Claude Code Dynamic Workflows 入门 --- 用并行子智能体自动搞定大规模任务
写在前面
2026 年 5 月 28 日,Anthropic 在发布 Claude Opus 4.8 的同一天,把 Claude Code 的新功能 Dynamic Workflows 作为研究预览版(research preview)放了出来。
老版本的 Claude Code 是从一次对话轮次出发,一步一步顺着往下处理。而 Dynamic Workflows 的玩法完全不同------它会自动生成一段 JavaScript 编排脚本,然后并行跑起最多 1000 个子智能体。像整个代码库的迁移、安全审计、多来源调研这类大活儿,现在可以在几乎不吃上下文窗口的前提下一口气干完。
这篇文章笔者就基于官方文档和公开信息,把 Dynamic Workflows 的原理和实际用法讲清楚。
读完这篇大概能搞明白这么几件事:Dynamic Workflows 跟普通的 Claude Code 到底差在哪、三种触发方式分别怎么用(/deep-research、workflow 关键词、/effort ultracode)、执行过程中怎么看脚本(按 Ctrl+G),以及工作流怎么存下来复用、成本又该怎么控制。
适合看的人也很明确:日常就在用 Claude Code 的工程师,想拿它来折腾大型代码库迁移、审计、调研的开发者,还有已经订了 Claude Code 付费方案、或者正在犹豫要不要订的人。
至于前提环境,需要 Claude Code v2.1.154 以上(用 claude --version 查),所有付费方案 (Pro / Max / Team / Enterprise)都能用------不过 Pro 方案得自己去 /config 里的 Dynamic workflows 那一行手动开一下。总之确认它在 /config 里已经启用就行。
简单来说:Claude Code 的裂变
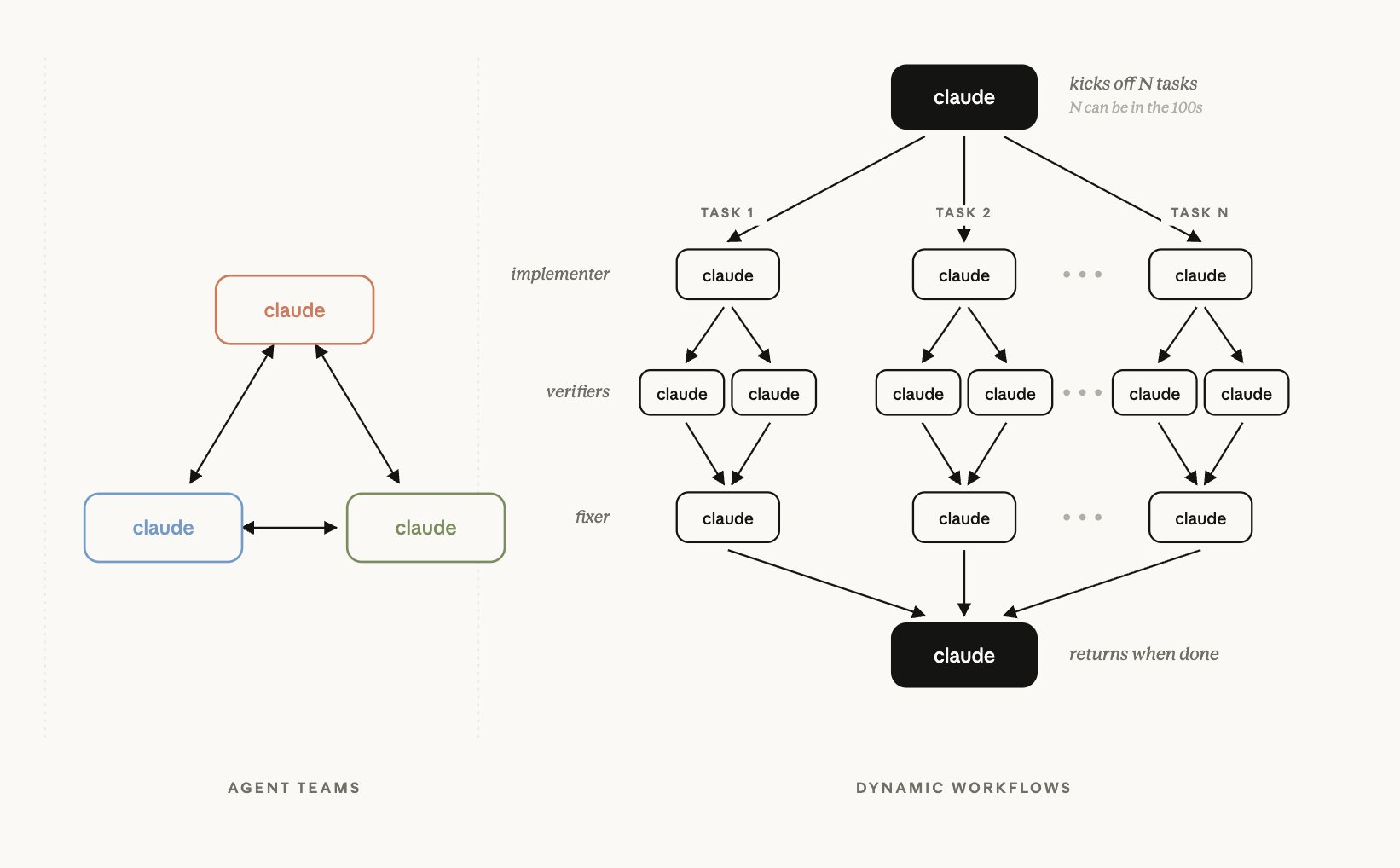
一句话概括,Dynamic Workflows 就是让 Claude Code 先分析任务、生成一段 JavaScript 编排脚本,再调度最多 1000 个子智能体并行跑。
触发它有三个口子:内置的 /deep-research、在提示词里塞个 "workflow" 关键词、以及 /effort ultracode。执行前可以按 Ctrl+G 把脚本调出来审一遍再批准;跑起来之后用 /workflows 能实时盯着当前阶段、智能体数量和 token 消耗。跑成功的工作流还能存成斜杠命令反复用。
唯一要记牢的坑:token 消耗会是平时的几倍到几十倍,所以一定要把范围圈小了再用。
Dynamic Workflows 到底是个啥
跟普通 Claude Code 的区别
普通的 Claude Code,收到用户消息后,Claude 是在一次对话轮次里按顺序处理的。读文件 → 写代码 → 跑测试,整条链路全是串行。一旦碰上大代码库,光是读文件就能把上下文窗口塞爆,这一直是个老大难。
