只要神经网络输出的是每个动作的执行概率,通过梯度上升/下降进行参数更新,那就是策略梯度算法

策略梯度定理(Policy Gradient Theorem) ,也通常被称为 REINFORCE 算法的核心公式。
公式拆解:数学符号与代码的映射
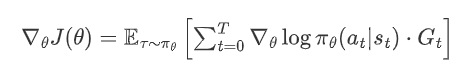
-
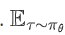 (求期望):
(求期望):-
数学含义: 按照当前策略 \pi_\theta 去环境中玩游戏,采样出很多条轨迹 \tau,然后求平均。
-
代码实现: 在代码中,这体现为我们让智能体在环境中跑完一整局游戏,收集到一个批次(Batch)的数据,最后在算 Loss 时调用
torch.mean()取平均。
-
-
G_t (累积回报):
-
数学含义: 从时间步 t 开始,直到游戏结束,未来所有奖励的总和(带衰减)。
-
代码实现: 用一个从后往前的
for循环,倒序累加真实的reward。
-
-
\log \pi_\theta(a_t|s_t) (对数概率):
-
数学含义: 在状态 s_t 下,网络决定采取动作 a_t 的概率,再取自然对数。
-
代码实现:
torch.log( policy_net(state) )。
-
-
\nabla_\theta (求梯度):
-
数学含义: 对参数 \theta 求偏导,指示参数更新的方向。
-
代码实现: 代码里根本不需要你手写微积分,只需要一句极其简单的
loss.backward(),PyTorch 就会自动顺着计算图把这部分算出来。
-
二、 代码实现(REINFORCE 更新逻辑)
python
import torch
import torch.nn.functional as F
# 假设这是一局游戏打完后,我们收集到的完整轨迹数据 (Trajectory)
# 长度为 T (例如 T=4)
reward_list = [1.0, 1.0, 1.0, -10.0] # 每一步环境给的真实瞬时奖励 r_t
state_list = [...] # 每一步的环境状态 s_t
action_list = [0, 1, 0, 1] # 每一步智能体实际做出的动作 a_t
gamma = 0.99 # 折扣因子
def update_policy(policy_net, optimizer):
# ---------------------------------------------------------
# 1. 计算公式右侧的 G_t (累积折扣回报)
# 技巧:由于计算 t 时刻的回报需要用到 t+1 时刻的回报,所以必须"倒序计算"
# ---------------------------------------------------------
G_t_list = []
G = 0 # 游戏结束后的未来回报是 0
for r in reversed(reward_list):
G = r + gamma * G # G_t = r_t + gamma * G_{t+1}
G_t_list.insert(0, G) # 把算好的 G 塞回列表头部,恢复正序排列
# 将 G_t 转换为 PyTorch 张量,准备参与神经网络的计算
G_t_tensor = torch.tensor(G_t_list, dtype=torch.float32)
# ---------------------------------------------------------
# 2. 计算公式中间的 \log \pi_\theta(a_t|s_t)
# ---------------------------------------------------------
states_tensor = torch.tensor(state_list, dtype=torch.float32)
actions_tensor = torch.tensor(action_list).view(-1, 1) # 重塑为列向量方便提取
# 网络前向传播,算出这批状态下,所有动作的概率分布
# 假设输出:[[0.8, 0.2], [0.3, 0.7], ...]
all_action_probs = policy_net(states_tensor)
# 核心:用 gather 提取出"实际执行的那个动作"对应的概率
action_probs = all_action_probs.gather(1, actions_tensor).squeeze()
# 取对数,完美对应公式里的 \log \pi_\theta
log_probs = torch.log(action_probs)
# ---------------------------------------------------------
# 3. 缝合公式,计算最终的 Loss,并触发 \nabla_\theta
# ---------------------------------------------------------
# 公式:\sum [ \log \pi_\theta * G_t ]
# 注意两个细节:
# 第一:PyTorch 的优化器默认是"梯度下降(求极小值)",但策略梯度是要"最大化期望收益 J(\theta)"!
# 所以我们必须在公式前面强行加一个负号 (-),把最大化问题变成最小化问题。
# 第二:公式里的期望 \mathbb{E} 在代码中体现为对整个 Batch 的数据求平均 torch.mean()
loss = -torch.mean(log_probs * G_t_tensor)
# 清空优化器上一步残留的旧梯度
optimizer.zero_grad()
# 魔法发生的地方:这一步等价于公式最外层和最里层的 \nabla_\theta!
# PyTorch 会自动顺着 log_probs 追溯到 policy_net 里的每一个权重参数,算出更新方向
loss.backward()
# 执行参数更新:\theta \leftarrow \theta + \alpha \nabla_\theta J(\theta)
optimizer.step()