目标
搭建前后端基础框架,完成Model I/O核心封装,跑通基础对话接口,实现最基础的AI对话。
Model I/O = 标准化AI的输入输出流程 = 提示词模板 + 输出解析 + 大模型调用封装
后端任务
- 创建Python虚拟环境,安装依赖 ✅️
- 配置大模型API Key,封装LLM调用工具类✅️
- 实现
- 提示词模板(ChatPromptTemplate)✅️
- 输出解析器(StrOutputParser)✅️
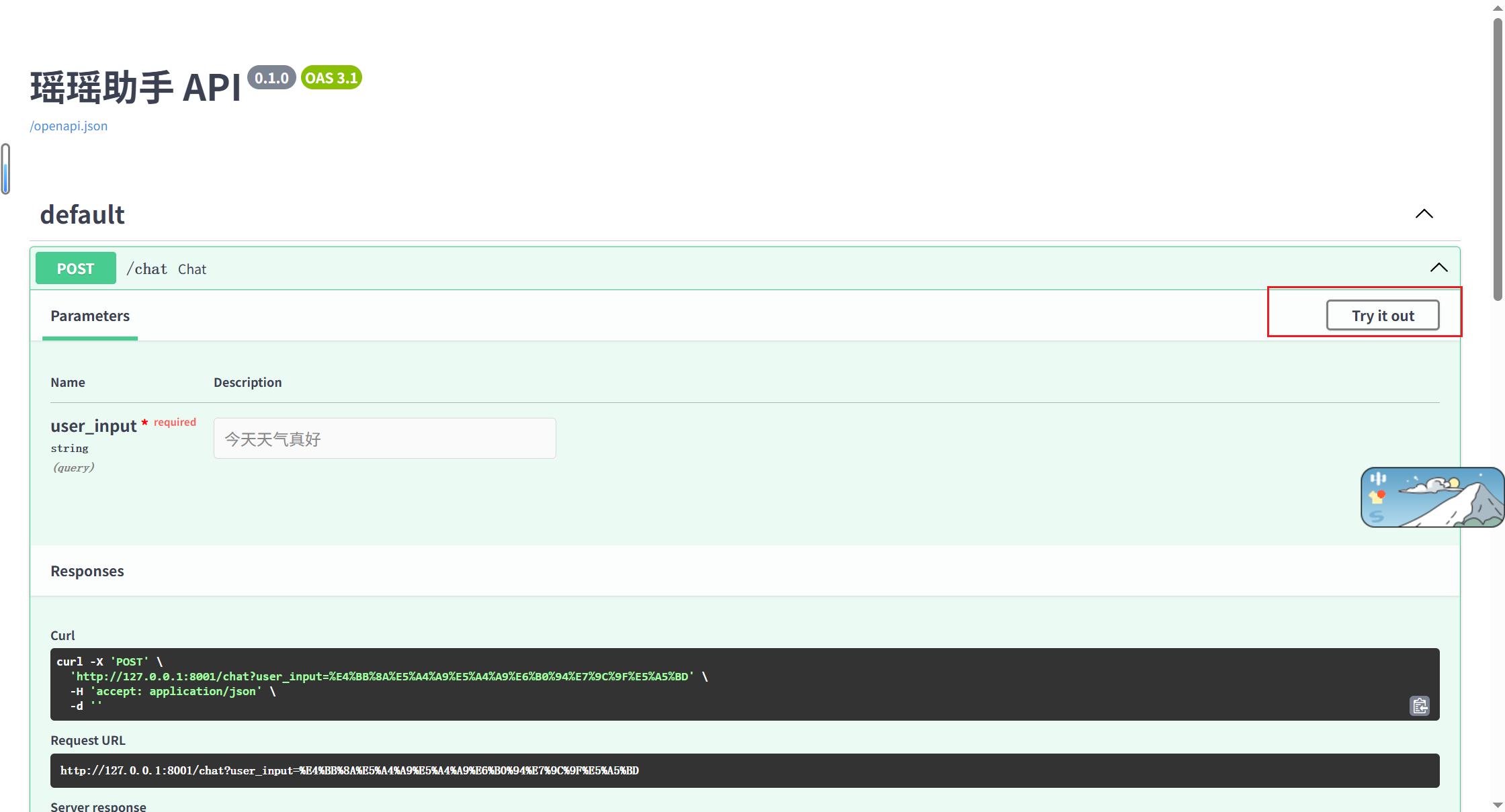
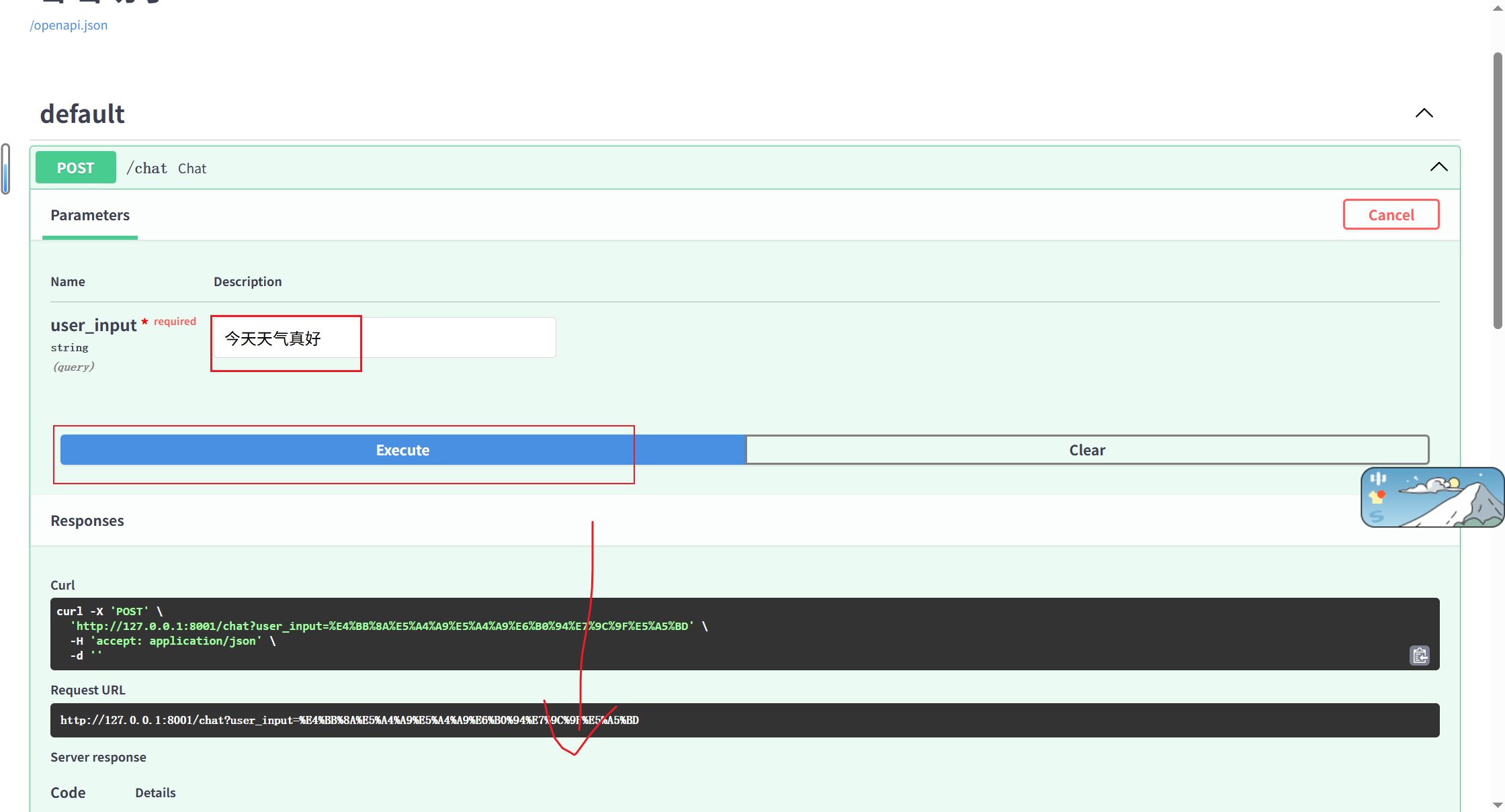
- 基础对话接口(/chat)✅️
- 搭建FastAPI服务,测试接口通断 ✅️
封装 LLM 调用工具类
