真人分割线:
上面的那个文章基本上还是以科普和简单的架构为主,很多都是生成出来的结论。但是知识主要的应用人员还是要靠人来做,那么下面基本上都是我自己的解析和理解。
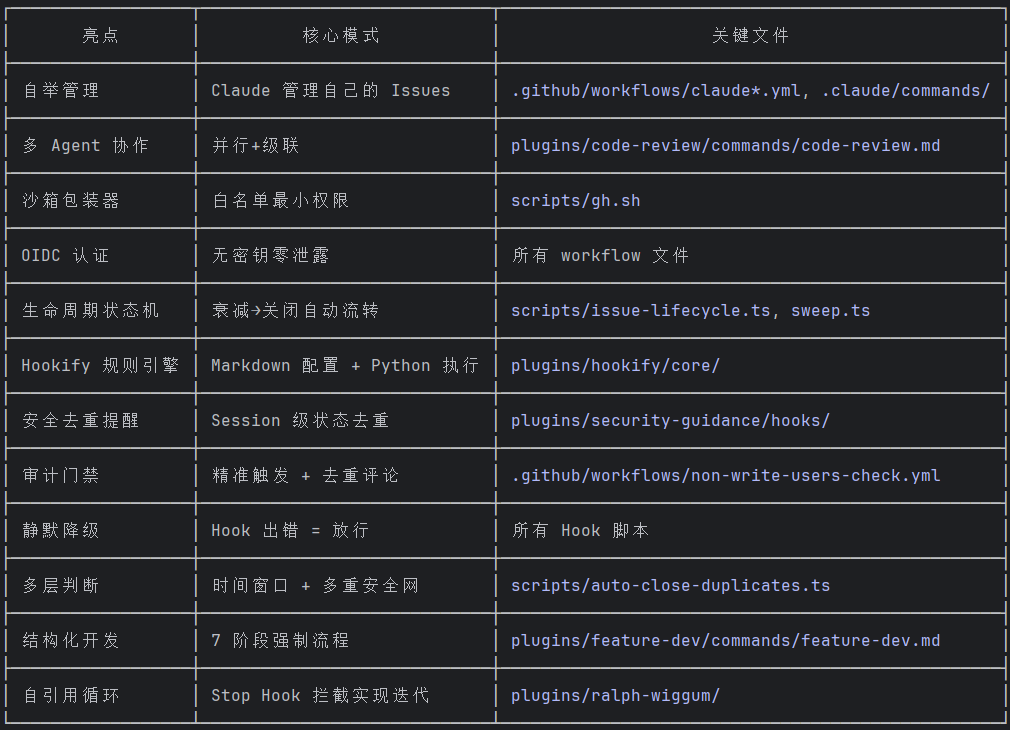
设计亮点-简单理解:
我就直接写一个表格放这里了,然后下面我们就每个按照源码来深度看下到底是怎么实现的。
夹带一个小私货是我自己写的流程图的小网页,但是已经完全开源了,直接点击就可以用。只是因为之前用别的哪些不是很好用,自己写了一个。下面的那个是git的代码链接。
https://gitee.com/art-boat/yi-process.git
自举管理
实现原理:
实现分为四个层级 触发层、命令层级、权限控制层、执行层四层架构
但是这个主要是和github进行联动,在我们实际的操作过程中其实没有太重要,所以这里先跳过。我最后的终极目标是通过学习claude的原理来做其他的agent以及使用claude的sdk来构建其他的agent。
多Agent协作:
设计亮点:
多 Agent 协作有 7 个精妙的设计模式,分布在三个命令中。逐一拆解。
我觉得通过设计让agent协作然后向用户提出了关键性的问题这一步就很重要也很妙。
就比如说在claude code在进行开发的时候。
这是我自己总结的一个在Coding的时候的流程图
代码与业务理解:
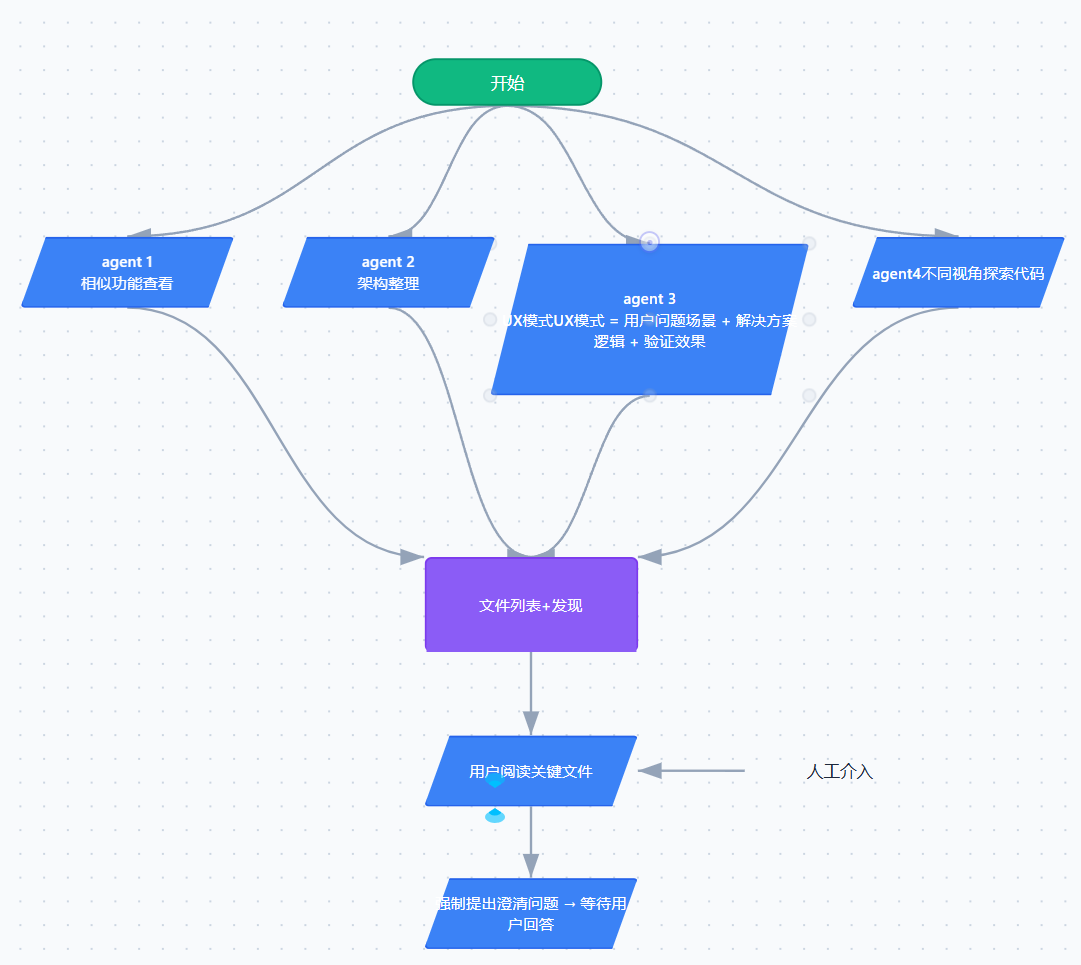
代码方案构建以及方案抉择:
7中设计模式:
模式 1:信息压缩传递(Producer → Consumer)
实现位置:dedupe.md 第 2-3 步
文件位置:claude-code\.claude\commands\dedupe.md
Step 2: 1 个 Agent 读取 Issue,输出 "摘要"
Step 3: 5 个 Agent 用这份 "摘要" 去搜索
为什么不是每个 Agent 自己读 Issue?
如果 5 个 Agent 各自读一遍原始 Issue → 5 次 API 调用 + 每个 Agent 上下文窗口被原始 Issue
正文占满。而压缩成一页摘要后再分发 → 每个搜索 Agent 的上下文窗口更轻,可以装更多搜索结果。
这是「信息蒸馏」思想:上一级 Agent 把原始信息提炼为高密度摘要,下一级 Agent
基于摘要工作,避免在整个链路中搬运原始数据。
关键机制:主 Claude 作为编排者,它调用 Agent → 收到 Agent 的文本返回值 → 把这段文本写入下一批 Agent 的
prompt。这就是全部。
实现思路:
为什么这构成了一个"模式"
单独看每一步都是普通的 Agent 调用,但三步组合起来形成了一个信息精炼管道:
