Spring AI 2026 可观测性最佳实践:从链路追踪到企业级 AI 治理落地
作者 :架构源启
技术栈 :Spring Boot 3.5.9 + Spring AI 1.1.4 + OpenTelemetry 2.0 + OpenFeature + AI Observability Framework + eBPF
前置知识:已完成基础12篇博客

📚 前言
在 2026 年,AI 应用已经从"调用一个大模型接口"演进为多阶段、多组件、多策略协同的复杂系统。一次用户请求背后,往往同时经过网关、Prompt 编排、RAG 检索、模型路由、工具调用、质量评估、成本控制和治理策略执行。这个阶段的可观测性,已经不再只是"看看延迟和错误率",而是要回答系统是否可靠、是否可解释、是否值得这个成本、是否能够稳定落地。
2026 年 AI 应用面临的新挑战:
- ❌ 黑盒决策:模型给出答案,但团队无法解释答案为什么这样生成
- ❌ 链路变长:检索、重排、路由、工具、评估共同影响最终结果
- ❌ 质量退化隐蔽:系统不报错,不代表答案仍然可靠
- ❌ 成本波动加剧:Token、缓存、模型切换、工具调用共同决定成本
- ❌ 治理复杂化:Prompt、模型版本、知识库和 Feature Flag 都可能导致回归
2026 年 AI 应用的可观测性需求:
- ✅ 端到端 AI 感知追踪:从用户输入到最终业务结果全链路可见
- ✅ AI 原生指标体系:性能、质量、成本、体验四类指标统一建模
- ✅ 语义化日志聚合:能够解释系统"为什么这样决策"
- ✅ 质量驱动告警:不仅发现故障,还能发现答案质量问题
- ✅ 持续治理能力:支持灰度、回滚、降级、审计和成本控制
- ✅ 复杂系统落地:适配多租户、多模型、多地域和多团队协作
① 本文你将学到
✅ OpenTelemetry 2.0 在 AI 场景下的定位
✅ Spring AI 项目的观测接入思路
✅ AI 原生指标设计方法
✅ 语义化日志与质量评估的工作原理
✅ 机器学习驱动告警的设计边界
✅ 模型漂移与系统退化的识别思路
✅ 复杂系统中的 AI 原生可观测性架构
⚡ 一、OpenTelemetry 2.0 在 AI 场景中的集成
① 2026 年 OpenTelemetry 新特性
到了 2026 年,OpenTelemetry 在 AI 场景里的意义已经不再是"把 HTTP 调用串起来",而是提供一套统一的运行时语义,让模型调用、检索链路、工具调用、评估结果和治理事件能够进入同一个观测体系。
如果从系统设计角度理解,OpenTelemetry 在 AI 系统里主要解决三个问题:
-
把黑盒请求拆成可追踪步骤
一次 AI 请求不再被视为单个 RPC,而是拆成 Prompt 构建、检索、重排、模型路由、模型调用、工具执行、评估回写等多个阶段。
-
让跨信号数据具备统一语义
traces、metrics、logs 不再各说各话,而是围绕模型版本、Prompt 版本、知识库版本、租户、场景和业务结果工作。
-
让观测结果能回流到控制面
模型切换、Prompt 回滚、流量灰度、成本限流和降级策略,不再是孤立运维动作,而是建立在观测结果之上的治理动作。
所以在 AI 场景里,OpenTelemetry 更像一套"运行时语义底座",而不是单纯的打点工具。
② 2026 年 Spring AI 接入思路
对 Spring AI 项目来说,更重要的不是依赖列表,而是接入顺序。成熟的接入路径通常是:
-
先启用 Spring Boot Actuator 与 Micrometer Observation
这是 Spring AI 观测链路的底座,用来把关键 AI 操作纳入统一 Observation 模型。
-
再接入 OTel 导出链路
让 Observation 能被映射成 trace 和 metrics,并进入统一的数据面。
-
最后补齐 AI 业务语义
例如 Prompt 版本、模型版本、知识库版本、Feature Flag 命中结果、质量分数和成本估算。
复杂系统里,依赖装齐并不代表接入成功。真正决定能否落地的,是下面三件事:
- 你是否定义了统一字段。
- 你是否区分了低基数和高基数字段。
- 你是否把治理事件也接入了观测体系。
如果没有这些设计,系统最多只能看到"模型调用慢了",却回答不了"为什么慢、为什么错、为什么贵"。
下面这张图更适合从技术视角理解 Spring AI 与 OTel 的协作关系:
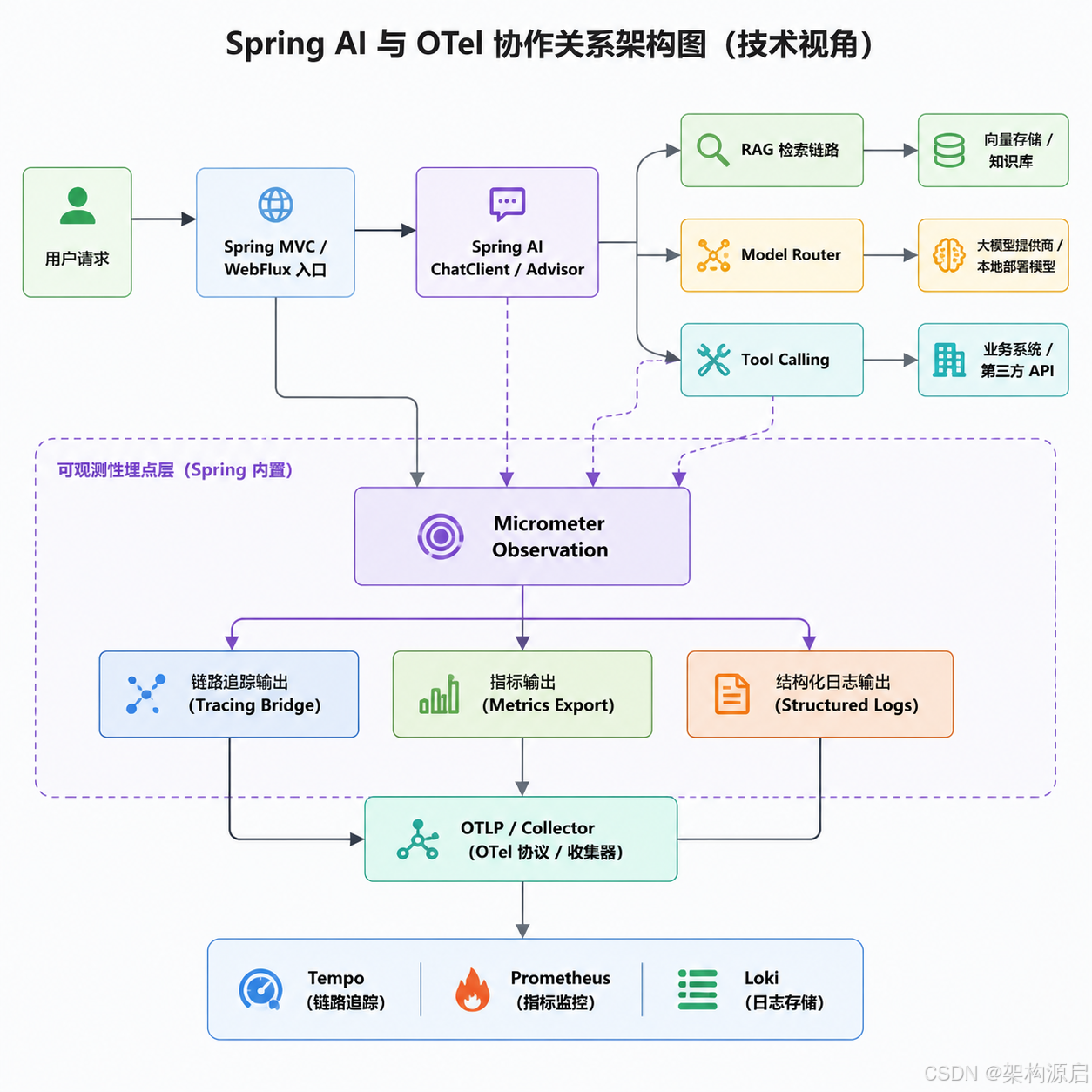
这张技术架构图强调的是一个核心事实:Spring AI 不是单独向 OTel 打点,而是通过 Observation 把 AI 操作统一纳入 Spring 的观测模型,再由 OTel 统一导出。
📊 二、AI 原生指标设计模式
① 多维度 AI 指标体系
传统系统的指标体系大多围绕 RED 和 USE 展开,但 AI 系统只靠这两套方法是不够的。因为 AI 请求即使成功返回,也可能答错、答偏、答得太贵,或者根本没有实现业务目标。
更适合 AI 系统的做法,是把指标分成四个维度:
| 维度 | 核心问题 | 典型指标 |
|---|---|---|
| 性能 | 请求是否稳定、是否变慢 | 延迟、吞吐、错误率、超时率 |
| 质量 | 输出是否可靠、是否基于上下文 | groundedness、relevance、hallucination risk、tool success rate |
| 成本 | 输出是否值这个价格 | input/output tokens、cache hit、cost per request、cost per resolved case |
| 体验 | 用户是否真正获得价值 | 转人工率、完成率、CSAT、留存、转化 |
这四个维度里,最容易被忽略的是"质量"和"体验"。很多团队会把成本和延迟做得很细,却没有办法解释:
- 为什么系统很快,但用户满意度下降?
- 为什么模型没报错,但 groundedness 一直在跌?
- 为什么成本稳定,但业务转人工率明显上升?
所以 AI 指标体系的核心不是"指标更多",而是让指标服务于业务判断和治理决策。
② RAG AI 增强指标
RAG 系统比单次模型调用更复杂,因为它天然包含"检索质量"和"生成质量"两层问题。真正有效的 RAG 指标设计,应该围绕三层问题展开:
-
召回是否正确
关注
top_k、过滤命中率、ACL 失配、重排前后保留率。这层回答"知识有没有找对"。
-
上下文是否被有效使用
关注 context tokens、引用命中率、文档利用率、groundedness。
这层回答"找到了有没有真正用上"。
-
最终答案是否实现业务目标
关注完成率、转人工率、用户反馈、误答损失。
这层回答"最终有没有解决用户问题"。
RAG 最难排障的地方,不是链路长,而是这三层问题会互相伪装。很多看起来像"模型退化"的问题,本质上其实是召回语义错位、过滤条件变化,或者知识库版本切换导致的上下文失真。
