Mem0 的检索管线已经配备了语义向量搜索和 BM25 关键词匹配两路信号。语义搜索负责"意思差不多"的模糊召回,BM25 负责"字面重叠"的精确命中。两路融合,覆盖了大多数场景。
但有一个问题:当用户查询中包含专有名词------人名、品牌、技术术语------向量搜索经常匹配不上,BM25 也常常因为形态差异而丢失。更致命的是,语义搜索无法表达"这些记忆都提到了同一个实体"这种跨记忆关联。
于是 Mem0 在检索管线中加入了第三路信号:Entity Boost。它的背后是一个独立的 Entity Store。
纯向量搜索的三大盲区
在深入 Entity Store 之前,先弄清楚它到底在补什么短板。这不是理论推演------这是每次检索都会发生的真实故障模式。
盲区一:专有名词匹配弱。
向量嵌入擅长编码语义空间中的相对位置。"我喜欢打网球"和"我爱网球运动"在向量空间中距离很近,因为它们共享相似的语义邻域。但专有名词在嵌入空间中的表现截然不同------"OpenAI"和"Anthropic"在语义上都是 AI 公司,向量距离可能很近,但你搜 OpenAI 时绝不希望召回 Anthropic 相关的记忆。反过来,"React"作为框架名和"react"作为动词,向量可能完全重合,但语义南辕北辙。
向量搜索在处理专有名词时,本质上是在用"模糊相似度"做"精确匹配"的活,力不从心。
来一个更具体的例子。用户告诉 Mem0:"我的狗叫 Poppy,它最喜欢追球"。这条记忆被存储后,向量嵌入编码的是整句话的语义------"宠物""狗""玩耍"。现在用户问:"Poppy 最近怎么样?"
问题来了。"Poppy"是一个人名嵌入。在向量空间中,"Poppy"的嵌入与"狗""宠物""追球"这些词的嵌入距离很远。向量搜索会在语义空间中寻找与"Poppy"最近的记忆向量,但它找到的可能是关于花(poppy 是罂粟花)的记忆,或者是名字中恰好包含"Poppy"的其他无关记忆。而那条"我的狗叫 Poppy"的记忆,因为"Poppy"只占整句话的一小部分,在向量中权重极低,语义分数很可能排在十名开外。
这就是专有名词的致命问题:它在嵌入空间中没有"锚定力"。一个名字在句子中只是一个小小的 token,但它恰恰是用户检索的入口。向量搜索在全局语义上可能很准,但在局部专有名词上却近乎失明。
盲区二:关键词精确匹配差。
BM25 部分解决了这个问题,但它依赖于字面分词的精确命中。"GPT-4"和"GPT4"是同一个东西,BM25 无法关联;"Kubernetes"和用户查询中的"k8s"更是天差地别。词形变化、缩写、别名------这些在自然语言中极为常见的现象,BM25 无能为力。
再回到 Poppy 的例子。BM25 能匹配到"Poppy"吗?如果用户的记忆原文是"我的狗叫 Poppy",查询是"Poppy",BM25 确实能命中。但这要求原文和查询中"Poppy"的字面完全一致。如果用户记忆中写的是"Poppy(我家的金毛)",而查询是"我的 Poppy",BM25 的分词可能把括号打断匹配。更常见的情况是,用户的记忆中根本没有出现"Poppy"这个词------用户说的是"我家那只金毛最近不太吃东西",而"Poppy"这个实体只出现在另一条记忆中。BM25 对这种跨记忆的实体关联完全无能为力。
盲区三:跨记忆关联无法表达。
假设用户说过三条记忆:
- "我在 Tesla 工作"
- "Tesla 的自动驾驶技术很前沿"
- "我打算买一辆 Model Y"
在向量搜索中,这三条记忆的向量可能散落在不同区域(工作、技术、购物)。但如果用户问"告诉我关于 Tesla 的事",你期望全部召回。现有机制缺少一种方式来表达:"这三条记忆都锚定在 Tesla 这个实体上"。
这就是 Entity Store 要解决的核心问题:建立一个以实体为锚点的记忆关联网络。
让我们把三个盲区串起来看一个完整的故障场景。用户告诉系统五条记忆:
- "Poppy 是我养的狗,一只金毛"
- "Poppy 最喜欢在公园追球"
- "上周带 Poppy 去看了兽医"
- "金毛犬的平均寿命是 10-12 年"
- "我工作很忙,经常加班到很晚"
现在用户问:"Poppy 的健康状况怎么样?"
向量搜索会怎么工作?它把"Poppy 的健康状况"嵌入为向量,然后在记忆向量中搜索最近邻。记忆 1 包含"Poppy"和"狗",语义分数可能中等;记忆 3 包含"兽医",与"健康状况"语义相关,但"Poppy"在其中权重低;记忆 4 讨论金毛寿命,与"健康状况"语义相关,但完全没有"Poppy"。最终,最相关的记忆 3 可能排在第 3-4 位,被 top-k 截断丢弃。
