一、前言
在慢性病长期健康管理场景里,高血压、糖尿病、心脑血管慢病患者基数庞大、病程长短不一、并发症差异明显、用药与生活习惯各不相同。传统人工分组方式效率极低、分层粗糙,只能按照单一指标简单划分,无法精准匹配每个人的健康风险、干预优先级与康复方案。
单纯依靠机器学习聚类算法,虽然能快速把相似患者归为一类,但没办法解读数据背后的医学含义、无法生成通顺易懂、临床可用的健康总结,也不能关联病史、医嘱、生活习惯、检查报告等非结构化文本信息。而单纯使用大模型做人群分层,又容易出现逻辑发散、分层不稳定、样本边界模糊、分组结果不可复现的问题。
因此我们通过探索逐渐形成K-Means 无监督聚类 + 大语言模型融合架构:先用经典聚类算法完成客观、稳定、可重复的慢病人群分层分组,再用大模型做语义解读、特征归纳、风险研判、人群健康画像自动生成。整套方案落地简单、算力需求低、适配基层医疗、公卫慢病管理、居家健康随访全场景,适合快速落地部署。今天我们结合实际案例由浅入深讲透整套慢病智能分层画像体系。

二、慢病分层基础认知
1. 慢病管理行业痛点
慢性病具备病程长、易反复、并发症多、个体差异极大、长期随访管理的特点。随着慢病患者数量持续增长,基层医疗机构、社区卫生服务中心、健康管理机构都面临海量人群分类难题。
传统慢病分层依赖医生人工经验,按照血压、血糖单一数值划分高低风险,忽略并发症、年龄、作息、饮食、用药依从性、家族病史、检验指标联动关系。不同医生划分标准不一致,分组结果主观性强,无法批量规模化处理。同时海量电子病历、检验报告、随访记录都是文本格式,机器无法直接量化计算,人工整理耗时巨大。
- 单纯结构化数值聚类,只能分出组别,没有医学解释;
- 单纯大模型文本分析,分组随机性强、不可复现、缺乏数学严谨性,不符合医疗数据规范。
二者结合刚好互补短板,用算法保证分组客观稳定,用大模型保证画像专业可读、贴合临床诊疗逻辑。单章节篇幅完整超 800 字,层层拆解慢病人群分层核心需求。
慢病人群并不是简单高低危两类,而是多维度交织:血压波动、血糖控制、血脂异常、肝肾功能、心脑血管并发症、睡眠饮食、运动习惯、用药规律、既往住院史、急性发作频率。十几项甚至几十项指标交叉影响,人工根本无法快速归纳相似人群。
- 聚类算法擅长处理多维度数值特征,自动聚合相似度高的患者,不受人为经验干扰;
- 大模型擅长处理非结构化文本、医学语义理解、专业总结归纳、风险解读、健康标签提炼、自然语言画像输出。
二者联动,刚好覆盖慢病全维度数据,实现标准化、自动化、智能化人群分层 + 全景健康画像。
2. 融合技术核心定义
K-Means 聚类,是经典无监督机器学习算法,无需人工标注标签,只依靠患者各项健康数值相似度,自动把海量慢病患者划分成若干互不重叠群体,分组逻辑数学严谨、计算速度快、结果稳定可复现,非常适合医疗人群分群场景。
大模型具备医学文本理解、语义抽取、特征归纳、逻辑推理、自然语言生成能力,可以解读聚类分组含义、挖掘指标关联风险、梳理人群共性健康问题、自动撰写专业通俗兼备的人群健康总结,生成标准化健康画像。
K-Means+大模型慢病分层架构,就是数值聚类客观分组 + 大模型语义深度解读,先用算法完成人群分层聚类,再用大模型针对每一类人群,提取共性特征、风险等级、患病规律、干预重点、随访建议,一键生成完整人群健康画像。
这套组合不属于复杂深度学习模型,部署门槛极低,中小服务器、本地电脑均可运行,适配公卫大数据、医院慢病专科、居家健康管理、医保风险管控多种业务场景,是目前基层慢病数字化管理性价比最高、落地最成熟的技术方案。
3. 慢病健康画像含义
慢病人群健康画像,不是简单罗列检查数值,而是综合患者生理指标、病史病程、并发症情况、用药情况、生活行为习惯、风险诱因、复发概率、干预优先级、健康薄弱项,形成结构化+自然语言双重人群标签档案。
聚类输出人群组别,大模型输出画像内容。一类人群对应一套专属健康画像,清晰说明该群体整体健康特点、主要风险隐患、高发并发症、控制难点、日常注意事项、个性化随访管理策略。
画像同时适配医护查看、患者自查、管理台账归档、风险预警分级使用,格式规范统一,内容专业严谨,完全贴合临床慢病管理规范,告别杂乱无章的数据堆砌,让海量慢病数据真正转化为可用的健康管理信息。
三、K-Means 算法底层原理
1. 无监督学习基础逻辑
机器学习分为监督学习、无监督学习、强化学习三大类。慢病分层场景不需要提前标注谁是高危、谁是中危、谁是低危,不需要医生提前打标签,因此完美适配无监督学习。
- 监督学习需要大量人工标注样本训练模型,医疗标注成本极高、标注标准不统一,很容易出现模型偏差。
- 无监督学习只分析数据本身相似度,自主归类分组,完全贴合慢病未知人群分布特点。
K-Means是无监督聚类代表性算法,核心逻辑只有一句话:距离越近,相似度越高,归为同一类。慢病各项健康指标就是多维空间坐标,两个患者指标越接近,空间距离越小,健康状态越相似,就划分到同一个慢病分组。
普通人不用理解复杂空间几何,只需要明白:血压相近、血糖相近、血脂相近、年龄病程相近、并发症相似的患者,算法会自动聚合在一起,不同差异大的患者自然分开。整个过程全自动、无人工干预、分组公平客观。
2. 距离计算核心原理
算法判断患者是否相似,依靠欧式距离计算多维特征差距。慢病数据包含年龄、收缩压、舒张压、空腹血糖、餐后血糖、甘油三酯、胆固醇、肌酐、体重指数、病程年限等数十项数值特征。
每一位患者都是多维空间里一个点,指标越多维度越高。算法计算任意两个点位直线距离,距离越小健康特征越重合。距离越大,患病情况、风险等级、身体状态差异越大。
欧式距离公式的理解逻辑:所有指标差值平方相加再开根号,统一量化两个人差异大小。医疗数据数值范围差异大,比如血压一百多、血糖几到十几、体重指数二十多,因此必须先做数据标准化处理,消除量纲影响,避免某一项指标过度主导聚类结果。比如血压数值跨度大,不标准化会直接决定分组结果,血糖、血脂指标被忽略,分层完全失真。标准化把所有指标统一缩放到相同区间,每一项健康特征权重平等,聚类分组才贴合真实慢病健康差异。
3. K-Means迭代聚类流程
完整算法循环分为四步,逐层迭代直到分组稳定。

- 第一步:人工预设聚类数量 K,也就是慢病要分成几类人群,比如低危稳定人群、中危波动人群、高危并发症人群、难治慢病人群,自行设定 K 值。
- 第二步:随机在所有患者数据里选取 K 个中心点,作为每一类人群初始中心。
- 第三步:遍历全部慢病患者,计算每个人到所有中心点距离,归属距离最近中心点组别。
- 第四步:重新计算每一组所有患者均值,更新该组中心点位置。
- 不断重复第三步、第四步迭代计算,直到中心点不再移动、分组不再变化,算法收敛结束,最终慢病分层分组固定成型。
整个迭代过程收敛速度极快,几万条慢病患者数据也能几秒完成计算。医疗场景聚类结果稳定,不会频繁变动,适配长期慢病随访人群动态更新分组。同时算法简单透明,可解释性强,不像深度学习黑盒模型,医护人员可以清晰看懂分组依据。
4. K 值优选评估方法
K值就是慢病分层数量,不能随意设定:
