pod的详细信息(输出结果中Controlled By指明此Pod 是由ReplicaSet/http-deployment-6d6d5f65c9创建。最后的Events记录了Pod的启动过程) 注意:若操作失败(如 image 不存在),也能从这里也能查看到失败的原因。 |
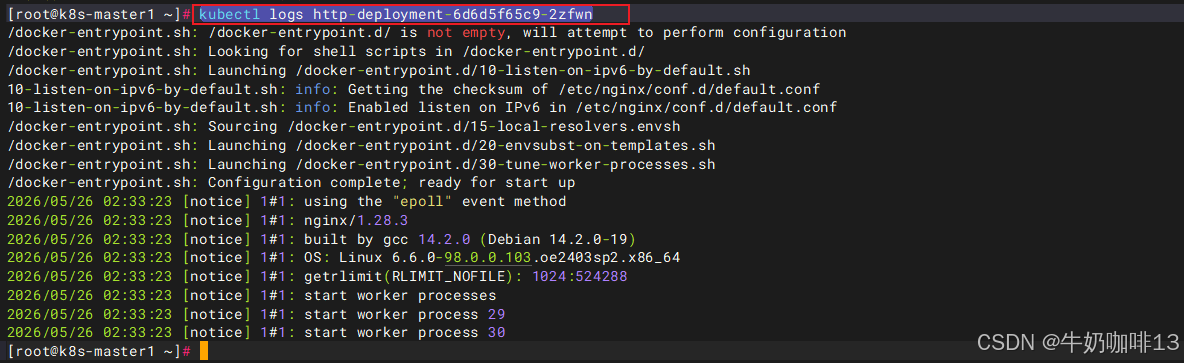
| 查看指定pod的日志排查问题 | kubectl logs http-deployment-6d6d5f65c9-2zfwn |
总结一下deployment实现的过程:
- 首先用户通过 kubectl 创建 deployment。
- 接着,deployment 创建 ReplicaSet。
- 然后,ReplicaSet 创建 Pod
- 最后,pod在每个节点上通过kubelet调用docker完成容器创建。
可以看出,对象的命名方式是:子对象的名字 = 父对象名字 + 随机字符串或数字。
2.2、k8s中创建资源的方式
2.2.1、基于命令行方式创建
- 简单直观快捷,上手快;
- 适合临时测试或实验;
注意:从1.18版本之后,k8s已经不支持在命令行中通过参数指定资源的属性。这种方式已经基本废弃(--replicas参数已弃用,k8s推荐用deployment创建 pods)。
bash
#直接用kubectl命令直接创建资源
