1.研究背景:为什么需要 Wan?
自从 Sora 发布之后,视频生成模型受到了非常大的关注。闭源模型如 Sora、Kling、Runway Gen-3、Veo 2 等展示了很强的视频生成能力,但开源社区仍然存在几个明显问题:
1. 开源模型与闭源模型仍有差距
虽然 HunyuanVideo、Mochi、CogVideoX 等开源模型已经推动了视频生成的发展,但论文认为开源模型和商业闭源模型之间仍然有差距,主要体现在:
-
生成质量仍有差距
闭源商业模型通常有更大的数据、更强的算力和更完善的工程优化。
-
能力不够全面
很多模型主要支持 Text-to-Video,但真实视频创作需求远不止文本生成视频,还包括:
- Image-to-Video
- 视频编辑
- 视频续写
- 个性化视频生成
- ...
-
推理成本较高
大模型虽然效果好,但对普通用户和创作者来说,显存和算力门槛太高。
Wan 的目标就是在这些方面进行系统改进。
2. Wan 的核心贡献
论文把 Wan 的特点总结为四个方面:
2.1 Leading Performance:性能领先
Wan 训练了两个主要规模的模型:
- Wan 1.3B
- Wan 14B
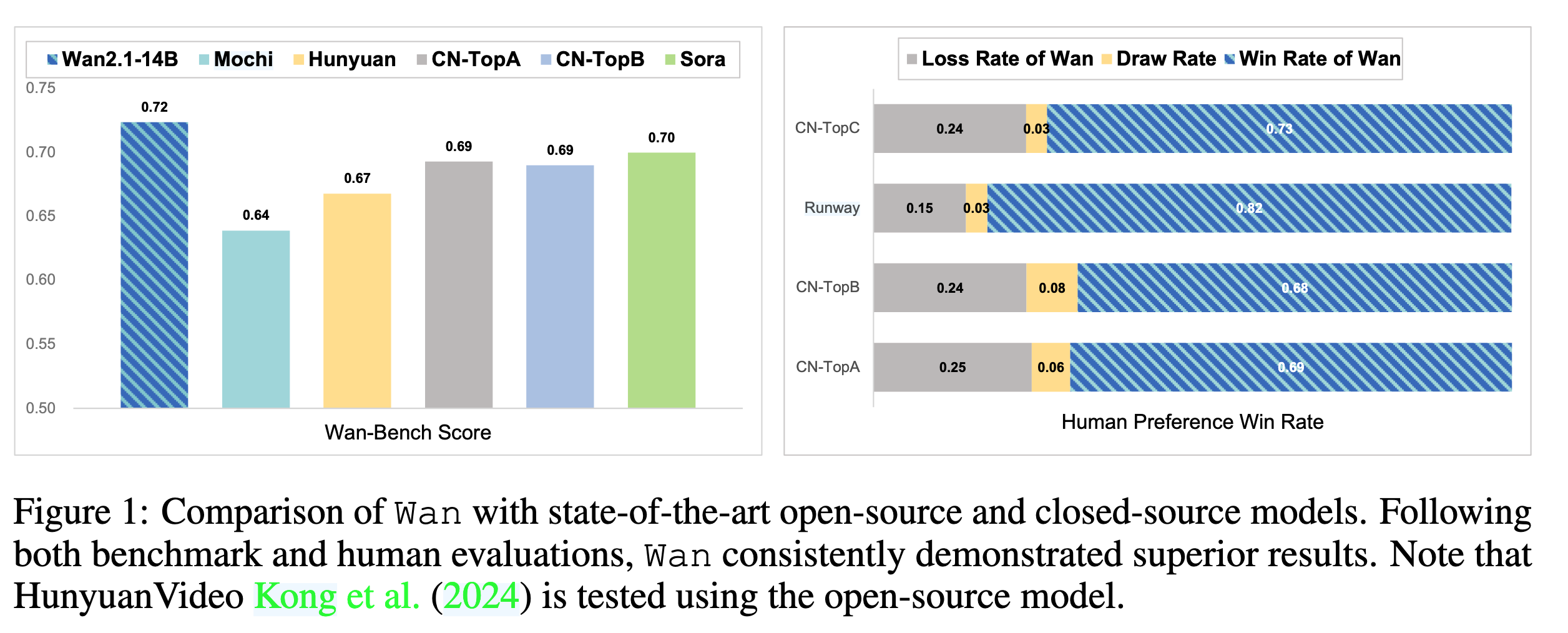
其中 14B 模型使用了大规模图像和视频数据进行训练。在内部 Wan-Bench、人类偏好评测和公开 VBench 上,Wan 14B 都取得了很强的效果。
特别值得注意的是,Wan 不只是追求静态画质,还强调:
- 大幅度运动生成
- 物理合理性
- 指令遵循能力
- 中英文视觉文字生成
- 相机控制
- 风格多样性
2.2 Comprehensiveness:能力全面
Wan 不只是一个单纯的 Text-to-Video 模型,而是扩展到了多个任务:
- Text-to-Video
- Image-to-Video
- Video Editing
- Text-to-Image
- Video Personalization
- Camera Motion Control