Dynamic Workflows 就是冲着这个限制来的。
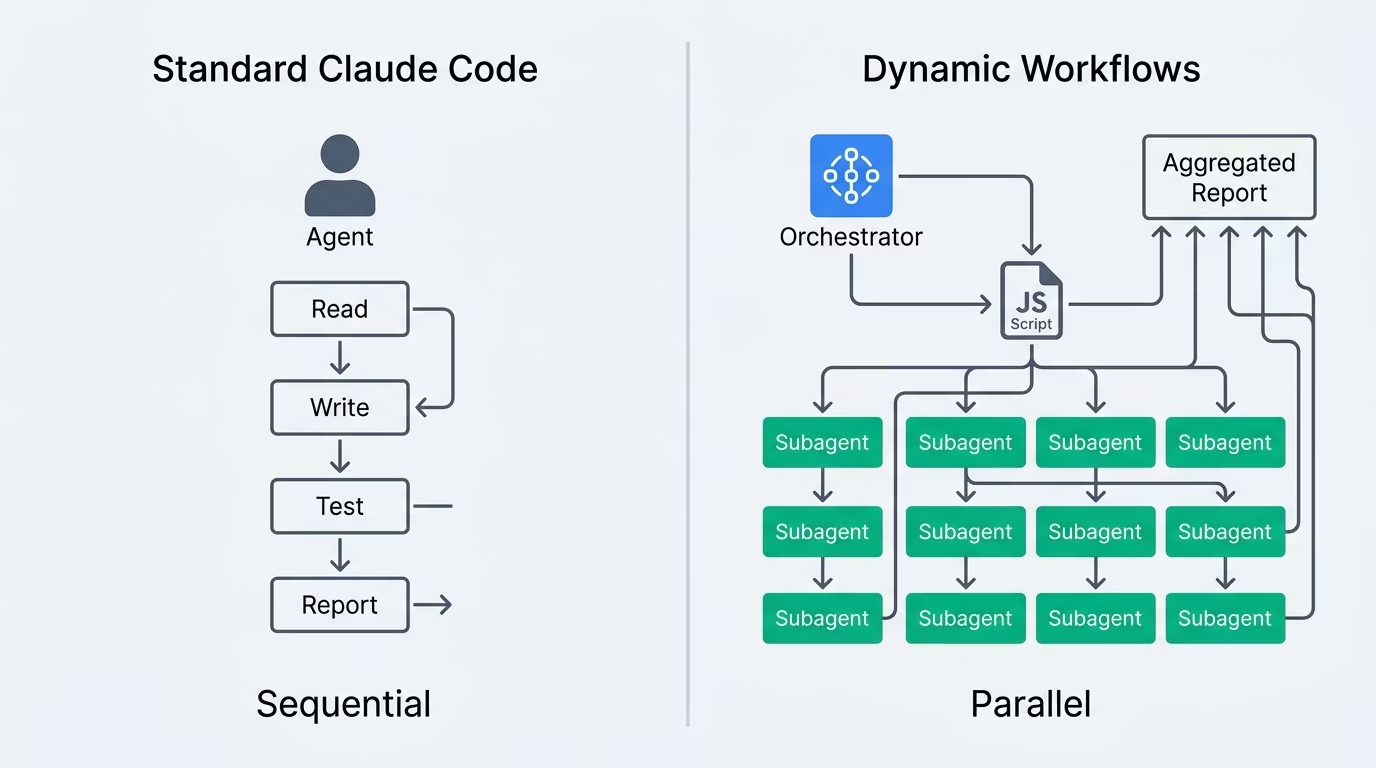
两者的差异大致可以这样对照:
| 项目 | 普通 Claude Code | Dynamic Workflows |
|---|---|---|
| 执行模型 | 单智能体(串行) | 多智能体(并行) |
| 中间结果存哪 | 上下文窗口 | 脚本变量 |
| 最大智能体数 | 1 | 1000(同时并行 16 个) |
| 任务规模 | 文件级到模块级 | 整个代码库 |
| 中断与恢复 | 依赖会话 | 会话内可恢复 |
大致原理
按照官方文档的说法,Dynamic Workflows 跑起来是这么个流程:用户先发一条能触发工作流的提示词,Claude 把任务转写成一段 JavaScript 编排脚本;接着弹出审批提示,这时按 Ctrl+G 就能在编辑器里把脚本看个明白;批准之后,工作流运行时开始执行脚本,最多 16 个子智能体并行干活;最后各个子智能体的结果汇集到脚本变量里,作为一份最终报告回到会话中。
三种触发方式
方式一:/deep-research(内置工作流)
最省事的入门方式,就是 Claude Code 自带的这个内置工作流。
/deep-research Claude Code Dynamic Workflows的最新规格和限制事项/deep-research 会从多个角度并行检索信息,对信息源做交叉核对,最后生成一份带引用的整合报告。它跟单纯搜索不一样的地方在于------信息的可靠性是由多个智能体互相验证出来的。
方式二:"workflow" 关键词
只要在提示词里带上 "workflow" 这个词,Dynamic Workflows 就会被唤起。
Run a workflow to audit every API endpoint under src/routes for missing auth checks.
Migrate the authentication module from Express 4 to Express 5 using a workflow.
Verify all tests pass at each stage.关键是把范围、输出格式、验证规则、编辑策略都写清楚。要是丢一句"帮我把应用改好点"这种含糊的话,子智能体根本收敛不了,token 白白烧掉。
方式三:/effort ultracode
/effort ultracode执行这条命令后,Claude Code 会针对那些处理量确实不小的任务,自动判断要不要启动 Workflows。它本质上是个跟 xhigh 推理搭配在一起的自动编排模式。
把
/effort ultracode一直开着,token 消耗会暴涨。官方建议只在重要任务上用它。
执行流程:一步一步来
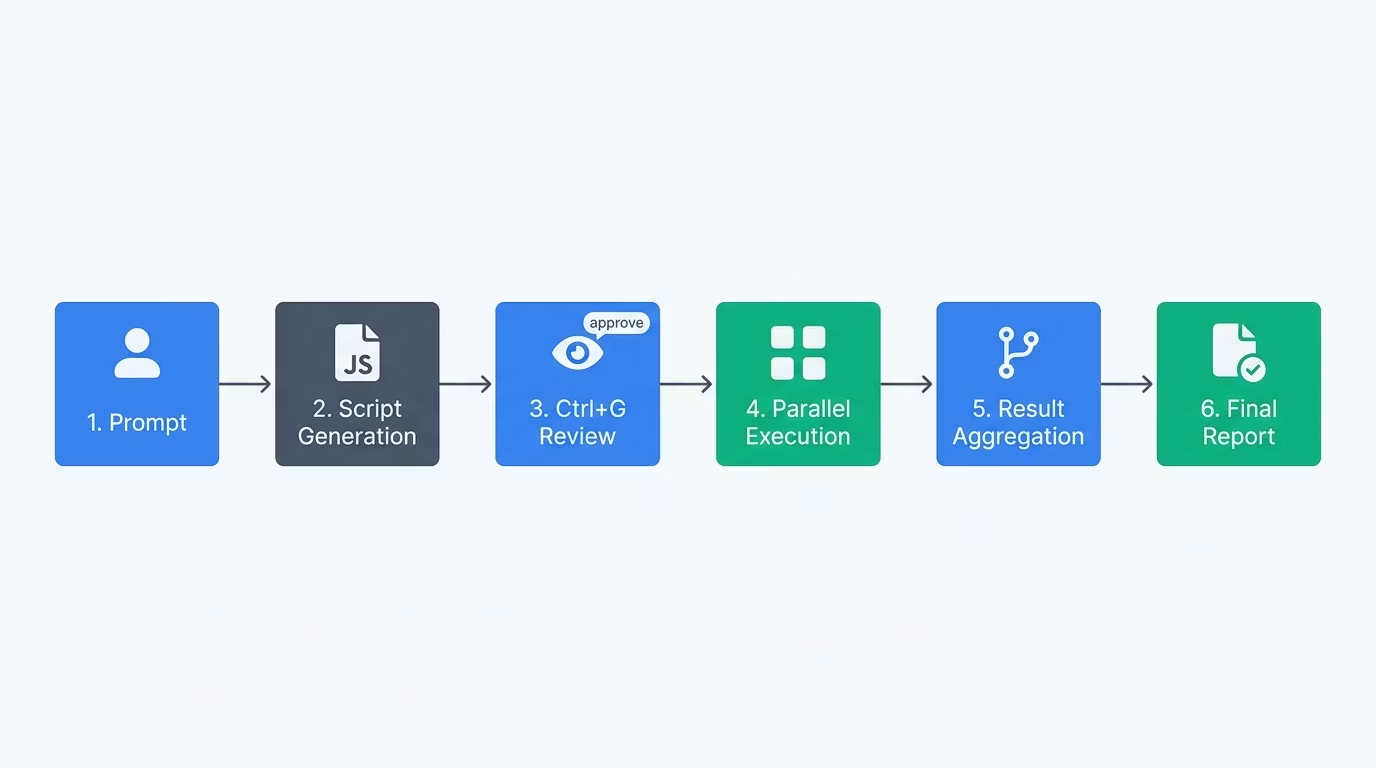