而有了 Entity Store,情况完全不同。记忆 1、2、3 都被链接到"Poppy"这个实体记录上。查询"Poppy 的健康状况"时,实体提取从查询中识别出"Poppy",搜索 Entity Store 命中"Poppy"实体,读取 linked_memory_ids,记忆 1、2、3 全部获得 Entity Boost。记忆 3("兽医"那条)的语义分数本身就不低,加上 Entity Boost 后直接冲到 top-1。
这就是 Entity Store 的价值:它不是替代语义搜索,而是在语义搜索"看不见"的地方打一束聚光灯。
Entity Store 的架构
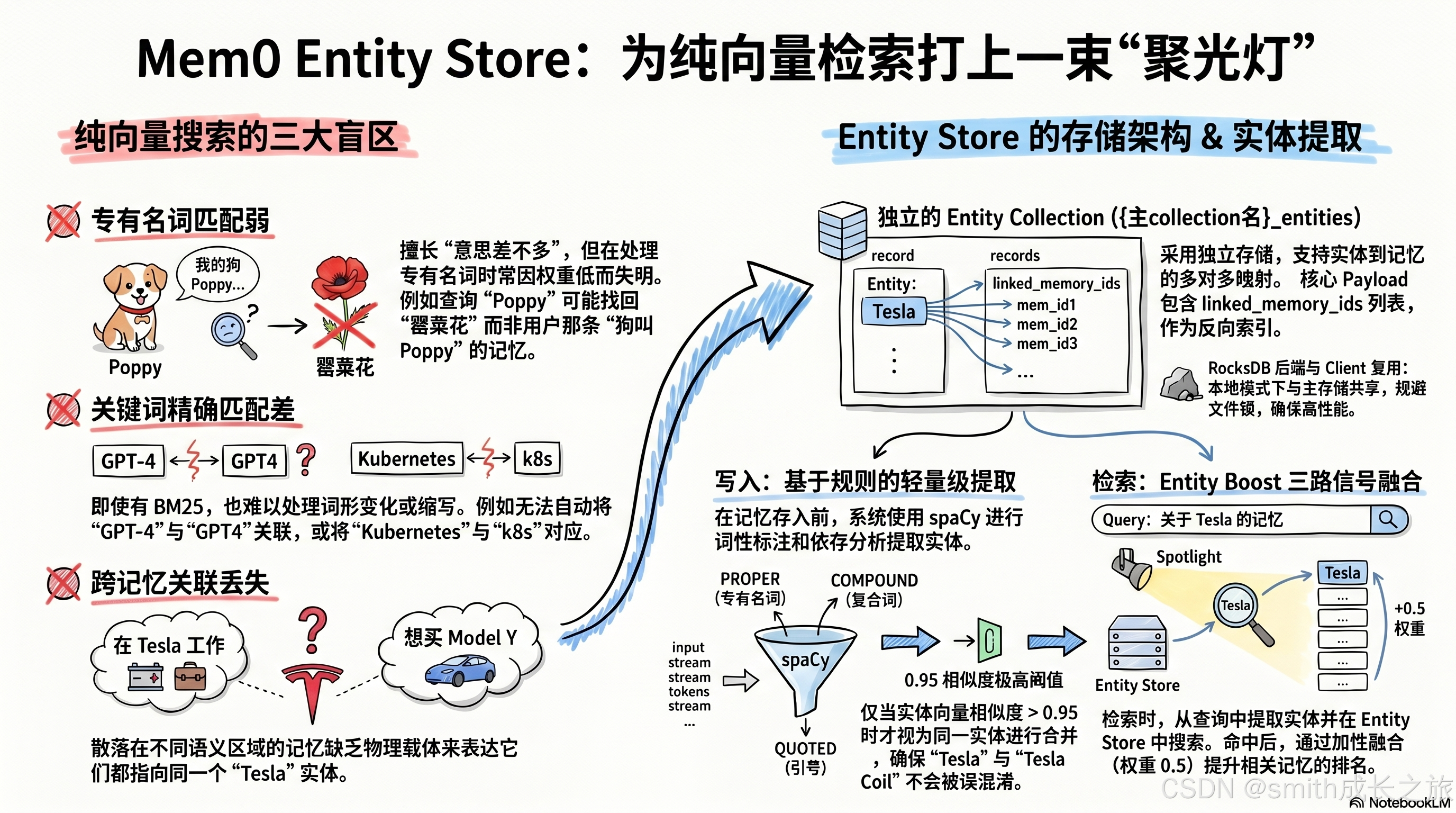
Entity Store 架构:纯向量搜索的三大盲区与实体存储结构
Entity Store 并不是一个全新的数据库,而是复用了 Mem0 已有的向量存储基础设施。它是一个独立的 collection,命名规则为 {主collection名}_entities。
为什么独立 collection 而不是在记忆记录上加字段? 因为实体和记忆是多对多关系------一个实体可以被多条记忆提及,一条记忆也可以包含多个实体。如果做成字段,要么冗余存储(每条记忆都带上所有实体的完整信息),要么嵌套查询(先查实体再反向关联记忆),都不如独立 collection 来得干净。
但这个解释还不够深入。让我们追问:多对多关系可以用关联表解决,为什么一定要用独立的向量 collection?
答案在于检索方式。Entity Store 不仅需要按实体文本精确查找,还需要按实体嵌入做相似度搜索(比如"Poppy"和"poppy"的嵌入可能很接近,但字面不同)。如果实体信息只存在记忆记录的字段中,你就只能在记忆的向量空间中搜索实体------但记忆的向量编码的是整句话的语义,不是实体本身的语义。你需要在实体的向量空间中搜索实体,这要求实体有自己独立的嵌入和索引。
换一个角度:如果你把实体信息存为记忆 payload 的一个数组字段,当新记忆提及"Tesla"时,你需要遍历所有记忆的实体字段来查找是否已有"Tesla"实体。这是 O(N) 的全表扫描,而独立 collection 的向量搜索是 O(log N) 甚至亚线性的 HNSW 查找。在百万级记忆的场景下,这个差异是秒级和毫秒级的区别。
还有一个被忽视的原因:隔离故障域。Entity Store 的写入失败不应该影响记忆的增删改核心路径。如果实体和记忆共享同一个 collection,实体的向量写入失败可能触发 collection 级别的异常(比如 Qdrant 的 WAL 损坏),波及记忆数据。独立 collection 把实体操作的故障隔离在自己的空间内。
Entity Store 中每条记录的 payload 结构:
{
"data": "Tesla", # 实体文本
"entity_type": "PROPER", # 实体类型
"linked_memory_ids": [ # 关联的记忆 ID 列表
"mem_001",
"mem_002",
"mem_003"
],
"user_id": "user_123" # 作用域过滤
}关键字段是 linked_memory_ids------它就是那个"跨记忆关联"的物理载体。通过这个列表,Entity Store 建立了从实体到记忆的反向索引。
懒初始化 是 Entity Store 的另一个设计细节。它通过 entity_store 属性实现延迟加载:只有在第一次真正需要实体操作时才初始化。如果用户的查询不触发实体提取,或者 spaCy 不可用,Entity Store 就永远不会创建。这避免了无谓的资源开销。
懒初始化的工程实现值得细看。_entity_store 在构造函数中被设为 None,只有在第一次访问 self.entity_store 属性时才触发创建。创建过程会深拷贝主存储的配置,修改 collection 名为 {主collection名}_entities,然后用 VectorStoreFactory.create() 生成实例。这意味着 Entity Store 和主存储使用相同的向量库提供商(Qdrant、Chroma、PGVector 等)和相同的嵌入维度,但拥有独立的索引和 payload schema。
初始化时还有一个工程细节值得注意:对于 Qdrant 向量库,Entity Store 会复用主存储的 client 对象,而不是创建新连接。原因是 Qdrant 的嵌入式模式(path=...)使用 RocksDB 作为后端,RocksDB 不允许多进程同时打开同一个数据库(文件锁冲突)。共享 client 规避了这个问题。这个细节看似微不足道,但在本地部署场景下,如果你不共享 client,Entity Store 初始化时会直接抛出 RocksDB 锁冲突异常,整个记忆系统不可用。
为什么用 spaCy 而不是更"高级"的 NER 模型?
