随着 Anthropic 发布终端智能体 Claude Code,通过 CLI 直接让大模型接管代码审查与编写成为可能。然而,出于数据隐私或成本考量,许多开发者希望将其后端替换为本地开源模型。
本文将详细记录在 macOS 环境下,使用 oMLX 部署 Qwen 3.6 (35B) 模型,并通过 LiteLLM 解决多轮对话协议冲突,最终无缝桥接 Claude Code 的完整工程步骤。全程采用纯命令行操作,无需修改任何底层源码或编写静态配置文件。
硬件与运行环境
-
宿主机: Mac Studio (Apple M4 Max芯片, 128GB 统一内存)
注:128G 的统一内存为运行 35B 参数量的 8-bit 量化模型提供了极其充裕的显存空间,保证了极高的推理吞吐率。
-
操作系统: macOS 15+ (Sequoia 或同级)
-
推理引擎: oMLX (专为 Apple Silicon 优化的推理后端)
-
协议网关: LiteLLM (用于 Anthropic 到 OpenAI 格式的协议转换)
-
大模型 :
Qwen3.6-35B-A3B-8bit -
前端 Agent : Claude Code (
@anthropic-ai/claude-code)
核心痛点说明:为何需要 LiteLLM 做网关?
如果直接将 Claude Code 的请求打向本地 oMLX 提供的标准 OpenAI 兼容接口,会大概率遇到以下两个致命报错:
-
协议时序冲突 (HTTP 422) :Claude Code 在多轮工具调用(Tool Calling)时,会在请求体(messages 数组)的中间强行插入
system角色的消息。大多数严谨的后端推理引擎(包括 oMLX)遵循严格的 OpenAI 规范,拒绝在首轮对话之外接受system消息。 -
凭证强校验死锁 (HTTP 500) :当试图使用 LiteLLM 进行跨协议路由拦截时,LiteLLM 内部的提供商状态机会强制在环境变量中寻址对应的 API Key,若未配置则直接抛出
Missing credentials异常。
本方案的核心即是通过内存级的协议重组 与临时环境变量注入,优雅且无痕地解决上述问题。
部署与桥接步骤
整个系统分为三层架构:推理后端 -> 协议网关 -> 前端客户端。请分别打开三个独立的终端窗口执行以下操作。
Step 1: 启动 oMLX 推理后端
在终端 1 中,拉起 Qwen 3.6 模型并暴露标准服务端口(此步骤利用 M4 Max 的算力进行本地推理):
Bash
omlx serve --model /Users/model/models/Qwen3.6-35B-A3B-8bit --host 0.0.0.0 --port 8001服务启动后,oMLX 将在 8001 端口监听标准的 /v1/chat/completions 请求。
Step 2: 启动 LiteLLM 协议网关(核心处理层)
在终端 2 中,执行以下复合命令。这是打通链路的关键:
Bash
export CUSTOM_OPENAI_API_KEY="not-needed" && \
export OPENAI_API_KEY="not-needed" && \
litellm \
--model custom_openai/Qwen3.6-35B-A3B-8bit \
--api_base http://localhost:8001/v1 \
--alias claude-opus-4-7 \
--port 8000 \
--drop_params参数解析:
-
export ...="not-needed": 在当前 Shell 进程中显式注入双重虚拟凭证。这彻底阻断了 LiteLLM 的 500 凭证报错,且关闭终端即失效,不污染 macOS 系统全局环境变量。 -
custom_openai/: 触发 LiteLLM 的自定义路由逻辑。它会在内存中拦截 Claude Code 发出的错位system消息,将其自动转换为模型可接受的时序结构,解决 422 报错。 -
--alias claude-opus-4-7: 欺骗 Claude Code 客户端,声明当前网关具备顶级模型的处理能力。 -
--drop_params: 自动剥离请求体中 Anthropic 专有的、本地模型无法解析的冗余参数字段。
Step 3: 配置并拉起 Claude Code 客户端
在终端 3 中,将 Claude Code 的请求目标指向我们在本地建立的 8000 端口网关:
# 声明网关地址(注意:无需拼接 /v1 或 /messages 后缀,Claude Code 内部会自动处理)
export ANTHROPIC_BASE_URL=http://localhost:8000
export ANTHROPIC_API_KEY=not-needed
# 启动智能体
claude随着 Anthropic 发布终端智能体 Claude Code,通过 CLI 直接让大模型接管代码审查与编写成为可能。然而,出于数据隐私或成本考量,许多开发者希望将其后端替换为本地开源模型。
本文将详细记录在 macOS 环境下,使用 oMLX 部署 Qwen 3.6 (35B) 模型,并通过 LiteLLM 解决多轮对话协议冲突,最终无缝桥接 Claude Code 的完整工程步骤。全程采用纯命令行操作,无需修改任何底层源码或编写静态配置文件。
硬件与运行环境
-
宿主机: Mac Studio (Apple M4 Max芯片, 128GB 统一内存)
注:128G 的统一内存为运行 35B 参数量的 8-bit 量化模型提供了极其充裕的显存空间,保证了极高的推理吞吐率。
-
操作系统: macOS 15+ (Sequoia 或同级)
-
推理引擎: oMLX (专为 Apple Silicon 优化的推理后端)
-
协议网关: LiteLLM (用于 Anthropic 到 OpenAI 格式的协议转换)
-
大模型 :
Qwen3.6-35B-A3B-8bit -
前端 Agent : Claude Code (
@anthropic-ai/claude-code)
核心痛点说明:为何需要 LiteLLM 做网关?