- Real-time Video Generation
- Video-to-Audio Generation
这说明 Wan 更像是一个"视频基础模型平台",而不是单一任务模型。
2.3 Consumer-Grade Efficiency:消费级显卡可用
Wan 1.3B 的一个重要特点是显存需求较低。论文中提到,Wan 1.3B 只需要约 8.19GB VRAM,可以运行在很多消费级 GPU 上。
这对于开源视频生成非常重要,因为如果模型只能在高端服务器上跑,那么实际社区使用门槛会很高。
2.4 Openness:开源
论文强调 Wan 开源了模型和代码,希望推动视频生成社区的发展。
这点和很多闭源商业模型形成了对比。对于学术研究者来说,开源模型可以作为很好的 baseline,也可以帮助大家研究视频生成模型的内部结构、训练策略和评测方法。
3. 整体框架概览
Wan 的主体框架采用当前主流的视频生成范式:
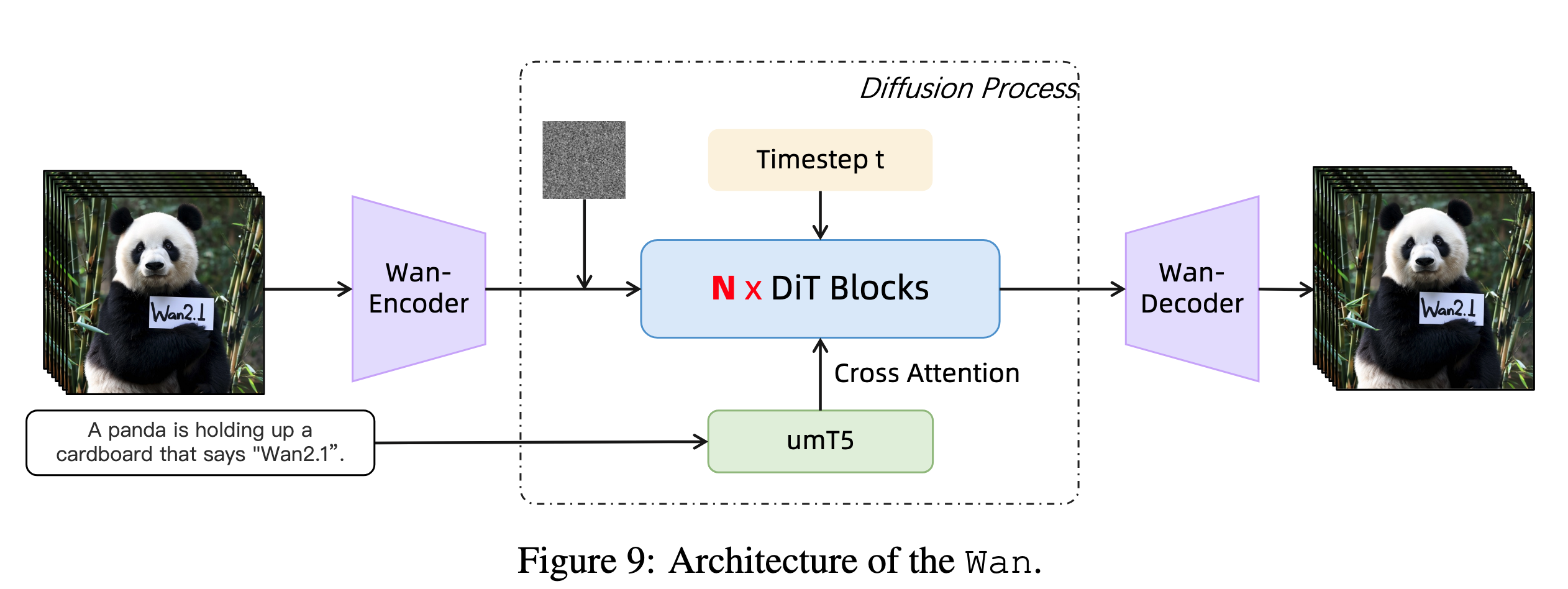
核心模块包括:
-
Wan-VAE
把视频从像素空间压缩到 latent space,降低训练和生成成本。
-
Diffusion Transformer, DiT
在 latent space 中进行视频生成建模。
-
umT5 Text Encoder
负责理解用户输入的文本 prompt,尤其支持中英文。
-
Flow Matching 训练目标
用连续时间的 velocity prediction 来训练生成过程。
4. 数据处理 Pipeline
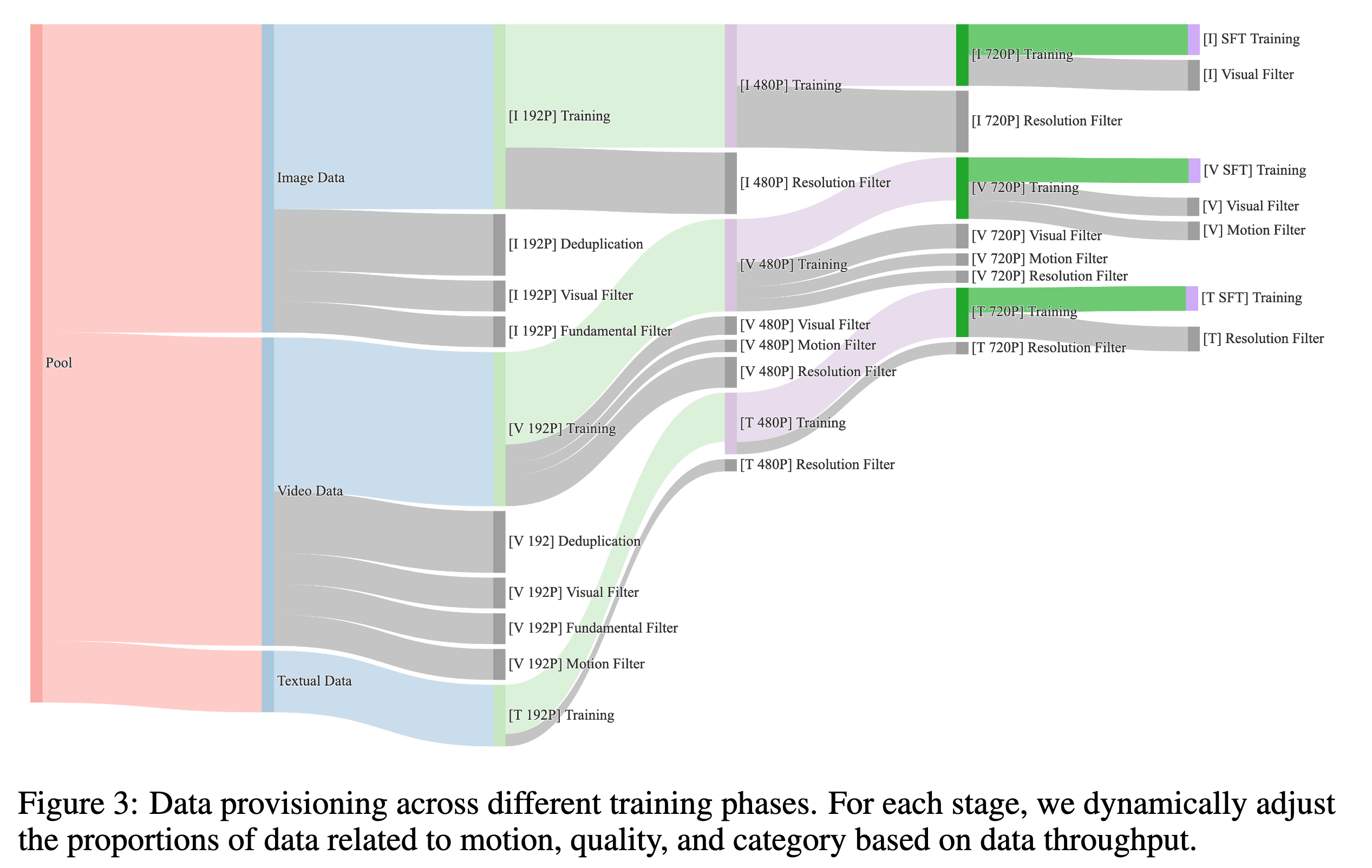
大规模生成模型非常依赖数据质量。Wan 的数据构建目标是:
高质量、高多样性、大规模。
论文中提到 Wan 使用了数十亿级别的视频和图像数据,并设计了比较复杂的数据过滤流程。
4.1 预训练数据过滤
Wan 对原始候选数据进行了多维度清洗,包括:
1. 基础过滤
包括:
- OCR 文本检测
- 美学评分
- NSFW 过滤
- 水印和 logo 检测
- 黑边检测
- 过曝检测
- 合成图像检测
- 模糊检测