实体提取的核心在 entity_extraction.py,它使用 spaCy 的 NLP 管线,定义了四类提取规则。看到这里,很多人会问:为什么不直接用 spaCy 内置的 NER 模型?或者用更"先进"的深度学习 NER(如 spaCy 的 transformer 模型、HuggingFace 的 BERT-NER、甚至 LLM-based NER)?
这是一个好问题,答案藏在工程约束里。
先看最直接的选项------spaCy 内置 NER。en_core_web_sm 确实自带 NER 组件,能识别 PERSON、ORG、GPE、PRODUCT。但它的训练数据是 OntoNotes,一个新闻语料为主的数据集。用户对话里的非正式实体------项目名、技术术语、宠物名------根本不在它的识别体系内。"Poppy"作为人名也许能命中,但作为宠物名几乎不可能。"machine learning"作为技术术语不在 OntoNotes 的实体类型中。更致命的是,NER 是黑盒------它漏掉一个实体,你没有修复手段,只能换模型。所以,精度不够,而且不可修补。
那就换精度更高的模型。spaCy 的 transformer 模型(en_core_web_trf)精度确实上去了,但代价也上去了------模型从 12MB 跳到 400MB+,推理延迟从毫秒级跳到百毫秒级。记忆写入是热路径,每条记忆都要跑一次 NER,百毫秒的延迟不可接受。更不用说 GPU 依赖------大多数 Mem0 的部署环境根本没有 GPU。所以,精度问题解决了,但工程代价把这条路也堵死了。
那就用精度最高的方案------LLM。但精度最高的方案,成本也最高。每次记忆写入都要调一次 LLM,批量写入 10 条记忆就是 10 次 LLM 调用,即使是最便宜的小模型,成本也远超 spaCy。而且 LLM 输出不稳定,同样的输入可能产出不同格式的实体列表,还需要额外的后处理来兜底。所以,三条路都走不通------精度不够的不可修补,精度够的不可部署,精度最高但成本和稳定性都不可控。
结论:只能在一个轻量工具上自建规则。
Mem0 的选择:基于规则的实体提取 + spaCy 的语言学分析。
Mem0 没有使用 spaCy 的 NER 组件,而是使用了 spaCy 的词性标注(POS tagger)、依存分析(dependency parser)和名词短语切分(noun chunks)。这些都是确定性的语言学分析,不依赖统计模型的概率输出,因此可控、可预测、可调试。
具体来说,Mem0 利用了 spaCy 的三个能力:
- 词性标注:识别 PROPN(专有名词)、NOUN(名词)、ADJ(形容词)、VERB(动词)等词性,作为实体提取的信号
- 依存分析:识别 compound(复合修饰)、amod(形容词修饰)、poss(所有格)等语法关系,用于拆分和组合实体
- 名词短语切分 :
noun_chunks提供现成的名词短语边界,作为 COMPOUND 类型实体的基础
这三个能力是 spaCy 的"基础设施",不是 NER 的"应用层"。Mem0 在这些基础设施上构建了自己的规则引擎,比 NER 更灵活、更可控、更快。
权衡是明确的:规则引擎的召回率不如 NER 模型(它无法识别"New York"是一个 GPE,除非"New York"是大写序列),但精确率更高(它不会把"the company"误识别为 ORG),延迟更低(毫秒级 vs 百毫秒级),且完全可解释。对于记忆系统来说,精确率比召回率更重要------错误提取一个实体比漏掉一个实体的危害更大,因为错误实体会产生虚假的跨记忆关联,污染检索结果。
spaCy 四类实体提取规则
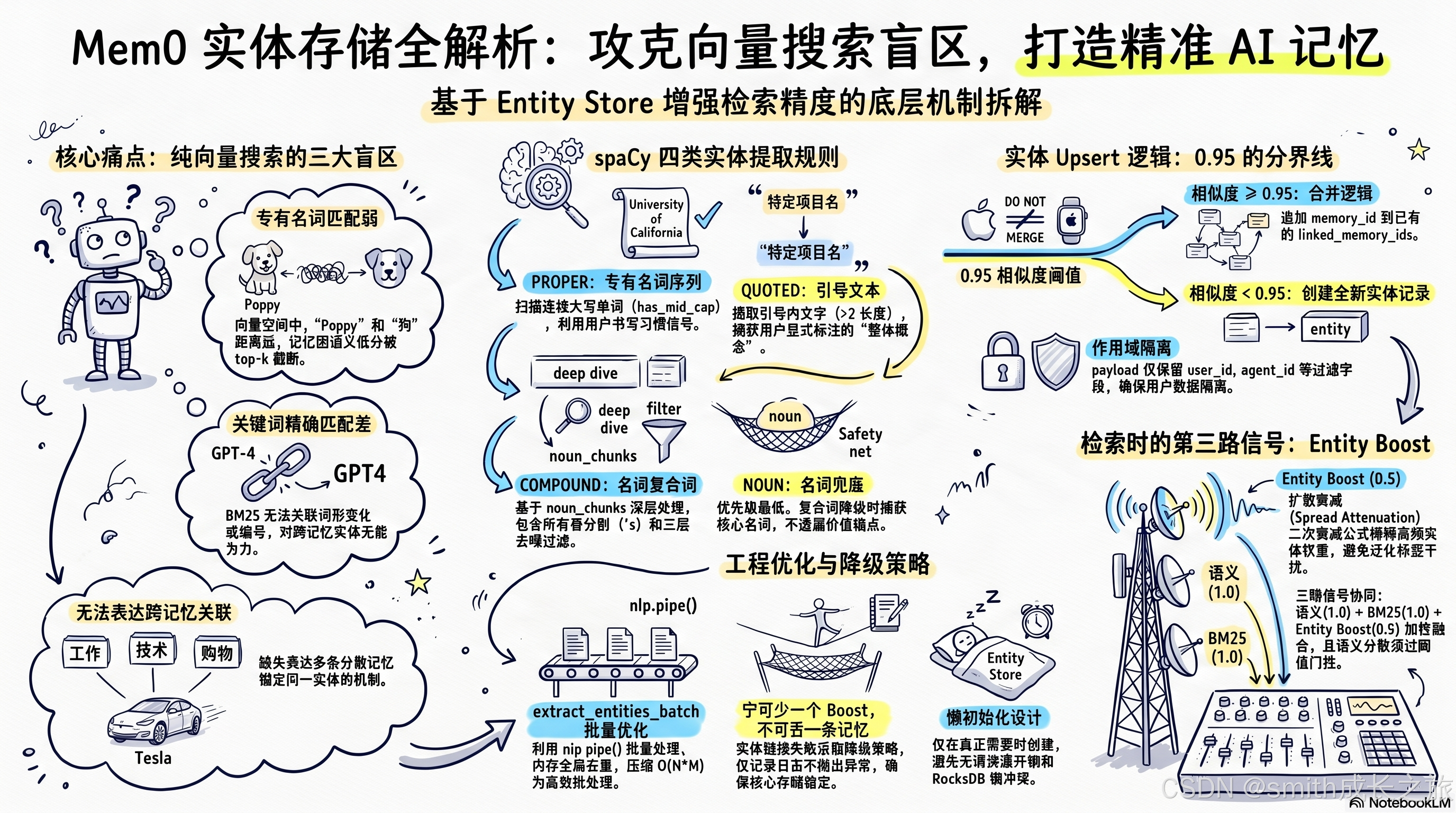
spaCy 四类实体提取规则 + Upsert 0.95 分界线
实体提取的核心在 entity_extraction.py,它使用 spaCy 的 NLP 管线,定义了四类提取规则,按优先级从高到低:
PROPER------专有名词序列。
扫描连续的大写单词序列,要求序列中至少有一个非句首的大写词(has_mid_cap),排除句首因语法规则而大写的情况。同时跳过后面紧跟冒号的词(如 "Summary:" 这种标题标记)。
连续序列中允许穿插小写虚词('s, of, the, in, and, for, at, is),如 "University of California" 会被完整提取。尾部虚词会被自动裁剪,避免出现 "Tesla and" 这种不完整的实体。
PROPER 规则的核心设计哲学是:大写是用户标注专有名词的方式。在英文中,用户写 "Tesla" 而不是 "tesla",写 "Poppy" 而不是 "poppy",这本身就是一种信号。spaCy 的 POS tagger 会把这些词标为 PROPN,但 Mem0 不依赖 POS 标签------它直接看大写。原因很简单:POS tagger 在非正式文本中经常把专有名词误标为普通名词(尤其是宠物名、项目名等不在训练集中的词),但大写是用户自己的标注,更可靠。
has_mid_cap 检查是关键的去噪机制。句首的词因为语法规则而大写("The dog is cute"),这不是专有名词。只有序列中间出现大写词("University of California" 中的 "California"),才能确认这是专有名词序列。这个检查通过 _is_sentence_start 函数实现,它不仅检查句法边界(句号、感叹号),还检查格式标记(Markdown 的 *、-、#),适应了用户输入中常见的非正式格式。
