数据分析
数据分析:从一堆看似杂乱的数据中,通过数据清洗,分析,可视化等手段,找出有价值的信息或结论,从而帮助我们解决实际的问题
例如:用户订单数据的分析、电影榜单数据分析、学生成绩数据分析
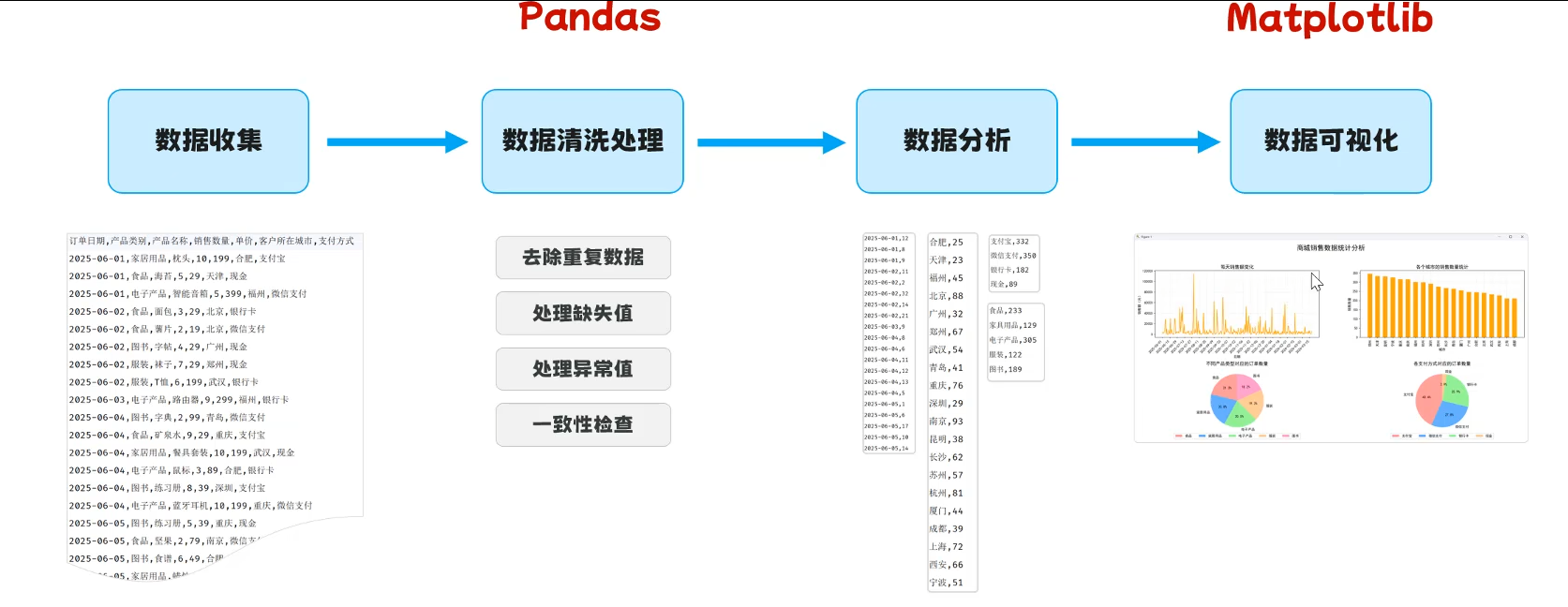
学习计划:
环境准备 → Pandas基础 → Matplotlib基础 → 数据分析案例
环境准备
Jupyter Notebook
Jupyter Notebook是一个基于Web网页的、交互式的编程笔记本,让你可以把代码、运行结果、图标和笔记本全部放在一个文件里(在数据分析、机器学习、教学和科研等领域的数据实验室)
快捷键:
Ctrl + 回车 运行
Ctrl + 空格 另开单元格
运行:
jupyter lab 或者 jupyter notebook
Pandas介绍
Pandas是一个功能强大的结构化数据分析的工具集,底层是局域Numpy,无论是在数据分析领域、还是大数据开发场景都有显著的优势。
核心:DataFrame(类似表格),Series(类似表格的一列)
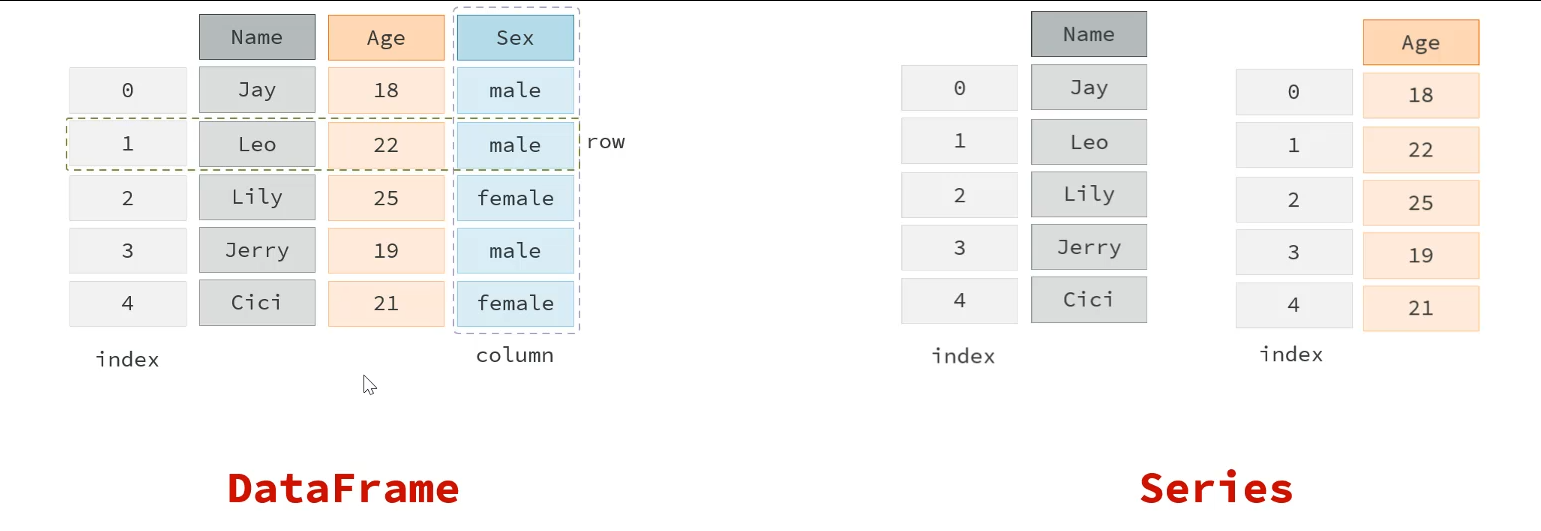
Pandas初体验
需求:基于Pandas统计班级成员的最高分,最低分,平均分,总分
python
import pandas as pd
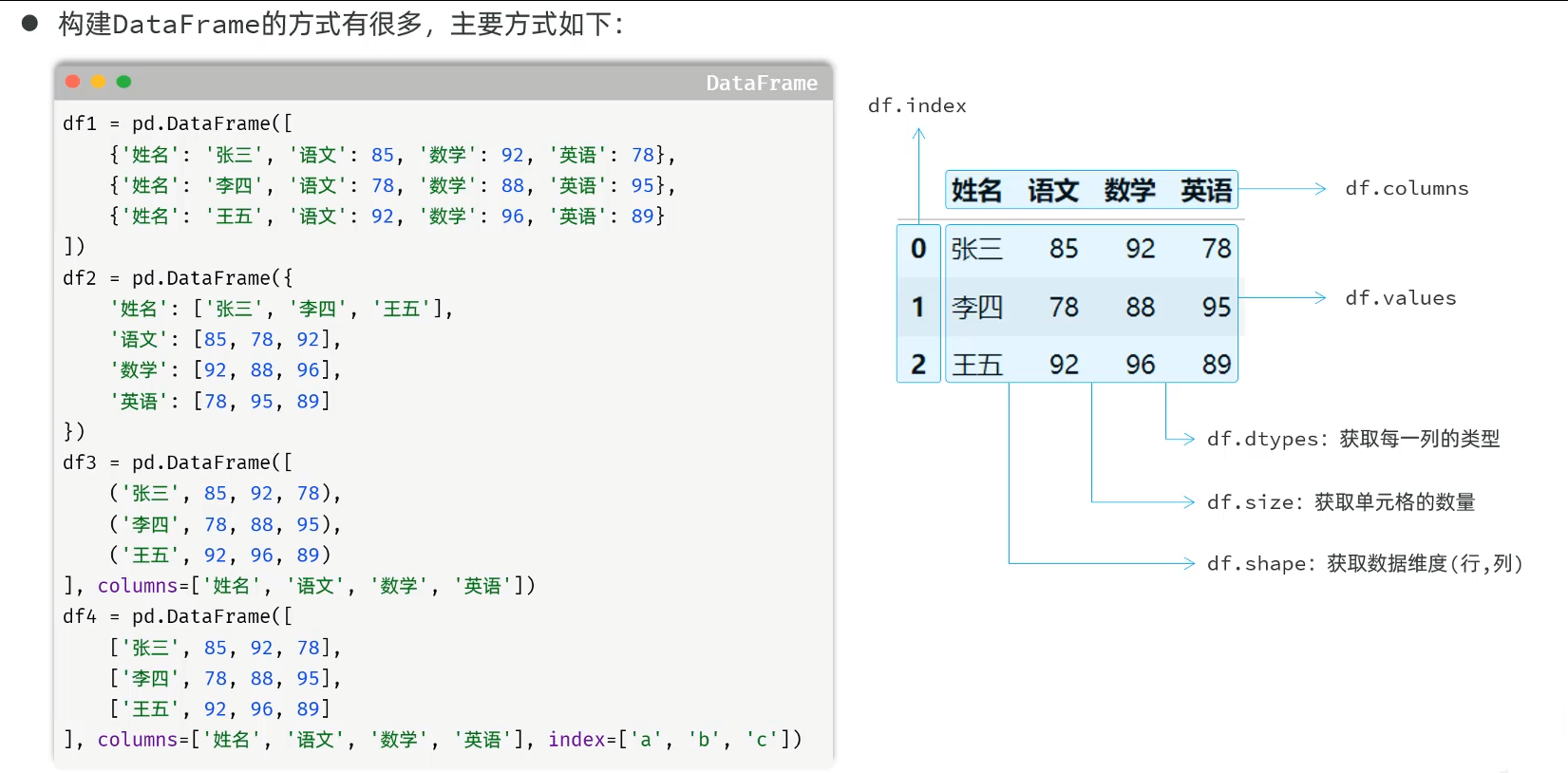
