目录
(二)同一句话的不同说法:向量数据库如何找到"同一个意思"?
[1. BERT](#1. BERT)
[2. DistilBERT](#2. DistilBERT)
[3. SentenceTransformer](#3. SentenceTransformer)
[1. 掩码语言模型(MLM)](#1. 掩码语言模型(MLM))
[2. 下一句预测 (NSP)](#2. 下一句预测 (NSP))
[3. 学习句子中不同词语之间的关系](#3. 学习句子中不同词语之间的关系)
[八、总结:向量数据库,正在重构 AI 的"知识获取方式"](#八、总结:向量数据库,正在重构 AI 的“知识获取方式”)
[参考链接 / 论文](#参考链接 / 论文)
[官方文档 & 向量数据库](#官方文档 & 向量数据库)
[核心论文(Embedding / Transformer / 检索)](#核心论文(Embedding / Transformer / 检索))
干货分享,感谢您的阅读!
在大模型席卷一切的今天,人们逐渐意识到:仅靠参数记忆的智能,是不够的。模型再强,也终究被训练数据"锁死",既无法实时更新,也难以避免"幻觉"。于是,一种新的范式开始崛起------检索增强生成(RAG):让模型学会"查资料",再"作答"。而在这套体系中,真正承担"知识检索引擎"角色的,正是矢量数据库(What are RAG vector databases?)。
但问题也随之而来:
为什么传统数据库无法胜任?
为什么"相似度搜索"成为关键能力?
又为什么矢量数据库,会在短时间内成为 AI 基础设施中的核心组件?
事实上,矢量数据库并不是一个新概念------你早已在推荐系统、搜索引擎甚至社交媒体中"无感使用"过它。只是随着生成式 AI 的爆发,它从幕后走向台前,成为连接"数据"与"智能"的关键桥梁。
从本质上看,RAG 的核心转变只有一句话:
从"记住世界",走向"理解并检索世界"。
而要实现这一点,就必须把文本、图片乃至多模态信息,映射为可以计算"语义距离"的向量,并在海量数据中高效找到"最相关"的内容------这正是矢量数据库的使命:用"意义"替代"关键词",重构信息检索的底层逻辑。
我们整理这部分的内容,将以系统性的视角,带你深入理解矢量数据库的底层原理与工程实现:从 embedding 的生成机制,到 ANN(近似最近邻)搜索的性能权衡;从索引结构设计,到 RAG 系统中的实际落地;再到它在真实 AI 应用中的价值与局限。
如果说大模型是"大脑",那么矢量数据库,就是它连接现实世界的"感官系统"。理解它,才能真正理解 RAG。
一、快速走进矢量数据库
首先,我们必须指出,向量数据库并不是新生事物。
事实上,它们已经存在很长时间了。即使在它们最近变得广为人知之前,你也一直在间接地与它们互动。例如,推荐系统和搜索引擎等应用就属于这种情况。
简而言之,向量数据库以向量嵌入的形式存储非结构化数据(文本、图像、音频、视频等) 。
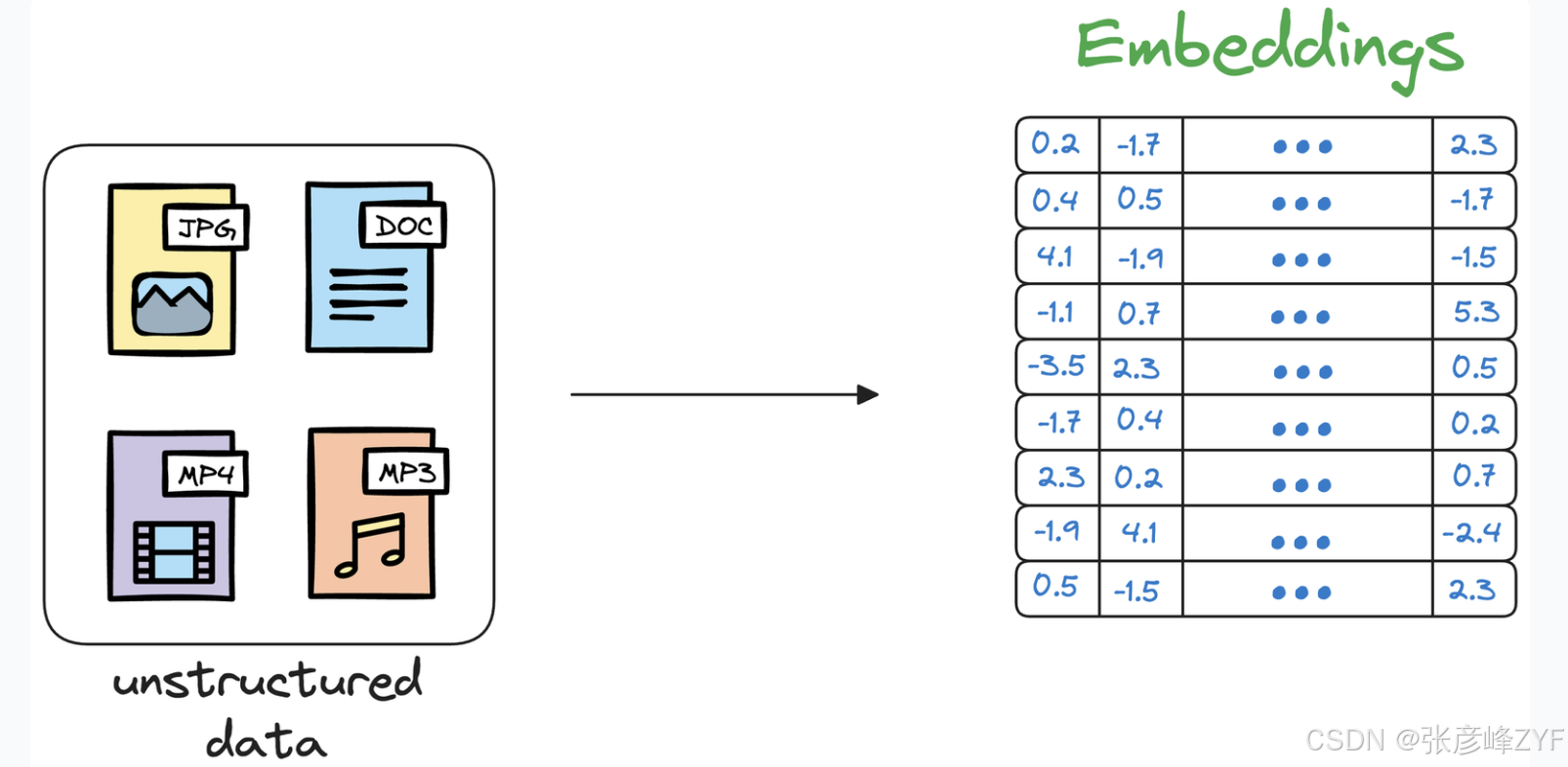
每个数据点,无论是单词、文档、图像还是任何其他实体,都会使用 ML 技术(我们将在后面看到)转换为数值向量。
这个数值向量被称为**嵌入,**模型经过训练,使得这些向量能够捕捉底层数据的基本特征和特性。
例如,考虑词嵌入,我们可能会发现,在嵌入空间中,水果的嵌入彼此靠近,城市形成另一个聚类,等等。
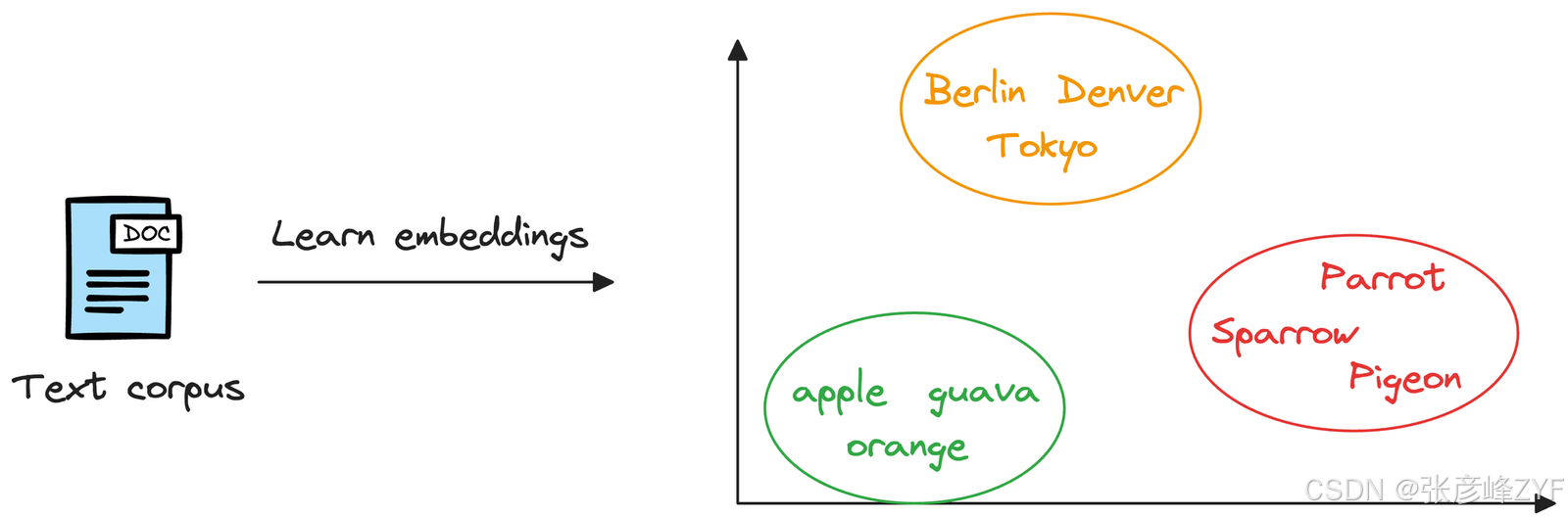
这表明嵌入可以学习它们所代表的实体的语义特征(前提是它们经过适当的训练)。
一旦存储在向量数据库中,我们就可以检索与我们希望对非结构化数据运行的查询类似的原始对象。
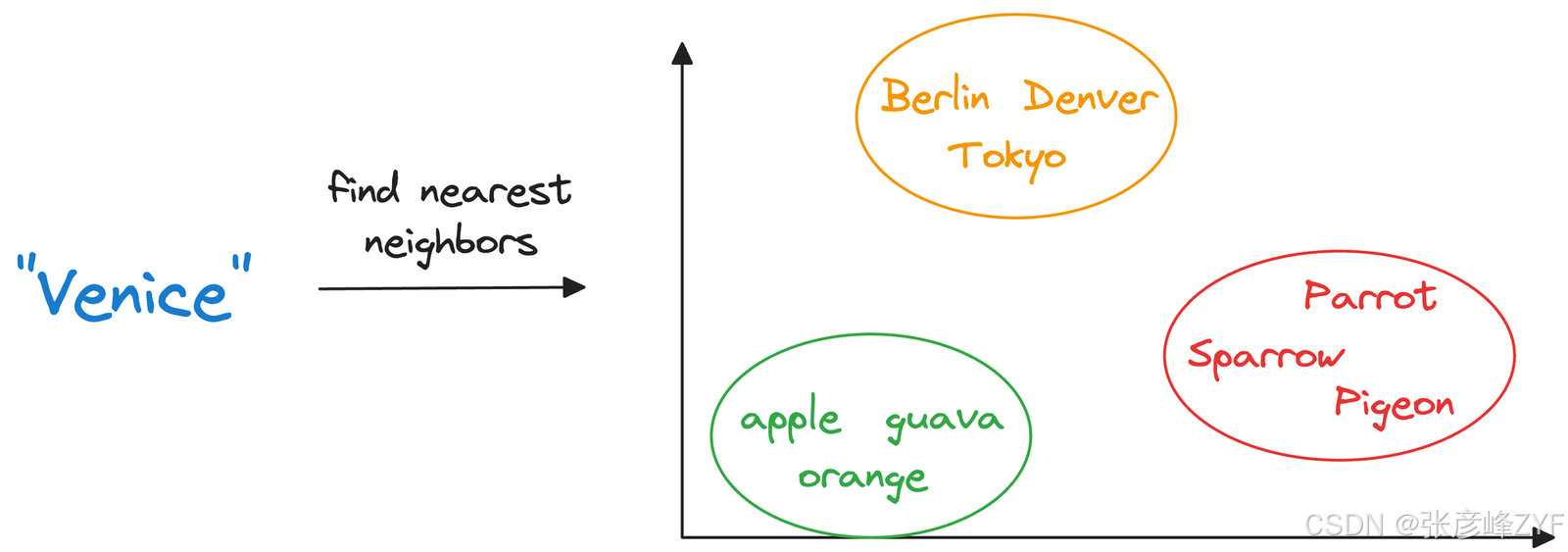
换句话说,对非结构化数据进行编码,可以让我们对其运行许多复杂的操作,例如相似性搜索、聚类和分类,而这些操作对于传统数据库来说是很难实现的。
举例来说,当电子商务网站根据输入的查询提供类似商品的推荐或产品搜索时,我们(在大多数情况下)在后台与矢量数据库进行交互。
在深入技术细节之前,让我举几个直观的例子来帮助您理解矢量数据库及其巨大的用途。
(一)从"照片检索"理解向量数据库的相似性搜索机制