如果直接将 Claude Code 的请求打向本地 oMLX 提供的标准 OpenAI 兼容接口,会大概率遇到以下两个致命报错:
-
协议时序冲突 (HTTP 422) :Claude Code 在多轮工具调用(Tool Calling)时,会在请求体(messages 数组)的中间强行插入
system角色的消息。大多数严谨的后端推理引擎(包括 oMLX)遵循严格的 OpenAI 规范,拒绝在首轮对话之外接受system消息。 -
凭证强校验死锁 (HTTP 500) :当试图使用 LiteLLM 进行跨协议路由拦截时,LiteLLM 内部的提供商状态机会强制在环境变量中寻址对应的 API Key,若未配置则直接抛出
Missing credentials异常。
本方案的核心即是通过内存级的协议重组 与临时环境变量注入,优雅且无痕地解决上述问题。
部署与桥接步骤
整个系统分为三层架构:推理后端 -> 协议网关 -> 前端客户端。请分别打开三个独立的终端窗口执行以下操作。
Step 1: 启动 oMLX 推理后端
在终端 1 中,拉起 Qwen 3.6 模型并暴露标准服务端口(此步骤利用 M4 Max 的算力进行本地推理):
Bash
omlx serve --model /Users/model/models/Qwen3.6-35B-A3B-8bit --host 0.0.0.0 --port 8001服务启动后,oMLX 将在 8001 端口监听标准的 /v1/chat/completions 请求。
Step 2: 启动 LiteLLM 协议网关(核心处理层)
在终端 2 中,执行以下复合命令。这是打通链路的关键:
Bash
export CUSTOM_OPENAI_API_KEY="not-needed" && \
export OPENAI_API_KEY="not-needed" && \
litellm \
--model custom_openai/Qwen3.6-35B-A3B-8bit \
--api_base http://localhost:8001/v1 \
--alias claude-opus-4-7 \
--port 8000 \
--drop_params参数解析:
-
export ...="not-needed": 在当前 Shell 进程中显式注入双重虚拟凭证。这彻底阻断了 LiteLLM 的 500 凭证报错,且关闭终端即失效,不污染 macOS 系统全局环境变量。 -
custom_openai/: 触发 LiteLLM 的自定义路由逻辑。它会在内存中拦截 Claude Code 发出的错位system消息,将其自动转换为模型可接受的时序结构,解决 422 报错。 -
--alias claude-opus-4-7: 欺骗 Claude Code 客户端,声明当前网关具备顶级模型的处理能力。 -
--drop_params: 自动剥离请求体中 Anthropic 专有的、本地模型无法解析的冗余参数字段。
Step 3: 配置并拉起 Claude Code 客户端
在终端 3 中,将 Claude Code 的请求目标指向我们在本地建立的 8000 端口网关:
Bash
# 声明网关地址(注意:无需拼接 /v1 或 /messages 后缀,Claude Code 内部会自动处理)
export ANTHROPIC_BASE_URL=http://localhost:8000
export ANTHROPIC_API_KEY=not-needed
# 启动智能体
claude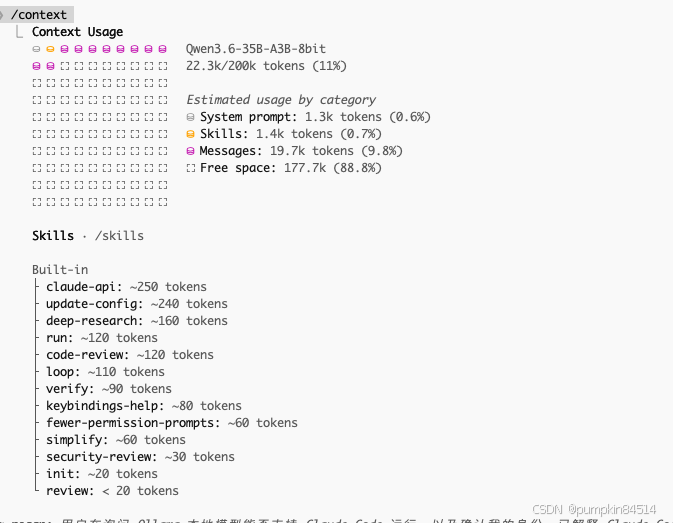
(mlx-qwen-311) model@pumpkindeMac-Studio ~ % sudo powermetrics --samplers gpu_power
Machine model: Mac16,9
OS version: 25F71
Boot arguments:
Boot time: Sun May 24 16:52:51 2026
*** Sampled system activity (Sat May 30 03:04:06 2026 +0800) (5005.32ms elapsed) ***
**** GPU usage ****
GPU HW active frequency: 740 MHz
GPU HW active residency: 7.66% (338 MHz: .94% 618 MHz: 0% 796 MHz: 6.7% 924 MHz: 0% 952 MHz: 0% 1056 MHz: 0% 1062 MHz: 0% 1182 MHz: 0% 1182 MHz: 0% 1312 MHz: 0% 1242 MHz: 0% 1380 MHz: 0% 1326 MHz: 0% 1470 MHz: 0% 1578 MHz: 0%)
GPU SW requested state: (P1 : 0% P2 : 0% P3 : 100% P4 : 0% P5 : 0% P6 : 0% P7 : 0% P8 : 0% P9 : 0% P10 : 0% P11 : 0% P12 : 0% P13 : 0% P14 : 0% P15 : 0%)
GPU SW state: (SW_P1 : .94% SW_P2 : 0% SW_P3 : 6.7% SW_P4 : 0% SW_P5 : 0% SW_P6 : 0% SW_P7 : 0% SW_P8 : 0% SW_P9 : 0% SW_P10 : 0% SW_P11 : 0% SW_P12 : 0% SW_P13 : 0% SW_P14 : 0% SW_P15 : 0%)
GPU idle residency: 92.34%
GPU Power: 33 mW