第一步:确认版本和配置
claude --version
# 确认是 v2.1.154 以上然后在 Claude Code 里头确认配置:
/config
# 确认 Dynamic Workflows 已经启用
/usage
# 看看现在的 token 消耗量(当作执行前的基准线)第二步:发送提示词
发出能触发工作流的提示词,Claude 会分析任务并给出执行计划。
Run a workflow to find all TypeScript files in src/ that use deprecated React
lifecycle methods (componentWillMount, componentWillReceiveProps,
componentWillUpdate), list them with line numbers, then replace each with
the modern equivalent. Verify the test suite stays green after each file change.第三步:审查脚本(Ctrl+G)
这时会弹出审批提示。按 Ctrl+G 就能把脚本在编辑器里打开看。检查一下有没有夹带不该动的文件改动、范围是不是开得太大,确认没问题后,在审批菜单里选「Yes, run it」。
// Claude 生成的编排脚本大致长这样(示例)
const files = await findFiles("src/**/*.ts", { grep: "componentWill" });
const phases = chunk(files, 4); // 每 4 个文件一批并行处理
for (const phase of phases) {
await Promise.all(phase.map(file =>
agent({ task: "migrate_lifecycle", file, verifyTests: true })
));
}
return summarize(results);脚本一旦批准,工作流运行时就启动了。
第四步:盯着进度
/workflows在 /workflows 面板里能实时看到:当前跑到第几个阶段、活跃的子智能体有几个(最多 16)、累计起过多少个智能体(最多 1000),以及 token 消耗量。要是发现哪里不对劲,直接在这个面板里就能把执行停掉。
第五步:拿结果
所有子智能体跑完之后,汇总好的最终报告会回到会话里。因为上下文窗口里压根没堆中间数据,所以就算是大代码库,结果也能清清楚楚地展示出来。
工作流的保存与复用
跑成功的工作流,可以存成斜杠命令反复用。
/workflows
# 选中已完成的执行 → 按 's' 键打开保存菜单存的地方有两类:一类是项目共享,路径在 .claude/workflows/,团队所有人都能用;另一类是个人用,路径在 ~/.claude/workflows/,只在自己的 Claude Code 环境里生效。
存好之后,就能像 /audit-routes 这样当斜杠命令来调用了。定期的安全审计、回归检查这类反复要跑的活儿,特别适合复用同一个工作流。