- 视频时长和分辨率过滤
其中一个有意思的点是,论文特别提到 合成图像污染 会影响模型训练,即使生成图像污染比例小于 10%,也可能降低模型性能。因此他们训练了专门的分类器来过滤生成图像。
2. 视觉质量筛选
Wan 会先对数据聚类,再在每个 cluster 内进行质量打分和筛选。
这样做的好处是:
如果直接按质量排序筛选,可能会丢掉一些长尾类别;而先聚类再筛选,可以尽量保持数据多样性。
3. 运动质量筛选
视频生成和图像生成最大的区别就是"运动"。Wan 将视频运动质量分成多个等级,例如:
- 最优运动视频
- 中等运动视频
- 静态视频
- 相机主导运动
- 低质量运动
- 抖动镜头
这样可以让模型学习到更自然、更稳定的视频运动。
5. Dense Video Caption:高质量视频描述
这篇论文里很重要的一部分是 Dense Video Caption。
普通网页上的视频 caption 往往很短,比如:
text
A dog running.但视频生成模型需要学习更加细致的文本-视频对应关系,比如:
text
A golden retriever runs across a green field under bright sunlight,
with its ears flapping and the camera following from the side.这种详细 caption 能提升模型的 prompt following 能力。
Wan 训练了自己的 caption model,用于给图片和视频生成详细描述。
5.1 Caption 的评测维度
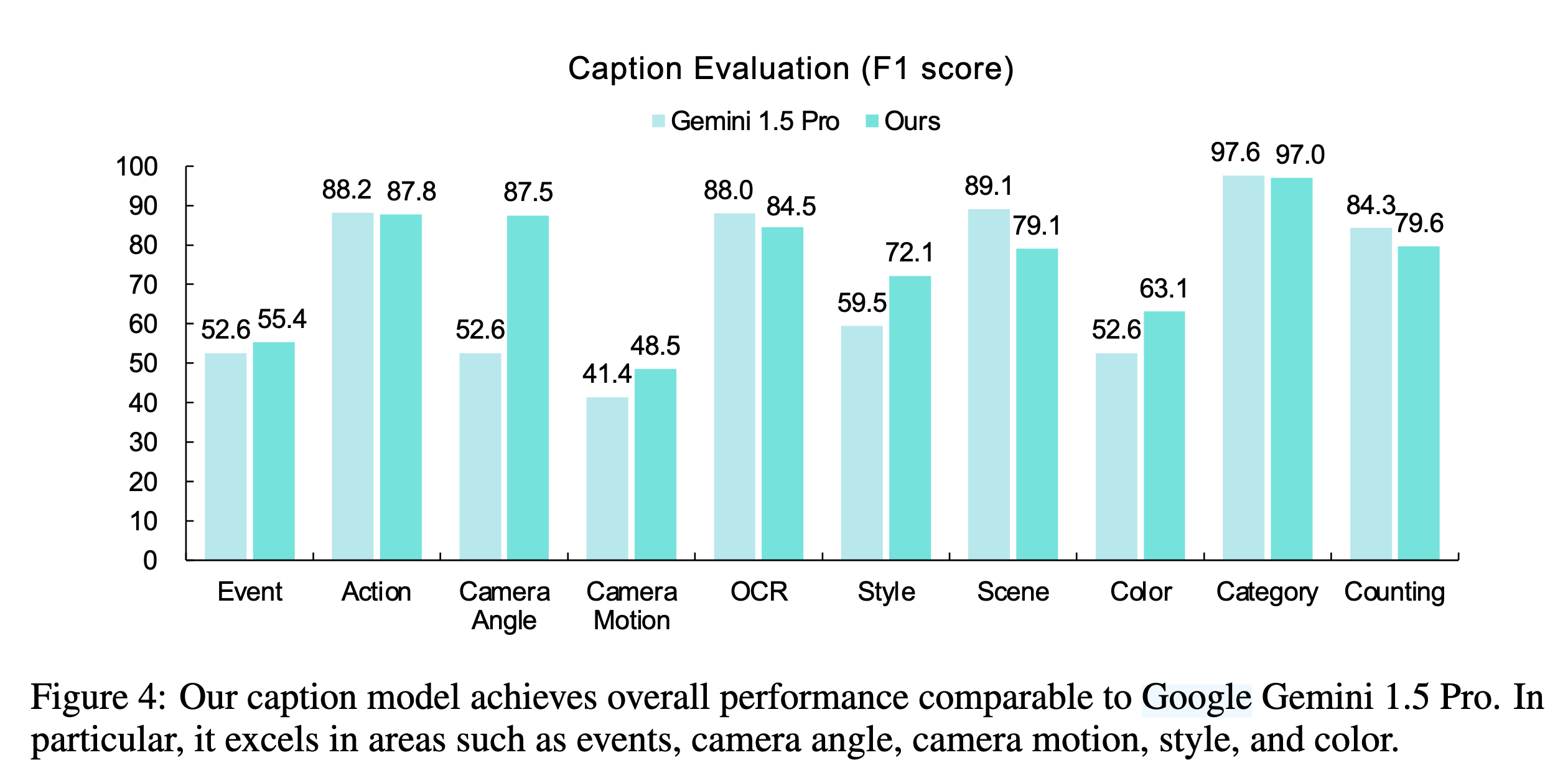
论文中评估 caption model 的维度包括:
- action
- camera angle
- camera motion
- object category
- object color
- object counting
- OCR
- scene
- style
- event
6. Wan-VAE
