前言
最近帮几个刚入行的朋友做技术指导,发现一个普遍现象:很多人从大学学完MySQL之后,就再也没碰过别的数据库了。
到了工作中,遇到一些复杂业务场景,用MySQL去硬撑,搞得焦头烂额。
说实话,PostgreSQL这几年在企业级应用中的普及速度非常快。
2026年DB-Engines排名显示,PostgreSQL稳坐全球第四大数据库的宝座,仅次于Oracle、MySQL和SQL Server。
今天,我就用一篇文章跟大家一起聊聊PostgreSQL,希望对你会有所帮助。
更多项目实战在我的技术网站:susan.net.cn/project
一、先说一个扎心的事实
有些小伙伴在工作中可能会说:"我用MySQL用了好几年了,感觉也挺好的啊,为什么要学PostgreSQL?"
我举个简单的例子:假如你的电商系统需要查询"2024年每个季度销售额排名前3的商品",用MySQL写这个SQL起码20行起步,各种嵌套子查询、窗口函数疯狂套娃。
而PostgreSQL原生就支持RANK()窗口函数,10行代码轻松搞定。
这不叫花里胡哨,这叫生产力。
数据库的选型,决定着你未来无数个加班的夜晚是不是真的在"用代码解决问题",还是在"跟数据库做斗争"。
而且,国内外很多大厂都已经在从MySQL向PostgreSQL迁移了。
Apple、Instagram、Uber、Reddit,甚至阿里巴巴的部分业务线,都在逐步拥抱PostgreSQL。
这背后是有原因的------简单来说,MySQL适合80%的普通场景,而PostgreSQL适合剩下那20%复杂至极、对数据一致性要求极高的"硬骨头"。
二、PostgreSQL到底是什么?
PostgreSQL是一个功能强大的开源关系型数据库管理系统,它起源于1986年加州大学伯克利分校的POSTGRES项目。
经过近40年的发展,它已经成长为全球最先进的开源数据库之一。
它的核心特性有这么几个:
- 完全开源:遵循PostgreSQL许可证,可以自由使用、修改和分发。
- 高度可扩展:支持自定义数据类型、函数、操作符和索引方法。
- 标准兼容性强:对SQL:2023标准的兼容度超过90%,完整支持窗口函数、公共表表达式(CTE)、全文搜索等高级SQL特性。
- 多版本并发控制(MVCC) :读写互不阻塞,完美解决了高并发场景下的锁争用问题。
- 丰富的扩展生态:提供PostGIS(地理信息系统)、pgvector(向量检索)、TimescaleDB(时序数据)等行业级扩展。
PostgreSQL和MySQL两者最根本的差异,我用一张图帮你理清楚:
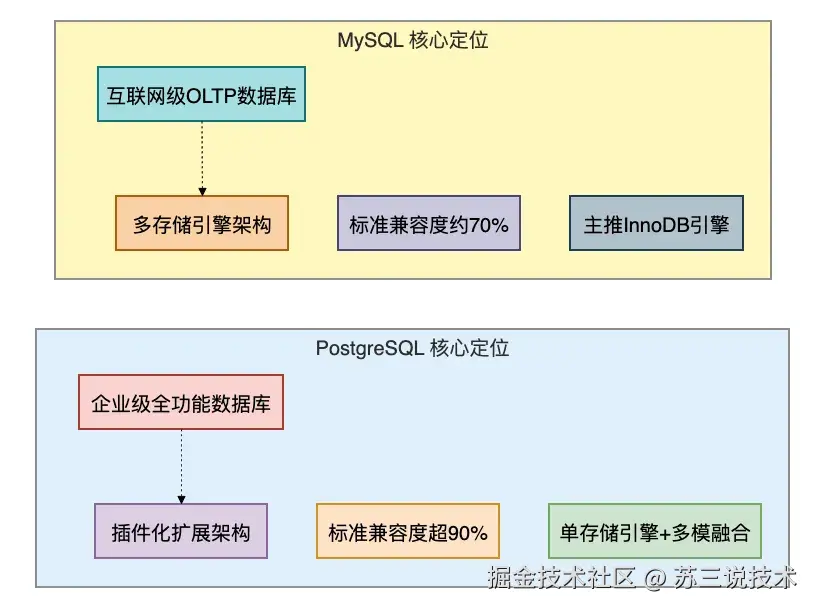
简单来说,一个擅长"全都要",什么都能干;另一个擅长"一招鲜",在特定场景下做到极致。
三、环境搭建
咱们先把环境弄起来。
PostgreSQL可以在Linux、Windows、macOS等各种操作系统上运行。
生产环境建议内存至少8GB以上。
3.1 Windows用户
对于Windows新手,推荐使用官方图形化安装包。
步骤如下:
- 访问postgresql.org/download,下载Windows安装包
- 双击运行,一路Next
- 设置安装路径(默认C:\Program Files\PostgreSQL\16)
- 设置超级用户(postgres)密码------切记记住这个密码!
