文章目录
- 前言
- 一、页
- 二、区
-
- [2.1 概述](#2.1 概述)
- [2.2 碎片区](#2.2 碎片区)
- 三、区组
-
- [3.1 概述](#3.1 概述)
- [3.2 组织方式](#3.2 组织方式)
- 三、段
-
- [3.1 概述](#3.1 概述)
前言
表空间文件是什么
用MySQL的Innodb创建一个自定义用户表,会生成一个idb文件,这个文件存储了索引和用户数据,.idb文件就是表空间文件。
表空间文件有很多类型:
- 系统表空间:ibdata1,存储数据字典、undo日志、双写缓冲区、变更缓冲区等全局数据
- 独立表空间(单表表空间) :
.ibd,每张InnoDB表独立生成,存放表数据、索引 - 临时表空间:ibtmp1,存储临时表、排序操作产生的临时数据
- Undo 表空间 :
undoN(如undo001、undo002),专门存放undo日志,MySQL 8.0默认独立拆分 - Redo 日志文件 :
ib_logfile0、ib_logfile1,属于重做日志,崩溃恢复核心文件 - 通用表空间 :自定义命名(如
test.ibd),可容纳多张表,由CREATE TABLESPACE创建
一、页
1、概述
页是Innodb进行磁盘IO操作的最小单位,默认16kb。可以通过命令修改。建议设置为4的整倍数。
原因是大部分操作系统进行IO操作的最小单位是4kb,如果是非4的整倍数,需要进行额外的cpu计算,降低性能。
2、结构

3、 页头&页尾
页头结构:

页尾结构:

LSN:Log Sequence Number 日志序列号
用于记录数据的写入顺序,方便灾难恢复、数据刷盘、事务回滚;
循环递增
4、数据行
4.1概述
数据行主要用于存储索引或用户实际数据。在多种数据行组织类型中,目前最主流、最常见的是动态格式(Dynamic)。
