第 2 章 逻辑与推理
2.1 命题逻辑
命题逻辑是应用一套形式化规则对以符号表示的描述性陈述 进行推理的系统。
2.1.1 基本概念
-
命题:能确定真(T)或假(F)的陈述句(如 "北京是中国的首都")。
-
原子命题:不可分解的简单命题(如 P)。
- 任何一个命题或为真或为假
-
复合命题:由联结词组合的命题(如 P ∧ Q)。
2.1.2 命题联结词
可以通过命题联结词对已有命题进行组合,得到新命题
| 联结词 | 符号 | 真值表逻辑 |
|---|---|---|
| 与(and) | P ∧ Q | 仅当 P 和 Q 均为真时为真 |
| 或(or) | P ∨ Q | 至少一个为真时即为真 |
| 非(not) | ¬P | 真值取反 |
| 条件(if-then) | P → Q | 命题蕴含,如果p则q |
| 双向条件(iff) | P ↔ Q | P 和 Q 同真或同假时为真 |
| ppp | q | ¬p\neg p¬p | P and Q | p V q | p→qp \to qp→q | p↔qp \leftrightarrow qp↔q |
|---|---|---|---|---|---|---|
| False | False | True | False | False | True | True |
| False | True | True | False | True | True | False |
| True | False | False | False | True | False | False |
| True | True | False | True | True | True | True |
2.1.3 逻辑等价
-
交换律
-
结合律
-
双重否定
-
逆否命题:P→Q≡¬Q→¬PP \to Q \equiv \neg Q \to \neg PP→Q≡¬Q→¬P
-
分配律:
- P∧(Q∨R)≡(P∧Q)∨(P∧R) P \land (Q \lor R) \equiv (P \land Q) \lor (P \land R) P∧(Q∨R)≡(P∧Q)∨(P∧R)(∧对∨的分配律)
- P∨(Q∧R)≡(P∨Q)∧(P∨R) P \lor (Q \land R) \equiv (P \lor Q) \land (P \lor R) P∨(Q∧R)≡(P∨Q)∧(P∨R)(∨对∧的分配律)
-
蕴涵消除 : P→Q≡¬P∨Q P \to Q \equiv \neg P \lor Q P→Q≡¬P∨Q
-
双向消除 : P↔Q≡(P→Q)∧(Q→P)P \leftrightarrow Q \equiv (P \to Q) \land (Q \to P) P↔Q≡(P→Q)∧(Q→P)
-
德摩根定律:
- ¬(P∧Q)≡¬P∨¬Q\neg (P \land Q) \equiv \neg P \lor \neg Q ¬(P∧Q)≡¬P∨¬Q
- ¬(P∨Q)≡¬P∧¬Q \neg (P \lor Q) \equiv \neg P \land \neg Q ¬(P∨Q)≡¬P∧¬Q
2.1.4 推理规则
| 假言推理(Modus Ponens) | a→β,aβ\frac{a \to \beta, a}{\beta}βa→β,a |
|---|---|