视频生成直接在像素空间训练成本非常高,所以主流方法都会先把视频压缩到 latent space,再在 latent space 中训练扩散模型。
Wan 提出了自己的 Wan-VAE。
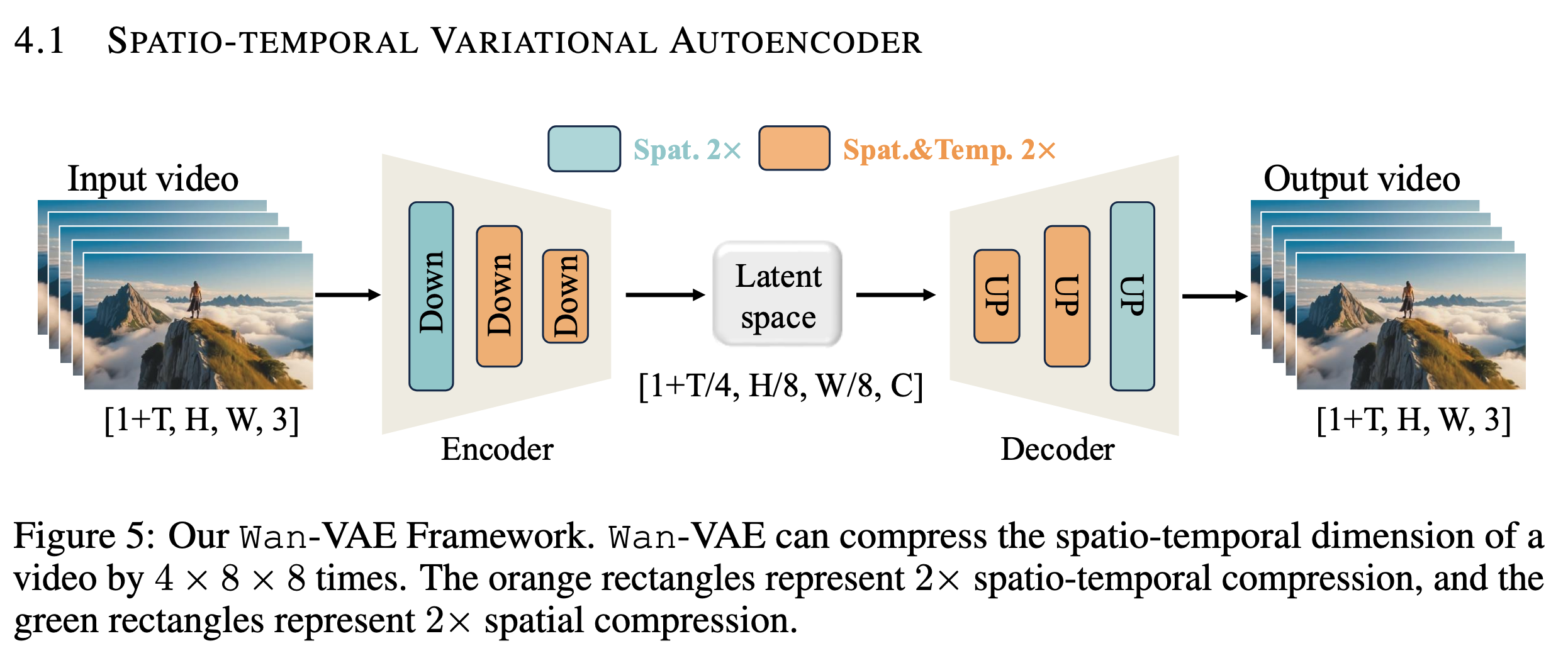
6.1 3D Causal VAE
Wan-VAE 是一个 3D causal VAE。
这里的 causal 指的是时间因果性:
模型在处理当前帧时不能依赖未来帧的信息。
论文中还把 GroupNorm 替换成 RMSNorm,目的是更好地保持 temporal causality,并支持 feature cache 机制。
6.4 Feature Cache 机制
为了支持任意长度视频的编码和解码,Wan-VAE 使用了 feature cache。
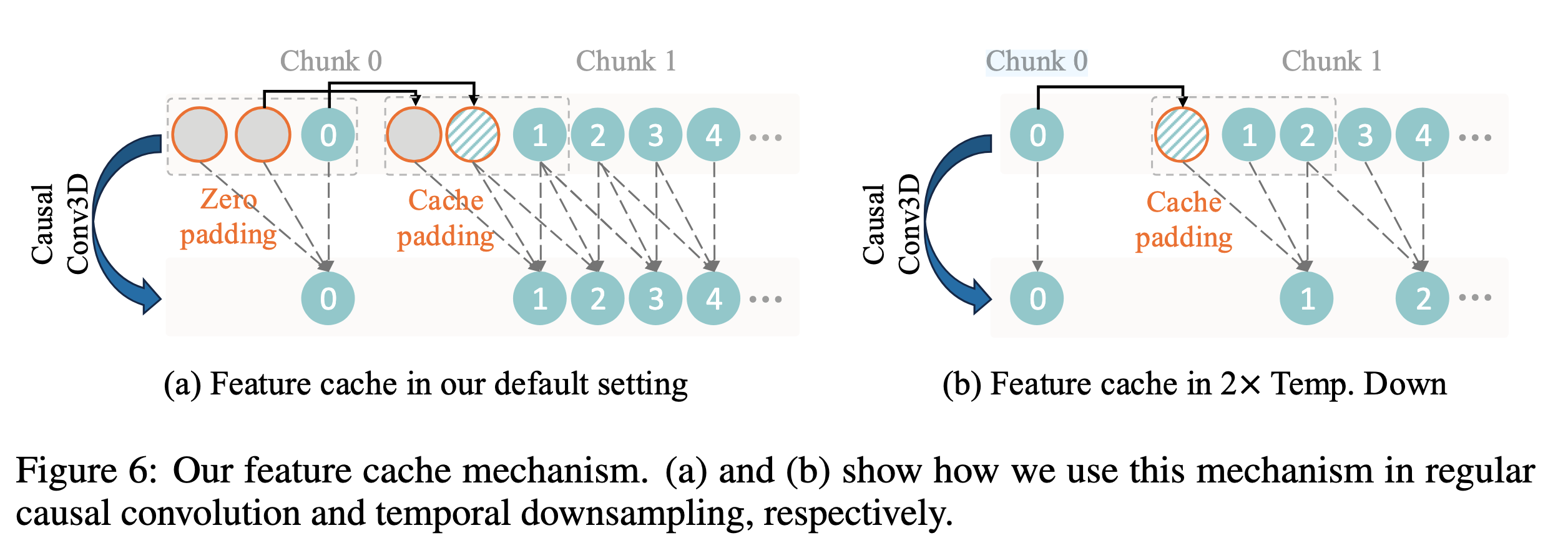
简单理解:
视频被分成多个 chunk 处理,每个 chunk 只处理少量帧,同时缓存前面 chunk 的部分特征,用来保证 chunk 之间的时间连续性。
这有点像流式处理视频。它既能减少显存压力,又能保持视频连续性。
7. Video Diffusion Transformer
Wan 的生成主体是 Diffusion Transformer,也就是 DiT。
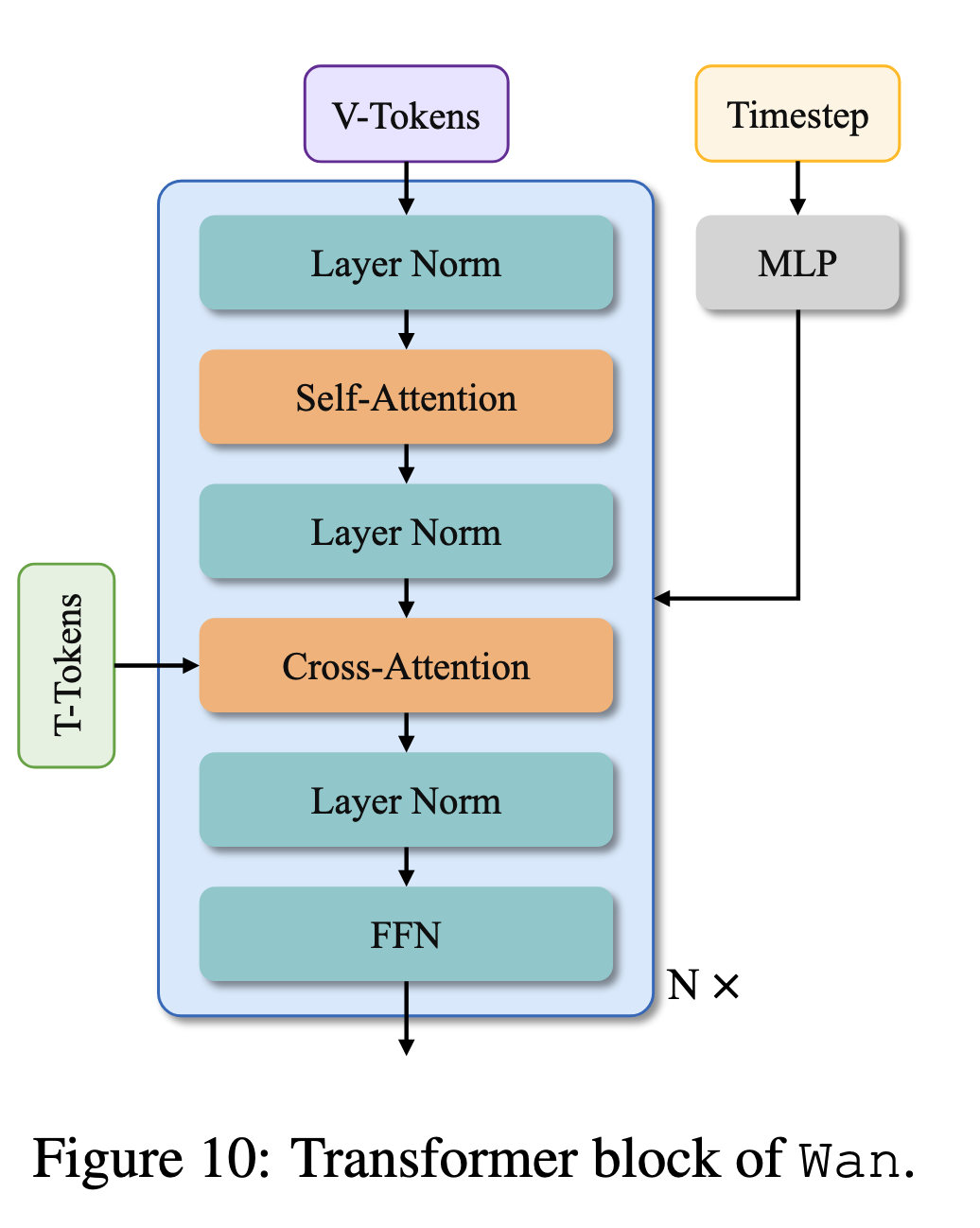
7.1 Patchifying
Wan 先使用 3D convolution 对 latent 进行 patchify,把视频 latent 转换成 token sequence。
这个过程类似 Vision Transformer 对图像切 patch,但这里处理的是视频 latent,所以包含时间和空间维度。
7.2 Cross-Attention 注入文本条件
Wan 使用 cross-attention 来注入文本条件。
也就是说:
- video tokens 作为 query;
- text embeddings 作为 key/value;
- 模型通过 cross-attention 学习文本和视频内容的对应关系。