📈 三、AI 原生 Grafana Dashboard 2.0
① AI 系统全景看板
AI 系统的 dashboard 设计,不应该只是把指标堆在一张大屏上,而应该让不同角色都能快速判断系统当前处于哪种状态。全景看板最重要的作用,是建立"从症状到定位"的第一层视图。
比较成熟的全景看板通常会同时呈现四个方向:
-
系统是否稳定
看延迟、错误率、请求量、Collector 健康度、核心依赖状态。
-
AI 是否可靠
看 groundedness、relevance、工具成功率、质量评分变化。
-
成本是否可控
看 Token 消耗、缓存命中、模型切换、单请求成本和预算消耗速度。
-
业务是否受影响
看完成率、转人工率、工单解决率、用户反馈和业务 SLA。
全景看板的设计目标不是"展示更多图",而是帮助团队在 1 到 3 分钟内完成初步判断:这是系统问题、质量问题、成本问题,还是治理策略问题。
② AI 模型性能专项看板
专项看板更适合回答"为什么这个模型最近表现变差"。它不强调全局,而强调可比较性。
比较有价值的专项视角包括:
- 不同模型版本之间的质量对比
- 不同 Prompt 模板之间的效果差异
- 不同知识库版本之间的 groundedness 变化
- 不同模型路由策略之间的成本与质量权衡
- 不同输入类型、不同租户、不同业务场景下的表现差异
专项看板的本质,是把"平均值幻觉"拆掉。因为 AI 系统很容易出现整体均值稳定、局部场景明显恶化的情况。
📝 四、AI 驱动的语义化日志系统
① 语义化日志处理器
传统业务系统的日志主要是"记录发生了什么",而 AI 系统里的日志更重要的作用是"解释系统当时为什么这样做"。这就是为什么 AI 场景里必须强调语义化日志。
语义化日志至少要覆盖三层信息:
-
事件层
记录发生了哪类动作,例如请求入站、模型路由、工具调用、评估完成、治理策略命中。
-
上下文层
记录动作发生时的上下文,例如租户、会话、Prompt 版本、知识库版本、实验组、模型版本。
-
解释层
记录系统为什么这样做,例如路由原因、拦截原因、脱敏原因、降级原因、失败类型。
没有解释层的日志,最多只能算结构化日志;只有把"决策原因"也写进去,日志才真正具备 AI 语义。
② 2026 年日志设计边界
日志系统里最重要的不是"输出 JSON",而是职责分层。成熟系统通常会把日志分成三类:
| 日志类型 | 主要作用 | 典型内容 |
|---|---|---|
| 运行日志 | 排障与链路分析 | trace_id、span_id、模型路由、工具调用、延迟、失败原因 |
| 质量日志 | 评估与回放分析 | groundedness、relevance、工具正确率、引用命中、人工反馈 |
| 审计日志 | 合规与治理留痕 | 策略命中、权限变化、Prompt 切换、脱敏动作、人工介入 |
把这三类日志混在一起,会带来两个直接问题:
- 排障、回放和审计场景彼此污染,查询成本越来越高。
- 数据保留策略没有边界,最终不是留不够,就是留太多。
所以日志设计真正要先解决的问题,是"按什么职责分流",而不是"用哪种日志框架"。
③ AI 驱动的日志分析引擎
AI 驱动日志分析的工作原理,并不是"让大模型去读全部日志",而是先把日志变成可以聚类、比较、回放的事件流,再把 AI 用在归纳和解释层。
比较稳妥的分析链路通常是:
-
先做结构化和归一化
把事件名称、失败类型、组件、模型版本、工具名等统一成可统计字段。
-
再做窗口聚合和异常检测
比较当前窗口和历史窗口之间的失败分布、路由变化、工具异常占比和质量趋势。
-
最后让 AI 参与归纳说明
把异常窗口里的主要变化点总结成适合人工判断的语言,而不是让 AI 直接替代规则系统。
这背后的原则很重要:AI 更适合解释复杂模式,不适合替代日志基础设施。
🚨 五、机器学习驱动的智能告警
① 自适应告警规则引擎
AI 场景下的告警设计,最大的变化不是规则语法,而是告警对象发生了变化。过去我们主要对"服务是否挂了"告警,而现在还要对"结果是否变差""成本是否失控""治理策略是否异常"告警。
成熟的 AI 告警通常会分成四层:
-
基础设施告警
看 CPU、内存、网络、队列、Collector 健康度。
这是底线,但不是重点。
-
执行链路告警
看模型调用失败率、工具调用失败率、检索超时、缓存击穿、路由切换频率。
-
质量告警
看 groundedness、relevance、幻觉风险、错误引用率、人工兜底率。
-
业务与成本告警
看转人工率、完成率、工单解决率、成本异常增长和预算透支速度。
真正最有价值的,往往是"质量 + 业务"这两层告警,因为它们最接近用户感知和业务损失。
② AI 增强的告警处理管道
告警管道的核心工作原理可以概括为四步:
-
先检测异常
识别哪些指标和信号偏离了稳定状态。
-
再判断异常是否重要
不是每次波动都值得打扰人工,必须先做噪音压制和影响评估。
-
然后定位异常更可能属于哪类问题
是基础设施故障、检索异常、模型退化、工具失败,还是治理策略变更导致的回归。
-
最后决定处理方式
是抑制、路由、升级、自动回滚,还是执行自动化修复。
AI 在这里最有价值的地方,主要是第 2 步和第 3 步,也就是帮助压制噪音、归纳异常模式、解释更可能的原因,而不是替代整个告警体系。
③ 2026 年告警通知配置
通知设计最关键的不是"发到哪里",而是"发给谁、附带什么解释"。同样的异常,发给平台团队、AI 团队、业务团队和管理层,关注点完全不同。
因此更合理的通知策略应该是:
- 平台团队看到链路、组件和资源影响
- AI 团队看到模型、Prompt、检索和质量信号
- 业务团队看到用户影响和业务结果
- 管理层看到成本、风险和恢复进展
这就是为什么成熟告警通知都会强调"分层摘要",而不是单一模板群发。
🔍 六、AI 模型漂移检测与性能监控
① 概念漂移检测算法
漂移检测是 AI 可观测性里最容易被说玄、但最应该讲清原理的部分。所谓"漂移",本质上是在说:系统面对的输入、上下文或输出分布,已经和原来的稳定状态不一样了。
在生产系统里,至少要区分三类漂移:
-
输入漂移
用户问题类型、输入长度、语言、领域分布发生变化。
这意味着系统面对的问题本身变了。
-
上下文漂移
知识库内容、召回文档质量、工具返回结构、权限过滤结果发生变化。
这意味着模型使用的依据变了。
-
输出漂移
groundedness、relevance、正确率、转人工率、业务完成率持续变化。
这意味着用户实际看到的结果变了。
真正成熟的漂移监控,不是只盯某一条准确率曲线,而是同时观察输入、上下文和输出三层分布。
从工程实现上看,漂移检测通常分成两种思路:
-
统计分布检测
通过滑动窗口比较均值、方差、分位数和分布差异,判断最近一段时间是否明显偏离历史基线。
-
表征空间检测
通过 embedding、聚类中心或语义相似度结构变化,判断输入语义空间是否正在偏移。