4.2动态格式结构

4.2.1可变长度列表如何解决粘包问题?
Innodb读取数据行,一般从下一行地址开始,从右往左读;
先读一个字节,如果最高位为0,则直接截断,计算长度;如果最高位是1,则继续读取一个字节;
4.2.2头信息结构

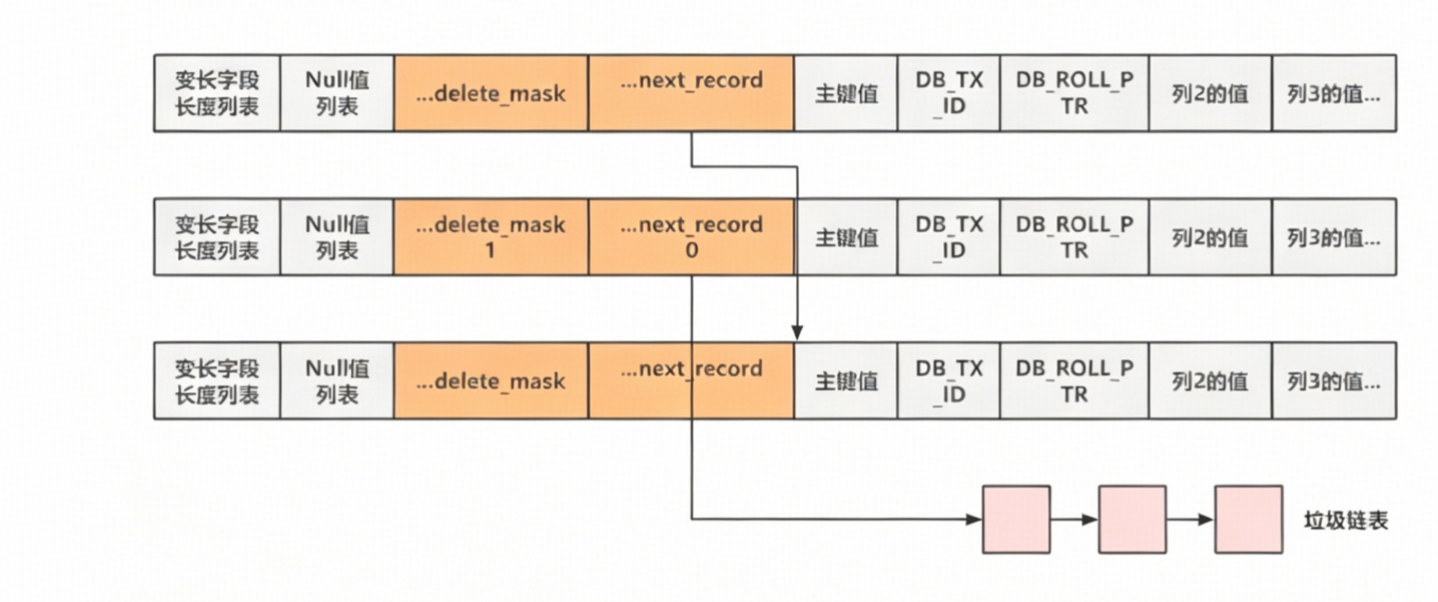
当需要删除某行数据是,innodb不会直接删除,而是把
delete_mark设置为1,并且从数据行链表中断开。存放到垃圾链表中;这个垃圾链表可以用于事物会滚:
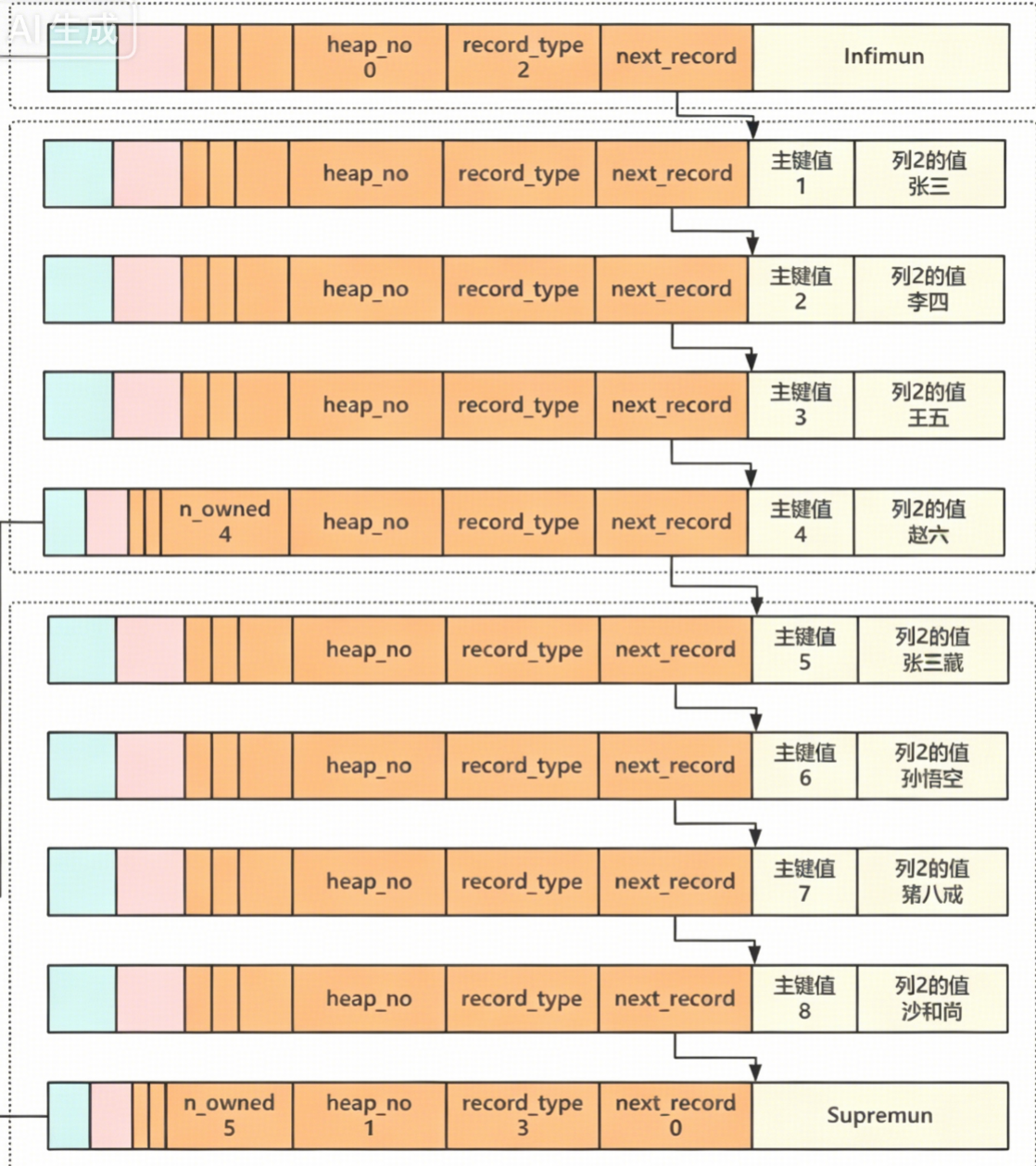
4.3 行与行的组织方式
next_record作为指针,最小行和最大行组成一个链表的头、尾巴,中间存放实际的索引或者用户数据,向左可以读取元信息,向右可以读取值:
4.4 数据行的查询优化(页目录)
