标签:#AI Agent #ReAct范式 #大模型工程化 #智能体执行原理 #LLM实战
前言
2026年AI Agent技术全面爆发,从个人助手到企业级自动化系统,智能体正在重构各行各业的工作方式。但绝大多数开发者都会遇到同一个核心困惑:AI Agent到底是怎么自主思考、自主调用工具、自主完成复杂任务闭环的?
答案就是:依靠 ReAct 执行范式。
ReAct 是目前 90% 以上开源Agent(LangChain、LlamaIndex、Meta Agent)的底层核心执行逻辑,也是工业界公认的AI Agent标准思考框架。如果说大模型是Agent的大脑,那ReAct就是Agent的"思考与行动规则",是让AI从"只会说话"变成"会干活"的关键转折点。
本文从零彻底吃透ReAct:解决「什么是ReAct、为什么需要ReAct、ReAct思考流程、源码底层逻辑、企业级实战、常见踩坑与优化」,读完彻底打通AI Agent底层运行机制。
一、什么是 ReAct?官方定义与核心思想
1.1 ReAct 起源
ReAct 源自普林斯顿大学与Google Brain 2022 年联合发表的经典论文《ReAct: Synergizing Reasoning and Acting in Language Models》。
在ReAct出现之前,大模型只有单纯的推理能力(Reasoning) ,只能基于自身参数知识输出答案,存在严重的幻觉、知识滞后、无法实操的问题;而单纯的工具调用只有行动能力(Acting),缺乏逻辑推理,无法自主判断何时调用工具、调用什么工具。
ReAct 的核心颠覆式创新:将大模型的推理思考(Thought)与外部工具行动(Action)进行闭环融合。
1.2 核心定义
ReAct = Reasoning(推理思考) + Acting(工具行动)
它是一套迭代式循环执行范式:Agent不再一次性输出答案,而是通过「思考→行动→观察→再思考」的无限循环,逐步拆解复杂任务、调用外部工具、修正推理偏差,直到任务完成输出最终结果。
1.3 核心价值(解决的行业痛点)
-
解决大模型知识滞后、幻觉严重问题:通过工具实时获取外部最新数据;
-
解决大模型无法实操问题:从"只会说话"变成"会计算、会查询、会操作";
-
解决复杂任务拆解难问题:自动拆分多步骤任务,分步迭代执行;
-
完美适配工程化落地:ReAct是AI Agent Harness流程编排层的核心执行内核,为企业级应用提供标准化执行逻辑。
二、ReAct 核心执行闭环:三步循环机制
所有基于ReAct的Agent,底层都是统一的T-A-O 循环闭环,这是必须掌握的核心底层逻辑,没有任何例外。
2.1 三大核心环节(T-A-O)
1. Thought(推理思考)
大模型基于当前用户问题、历史上下文、已有工具列表,进行自主推理判断:
-
当前任务是否需要调用工具?
-
需要调用哪一个工具?
-
工具入参应该如何构造?
-
当前任务是否已经完成,可以直接输出答案?
这一步是Agent的智能核心,完全依靠大模型的理解与推理能力。
2. Action(工具行动)
Agent根据Thought的推理结果,通过Harness工具编排层,执行具体外部操作:
-
调用计算器、搜索引擎、数据库查询、接口请求、代码解释器等;
-
严格按照Harness约束规则执行,受超时、重试、权限管控;
-
单次仅执行单一工具任务,保证流程可控。
3. Observation(结果观察)
获取Action工具执行的返回结果,将结果作为新的上下文信息,喂给大模型,进入下一轮循环。
Observation 是修正模型幻觉、补充真实信息的关键,让模型不再依赖陈旧参数知识。
2.2 完整闭环逻辑
用户提问 → Thought思考 → Action执行工具 → Observation获取结果 → 再次Thought迭代 → 任务完成 → 输出最终答案
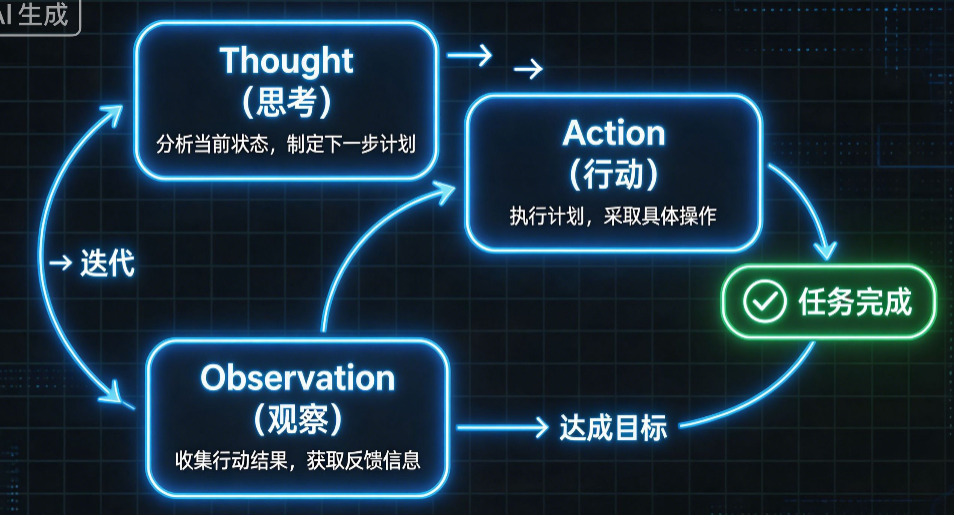
简单理解:人类解决复杂问题的思路,就是ReAct的底层逻辑。遇到不会的问题先思考、再查资料、看完资料再思考,直到解决问题。
三、ReAct范式 VS 传统一次性Prompt范式
很多新手分不清普通问答和Agent的区别,本质就是「是否具备ReAct循环能力」,对比如下:
| 对比维度 | 传统一次性Prompt问答 | ReAct智能体范式 |
|---|---|---|
| 执行方式 | 单次推理、一次性输出结果 | 迭代式循环、多轮思考执行 |
| 信息来源 | 仅依赖模型训练参数知识 | 模型知识+实时外部工具数据 |
| 复杂任务能力 | 无法拆解,复杂问题直接答错 | 自动拆解分步解决,适配复杂业务 |
| 幻觉概率 | 极高,知识滞后严重 | 大幅降低,以工具真实结果为准 |