QUOTED------引号文本。
正则匹配双引号和单引号内的文本,长度需大于 2 字符。单引号匹配要求引号前后有标点或空白边界,避免误匹配英文缩写(如 it's)。引号文本天然是用户强调的专有概念------项目名、书名、特定术语。
QUOTED 规则的设计哲学是:引号是用户显式标注"这是一个整体"的方式。当用户说"我在做'Project Aurora'",引号明确告诉系统:这是一个专有概念,不要拆开。这比 NER 模型的概率判断更可靠。
但引号匹配有一个陷阱:英文中单引号的使用非常随意,it's、don't、'90s 都包含单引号。Mem0 的正则表达式要求单引号前后有标点或空白边界,这排除了缩写但保留了真正的引号文本。比如 'Project Aurora' 前后有空格,匹配成功;it's 中的 's 前面是字母,不匹配。
COMPOUND------名词复合词。
基于 spaCy 的 noun_chunks(名词短语)进行分析,这是四类规则中最复杂的一类。它做了以下处理:
-
所有格分割 :遇到
's结构时,将名词短语拆分为所有者和所有物两组。如 "Tesla's Autopilot" 拆为 "Tesla" 和 "Autopilot"。 -
泛化过滤:这是核心的去噪机制。定义了三组过滤词表:
_GENERIC_HEADS(泛化中心词):thing, stuff, way, time, method... 如果名词短语的中心词是这些泛化词,且没有特指性修饰语或复合修饰语,直接丢弃。"a good way" 不是实体,"machine learning" 才是。_CIRCUMSTANTIAL_MODS(情景修饰词):solo, first, main... 如果复合词中只有情景修饰词,降级提取中心名词本身,而非整个复合词。"first step" 提取 "step"(类型为 NOUN),"machine learning" 提取完整短语(类型为 COMPOUND)。_NON_SPECIFIC_ADJ(非特指形容词):many, good, new, important... 这些形容词太泛化,不足以让名词短语变成特指实体。"important technique" 不提取,"neural network" 提取。
-
尾部裁剪 :
_strip_generic_ending函数去除复合词尾部的泛化词(work, job, task, stuff, info...),但至少保留两个词。如 "machine learning technique" 裁剪为 "machine learning"。 -
动词中心词回退 :spaCy 有时会将名词性复合词的中心词误标为 VERB(如 "machine learning" 的 learning)。代码检测
VERB+compound依存结构,对泛化动词中心词只保留其复合修饰语,对非泛化动词中心词保留完整短语。
COMPOUND 规则的核心挑战是去噪 。spaCy 的 noun_chunks 会返回大量名词短语,其中绝大多数不是实体------"a good way"、"the first step"、"many things"------这些是语言的结构性产物,不是用户想强调的概念。三层过滤词表(_GENERIC_HEADS、_CIRCUMSTANTIAL_MODS、_NON_SPECIFIC_ADJ)加起来约 100 个词,覆盖了英语中最常见的泛化表达。
为什么不用机器学习来做这个过滤?因为词表的精确率远高于分类器。泛化词的判定是确定性的------"thing" 在任何语境下都不是实体------机器学习模型在这里只会引入噪声。词表的维护成本也很低,每季度 review 一次误提取的实体,补充几个新词即可。
NOUN------名词兜底。
当复合词的中心词只有情景修饰词时,降级提取中心名词本身。这是优先级最低的实体类型,在去重阶段会被 COMPOUND 和 PROPER 覆盖。
NOUN 类型的存在是为了捕获被情景修饰词"污染"的名词短语中的核心名词。"first step" 的中心词 "step" 本身可能是有价值的实体(在一个关于流程管理的记忆系统中),但 "first step" 作为一个整体太泛化。NOUN 类型只保留 "step",让后续的向量搜索来决定它是否真的与查询相关。
最终去重:对提取结果按小写去重,保留优先级最高的类型(PROPER > COMPOUND > QUOTED > NOUN),并移除是其他实体子串的短实体。
子串移除的逻辑很重要。如果提取了 "University" 和 "University of California",保留后者、移除前者。因为 "University" 作为短实体太泛化,而且 "University of California" 已经包含了它的信息。但如果提取了 "Tesla" 和 "Tesla Coil",两者都会保留------因为 "Tesla" 不是 "Tesla Coil" 的语义子集,它们是完全不同的实体。
实体 Upsert 逻辑:0.95 的分界线
实体写入 Entity Store 的核心逻辑在 _upsert_entity 方法中,关键决策点是 0.95 的相似度阈值:
嵌入实体文本 → 在 Entity Store 中搜索 →
若最高分 >= 0.95 → 合并 linked_memory_ids