- 设置端口(默认5432,一般不改)
- 选择区域,建议选Chinese (Simplified)或English_United States
- 安装完成后勾选Launch Stack Builder可以跳过
- 打开CMD或PowerShell,输入
psql -U postgres,输入密码,看到postgres=#提示符即为成功
3.2 macOS用户
macOS推荐使用Homebrew安装:
bash
# 安装PostgreSQL
brew install postgresql
# 启动服务
brew services start postgresql
# 连接数据库
psql postgres如果不习惯用命令行,也可以去官网下载.dmg安装包,拖拽到Applications即可。
3.3 Linux用户(Ubuntu/Debian)
Ubuntu用户推荐从官方仓库安装,确保版本最新:
bash
# 添加官方仓库
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
# 更新并安装
sudo apt update
sudo apt install postgresql postgresql-contrib
# 启动服务
sudo systemctl start postgresql
# 切换到postgres用户
sudo -i -u postgres
psql3.4 安装验证
无论哪个系统,安装完成后可以用下面这个命令快速验证:
sql
SELECT version();看到类似"PostgreSQL 16.x"的输出,恭喜你,安装成功了!
四、基础SQL全掌握
4.1 数据库基本操作
sql
-- 创建数据库
CREATE DATABASE mydb;
-- 查看所有数据库
\l
-- 切换到指定数据库
\c mydb
-- 创建用户并授权
CREATE USER myuser WITH PASSWORD 'mypass';
GRANT ALL PRIVILEGES ON DATABASE mydb TO myuser;
-- 删除数据库(生产环境慎用)
DROP DATABASE mydb;4.2 数据类型详解
PostgreSQL支持的数据类型非常丰富,远超MySQL:
| 类型分类 | 具体类型 | 说明 |
|---|---|---|
| 数值类型 | INTEGER、BIGINT、NUMERIC(precision, scale)、DOUBLE PRECISION | NUMERIC用于精确小数,适合金额 |
| 字符串类型 | VARCHAR(n)、TEXT、CHAR(n) | TEXT无长度限制 |
| 日期时间 | DATE、TIME、TIMESTAMP、TIMESTAMPTZ、INTERVAL | TIMESTAMPTZ带时区 |
| 布尔类型 | BOOLEAN | true/false |
| JSON类型 | JSON、JSONB | JSONB是二进制格式,支持索引 |
| 数组类型 | INTEGER\[\]、TEXT\[\] | 原生数组支持 |
| 网络地址 | INET、CIDR、MACADDR | IP地址处理 |
4.3 创建表和约束
sql
-- 创建商品表
CREATE TABLE products (
id SERIAL PRIMARY KEY, -- 自增主键
name VARCHAR(200) NOT NULL, -- 商品名,非空
price NUMERIC(10,2) CHECK (price > 0), -- 价格必须大于0
stock INTEGER DEFAULT 0, -- 库存,默认0
category VARCHAR(50),
tags TEXT[], -- 数组类型存标签
created_at TIMESTAMPTZ DEFAULT NOW() -- 带时区的时间戳
);4.4 基本的增删改查
sql
-- 插入数据
INSERT INTO products (name, price, stock, category, tags)
VALUES ('机械键盘', 399.00, 50, '外设', ARRAY['键盘', '电竞']),
('无线鼠标', 129.00, 100, '外设', ARRAY['鼠标', '无线']);
-- 查询数据
SELECT * FROM products WHERE price BETWEEN 100 AND 500;
-- 更新数据
UPDATE products SET stock = stock - 1 WHERE id = 1;
-- 删除数据
DELETE FROM products WHERE stock = 0;五、MVCC多版本并发控制
有些小伙伴在工作中可能会问:PostgreSQL和MySQL在并发性能上到底有什么本质区别?为什么说PostgreSQL更适合高并发写场景?