| 工程依赖 | 无需Harness,纯Prompt即可 | 强依赖Harness流程与工具管控 |
| 落地场景 | 简单问答、文案生成 | 企业自动化、数据查询、任务调度 |

四、ReAct 核心 Prompt 模板深度解析
ReAct之所以能自动完成T-A-O循环,核心靠固定格式的系统Prompt约束,这也是Harness规则约束层的核心体现。
原生ReAct标准Prompt核心结构(行业通用):
plain
你是一个可以自主思考和调用工具的智能体。
你需要遵循【Thought → Action → Observation】循环逻辑解决问题。
可用工具列表:{tools}
严格遵循输出格式:
1. 思考(Thought): 分析当前问题,判断是否需要调用工具
2. 行动(Action): 需要调用工具时,输出工具名称和参数
3. 观察(Observation): 接收工具返回结果
如果已经获取足够信息,无需继续调用工具,直接输出最终答案。
问题:{input}
历史记录:{agent_scratchpad}4.1 关键参数说明
-
agent_scratchpad:ReAct的核心缓存,记录每一轮的Thought、Action、Observation,保存迭代全过程状态,属于Harness上下文记忆层能力;
-
tools:Harness注册的全部可调用工具列表;
-
input:用户原始任务指令。
五、实战代码:从零实现标准 ReAct Agent(可直接运行)
采用标准工程化代码风格,本次实现标准原生ReAct智能体,完整保留T-A-O循环、格式约束、容错机制、Harness管控能力,适配国内开源大模型,无翻墙依赖。
5.1 环境依赖
python
pip install langchain langchain-openai python-dotenv5.2 完整可运行代码
python
from dotenv import load_dotenv
import os
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain.tools import CalculatorTool, WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
from langchain.prompts import PromptTemplate
from langchain.globals import set_debug
# 加载环境变量
load_dotenv()
# 开启全链路日志(Harness可观测能力)
set_debug(True)
# ===================== 1. 初始化模型(适配国内任意OpenAI格式接口) =====================
llm = ChatOpenAI(
model="qwen-turbo",
temperature=0.0, # 零随机性,保证ReAct思考逻辑稳定
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_API_BASE")
)
# ===================== 2. 注册工具(Harness工具层) =====================
# 计算器工具
calc_tool = CalculatorTool()
# 维基百科查询工具(实时获取外部信息)
wiki_api = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=500)
wiki_tool = WikipediaQueryRun(api_wrapper=wiki_api)
tools = [calc_tool, wiki_tool]
# ===================== 3. 标准ReAct约束Prompt(核心) =====================
react_prompt = PromptTemplate.from_template("""
你是严格遵循ReAct范式的智能体,必须按照 Thought → Action → Observation 循环执行任务。
可用工具:{tools}
执行规则:
1. 遇到需要计算、外部知识查询的问题,必须调用工具,禁止自行编造答案
2. 每一轮只能做一次思考+一次工具调用
3. 信息足够后,停止循环,输出简洁完整的最终答案
用户问题:{input}
执行过程记录:{agent_scratchpad}
""")
# ===================== 4. 创建ReAct Agent + Harness管控 =====================
agent = create_react_agent(llm, tools, react_prompt)
