一笔账,惊出一身冷汗
2022年某电商平台做大促压测,下单高峰期并发数突破10万QPS,数据库响应时间飙升至3秒以上,订单系统几近崩溃。排查原因:团队为了追求"现代感",把订单核心库从PostgreSQL迁到了MongoDB,理由是"文档型更灵活,水平扩展更方便"。
结果呢?促销期间,一笔支付扣款成功、订单状态却没更新,出现了"钱扣了但订单还在待支付"的脏数据。根本原因:MongoDB当时的多文档事务支持有限,而订单场景天然需要跨表的原子操作。团队不得不在凌晨紧急回滚,代价惨重。
这个故事不是在黑MongoDB------MongoDB是优秀的数据库。问题在于,选型从来不是"哪个更先进",而是"哪个更适合这个问题"。
两套哲学,两种答案
关系型数据库(RDBMS)和非关系型数据库(NoSQL)从设计哲学上就走了两条路:
RDBMS 的核心信仰是 ACID------原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。你可以把它理解为"宁可慢,不出错"。一旦事务提交,数据必然正确;一旦失败,必然完整回滚。这套机制让 MySQL、PostgreSQL 成为金融交易、电商订单、库存管理等场景的默认选择。
NoSQL 的核心信仰是 BASE------基本可用(Basically Available)、软状态(Soft State)、最终一致性(Eventually Consistent)。它的出发点是:在分布式环境下,强一致性代价太高,很多业务可以接受"稍后一致"。换取的是:超高写入吞吐、水平扩展能力、灵活的数据模型。
这不是谁优谁劣,是 CAP 定理在现实中的取舍------一致性(Consistency)、可用性(Availability)、分区容忍性(Partition Tolerance),三者最多只能同时满足两个。

真正决定选型的,是这三个问题
问题一:你的业务能接受"暂时不一致"吗?
这是最关键的问题,没有之一。
场景 A: 用户A向用户B转账100元。这个操作涉及两步:A账户扣款、B账户入账。如果系统在第一步完成后崩溃,钱凭空消失------这不可接受。这种场景必须用关系型数据库,ACID事务是唯一保障。
场景 B: 用户发了一条微博,粉丝们的时间线需要同步。系统在高峰期处理几百万条推送,允许某个粉丝晚几秒看到内容。这种场景可以接受最终一致性,NoSQL的高吞吐写入更合适。
Instagram 在早期使用 PostgreSQL 支撑其核心业务(用户数据、照片元信息、社交关系),但对于"用户动态 Feed"这类高并发读写、可接受略微延迟的场景,引入了 Cassandra 和 Redis 做分层缓存。这种混用策略正是行业主流------不是非此即彼,而是各司其职。
问题二:你的数据结构稳定吗?
关系型数据库要求预先定义 Schema------字段名、字段类型、表关系必须提前设计好。这带来了严格的约束,也带来了可预期性:每一行数据都符合同一结构,JOIN 查询、复杂报表成为可能。
非关系型(尤其是文档型,如 MongoDB)允许同一集合中的文档有不同字段。对于那些数据结构频繁变化的场景------比如用户行为日志、IoT 设备上报数据、内容管理系统的自定义字段------文档型数据库的灵活性能大幅降低开发成本。
一个实际决策参考:
- 字段结构固定 → 关系型
- 字段经常新增/变化,不同记录结构差异较大 → 文档型 NoSQL
- 数据主要是 key-value 对,读取频繁 → Redis 等键值型
- 需要分析复杂多跳关系(如社交图谱、推荐系统) → 图数据库(如 Neo4j)
问题三:你的规模和扩展方向是什么?
关系型数据库的扩展主要靠"垂直扩展"------换更强的机器,加更多内存和CPU。单机 PostgreSQL 在优化得当的情况下可以支撑 TB 级数据,但到一定量级后,垂直扩展的成本曲线会急速上升。
NoSQL 的核心优势之一是"水平扩展"------通过分片(Sharding)将数据分散到多台机器,理论上可以无限横向扩展。Cassandra 的节点扩展尤其平滑:向集群中添加节点,无需重启服务,数据自动均衡。腾讯云 NoSQL 团队的测试数据显示,MongoDB 6.0 的 Balance 数据迁移效率比 5.0 版本提升了 30%-45%。
但注意:水平扩展的代价是跨节点事务变得极其复杂。许多 NoSQL 数据库为了保持扩展性,放弃了跨节点的强事务支持。
一个被误解的陷阱:NewSQL 不是万能药
近年来出现了 TiDB、CockroachDB 等"NewSQL"数据库,承诺"既有 ACID 事务,又能水平扩展"。听起来两全其美------但现实是:分布式事务的性能开销是真实的。
TiDB 在事务提交时需要通过 Raft 协议在多节点间达成一致,延迟通常比单机 MySQL 高出数倍。对于极致低延迟的场景,这个开销不可忽视。NewSQL 适合的是:数据量已经超过单机上限、但业务又强依赖事务一致性的场景,比如中型银行核心系统、大型电商订单中心。它不是"用了就万事大吉"的银弹。
选型决策树(实战版)
markdown
你的业务场景是什么?