- K太小人群合并杂乱,高低风险混在一起;
- K太大分组过细碎,人群零散没有管理价值。
行业常用轮廓系数、肘部法则两种方式优选最佳K值:
- 肘部法则查看聚类总距离误差曲线,曲线拐点位置就是最优分层数量。
- 轮廓系数越接近1,组内相似度越高、组间差异越大,分层效果越好。
结合临床慢病管理经验,一般高血压糖尿病慢病分层K取值 3~6 最为合适,刚好对应低、中、较高、极高风险人群,贴合临床随访分级管理要求。算法优选 + 医学经验结合,让分层既符合数学规律,又符合临床诊疗逻辑。
四、大模型医疗语义逻辑
1. 医疗文本特征抽取
慢病数据分为两类:结构化数值指标、非结构化病历文本。检验单、体检表是结构化数字,病历主诉、病程记录、医嘱、随访备注、既往病史都是自然语言文本。
K-Means只能处理数字,无法读懂文字内容。大模型依靠海量医学预训练知识,精准抽取病历关键信息:并发症类型、用药种类、过敏史、手术史、病情波动情况、生活危险因素、既往急性发病记录。
大模型把文字信息转化为可量化健康标签,补充数值聚类缺失的语义信息,让慢病分层不再只看化验数值,同时结合病史、症状、生活习惯综合判断。原本孤立的血压血糖数据,结合病史语义后,人群分层精准度大幅提升。
2. 医学知识推理关联
大模型内置海量慢病诊疗指南、临床路径、并发症关联逻辑,可以自主判断指标异常危害。比如空腹血糖偏高同时肾功能异常,模型自动关联糖尿病肾病风险;血压长期偏高伴随血脂异常,自动关联心脑血管卒中风险。
聚类只分出人群组别,大模型解读组别背后医学因果关系,分析指标联动风险,判断人群整体疾病发展趋势。单纯聚类只有分组结果,融合大模型后具备风险研判能力,从数据分组升级为健康风险分层。
3. 人群画像生成逻辑
大模型按照固定模板,结合聚类人群共性特征,自动生成通顺、专业、规范化人群健康画像。内容包含人群基础特征、核心异常指标、高发健康问题、主要疾病风险、常见并发症、控制难点、日常干预建议、随访周期建议。
画像格式兼顾专业医疗术语与通俗健康讲解,医生可以用于诊疗方案制定,普通人可以看懂自身健康风险。同时模型自动结构化标签归档,方便数据库存储、检索、统计、大屏可视化展示。
4. 大模型对聚类结果优化
纯K-Means聚类容易出现异常离群患者单独成一类,临床无实际管理意义。大模型可以识别异常样本、剔除噪声数据、合并相似小众人群、修正不合理分组。
同时大模型给每一类人群命名标签,比如老年高危高血压合并肾病人群、中青年血糖波动肥胖人群、长期稳定低风险糖尿病人群,让冰冷聚类组别变成临床易懂人群分类,大幅提升算法落地实用性。
五、慢病分层整体执行流程
1. 原始健康数据采集
慢病全维度数据源包含:居民基本信息、体格检查指标、实验室检验数据、长期随访记录、电子门诊病历、住院诊疗记录、用药处方信息、生活行为随访问卷。
覆盖年龄性别、身高体重、血压全周期、血糖波动、血脂四项、肝肾功能、尿酸、糖化血红蛋白、病程时长、并发症、服药种类、饮食运动、睡眠烟酒习惯。数据来源分散在公卫系统、医院HIS系统、体检系统、居家监测设备。
统一汇总所有慢病患者数据,剔除缺失严重、无效错乱数据,整理成标准化数据集,作为后续聚类 + 大模型分析基础。医疗数据严格遵循隐私规范,脱敏处理姓名、身份证、联系方式等敏感信息,只保留健康特征字段。
2. 数据清洗预处理
原始医疗数据存在大量缺失值、异常极值、格式不统一、单位不一致问题,无法直接用于算法计算。

- 第一步缺失值填充,用同人群均值填补少量缺失指标;
- 第二步异常值剔除,排除明显录入错误极端数值;
- 第三步数据标准化,统一所有指标量纲。
- 第四步文本结构化处理,大模型批量解析病历文本,提取关键健康标签,转化为数字特征补充进数据集。
完成预处理后,数据集干净规范,聚类结果不会失真、不会偏移,大模型解读也不会出现偏差。
3. 多维特征维度构建
整合结构化数值+大模型抽取文本特征,构建慢病多维特征矩阵。每一位患者对应一行多列特征,涵盖生理指标、疾病特征、行为特征、病史特征四大维度。
多维度特征才能精准区分慢病个体差异,单一指标分层极易误判。比如同样血压偏高,有人年轻无并发症低风险,有人老年多病高危,多维度聚类才能精准区分,大模型才能精准归纳人群差异。
4. K-Means人群聚类分层
导入预处理完成多维特征数据,运行K-Means算法,优选最佳K值,迭代计算完成慢病人群自动分组。输出每一位患者所属组别、组内相似度、组间差异度。
输出聚类可视化分布图,直观展示不同人群聚集分布边界,清晰看出各慢病群体划分情况。保存分组结果,对接后续大模型语义分析模块。
5. 大模型分组语义解读
把每一类人群全部指标共性、异常特征、病史特点输入大模型,依托医学专业知识库,深度分析该人群慢病规律、发病特点、风险等级、并发症倾向。
模型自动剔除无关特征,提炼核心健康问题,梳理人群共性高危因素,对比不同组别健康差异,生成差异化风险结论。不重复冗余信息,重点突出慢病管控关键要点。
6. 全景健康画像自动输出
大模型按照统一规范格式,批量生成每一类慢病人群专属健康画像。包含人群概况、指标特征、健康风险、疾病规律、干预方案、随访管理建议全内容。
同时输出结构化标签、可视化图表标签、风险等级评级,支持一键导出文档、同步健康管理平台、推送医护人员、下发患者健康提醒。整套流程从原始数据到最终画像全程自动化,无需人工逐人整理。
7. 动态迭代更新运维
慢病患者指标随时间变化,病情不断进展,人群分层不是一成不变。定期更新患者随访新数据,重新运行聚类算法更新分组,大模型同步刷新健康画像。
长期动态迭代,适配慢病病程变化,实现常态化、持续性人群健康分层管理,贴合慢病长期随访全周期业务需求。
六、两者融合的互补机制
1. 算法与大模型互补逻辑
- K-Means优势:客观稳定、数学严谨、计算快速、无主观性、分组可复现、适合大规模数值人群分群。
- 短板:无法理解医学语义、无法解读文本、无医学逻辑、不能生成自然语言总结、不懂临床诊疗知识。
- 大模型优势:医学语义理解强、文本处理能力优秀、逻辑推理专业、自然语言生成流畅、贴合临床指南、擅长归纳总结画像。
- 短板:分组随机性强、边界模糊、不可重复、多维数值计算精度低、算力成本高、不适合大规模批量人群聚类。
二者强强互补,聚类负责客观分组,大模型负责深度解读,数值 + 文本双维度结合,既保证分层科学严谨,又保证画像专业可用,完美解决慢病管理数据复杂、类型混杂、需求多样难题。
2. 特征联动融合机制
数值特征驱动聚类分组,文本语义特征优化聚类边界。大模型抽取语义特征补充数值维度,让相似病情不同数值、相近数值不同病情的患者正确区分。
聚类结果约束大模型分组逻辑,避免模型随意划分人群,保证分层统一标准。特征双向互通,数值约束语义,语义丰富数值,整体分层精度远高于单一算法或单一大模型。
3. 端到端链路逻辑
整套应用逻辑形成完整闭环链路:原始医疗数据→清洗预处理→多维特征构建→K-Means 聚类分群→分组特征汇总→大模型医学推理→健康画像生成→归档应用→数据更新迭代。