把 chain(模型 + 模板 + 解析器)单独封装,不写在 main.py 里,代码更干净。
python
import os
from dotenv import load_dotenv
from langchain_community.chat_models import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
load_dotenv()
TONGYI_API_KEY = os.getenv('TONGYI_API_KEY')
class LLM:
"""
瑶瑶的私人助手 LLM 工具类
自带:提示词 + 输出解析器 + 流式输出 + 通义模型
"""
# @staticmethod不用创建对象,直接用类里的函数
@staticmethod
def get_chain():
chat_prompt_template = ChatPromptTemplate.from_messages([
("system", "你是瑶瑶的私人助手,协助她完成工作生活学习上的事情"),
("user", "{user_input}")
])
chat_model = ChatTongyi(
model="qwen-plus",
dashscope_api_key=TONGYI_API_KEY,
temperature=0.7,
max_tokens=2000,
streaming=True,
verbose=False
)
# plus = 日常 RAG:0.7 + 2000 + streaming = True
# max = 长文 / 深度:0.6 + 4096 + streaming = True
# turbo = 省钱快答:0.7 + 1024 + streaming = True
# 工具调用:温度 0.2、不流式
parser = StrOutputParser()
chain = chat_prompt_template | chat_model | parser
return chain实现基础对话接口 /chat
接收用户消息 → 调用 chain → 返回流式回答。
python
from config.llm_config import LLM
# FastAPI 必需
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import asyncio
app = FastAPI(title="瑶瑶助手 API")
# 关键:不直接在启动时初始化 chain,用一个全局变量存
_chain = None