kubectl run nginx-deployment --image=library/nginx --port=80
#查看当前所有的pod
kubectl get pod
#删除指定名称的pod
kubectl delete pod nginx-deployment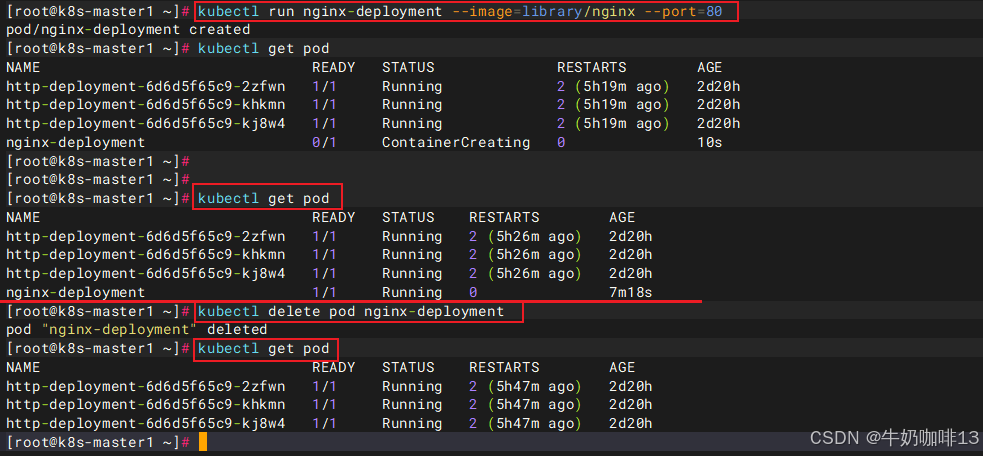
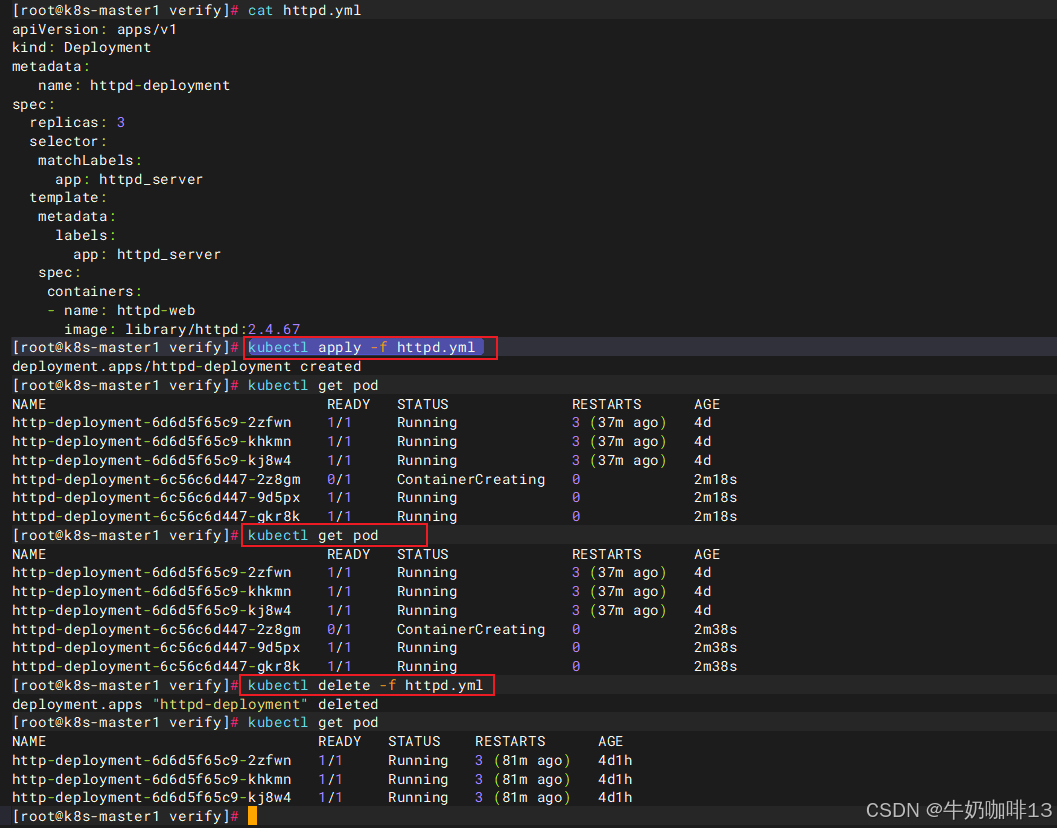
2.2.2、通过配置文件和kubectl apply命令创建资源【推荐使用】
bash
#通过配置文件和kubectl apply命令创建资源
#1-创建资源文件
cat > httpd.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
spec:
replicas: 3
selector:
matchLabels:
app: httpd_server
template:
metadata:
labels:
app: httpd_server
spec:
containers:
- name: httpd-web
image: library/httpd:2.4.67
EOF
#2-创建指定资源
kubectl apply -f httpd.yml
#查看当前所有pod状态