| 与消解(And-Elimination) | a1∧a2∧...∧anai(1≤i≤n)\frac{a_{1} \land a_{2} \land \ldots \land a_{n}}{a_{i}(1 \leq i \leq n)}ai(1≤i≤n)a1∧a2∧...∧an |
| 与导入(And-Introduction) | a1,a2,...,ana1∧a2∧...∧an\frac{a_{1}, a_{2}, \ldots, a_{n}}{a_{1} \land a_{2} \land \ldots \land a_{n}}a1∧a2∧...∧ana1,a2,...,an |
| 双重否定 (Double-Negation Elimination) | ¬¬aa\frac{\neg \neg a}{a}a¬¬a |
| 单项消解或单项归结 (Unit Resolution) | a∨β,¬βa\frac {a \vee \beta, \neg \beta}{a}aa∨β,¬β |
| 消解或归结 (Resolution) | a1∨a2∨...∨am,¬βa1∨a2∨...∨ak−1∨ak+1∨...∨am (ak=β)\frac{a_{1} \vee a_{2} \vee \ldots \vee a_{m}, \neg \beta}{a_{1} \vee a_{2} \vee \ldots \vee a_{k-1} \vee a_{k+1} \vee \ldots \vee a_{m}} \ (a_{k}=\beta)a1∨a2∨...∨ak−1∨ak+1∨...∨ama1∨a2∨...∨am,¬β (ak=β) |
- 假言推理:若 P → Q 且 P 成立,则 Q 成立。
- 与消解:若一个合取命题为真,则其任意一个子命题必然为真
- 与导入:多个独立命题均为真,则合取命题为真
- 双重否定:
- 单项消解或单项归结:若已知一个析取命题为真,且其中一个子命题的否定为真,则另一个命题为真
- 消解或归结:将 aka_kak 去掉
- 归结法:通过消解矛盾得出结论(如由 P ∨ Q 和 ¬Q ∨ R 导出 P ∨ R)。
2.1.5 范式
-
一个析取范式是不成立的,当且仅当它的每个简单的合取式都不成立
-
一个合取范式是成立的,当且仅当它的每个简单的析取式都是成立的
-
任何一个命题公式都存在着与之等价的析取范式和合取范式
-
析取范式(DNF) :合取式的析取(如(¬P∧Q)∨R(¬P ∧ Q) ∨ R(¬P∧Q)∨R)。
-
合取范式(CNF) :析取式的合取(如(P∨Q)∧(¬R∨S)(P ∨ Q) ∧ (¬R ∨ S)(P∨Q)∧(¬R∨S))。
2.2 谓词逻辑
2.2.1 基本元素
- 个体:研究对象的实例(分为常量 "苏格拉底" 和变量 x)。
- 谓词:描述属性或关系的符号(如 Mortal(x): x 会死亡)。
- 量词 :
- 全称量词 ∀x:所有个体满足条件(如"所有人")。
- 存在量词 ∃x:至少一个个体满足条件(如"存在英雄")
2.2.2 量词逻辑等价
-
∀x¬P(x)≡¬∃xP(x)\forall x \neg P(x) \equiv \neg \exists x P(x)∀x¬P(x)≡¬∃xP(x)
-
¬∀xP(x)≡∃x¬P(x)\neg \forall x P(x) \equiv \exists x \neg P(x)¬∀xP(x)≡∃x¬P(x)