相比把文本 token 和视觉 token 直接拼接后做 full attention,cross-attention 可以更清晰地建模文本条件,也有利于长上下文控制。
7.3 时间步调制
DiT 中还需要 timestep embedding。Wan 使用一个 MLP 处理时间步信息,并预测 modulation parameters,用于调制 transformer block。
论文中提到,这个设计可以减少约 25% 参数量,同时保持甚至提升性能。
8. Flow Matching 训练目标
Wan 使用的是 Flow Matching / Rectified Flow 风格的训练目标,而不是传统 DDPM 那种直接预测噪声的形式。
设:
x0是随机噪声;x1是真实图像或视频 latent;t ∈ [0, 1]是时间步。

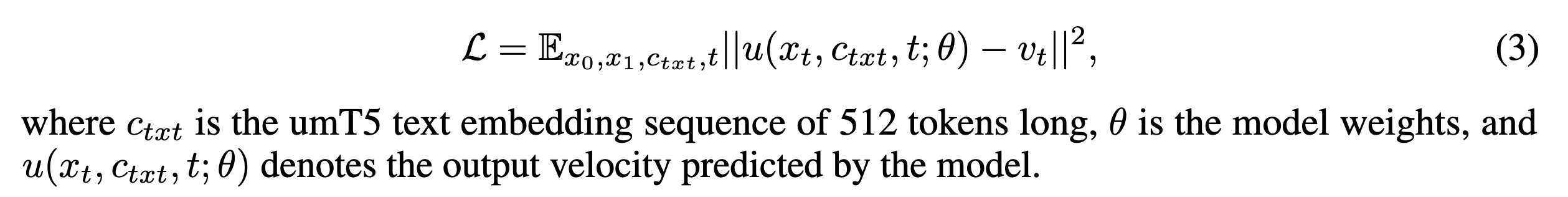
直观理解:
Flow Matching 让模型学习从噪声
x0流向真实数据x1的方向,也就是学习一条从噪声到数据的生成路径。
9. 训练策略
Wan 的训练大致分为:
- 图像预训练
- 图像-视频联合训练
- 后训练
9.1 为什么先做图像预训练?
直接用高分辨率、长视频训练 14B 模型非常困难,因为:
- 视频 token 序列太长;
- attention 计算量巨大;
- 显存占用过高;
- batch size 变小后训练不稳定。
所以 Wan 先在低分辨率图像上预训练,让模型先学习基本的视觉语义对齐和结构生成能力。
9.2 图像-视频联合训练
之后进入多阶段 image-video joint training:
- 第一阶段:256px 图像 + 低分辨率 5 秒视频;
- 第二阶段:提升到 480px;
- 第三阶段:提升到 720px。
这种 progressive curriculum 的思想很常见:
先让模型在简单任务上稳定,再逐步提高分辨率和视频复杂度。
9.3 后训练
Post-training 阶段主要使用更高质量的数据,进一步提升:
- 视觉保真度;