假设我们收集了一些多年来不同旅行中拍摄的照片。每张照片都记录了不同的场景,例如海滩、山脉、城市和森林。

现在,我们希望以一种能够更快速地找到类似照片的方式来整理这些照片。
传统上,我们可能会按拍摄日期或拍摄地点对它们进行整理。

但是,我们可以采用更复杂的方法,将它们编码为向量。
更具体地说,我们可以不仅仅依靠日期或地点,而是将每张照片表示为一组数值向量,以捕捉图像的本质。
假设我们使用一种算法,根据照片的颜色组成、突出形状、纹理、人物等,将每张照片转换为矢量图。
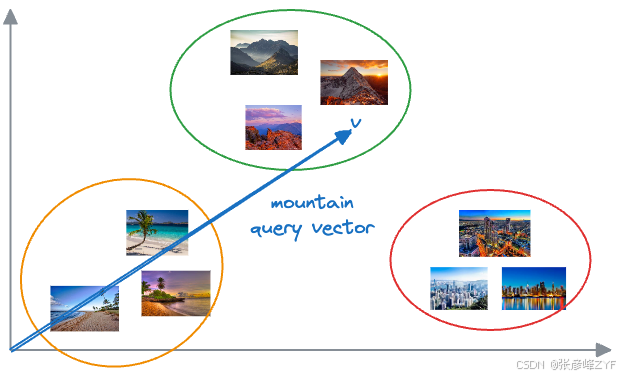
现在,每张照片都被表示为多维空间中的一个点,其中维度对应于图像中不同的视觉特征和元素。当我们想要根据输入的文本查询查找相似照片时,我们会将文本查询编码成一个向量,并将其与图像向量进行比较。
与查询匹配的照片,其向量在这个多维空间中应该彼此靠近。假设我们想找到山脉的图片。在这种情况下,我们可以通过查询矢量数据库,找到与表示输入查询的矢量接近的图像,从而快速找到此类照片。
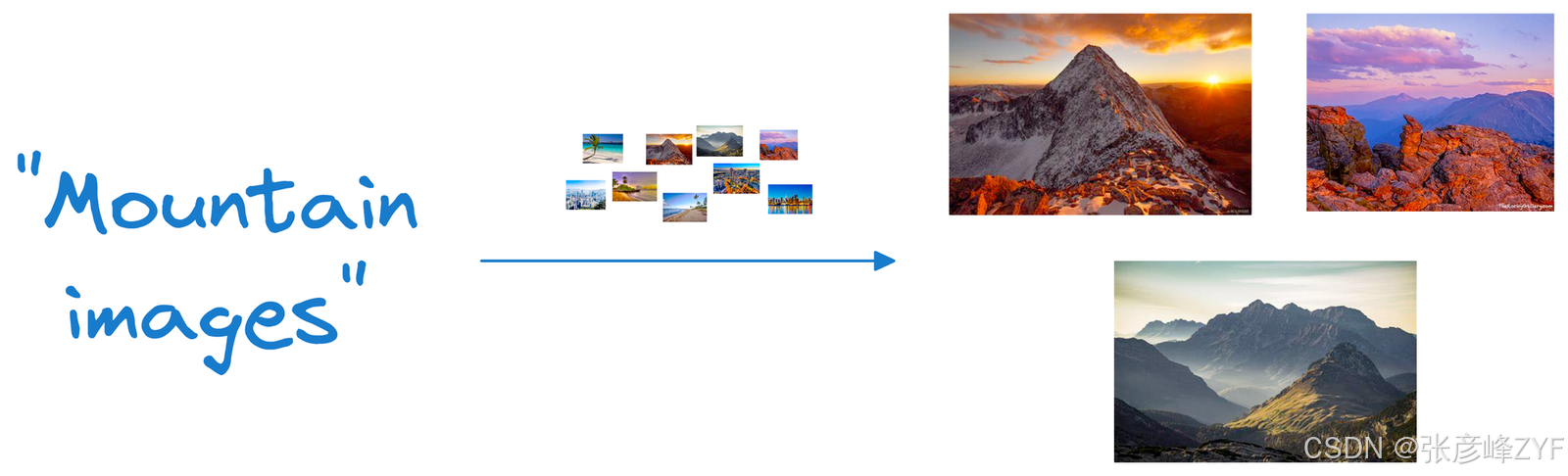
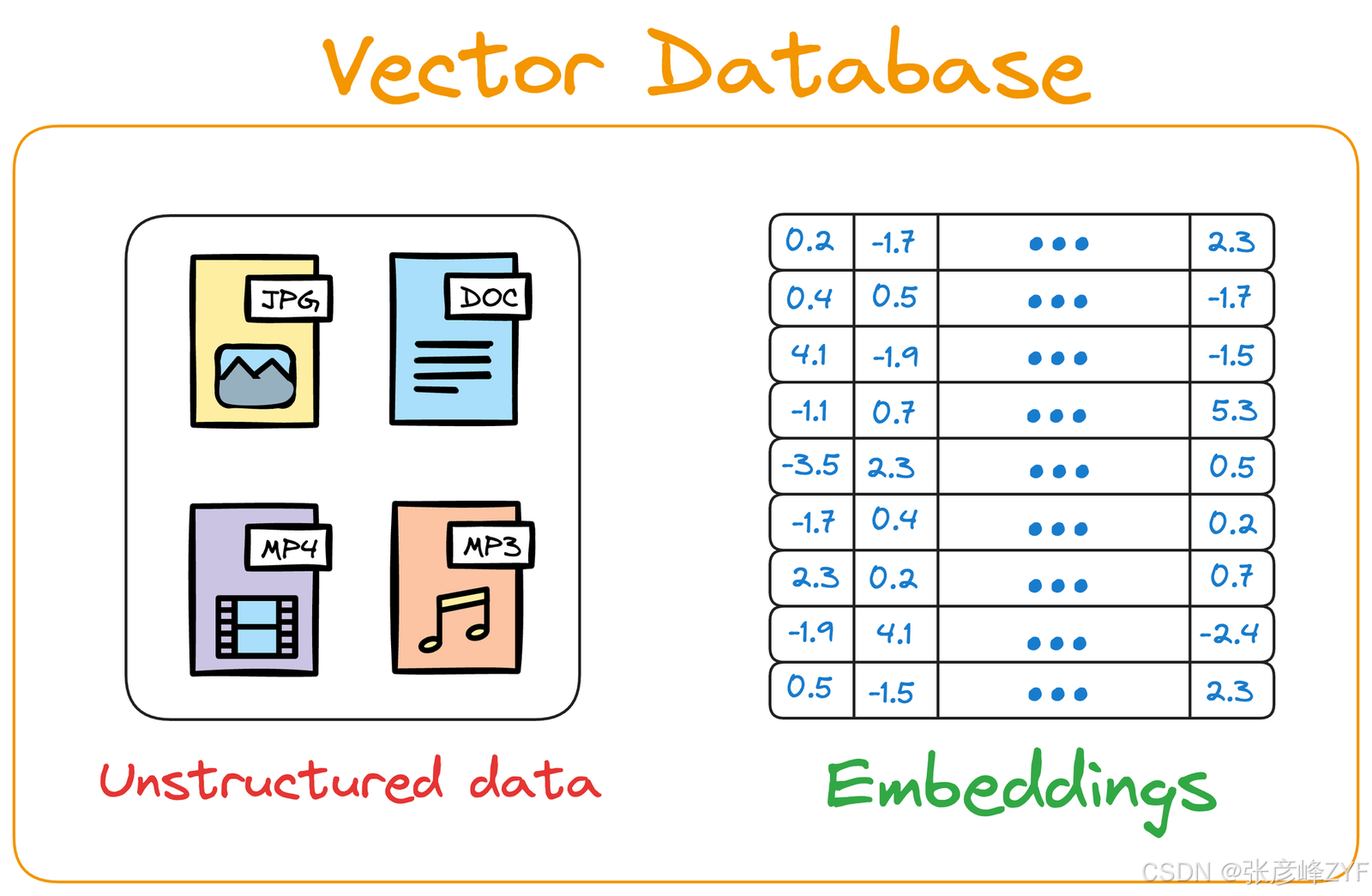
这里需要注意的一点是,向量数据库不仅仅是一个用来跟踪向量嵌入的数据库。相反,它同时保留了嵌入和生成这些嵌入的原始。
你可能会问,为什么有必要这样做呢?
再考虑上述图像检索任务,如果我们的矢量数据库仅由矢量组成,我们也需要一种方法来重建图像,因为这是最终用户需要的。
当用户查询山脉的图片时,他们会收到一个表示相似图片的向量列表,但没有实际的图片。

通过存储嵌入(表示图像的向量)和原始图像数据,向量数据库确保当用户查询相似图像时,它不仅返回最接近的匹配向量,而且还提供对原始图像的访问。
(二)同一句话的不同说法:向量数据库如何找到"同一个意思"?
在这个例子中,考虑一个全部由文本组成的非结构化数据,比如数千篇新闻文章,我们希望从这些数据中搜索答案。
传统搜索方法依赖于精确的关键词搜索,这完全是一种蛮力搜索方法,没有考虑到文本数据固有的复杂性。
换句话说,语言极其微妙,每种语言都提供了多种方式来表达同一个想法或提出同一个问题。例如,像"今天天气怎么样?"这样的简单询问可以用多种方式表达,例如"今天天气如何?"、"外面阳光明媚吗?"或"目前的天气状况如何?"。这种语言多样性使得传统的基于关键词的搜索方法无法满足需求。
你可能已经猜到了,在这种情况下,将这些数据表示为向量也很有帮助。与其仅仅依赖关键词进行暴力搜索,我们可以先将文本数据表示为高维向量空间,并将其存储在向量数据库中。
当用户提出查询时,即使查询和文本数据的措辞不完全相同,向量数据库也可以将查询的向量表示与文本数据的向量表示进行比较。
二、如何生成嵌入向量?
要构建面向语言任务的模型,生成单词的数值表示(或向量)至关重要。这使得文字能够被数学地处理和操纵,并对文字执行各种计算操作。
词嵌入的目标是捕捉词语之间的语义和句法关系。这有助于机器更有效地理解和推理语言。
(一)嵌入向量模型简单介绍
在变形金刚时代之前,这主要是使用预训练的静态嵌入来实现的。本质上,有人会使用深度学习技术,对例如 10 万或 20 万个常用词进行词嵌入训练,然后将其开源。
因此,其他研究人员会在他们的项目中利用这些嵌入代码。当时(2013-2017 年左右)最受欢迎的模型有:
- Glove
- Word2Vec
- FastText 等。
这些词嵌入在学习词语之间的关系方面确实展现出了一些很有前景的结果。
例如,当时的一项实验表明,向量运算 (King - Man) + Woman 返回的向量与单词接近 Queen。
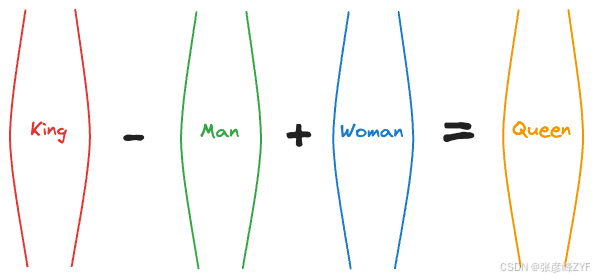
这很有意思,不是吗?
事实上,以下关系也被发现是成立的:
- Paris - France + Italy ≈ Rome
- Summer - Hot + Cold ≈ Winter
- Actor - Man + Woman ≈ Actress
- 还有更多。
因此,虽然这些嵌入捕捉到了相对的词语表示,但存在一个重大局限性。请看以下两个句子:
- Convert this data into a table in Excel.
- Put this bottle on the table.