漂移检测真正有价值的地方,不是"检测到了漂移"本身,而是它能驱动后续治理动作:
- 触发质量回归检查
- 触发 Prompt 或模型版本回滚
- 触发知识库重建与检索策略校正
- 触发重新标注和评估样本抽样
所以漂移监控本质上不是一个单独算法模块,而是"从观测走向治理"的桥梁。
📊 七、2026 年 AI 原生可观测性完整架构
这一章不再停留在"监控三件套 + 几个 AI 指标"的层面,而是把 Spring AI 应用放回真实生产系统中来设计。到了 2026 年,复杂 AI 系统的瓶颈已经不只是慢和贵,而是以下四类问题同时出现:
- 请求链路变长:一次用户请求往往会经过网关、ChatClient、Advisor 链、模型路由、RAG 检索、工具调用、重排、评估器和缓存。
- 质量问题更隐蔽:系统可能没有报错,但答案已经偏题、上下文召回失效、工具选择错误,或者成本异常飙升。
- 责任边界变复杂:基础设施、平台、模型、知识库、策略开关和合规控制都在影响结果。
- 排障必须跨信号:单看 metrics 不够,单看 traces 也不够,必须把 traces、metrics、logs、evaluation、feature flag、成本和部署事件串起来。
因此,2026 年更可落地的设计思路不是"给 LLM 调用打点",而是把 AI 可观测性做成一套完整的运行时控制面。
① 设计目标与架构原则
如果从系统设计角度来概括,AI 可观测性本质上是在回答四个问题:
- 这次请求到底经历了什么链路。
- 它为什么得到这个结果。
- 这个结果是否可靠、是否合规、是否值得这个成本。
- 当结果变差时,系统能否快速定位并执行治理动作。
一套能在复杂系统中落地的 AI 可观测性架构,至少要同时满足下面五个目标:
- 端到端可追踪:能从用户请求一路追到 Prompt、检索文档、模型响应、工具执行、评估结果和最终业务结果。
- 质量可解释:不仅知道"慢了",还要知道"为什么答错""错在检索、推理还是工具调用"。
- 成本可归因:Token、缓存命中、模型单价、GPU/CPU 资源占用,必须能归因到租户、用户、场景和功能。
- 治理可执行:灰度、A/B、模型切换、降级、脱敏、审计不能分散在多个系统里各自为战。
- 落地可演进:允许团队从最小可用方案起步,逐步演进到多集群、多模型、多租户、多地域。
基于这五个目标,建议采用下面四条架构原则:
- 应用面、观测面、控制面分离:业务流量和治理流量分开,避免把策略判断写死在业务代码里。
- 先统一语义,再统一工具:先定 span、metric、log 和 evaluation 的字段规范,再考虑接 Grafana、Tempo、Loki、Phoenix 或其他平台。
- 默认低侵入,关键路径显式增强:基础指标交给 Spring AI + Micrometer + OTel 自动完成;Prompt 模板版本、召回文档 ID、评估分数等关键信息再手工补齐。
- 先保障召回和质量,再做智能运维:没有稳定 schema、trace 语义和评估闭环,所谓"AI 运维"只会制造更多噪音。
② 生产级分层架构总览
下面这个架构比"单个 Spring Boot 服务接一个 OTel Agent"更接近真实项目。
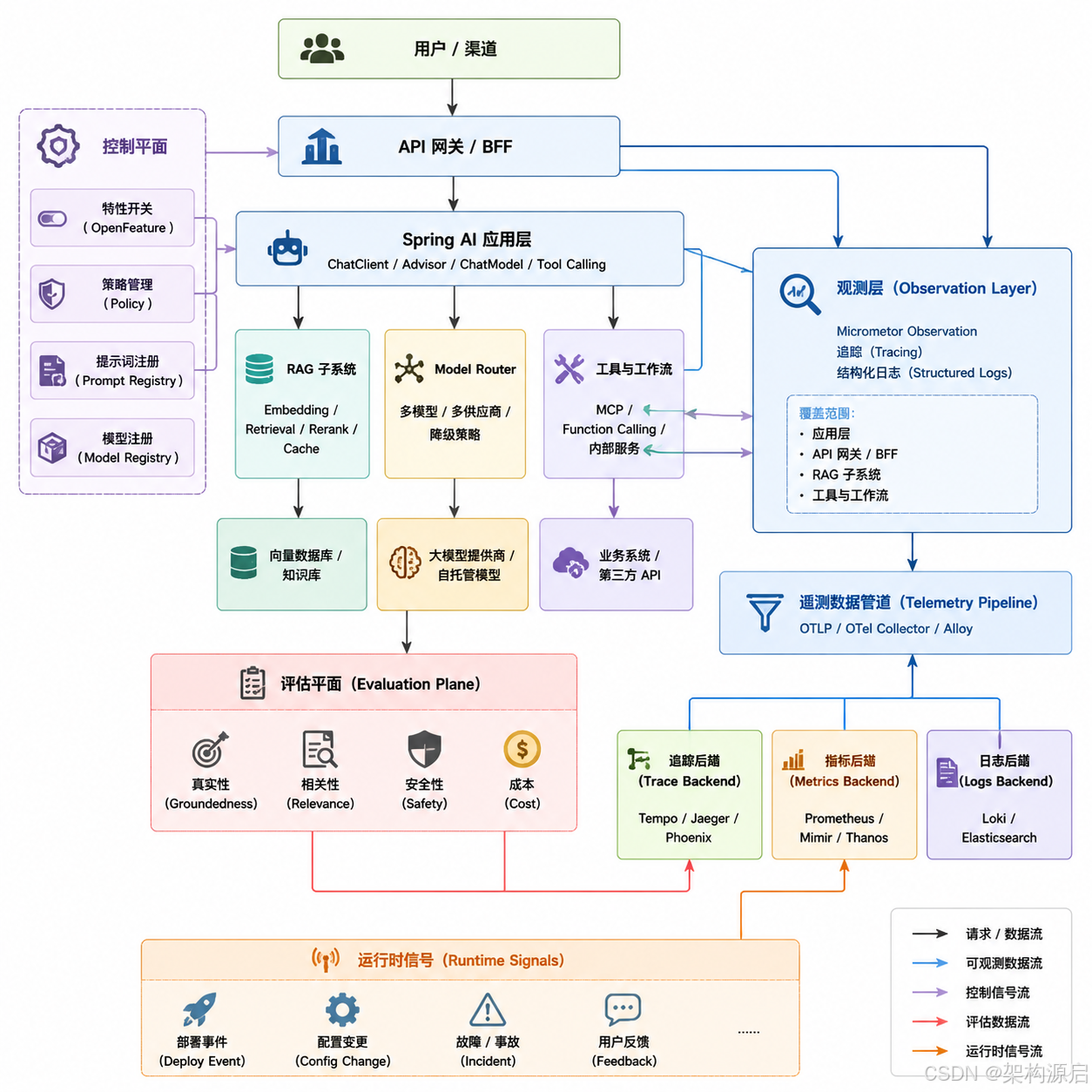
从设计职责上看,这个架构可以拆成五层:
| 层面 | 核心职责 | 设计重点 |
|---|---|---|
| 入口协同层 | 网关、BFF、鉴权、限流、租户隔离、灰度入口 | 必须在最外层注入 trace_id、tenant_id、session_id,并记录流量镜像与实验组信息 |
| AI 应用层 | Spring AI 编排、Prompt 构建、RAG、模型选择、工具调用 | 用 ChatClient + Advisor 统一拦截链,把上下文和业务标签放到 Observation 中 |
| 观测采集层 | metrics、traces、logs、evaluation、profiles 的采集与预处理 | 低基数字段进入 metrics,高基数字段只进 traces/logs,避免指标爆炸 |
| 中央平台层 | Collector、后端存储、查询、看板、告警 | 强调队列、批量、重试、持久化队列、冷热分层存储 |
| 控制治理层 | Feature Flags、策略中心、提示词版本、模型注册、审计 | 把模型切换、Prompt 版本和合规策略做成控制面,不直接散落在代码中 |
真正让架构变复杂的,不是层数,而是层与层之间的职责边界:
- 入口协同层负责定义"这是谁的请求、属于哪个场景、走哪条实验链路"。
- AI 应用层负责定义"这次请求做了哪些 AI 决策"。
- 观测采集层负责定义"哪些信息能被稳定、低成本地记录下来"。
- 中央平台层负责定义"这些信号如何可靠运输、存储、查询和告警"。
- 控制治理层负责定义"当结果变差时,系统应该如何切换、回滚、限流或降级"。
很多系统之所以越做越乱,就是这五层职责混在一起了:业务代码里写模型切换,网关里写 Prompt 逻辑,监控系统里再临时补业务解释。最后既不好排障,也不好治理。
③ 一次真实请求的数据流
理解 AI 可观测性,最重要的不是看组件图,而是看一次请求如何穿过系统。用"企业知识助手"举例,一次完整请求通常会经历下面九个阶段:
| 阶段 | 关键 Span / Event | 必须记录的核心字段 | 为什么关键 |
|---|---|---|---|
| 请求入站 | ai.request |
trace_id、tenant_id、user_id_hash、session_id、entrypoint |
统一业务入口,后续所有信号都要回挂到这里 |
| Prompt 组装 | ai.prompt.build |
prompt_template_id、prompt_template_version、conversation_turns、policy_profile |
能区分是模型问题还是模板问题 |
| 检索召回 | ai.retrieval |
knowledge_base_id、top_k、doc_ids、scores、filter_expr |
RAG 系统最常见的问题就在这一步 |
| 重排裁剪 | ai.rerank |
reranker_model、selected_doc_ids、dropped_doc_ids、context_tokens |
解释"为什么明明召回了却没有被使用" |
| 模型路由 | ai.model.route |
candidate_models、selected_model、route_reason、fallback_count |
解释成本、延迟和质量差异 |
| 模型调用 | gen_ai.client / ai.llm.call |
provider、model、latency_ms、input_tokens、output_tokens、cache_hit |