- 运动质量;
- prompt following;
- 高质量视频生成能力。
10. 推理加速
视频生成模型推理很慢,尤其是 14B 这种大模型。Wan 在推理阶段做了多种优化。
10.1 多 GPU 并行
Wan 使用 FSDP 和 2D Context Parallelism 来加速长序列生成。
视频 token 序列可能非常长,普通 attention 会成为瓶颈。Wan 使用 Ring Attention 和 Ulysses 组合的方式进行 context parallel,从而提升多 GPU 推理效率。
10.2 Diffusion Cache
Wan 观察到两个现象:
- 相邻采样步之间,attention 输出非常相似;
- 在采样后期,CFG 的 conditional 和 unconditional 输出也有相似性。
因此它引入了 diffusion cache:
- attention cache:隔几步计算一次 attention,其余步骤复用缓存;
- CFG cache:复用部分 conditional/unconditional 结果,并做 residual compensation。
论文中提到,diffusion cache 可以让 Wan 14B T2V 推理提速约 1.62 倍。
10.3 量化
Wan 还使用了:
- FP8 GEMM
- 8-bit FlashAttention
其中 FP8 GEMM 可以提升 DiT 模块速度,8-bit FlashAttention 进一步提升 attention 效率。
11. Prompt Alignment:提示词重写

用户输入的 prompt 往往很短,例如:
但训练数据里的 caption 往往更详细。因此,用户 prompt 和训练 caption 之间存在分布差异。
Wan 使用 LLM 对用户 prompt 进行重写,让它更接近训练 caption 的风格。
重写原则包括:
- 添加细节,但不改变原意;
- 添加自然运动描述;
- 按照"风格 + 内容概括 + 细节描述"的结构组织 prompt。