这里,"table"一词表达了两种截然不同的含义:
- 第一句话指的是"表格"一词特指的"data"含义。
- 第二句指的是"桌子"一词特指的"家具"含义。
- 然而,静态嵌入模型却赋予了它们相同的表示形式。
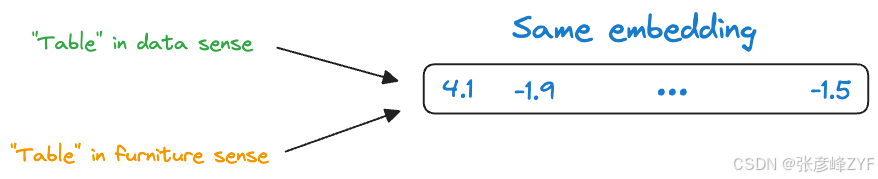
因此,这些词嵌入没有考虑到一个词在不同的语境中可能有不同的用法。
但这个问题在Transformer时代得到了解决,由此产生了由Transformer驱动的上下文嵌入模型,例如:
1. BERT
一种使用两种技术训练的语言模型:
- 掩码语言模型(MLM):根据句子中的周围词语预测句子中缺失的词语。
- 下一句预测(NSP)。
2. DistilBERT
BERT 的一个简单、高效且更轻量级的版本,体积缩小了约 40%:
- 采用一种称为师生理论的常见机器学习策略。
- 在这里,学生是 BERT 的精简版,而教师是原始的 BERT 模型。
- 学生模型应该模仿教师模型的行为。
3. SentenceTransformer
-
本质上,SentenceTransformer模型接收一个完整的句子,并生成该句子的嵌入向量。
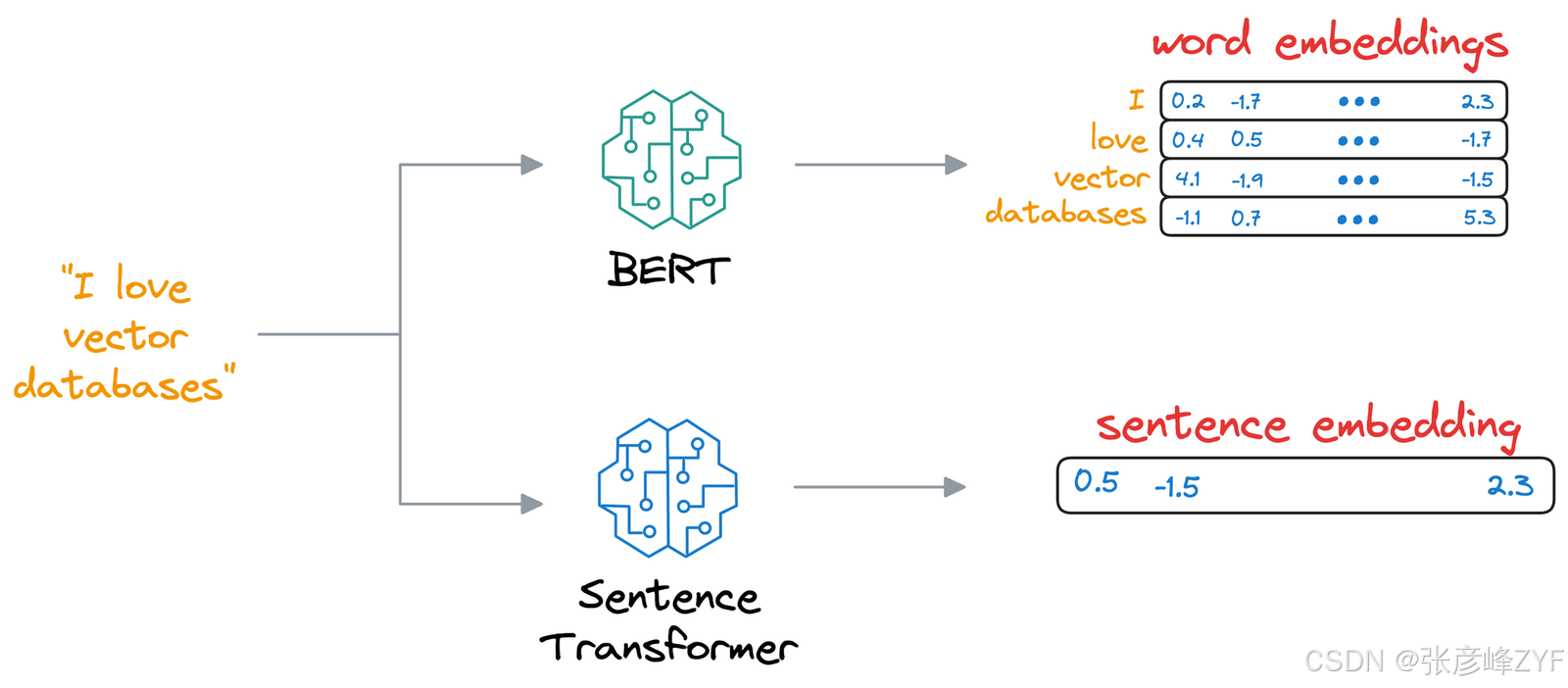
-
这与 BERT 和 DistilBERT 模型不同,后者会为句子中的所有单词生成嵌入。
还有更多模型,但我们这里就不详细介绍了,希望你们明白我的意思。其理念是,这些模型凭借其自注意力机制和适当的训练机制,完全能够生成上下文感知表示。
(二)深入理解BERT
BERT,我们上面讨论过它使用掩码语言建模 (MLM) 技术和下一句预测 (NSP)。
这些步骤也称为BERT 的预训练步骤,因为它们涉及在针对特定下游任务进行微调之前,先在大文本语料库上训练模型。
在机器学习模型训练的语境下,预训练指的是训练的初始阶段,在此阶段,模型会从大型文本语料库中学习通用的语言表征。预训练的目标是使模型能够捕捉语言的句法和语义属性,例如语法、上下文以及词语之间的关系。虽然文本本身没有标注,但多语言学习(MLM)和自然语言处理(NSP)这两个任务可以帮助我们以监督的方式训练模型。模型训练完成后,我们可以利用模型在预训练阶段获得的语言理解能力,并针对特定任务的数据进行微调。
以下动画演示了微调过程:
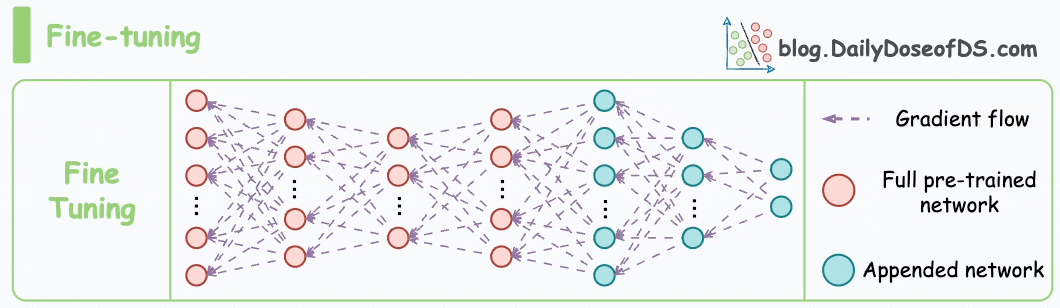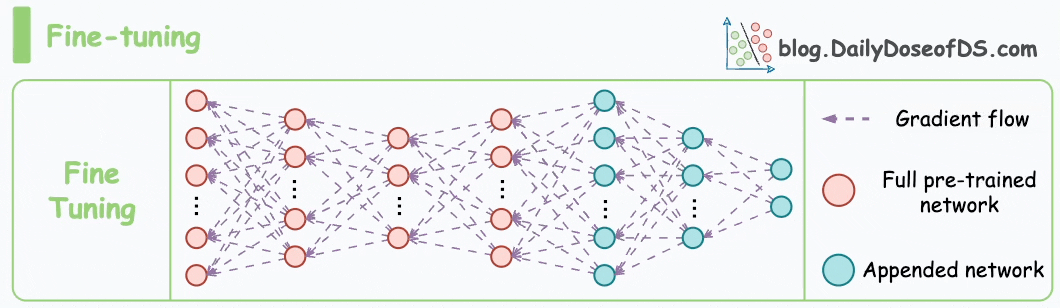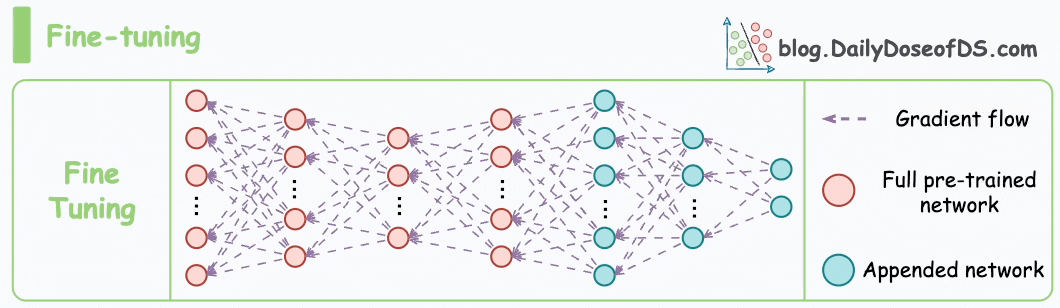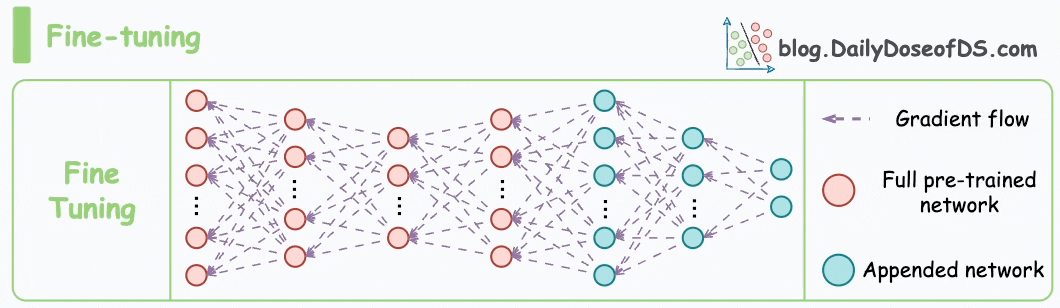
接下来,让我们看看掩码语言模型(MLM)和下一句预测(NSP)的预训练目标如何帮助 BERT 生成嵌入。
1. 掩码语言模型(MLM)
在 MLM 中,BERT 被训练来预测句子中缺失的单词。为此,大多数(并非所有)句子中的一定比例的单词会被随机替换为一个特殊的标记**MASK**。
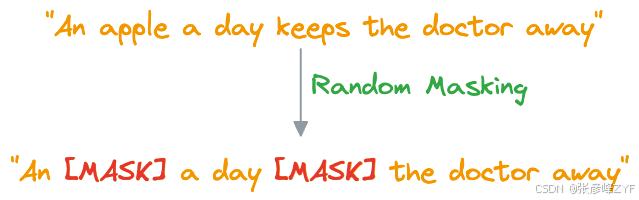
然后,BERT 双向处理掩码句子,这意味着它会考虑每个掩码词的左侧和右侧上下文,这就是它被称为"来自 Transformers 的双向编码器表示 (BERT)"的原因。

对于每个被掩码的词,BERT 会根据上下文预测其原始词是什么。它通过为整个词汇表分配一个概率分布,并选择概率最高的词作为预测词来实现这一点。
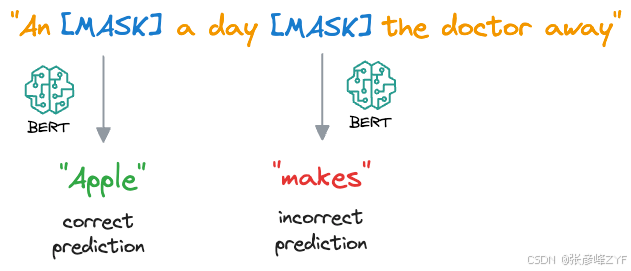
在训练过程中,BERT 通过交叉熵损失等技术进行优化,以最小化预测词与实际掩码词之间的差异。
2. 下一句预测 (NSP)
在 NSP 中,BERT 经过训练,可以确定两个输入句子是否连续出现在文档中,或者它们是否是来自不同文档的随机配对句子。
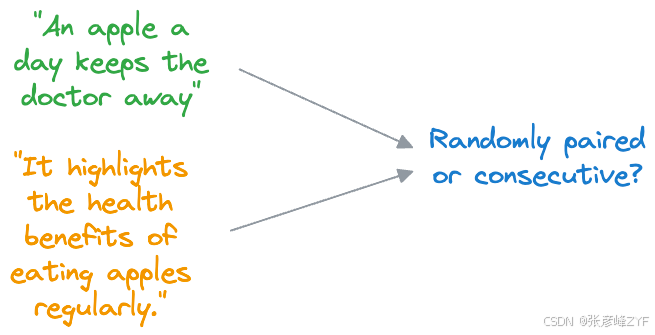
在训练过程中,BERT 接收成对的句子作为输入。其中一半句子对来自同一文档,是连续的句子(正例);另一半句子对来自不同文档,是随机配对的句子(负例)。
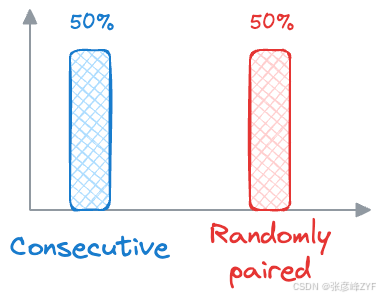
然后,BERT 学习预测第二个句子是否在原始文档中紧随第一个句子之后(label 1),或者它是否是一个随机配对的句子(label 0)。
与 MLM 类似,BERT 也经过优化,以最小化预测标签与实际标签之间的差异,它使用诸如二元交叉熵损失之类的技术。
回顾 MLM 和 NSP,在这两种情况下,我们一开始都不需要标注数据集。相反,我们利用文本本身的结构来创建训练样本。这使我们能够利用大量未标注的文本数据,而这些数据通常比标注数据更容易获取。
3. 学习句子中不同词语之间的关系
现在,让我们看看这些预训练目标如何帮助 BERT 生成词嵌入:
- MLM: BERT 通过基于上下文预测被掩码的词,学习捕捉句子中每个词的含义和上下文。BERT 生成的词嵌入不仅反映了词的个体含义,还反映了它们与句子中周围词的关系。
- NSP:通过判断句子是否连续,BERT 可以学习理解文档中不同句子之间的关系。这有助于 BERT 生成词嵌入,不仅捕捉单个句子的含义,还能捕捉文档或文本段落的整体上下文。
通过持续训练,该模型能够学习句子中不同词语之间的关系。它能学习哪些词语经常一起使用,以及它们如何融入句子的整体含义。
这种学习过程帮助 BERT 创建词和句子的嵌入,这些嵌入是上下文相关的,这与早期的嵌入(如 Glove 和 Word2Vec)不同:
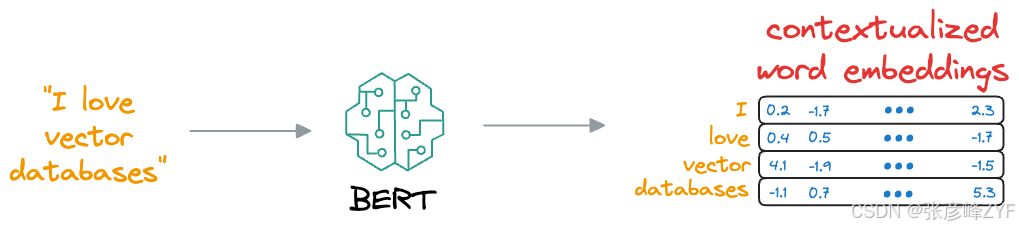
上下文相关的是指嵌入模型可以根据单词使用的上下文动态生成单词的嵌入向量。因此,如果一个词出现在不同的上下文中,模型将返回不同的表示形式。
下图精确地描绘了该词的不同用法Bank。为了便于可视化,使用 t-SNE 将嵌入投影到 2d 空间中。
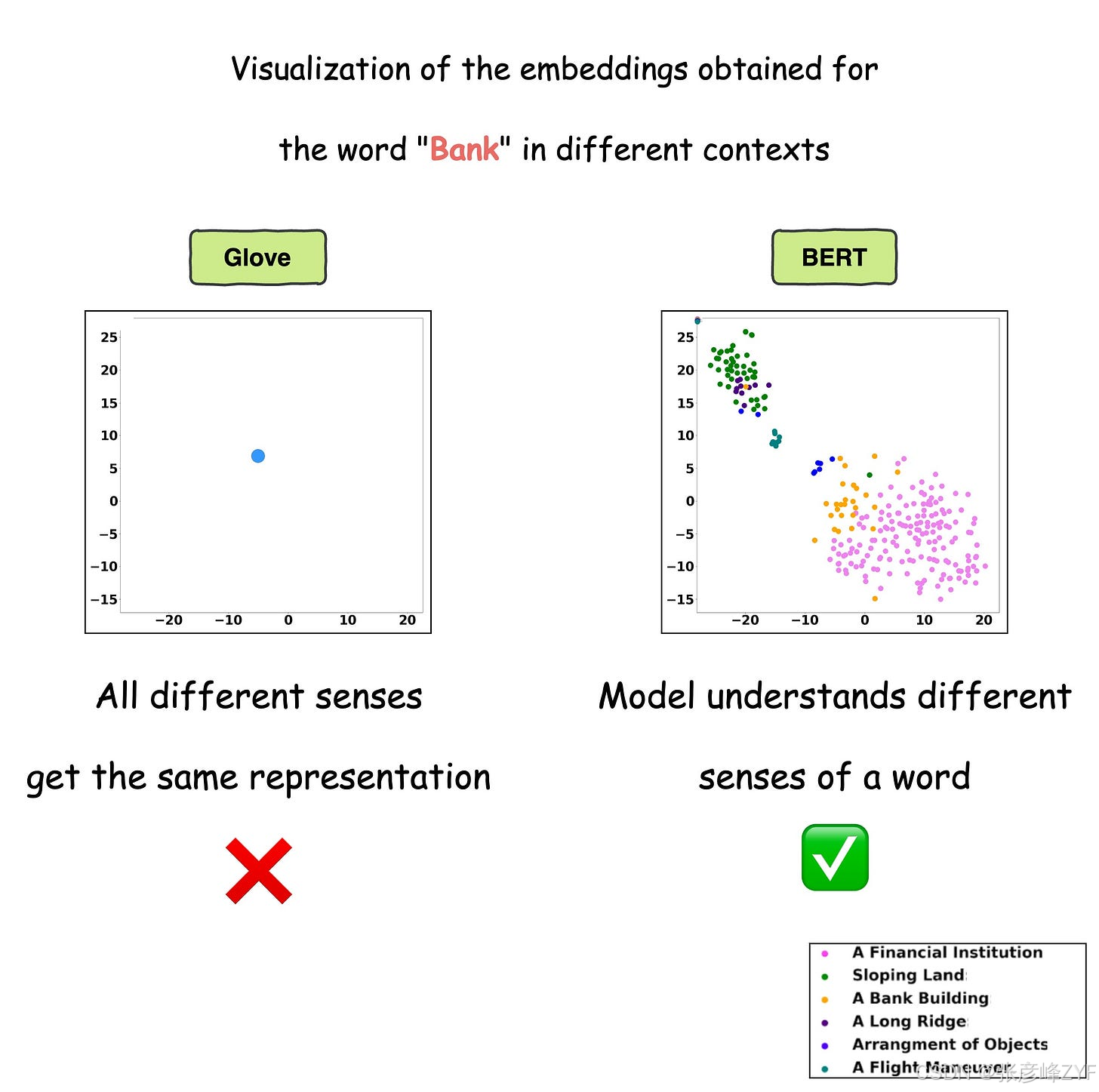
如上图所示,静态嵌入模型------Glove 和 Word2Vec 对单词的不同用法产生相同的嵌入。
然而,上下文嵌入模型却并非如此。事实上,上下文嵌入能够理解"银行"一词的不同含义/意义:
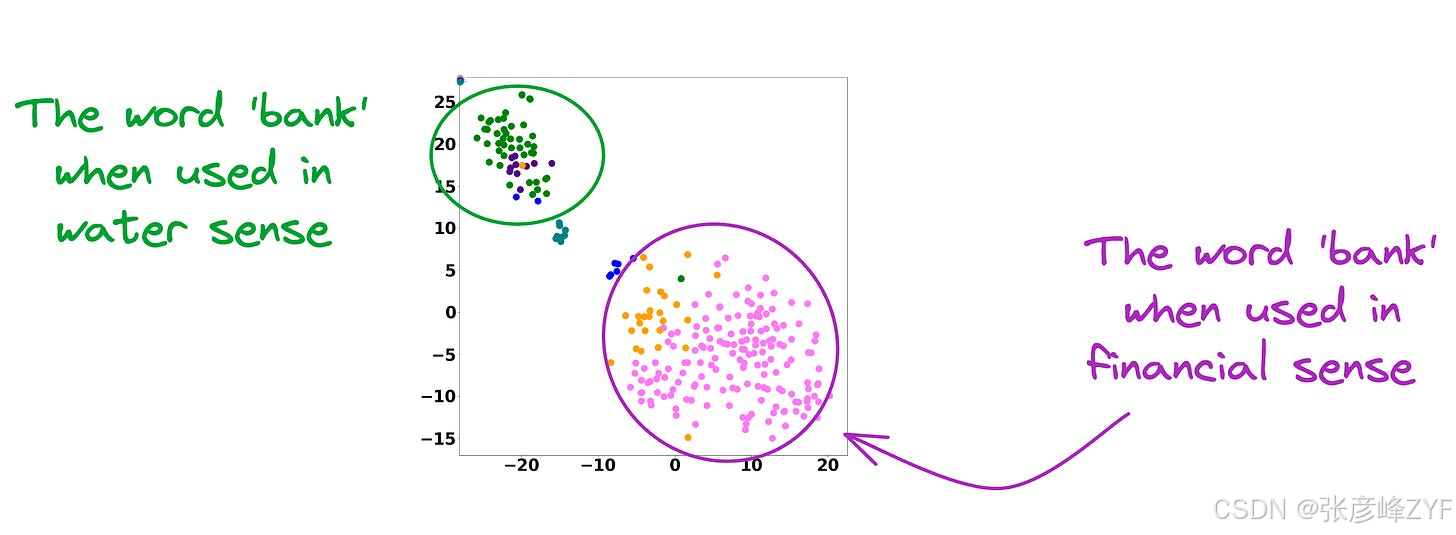
- A financial institution
- Sloping land
- A Long Ridge, and more.