这是成本和延迟的核心来源 |
| 工具调用 | ai.tool.call |
tool_name、tool_latency_ms、tool_status、tool_retry_count |
Agent / Tool Calling 失效通常发生在这里 |
| 输出评估 | ai.eval |
groundedness、relevance、safety_score、hallucination_risk |
没有评估就没有"质量可观测性" |
| 业务落点 | ai.business.outcome |
resolved、handoff_to_human、conversion、csat |
把技术指标和业务结果真正打通 |
这条链路里最核心的设计思想,是把一次 AI 请求拆成多个"可解释的决策阶段"。传统系统常把 AI 请求视为一个黑盒 RPC,只看总延迟和总错误率;但在复杂 AI 系统里,真正出问题的通常是局部阶段:
- 召回没问题,但重排把关键文档裁掉了。
- 模型本身没问题,但路由策略切到了低质量模型。
- 工具调用成功了,但返回的数据不符合当前对话上下文。
- 响应看起来流畅,但 groundedness 已经显著下降。
所以复杂系统中最容易被忽略的一点是:可观测性数据本身也要建模。如果没有统一字段,后面所有告警、归因、审计和成本分析都会散。
④ 核心技术工作原理
这一节不再给实现代码,而是把真正决定系统能否落地的工作原理讲清楚。
1. Spring AI 观测链路的底层逻辑
Spring AI 的观测能力并不是额外拼上去的,而是站在 Spring Boot Actuator、Micrometer Observation 和 Tracing 这条链路上工作。它的底层逻辑可以概括为一句话:
先把 AI 操作变成 Observation,再把 Observation 映射成 metrics 与 trace,最后统一导出到 OTel 后端。
这背后有三个关键点:
-
观测对象要足够细
不是只记录"调用一次模型",而是把 Prompt 构建、检索、重排、模型路由、工具调用、评估这些动作拆成多个可观测节点。这样才能解释问题发生在哪个阶段。
-
同一份上下文要能跨信号复用
一次请求里的租户、场景、模型版本、Prompt 版本、知识库版本,不应该在日志、指标、追踪里各维护一份不同定义。否则系统越大,语义越乱。
-
观测要服务决策,而不是只服务展示
真正有价值的不是"看板更炫",而是观测数据能回到模型路由、实验切流、回滚和告警策略里,成为控制面的输入。
2. 为什么复杂系统里先要做语义建模
很多团队以为"多打点"就等于"更可观测",其实复杂系统里首先要解决的是语义一致性。AI 系统最大的难点,是一次请求里既有基础设施语义,也有 AI 特有语义,还有业务语义。如果不先分层,后面一定会乱。
建议把语义分成三层理解:
| 语义层 | 典型内容 | 作用 |
|---|---|---|
| 平台层语义 | service.name、instance、region、http.route |
解释系统运行状态 |
| AI 运行层语义 | prompt_template_version、model_version、retrieval_top_k、tool_name |
解释 AI 决策过程 |
| 业务层语义 | tenant_id、scenario、business_outcome、handoff_to_human |
解释业务结果和价值 |
这三层语义如果混写,会带来三个直接问题:
- 指标系统里出现大量高基数字段,存储成本失控。
- 排障时只能看到技术链路,看不到业务上下文。
- 后续做 A/B、灰度、质量归因和审计时,很难把事件串起来。
所以 2026 年更成熟的做法是:先定义统一 schema,再决定数据去哪儿存。
3. Collector 为什么是数据面的中枢
在复杂系统里,Collector 的价值不是"转发数据",而是承担观测数据的数据面治理。它处在应用与后端之间,所以天然承担了四类职责:
-
协议汇聚
不同应用、sidecar、代理、eBPF 工具采集到的数据,需要先在这里汇合。
-
流量整形
AI 系统的 trace 和日志体量通常很大,如果没有批量、限流、采样和属性处理,后端很快会被压垮。
-
可靠缓冲
后端抖动、网络闪断、存储瞬时不可用在生产系统里是常态。Collector 必须具备队列、重试和必要的持久化缓冲能力。
-
策略执行
脱敏、删字段、降采样、异常样本保留、贵价请求优先保留,这些都更适合放在 Collector 或 sidecar 一侧执行,而不是写死在业务代码里。
这也是为什么在大规模系统里,Collector 更像"遥测网关",而不是简单的 agent。
4. 质量评估为什么必须进入主观测面
传统系统把"成功返回"视为请求完成,但 AI 系统里这远远不够。模型返回了 200,不等于答案正确、可靠、合规,也不等于用户真正解决了问题。
从工作原理上看,质量评估进入主观测面,意味着系统从只观测"执行过程"升级为同时观测"输出质量"。这件事至少有四层价值:
-
把技术成功和业务成功区分开
一次调用可以在技术上成功,但在业务上失败,比如答案编得很流畅,却根本没有基于知识库回答。
-
让告警从基础设施问题升级到质量问题
真正影响用户体验的,往往不是 CPU 突增,而是 groundedness、relevance、工具正确率、转人工率的变化。
-
让根因分析更接近真实问题
当质量下降时,系统才能继续追问:是 Prompt 变了,召回差了,路由切错了,还是工具返回异常。
-
让治理动作有依据
模型回滚、Prompt 回滚、路由切换、缓存策略调整,都应该基于质量信号,而不只是基于延迟。
所以复杂 AI 系统里,质量评估不是"附加分析",而是主观测面的组成部分。
5. 控制面为什么必须和观测面联动
AI 系统比传统系统更依赖运行时治理,因为影响结果的不只是代码版本,还有 Prompt、知识库、模型供应商、工具权限、实验组和安全策略。
这意味着系统里至少存在两条并行链路:
- 执行链路:请求如何被处理。
- 治理链路:系统为什么做出当前处理方式。
如果观测面只记录执行链路,不记录治理链路,就会出现典型问题:
- 发现质量下降,但不知道是不是某个灰度策略触发的。
- 看到成本激增,但不知道是不是模型路由规则刚被调整。
- 查到某批请求都答错了,但不知道是不是 Prompt 版本刚被替换。
因此成熟系统一定会把下面这些治理事件接入可观测性:
- Feature Flag 命中结果
- Prompt 模板版本切换
- Model Router 选型原因
- 知识库版本变更
- 安全策略命中与拦截事件
当这些治理事件回挂到同一个 trace_id 或请求上下文上,系统才真正具备"可解释运行时"的能力。
6. eBPF 与应用埋点的正确分工
这一点很容易被误解。eBPF 的价值非常大,但它解决的是"底层盲区"而不是"业务语义缺失"。