这就是MVCC(Multi-Version Concurrency Control)的功劳。
PostgreSQL的并发承诺非常简单:读永远不阻塞写,写永远不阻塞读。
5.1 MVCC核心原理
PostgreSQL中,每个事务都会获得一个唯一的事务ID,称为XID。
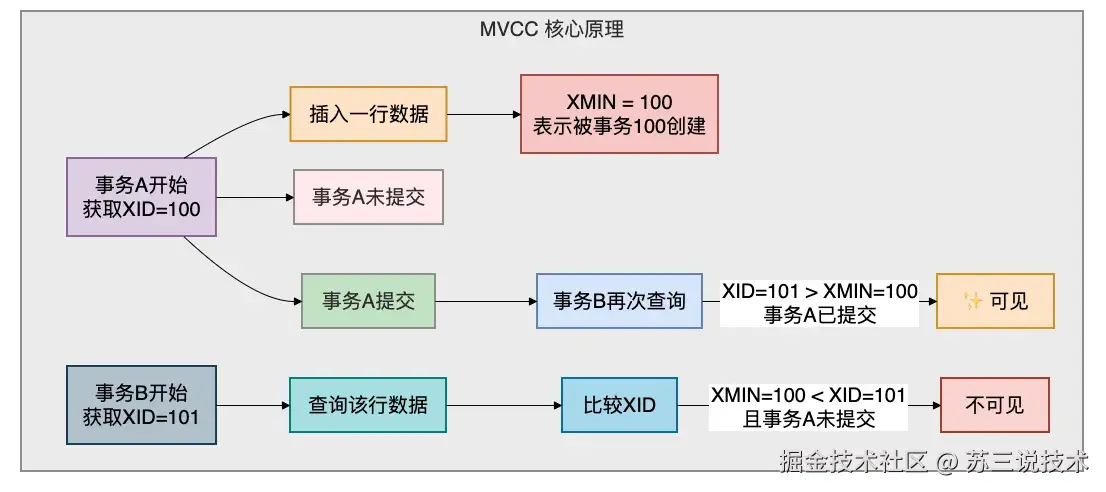
MVCC的核心区别在于:MySQL通过锁机制实现,读数据时可能会被写操作阻塞;而PostgreSQL通过快照隔离实现,永远不会有读写互锁。
XMIN和XMAX是两个隐藏字段,每个数据行都有。插入时写入XMIN(创建这个版本的事务ID),更新/删除时写入XMAX(删除这个版本的事务ID),通过比较XID就可以判断事务的可见性。
5.2 事务隔离级别
PostgreSQL支持四种隔离级别,默认是READ COMMITTED,同时也提供了严格的SERIALIZABLE级别:
- READ UNCOMMITTED:实际上等同于READ COMMITTED
- READ COMMITTED(默认):查询只能看到已提交的数据
- REPEATABLE READ:保证在同一事务内多次查询结果一致
- SERIALIZABLE:最高隔离级别,使用可序列化快照隔离(SSI),能真正防止幻读和写偏序异常
如果两个事务同时修改同一行,PostgreSQL会如何处理?