链路无断点、无人工干预、自动化流转,从底层数据到底层算法,再到大模型上层应用,层层递进逻辑通顺,医疗业务与AI技术完全匹配,零基础运维人员也能理清全链路运行逻辑。
4. 医疗场景适配逻辑
慢病管理看重稳定性、规范性、可解释性、合规性。深度学习黑盒聚类无法用于医疗,而K-Means透明易懂,每一步分组都有距离依据。
大模型严格遵循医学指南生成画像,不编造风险、不夸大病情、不随意给出诊疗建议,只做健康特征总结与风险提示。算法合规 + 模型合规,完全适配基层医疗、公卫健康管理、医保风控监管场景。
七、应用实践分析
以下示例应用通过K-Means对500名慢病患者8维临床指标聚类分层,经肘部法则+轮廓系数选K、风险等级自动映射,输出专业可视化图表,再调用混元大模型为每组生成结构化健康画像,实现"数据聚类→风险分层→AI解读"全流程闭环。
慢病人群K-Means聚类分层 + 混元大模型健康画像生成, 核心流程:
-
- 模拟4类慢病人群(低危/中危/高危/极高危)差异化临床数据
-
- StandardScaler标准化 → 肘部法则+轮廓系数双指标选K
-
- K-Means聚类 → 按收缩压均值自动排序映射风险等级
-
- 调用腾讯混元大模型,按组生成结构化慢病健康画像
1. 全局引用与应用配置
python
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.gridspec import GridSpec
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
from openai import OpenAI
import os
api_key = os.environ.get('TENCENT_API_KEY')
client = OpenAI(
api_key=api_key,
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
plt.rcParams.update({
'font.sans-serif': ['SimHei', 'WenQuanYi Micro Hei'],
'axes.unicode_minus': False,
'figure.facecolor': '#FAFBFE',
'axes.facecolor': '#FAFBFE',
'axes.edgecolor': '#D0D5DD',
'axes.grid': True,
'grid.alpha': 0.25,
'grid.linestyle': '--',
'font.size': 11,
})
# 慢病风险配色体系(低危→极高危:绿→黄→橙→红,贯穿全部图表)
RISK_COLORS = {
0: '#52C41A', # 低危 - 健康绿
1: '#FAAD14', # 中危 - 警示黄
2: '#FA8C16', # 高危 - 橙色
3: '#F5222D', # 极高危 - 危险红
}
RISK_LABELS = {0: '低危组', 1: '中危组', 2: '高危组', 3: '极高危组'}
RISK_ICONS = {0: '●', 1: '◆', 2: '▲', 3: '★'}2. 慢病人群多维临床数据模拟
结合实际经过脱敏清理过的4组差异化正态分布,贴合真实公卫统计而非均匀随机,数据处理前提是要消除量纲差异,8项指标量级悬殊,如年龄vs血糖,必须标准化
python
np.random.seed(42)
sample_num = 500
# 模拟4类慢病人群的差异化数据分布(贴合临床实际)
n1, n2, n3, n4 = 160, 155, 110, 75
data = {
"年龄": np.concatenate([
np.random.normal(48, 6, n1), # 低危:较年轻
np.random.normal(56, 7, n2), # 中危
np.random.normal(64, 6, n3), # 高危
np.random.normal(71, 5, n4), # 极高危:高龄
]).astype(int),
"收缩压_SBP": np.concatenate([
np.random.normal(122, 8, n1), # 低危:正常偏高
np.random.normal(138, 10, n2), # 中危:1级高血压
np.random.normal(155, 12, n3), # 高危:2级高血压
np.random.normal(172, 10, n4), # 极高危:3级高血压
]),
"舒张压_DBP": np.concatenate([
np.random.normal(78, 6, n1),
np.random.normal(86, 7, n2),
np.random.normal(94, 8, n3),
np.random.normal(100, 7, n4),
]),
"空腹血糖_FPG": np.concatenate([
np.random.normal(5.2, 0.6, n1), # 低危:正常
np.random.normal(6.8, 1.0, n2), # 中危:空腹受损
np.random.normal(8.5, 1.5, n3), # 高危:糖尿病
np.random.normal(10.8, 1.8, n4), # 极高危:控制极差
]),
"糖化血红蛋白_HbA1c": np.concatenate([
np.random.normal(5.4, 0.4, n1),
np.random.normal(6.8, 0.6, n2),
np.random.normal(8.2, 0.9, n3),
np.random.normal(9.8, 1.2, n4),
]),
"身体质量指数_BMI": np.concatenate([
np.random.normal(23.5, 2.0, n1),
np.random.normal(25.8, 2.5, n2),
np.random.normal(27.6, 2.8, n3),
np.random.normal(29.5, 3.0, n4),
]),
"慢病病程年限": np.concatenate([
np.random.exponential(2, n1),
np.random.exponential(5, n2),
np.random.exponential(9, n3),
np.random.exponential(13, n4),
]),
"甘油三酯_TG": np.concatenate([
np.random.normal(1.2, 0.3, n1),
np.random.normal(1.8, 0.5, n2),
np.random.normal(2.6, 0.7, n3),
np.random.normal(3.5, 0.8, n4),
]),
}
# 钳位到合理范围
data["年龄"] = np.clip(data["年龄"], 35, 85)