df1 = pd.DataFrame([
{'姓名': '张三', '语文': 85, '数学': 92, '英语': 78},
{'姓名': '李四', '语文': 78, '数学': 88, '英语': 95},
{'姓名': '王五', '语文': 92, '数学': 96, '英语': 89},
{'姓名': '赵六', '语文': 85, '数学': 90, '英语': 90},
{'姓名': '孙七', '语文': 72, '数学': 59, '英语': 66},
{'姓名': '周八', '语文': 80, '数学': 76, '英语': 68},
{'姓名': '吴九', '语文': 85, '数学': 85, '英语': 85},
{'姓名': '郑十', '语文': 57, '数学': 68, '英语': 49}
])
print("语文成绩:")
print(f"语文最高分:{df1['语文'].max()},最低分:{df1['语文'].min()},平均分:{df1['语文'].mean()},总分:{df1['语文'].sum()}")
print(f"数学最高分:{df1['数学'].max()},最低分:{df1['数学'].min()},平均分:{df1['数学'].mean()},总分:{df1['数学'].sum()}")
print(f"英语最高分:{df1['英语'].max()},最低分:{df1['英语'].min()},平均分:{df1['英语'].mean()},总分:{df1['英语'].sum()}")Datafream
python
import pandas as pd
df1 = pd.DataFrame([
{'姓名': '张三', '语文': 85, '数学': 92, '英语': 78},
{'姓名': '李四', '语文': 78, '数学': 88, '英语': 95},
{'姓名': '王五', '语文': 92, '数学': 96, '英语': 89},
{'姓名': '赵六', '语文': 85, '数学': 90, '英语': 90},
{'姓名': '孙七', '语文': 72, '数学': 59, '英语': 66},
{'姓名': '周八', '语文': 80, '数学': 76, '英语': 68},
{'姓名': '吴九', '语文': 85, '数学': 85, '英语': 85},
{'姓名': '郑十', '语文': 57, '数学': 68, '英语': 49}
])
print("语文成绩:")
print(f"语文最高分:{df1['语文'].max()},最低分:{df1['语文'].min()},平均分:{df1['语文'].mean()},总分:{df1['语文'].sum()}")