一个数据页内,包含许多的数据行,innodb不会直接暴力枚举。他会把连续的数据行进行顺序排列分组(最多8行一组)形成一个槽。槽内包含了组内最大heap_no。当需要查询某行数据时,给予槽的最大heap_no进行二分,最终在组内进行数据行的枚举就可以快速查询到值:
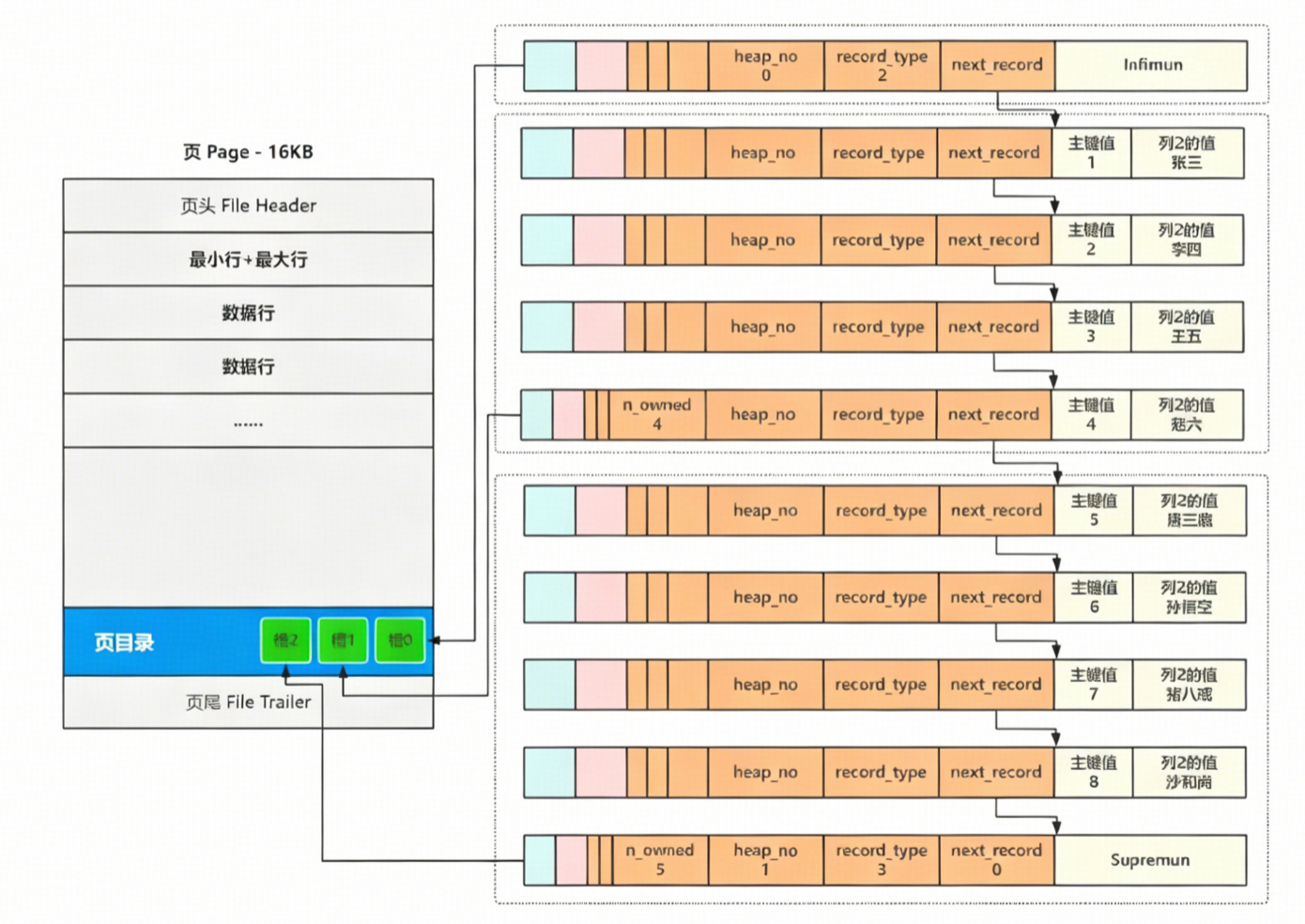
这里做个槽组成的可二分的列表就是页目录;
数据页头
存储了数据行集合的一些统计信息、位置信息、索引和事务信息;
二、区
2.1 概述
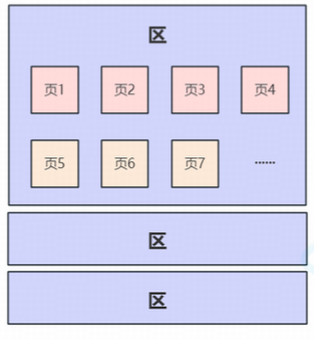
64个页组成一个区,即一个区默认1MB大小。区中的页是物理上连续的,这里运用到了局部性原理;
2.2 碎片区
如果建立的空表,innodb不会创建一个完整的区,若数据量不大只有几个数据页的话。它会把表的一些元数据存储到数据页中(默认7个),组成一个碎片区,碎片区中的页被称为零散页。目的是节省空间。