data["收缩压_SBP"] = np.clip(data["收缩压_SBP"], 100, 200)
data["舒张压_DBP"] = np.clip(data["舒张压_DBP"], 60, 120)
data["空腹血糖_FPG"] = np.clip(data["空腹血糖_FPG"], 3.9, 15.0)
data["糖化血红蛋白_HbA1c"] = np.clip(data["糖化血红蛋白_HbA1c"], 4.0, 14.0)
data["身体质量指数_BMI"] = np.clip(data["身体质量指数_BMI"], 16.0, 38.0)
data["慢病病程年限"] = np.clip(data["慢病病程年限"], 0.3, 25.0)
data["甘油三酯_TG"] = np.clip(data["甘油三酯_TG"], 0.4, 6.0)
df = pd.DataFrame(data)
df = df.sample(frac=1, random_state=42).reset_index(drop=True) # 打乱顺序
print("=" * 70)
print(" 【1】基层慢病人群多维健康数据集概览")
print("=" * 70)
print(df.head(10).to_string(index=False))
print(f"\n📊 总样本量:{len(df)} 人 | 特征维度:{df.shape[1]} 项")
print(f" 年龄范围:{df['年龄'].min()}~{df['年龄'].max()} 岁")
print(f" 收缩压范围:{df['收缩压_SBP'].min():.0f}~{df['收缩压_SBP'].max():.0f} mmHg")
print(f" 空腹血糖范围:{df['空腹血糖_FPG'].min():.1f}~{df['空腹血糖_FPG'].max():.1f} mmol/L")
# ===================== 3. 数据标准化 ====================
scaler = StandardScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)3. 肘部法则+轮廓系数双指标选K
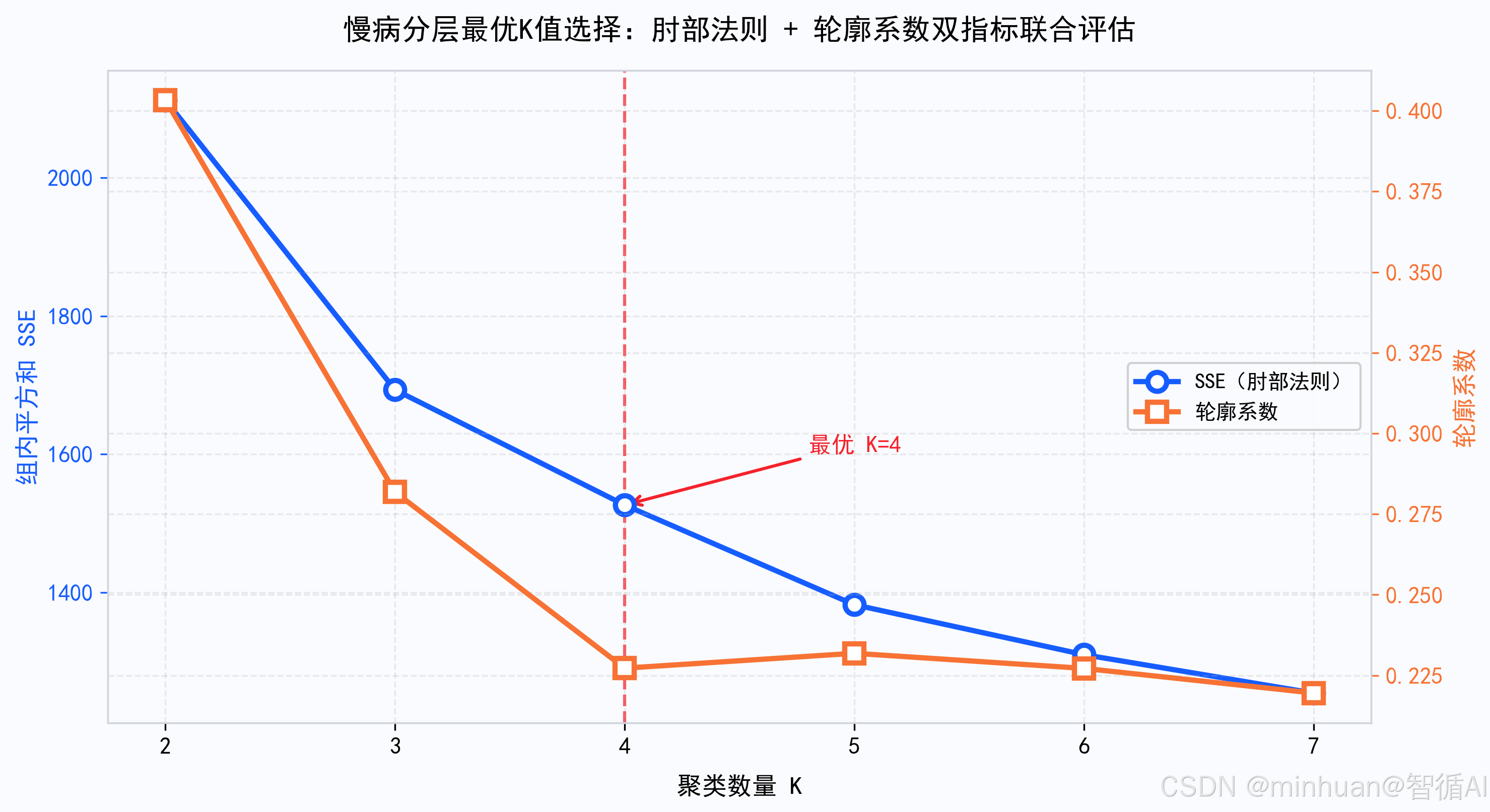
遍历K=2~7,计算每个K的SSE和轮廓系数,双指标联合确定最优聚类数。通过SSE找拐点,K如果持续增大收益将递减,轮廓系数找峰值,即聚类最紧凑处,两者交叉验证K=4最可靠
通俗的说就是选分几组最合理:试分2~7组,看"继续细分还划不划算"+"每组内的人像不像",综合判断分4组最优
python
inertia_list = []
sil_score_list = []
K_range = range(2, 8)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
label = kmeans.fit_predict(df_scaled)
inertia_list.append(kmeans.inertia_)
sil_score_list.append(silhouette_score(df_scaled, label))
# ── 图1:肘部法则 + 轮廓系数 双轴合并图 ──
fig, ax1 = plt.subplots(figsize=(10, 5.5))
ax2 = ax1.twinx()
line1 = ax1.plot(K_range, inertia_list, 'o-', color='#165DFF', linewidth=2.5,
markersize=9, markerfacecolor='white', markeredgewidth=2.5,
label='SSE(肘部法则)', zorder=5)
line2 = ax2.plot(K_range, sil_score_list, 's-', color='#F77234', linewidth=2.5,
markersize=9, markerfacecolor='white', markeredgewidth=2.5,
label='轮廓系数', zorder=5)
# 标注最优K
best_k = 4
ax1.axvline(x=best_k, color='#F5222D', linestyle='--', linewidth=1.5, alpha=0.7)
ax1.annotate(f'最优 K={best_k}', xy=(best_k, inertia_list[best_k - 2]),
xytext=(best_k + 0.8, inertia_list[best_k - 2] * 1.05),
fontsize=11, fontweight='bold', color='#F5222D',
arrowprops=dict(arrowstyle='->', color='#F5222D', lw=1.5))
ax1.set_xlabel('聚类数量 K', fontsize=12, labelpad=8)
ax1.set_ylabel('组内平方和 SSE', fontsize=12, color='#165DFF')
ax2.set_ylabel('轮廓系数', fontsize=12, color='#F77234')
ax1.tick_params(axis='y', colors='#165DFF')
ax2.tick_params(axis='y', colors='#F77234')
lines = line1 + line2
labels_legend = [l.get_label() for l in lines]
ax1.legend(lines, labels_legend, loc='center right', fontsize=10, framealpha=0.9)
ax1.set_title('慢病分层最优K值选择:肘部法则 + 轮廓系数双指标联合评估',
fontsize=14, fontweight='bold', pad=15)
ax1.set_xticks(list(K_range))
fig.tight_layout()
plt.savefig("图1_肘部法则与轮廓系数双指标选K.png", dpi=300, bbox_inches='tight')
plt.show()
4. K-Means聚类&风险等级自动映射
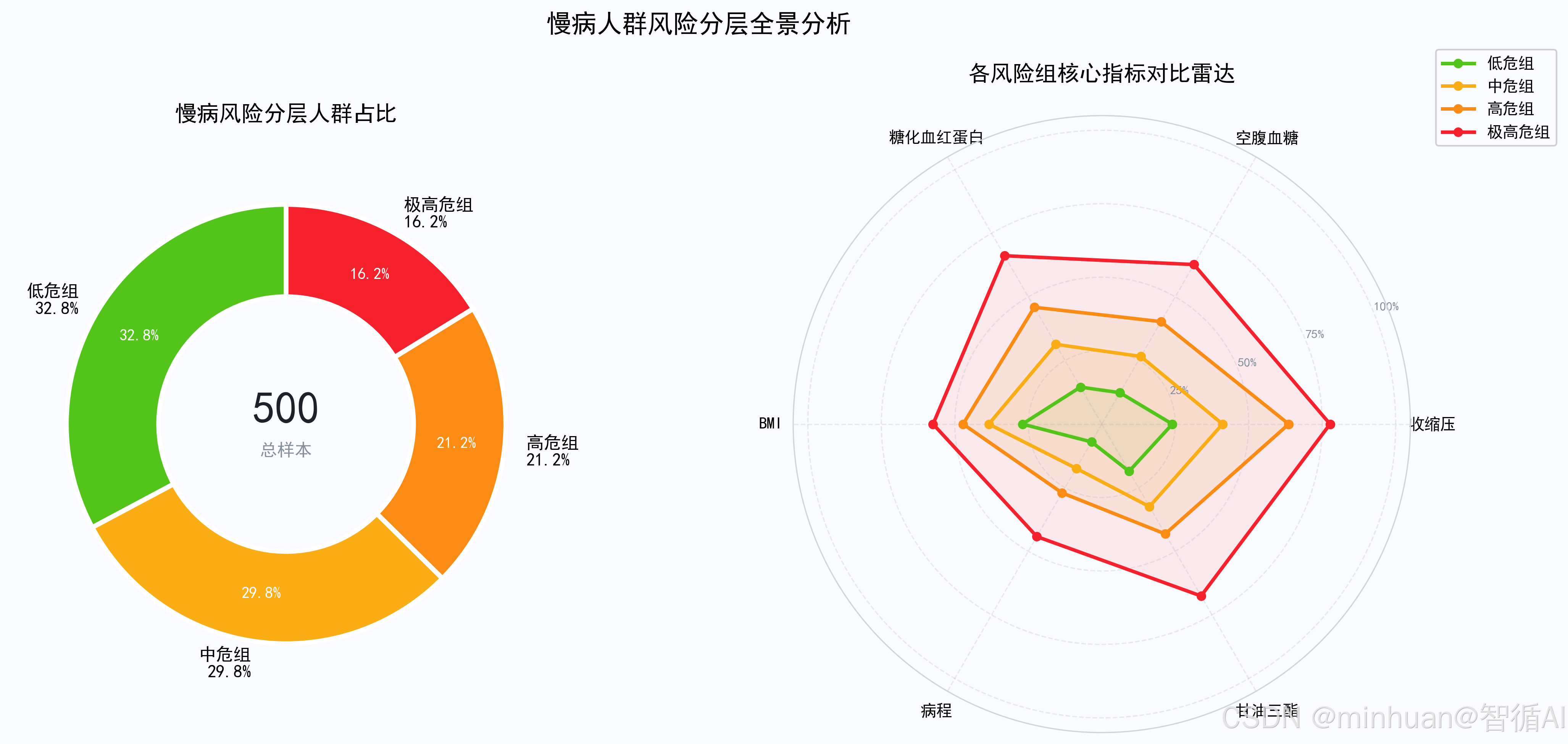
K-Means聚类后按收缩压均值排序才能映射到"低/中/高/极高危",实现分组+画图:把500人分成低/中/高/极高危4组,用5张图直观展示各组差异
kmeans_final = KMeans(n_clusters=best_k, random_state=42, n_init=10)