print(f"数学最高分:{df1['数学'].max()},最低分:{df1['数学'].min()},平均分:{df1['数学'].mean()},总分:{df1['数学'].sum()}")
print(f"英语最高分:{df1['英语'].max()},最低分:{df1['英语'].min()},平均分:{df1['英语'].mean()},总分:{df1['英语'].sum()}")
df2 = pd.DataFrame([
['王林', 85, 92, 78],
['李华', 78, 88, 95],
['张三', 92, 96, 89],
], columns = ['姓名', '语文', '数学', '英语'],index=['学生1', '学生2', '学生3'])
df2.shape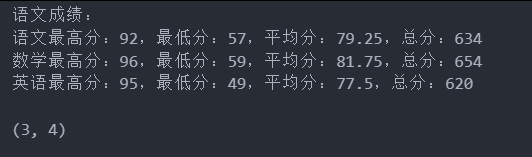
Series

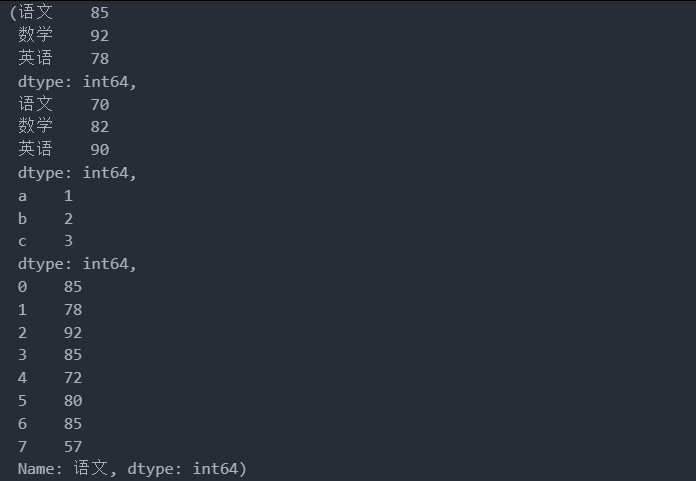
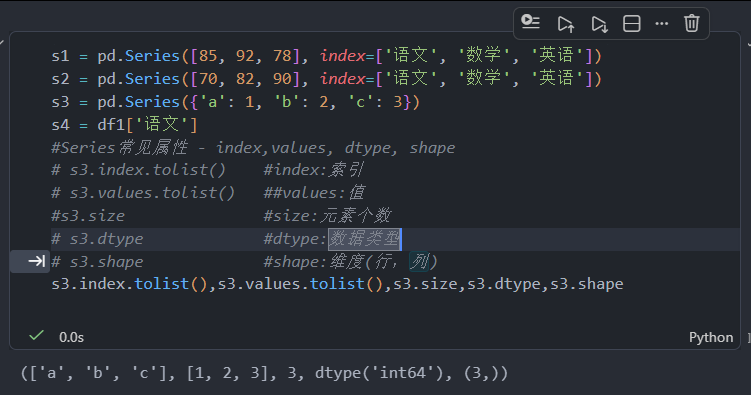
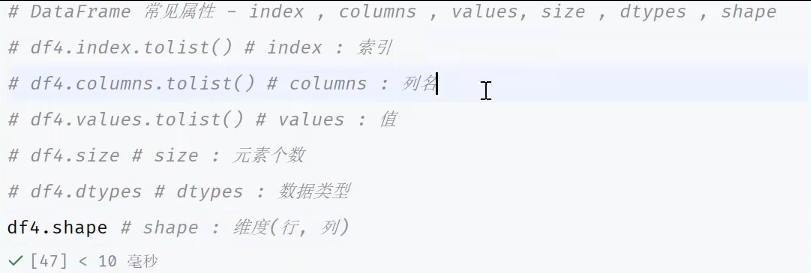
DataFream以及Series总结

数据的读取与写入
基于Pandas中提供的API,可以很方便的各类数据文件(csv,Excel,数据库,网络数据)的读取和写入。