因此,这些上下文相关的嵌入模型解决了静态嵌入模型的主要局限性。
以上讨论的重点是,现代嵌入模型在编码任务上非常熟练。
因此,它们可以轻松地将文档、段落或句子转换为能够捕捉其语义含义和上下文的数值向量。
三、查询向量数据库
(一)快速感受体会
在前文我们提供了一个输入查询,该查询经过编码,然后我们在向量数据库中搜索与输入向量相似的向量。

换句话说,目标是返回根据相似度指标衡量的最近邻居,该指标可以是:
- 欧氏距离(指标值越低,相似度越高)。
- 曼哈顿距离(指标越低,相似度越高)。
- 余弦相似度(度量值越大,相似度越高)。
这个想法与我们在典型的 k 近邻 (kNN) 设置中所做的工作相呼应。
我们可以将查询向量与已编码的向量进行匹配,并向模型返回相似的向量。这种方法的缺点是,为了找到例如第一个最近邻,输入查询必须在向量数据库中存储的所有向量中进行匹配。
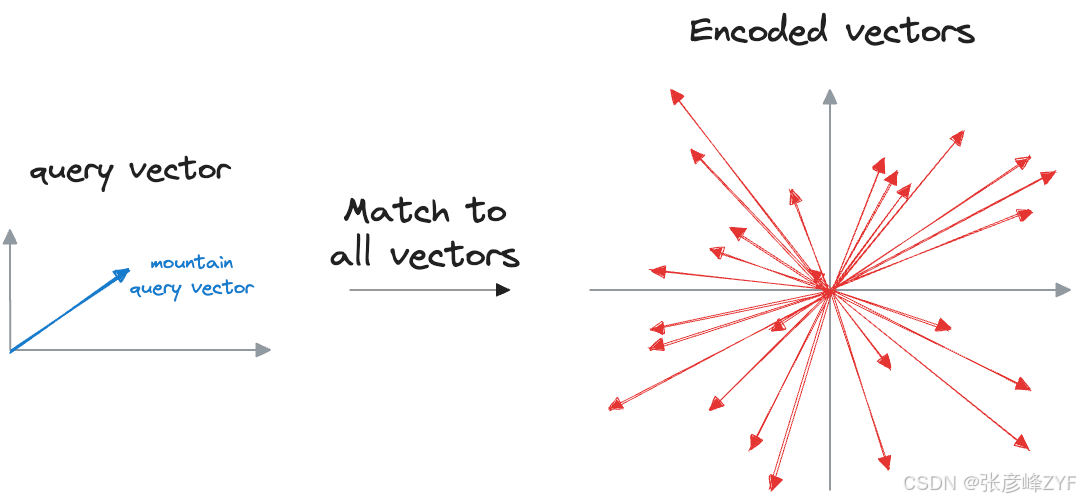
这种方法计算量很大,尤其是在处理可能包含数百万个数据点的大型数据集时。随着向量数据库规模的增长,执行最近邻搜索所需的时间也会成比例地增加。
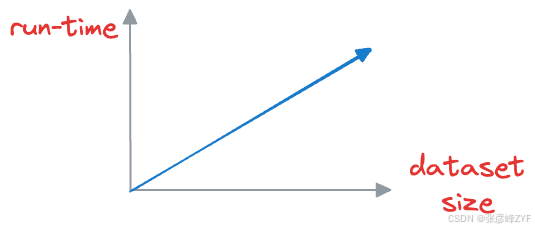
但在需要实时或近乎实时响应的情况下,这种蛮力方法就变得不切实际了。
事实上,典型的关系型数据库也存在这个问题。如果我们想要获取符合特定条件的行,就必须扫描整个表。
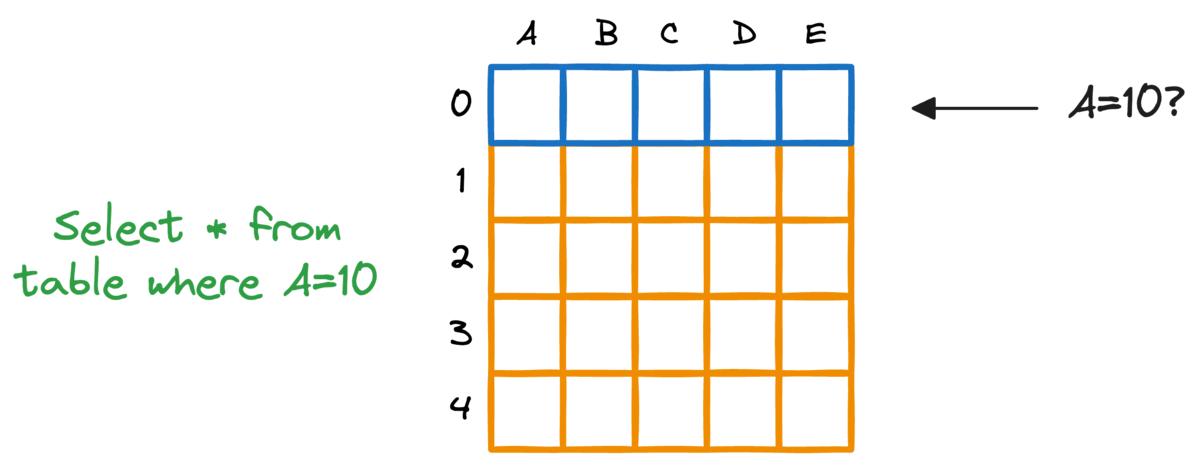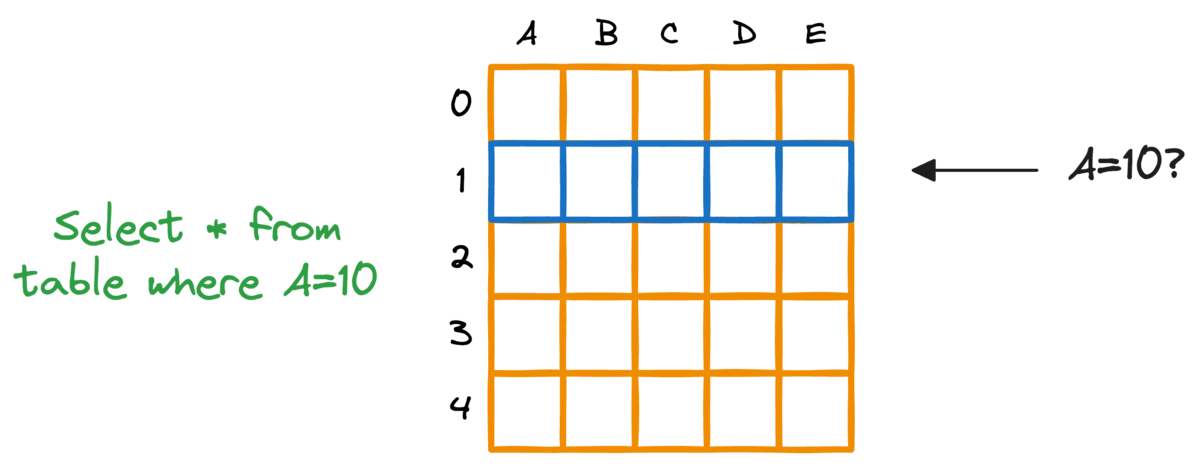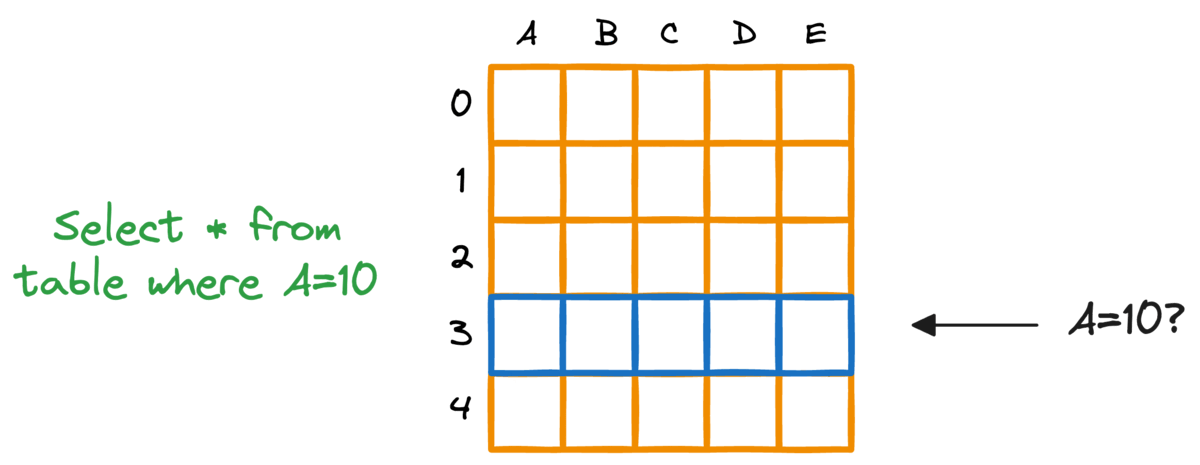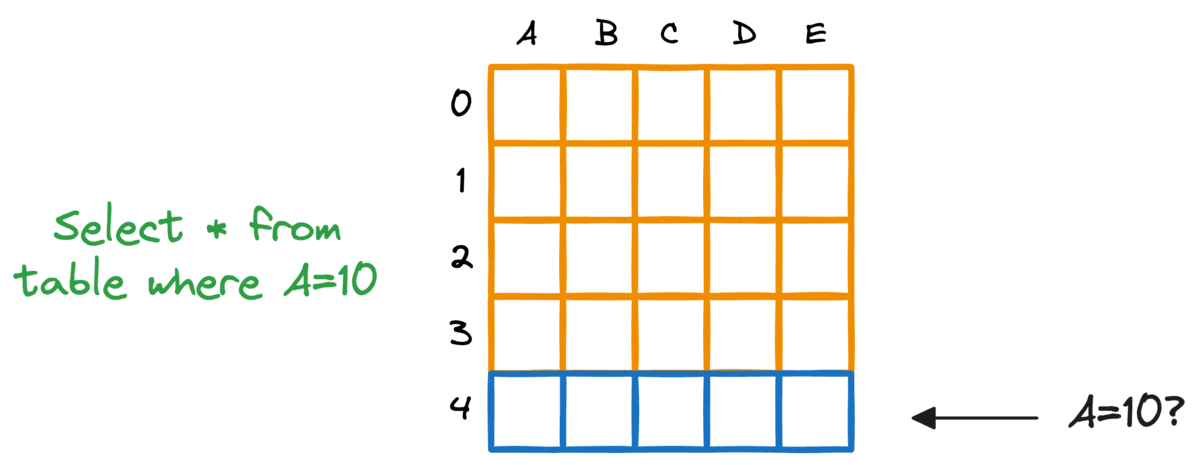
对数据库进行索引提供了一种快速查找机制,尤其是在近乎实时延迟至关重要的情况下。更具体地说,当对WHERE子句或JOIN条件中使用的列建立索引时,可以显著提高查询性能。
向量数据库中也采用了类似的索引思想,由此产生了我们称之为**近似最近邻(ANN)**的东西,这已经很清楚地说明了它的作用,不是吗?