更准确的分工应该是:
- 应用埋点负责解释 AI 决策过程。
- eBPF/零侵入采集负责解释系统运行时行为。
前者回答"为什么选了这个模型、为什么用了这些文档、为什么调用了这个工具",后者回答"请求为什么在网络、内核、运行时或代理层变慢"。两者结合,才能把"AI 质量问题"和"系统性能问题"区分开。
⑤ 贴近实际的复杂场景落地模式
下面用三个常见场景说明,为什么文章里的架构必须设计得更深。
场景一:多租户企业知识助手
特点是租户多、知识库多、权限差异大、召回链路长。这里的核心不是模型本身,而是"每个租户看到的上下文是否正确"。
建议重点关注的不是"模型平均延迟",而是下面这些真正影响业务的信号:
tenant_id、knowledge_base_id、retrieval_filter、doc_acl_misstop_k、rerank_drop_ratio、groundedness_scorecache_hit_ratio、cost_per_answer、handoff_to_human
落地关键点:
- 网关就做租户身份注入和 trace 透传。
- 检索层必须记录"命中的文档"和"被裁掉的文档"。
- 评估层必须能够区分"模型答错"和"召回上下文错了"。
对应的业务架构图更适合这样表达:
#mermaid-svg-Y4UarbEHJEpvq46g{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-Y4UarbEHJEpvq46g .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-Y4UarbEHJEpvq46g .error-icon{fill:#552222;}#mermaid-svg-Y4UarbEHJEpvq46g .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-Y4UarbEHJEpvq46g .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-Y4UarbEHJEpvq46g .marker{fill:#333333;stroke:#333333;}#mermaid-svg-Y4UarbEHJEpvq46g .marker.cross{stroke:#333333;}#mermaid-svg-Y4UarbEHJEpvq46g svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-Y4UarbEHJEpvq46g p{margin:0;}#mermaid-svg-Y4UarbEHJEpvq46g .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-Y4UarbEHJEpvq46g .cluster-label text{fill:#333;}#mermaid-svg-Y4UarbEHJEpvq46g .cluster-label span{color:#333;}#mermaid-svg-Y4UarbEHJEpvq46g .cluster-label span p{background-color:transparent;}#mermaid-svg-Y4UarbEHJEpvq46g .label text,#mermaid-svg-Y4UarbEHJEpvq46g span{fill:#333;color:#333;}#mermaid-svg-Y4UarbEHJEpvq46g .node rect,#mermaid-svg-Y4UarbEHJEpvq46g .node circle,#mermaid-svg-Y4UarbEHJEpvq46g .node ellipse,#mermaid-svg-Y4UarbEHJEpvq46g .node polygon,#mermaid-svg-Y4UarbEHJEpvq46g .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-Y4UarbEHJEpvq46g .rough-node .label text,#mermaid-svg-Y4UarbEHJEpvq46g .node .label text,#mermaid-svg-Y4UarbEHJEpvq46g .image-shape .label,#mermaid-svg-Y4UarbEHJEpvq46g .icon-shape .label{text-anchor:middle;}#mermaid-svg-Y4UarbEHJEpvq46g .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-Y4UarbEHJEpvq46g .rough-node .label,#mermaid-svg-Y4UarbEHJEpvq46g .node .label,#mermaid-svg-Y4UarbEHJEpvq46g .image-shape .label,#mermaid-svg-Y4UarbEHJEpvq46g .icon-shape .label{text-align:center;}#mermaid-svg-Y4UarbEHJEpvq46g .node.clickable{cursor:pointer;}#mermaid-svg-Y4UarbEHJEpvq46g .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-Y4UarbEHJEpvq46g .arrowheadPath{fill:#333333;}#mermaid-svg-Y4UarbEHJEpvq46g .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-Y4UarbEHJEpvq46g .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-Y4UarbEHJEpvq46g .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-Y4UarbEHJEpvq46g .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-Y4UarbEHJEpvq46g .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-Y4UarbEHJEpvq46g .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-Y4UarbEHJEpvq46g .