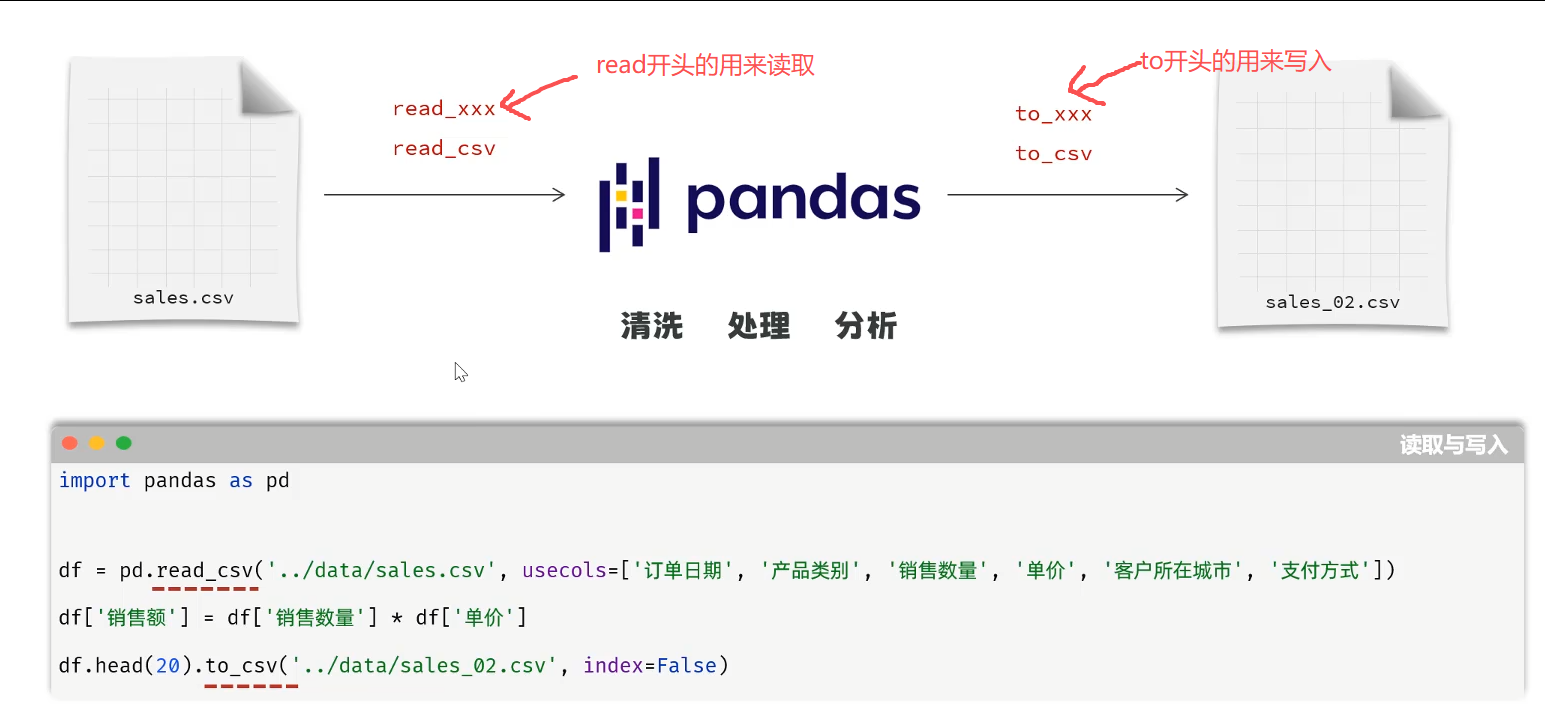
python
import pandas as pd
#读取数据
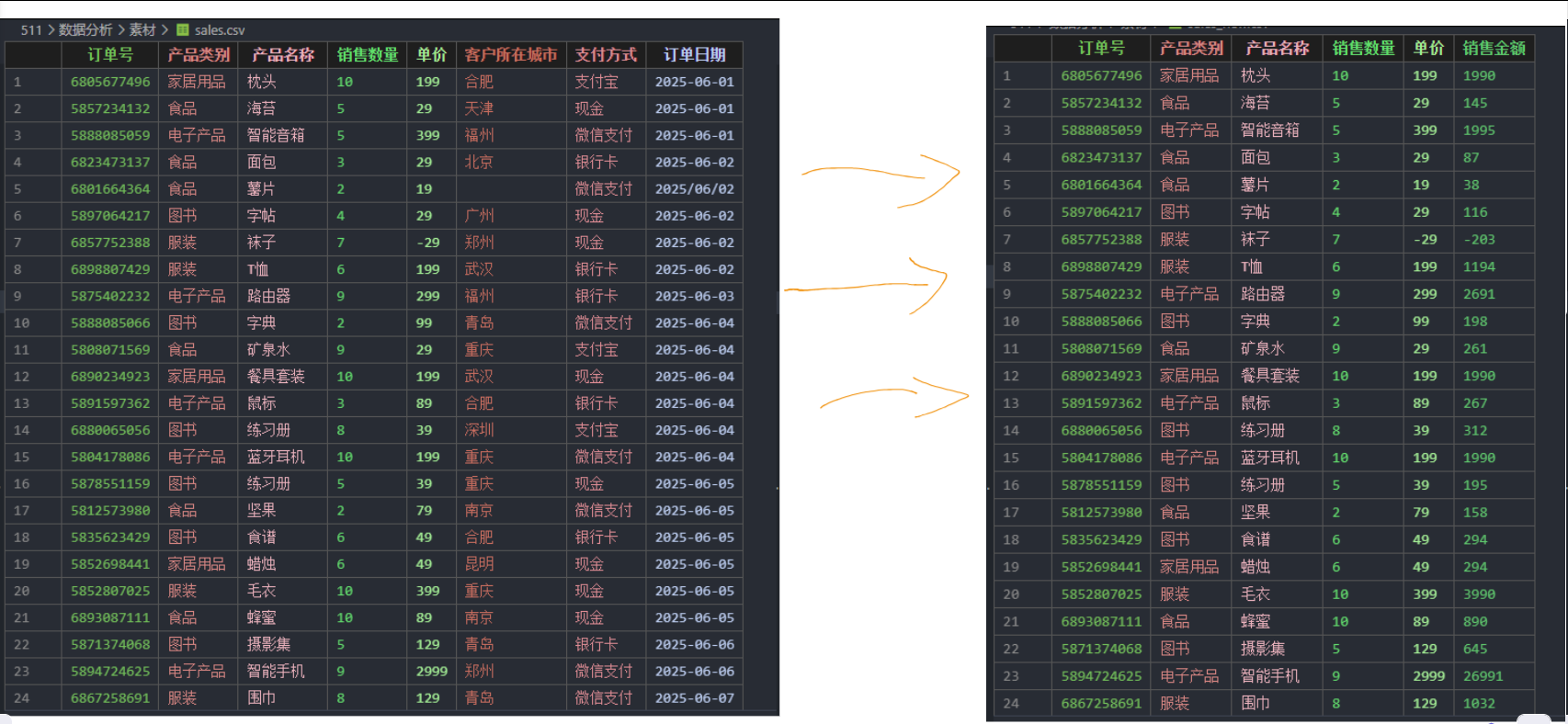
df = pd.read_csv('素材/sales.csv',usecols=['订单号','产品类别','产品名称','销售数量','单价'])
#数据处理
df['销售金额'] = df['销售数量'] * df['单价']
#写入数据
df.to_csv('素材/sales_new.csv',index=False)通过上述代码可以让左图变成右图
数据的查看、选择及过滤
列
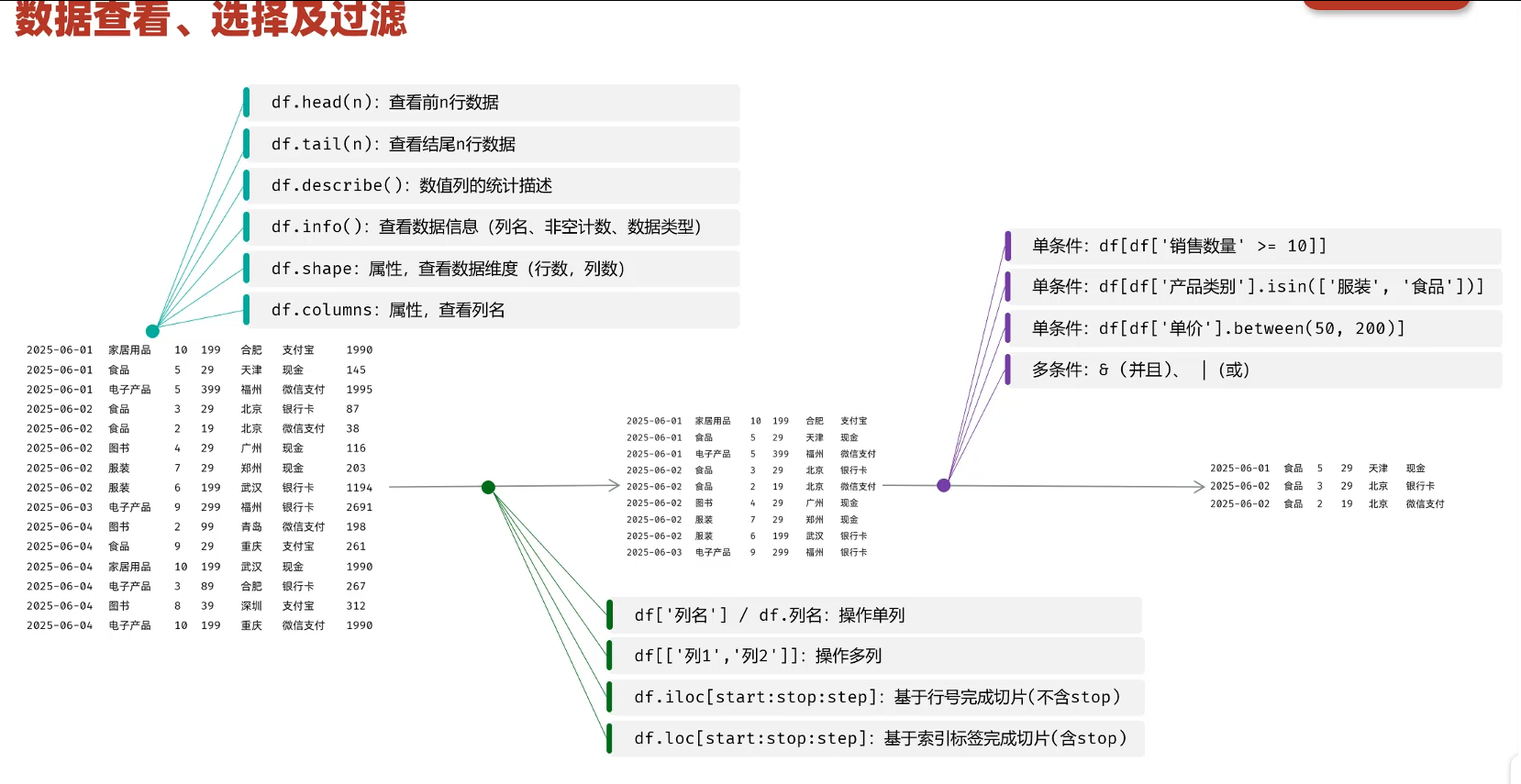
df.head(n):查看前n行数据
df.tail(n):查看结尾n行数据
df.describe():数值列的统计描述
df.info():查看数据信息(列名、非空计数、数据类型)
df.shape():属性,查看数据维度(行数,列数)
df.columns:属性,查看列名
行

过滤

python
df1 = pd.read_csv('素材/sales.csv',usecols=['订单号','产品类别','产品名称','销售数量','单价'])