其核心思想是在准确性和运行时间之间取得平衡。因此,使用近似最近邻算法来寻找数据点的最近邻,尽管这些邻居可能并非总是最接近的邻居。
因此,它们也被称为非穷举搜索算法。
这样做的目的是,在使用向量搜索时,大多数情况下并不一定需要精确匹配。近似最近邻 (ANN) 算法利用了这一观察结果,并以一定的精度换取运行效率。
因此,人工神经网络算法无需穷举搜索数据库中的所有向量来查找最接近的匹配项,而是提供快速、亚线性时间复杂度的解决方案,从而得出近似的最近邻。
(二)近似最近邻(ANN)
虽然近似最近邻算法与精确最近邻方法相比可能会牺牲一定程度的精度,但它们可以提供显著的性能提升,尤其是在需要实时或近实时响应的场景中。
核心思想是缩小查询向量的搜索空间,从而提高运行时性能。
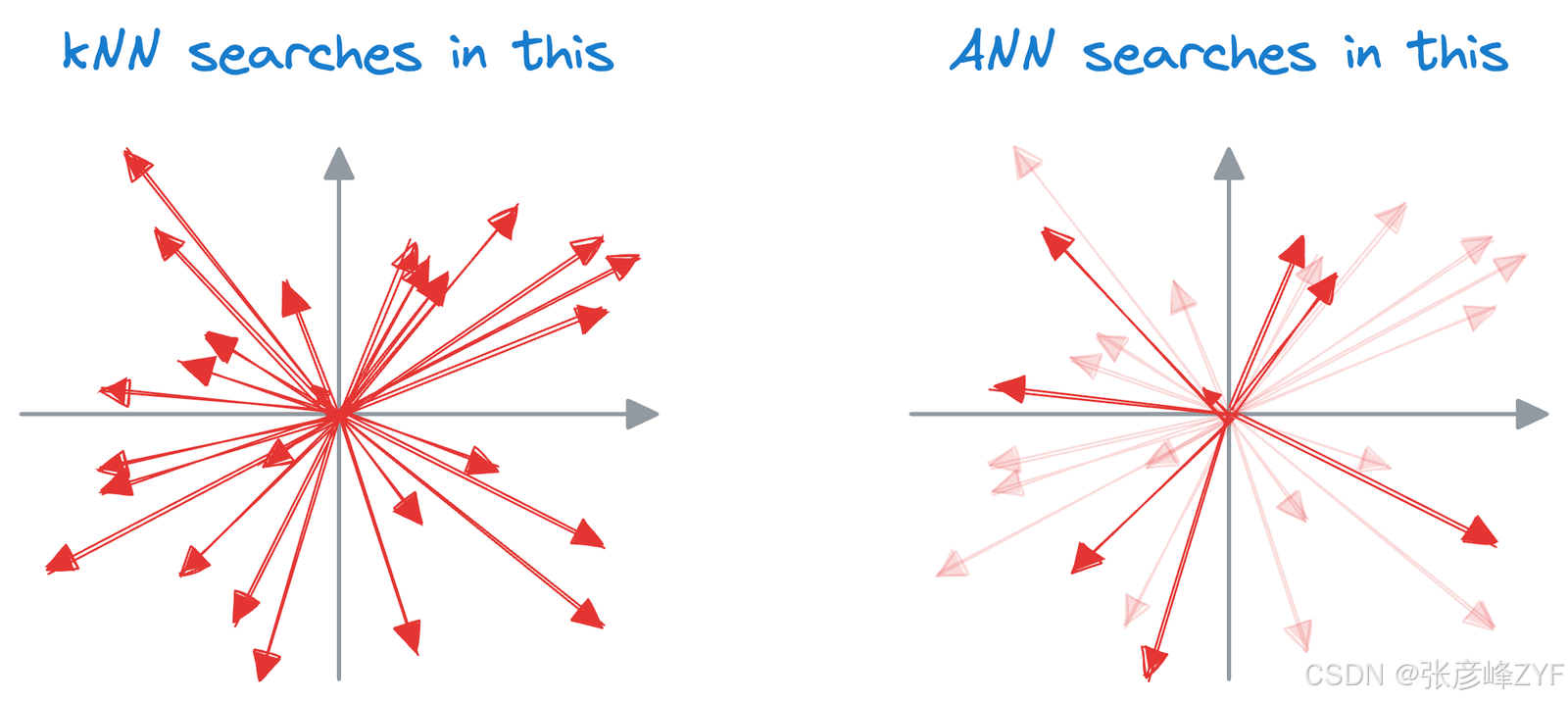
借助索引可以缩小搜索空间,我们简单介绍常用的索引策略(见)。
还有,不是所有场景都该用 ANN:
- 数据量 < 1万 → 直接暴力
- 精度必须 100% → 用精确 NN
- 向量维度极低 → KD-Tree 更好
ANN 本质是:
在高维空间中,用结构化索引替代全量扫描,实现"近似但高效"的相似度搜索。
四、在LLM中使用向量数据库
值得了解的一个有趣问题是,大型语言模型(LLM)究竟是如何利用向量数据库的。
根据经验,许多人面临的最大难题如下:
训练好LLM模型后,它会获得一些用于文本生成的模型权重。那么,向量数据库在这里扮演什么角色呢?
这确实是一个很合理的问题。让我们解释一下矢量数据库如何帮助 LLM 提高其生成结果的准确性和可靠性。
(一)自回归模型:少量信息
首先,我们必须了解 LLM 是在从训练期间输入的语料库的静态版本中学习之后部署的。
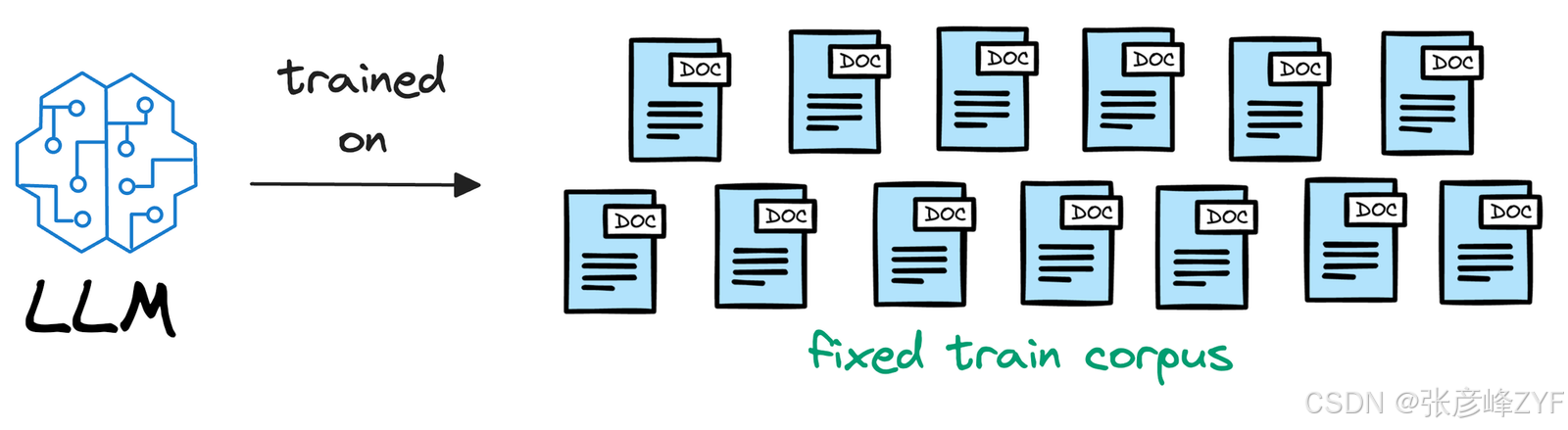
例如,如果模型是在考虑了数据之后部署的31st Jan 2024,而我们在训练一周后使用它,那么它将完全不知道那几天发生了什么。
每天都用新数据反复训练新模型(或调整最新版本)既不切实际,成本也过高。事实上,LLM 的训练可能需要数周时间。另外,如果我们开源了 LLM,而其他人想在他们私有的数据集上使用它,而该数据集当然不会在训练过程中显示出来,那该怎么办?不出所料,大模型对此一无所知。
但仔细想想,我们的目标真的是培养一个大模型让他了解世界上所有的事物吗?绝对不行!那不是我们的目标。相反,它更多的是帮助大模型学习语言的整体结构,以及如何理解和生成语言。
因此,一旦我们在足够大的训练语料库上训练了这个模型,就可以预期该模型将具有相当不错的语言理解和生成能力。如果我们能找到一种方法,让 LLM 能够查找它们没有接受过训练的新信息,并将其用于文本生成(而无需再次训练模型),那就太好了!
一种方法是在提示信息本身中提供该信息。换句话说,如果不需要训练或微调模型,我们可以在给 LLM 的提示中提供所有必要的细节。
遗憾的是,这种方法只适用于少量信息。这是因为LLM是自回归模型。
自回归模型是指每次生成一个输出的模型,其中每一步都依赖于之前的步骤。对于语言学习模型(LLM)而言,这意味着模型会根据已生成的词语,一次生成一个词。
因此,由于 LLM 会考虑前面的词语,所以它们的提示词数量实际上不能超过限制。
总的来说,这种在提示中提供所有信息的做法并不那么有前景,因为它将效用限制在几千token以内,而现实生活中,额外的信息可能价值数百万token。这时矢量数据库就派上用场了。
(二)向量数据库赋能
与其每次出现新数据或数据发生变化时都重新训练 LLM,我们可以利用向量数据库动态地更新模型对世界的理解。
正如文章前面所讨论的,向量数据库帮助我们以向量的形式存储信息,其中每个向量捕获有关正在编码的文本片段的语义信息。因此,我们可以利用嵌入模型将可用信息编码成向量,从而将其保存在向量数据库中。
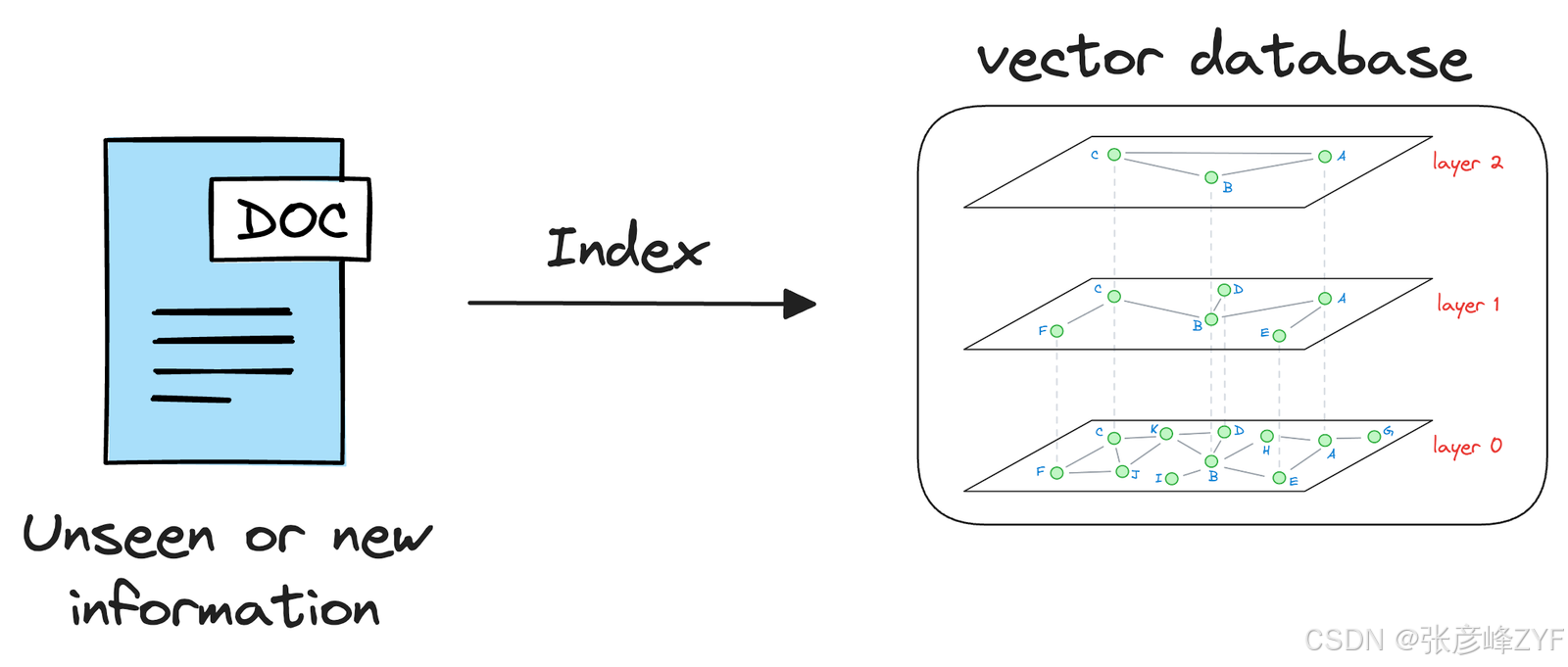