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-Y4UarbEHJEpvq46g .cluster text{fill:#333;}#mermaid-svg-Y4UarbEHJEpvq46g .cluster span{color:#333;}#mermaid-svg-Y4UarbEHJEpvq46g div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-Y4UarbEHJEpvq46g .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-Y4UarbEHJEpvq46g rect.text{fill:none;stroke-width:0;}#mermaid-svg-Y4UarbEHJEpvq46g .icon-shape,#mermaid-svg-Y4UarbEHJEpvq46g .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-Y4UarbEHJEpvq46g .icon-shape p,#mermaid-svg-Y4UarbEHJEpvq46g .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-Y4UarbEHJEpvq46g .icon-shape .label rect,#mermaid-svg-Y4UarbEHJEpvq46g .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-Y4UarbEHJEpvq46g .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-Y4UarbEHJEpvq46g .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-Y4UarbEHJEpvq46g :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 企业用户
门户 / IM / OA
企业 AI 网关
知识助手服务
权限与租户上下文
RAG 检索服务
向量库
文档中心 / FAQ / 制度库
质量评估与引用校验
人工兜底 / 专家转接
观测与治理平台
Trace / Quality / Cost / Audit
这张图突出的是业务边界:企业知识助手真正的核心不是模型,而是"权限上下文 + 知识来源 + 引用校验 + 人工兜底"的组合。
场景二:电商客服与人工坐席协同
特点是链路里有强业务目标,例如转人工率、首响时长、问题解决率、退款成功率。这里不能只看模型质量,必须看业务结果。
建议重点关注:
intent、tool_success_rate、refund_workflow_successavg_tokens_per_session、cost_per_resolved_ticketcsat、escalation_rate、business_sla_breach
落地关键点:
- 每次工具调用都要挂 trace,尤其是库存、物流、退款接口。
- 告警必须关联业务结果,例如"退款工具成功率下降导致转人工率上升"。
- Feature Flag 要能按客服场景灰度切换模型和 Prompt。
对应的业务架构图如下:
#mermaid-svg-PfIbldhebztUhPPT{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-PfIbldhebztUhPPT .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-PfIbldhebztUhPPT .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-PfIbldhebztUhPPT .error-icon{fill:#552222;}#mermaid-svg-PfIbldhebztUhPPT .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-PfIbldhebztUhPPT .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-PfIbldhebztUhPPT .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-PfIbldhebztUhPPT .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-PfIbldhebztUhPPT .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-PfIbldhebztUhPPT .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-PfIbldhebztUhPPT .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-PfIbldhebztUhPPT .marker{fill:#333333;stroke:#333333;}#mermaid-svg-PfIbldhebztUhPPT .marker.cross{stroke:#333333;}#mermaid-svg-PfIbldhebztUhPPT svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-PfIbldhebztUhPPT p{margin:0;}#mermaid-svg-PfIbldhebztUhPPT .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-PfIbldhebztUhPPT .cluster-label text{fill:#333;}#mermaid-svg-PfIbldhebztUhPPT .cluster-label span{color:#333;}#mermaid-svg-PfIbldhebztUhPPT .cluster-label span p{background-color:transparent;}#mermaid-svg-PfIbldhebztUhPPT .label text,#mermaid-svg-PfIbldhebztUhPPT span{fill:#333;color:#333;}#mermaid-svg-PfIbldhebztUhPPT .node rect,#mermaid-svg-PfIbldhebztUhPPT .node circle,#mermaid-svg-PfIbldhebztUhPPT .node ellipse,#mermaid-svg-PfIbldhebztUhPPT .node polygon,#mermaid-svg-PfIbldhebztUhPPT .