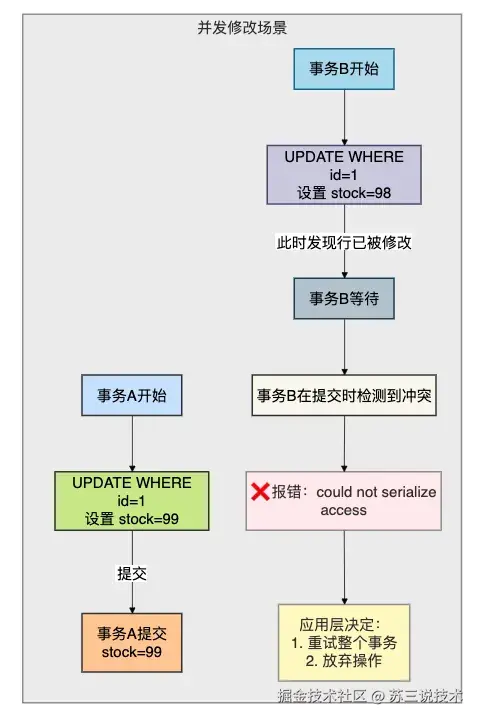
这在SERIALIZABLE隔离级别下会抛错误,应用层可以选择重试或者放弃。
六、PostgreSQL的索引武器库
有些小伙伴在工作中可能会遇到这样的情况:明明给字段建了索引,慢查询还是一堆。这是因为PostgreSQL的索引体系比MySQL复杂得多,也强大得多------索引类型不同,适用场景完全不同。
6.1 索引类型全家桶
MySQL主要依赖B-tree索引,而PostgreSQL提供了丰富的索引武器库:
| 索引类型 | 典型场景 | 关键要点 |
|---|---|---|
| B-tree | 等值与范围查询、排序 | 默认类型,支持= < <= > >= ORDER BY |
| Hash | 仅等值查询 | 不支持范围和排序 |
| GIN | 数组、JSONB、全文搜索 | 倒排结构,适合"多值"查询 |
| GiST | 地理空间、全文搜索 | 支持多种距离查询 |
| BRIN | 大表、按时间顺序插入的数据 | 体积小,适合"粗粒度"范围过滤 |
| Bloom | 多列高选择性查询 | 位图过滤,减少组合索引数量 |
B-tree是默认索引类型,但也是水最深的。比如查询LIKE '%keyword%'就不会走B-tree索引,这时候需要考虑GIN或全文搜索。
GIN索引实战:加速JSONB查询
PostgreSQL的JSONB类型配上GIN索引,查询性能可以提升几百倍:
sql
-- 创建含JSONB字段的表
CREATE TABLE products (
id SERIAL PRIMARY KEY,
details JSONB
);
-- 插入测试数据
INSERT INTO products (details) VALUES
('{"name": "Laptop", "specs": {"cpu": "i7", "ram": "16GB"}, "tags": ["electronics", "sale"]}'),
('{"name": "Keyboard", "specs": {"switch": "mechanical", "connection": "wired"}, "tags": ["peripherals"]}');
-- 不加索引的查询(慢)
SELECT * FROM products WHERE details -> 'specs' ->> 'cpu' = 'i7';
-- 创建GIN索引
CREATE INDEX idx_products_details ON products USING GIN (details);
-- 索引后的快速查询(快300倍)
SELECT details -> 'name' AS name, details -> 'specs' AS specs
FROM products
WHERE details @> '{"specs": {"cpu": "i7"}}';这里的@>是JSONB包含操作符,利用GIN索引快速定位。
6.2 表达式索引和部分索引
PostgreSQL支持两种高级索引,MySQL需要复杂配置才能实现:
sql
-- 表达式索引:按小写邮箱查询,避免写函数导致索引失效
CREATE INDEX idx_users_lower_email ON users (lower(email));
-- 现在可以直接走索引
SELECT * FROM users WHERE lower(email) = 'someone@example.com';
-- 部分索引:只为活跃用户建索引,大大减少索引体积
CREATE INDEX idx_users_active ON users (email) WHERE active = true;这两个特性的价值在于精准索引------不是所有数据都需要加速,只索引你最常查的那部分,存储和写入成本都降下来了。
6.3 执行计划分析
用EXPLAIN ANALYZE查看SQL的实际执行计划:
sql
EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM products WHERE price < 100;输出中重点关注Seq Scan (全表扫描,慢)还是Index Scan(索引扫描,快)。
如果想在图形界面操作,可以用pgAdmin执行可视化诊断。
七、JSONB与全文搜索
7.1 让关系型数据库也能"非结构化"
JSONB把JSON数据解析成二进制结构存储,支持索引,查询性能远超MySQL的JSON类型。
JSONB的核心操作符:
sql
-- 创建表
CREATE TABLE user_profiles (
id SERIAL PRIMARY KEY,
profile JSONB
);
INSERT INTO user_profiles (profile) VALUES
('{"name": "张三", "age": 30, "address": {"city": "北京", "zip": "100000"}, "skills": ["Java", "Python"]}'),
('{"name": "李四", "age": 25, "address": {"city": "上海", "zip": "200000"}, "skills": ["Go", "Rust"]}');
-- 查询:-> 返回JSON对象,->> 返回文本
SELECT
profile -> 'name' AS name_json,