若最高分 < 0.95 → 新建实体记录0.95 是一个极高的阈值。这意味着两个实体文本必须在嵌入空间中几乎重合才会被视为同一个实体。为什么这么高?因为实体天然需要精确匹配------"Tesla"(公司)和"Tesla Coil"(装置)虽然共享 "Tesla",但完全不是同一个东西。低阈值会导致实体过度合并,破坏关联的准确性。
让我们深入推演 0.95 阈值背后的权衡。
如果阈值太低(比如 0.7) :考虑 "Apple"(公司)和 "Apple Watch"(产品)。它们的嵌入相似度可能达到 0.75-0.80。如果阈值是 0.7,"Apple Watch" 会被合并到 "Apple" 实体上,导致查询 "Apple Watch" 时,所有关于 Apple 公司的记忆都会被 boost。这不仅是召回噪声,更严重的是关联污染 ------一个实体的 linked_memory_ids 被不相关的记忆稀释,后续所有通过这个实体做的检索都会受到影响。
如果阈值太高(比如 0.99):考虑 "GPT-4" 和 "GPT4"。它们的嵌入相似度可能在 0.93-0.96 之间------取决于嵌入模型对连字符的敏感度。如果阈值是 0.99,这两个永远会被视为不同实体,产生重复记录。更严重的是,查询 "GPT4" 无法命中 "GPT-4" 的实体记录,Entity Boost 失效。
0.95 的位置:它恰好落在"几乎相同"和"可能相关"的分界线上。两个文本的嵌入相似度达到 0.95,通常意味着它们是同一个词的不同形态(大小写、空格差异)或者是完全相同的文本。0.95 以下开始出现"相关但不同"的实体对。这个阈值在大多数嵌入模型上都能区分"Tesla"和"Tesla Coil"(相似度约 0.85-0.90),同时容忍"GPT-4"和"GPT4"的微小差异(相似度约 0.93-0.97)。
但 0.95 不是银弹。它无法处理跨语言的实体等价("Beijing"和"北京"),也无法处理语义等价但字面完全不同的别名("Elon Musk"和"马斯克")。这些场景需要 Entity Boost 的 0.5 搜索阈值来兜底------写入时 0.95 保证了精确合并,检索时 0.5 保证了模糊匹配。
当判定为同一实体时,memory_id 被追加到 linked_memory_ids,但不更新向量。这是合理的------实体文本不变,向量就不需要变。但这里有一个微妙的点:linked_memory_ids 的增长改变了实体的"语义权重"(关联记忆越多,Entity Boost 的扩散衰减越大),但这个权重变化是在检索时动态计算的,不需要预存储。
新建实体时,payload 中记录实体文本、类型、关联记忆 ID 和作用域过滤字段,向量使用实体文本自身的嵌入。注意 search_filters 的过滤逻辑------它只保留 user_id、agent_id、run_id 三个字段,确保实体搜索在正确的作用域内进行。这避免了用户 A 的 "Tesla" 实体被用户 B 的查询命中。
实体链接失败时的降级策略
_upsert_entity 的整个方法体被 try/except 包裹,异常被 logger.warning 记录但不向上抛出。这不是疏忽,这是刻意的降级设计。
Entity Store 的定位是检索增强设施,不是存储核心路径。如果实体写入失败(嵌入模型超时、向量库连接异常、payload 格式错误),记忆本身仍然应该成功写入。检索时,即使没有 Entity Boost,语义搜索和 BM25 仍然能工作------只是精度差一些。
降级策略的层次结构:
-
spaCy 不可用 :
extract_entities返回空列表,不触发任何实体操作。Entity Store 永远不会被初始化。检索时query_entities为空,_compute_entity_boosts返回空字典。系统退化为纯语义 + BM25 双路检索。 -
单条实体 upsert 失败 :
_upsert_entity的except捕获异常,记录 warning,跳过该实体。其他实体继续处理。一条记忆可能提取出 5 个实体,其中 3 个成功、2 个失败,失败的 2 个不会影响成功的 3 个。 -
整条记忆的实体链接失败 :
_link_entities_for_memory的外层try/except捕获extract_entities本身的异常(比如 spaCy 模型加载失败),记录 warning,不影响记忆写入。 -
Entity Store 搜索失败 :
_compute_entity_boosts的try/except捕获搜索异常,返回空字典。检索时退化为无 Entity Boost 的双路融合。 -
实体清理失败 :
_remove_memory_from_entity_store中,每条实体记录的清理都有独立的try/except(debug 级别),外层还有整体try/except(warning 级别)。清理失败的实体记录会变成孤儿------linked_memory_ids中包含已删除的记忆 ID,但这些 ID 在检索时不会被匹配(因为记忆向量已不存在),所以不会产生误召回,只是 Entity Store 中有冗余数据。
这个降级策略的哲学是:宁可少一个 boost,不可丢一条记忆。Entity Store 是锦上添花,不是生死攸关。
批量优化:extract_entities_batch
单条记忆的实体提取使用 extract_entities,逐条调用 spaCy 的 nlp() 方法。但在 add() 的批量写入路径中,Mem0 做了精心优化:
-
批量 NER :使用