kubectl get pod
#3-删除指定资源
kubectl delete -f httpd.ymlkubectl apply不但能够创建 Kubernetes资源,也能对资源进行更新,非常方便。不过Kubernets还提供了几个类似的命令(如:kubectl create、kubectl replace、kubectl edit 和 kubectl patch。但 kubectl apply命令已经能够应对超过 90% 的场景)。
| deployment资源文件内容 | 说明 |
|---|---|
| apiVersion | 当前配置格式的版本(先执行kubectl api-resources找到所有的资源,再执行命令 kubectl explain deploy即可获取到版本和类型信息) |
| kind | 要创建的资源类型,这里是Deployment。 |
| metadata | 该资源的元数据,name是必需的元数据项,后面名字任意起一个即可。 |
| 第一个spec | 第一个spec部分是该Deployment的规格说明 |
| replicas | 指明副本数量,默认为 1,这里指定为3。 |
| selector | 是个选择器, matchLabels是个匹配标签, 在发布Service时,selector需要和这里对应。 |
| template | 定义Pod的模板,这是配置文件的重要部分。 |
| metadata | 定义Pod的元数据,至少要定义一个label。label的key和value可以任意指定。 |
| 第二个spec | 第二个spec描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。 注意:最后name前面需要加个中杠,是因为container后面是一个列表。 |
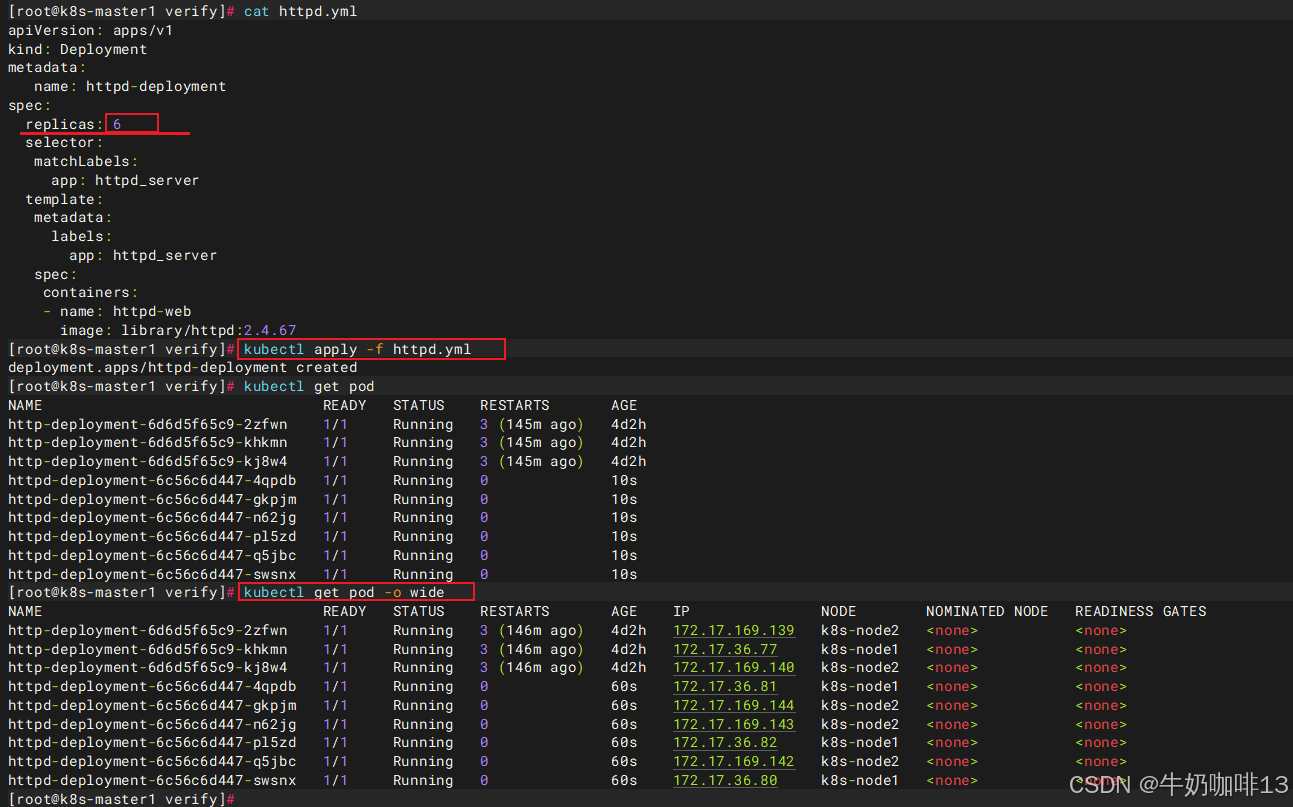
2.2.3、增加pod副本数
修改httpd.yml文件,将副本数从3增加到6,然后查看pod状态,如下图所示:
2.2.4、减少pod副本数
修改httpd.yml文件,将副本数从6减少到3,然后查看pod状态,如下图所示:
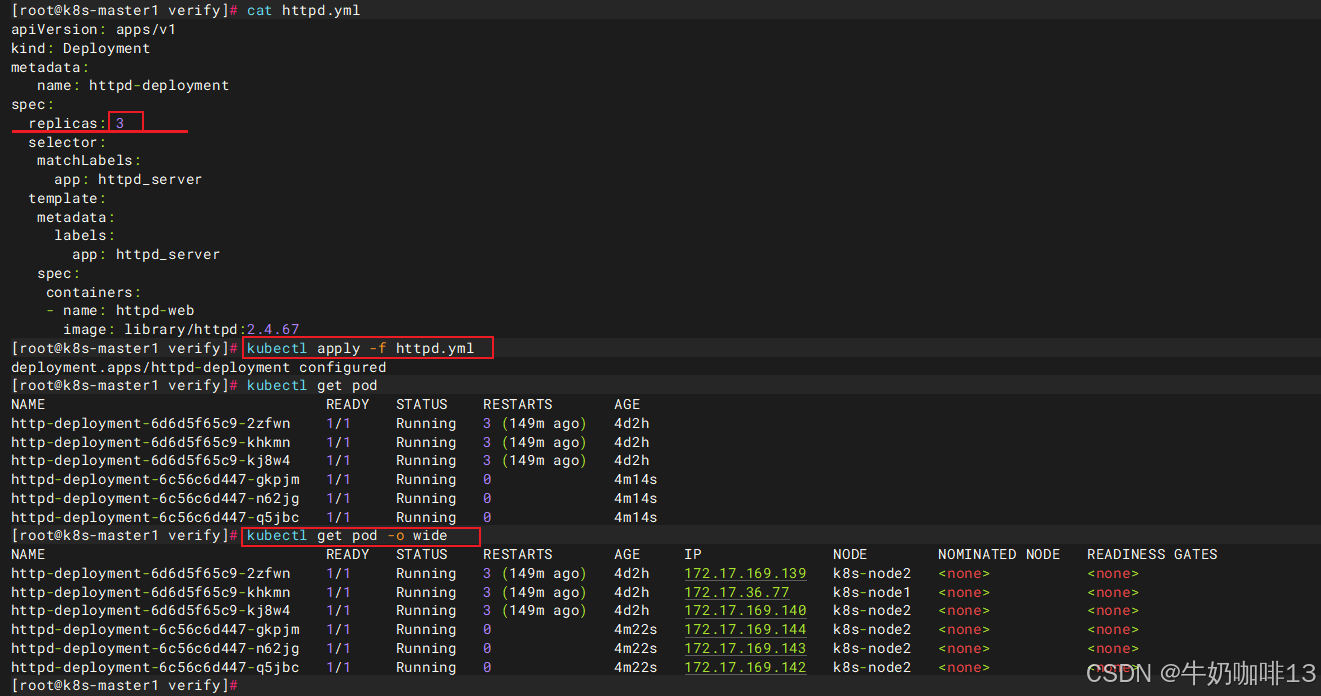
2.2.5、node节点故障时pod切换
现在有3 个 httpd副本分别运行在node2 上,如下图所示:
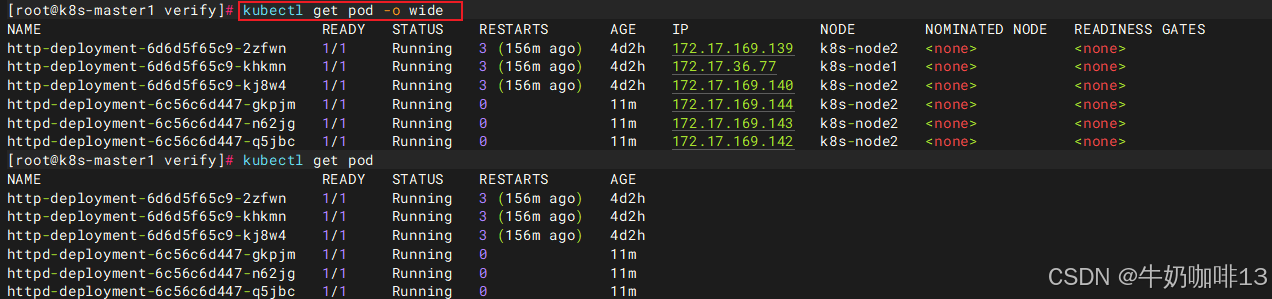
现在模拟 node2故障(即:关闭该节点服务器),然后查看pod状态,如下图所示:
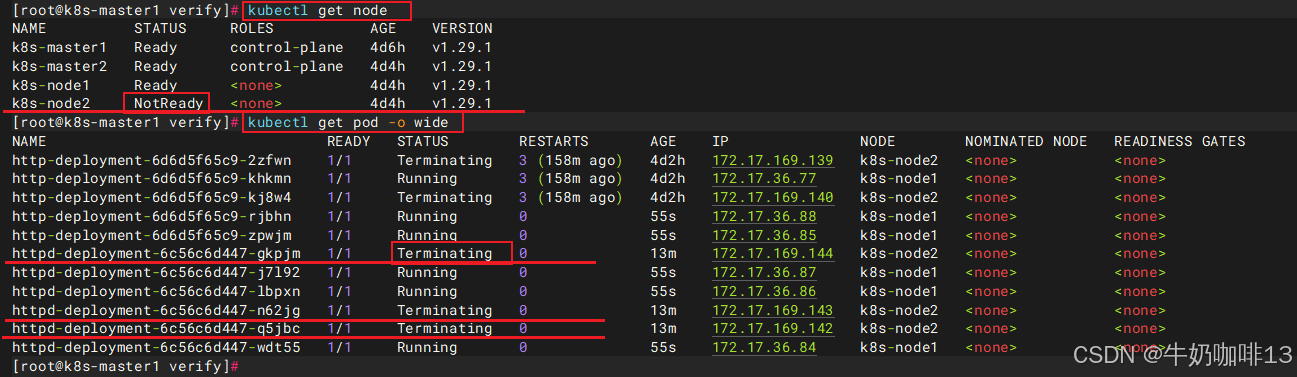