例如,短 prompt 会被扩展成包含:
- 拍摄风格;
- 主体;
- 动作;
- 场景;
- 镜头;
- 光照;
- 氛围。
这可以显著提升视频生成质量。
模型本身很重要,但 prompt rewriting 对最终用户体验也非常重要。
12. Wan-Bench:视频生成评测体系
视频生成很难评测。传统指标如 FVD、FID 和人类感知并不总是一致。
因此论文提出了 Wan-Bench,从三个核心维度评估视频:
- Dynamic Quality
- Image Quality
- Instruction Following
并进一步拆成 14 个细粒度指标。
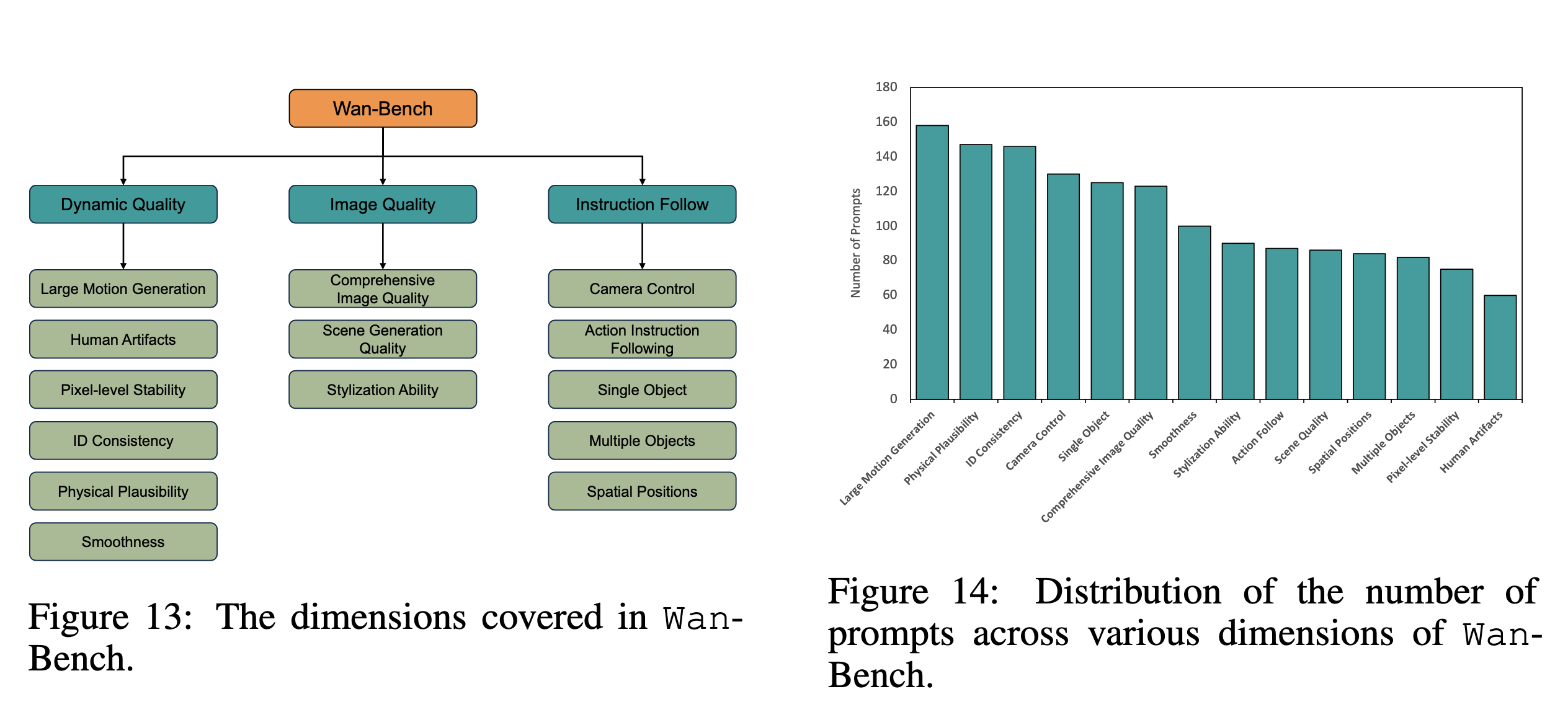
12.1 Dynamic Quality
包括:
- 大幅度运动生成
- 人体伪影
- 像素级稳定性
- ID 一致性
- 物理合理性
- 运动平滑性
例如,大幅度运动生成用 optical flow 评估;物理合理性使用 Qwen2-VL 做视频问答判断。
12.2 Image Quality
包括:
- 综合图像质量
- 场景生成质量
- 风格化能力
综合图像质量由多个质量和美学模型共同评分。
12.3 Instruction Following
包括:
- 单物体准确性
- 多物体准确性
- 空间位置准确性
- 相机控制
- 动作指令遵循
这部分比较关注生成视频是否真的满足 prompt。
12.4 人类反馈加权
Wan-Bench 不是简单平均所有指标,而是根据人类偏好进行加权。论文收集了超过 5000 个视频 pairwise comparison,用来估计不同指标对用户偏好的影响。
13. 实验结果
论文从多个角度评估了 Wan:
13.1 Wan-Bench
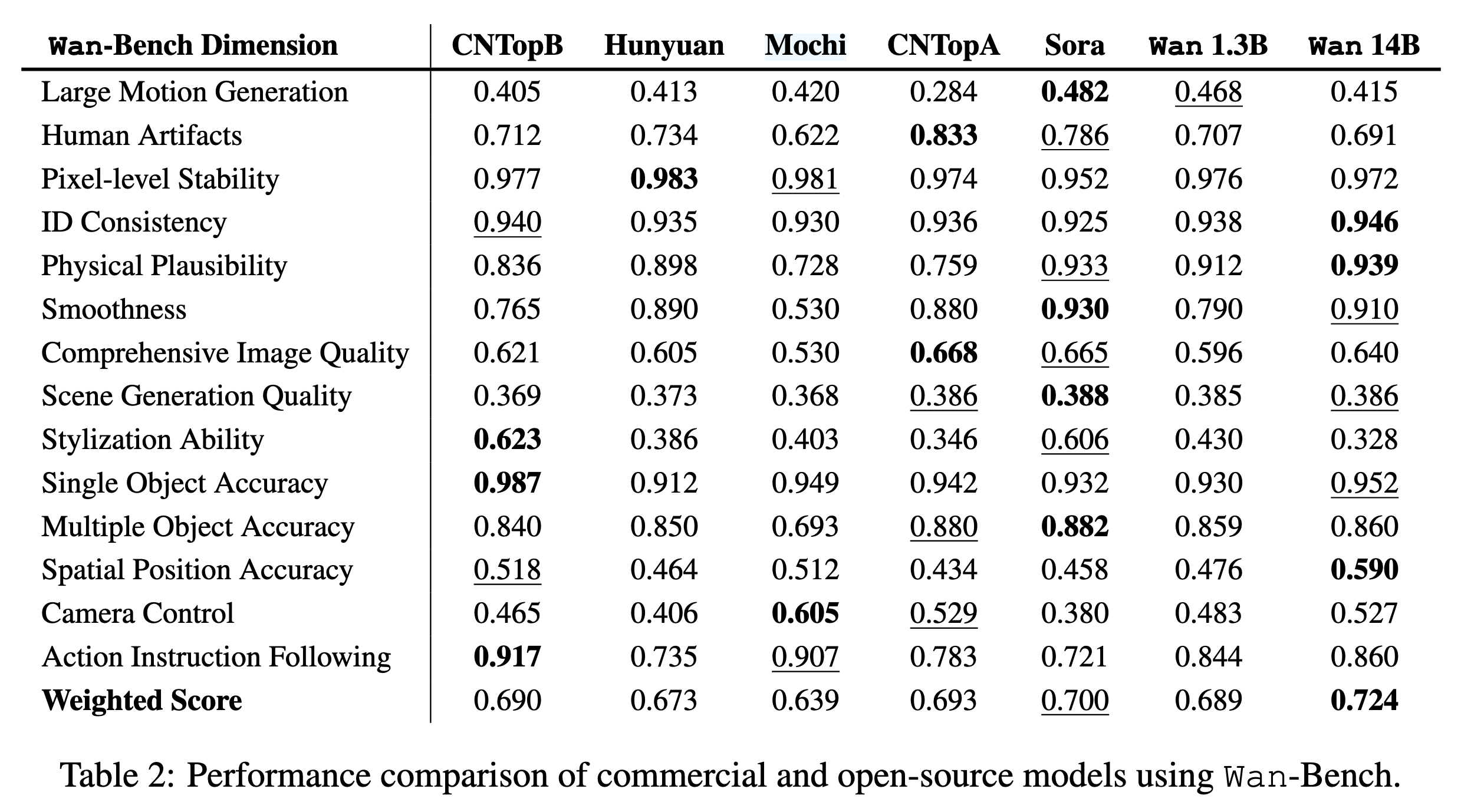
Wan 14B 在 Wan-Bench 上取得最高 weighted score。
表格中 Wan 14B 的 weighted score 为 0.724,高于 Sora、Hunyuan、Mochi、CN-TopA/CN-TopB 等模型。