成本控制和怎么安全地用
token 消耗大概什么量级
Dynamic Workflows 是好几个子智能体一起并行跑的,所以比起平时用 Claude Code,token 消耗会大幅上涨 。官方文档里也白纸黑字写了,工作流可能比普通对话处理消耗多得多的 token。
养成习惯:执行前用 /usage 看一眼基准线,执行后再核对一下消耗量。
至于怎么把成本压下来,几条思路值得记住。第一是把范围圈小,比如明确写成 src/routes/** 这样指定目标目录。第二是把只读阶段单独拎出来------头一个阶段只做分析、不做改动,看完结果再进到改动阶段。第三是分步骤推进,先拿一小撮子集验证,没问题再铺到全部。第四是别一直开着 Ultracode,只在真正需要的任务前后临时开一下就行。
要安全地跑,还有几点得放在心上:执行前用 Ctrl+G 把脚本审一遍,确认范围跟预期一致;凡是带破坏性改动的工作流(删文件、改数据库之类),都拆成两阶段流程来做;要是你用了 --dangerously-skip-permissions,那就得格外小心了。
分场景的最佳实践
代码库迁移
框架升级、库替换这类活儿,是 Dynamic Workflows 最能打的场景之一。
公开信息里有个挺亮眼的案例:JavaScript 运行时「Bun」的开发者 Jarred Sumner 用 Dynamic Workflows 把 Bun 从 Zig 重写成了 Rust。据 The Register 等多家媒体报道,6 天里生成了约 96 万行代码,跑通了现有测试套件的 99.8%。
推荐的提示词结构是这样的:
Run a workflow to migrate [对象] from [旧版本] to [新版本].
- Scope: [目录/文件模式]
- Verification: Run [测试命令] after each file change
- Edit policy: Only modify files that fail verification
- Output: Summary of changed files and test results安全审计
Run a workflow to audit all API endpoints in src/api/ for:
1. Missing authentication middleware
2. Unsanitized input parameters
3. Exposed sensitive data in responses
For each finding, report: file path, line number, severity (high/medium/low),
and recommended fix. Do not modify any files.把 Do not modify any files 写明白,就能当成一个纯只读的分析阶段来跑,安全得很。