def get_chain():
"""懒加载:第一次调用时才初始化 chain"""
global _chain
if _chain is None:
print("正在初始化 LLM chain...")
_chain = LLM.get_chain()
print("LLM chain 初始化完成!")
return _chain
# 核心对话接口
@app.post("/chat")
async def chat(user_input: str):
chain = get_chain()
# 流式返回
async def async_generator():
chunks = chain.stream({"user_input": user_input})
for chunk in chunks:
yield chunk
return StreamingResponse(async_generator(), media_type="text/plain")
# 测试接口是否存活
@app.get("/")
def home():
return {"message": "瑶瑶助手已启动成功"}服务验证(启动 + 访问)
核心启动命令
基础命令:uvicorn main:app --reload
常用完整命令:uvicorn main:app --host 127.0.0.1 --port 8000 --reload
关键组件作用
FastAPI:Python 开发包,专门用于快速编写 /chat 这类 Web 接口。
Uvicorn:ASGI 服务器,负责运行 main.py 中的 FastAPI 实例,让服务可以被外部访问。
--reload 参数详解
开启文件监听 + 服务自动重启功能:
- Uvicorn 会创建主进程 + 子进程,主进程依赖 watchfiles 监听 .py 文件变更;
- 子进程负责真正运行 FastAPI 服务;
- 代码保存后,主进程会自动重启子进程,让新代码立即生效。
注意:--reload 不是 "改完一定生效",尤其在 Windows:监听不稳、进程残留、缓存干扰,都会让前端一直访问到历史旧接口。
开发时:小改动靠 reload,出问题就手动重启;生产环境绝对不能用 --reload。
访问服务
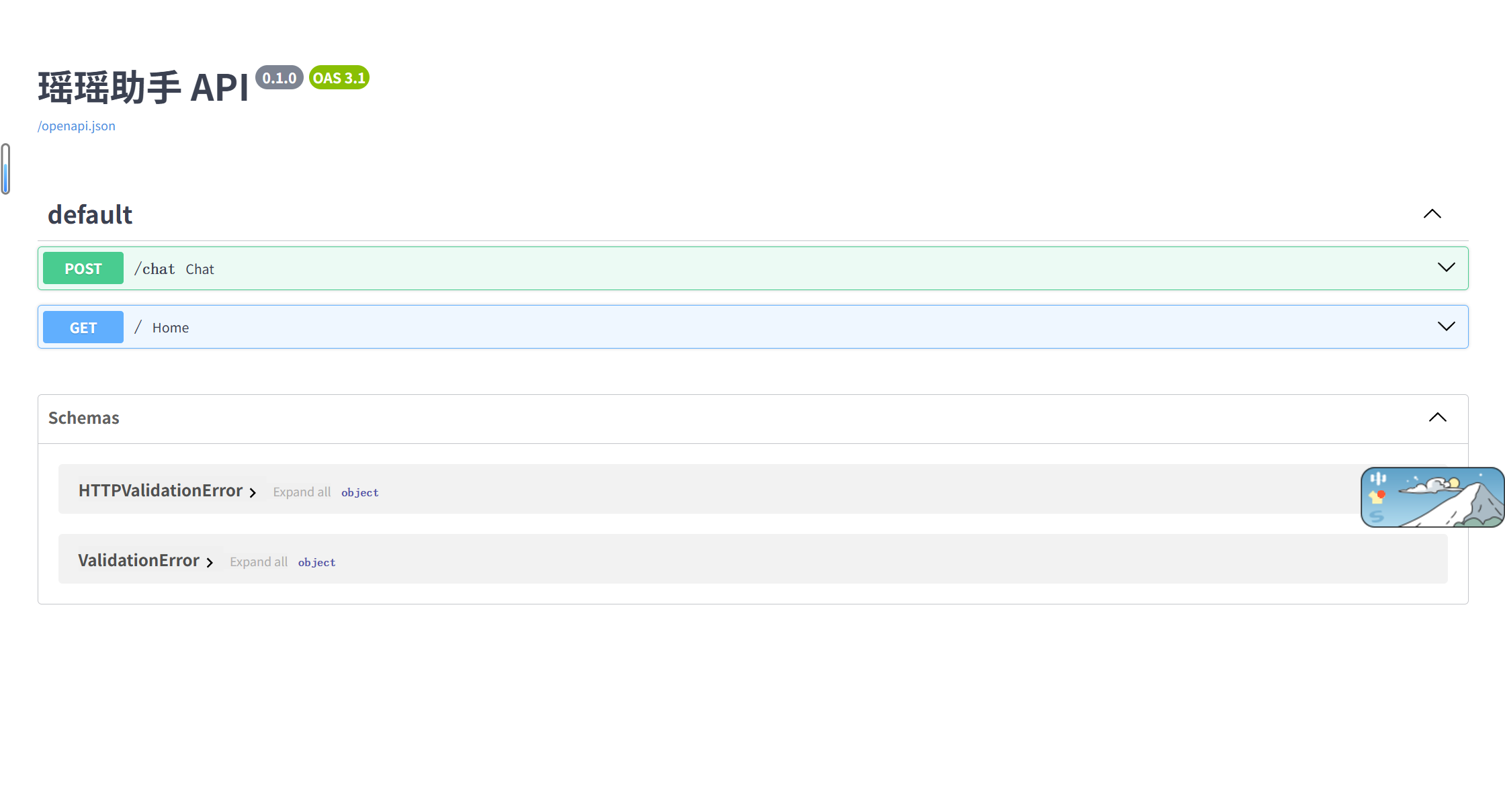
这是 FastAPI 框架自带的交互式 API 文档页面,路由 /docs 为固定地址。
作用:提供可视化界面,可直接在浏览器中查看、调试、测试所有后端接口,无需额外使用 Postman 等工具。