# df1.info() #获取数据信息(列名,非空计数,数据类型等)
# df1.head(5) #查看前5行数据
# df1.tail(5) #查看后5行数据
# df1.describe() #数据描述
# df1.shape #数据行数和列数
# df1.columns #列名
df1.info(),df1.head(5),df1.tail(5),df1.describe(),df1.shape,df1.columns运行结果:
python
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单号 1000 non-null int64
1 产品类别 1000 non-null object
2 产品名称 1000 non-null object
3 销售数量 1000 non-null int64
4 单价 1000 non-null int64
dtypes: int64(3), object(2)
memory usage: 39.2+ KB
(None,
订单号 产品类别 产品名称 销售数量 单价
0 6805677496 家居用品 枕头 10 199
1 5857234132 食品 海苔 5 29
2 5888085059 电子产品 智能音箱 5 399
3 6823473137 食品 面包 3 29
4 6801664364 食品 薯片 2 19,
订单号 产品类别 产品名称 销售数量 单价
995 5887473055 图书 小说 10 49
996 5808511756 食品 坚果 2 79
997 5811169466 服装 围巾 4 129
998 6876456690 食品 果汁 7 39
999 6842608338 食品 蜂蜜 5 89,
订单号 销售数量 单价
count 1.000000e+03 1000.000000 1000.000000
mean 6.366022e+09 5.539000 388.152000
std 5.015131e+08 2.908769 991.402736
min 5.800194e+09 1.000000 -29.000000
25% 5.851898e+09 3.000000 49.000000
50% 6.802488e+09 5.000000 89.000000
75% 6.854162e+09 8.000000 299.000000
max 6.899878e+09 10.000000 5999.000000,
(1000, 5),
Index(['订单号', '产品类别', '产品名称', '销售数量', '单价'], dtype='object'))常规选择行
python