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-PfIbldhebztUhPPT .rough-node .label text,#mermaid-svg-PfIbldhebztUhPPT .node .label text,#mermaid-svg-PfIbldhebztUhPPT .image-shape .label,#mermaid-svg-PfIbldhebztUhPPT .icon-shape .label{text-anchor:middle;}#mermaid-svg-PfIbldhebztUhPPT .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-PfIbldhebztUhPPT .rough-node .label,#mermaid-svg-PfIbldhebztUhPPT .node .label,#mermaid-svg-PfIbldhebztUhPPT .image-shape .label,#mermaid-svg-PfIbldhebztUhPPT .icon-shape .label{text-align:center;}#mermaid-svg-PfIbldhebztUhPPT .node.clickable{cursor:pointer;}#mermaid-svg-PfIbldhebztUhPPT .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-PfIbldhebztUhPPT .arrowheadPath{fill:#333333;}#mermaid-svg-PfIbldhebztUhPPT .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-PfIbldhebztUhPPT .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-PfIbldhebztUhPPT .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-PfIbldhebztUhPPT .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-PfIbldhebztUhPPT .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-PfIbldhebztUhPPT .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-PfIbldhebztUhPPT .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-PfIbldhebztUhPPT .cluster text{fill:#333;}#mermaid-svg-PfIbldhebztUhPPT .cluster span{color:#333;}#mermaid-svg-PfIbldhebztUhPPT div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-PfIbldhebztUhPPT .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-PfIbldhebztUhPPT rect.text{fill:none;stroke-width:0;}#mermaid-svg-PfIbldhebztUhPPT .icon-shape,#mermaid-svg-PfIbldhebztUhPPT .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-PfIbldhebztUhPPT .icon-shape p,#mermaid-svg-PfIbldhebztUhPPT .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-PfIbldhebztUhPPT .icon-shape .label rect,#mermaid-svg-PfIbldhebztUhPPT .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-PfIbldhebztUhPPT .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-PfIbldhebztUhPPT .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-PfIbldhebztUhPPT :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 消费者
App / 小程序 / Web 客服
客服 BFF / 网关
智能客服编排服务
意图识别 / 对话状态
知识库问答
工具调用层
订单系统
库存系统
物流系统
退款系统
人工坐席工作台
质量评估 / SLA / 满意度
观测与告警平台
Trace / Outcome / Cost / Routing
这张图强调的不是"接了多少系统",而是客服业务里存在一条非常明确的结果链路:问题识别、知识回答、工具执行、人工兜底和满意度回写。
场景三:多区域、多模型路由平台
特点是模型供应商多、价格波动、区域延迟差异、合规要求高。问题不只是"哪个模型最好",而是"在某个区域、某类用户、某个成本阈值下哪个组合最优"。
建议重点关注:
route_reason、provider_region、fallback_countcost_per_1k_tokens、effective_latency_msquality_score_by_model、compliance_policy_hit
落地关键点:
- 路由决策必须是控制面输出,而不是散落在业务代码的
if-else。 - trace 中必须保留候选模型、最终模型和切换原因。
- 所有灰度、A/B、降级动作都要与 Feature Flag 事件关联。
对应的系统架构图如下:
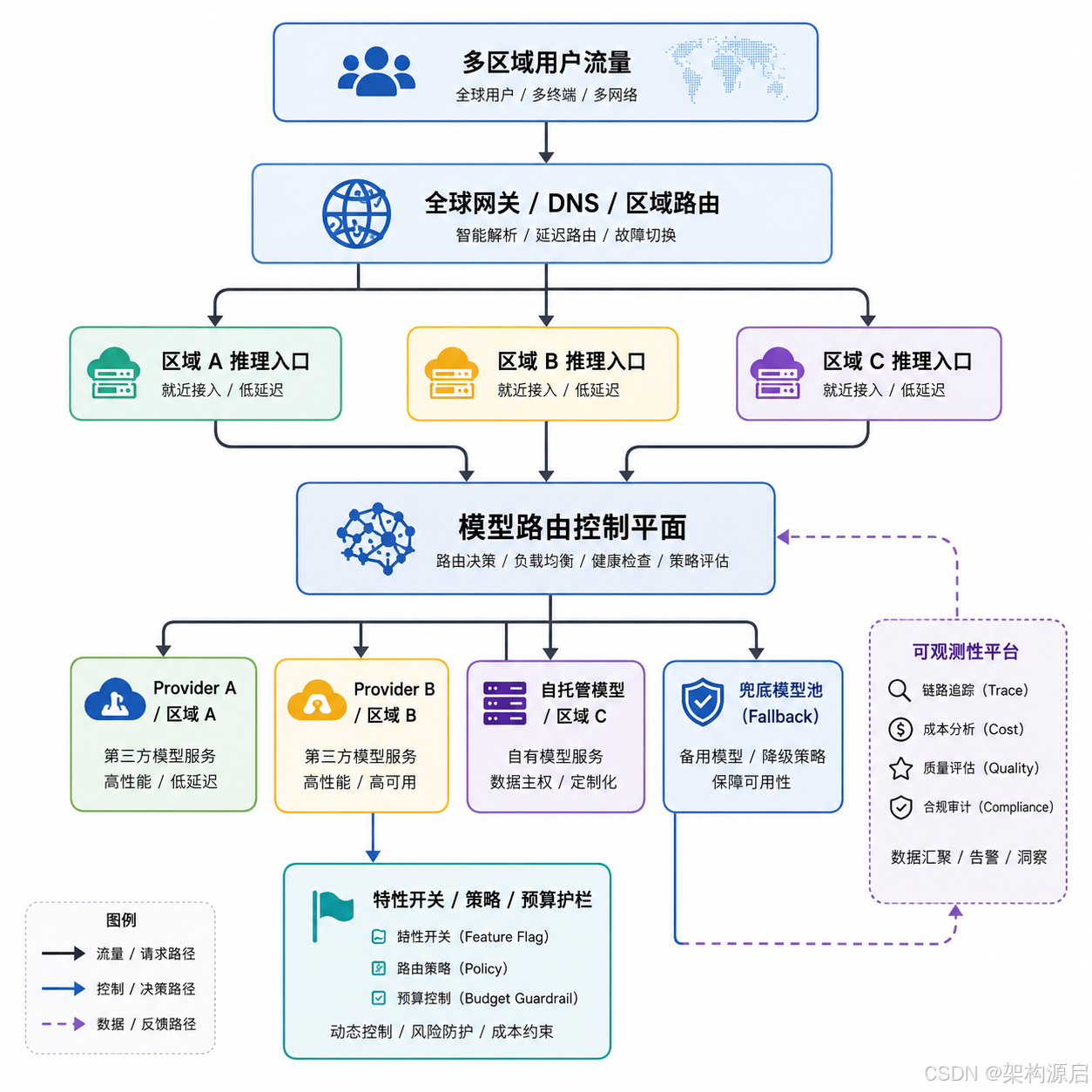
这张图体现的是平台型场景的关键矛盾:路由并不是静态配置,而是受区域、成本、质量、预算、合规和降级策略共同驱动的动态决策系统。
⑥ 推荐的落地判断标准
判断一套架构是否真的能在复杂系统中落地,不要只看"有没有 dashboard",而要看下面这些能力是否可被持续验证:
| 能力 | 建议目标 |
|---|---|