-
∀xP(x)≡¬∃x¬P(x)\forall x P(x) \equiv \neg \exists x \neg P(x)∀xP(x)≡¬∃x¬P(x)
-
∃xP(x)≡¬∀x¬P(x)\exists x P(x) \equiv \neg \forall x \neg P(x)∃xP(x)≡¬∀x¬P(x)
函数与谓词的区别:
- 函数中个体变元常用个体常量带入后结果仍是个体
- 谓词中个体变元用个体常量带入后就变成了命题
- 函数是从定义域到值域的映射
- 谓词是从定义域到 True,false{True, false}True,false
2.2.3 变量与法则
-
约束变元:受量词约束的变量(如 ∀x 中的 x)。
-
自由变元:无约束的变量(如表达式中的独立变量)。
-
分配律 : ∀x(P(x)∧Q(x))≡∀xP(x)∧∀xQ(x)∃x(P(x)∨Q(x))≡∃xP(x)∨∃xQ(x)∀x(P(x) ∧ Q(x)) ≡ ∀x P(x) ∧ ∀x Q(x) ∃x(P(x) ∨ Q(x)) ≡ ∃x P(x) ∨ ∃x Q(x)∀x(P(x)∧Q(x))≡∀xP(x)∧∀xQ(x)∃x(P(x)∨Q(x))≡∃xP(x)∨∃xQ(x)
若干谓词逻辑的推理规则
- 全称量词消去: (∀x)A(x)⇒A(y)(\forall x)A(x) \Rightarrow A(y)(∀x)A(x)⇒A(y)
- Universal Instantiation, UI
- 全称量词引入: A(y)⇒(∀x)A(x)A(y) \Rightarrow (\forall x)A(x)A(y)⇒(∀x)A(x)
- Universal Generalization, UG
- 存在量词消去: (∃x)A(x)⇒A(c)(\exists x)A(x) \Rightarrow A(c)(∃x)A(x)⇒A(c)
- Existential Instantiation, EI
- 存在量词引入: A(c)⇒(∃x)A(x)A(c) \Rightarrow (\exists x)A(x)A(c)⇒(∃x)A(x)
- Existential Generalization, EG
2.2.4 示例推理
- 苏格拉底三段论: ∀x (Human(x) → Mortal(x)) Human(Socrates) → Mortal(Socrates)
2.3 知识图谱推理
2.3.1 基本概念
- 知识图谱可视为包含多种关系的图
- 每个节点是一个实体
- 可将知识图片中任意两个相连节点及连接边表示成三元组
2.3.1 归纳推理
- FOIL 算法:从正例和反例中学习规则(如 "X 是 Y 的朋友 → X 与 Y 有关联")。
FOIL(First Order Inductive Learner)是一种基于一阶谓词逻辑的归纳学习算法,用于从知识图谱中推理新的关系规则。以下是其核心步骤总结:
-
定义目标谓词
-
明确需要推理的目标关系(如父子关系
Father(x, y)),并确定训练样例集合:-
正例 :已知满足目标谓词的实体对(如
(David, Mike))。 -
反例 :已知不满足目标谓词的实体对(如
(David, James)),通常通过知识图谱中相悖关系构造。 -