extract_entities_batch,底层调用 spaCy 的nlp.pipe(),以batch_size=32批量处理文本,避免逐条加载的管线开销。 -
全局去重 :先收集所有记忆中的实体,按 normalized key 去重,相同实体只处理一次。如两条记忆都提到 "Tesla",只会产生一个实体记录,
linked_memory_ids合并。 -
批量嵌入 :调用
embed_batch()一次性嵌入所有唯一实体文本。 -
批量搜索 :调用
search_batch()一次性查找所有实体的已有匹配。 -
分离写入 :将搜索结果分为"需要更新的"和"需要新建的"两组,新建组使用单次
insert()批量写入。
这个批量路径把 O(N*M) 的逐条操作(N 条记忆 × M 个实体)压缩为 O(M) 的批操作,在大量记忆同时写入时效果显著。
批量路径的全局去重值得细看。当两条记忆都提到 "Tesla" 时,逐条路径会搜索两次 Entity Store、执行两次 upsert。批量路径只搜索一次、只执行一次 upsert,linked_memory_ids 中直接包含两条记忆的 ID。这不仅减少了 I/O,还避免了并发写入时的竞态条件------如果两个 upsert 同时读取 "Tesla" 实体的 linked_memory_ids,各自追加一个 memory_id,后写入的会覆盖先写入的,导致丢失一个关联。批量路径在内存中完成合并,只写一次,消除了竞态。
但批量路径也有代价:代码复杂度。它需要维护全局实体映射表、分离更新组和新建组、处理批量搜索的异常------这些逻辑在逐条路径中不需要。Mem0 选择在 add() 的高频路径(批量写入)使用复杂但高效的批量路径,在 update() 和 delete() 的低频路径使用简单但较慢的逐条路径。这是典型的工程权衡:在热路径上优化性能,在冷路径上优化可维护性。
链接与清理:实体的生命周期
实体与记忆的关联不是一次性的,它需要跟随记忆的生命周期维护。
写入时链接 :_link_entities_for_memory 是单条记忆的实体链接入口,在 add() 和 update() 中被调用。它提取实体文本后逐个调用 _upsert_entity。
更新时重链接 :当记忆内容被更新时,流程是:先调用 _remove_memory_from_entity_store 清除旧文本的实体关联,再调用 _link_entities_for_memory 建立新文本的实体关联。这保证了实体关联始终反映记忆的当前内容。
更新时重链接的因果推演:假设记忆从 "我在 Tesla 工作" 更新为 "我在 SpaceX 工作"。如果不先清除旧关联,"Tesla" 实体的 linked_memory_ids 中仍然包含这条记忆的 ID。当用户查询 Tesla 相关信息时,这条实际上已经与 Tesla 无关的记忆会获得 boost,产生误召回。所以先删后建是必须的,不是可选的。
删除时清理 :_remove_memory_from_entity_store 遍历所有在 filters 作用域内的实体记录,将 memory_id 从 linked_memory_ids 中移除。如果移除后列表为空,直接删除该实体记录;否则更新 payload 和向量。
这个清理过程有一个值得注意的设计决策:它使用 list(filters=top_k=10000) 全量扫描而非搜索。因为清理不需要相似度匹配,只需要精确过滤------找到所有包含目标 memory_id 的实体记录。虽然 10000 的上限看起来粗暴,但实体数量通常不会达到这个量级,且这是一次性操作而非热路径。
为什么不用搜索来清理?因为搜索是"给定文本,找相似向量",而清理是"给定 ID,找包含该 ID 的 payload"。这是两种完全不同的查询模式,向量搜索对后者无能为力。全量扫描 + payload 过滤是唯一可行的方案。如果未来实体数量增长到百万级,可能需要引入反向索引(memory_id → entity_ids),但目前的规模下全量扫描足够。
所有实体操作的异常都被静默处理(logger.debug 或 logger.warning),不会中断主流程。这是刻意的设计------Entity Store 是增强检索的辅助设施,它的失败不应该影响记忆的增删改核心路径。
Entity Boost:检索时的第三路信号
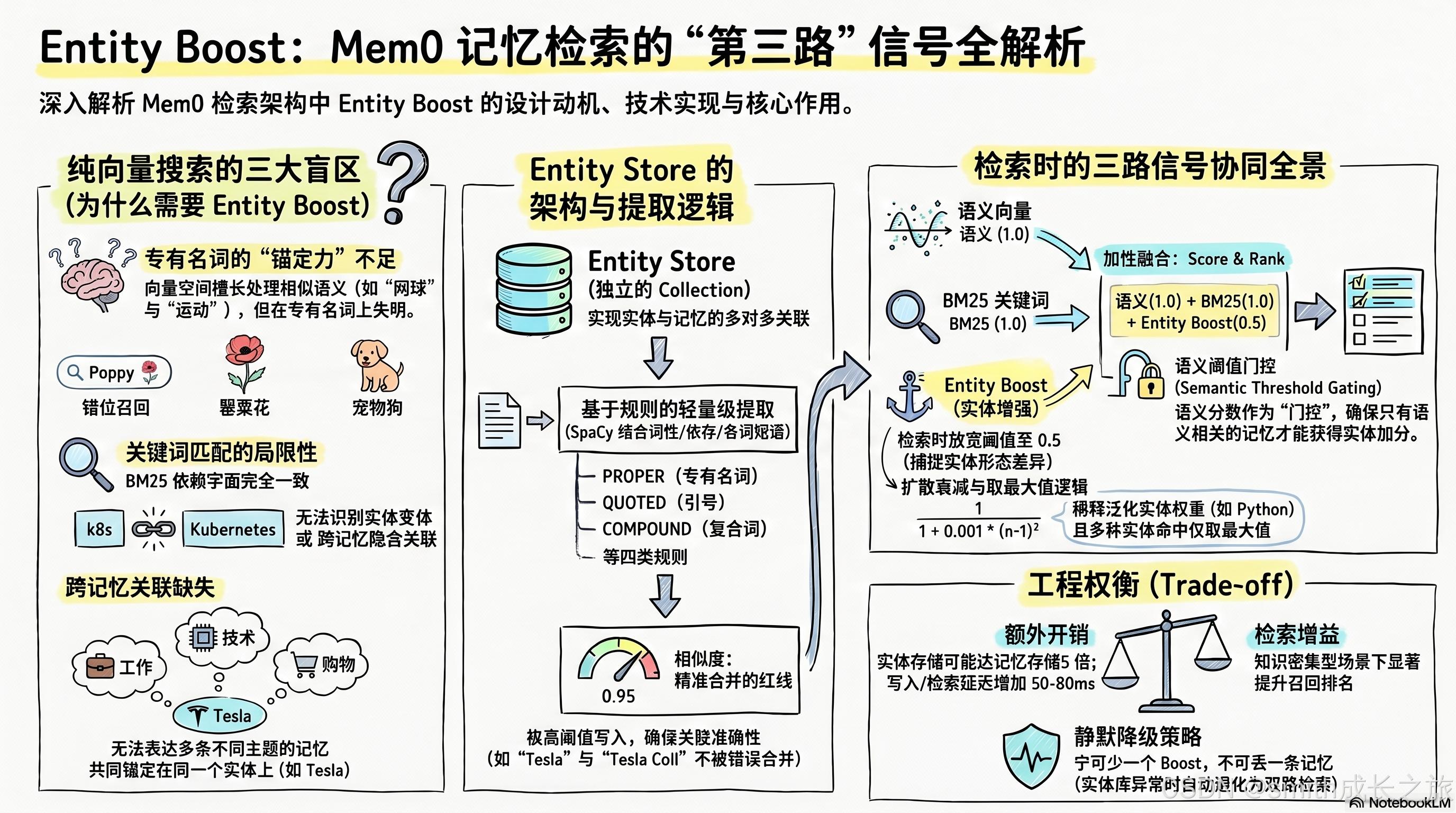
Entity Boost 第三路信号与三路协同全景
Entity Store 的价值最终体现在检索时。在 _search_vector_store 方法中,检索管线分为三步:
- 语义向量搜索(semantic)
- BM25 关键词搜索(keyword)
- Entity Boost 计算
Entity Boost 的计算逻辑在 _compute_entity_boosts 中:
提取查询实体(最多8个)→ 逐个嵌入 → 搜索 Entity Store(top_k=500, 阈值0.5)→
对每个匹配的实体 → 读取 linked_memory_ids →
计算单条 boost = similarity × 0.5 × memory_count_weight
其中 memory_count_weight = 1 / (1 + 0.001 × (num_linked - 1)²)这里有几个精巧的设计,每一个都值得深入追问。