| 关键 AI 路径 trace 覆盖率 | >= 95% |
| Prompt / 检索 / 模型版本可追溯率 | >= 99% |
| 质量异常发现时延 | < 10 分钟 |
| 成本归因覆盖率 | >= 90% |
| 异常样本召回率 | >= 90% |
| 人工排障时间缩短 | 至少下降 50% |
🚀 八、实施指南与最佳实践
① 渐进式实施路线
在生产系统里,不建议一步到位堆满所有能力,更推荐下面这条五阶段路线。它的核心不是"逐步加工具",而是"逐步补齐系统解释能力"。
-
阶段 0:定义统一语义模型
- 先定义 trace、metrics、logs、evaluation 的字段规范。
- 明确哪些字段是低基数、哪些字段只能进 traces、哪些字段必须脱敏。
- 统一
prompt_template_id、model_version、knowledge_base_id、business_outcome等关键字段命名。
-
阶段 1:打通最小闭环
- 在网关、Spring AI 服务、Collector 和三大后端之间打通 OTLP。
- 先拿到根 trace、模型调用时延、Token 用量、错误率和核心业务结果。
- 这一步只解决"看得见",不要急着追求"全智能分析"。
-
阶段 2:补齐 RAG 与 Tool Calling 可解释性
- 增加检索、重排、工具调用和评估 span。
- 开始采集文档召回、工具成功率、上下文长度、评估分数。
- 让排障能够回答"错在检索、路由、工具还是模型"。
-
阶段 3:引入治理控制面
- 接入 OpenFeature 或等价的 Feature Flag 平台。
- 让模型切换、灰度、Prompt 版本发布、回滚和实验组划分可审计。
- 把 deploy event、config change 和 trace 关联起来。
-
阶段 4:建立质量与成本闭环
- 在线评估、离线回放、人工标注和用户反馈统一回写。
- 做按场景、租户、模型、模板的质量和成本归因。
- 告警从基础设施视角升级到"质量 + 成本 + 业务结果"视角。
② 复杂系统中的关键实践
这一节可以理解为"复杂系统里最容易做错的五个地方"。
-
把 Prompt、模型和知识库都视为"版本化运行时资产"
- 在 AI 系统里,真正频繁变化的往往不是 Java 代码,而是 Prompt、知识库和模型路由。版本如果不进 trace,出问题时几乎无法回溯。
-
让业务指标成为第一层告警对象
- 比如"转人工率升高""问题解决率下降"通常比"CPU 飙高"更早说明 AI 系统失效。因为用户感知到的是结果变差,而不是技术栈某个数字波动。
-
控制高基数字段进入指标系统
- 用户 ID、session ID、doc IDs、原始 prompt 这类字段看上去信息量很大,但直接进入指标标签会迅速把系统拖垮。它们更适合进入 trace 或结构化日志。
-
把脱敏放在采集链路前段
- 复杂系统里最危险的做法,是先把原始 prompt、召回片段和用户输入全量落库,再想着后面清洗。正确做法是尽量在应用出口、sidecar 或 Collector 前段就完成裁剪与脱敏。
-
保留部署、配置和实验事件
- 大量 AI 事故并不是模型本身退化,而是 Prompt、Flag、Retriever 参数或知识库切换引入的回归。如果这些事件没有进入观测链路,团队最终只能靠猜。
③ 常见落地难点与对策
| 难点 | 本质问题 | 对系统设计的启示 |
|---|---|---|
| 指标爆炸 | 高基数字段直接进 metrics | 观测设计要先考虑基数与存储,再考虑展示 |
| 追到模型但追不到业务 | 技术打点和业务事件分离 | trace_id 必须贯穿订单、会话、工单、反馈等业务实体 |
| 发现问题但解释不了 | 没有评估闭环 | 质量信号必须和执行链路一起建模 |
| 告警太吵 | 规则只看基础设施波动 | 告警必须结合质量和业务结果做二次判定 |
| 成本失控 | 只记总账,不记归因 | 成本观测必须绑定租户、场景、模型与缓存策略 |
| 灰度不可控 | 模型切换分散在代码中 | 路由与开关必须回收到统一控制面 |
从架构角度总结,这些问题其实都指向同一件事:AI 可观测性不是监控补丁,而是系统建模问题。
💡 九、未来发展趋势
① 2026 年值得关注的真实趋势
真正值得架构师关注的,不是夸张的"全自动 AI 运维",而是下面这些已经在持续落地的趋势:
-
从模型可观测性走向系统可观测性
- 重点不再是单次 LLM 调用,而是整个 AI 请求图,包括检索、路由、工具、评估和业务结果。
-
评估信号并入主观测面
groundedness、relevance、safety、business outcome会逐步成为和 latency、error rate 同级的核心信号。
-
控制面与观测面深度联动
- Feature Flag、Prompt Registry、Model Registry、Policy 引擎会和 trace 直接关联,形成可审计的运行时决策链。
-
eBPF 与应用语义观测融合
- 系统时延、网络行为、运行时队列等待会越来越多地由 eBPF 类工具补盲,但业务语义仍然需要应用层显式建模。
-
AI 可观测性 schema 逐步收敛
- OpenTelemetry 的 GenAI 语义、OpenFeature 的事件映射、OpenInference 一类补充规范会继续推动跨框架、跨供应商的字段统一。
② 对架构设计的直接影响
这些趋势会直接推动系统设计发生三种变化:
-
平台团队需要建设统一语义层
- 没有统一 schema,后续任何平台化都会碎片化。
-
业务团队需要显式建模"质量"和"结果"
- 只把 AI 当成一个 RPC 调用已经不够,必须把评估和业务 outcome 一起纳入设计。
-
治理能力必须前置
- Prompt 版本、模型路由、实验分流、数据脱敏、合规审计,都会从"上线后补"变成"系统设计时就必须存在"。
如果再往前看一步,未来架构的竞争点也会越来越明确:
- 不是谁接入的模型更多,而是谁的运行时更可解释。
- 不是谁的 dashboard 更多,而是谁能把质量、成本和治理动作连成闭环。
- 不是谁打点更细,而是谁能用一致语义支撑长期演进。
🎯 总结
2026 年真正成熟的 AI 可观测性,不再是"给模型调用加几个指标",而是一套围绕运行时控制面构建的系统工程能力。它要求你同时看见请求链路、质量评估、模型路由、成本归因、治理事件和业务结果,并且让这些信号在同一个 trace_id 上汇合。
如果你希望这套架构能够在复杂系统中落地,最重要的不是先上多少工具,而是先把三件事做对:
- 统一语义模型。
- 打通请求到结果的端到端追踪。
- 把评估、成本和治理事件纳入主观测面。
做到这三点之后,Spring AI 才能真正从"能跑起来"走向"能运营、能治理、能持续优化"。

让AI应用更透明、更可控、更可运营。