当 LLM 需要访问此信息时,它可以使用提示向量进行相似性搜索来查询向量数据库。更具体地说,相似性搜索将尝试在向量数据库中查找与输入查询向量相似的内容。
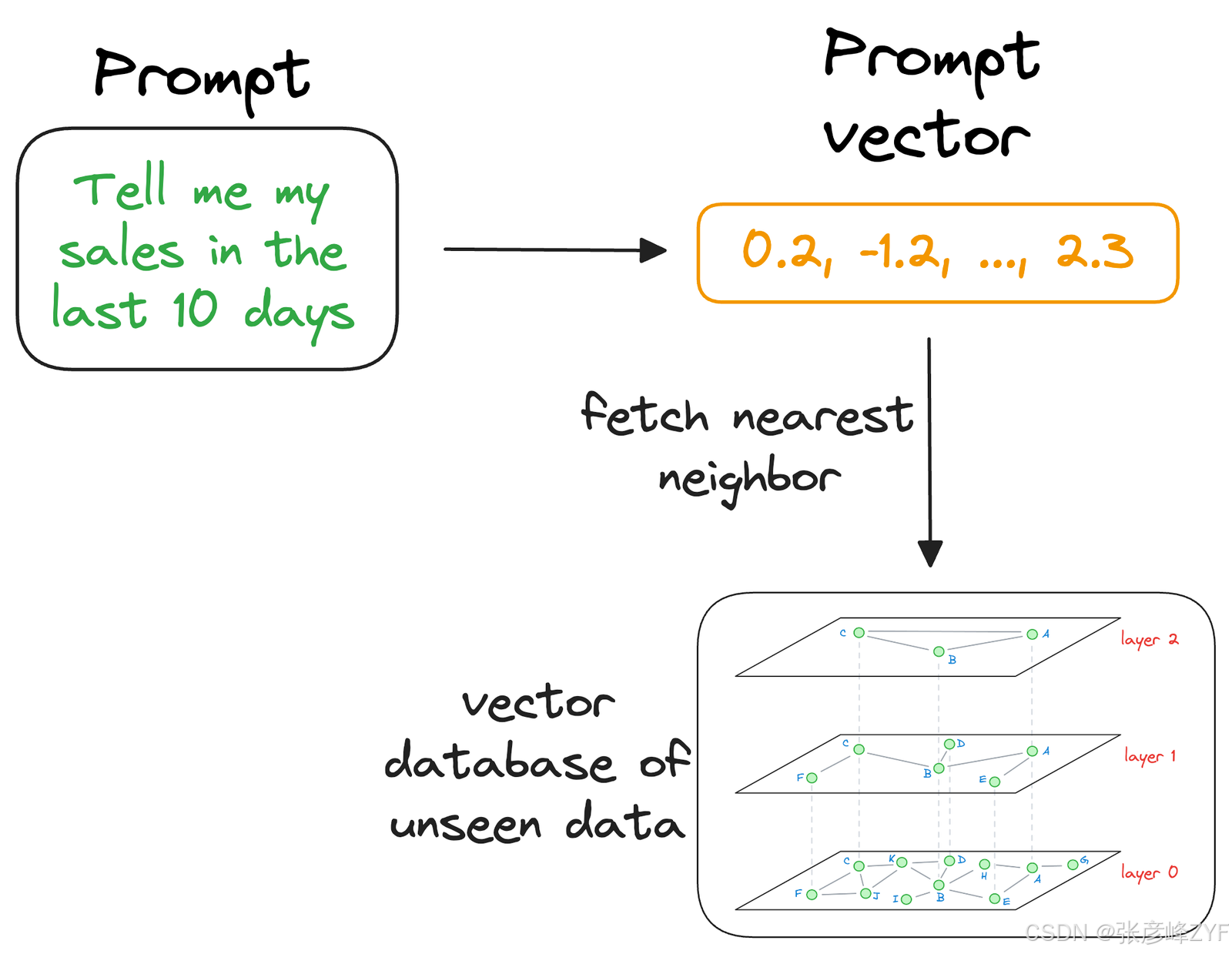
这就是为什么索引如此重要的原因,因为我们的向量数据库可能包含数百万个向量。理论上,我们可以将输入向量与向量数据库中的每个向量进行比较。但从实际应用的角度来看,我们必须尽快找到最近邻。这就是为什么我们之前讨论过的索引技术如此重要的原因。它们可以帮助我们几乎实时地找到近似最近邻。
接下来,一旦检索到近似最近邻,我们就可以收集生成这些特定向量的上下文信息。这是可行的,因为向量数据库不仅存储向量,还存储生成这些向量的原始数据。
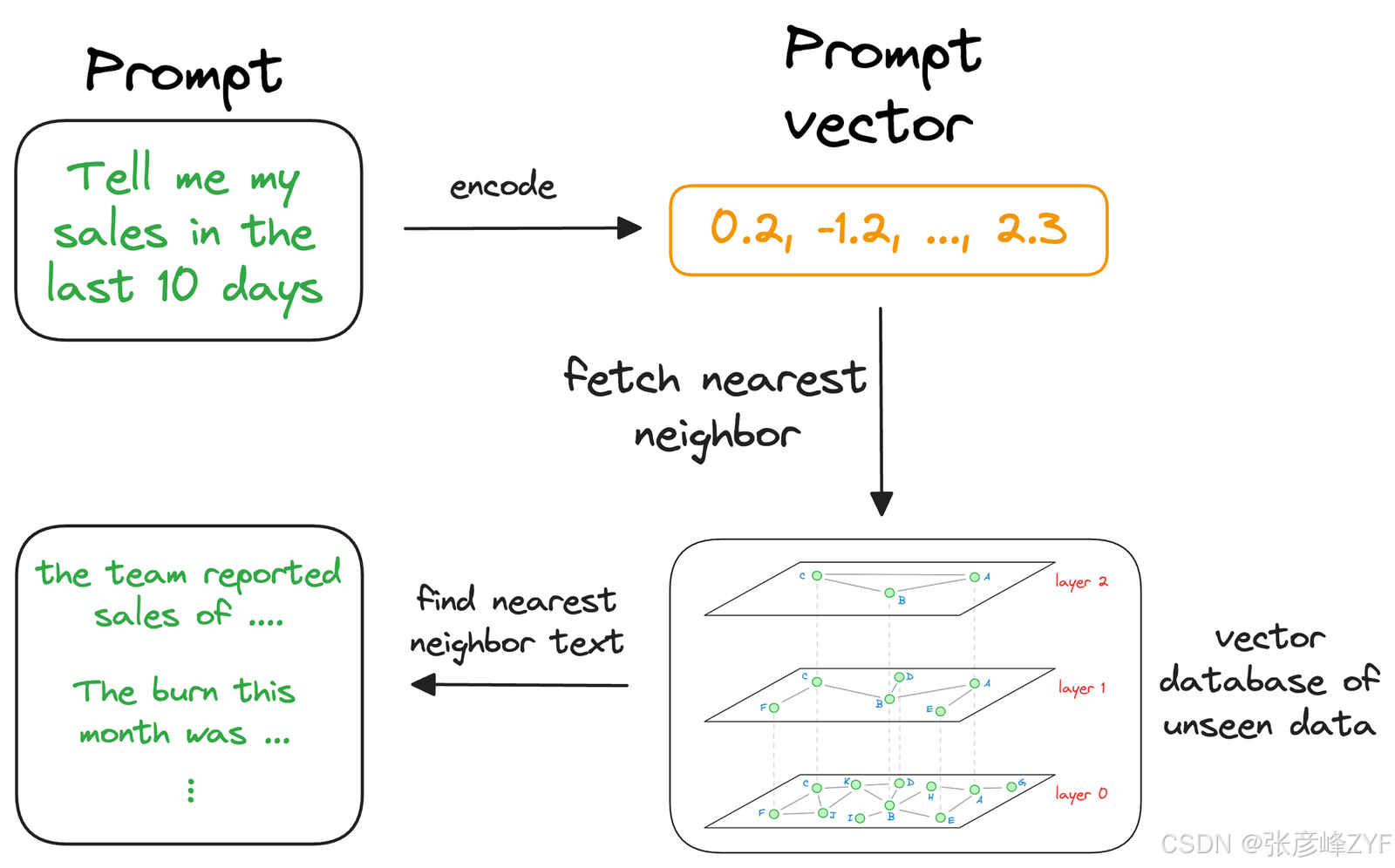
该搜索过程检索与查询向量相似的上下文,该查询向量表示 LLM 感兴趣的上下文或主题。我们可以将检索到的内容与用户提供的实际提示相结合,并将其作为 LLM 的输入。
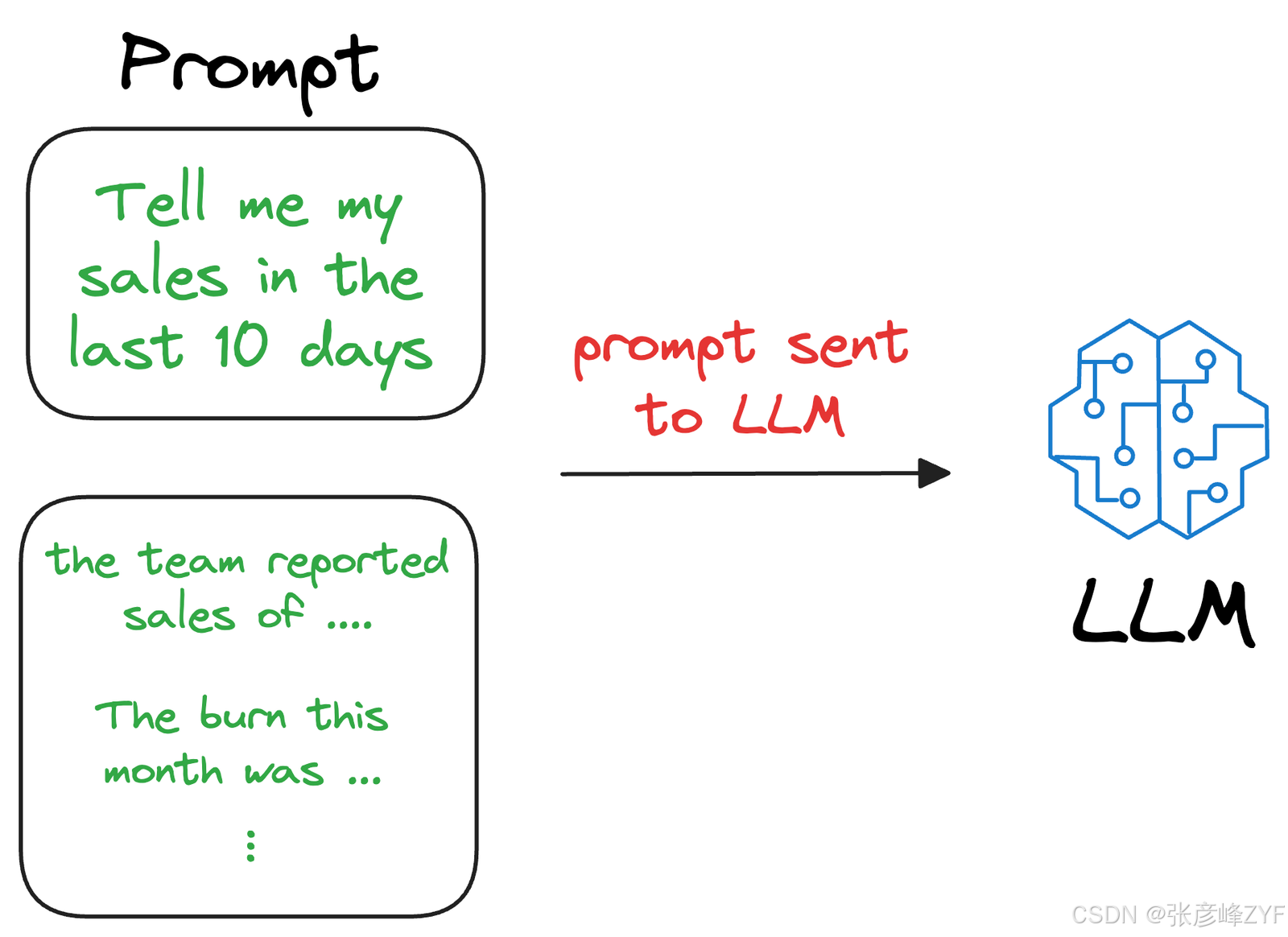
因此,LLM 在生成文本时可以轻松地将此信息融入其中,因为它现在在提示中已经有了相关细节,这就是检索增强生成(RAG),我们上面讨论的正是RAG背后的全部理念。
我们之前故意没有提到 RAG,是为了营造理想的流程,避免一开始就用这个术语吓到你。事实上,它的名称本身就完全说明了我们使用这种技术的目的:
- 检索:从知识源(例如数据库或内存)访问和检索信息。
- 增强:通过添加额外信息或上下文来增强或丰富某事物,在本例中是指文本生成过程。
- 生成:指创造或生产某物的过程,在本语境中,指生成文本或语言。
RAG的另一个关键优势在于,它能显著帮助LLM减少反应中的幻觉。当语言模型生成与现实无关的信息或捏造事实时,就会出现幻觉。这可能导致模型生成不正确或误导性的信息,这在许多应用中都可能造成问题。借助 RAG,语言模型可以利用从向量数据库中检索到的信息(预计是可靠的),以确保其响应基于现实世界的知识和上下文,从而降低出现幻觉的可能性。这使得模型的响应更加准确、可靠且与上下文相关,从而提高了模型的整体性能和实用性。
五、向量数据库提供商
如今,有很多矢量数据库提供商,可以帮助我们高效地存储和检索数据的矢量表示。
- Pinecone:Pinecone 是一款托管式矢量数据库服务,可提供快速、可扩展且高效的矢量数据存储和检索。它提供了一系列用于构建人工智能应用程序的功能,例如相似性搜索和实时分析。
- Weaviate:Weaviate 是一个 开源矢量数据库, 它功能强大、可扩展、云原生且速度快。借助 Weaviate,可以利用最先进的机器学习模型,将文本、图像等内容转换为可搜索的矢量数据库。
- Milvus:Milvus 是一个开源向量数据库,旨在为嵌入相似性搜索和人工智能应用提供支持。Milvus 使非结构化数据搜索更加便捷,并无论部署环境如何,都能提供一致的用户体验。
- Qdrant:Qdrant 是一个向量相似度搜索引擎和向量数据库。它提供生产就绪的服务,并配备便捷的 API,用于存储、搜索和管理点(即带有附加有效载荷的向量)。Qdrant 针对扩展过滤功能进行了优化,使其适用于各种神经网络或基于语义的匹配、分面搜索以及其他应用。
六、Pinecone应用展示
接下来,让我们深入了解一下如何在向量数据库中对向量进行索引,并对其执行搜索操作。
本次演示将使用 Pinecone,因为它可能是最容易上手和理解的模板之一。不过,上面也提供了许多其他模板的链接,您可以根据自己的兴趣进行探索。
首先,我们安装一些依赖项,例如 Pinecone 和 Sentence transformers:

我们将利用 SentenceTransformers 库将文本数据集编码为向量嵌入并存储到向量数据库中,它提供预训练的基于 Transformer 的架构,可以有效地将文本编码为密集向量表示,通常称为嵌入。SentenceTransformers 模型提供了各种预训练架构,例如BERT,RoBERTa和DistilBERT,专门针对句子嵌入进行了微调。这些嵌入能够捕捉文本输入之间的语义相似性和关系,使其适用于分类和聚类等下游任务。