只有当插入新数据,使得总的页数大于32才会申请一个区进行存储;
三、区组
3.1 概述
实际使用数据库的时候,数据查询可能大于1MB,为了进一步提升查询速度和局部性原理的使用,innodb维护了区组的物理结构。默认256个区形成一个区组。
3.2 组织方式
区组中第一个区的前四个页比较特殊,存储了一些元数据:
- 表空间和区组条目信息
- change buffer信息
- 段信息
- 索引数节点信息
三、段
3.1 概述
段是Innodb组织数据的逻辑概念,也就是一种数据结构。一个段中包含多个区组(根据实际存储情况而定);
段的类型分为叶子节点段 和非叶子节点段 ,和B+数索引的叶子节点和非叶子节点相互对应。
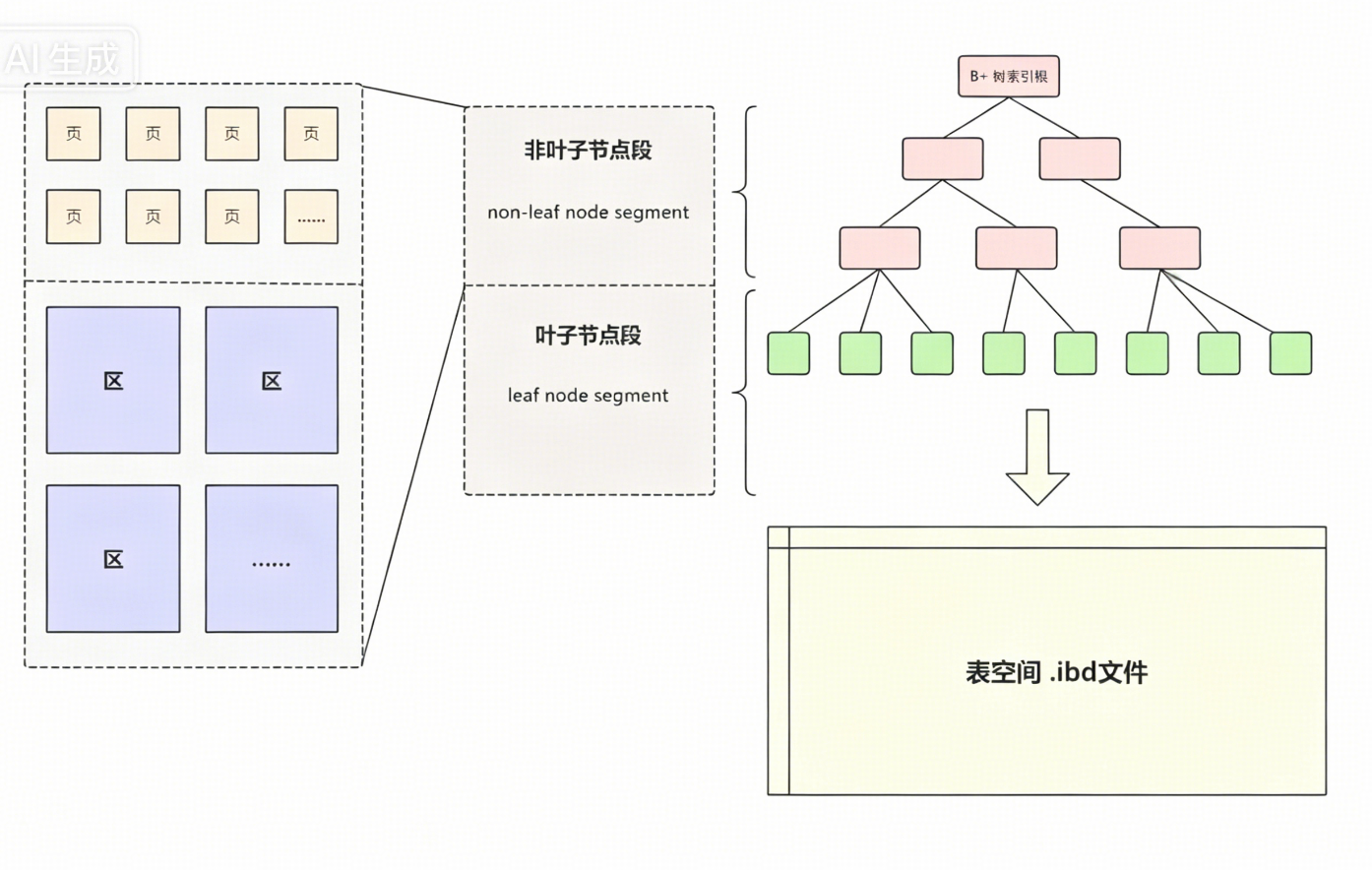
一个.idb文件包含多个B+树。