为什么查询实体限制 8 个? 查询通常比记忆短得多,提取出的实体数量也少。但有些查询可能很长("告诉我关于 Tesla、SpaceX、Neuralink、Boring Company、xAI 的信息"),提取出大量实体。如果不限制数量,每个实体都要嵌入 + 搜索 Entity Store,延迟线性增长。8 个实体的嵌入 + 搜索大约需要 50-100ms(取决于向量库延迟),对用户体验影响可接受。超过 8 个实体的查询极其罕见,即使截断也不会显著影响检索质量。
为什么搜索阈值是 0.5 而不是 0.95? 写入时 0.95 是为了保证精确合并,但检索时 0.5 是为了模糊匹配。考虑用户查询 "poppy"(小写),而 Entity Store 中存储的是 "Poppy"(大写)。嵌入模型对大小写的敏感度不同,有些模型 "poppy" 和 "Poppy" 的相似度可能只有 0.7-0.8。如果检索阈值也是 0.95,这个查询就无法命中实体记录。0.5 的阈值宽松地捕获所有可能的实体匹配,然后通过扩散衰减和取最大值来抑制噪声。
扩散衰减(Spread Attenuation) :如果一个实体关联了大量记忆(比如 "Python" 可能关联了几百条),它的 boost 应该被稀释。否则,一个泛化实体会不成比例地提升大量无关记忆的排名。衰减公式 1 / (1 + 0.001 × (n-1)²) 是一个温和的二次衰减------当关联 10 条记忆时权重约 0.99,100 条时约 0.5,300 条时约 0.1。
为什么是二次衰减而不是线性衰减?线性衰减 1/n 的下降速度太快------"Python" 关联 10 条记忆时权重就降到了 0.1,但 "Python" 可能确实是一个重要的实体,10 条关联记忆应该获得比 0.1 更高的权重。二次衰减 1/(1+0.001*(n-1)²) 在前 30 条记忆内衰减缓慢(权重 > 0.9),100 条之后才快速下降。这反映了 Mem0 的判断:少量关联的实体是"精确锚点",应该获得高权重;大量关联的实体是"泛化标签",应该被稀释。中间过渡区(30-100 条)是平滑的,不会产生突变。
取最大值而非累加 :多条实体可能 boost 同一条记忆,代码取 max 而非 sum。这避免了多实体对同一记忆的过度提升。
为什么取 max 而不是 sum?考虑查询 "Tesla Model Y",提取出 "Tesla" 和 "Model Y" 两个实体。如果一条记忆同时提到了 Tesla 和 Model Y,sum 策略会给它 2 倍的 boost,可能导致它超过语义上更相关的记忆。而 max 策略只取最强的 boost,确保 Entity Boost 不会让一条记忆"跳过"语义上更匹配的结果。Entity Boost 的定位是辅助信号,不是主信号------它应该把"相关但排名靠后"的记忆拉上来,而不是让"不太相关但命中多个实体"的记忆冲到最前面。
最终,三路信号在 score_and_rank 中通过加性融合合并:
combined = (semantic + bm25 + entity_boost) / max_possiblemax_possible 根据激活的信号数量动态调整:纯语义为 1.0,语义+BM25 为 2.0,语义+Entity 为 1.5,三路全开为 2.5。Entity Boost 的权重固定为 0.5,相比语义(1.0)和 BM25(1.0)是辅助性的。
重要的一点:语义阈值门控在融合之前。即使 BM25 和 Entity Boost 能把分数拉上来,如果语义分数低于 threshold,候选直接被排除。这保证了 Entity Boost 是"锦上添花"而非"雪中送炭"------它只能提升已经语义相关的记忆,不能拯救无关的记忆。
这个门控设计是深思熟虑的。如果允许 Entity Boost 把语义无关的记忆拉上来,会出现什么问题?考虑一条记忆 "Tesla 的股票今天涨了 5%",用户查询 "Poppy 的健康状况"。如果 "Tesla" 和 "Poppy" 在某个奇怪的嵌入空间中恰好相似度 > 0.5,Entity Boost 可能会给这条记忆加 0.3 分。没有语义门控的话,这条完全无关的记忆可能混入 top-k 结果。语义门控确保了:只有语义分数已经通过阈值的候选,才有资格获得 Entity Boost。Entity Boost 只改变排名,不改变候选集。
额外开销 vs 检索增益
Entity Store 不是免费的午餐。它的代价包括:
存储开销 :每个实体需要一条独立的向量记录,包含嵌入向量、payload 和索引。对于包含大量专有名词的用户记忆,实体数量可能接近甚至超过记忆本身。以 OpenAI 的 text-embedding-3-small 为例,1536 维的 float32 向量占 6KB,加上 payload 和索引开销,每个实体约 8-10KB。
一个更具体的估算:一个知识工作者一个月的对话中,可能产生 500 条记忆、2000 个实体。记忆存储约 3MB(500 × 6KB),实体存储约 16MB(2000 × 8KB)。实体的存储开销是记忆的 5 倍。在本地部署场景下(Qdrant 嵌入式模式),这意味着磁盘占用和内存占用都显著增加。在云端部署场景下,这意味着向量库的计费记录数翻倍。
计算开销 :每次 add() 都要运行 spaCy NER(即使 extract_entities_batch 已经做了优化),每次都要额外嵌入实体文本。检索时,Entity Store 的搜索是额外的 I/O 和计算。