profile ->> 'name' AS name_text,
profile -> 'address' ->> 'city' AS city
FROM user_profiles;
-- 条件查询:包含操作符 @>
SELECT * FROM user_profiles
WHERE profile @> '{"skills": ["Java"]}';
-- JSON路径查询:用 #>> 直接定位
SELECT profile #>> '{address,city}' FROM user_profiles;7.2 全文搜索:让数据库变成搜索引擎
PostgreSQL内置了全文搜索引擎,使用tsvector(词位向量)和tsquery(查询表达式)两个核心类型:
sql
-- 创建测试表
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT
);
INSERT INTO articles (title, content) VALUES
('PostgreSQL 全文搜索入门', '全文搜索让PostgreSQL能像搜索引擎一样检索文本'),
('JSONB 实战指南', 'JSONB类型支持高效的半结构化数据存储和查询');
-- 基础全文搜索
SELECT title FROM articles
WHERE to_tsvector('english', title || ' ' || content) @@ to_tsquery('english', 'search');
-- 最佳实践:创建GIN索引加速全文搜索
ALTER TABLE articles ADD COLUMN search_vector tsvector
GENERATED ALWAYS AS (to_tsvector('english', title || ' ' || content)) STORED;
CREATE INDEX idx_articles_search ON articles USING GIN(search_vector);
-- 按相关度排序
SELECT title, ts_rank(search_vector, query) AS rank
FROM articles, to_tsquery('english', 'search') query
WHERE search_vector @@ query
ORDER BY rank DESC;GENERATED ALWAYS AS ... STORED是PostgreSQL的一个巧妙设计------生成列自动维护,查询时直接用,不用每次都临时计算,性能和便捷性都兼顾了。
八、Java集成实战
作为Java后端,我们需要把数据库操作融入实际项目中。
这里以Spring Boot + MyBatis Plus为例。
8.1 添加依赖
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- PostgreSQL 驱动 -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.7.0</version>
</dependency>
<!-- MyBatis Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.7</version>
</dependency>8.2 配置数据源
yaml
spring:
datasource:
url: jdbc:postgresql://localhost:5432/mydb
username: postgres
password: your_password
driver-class-name: org.postgresql.Driver
# 连接池配置(推荐HikariCP)
datasource:
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: auto8.3 实体类和Mapper
java
@Data
@TableName("products")
public class Product {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private BigDecimal price;
private Integer stock;
private String category;
private List<String> tags; // PostgreSQL原生支持数组
}
@Mapper
public interface ProductMapper extends BaseMapper<Product> {
// 自定义查询:价格范围内的产品
@Select("SELECT * FROM products WHERE price BETWEEN #{min} AND #{max}")
List<Product> selectByPriceRange(@Param("min") BigDecimal min,
@Param("max") BigDecimal max);
}8.4 Service层使用
java
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
// 分页查询
public IPage<Product> pageList(int pageNum, int pageSize) {