深度调研(/deep-research)
技术选型、规格调研这类事,用 /deep-research 最合适。
/deep-research What are the performance differences between Bun, Node.js, and Deno
for HTTP server workloads in 2026? Include benchmark sources and methodology.它会从多个角度并行检索,把信息可靠性交叉核对一遍,最后给你一份带引用的报告。
几点注意事项
当前的限制
目前(截至 2026 年 5 月)它还处在研究预览阶段 ,规格往后可能会变。能用的方案是所有付费方案(Pro / Max / Team / Enterprise),其中 Pro 需要去 /config 里手动启用 Dynamic workflows。最低版本要求 Claude Code v2.1.154 以上。同时执行上限是 16 个智能体(会按 CPU 核心数来伸缩),单次执行累计上限是 1000 个智能体。
哪些场景不太适合
单个文件的小修小补、需要即时响应的交互式任务,还有那种范围本身就很难界定清楚的含糊任务------这几类就别硬上 Dynamic Workflows 了。
小结
Claude Code Dynamic Workflows 是个研究预览功能,专门用来自动化那些以前得靠人手动拆分的大规模任务,比如整个代码库的迁移、审计、调研。
它的核心是几样东西:自动生成的 JavaScript 编排脚本协调起最多 1000 个子智能体一块儿干;三种触发口子(内置的 /deep-research、"workflow" 关键词、/effort ultracode);执行前用 Ctrl+G 预审脚本、用 /workflows 实时盯着的那份透明感;以及把成功的工作流存成斜杠命令的可复用性。
记着 token 消耗大这件事,再配上范围圈得明明白白的提示词,大规模编码任务的自动化就能落地了。
最后提一句,毕竟还在研究预览阶段,规格往后可能有变,最新情况建议直接看官方文档。
参考链接
- Orchestrate subagents at scale with dynamic workflows --- Claude Code Docs --- Dynamic Workflows 官方文档(限制、成本、操作方法)
- Introducing Claude Opus 4.8 --- Anthropic --- Claude Opus 4.8 与 Dynamic Workflows 的官方发布
- Anthropic's Bun Rust rewrite merged at speed of AI --- The Register --- Jarred Sumner 的 Bun 重写案例(96 万行、6 天)
- What's new --- Claude Code Docs --- 最新发布信息