13.2 人类评测
论文设计了超过 700 个评估任务,由 20 多名标注者从以下维度评估:
- alignment
- image quality
- dynamic quality
- overall quality
结果显示 Wan 14B 在 T2V 任务上整体表现较强。
13.3 VBench
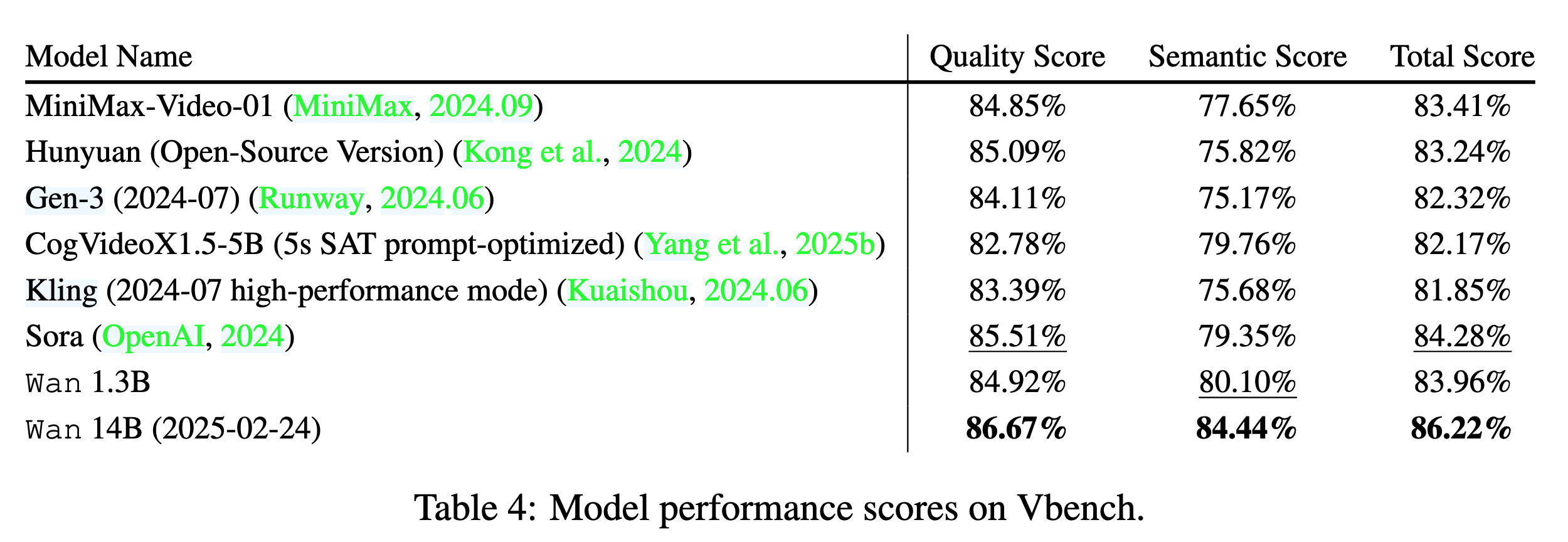
在公开 VBench 上,Wan 14B 取得了:
- Quality Score:86.67%
- Semantic Score:84.44%
- Total Score:86.22%
Wan 1.3B 也取得了比较强的结果,总分为 83.96%。
这说明小模型虽然规模小,但仍然有不错的综合性能。
14. 消融实验
论文做了几个关键消融实验。
14.1 AdaLN 是否共享
DiT 中 adaptive normalization layers 参数量很大。Wan 比较了:
- full-shared AdaLN
- half-shared AdaLN
- non-shared AdaLN
- 增加模型深度
结果发现:
与其把参数加到 AdaLN 上,不如增加网络深度更有效。
因此 Wan 采用 fully shared AdaLN,从而减少参数量并保持性能。
14.2 文本编码器选择
论文比较了:
- umT5
- Qwen2.5-7B-Instruct
- GLM-4-9B
- Qwen-VL-7B
结果显示 umT5 在 Wan 框架下表现更好。
原因可能是:
- umT5 支持中英文;
- T5 是 encoder-decoder 结构,encoder 使用双向 attention;
- 双向文本表示更适合 diffusion model 的条件注入。
这和 HunyuanVideo 等模型的经验也比较一致。
14.3 VAE 设计
论文比较了普通 VAE 和 VAE-D,结果显示 Wan-VAE 在 FID 上更好。
这说明对视频生成来说,一个高质量、稳定、高效的 latent tokenizer 非常关键。