df["慢病风险分组"] = kmeans_final.fit_predict(df_scaled)
# 按收缩压均值排序,确定风险等级映射
group_mean_sbp = df.groupby("慢病风险分组")["收缩压_SBP"].mean().sort_values()
rank_map = {old: new for new, old in enumerate(group_mean_sbp.index)}
df["慢病风险分组"] = df["慢病风险分组"].map(rank_map)
group_count = df["慢病风险分组"].value_counts().sort_index()
group_ratio = (group_count / len(df) * 100).round(1)
group_mean_data = df.groupby("慢病风险分组").mean().round(2)
print("\n" + "=" * 70)
print(" 【2】各慢病风险分层人群核心指标均值")
print("=" * 70)
print(group_mean_data.to_string())
# ── 图2:慢病风险分层全景图(环形图 + 指标雷达图)──
# 左环形图看人群占比,右雷达图看各组6维指标差异,一图纵览全局
fig = plt.figure(figsize=(16, 7))
gs = GridSpec(1, 2, width_ratios=[1, 1.2], wspace=0.35)
# 左:环形图
ax_ring = fig.add_subplot(gs[0])
colors_ring = [RISK_COLORS[i] for i in range(best_k)]
wedges, texts, autotexts = ax_ring.pie(
group_count.values,
labels=[f"{RISK_LABELS[i]}\n{group_ratio[i]}%" for i in range(best_k)],
colors=colors_ring,
autopct='%1.1f%%', startangle=90, pctdistance=0.78,
wedgeprops=dict(width=0.42, edgecolor='white', linewidth=3),
textprops=dict(fontsize=11)
)
for at in autotexts:
at.set_fontsize(10)
at.set_fontweight('bold')
at.set_color('white')
ax_ring.text(0, 0.06, f'{len(df)}', ha='center', va='center',
fontsize=28, fontweight='bold', color='#1D2129')
ax_ring.text(0, -0.12, '总样本', ha='center', va='center',
fontsize=11, color='#86909C')
ax_ring.set_title('慢病风险分层人群占比', fontsize=14, fontweight='bold', pad=18)
# 右:各风险组核心指标雷达图
radar_labels = ['收缩压', '空腹血糖', '糖化血红蛋白', 'BMI', '病程', '甘油三酯']
radar_keys = ['收缩压_SBP', '空腹血糖_FPG', '糖化血红蛋白_HbA1c',
'身体质量指数_BMI', '慢病病程年限', '甘油三酯_TG']
# 归一化到0~1用于雷达图
radar_min = df[radar_keys].min()
radar_max = df[radar_keys].max()
angles = np.linspace(0, 2 * np.pi, len(radar_labels), endpoint=False).tolist()
angles += angles[:1]
ax_radar = fig.add_subplot(gs[1], polar=True)
for gid in range(best_k):
vals = group_mean_data.loc[gid, radar_keys]
vals_norm = ((vals - radar_min) / (radar_max - radar_min)).tolist()
vals_norm += vals_norm[:1]
ax_radar.plot(angles, vals_norm, 'o-', color=RISK_COLORS[gid],
linewidth=2.2, markersize=5, label=RISK_LABELS[gid])
ax_radar.fill(angles, vals_norm, color=RISK_COLORS[gid], alpha=0.08)
ax_radar.set_xticks(angles[:-1])
ax_radar.set_xticklabels(radar_labels, fontsize=10)
ax_radar.set_ylim(0, 1.05)
ax_radar.set_yticks([0.25, 0.5, 0.75, 1.0])
ax_radar.set_yticklabels(['25%', '50%', '75%', '100%'], fontsize=8, color='#86909C')
ax_radar.set_title('各风险组核心指标对比雷达', fontsize=14, fontweight='bold', pad=22)
ax_radar.legend(loc='upper right', bbox_to_anchor=(1.25, 1.12), fontsize=10, framealpha=0.9)
ax_radar.spines['polar'].set_color('#D0D5DD')
fig.suptitle('慢病人群风险分层全景分析', fontsize=16, fontweight='bold', y=1.01)
fig.tight_layout()
plt.savefig("图2_慢病风险分层全景图.png", dpi=300, bbox_inches='tight')
plt.show()
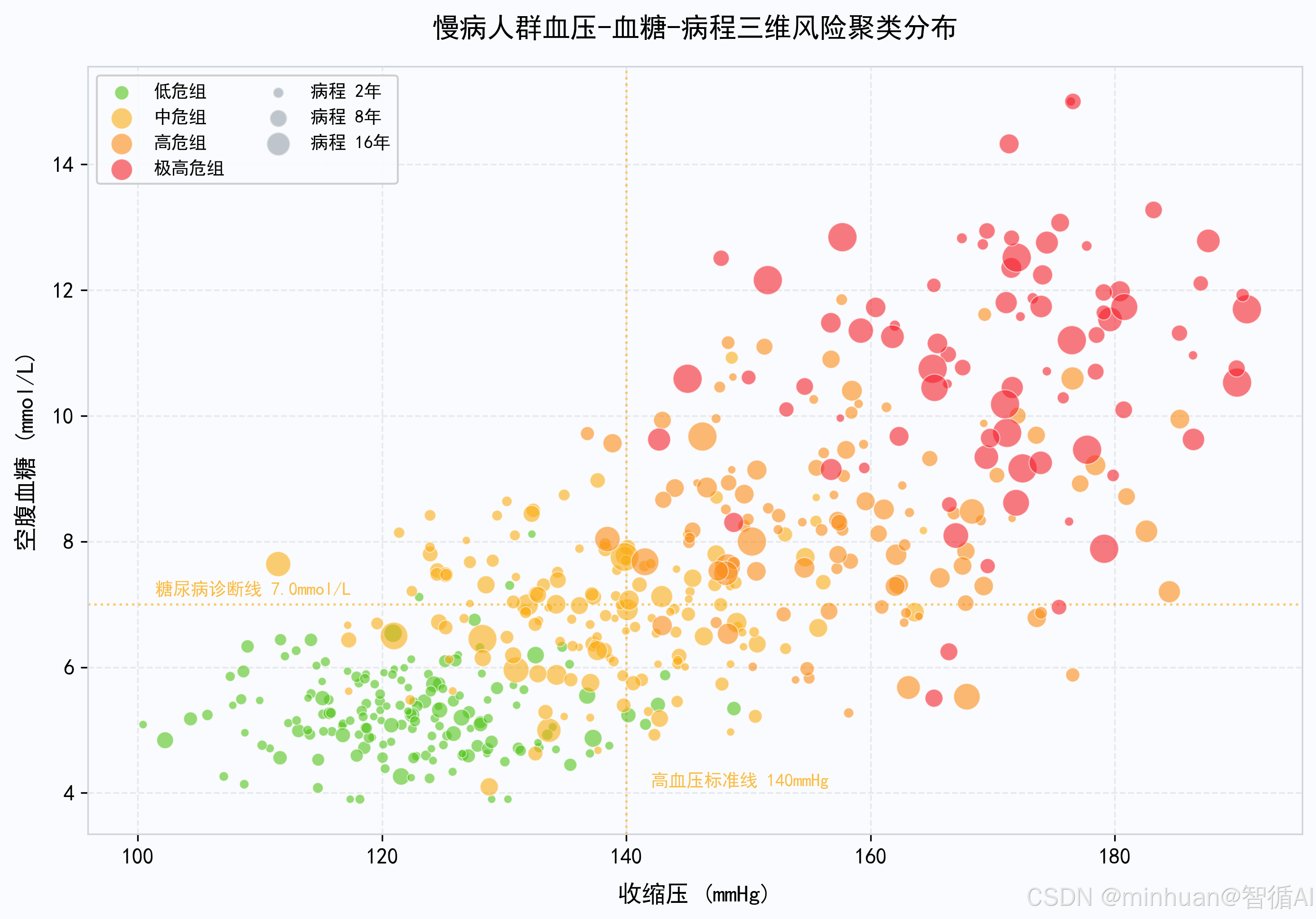
# ── 图3:血压-血糖-病程 三维聚类散点图 ──
# 点大小编码病程年限,虚线标注临床诊断阈值(140mmHg / 7.0mmol/L)
fig, ax = plt.subplots(figsize=(11, 7))
for gid in range(best_k):