│
├── 涉及资金/库存/合同等,数据错了会有损失
│ └── → 关系型数据库(MySQL / PostgreSQL)
│
├── 高并发写入,数据结构灵活,允许最终一致
│ ├── 文档型数据:MongoDB
│ ├── 时序数据 / IoT:InfluxDB / TimescaleDB
│ └── 纯键值高速读写:Redis
│
├── 超大规模,读写分散,社交/推荐
│ └── 宽列存储:Cassandra / HBase
│
└── 复杂关系查询,多跳遍历
└── 图数据库:Neo4j / Amazon Neptune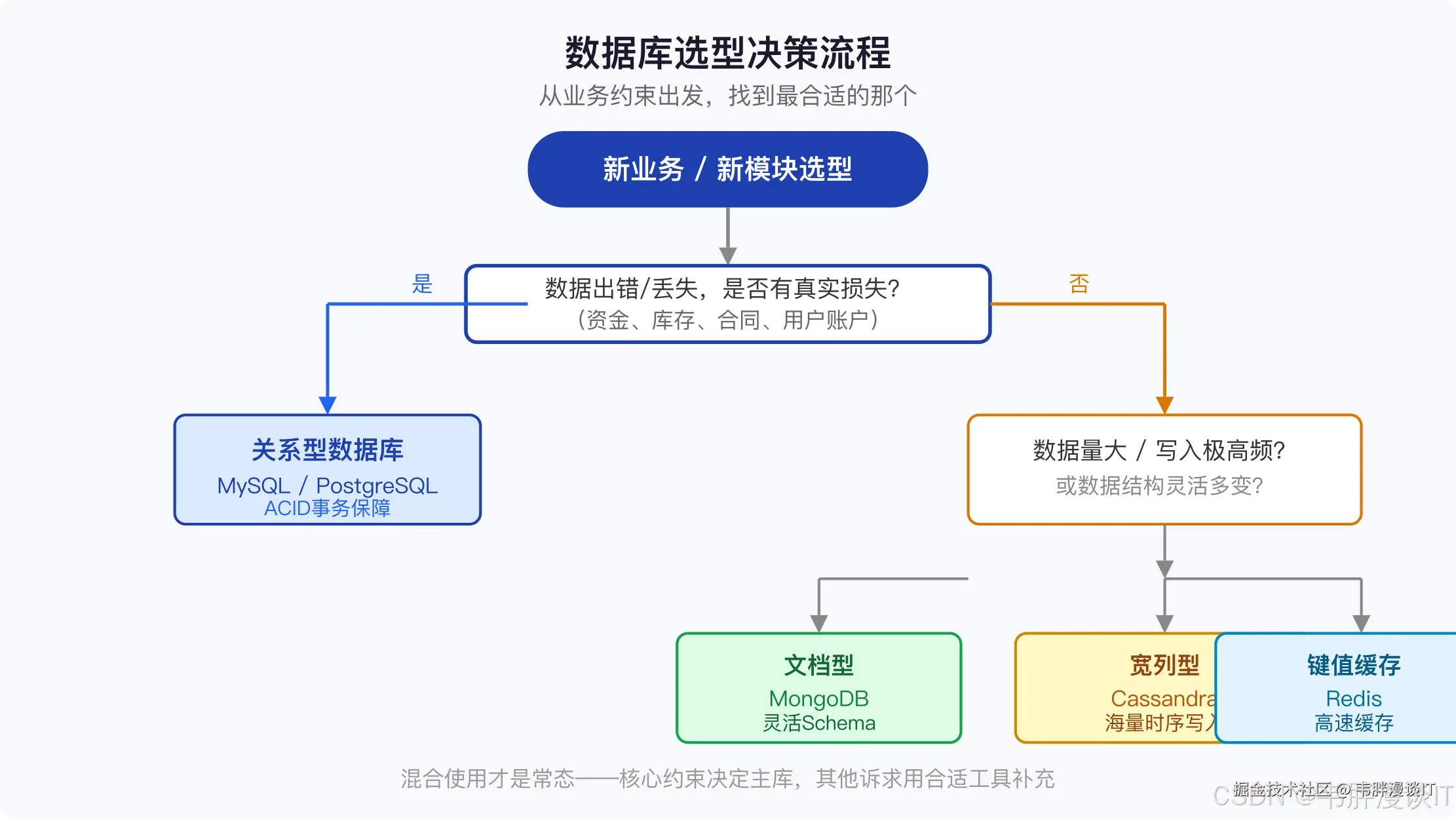
落地建议:混合使用才是常态
真实的生产系统,几乎没有"只用一种数据库"的。更常见的架构是:
- PostgreSQL / MySQL 存核心业务数据(订单、账户、商品)
- Redis 做热点数据缓存、Session 管理、计数器
- MongoDB / Elasticsearch 存日志、行为数据、全文检索
- Cassandra 处理时序数据、消息历史等海量追加写入
选型的本质不是选出"最好的数据库",而是识别你的业务问题中最核心的约束:如果数据不一致,代价是什么?如果扩展不够,代价是什么? 把代价最高的那个问题作为主要约束,再选对应的数据库。
一笔账、一个错误的选型,可能让你大促当天在凌晨四点盯着监控屏幕发抖。而一个从问题出发、匹配业务约束的选型,才是真正的技术落地。