# 1. 选择列
# 1.1 单列
# df2['产品名称']
# df2.产品名称
# 1.2 多列
# df2[['产品名称', '单价']]
# df2[['产品类别', '产品名称', '单价']]
# 2. 选择行 - iloc , loc
# 2.1 iloc ----> 基于行号选择行(不包含结束位置), 语法: df.iloc[start:stop:step]
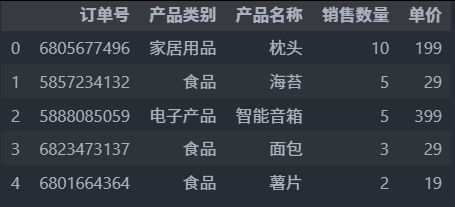
df2.iloc[0:5:1]
df2.iloc[0:5]
# 2.2 loc ----> 基于行索引选择行(包含结束位置), 语法: df.loc[start:stop:step]
df2.loc[6805677496:5888085066:2]运行结果:
| 代码 | 作用说明 |
|---|---|
df2['产品名称'] / df2.产品名称 |
提取 DataFrame 中名为产品名称的单列数据,返回 Series |
df2[['产品名称', '单价']] |
同时提取产品名称和单价两列,返回 DataFrame |
df2.iloc[0:5] |
按行号提取前 5 行数据(索引从 0 开始,不含结束位置) |
df2.loc[6805677496:5888085066:2] |
按行索引值提取数据,步长为 2,且包含结束位置 |
iloc vs loc 核心区别:
iloc:基于整数位置 筛选,切片是左闭右开 ([start:stop))loc:基于标签索引 筛选,切片是左闭右闭 ([start:stop])