DistilBERT 是一个相对较小的模型,因此我们将在本次演示中使用它。接下来,打开 Jupyter Notebook 并导入上述库:

接下来,我们按如下方式下载并实例化 DistilBERT 句子转换器模型:

要开始使用 Pinecone 并创建矢量数据库,我们需要一个 Pinecone API 密钥。要获得此功能,请访问 Pinecone 网站并在此处创建帐户:https://app.pinecone.io/?sessionType=signup。
注册后,我们将进入以下页面:
请从下方控制面板左侧面板获取您的 API 密钥:
点击API Keys-> Create API Key-> Enter API Key Name-> Create。
完毕!获取此 API 密钥(例如,点击复制到剪贴板按钮),返回 Jupyter Notebook,并使用此 API 密钥建立与 Pinecone 的连接,如下所示:

在Pinecone中,我们将向量嵌入存储在索引中。我们创建的任何索引中的向量都必须具有相同的维度和用于衡量相似性的距离度量。
我们使用上面创建的类对象create_index()的方法创建索引。另外,目前由于我们没有索引,运行该方法会在字典的键list_indexes()中返回一个空列表:indexes

回到创建索引的问题,我们使用类对象create_index()的方法,Pinecone如下所示:
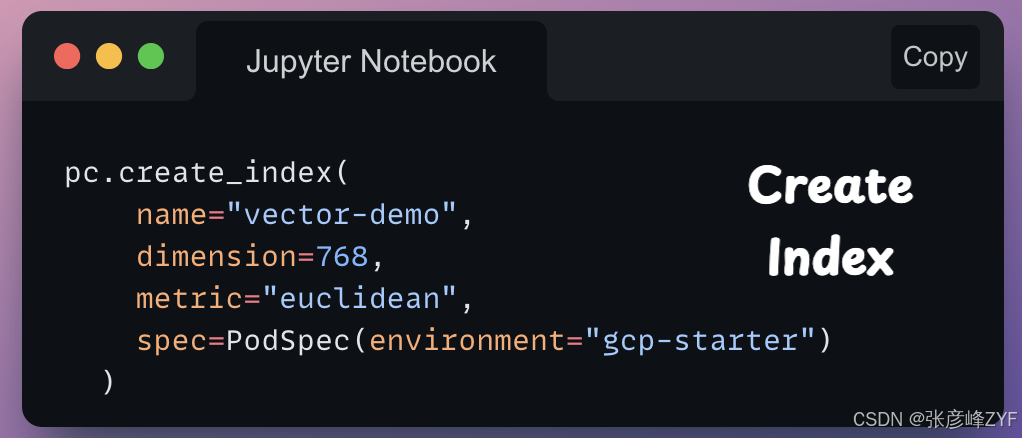
以下是该函数调用的详细分析:
- name:索引名称。这是一个用户自定义名称,可以在以后对索引执行操作时使用该名称来引用索引。
- dimension:索引中将存储的向量的维度。这应该与将要插入索引的向量的维度相匹配。我们在768此处指定是因为这是模型返回的嵌入维度SentenceTransformer。
- metric:用于计算向量间相似度的距离度量。在本例中,euclidean使用的是欧氏距离,这意味着将使用欧氏距离作为相似度度量。
- spec:一个PodSpec指定索引创建环境的对象。在本例中,索引是在名为 的 GCP(Google Cloud Platform)环境中创建的gcp-starter。
执行此方法会创建一个索引,我们也可以在仪表板中看到该索引:
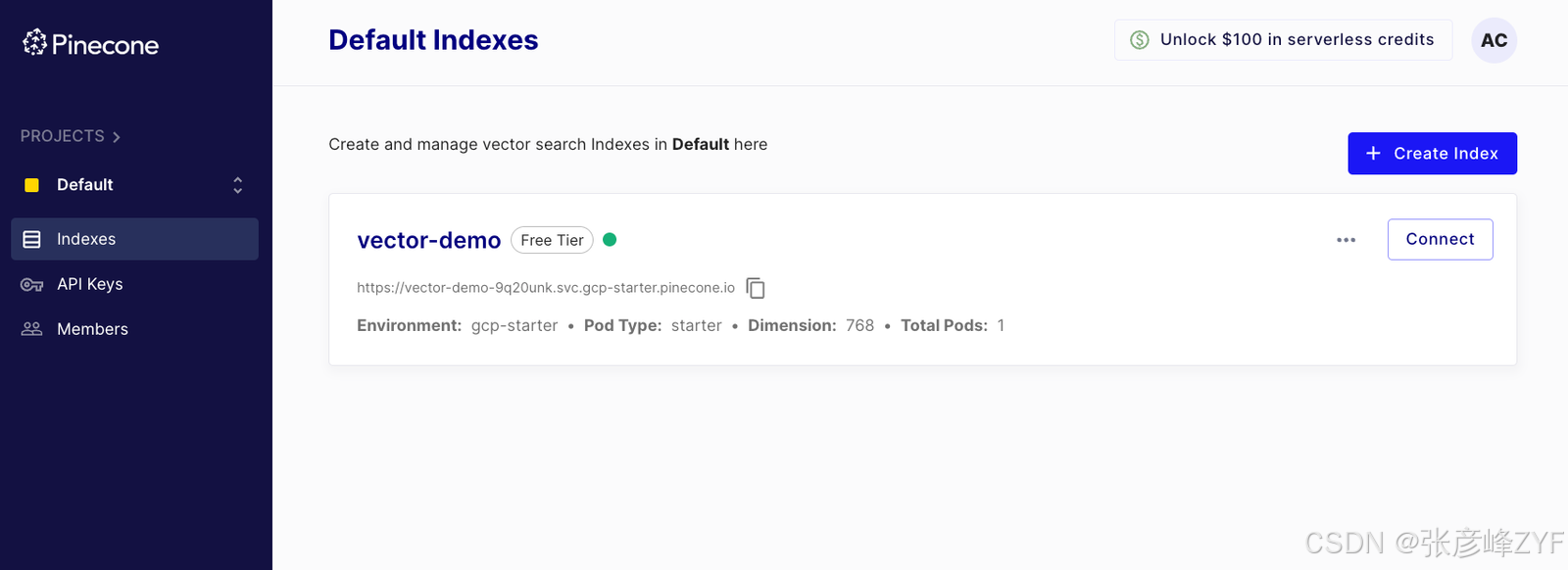
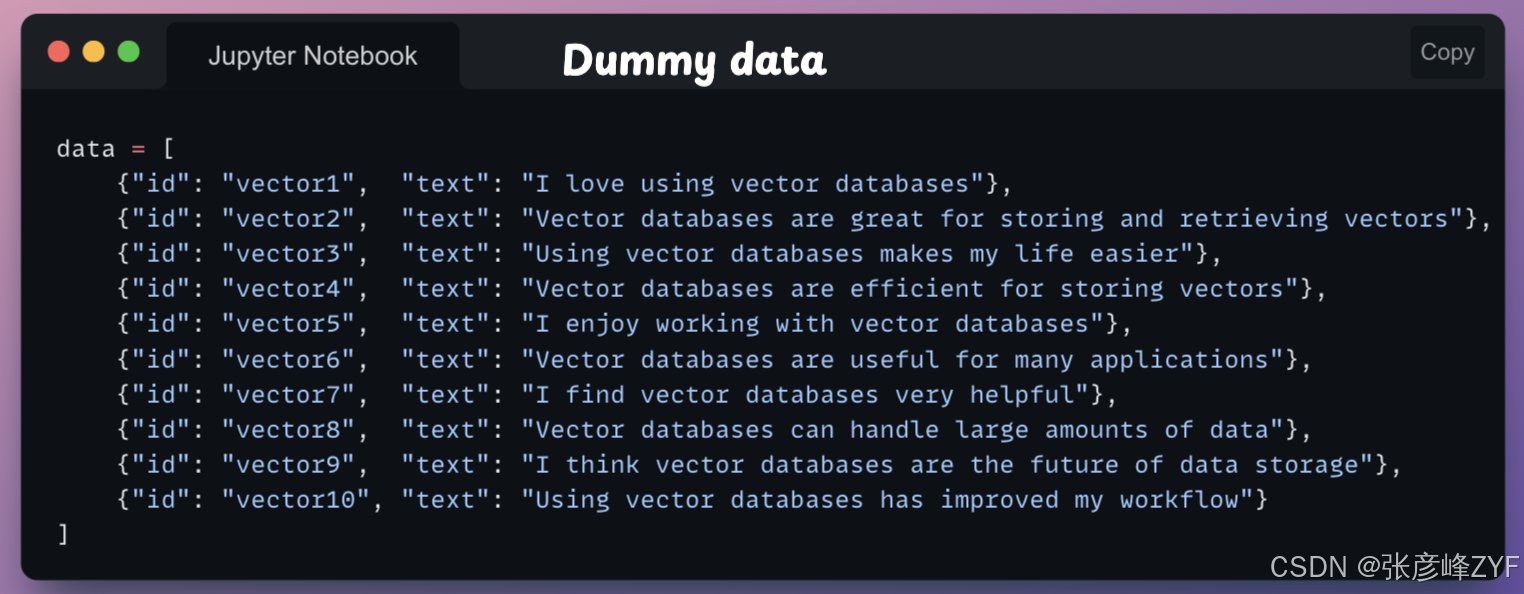
现在我们已经创建了索引,我们可以推送向量嵌入。为此,我们创建一些文本数据并使用该SentenceTransformer模型对其进行编码。下面创建了一些示例数据:
我们按如下方式为这些句子创建词嵌入:
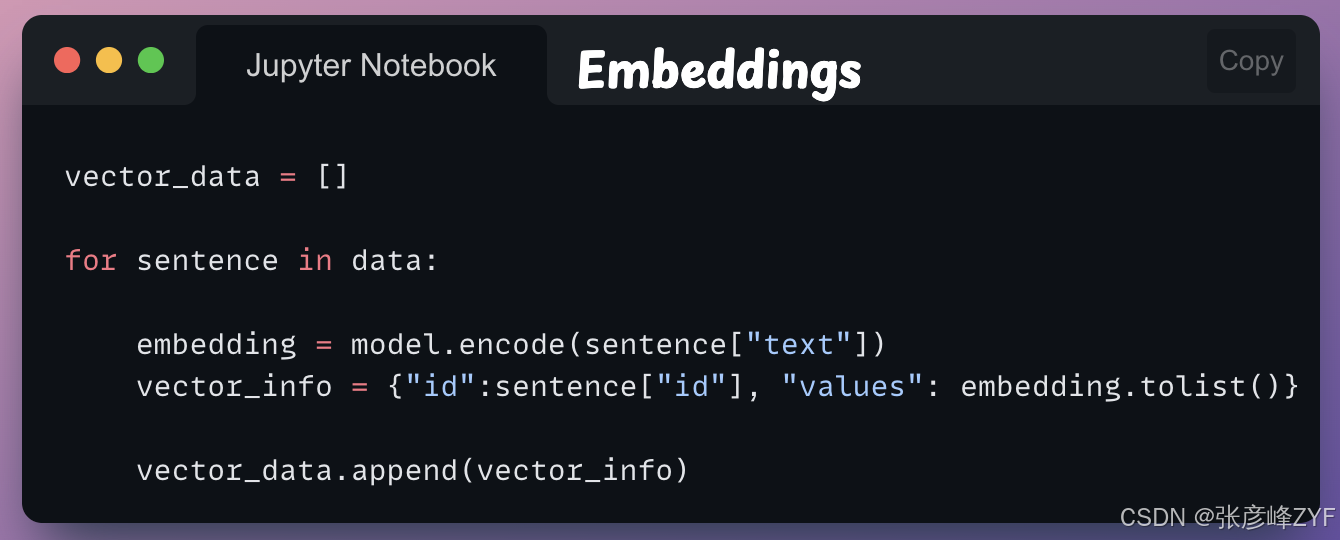
这段代码片段遍历data我们之前定义的列表中的每个句子,并使用下载的句子转换器模型将每个句子的文本编码成一个向量(model)。然后,它创建一个vector_info包含句子 ID ( id) 和相应向量 ( values) 的字典,并将该字典添加到vector_data列表中。
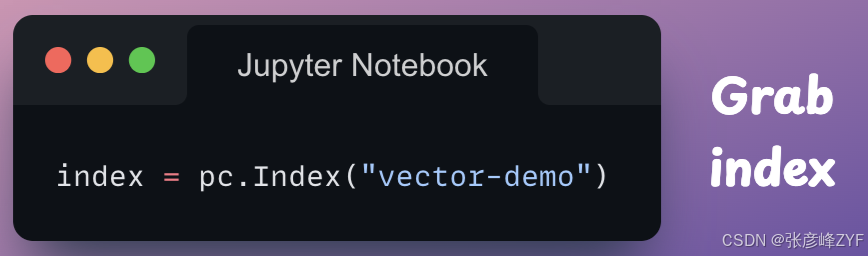
在实际应用中,同一个账户下可能存在多个索引,我们需要创建一个index对象来指定要添加这些嵌入的索引。具体操作如下:
现在我们有了嵌入向量和索引,我们 来插入 这些向量。
Upsert 是一种数据库操作,它结合了更新和插入两种操作。如果文档不存在,它会将新文档插入集合;如果文档已存在,则会更新现有文档。Upsert 是数据库(尤其是 NoSQL 数据库)中常见的操作,用于确保文档根据其在集合中的存在状态进行插入或更新。
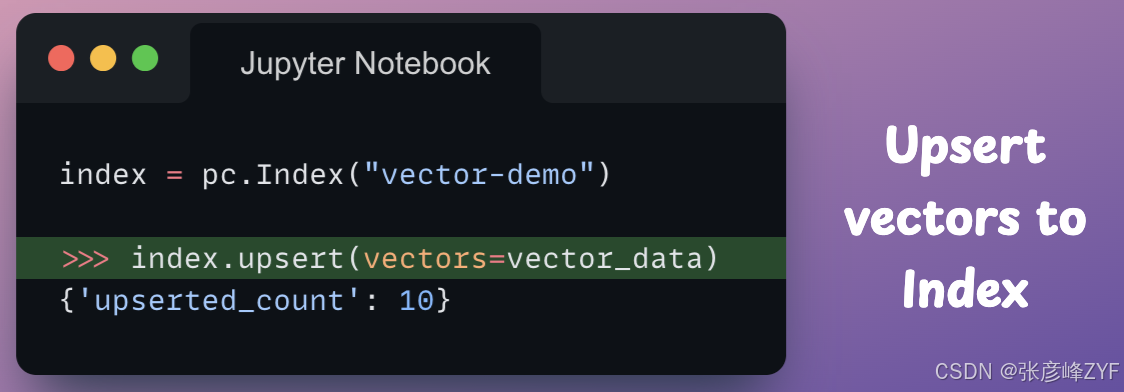
完毕!