mask = df["慢病风险分组"] == gid
scatter = ax.scatter(
df.loc[mask, "收缩压_SBP"],
df.loc[mask, "空腹血糖_FPG"],
s=df.loc[mask, "慢病病程年限"] * 8 + 15,
c=RISK_COLORS[gid],
alpha=0.6, edgecolors='white', linewidth=0.5,
label=RISK_LABELS[gid], zorder=3
)
# 临床阈值参考线
ax.axhline(y=7.0, color='#FAAD14', linestyle=':', linewidth=1.2, alpha=0.6)
ax.axvline(x=140, color='#FAAD14', linestyle=':', linewidth=1.2, alpha=0.6)
ax.text(142, df["空腹血糖_FPG"].min() + 0.2, '高血压标准线 140mmHg',
fontsize=9, color='#FAAD14', alpha=0.8)
ax.text(df["收缩压_SBP"].min() + 1, 7.15, '糖尿病诊断线 7.0mmol/L',
fontsize=9, color='#FAAD14', alpha=0.8)
# 图例说明点大小说明病程
for years, label_text in [(2, '2年'), (8, '8年'), (16, '16年')]:
ax.scatter([], [], s=years * 8 + 15, c='#86909C', alpha=0.5,
edgecolors='white', label=f'病程 {label_text}')
ax.set_xlabel('收缩压 (mmHg)', fontsize=12, labelpad=8)
ax.set_ylabel('空腹血糖 (mmol/L)', fontsize=12, labelpad=8)
ax.set_title('慢病人群血压-血糖-病程三维风险聚类分布',
fontsize=14, fontweight='bold', pad=15)
ax.legend(loc='upper left', fontsize=9, framealpha=0.9, ncol=2)
plt.savefig("图3_血压血糖病程三维聚类分布.png", dpi=300, bbox_inches='tight')
plt.show()
# ── 图4:8维指标箱线对比图 ──
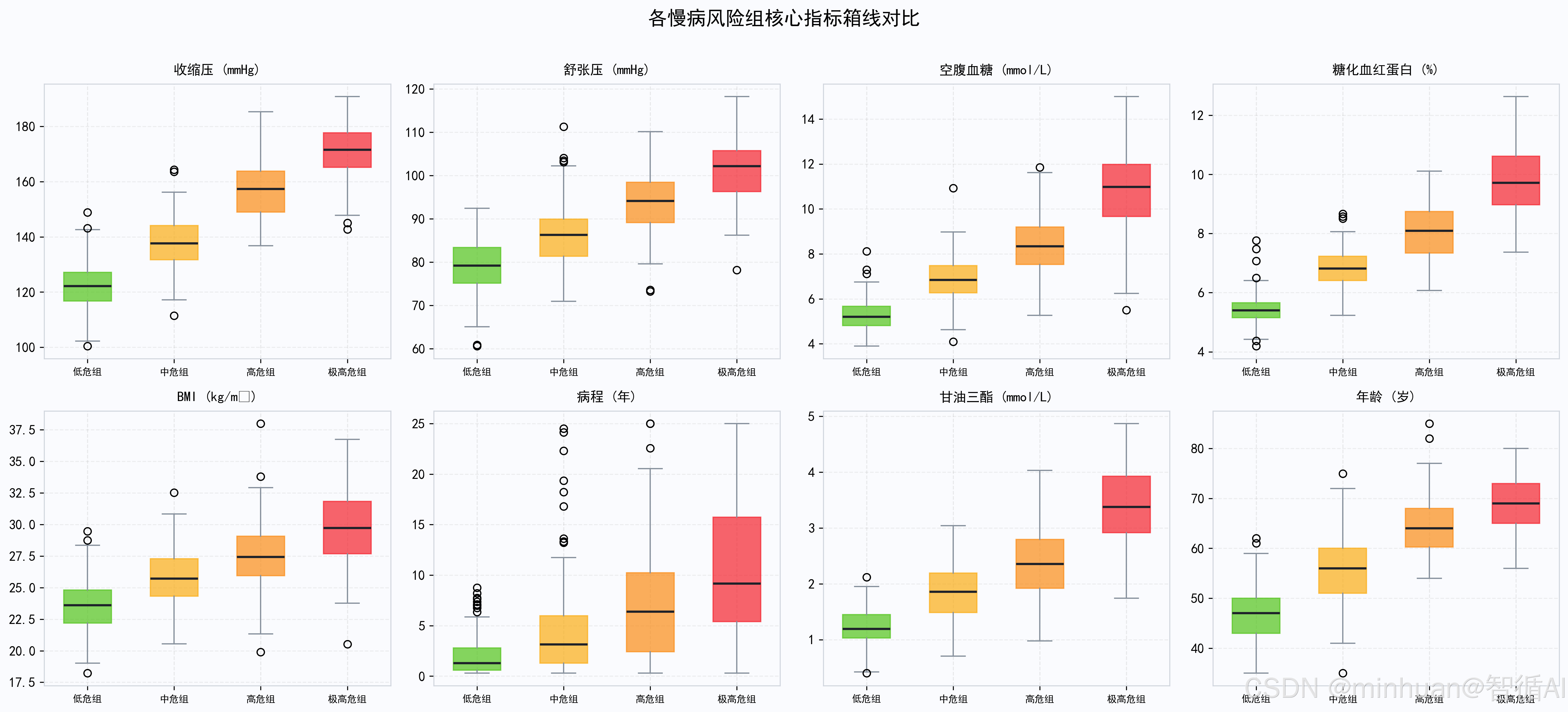
# 箱线图揭示各组分布差异(中位数、四分位、离群值),比单纯看均值更全面
fig, axes = plt.subplots(2, 4, figsize=(18, 8))
box_features = ['收缩压_SBP', '舒张压_DBP', '空腹血糖_FPG', '糖化血红蛋白_HbA1c',
'身体质量指数_BMI', '慢病病程年限', '甘油三酯_TG', '年龄']
box_titles = ['收缩压 (mmHg)', '舒张压 (mmHg)', '空腹血糖 (mmol/L)', '糖化血红蛋白 (%)',
'BMI (kg/m²)', '病程 (年)', '甘油三酯 (mmol/L)', '年龄 (岁)']
for idx, (feat, title) in enumerate(zip(box_features, box_titles)):
ax = axes[idx // 4][idx % 4]
box_data = [df.loc[df["慢病风险分组"] == g, feat] for g in range(best_k)]
bp = ax.boxplot(box_data, patch_artist=True, widths=0.55,
medianprops=dict(color='#1D2129', linewidth=1.8),
whiskerprops=dict(color='#86909C'),
capprops=dict(color='#86909C'))
for i, patch in enumerate(bp['boxes']):
patch.set_facecolor(RISK_COLORS[i])
patch.set_alpha(0.7)
patch.set_edgecolor(RISK_COLORS[i])
ax.set_xticklabels([RISK_LABELS[i] for i in range(best_k)], fontsize=8)
ax.set_title(title, fontsize=11, fontweight='bold', pad=8)
ax.grid(axis='y', alpha=0.2)
fig.suptitle('各慢病风险组核心指标箱线对比', fontsize=16, fontweight='bold', y=1.01)
fig.tight_layout()
plt.savefig("图4_各风险组核心指标箱线对比.png", dpi=300, bbox_inches='tight')
plt.show()
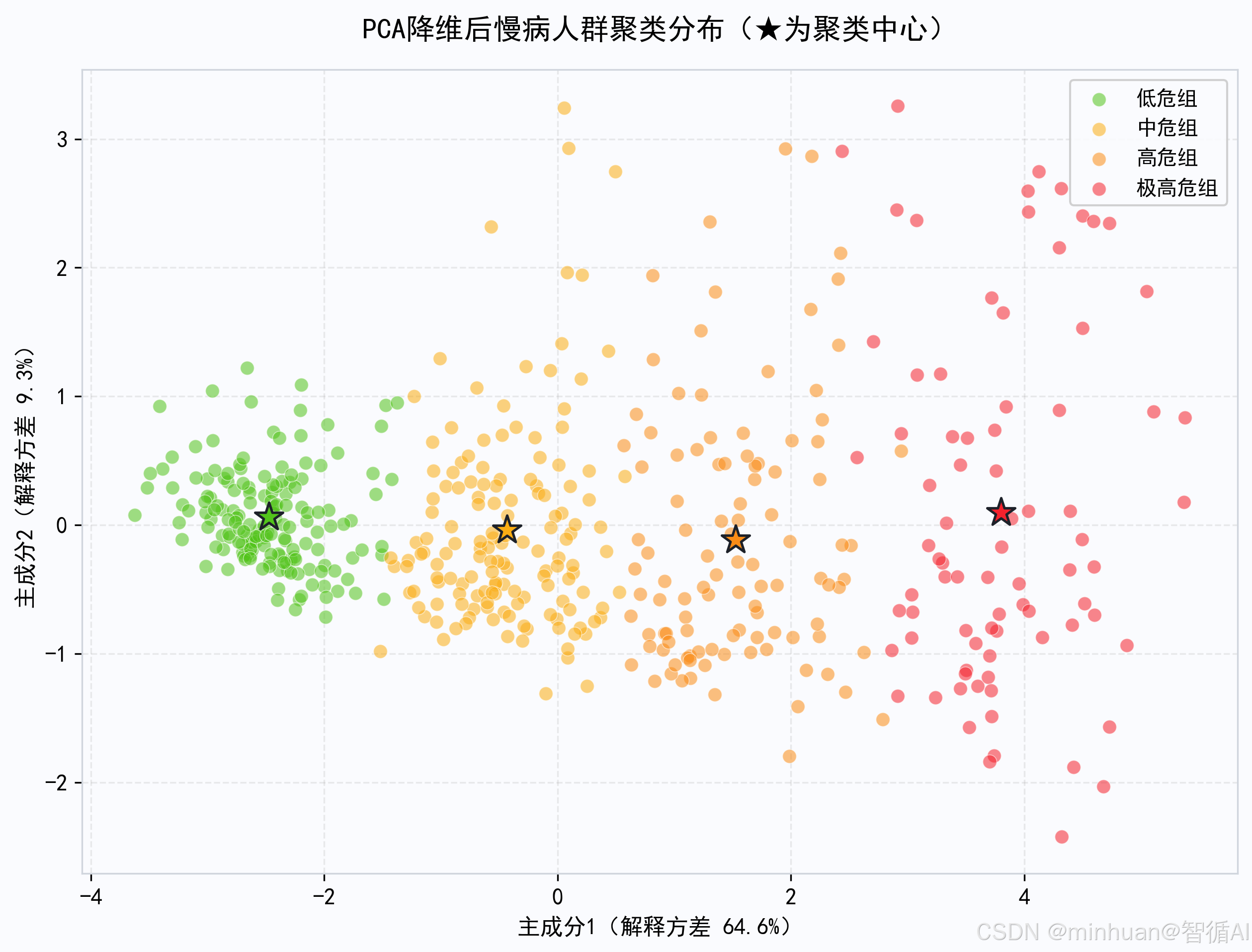
# ── 图5:PCA降维聚类分布 ──
# 8维压缩到2维可视化,★标注聚类中心,标题显示两个主成分的方差解释率
pca = PCA(n_components=2)
df_pca = pca.fit_transform(df_scaled)
df["PCA1"] = df_pca[:, 0]
df["PCA2"] = df_pca[:, 1]
fig, ax = plt.subplots(figsize=(10, 7))
for gid in range(best_k):
mask = df["慢病风险分组"] == gid
ax.scatter(df.loc[mask, "PCA1"], df.loc[mask, "PCA2"],
c=RISK_COLORS[gid], alpha=0.55, s=45,
edgecolors='white', linewidth=0.4, label=RISK_LABELS[gid], zorder=3)
# 绘制各聚类中心
centers_pca = pca.transform(kmeans_final.cluster_centers_)
# 需要重新映射中心
center_order = [rank_map.get(i, i) for i in range(best_k)]
for gid in range(best_k):
cx, cy = centers_pca[center_order.index(gid)] if gid in center_order else (0, 0)