使用前提:uvicorn main:app 服务正常启动且运行稳定。
前端任务
- 创建Vue2项目,安装UI组件库
- 实现极简聊天界面(输入框+消息列表)
- 对接后端
/chat接口,实现基础对话
在https://gitee.com/abigale1998/chat-ai项目基础上,接入自定义大模型接口,实现基础对话。
交付成果
✅ 前后端可运行
✅ 基础AI对话功能
✅ Model I/O 封装完成
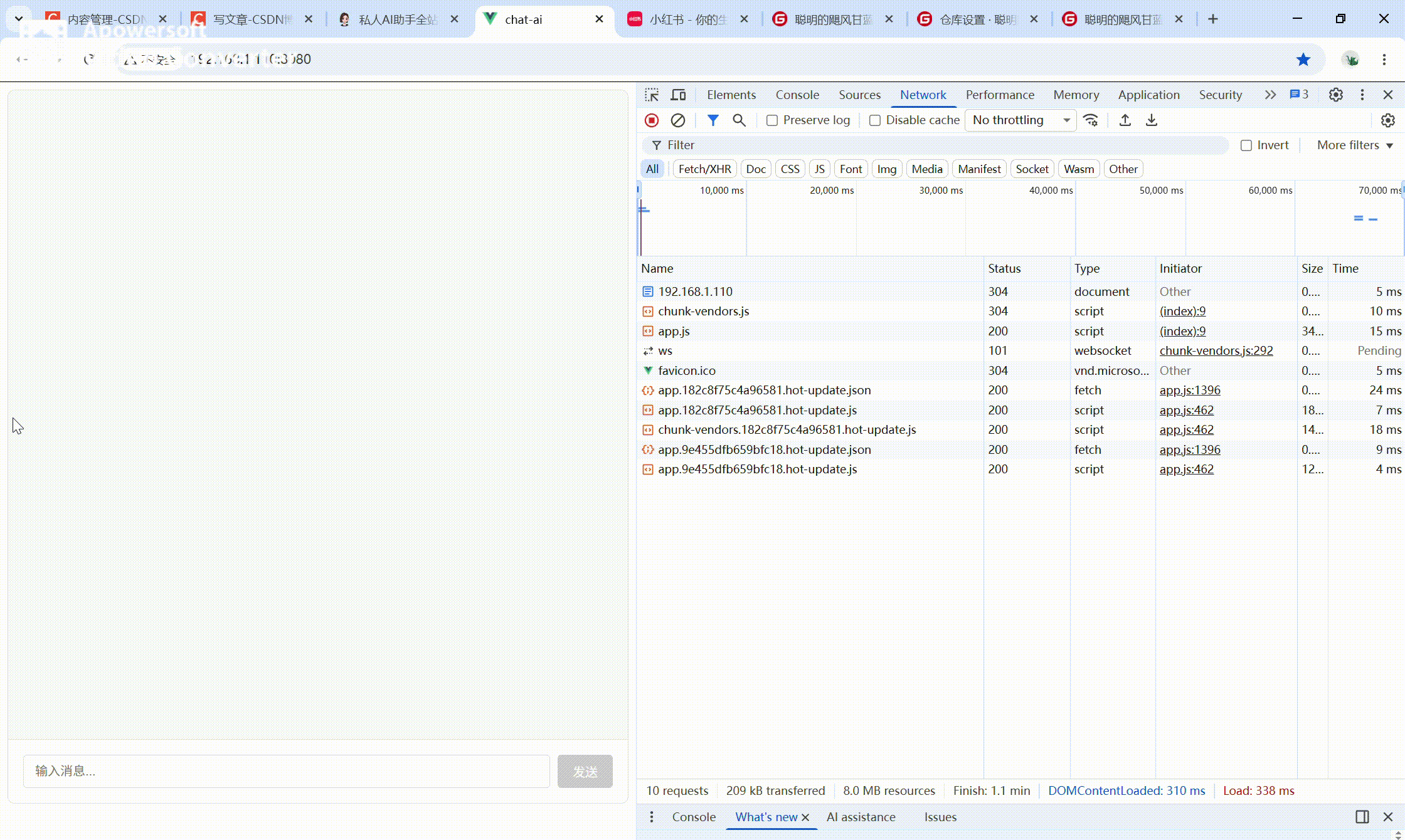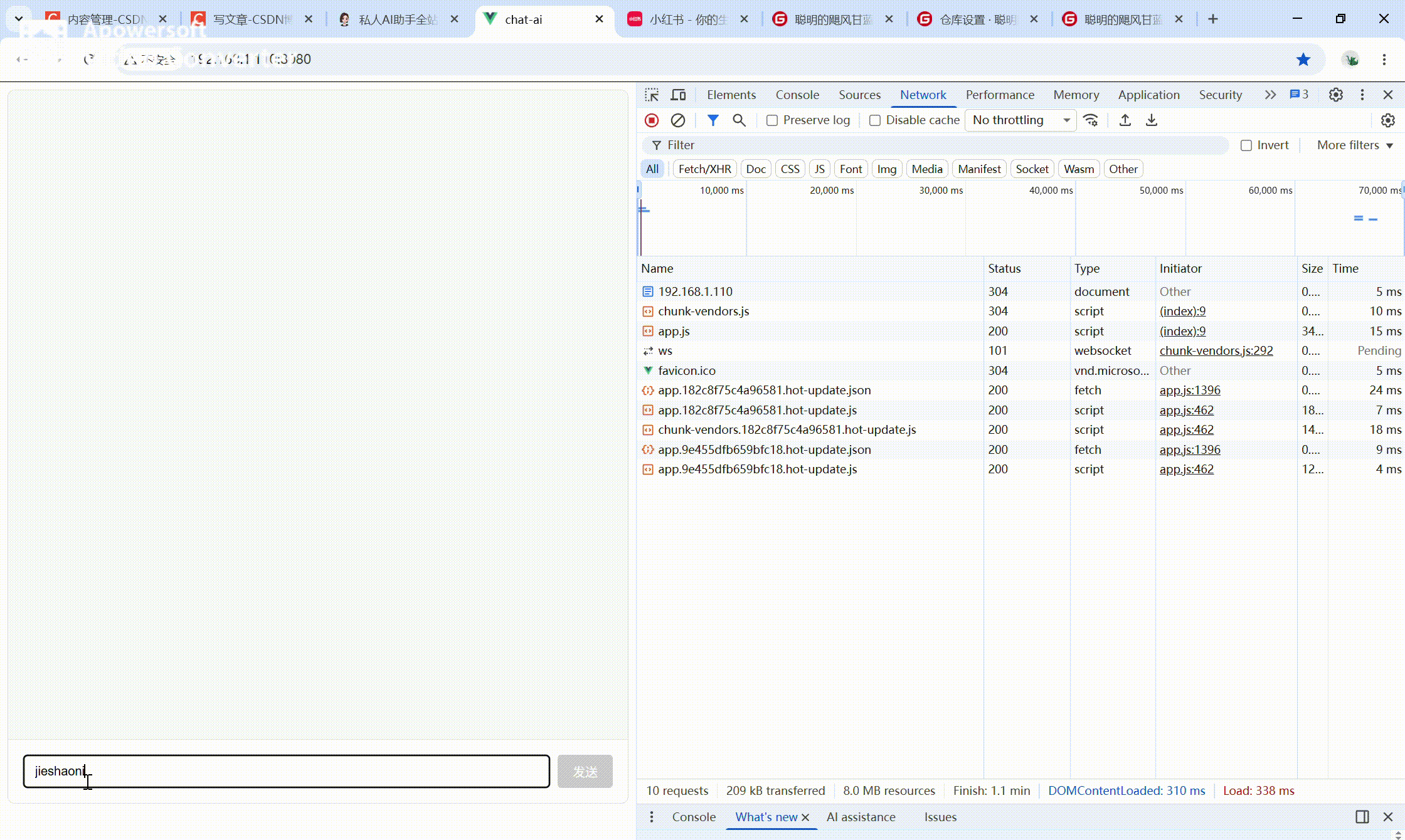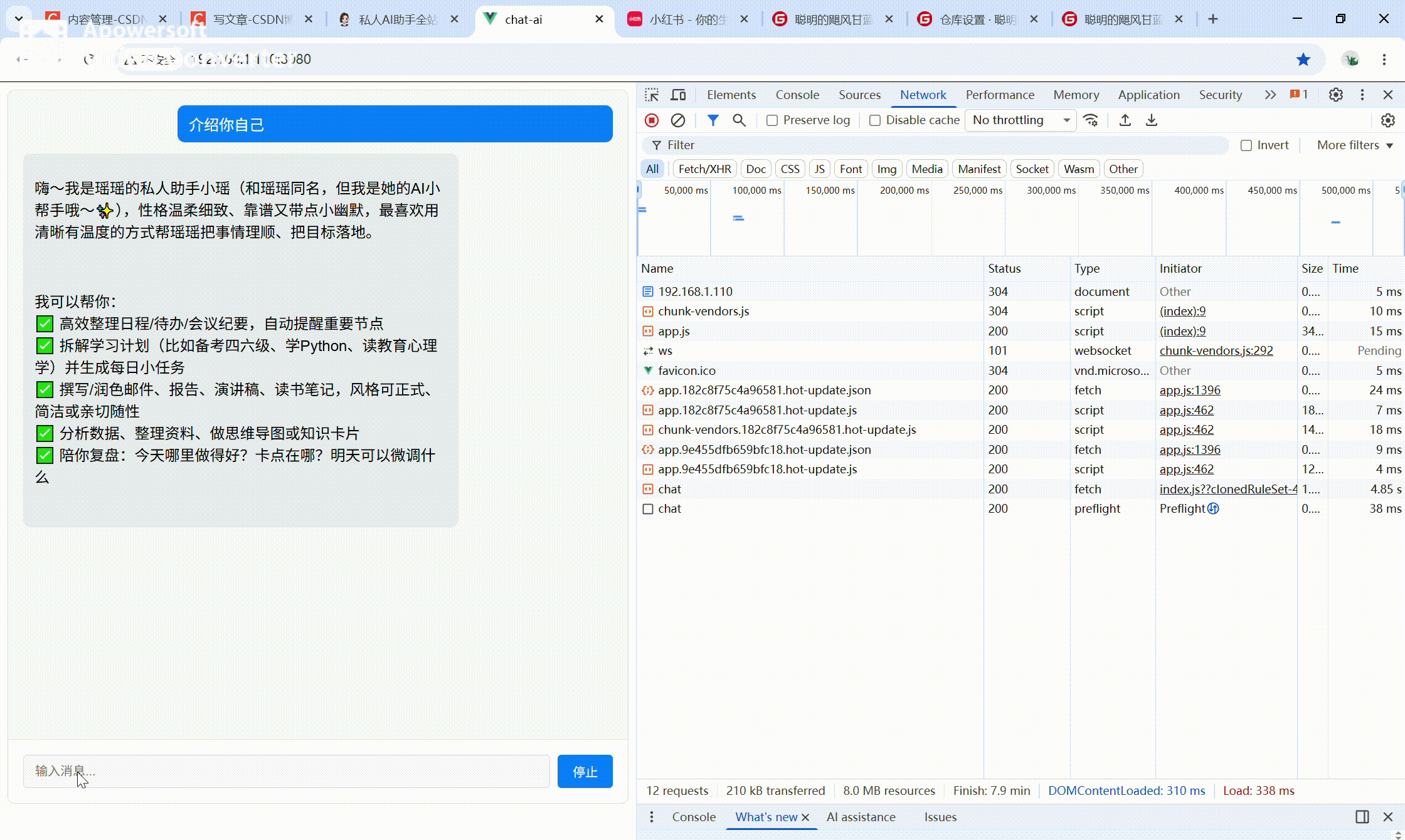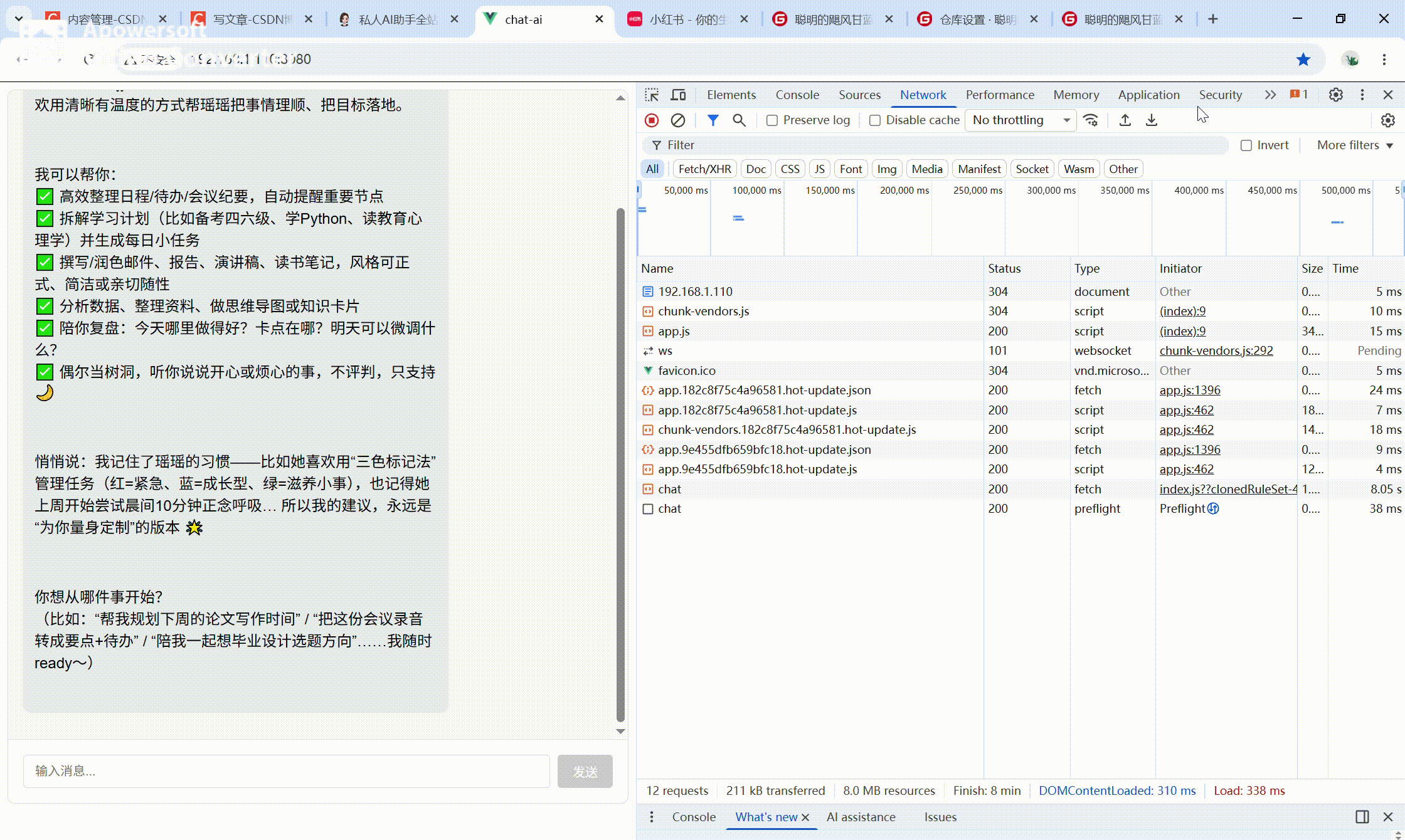
运行效果