我们已将这些向量添加到索引中。虽然输出结果已突出显示这一点,但我们可以通过以下 describe_index_stats 操作再次验证:检查当前向量计数是否与我们插入的向量数量匹配:
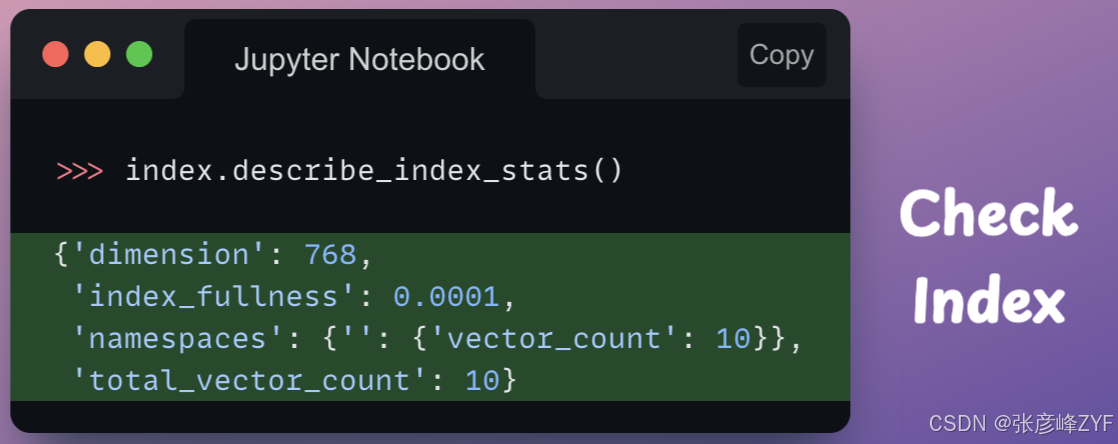
以下是返回字典中每个键的含义:
- dimension:存储在索引中的向量的维度(768在本例中为)。
- index_fullness:衡量索引填充程度的指标,通常表示索引中被占用位置的百分比。
- namespaces:一个字典,其中包含索引中每个命名空间的统计信息。在本例中,只有一个命名空间(''),其值为vector_count0 ,表示索引中10存在向量。10
- total_vector_count10:索引中所有命名空间(在本例中为 )的向量总数。
现在我们已经将向量存储在上述索引中,让我们运行相似性搜索来查看获得的结果。
我们可以使用之前创建的对象query()的方法来实现这一点。首先,我们定义搜索文本并生成其嵌入向量:
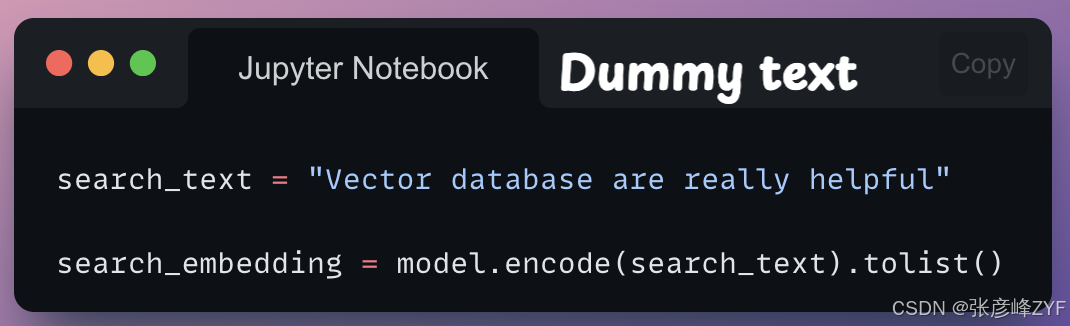
接下来,我们按如下方式查询:
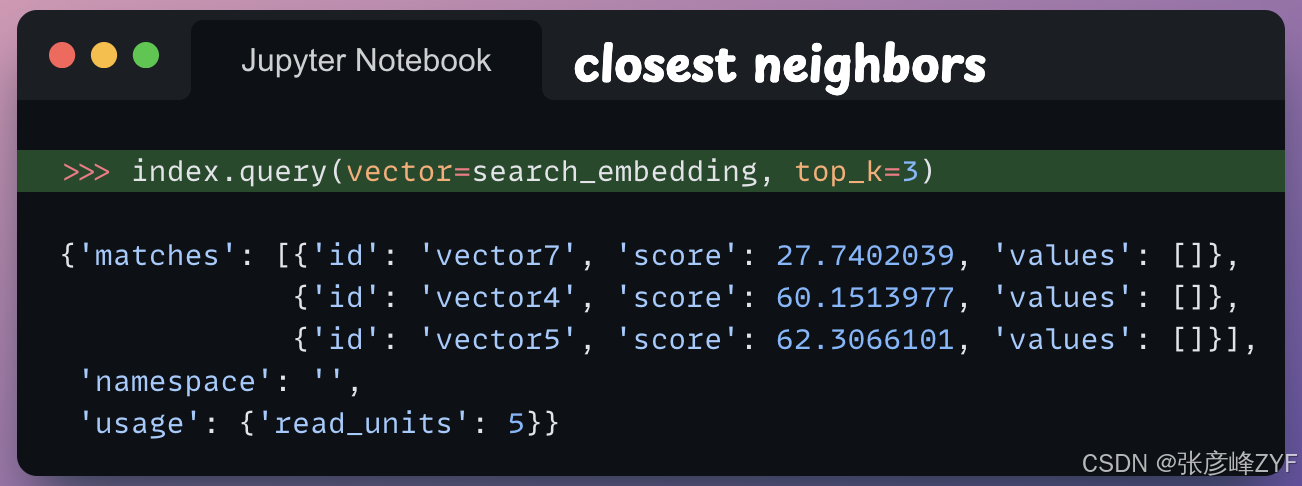
此代码片段调用query索引对象上的方法,该方法对给定的查询向量(search_embedding)执行最近邻搜索,并返回最佳3匹配项。
以下是返回字典中每个键的含义:
- matches:一个字典列表,其中每个字典包含有关匹配向量的信息。每个字典都包含id匹配向量的索引,该score索引指示查询向量和匹配向量之间的相似度。正如我们euclidean在创建此索引时指定的度量标准,更高的分数表示距离更大,进而意味着相似度更低。
- namespace:执行查询的索引的命名空间。在本例中,命名空间为空字符串(''),表示默认命名空间。
- usage:一个包含查询操作期间资源使用情况信息的字典。在本例中,read_units它表示查询操作消耗的读取单元数,即5。然而,我们最初将10向量附加到此索引中,这表明它并没有遍历所有向量来查找最近邻。
search_text从以上结果可以看出,括号( "Vector database are really helpful")的前 3 个邻项是:

七、声明
至此,我们对矢量数据库的深入探索就结束了。
综上所述,我们了解到向量数据库是专门设计用于高效存储和检索数据的向量表示的数据库。
通过将向量组织成索引,向量数据库能够实现快速准确的相似性搜索,使其在推荐系统和信息检索等任务中具有不可估量的价值。此外,我们还展示了使用 Pinecone 的服务创建和查询向量索引是多么容易。
在结束这篇文章之前,我想提一点重要的事情。矢量数据库听起来很酷,但这并不意味着你必须在每一个你想查找矢量相似性的地方都采用它们。
估是否有必要使用矢量数据库对于您的具体使用场景至关重要。对于向量数量有限的小规模应用,使用 NumPy 数组和穷举搜索等更简单的解决方案就足够了。
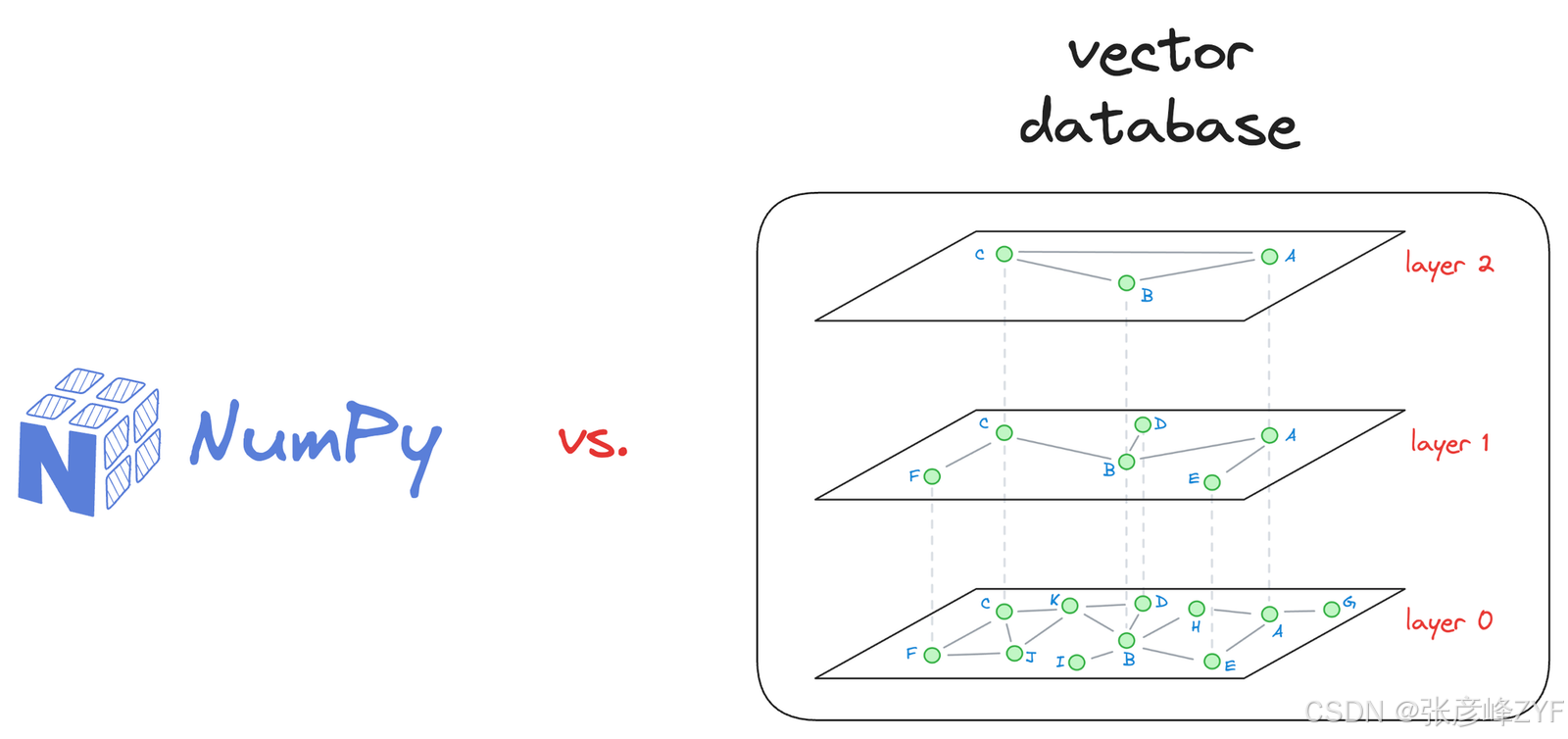
除非您看到迁移到矢量数据库能带来任何好处,例如提高应用程序的延迟、降低成本等等,否则没有必要迁移到矢量数据库。
八、总结:向量数据库,正在重构 AI 的"知识获取方式"
当我们回顾整篇文章,会发现向量数据库真正改变的,并不仅仅是"搜索速度",而是 AI 理解世界的方式。
传统数据库解决的是"数据存储"问题,而向量数据库解决的是"语义理解"问题。过去,系统只能依赖关键词做机械匹配;如今,通过 embedding 与向量检索,机器终于开始具备"理解含义"的能力。
这也是为什么 RAG 会迅速成为大模型时代的重要范式:
- 大模型负责"理解与生成"
- 向量数据库负责"记忆与检索"
- Embedding 模型负责"语义编码"
- ANN 索引负责"高效查找"
它们共同组成了一套完整的 AI 知识增强体系。但更重要的是,我们也应该意识到:向量数据库并不是"银弹"。
很多场景下,简单方案可能已经足够;很多系统真正的瓶颈,也未必是数据库本身,而可能是:
- Chunk 切分不合理
- Embedding 模型选择错误
- Metadata 设计不佳
- Rerank 缺失
- Prompt 工程薄弱
真正优秀的 RAG 系统,从来都不是"单点技术"的胜利,而是整条链路协同优化的结果。随着 Agent、长上下文模型、多模态 AI 的持续发展,向量数据库的重要性只会越来越高。
未来的大模型,很可能不再只是一个"参数化记忆体",而会逐渐演化为:
"推理能力 + 外部知识 + 长期记忆 + 实时检索" 的组合智能体。
而向量数据库,正是其中最核心的基础设施之一。希望这篇文章,能够帮助你真正建立起对:
- Embedding
- 语义检索
- ANN
- 向量索引
- RAG 架构
- AI 检索系统
的一整套系统性理解。也希望你未来在构建 AI 应用、Agent 系统、知识库问答、企业搜索平台时,能够更加清晰地理解:
为什么"检索"会成为大模型时代的新入口。
如果这篇文章对你有所帮助,也欢迎分享给更多正在学习 AI 工程、RAG 与向量数据库的朋友。
感谢阅读。
愿你既能理解原理,也能真正写出属于自己的 AI 系统。
参考链接 / 论文
官方文档 & 向量数据库
- Pinecone 官方文档
- Pinecone QuickStart 指南
- Weaviate 官方文档
- Weaviate Database 文档入口
- Milvus 官方文档
- Milvus Overview 介绍
- Milvus Docs Portal
- Qdrant 官方网站
- SentenceTransformers 官方项目
- FAISS 官方 GitHub
核心论文(Embedding / Transformer / 检索)
- BERT 原始论文(arXiv)
- BERT 论文阅读页(HuggingFace)
- BERT 应用综述论文
- Multi-passage BERT(开放域 QA)
- Simple BERT Models for Relation Extraction