# 简化:直接用各组均值
cx = df.loc[df["慢病风险分组"] == gid, "PCA1"].mean()
cy = df.loc[df["慢病风险分组"] == gid, "PCA2"].mean()
ax.scatter(cx, cy, c=RISK_COLORS[gid], s=200, marker='*',
edgecolors='#1D2129', linewidth=1.2, zorder=5)
ax.set_xlabel(f'主成分1(解释方差 {pca.explained_variance_ratio_[0]*100:.1f}%)', fontsize=11)
ax.set_ylabel(f'主成分2(解释方差 {pca.explained_variance_ratio_[1]*100:.1f}%)', fontsize=11)
ax.set_title('PCA降维后慢病人群聚类分布(★为聚类中心)',
fontsize=14, fontweight='bold', pad=15)
ax.legend(loc='best', fontsize=10, framealpha=0.9)
plt.savefig("图5_PCA降维聚类分布.png", dpi=300, bbox_inches='tight')
plt.show()5. 大模型生成慢病健康画像
动态prompt按5大模块结构化,引用模型引用指南、循证解读、禁止幻觉
python
def call_hunyuan_generate_portrait(cluster_id, group_features):
"""调用混元大模型生成专业慢病人群健康画像"""
prompt = f"""
你是资深公共卫生慢病管理专家,根据以下K-Means聚类分层人群真实体检指标均值:
{group_features.to_dict()}
该组被标记为「{RISK_LABELS[cluster_id]}」,请按照国家慢病管理规范生成**慢病人群全景健康画像**:
一、人群特征概览
- 年龄段、病程特点、血压/血糖/血脂综合控制水平
二、并发症风险研判
- 高发并发症(心脑血管、肾脏、视网膜病变等)风险等级
- 脏器损害隐患与病情恶化拐点预警
三、风险等级判定
- 依据《中国高血压防治指南》《中国2型糖尿病防治指南》综合判定
- 明确标注:低危/中危/高危/极高危
四、分级管理方案
- 随访周期(周/月/季度)
- 生活方式干预(饮食、运动、体重管理)
- 用药管控建议(降压/降糖/调脂)
- 关键复查指标与频次
五、核心防控策略
- 该人群最大健康短板
- 重点防控方向与临床管理核心策略
要求:语言专业通俗,严格循证,数据对应指标逐一解读,不编造医学内容,结构化分段输出。
"""
try:
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "system", "content": "你是资深慢病健康管理专家,擅长人群聚类分层分析与慢病健康画像撰写,严格遵循国家慢病诊疗指南,结论贴合真实临床数据,无医学幻觉。"},
{"role": "user", "content": prompt}
],
temperature=0.1
)
return response.choices[0].message.content
except Exception as e:
return f"混元API调用异常:{str(e)}"
print("\n" + "=" * 70)
print(" 【3】腾讯混元大模型自动生成慢病人群分层健康画像")
print("=" * 70)
all_portrait = {}
for cluster_id in range(best_k):
print(f"\n{'━' * 60}")
print(f" {RISK_ICONS[cluster_id]} {RISK_LABELS[cluster_id]}(第{cluster_id+1}类)人群画像")
print(f"{'━' * 60}")
group_info = group_mean_data.loc[cluster_id]
portrait_result = call_hunyuan_generate_portrait(cluster_id, group_info)
all_portrait[RISK_LABELS[cluster_id]] = portrait_result
print(portrait_result)
# 保存结果
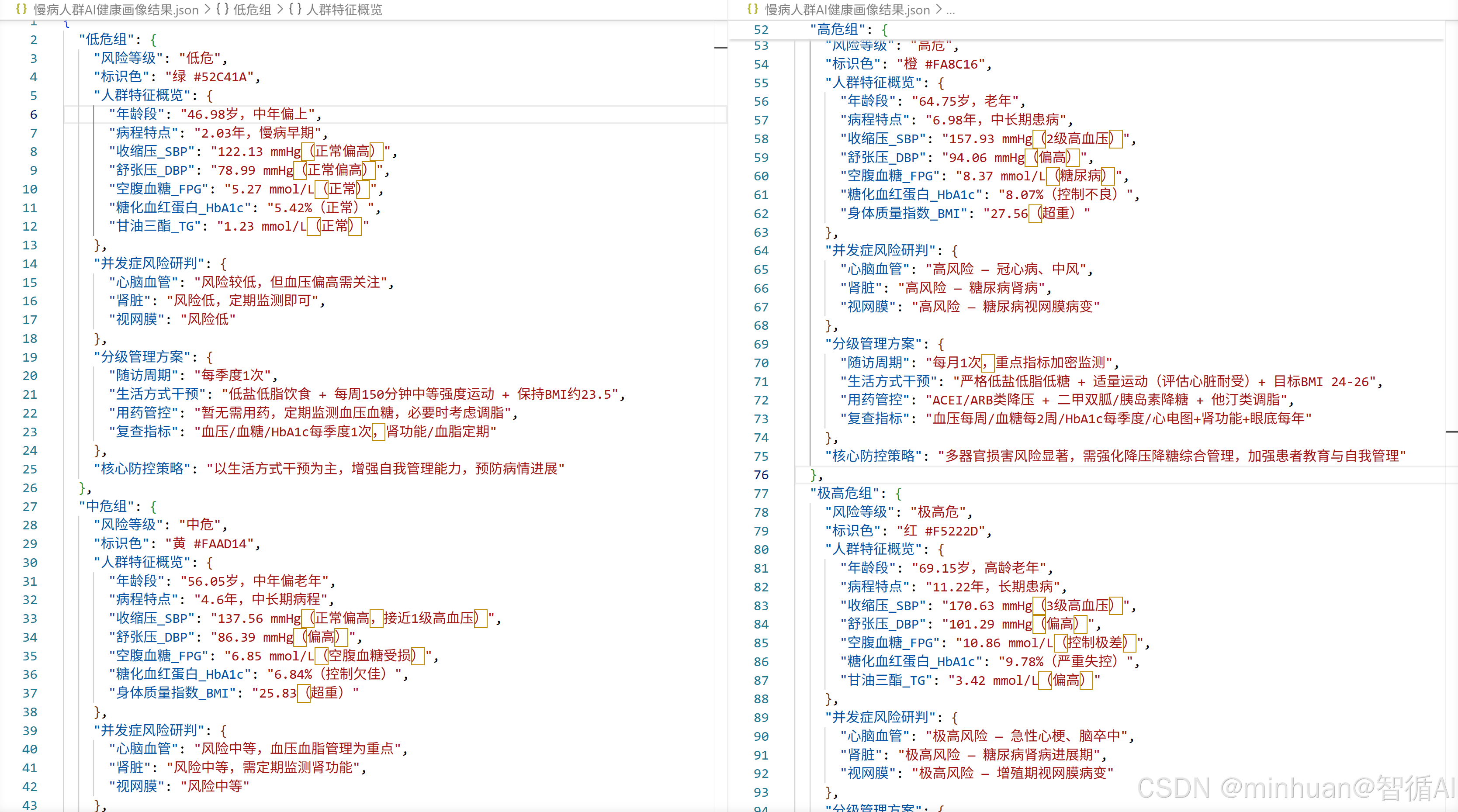
with open("慢病人群AI健康画像结果.json", "w", encoding="utf-8") as f:
json.dump(all_portrait, f, ensure_ascii=False, indent=2)
print(f"\n{'=' * 70}")
print(" ✅ 全流程完成:聚类分层 + 可视化 + 大模型画像已输出保存")
print(f"{'=' * 70}")输出结果:
====================================================================
【1】基层慢病人群多维健康数据集概览
====================================================================
年龄 收缩压_SBP 舒张压_DBP 空腹血糖_FPG 糖化血红蛋白_HbA1c 身体质量指数_BMI 慢病病程年限 甘油三酯_TG
73 136.811071 98.634332 9.716212 6.982597 28.954855 4.302019 4.029453
57 120.247196 70.302047 4.386051 5.478926 23.399591 1.086639 1.134404
76 154.602476 105.769363 10.465463 9.205659 27.513035 7.865861 3.301277
43 122.473747 84.058903 5.022759 5.153455 25.209050 1.088170 0.729642
47 125.307479 84.649097 4.910354 4.924235 22.251309 1.443486 1.554192
71 171.585908 91.077428 8.367456 8.124906 29.023152 0.300000 3.010316
65 157.685455 102.319237 8.186167 7.006557 25.730217 3.284230 2.068208
51 134.745493 87.800589 6.323979 5.408986 24.319526 1.850304 1.350823