Page<Product> page = new Page<>(pageNum, pageSize);
return productMapper.selectPage(page, null);
}
// Lambda条件查询
public List<Product> getInStockProducts() {
LambdaQueryWrapper<Product> wrapper = new LambdaQueryWrapper<>();
wrapper.gt(Product::getStock, 0)
.orderByDesc(Product::getPrice);
return productMapper.selectList(wrapper);
}
// JSONB字段查询(使用原生SQL)
@Select("SELECT * FROM products WHERE details @> #{jsonCondition}::jsonb")
List<Product> selectByJsonCondition(@Param("jsonCondition") String jsonCondition);
}九、PostgreSQL vs MySQL对比
9.1 核心差异一览表
| 对比维度 | PostgreSQL | MySQL |
|---|---|---|
| 核心定位 | 企业级全功能数据库,主打标准兼容、复杂计算 | 互联网级OLTP数据库,主打高性能、简单易用 |
| SQL标准兼容 | 对SQL:2023标准兼容度超90% | 兼容度约70%,高级功能大量阉割 |
| 架构模型 | 单存储引擎+插件化扩展 | 多存储引擎,主推InnoDB |
| MVCC实现 | 快照隔离,读写永不阻塞 | 依赖undo log,存在锁竞争 |
| 可序列化隔离 | 严格SSI实现,高性能 | 本质是全表加锁,性能极差 |
| 扩展能力 | 插件生态极强,支持时序/向量/地理空间等 | 扩展能力有限,生态集中在分库分表 |
| JSON支持 | JSONB二进制存储,GIN索引,速度快300倍 | JSON类型,查询性能较弱 |
| 高级SQL | 窗口函数、CTE、全文搜索原生支持 | MySQL 8.0后部分支持 |
| 开源协议 | PostgreSQL License(宽松类BSD) | GPLv2,修改源码需开源 |
| 适用场景 | 复杂查询、数据分析、金融、地理信息 | 高并发Web应用、内容管理、快速原型 |
PostgreSQL最大的优势在于功能完整性和标准合规性。
PostgreSQL 对 SQL 标准的支持最为完整,这对复杂应用和数据分析至关重要。
国内越来越多的大厂开始从MySQL向PostgreSQL迁移,看中的正是它的SQL标准兼容性和插件扩展能力。
十、优缺点与适用场景
10.1 优点
- 功能丰富,一库通吃:支持JSON、数组、地理空间、时序数据等多种数据类型
- SQL标准兼容度高:迁移成本低,生态工具丰富
- 数据完整性保障强:原生支持完整外键约束、CHECK约束、排除约束
- 强大的并发性能:MVCC机制让读写互不阻塞,高并发写入领先于MySQL
- 扩展性极强:通过插件扩展可实现几乎所有企业级需求
- 插件生态成熟:PostGIS(地理信息)、pgvector(向量检索)、TimescaleDB(时序数据)等
10.2 缺点
- 学习曲线陡峭:功能多,每个特性的学习成本也相应增加
- 默认配置保守:通常需要调优才能发挥最佳性能
- 社区热点分散:插件多,"最佳实践"不集中
- 简单查询吞吐量:比MySQL略低(MySQL约20,000 tpmC,PostgreSQL约18,000 tpmC)
- VACUUM维护成本:MVCC产生的死元组需要定期清理
10.3 适用场景
强烈推荐PostgreSQL的场景:
- 金融交易、订单系统(需要完整ACID和严格约束)
- 复杂报表、数据分析系统(需要高级SQL和窗口函数)
- JSON/半结构化数据存储(利用JSONB+GIN索引)
- 地理信息系统(PostGIS是行业标准)
- 全文搜索引擎(内置全文检索,无须Elasticsearch)
- AI+向量检索应用(借助pgvector扩展)
- 时序数据监控(借助TimescaleDB)
MySQL更适合的场景:
- 高并发纯OLTP、简单CRUD的应用
- 前期快速原型开发(配置简单、生态成熟)
- 已有成熟的MySQL运维体系和工具链
- 团队成员对PostgreSQL不熟悉的学习成本问题
总结
MySQL是"菜刀"式的数据库,锋利简单,一招吃遍天。
PostgreSQL是"瑞士军刀"式的数据库。它功能全面但学习门槛高。
没有哪个一定更好,但你需要了解这两把利器的各自神威。
我建议每个Java后端工程师,花两个月时间:
- 读一遍PostgreSQL官方文档的"SQL Language"和"Server Administration"部分
- 练一遍CRUD、索引、事务、JSONB、全文搜索所有本章例子的实际操作
- 想一遍如果在你的业务里用PostgreSQL,架构哪里可以做得更好
当你熟悉了PostgreSQL的这些高级特性,你会发现------原来复杂需求真的可以用数据库一行SQL解决,而不是在业务代码里凑一千行的Java if-else。
这是数据库思维上的根本改变。
我希望这篇文章不仅帮你入了PostgreSQL的门,更帮你打开了多模态数据管理和复杂业务建模的一扇窗。
更多项目实战在我的技术网站:susan.net.cn/project