背景知识 :目标谓词以外的其他谓词实例(如
Couple(David, James)、Mother(James, Mike))。
-
-
-
初始化推理规则
- 将目标谓词作为推理规则的结论,初始规则仅包含目标谓词,如:
Father(x,y)←\text{Father}(x, y) \leftarrowFather(x,y)←
此时规则覆盖所有训练样例(正例和反例)。
- 将目标谓词作为推理规则的结论,初始规则仅包含目标谓词,如:
-
选择最优前提约束谓词
-
逐一将背景知识中的谓词作为前提约束谓词加入规则,计算每条候选规则的 FOIL信息增益值,选择增益最大的谓词。
-
信息增益公式 :
FOIL_Gain=m+^⋅(log2m+^m+^+m−^−log2m+m++m−) \text{FOIL\Gain} = \hat{m+} \cdot \left( \log_2 \frac{\hat{m_+}}{\hat{m_+} + \hat{m_-}} - \log_2 \frac{m_+}{m_+ + m_-} \right) FOIL_Gain=m+^⋅(log2m+^+m−^m+^−log2m++m−m+)
其中:
- m+^\hat{m_+}m+^、m−^\hat{m_-}m−^ 为加入新谓词后规则覆盖的正例、反例数;
- m+m_+m+、m−m_-m− 为原规则覆盖的正例、反例数。
-
示例 :
若加入谓词
Couple(x, z)后,规则覆盖正例数 m+^=1\hat{m_+}=1m+^=1,反例数 m−^=1\hat{m_-}=1m−^=1,原规则 m+=1m_+=1m+=1,m−=4m_-=4m−=4,则:FOIL_Gain=1⋅(log212−log215)=1.32 \text{FOIL\_Gain} = 1 \cdot \left( \log_2 \frac{1}{2} - \log_2 \frac{1}{5} \right) = 1.32 FOIL_Gain=1⋅(log221−log251)=1.32
-
-
迭代优化规则
-
将选中的谓词加入规则,形成新规则(如 Father(x,y)←Couple(x,z)\text{Father}(x, y) \leftarrow \text{Couple}(x, z)Father(x,y)←Couple(x,z)),并从训练样例中剔除与新规则不符的实例(即不满足前提条件的样例)。重复此过程,直至规则不再覆盖任何反例。
-
终止条件 :新规则覆盖所有正例且不覆盖任何反例,如最终规则:
Father(x,y)←Couple(x,z)∧Mother(z,y) \text{Father}(x, y) \leftarrow \text{Couple}(x, z) \land \text{Mother}(z, y) Father(x,y)←Couple(x,z)∧Mother(z,y)
-
-
生成最终推理规则
- 经过迭代优化后,得到的规则即为能正确推理目标关系的逻辑表达式。例如,通过学习家庭关系知识图谱,最终规则可表示:
若 x 与 z 是配偶关系,且 z 是 y 的母亲,则 x 是 y 的父亲 ,对应一阶逻辑:
∀x,y,z (Couple(x,z)∧Mother(z,y)→Father(x,y)) \forall x, y, z \ (\text{Couple}(x, z) \land \text{Mother}(z, y) \rightarrow \text{Father}(x, y)) ∀x,y,z (Couple(x,z)∧Mother(z,y)→Father(x,y))
- 经过迭代优化后,得到的规则即为能正确推理目标关系的逻辑表达式。例如,通过学习家庭关系知识图谱,最终规则可表示:
2.3.2 路径排序
- 路径特征提取:通过实体间的路径关系推断新连接(如通过 A→B→C 推断 A→C 的隐含关系)。
步骤:
- 对于目标关系,生成四组训练样例,一个为正例,三个为负例
- 从知识图谱采样得到路径,每一路径链接上述每个训练样例中的两个实体
- 对于每个正例/负例,判断上述四条路经可否链接其包含的两个实体,将可链接(记为1)和不可链接(记为0)作为特征,于是每一个正例/负例得到一个四维特征向量
2.3.3 知识图谱推理:机器学习
从数据到知识、从知识到决策
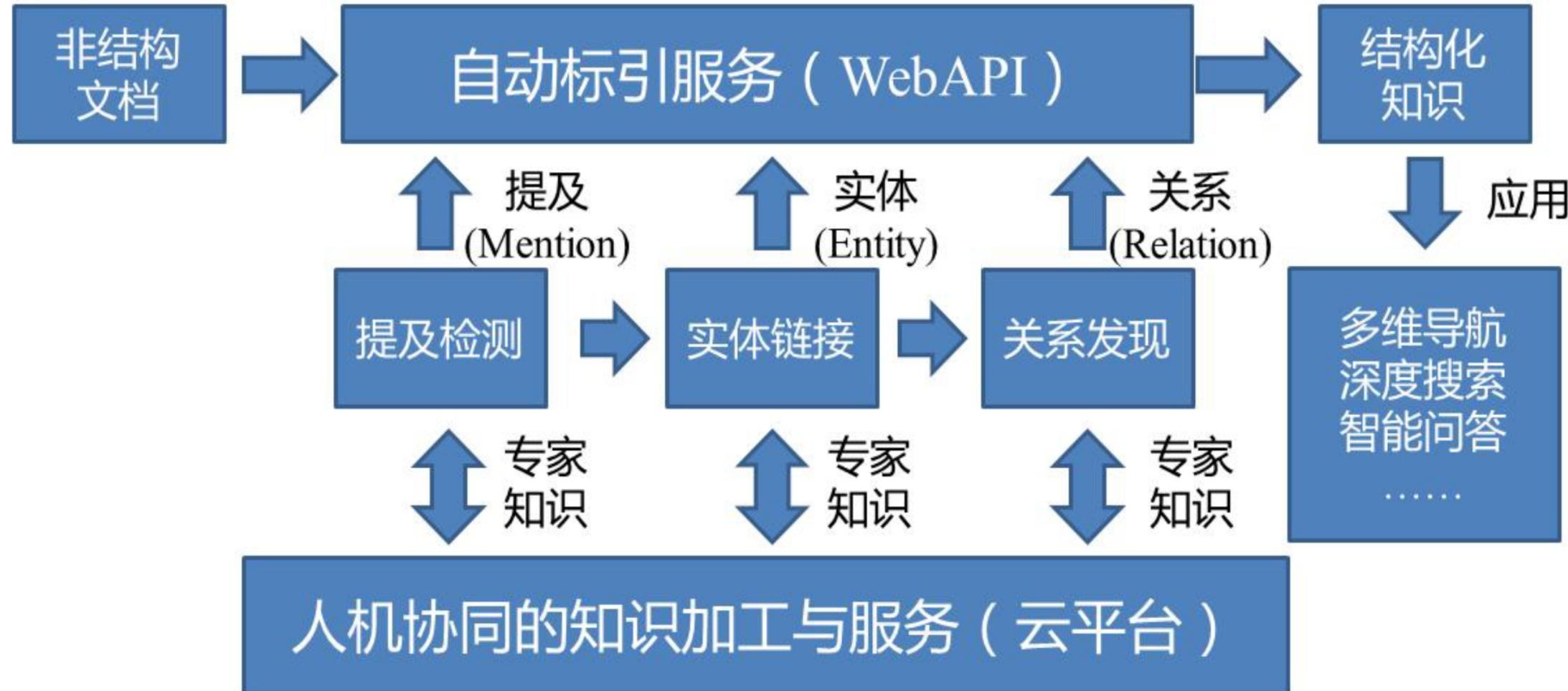
2.4 因果推理
2.4.1 辛普森悖论
- 现象:群体趋势与子群体趋势相反(需用分层分析揭示真实因果)。
2.4.2 因果图模型
因果推理的层级:
以下是修正后的表格,清晰对应因果推断的三个层次:
| 层次 | 问题 | 表达式 |
|---|---|---|
| 关联(可观测性) | What if we see A? | P(y∣A)P(y \mid A)P(y∣A) |
| 干预(决策行动) | What if we do A? | P(y∣do(A))P(y \mid do(A))P(y∣do(A)) |
| 反事实(Counterfactual) | What if we did things differently? | P(y′∣A)P(y' \mid A)P(y′∣A)(给定实际A,假设不同行动下y'的概率) |
-
节点:表示变量(如治疗、康复)。
-
边:因果方向(治疗 → 康复)。
2.4.3 因果推理:有向无环图
- 对于任意的DAG,模型中ddd个变量的联合概率分布由每个节点与其父节点之间条件概率的乘积给出:
P(x1,x2,⋯ ,xd)=∏j=1dP(xj∣xpa(j)) \begin{align*} P(x_1, x_2, \cdots, x_d) &= \prod_{j = 1}^{d} P(x_j|x_{pa(j)}) \end{align*} P(x1,x2,⋯,xd)=j=1∏dP(xj∣xpa(j))
其中,xpa(j)x_{pa(j)}xpa(j)表示节点xjx_jxj的父节点集合(所有指向xjx_jxj的节点)
2.4.4 因果推理:D-分离
-
A→C→B
-
D-分离用于判断集合A中变量是否与集合B中变量相互独立,给定集合C,记为 A⊥B∣C A \perp B | CA⊥B∣C
-
当C取值固定(可观测,observed),有
P(A,B∣C)=P(A,B,C)P(C)=P(A)P(C∣A)P(B∣C)P(C)=P(A∣C)P(B∣C) P(A, B | C)=\frac{P(A, B, C)}{P(C)}=\frac{P(A) P(C | A) P(B | C)}{P(C)}=P(A | C) P(B | C) P(A,B∣C)=P(C)P(A,B,C)=P(C)P(A)P(C∣A)P(B∣C)=P(A∣C)P(B∣C)