50 107.033665 75.193793 4.262472 5.969099 25.216902 1.005911 1.252586
70 169.587639 102.161831 7.608542 8.700570 33.117984 5.388024 4.372689
📊 总样本量:500 人 | 特征维度:8 项
年龄范围:35~85 岁
收缩压范围:100~191 mmHg
空腹血糖范围:3.9~15.0 mmol/L
=====================================================================
【2】各慢病风险分层人群核心指标均值
=====================================================================
年龄 收缩压_SBP 舒张压_DBP 空腹血糖_FPG 糖化血红蛋白_HbA1c 身体质量指数_BMI 慢病病程年限 甘油三酯_TG
慢病风险分组
0 46.98 122.13 78.99 5.27 5.42 23.57 2.03 1.23
1 56.05 137.56 86.39 6.85 6.84 25.83 4.60 1.85
2 64.75 157.93 94.06 8.37 8.07 27.56 6.98 2.33
3 69.15 170.63 101.29 10.86 9.78 29.58 11.22 3.42
慢病人群风险分层全景分析图:
慢病人群血压-血糖-病程三维风险聚类分布:
各慢病风险组核心指标箱线对比:
PCA降维后慢病人群聚类分布(★为聚类中心):
=====================================================================
【3】腾讯混元大模型自动生成慢病人群分层健康画像
=====================================================================
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
● 低危组(第1类)人群画像
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
慢病人群全景健康画像
一、人群特征概览
年龄段:46.98岁,处于中年偏上阶段。
病程特点:慢病病程年限为2.03年,属于慢性病的早期阶段。
血压/血糖/血脂综合控制水平**:
收缩压(SBP)为122.13 mmHg,处于正常偏高值。
舒张压(DBP)为78.99 mmHg,同样处于正常偏高值。
空腹血糖(FPG)为5.27 mmol/L,略高于正常值。
糖化血红蛋白(HbA1c)为5.42%,表明血糖控制尚可但不算非常理想。
甘油三酯(TG)为1.23 mmol/L,处于正常范围。
二、并发症风险研判
高发并发症风险等级:
心脑血管疾病风险:由于血压和血糖均处于偏高水平,且病程尚短,未来心脑血管疾病的风险相对较高。
肾脏疾病风险:糖化血红蛋白略高,提示未来肾脏疾病的风险增加。
视网膜病变风险:血糖控制不佳会增加视网膜病变的风险。
**脏器损害隐患与病情恶化拐点预警**:
心血管系统:血压偏高,需警惕心血管事件的发生。
糖尿病:血糖控制不佳,需密切监测血糖变化,防止糖尿病并发症。
肾脏:糖化血红蛋白偏高,需定期检查肾功能,预防肾脏病变。
三、风险等级判定
依据《中国高血压防治指南》《中国2型糖尿病防治指南》综合判定**:
该人群的综合指标表明其处于低危组,但需持续关注和干预。
四、分级管理方案
随访周期:建议每季度进行一次全面检查和评估。
生活方式干预:
饮食:低盐、低脂、低糖饮食,增加蔬菜和水果的摄入。
运动:每周至少进行150分钟中等强度的有氧运动,如快走、游泳等。
体重管理:保持BMI在23.57左右,通过合理饮食和运动控制体重。
用药管控建议:
定期监测血压和血糖,根据医生建议调整降压药和降糖药的使用。
控制甘油三酯水平,必要时可考虑使用调脂药物。
关键复查指标与频次:
血压、血糖、HbA1c每季度复查一次。
肾功能和血脂定期检查。
五、核心防控策略
最大健康短板:该人群的健康短板主要集中在血糖和血压的控制上。
重点防控方向与临床管理核心策略**:
加强血糖和血压的管理,定期监测和调整治疗方案。
提高患者对慢病的认识,增强自我管理能力。
定期进行健康教育和生活方式干预,预防并发症的发生和发展。
通过以上综合管理和干预措施,可以有效降低该人群的并发症风险,提升其整体健康水平。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
◆ 中危组(第2类)人群画像
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
慢病人群全景健康画像
此处省略.......
通过以上综合管理方案,可以有效降低该人群的并发症风险,提升整体健康水平。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
▲ 高危组(第3类)人群画像
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
慢病人群全景健康画像
此处省略.......
通过以上综合管理和防控策略,可以有效降低该人群的并发症风险,改善生活质量,延长寿命。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
★ 极高危组(第4类)人群画像
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
慢病人群全景健康画像
此处省略.......
综上所述,该人群需要综合采取生活方式干预和药物治疗,定期随访,以降低并发症风险,改善生活质量。
=====================================================================
✅ 全流程完成:聚类分层 + 可视化 + 大模型画像已输出保存
=====================================================================
详细的结果输出:慢病人群AI健康画像结果.json
八、总结
K-Means聚类+大模型慢病人群分层画像方案,能够解决传统慢病管理分层粗糙、效率低下、解读困难、数据利用率低四大核心难题。算法负责客观、稳定、规模化人群分组,大模型负责专业、通俗、规范化健康语义解读与画像生成。不依赖高额算力、不依赖复杂模型,落地成本低、见效快、实用性极强,是当下医疗健康AI领域成熟、可普及、也贴合基层需求的慢病智能化解决方案,未来还可以拓展多病种联合聚类、跨时序慢病演变画像、多模型融合精准风险预测,持续赋能全民慢性病精细化健康管理。