# Harness容错、限流、防死循环配置
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=5, # 最大循环次数,防止ReAct死循环
handle_parsing_errors=True, # 解析异常兜底
timeout=15, # 超时熔断
return_intermediate_steps=True # 返回完整ReAct步骤
)
# ===================== 5. 测试运行 =====================
if __name__ == "__main__":
# 复杂混合任务:需要查询知识+数学计算
query = "请查询圆周率的近似定义,并计算 3.14159 * 128 的结果"
result = agent_executor.invoke({"input": query})
print("=" * 50)
print("最终答案:", result["output"])
print("=" * 50)
print("完整ReAct迭代步骤:")
for step in result["intermediate_steps"]:
print(f"步骤详情:{step}")5.3 运行结果核心逻辑解析
-
第一轮Thought:识别任务需要先查询圆周率定义,调用维基百科工具;
-
第一轮Action:执行百科查询,获取圆周率官方定义;
-
第一轮Observation:拿到文本信息,判断还需要数学计算;
4.第二轮Thought:决定调用计算器工具执行乘法运算;
-
第二轮Action:执行计算,获取结果;
-
信息充足:终止循环,输出最终答案。
这就是最标准的 ReAct 多轮迭代闭环。
六、ReAct 常见核心踩坑点(工程落地必看)
在Harness工程落地中,ReAct是故障高发点,核心问题全部来自循环机制本身:
6.1 无限循环问题
现象:Agent反复调用同一个工具,无限迭代,无法结束任务;
原因:模型无法判断任务是否完成、工具返回信息重复、Prompt约束不严格;
解决方案 :Harness层配置 max_iterations 最大迭代限制,强制熔断。
6.2 格式解析失败
现象:模型输出不遵循Thought/Action格式,导致Agent解析报错、任务中断;
解决方案 :开启 handle_parsing_errors 异常兜底,同时优化Prompt格式约束。
6.3 过度调用工具
现象:简单问题(如1+1)也强行调用工具,浪费token、耗时变长;
解决方案:在Prompt中增加规则:简单常识问题可直接回答,无需调用工具。
6.4 上下文溢出
现象:多轮ReAct迭代后,agent_scratchpad内容过长,触发上下文超限;
解决方案:依托Harness记忆层,定时精简迭代日志、截断无效历史。
七、企业级 ReAct 工程优化方案(结合Harness架构)
原生ReAct仅能实现基础能力,企业落地必须结合AI Agent工程化的Harness五层架构做优化:
7.1 约束层优化:分级规则管控
简单任务弱约束、复杂任务强约束,避免格式僵化,平衡稳定性与灵活性。
7.2 容错层优化:智能重试+失败降级
工具调用失败时,自动重试2次,重试失败后触发兜底答案,不中断业务流程。
7.3 记忆层优化:迭代过程轻量化存储
区分「有效迭代步骤」和「冗余日志」,长期只保存关键ReAct决策过程,减少存储和token消耗。
7.4 可观测层优化:步骤级监控
统计每轮ReAct迭代耗时、失败率、工具调用命中率,数据驱动优化Prompt和规则。
八、ReAct 与 Harness 的层级关系(终极总结)
结合AI Agent完整工程化体系,彻底理清三者的层级关系:
-
LLM模型:提供基础推理智能,是Agent的大脑基础;
-
ReAct范式 :定义大脑的思考方式(T-A-O循环),是Agent的执行内核逻辑;
-
Harness工程 :为ReAct循环提供约束、容错、记忆、监控、工具调度的整套运行环境;
终极公式:企业级Agent = LLM + ReAct执行逻辑 + Harness工程管控
九、总结
ReAct 不是一个框架、不是一个工具,而是AI Agent的标准思考与执行范式,是所有智能体实现"自主解决复杂任务"的核心底层。
新手只学框架调用,高手深耕 Harness工程架构 + ReAct底层逻辑。只有吃透ReAct的迭代闭环、踩坑痛点、工程优化,才能开发出稳定、可落地、可迭代的企业级AI Agent,而不是只能跑Demo的玩具智能体。
后续会继续更新:ReAct进阶、Plan&Execute、多智能体协同、Agent评估体系等系列干货,形成完整AI Agent工程化闭环教程。
原创连载,点赞收藏持续更新!