-
可见A、B在C取值固定的时候,是条件独立的
-
-
A←C→B
- 当C取值固定(observed),有
- A和B在C的取值固定的情况下,是条件独立的
P(A,B∣C)=P(A,B,C)P(C)=P(C)P(A∣C)P(B∣C)P(C)=P(A∣C)P(B∣C) P(A, B | C)=\frac{P(A, B, C)}{P(C)}=\frac{P(C) P(A | C) P(B | C)}{P(C)}=P(A | C) P(B | C) P(A,B∣C)=P(C)P(A,B,C)=P(C)P(C)P(A∣C)P(B∣C)=P(A∣C)P(B∣C)
-
A→C←B
-
当C取值固定(observed)
P(A,B∣C)=P(A,B,C)P(C)=P(A)P(B)P(C∣A,B)P(C)≠P(A)P(B) P(A, B | C)=\frac{P(A, B, C)}{P(C)}=\frac{P(A) P(B) P(C | A, B)}{P(C)} \neq P(A) P(B) P(A,B∣C)=P(C)P(A,B,C)=P(C)P(A)P(B)P(C∣A,B)=P(A)P(B)
-
A和B在条件C下是不独立的
-
| 链结构(chain) | 分连结构(fork) | 汇连 (或碰撞) 结构 (collider) |
|---|---|---|
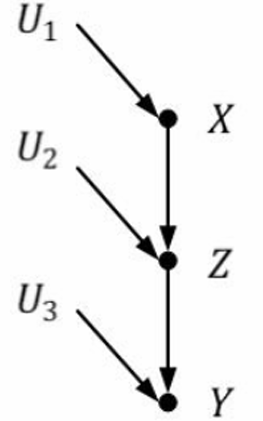 |
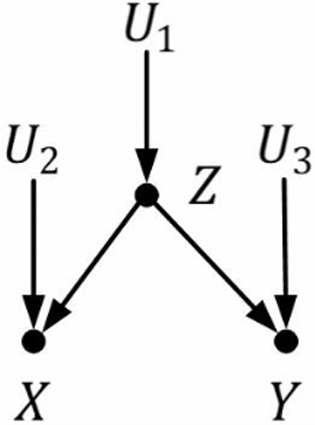 |
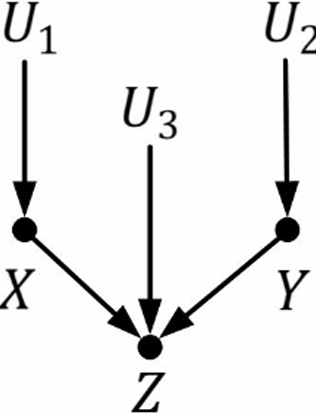 |
| Z和X是相关的 | X和Z是相关的 | Z和X是相关的 |
| Y和Z是相关的 | Y和Z是相关的 | Z和Y是相关的 |
| Y和X很有可能是相关的 | Y和X很有可能是相关的 | YYY 和 XXX 是相互独立的 |
| 给定Z时,Y和X是条件独立的 | 给定Z时,Y和X是条件独立的 | 给定Z时,Y和X是相关的 |
三种典型结构:
| 结构类型 | 图示 | 条件 | 独立性 |
|---|---|---|---|
| 链结构 | A→X→BA \rightarrow X \rightarrow BA→X→B | X∈CX \in CX∈C | $A \perp B |
| 分连结构 | A←X→BA \leftarrow X \rightarrow BA←X→B | X∈CX \in CX∈C | $A \perp B |
| 汇连结构 | A→X←BA \rightarrow X \leftarrow BA→X←B | X∉CX \notin CX∈/C 且后代不在 C | $A \perp B |
| 汇连结构 | A→X←BA \rightarrow X \leftarrow BA→X←B | X∈CX \in CX∈C 或后代在 C | A 与 B 不独立 |
- 在因果图上,若节点X和节点Y之间的每一条路径都是阻塞的
- 称节点X和节点Y是有向分离的
- 反之,称其为有向链接的
- 当两个节点是有向分离时,意味着这两个节点相互独立
2.4.3 干预与反事实
- 干预(do 操作):强制变量的取值(如强制治疗以评估效果)。
- 反事实分析:假设条件下可能的结果(如 "如果未治疗,患者是否仍会康复?")。