来一个延迟估算:spaCy 的 nlp.pipe() 处理一条记忆约 2-5ms,嵌入一个实体文本约 10-20ms(取决于嵌入模型),搜索 Entity Store 约 5-10ms(HNSW 索引)。一条记忆平均提取 3 个实体,实体相关的总延迟约 50-80ms。在 add() 的总延迟中(LLM 调用 500ms+),这个开销占比约 10%。可接受,但不是零。
一致性维护:记忆更新和删除时需要同步清理 Entity Store,增加了写入路径的复杂度和延迟。
那么增益呢?Entity Boost 的最大贡献权重是 0.5(在 max_possible=2.5 的三路融合中占比 20%),它对最终排名的影响是有限的。但对于包含专有名词的查询,这 20% 可能就是"相关记忆排第 3"和"排第 1"的区别------在 top-k 召回场景中,这个差异至关重要。
更深层的价值在于跨记忆关联。没有 Entity Store,"关于 Tesla 的事"只能靠语义搜索的模糊匹配来召回所有相关记忆。有了 Entity Store,只要查询实体命中了 "Tesla" 这条实体记录,所有 linked_memory_ids 中的记忆都会获得 boost。这种"实体锚点 → 记忆扩散"的召回模式,是纯语义搜索无法实现的。
让我们回到开头的 Poppy 例子,做一次完整的因果推演:
-
写入阶段:"我的狗叫 Poppy,它最喜欢追球" → spaCy 提取出 PROPER("Poppy") → 嵌入 "Poppy" → Entity Store 中搜索,无匹配 → 新建实体记录 {data: "Poppy", entity_type: "PROPER", linked_memory_ids: "mem_001"}
-
写入阶段:"上周带 Poppy 去看了兽医" → 提取出 PROPER("Poppy") → 嵌入 "Poppy" → Entity Store 搜索,命中已有 "Poppy"(相似度 > 0.95)→ 合并 linked_memory_ids: "mem_001", "mem_003"
-
检索阶段:用户查询 "Poppy 的健康状况" → 提取出 PROPER("Poppy") → 嵌入 "Poppy" → Entity Store 搜索(阈值 0.5),命中 "Poppy" 实体(相似度 ~1.0)→ 读取 linked_memory_ids: "mem_001", "mem_003" → boost = 1.0 × 0.5 × 1/(1+0.001×1) ≈ 0.5 → mem_001 和 mem_003 各获得 0.5 的 boost
-
融合阶段:mem_003("带 Poppy 看兽医")的语义分数约 0.6("兽医"与"健康状况"语义相关),加上 0.5 的 Entity Boost,原始总分 1.1,除以 max_possible=1.5(语义+Entity,无 BM25),最终分数 0.73。没有 Entity Boost 的话,最终分数只有 0.4(0.6/1.5),可能排在第 5 位,被 top-3 截断。
这个推演清晰地展示了 Entity Store 的因果链:实体提取 → 实体合并 → 实体搜索 → boost 计算 → 排名提升。每一步都是确定性的、可追踪的、可调试的。
最终判断:对于以通用对话为主的场景,Entity Store 的 ROI 可能不高;但对于知识密集型场景(企业知识库、技术文档记忆、客户画像),专有名词和术语的精确匹配是刚需,Entity Store 是不可或缺的基础设施。Mem0 选择默认启用、静默降级(spaCy 不可用时自动跳过),是一个务实的工程权衡。
全景:三路信号如何协同
把视野拉远,Mem0 的检索管线是一个三路信号协同的系统:
- 语义向量:覆盖"意思差不多"的模糊召回,权重 1.0
- BM25 关键词:覆盖"字面重叠"的精确命中,权重 1.0
- Entity Boost:覆盖"实体锚定"的跨记忆关联,权重 0.5
三路信号不是平等的。语义搜索是主干,BM25 和 Entity Boost 是辅助。语义门控确保了只有语义相关的候选才能进入融合阶段,BM25 和 Entity Boost 只改变排名,不改变候选集。这种"主干+辅助"的架构比"三路平等投票"更稳健------它避免了辅助信号把语义无关的结果拉上来。
Entity Store 的独特价值在于它引入了一种新的检索维度:实体锚点。语义搜索在"语义空间"中搜索,BM25 在"词频空间"中搜索,Entity Store 在"实体空间"中搜索。这三个空间正交------一个查询在语义空间中可能找不到"Poppy"的记忆,但在实体空间中可以精确命中。三路融合的本质是:在三个正交的维度上同时搜索,取交集(语义门控)后按加权和排序。
这种架构的扩展性也很好。如果未来需要加入第四路信号(比如时间衰减、用户偏好、社交关系),只需要在 score_and_rank 中加一个加性项,调整 max_possible 即可。Entity Store 的独立 collection 设计,让它在三路融合中既是参与者又是旁观者------参与检索评分,旁观记忆的增删改查。
但到目前为止,我们只回答了"为什么需要三路信号"和"每路信号各自怎么工作"。一个更根本的问题还悬在半空:三路信号到底怎么融合?semantic + bm25 + entity_boost 这个加法公式看起来简单,但权重为什么是 1.0、1.0、0.5?max_possible 的动态调整逻辑有没有边界条件?语义门控在融合之前执行,会不会漏掉 BM25 能救回来的候选?这些问题,下一篇我们拆开来看。