可以发现node2状态为NotReady,等待一段时间,Kubernetes会检查到node2不可用,将node2上的 Pod 标记为 Terminating状态,并在node1上新创建两个Pod,维持总副本数为3。
当 node2恢复后, Terminating的 Pod 会被删除,不过已经在node1上运行的 Pod 不会重新调度回node2。
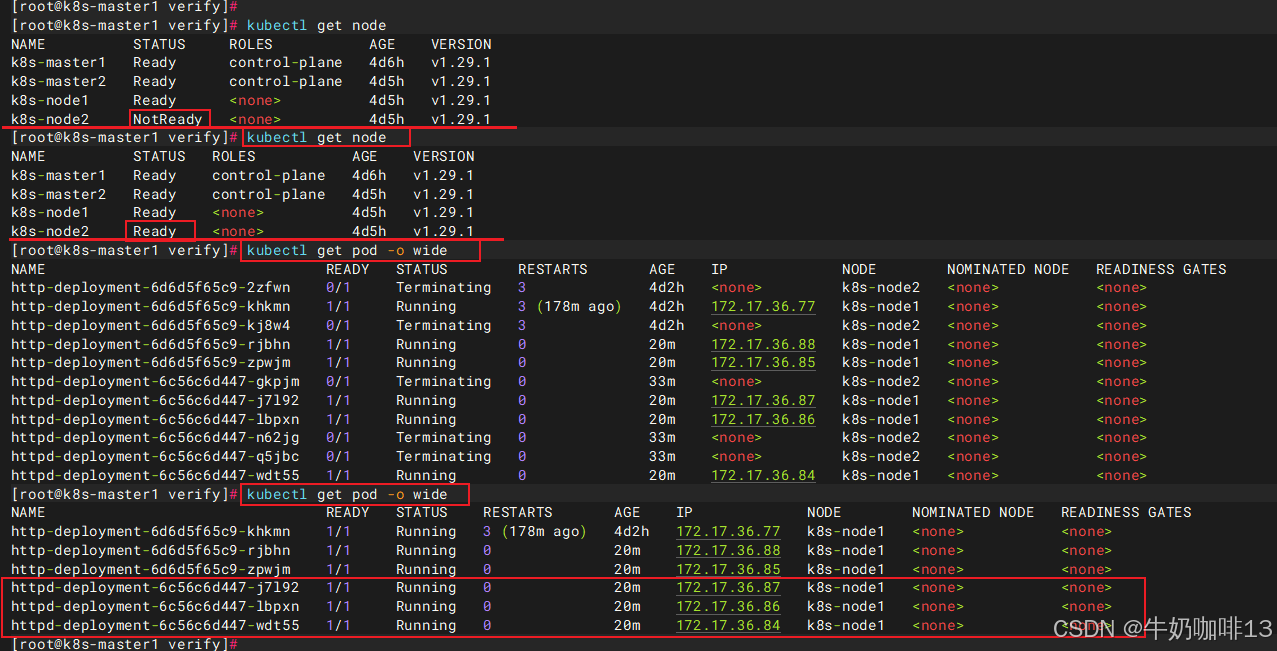
三、通过label 控制 Pod 的位置
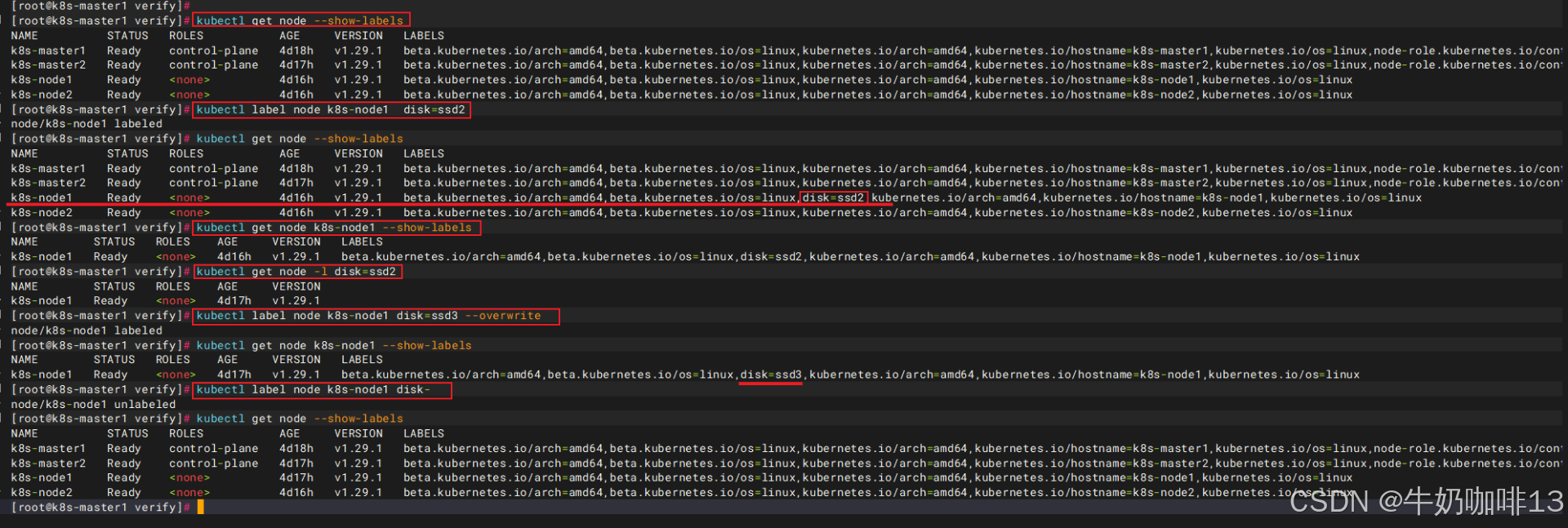
默认配置下,Scheduler 会将 Pod 调度到所有可用的 Node。不过有些情况希望将 Pod 部署到指定的 Node(如:将有大量磁盘I/O的Pod部署到配置了SSD的Node节点上;或者Pod需要GPU,需要运行在配置了GPU的节点上)。k8s是通过label来实现这个功能的。label是key-value 对,各种资源都可以设置label,灵活添加各种自定义属性。
bash
#将pod指定到对应的node节点上
#标注k8s-node1是配置了SSD磁盘的节点
kubectl label node k8s-node1 disk=ssd2
#查看所有节点的全部标签
kubectl get node --show-labels
#查看指定节点的标签
kubectl get node k8s-node1 --show-labels
#通过标签筛选节点(如:只列出带有disk=ssd2标签的节点)
kubectl get node -l disk=ssd2
#修改已存在的标签(如:将disk标签值改为ssd3)
kubectl label node k8s-node1 disk=ssd3 --overwrite
#删除指定节点标签(如:删除k8s-node1节点上的disk标签)
#标签删除之后,Pod 并不会重新部署,依然会在node1上运行。要改变Pod运行的节点,需要修改nodeSelector设置,然后通过 kubectl apply 重新部署即可。
kubectl label node k8s-node1 disk-
#一条命令添加多个标签(使用空格分隔多个key=value)
kubectl label node k8s-node1 disk=ssd2 env=prod arch=x86| kubectl label node k8s-node1 disk=ssd2命令解析 | 说明 |
|---|---|
| kubectl | Kubernetes 官方命令行客户端,集群操作入口 |
| label | kubectl 子命令,专门用来新增 / 修改 / 删除 资源标签 (Label) |
| node | 操作的资源类型,此处目标是集群节点 (Node) |
| k8s-node1 | 目标节点名称(需与 kubectl get nodes 查到的节点名完全一致) |
| disk=ssd2 | 标签键值对 * 标签键:disk * 标签值:ssd2 注意: 《1》集群节点多、业务复杂时,提前约定规则( * 格式:磁盘类型_容量_编号 * 示例:nvme_1t_01、ssd_2t_02 ); 《2》保持格式统一,不要混用多种写法(如:不要同一类磁盘一会儿写 ssd2、一会儿写 ssd_2,避免标签筛选失效); 《3》结合标签用途(磁盘类型、硬件、环境、角色等)取语义清晰、格式统一的值,不要随意写无意义字符。 《4》标签值不能使用大写、空格、中文、特殊符号。 |
bash
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpd-deployment
spec:
replicas: 3
selector:
matchLabels:
app: httpd_server
template:
metadata:
labels:
app: httpd_server
spec:
containers:
- name: httpd-web
image: library/httpd:2.4.67
# 节点选择器:绑定 disk=ssd2 标签节点
nodeSelector:
disk: ssd2