单独看每一步都是普通的 Agent 调用,但三步组合起来形成了一个信息精炼管道:
原始 Issue (可能 3000 字,包含截图描述、日志、情绪化表达)
│
▼ Step 2: Summary Agent
│ 输入: 完整 Issue 正文
│ 输出: "用户执行 /commit 后 claude 崩溃,Windows 11,v2.1.150"
│ ── 一句话蒸馏出 3 个搜索锚点:功能名、症状、环境
│
▼ Step 3: 5× Search Agent
│ 输入: 摘要 (50 字) + 搜索指令
│ 输出: 各自返回候选 Issue 列表
│
▼ Step 4: Filter Agent
输入: 原始 Issue + 所有候选
输出: 确认的重复项
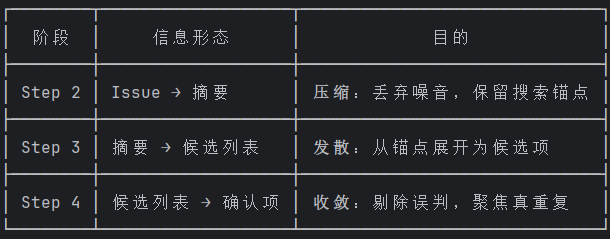
管道中每一步的输出都是下一步的输入,且在每一步中信息的形态在变化:
做压缩后:
1 个 Agent × 3000 字输入 = 3000 字 (生成摘要)
5 个 Agent × 50 字输入 + 1000 字结果 = 1050 字/Agent
但更重要的是质量层面------原始 Issue 中大量的「背景故事」「已经尝试过的方案」「情绪表达」对搜索重复 Issue
来说是噪音。摘要 Agent 提取出的锚点让搜索 Agent 的注意力集中在可搜索的关键信号上。
在 code-review 中的同样模式
code-review.md 里同一个模式出现得更复杂:
Step 2: Haiku Agent → 返回 CLAUDE.md 文件列表
Step 3: Sonnet Agent → 返回 PR 变更摘要
Step 4: 4 个 Agent 各自拿到 {CLAUDE.md 列表 + PR 摘要} → 开始审查
Step 5: 验证 Agent 拿到 {PR 摘要 + 具体问题描述} → 验证
这里生产者和消费者之间传递的不是一份摘要,而是一个上下文包:
生产者 (Step 2 + 3) 产出上下文包:
┌────────────────────────────┐
│ CLAUDE.md 文件列表 │
│ PR 摘要 │
│ PR 标题 + 描述 │
└────────────────────────────┘
│
▼ 分发给消费者
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Sonnet 合规 A │ │ Sonnet 合规 B │ │ Opus Bug C │ ...
└───────────────┘ └───────────────┘ └───────────────┘
上下文包的设计是:每个消费者都拿到完全相同的上下文包,但各自的 prompt
要求它们关注不同的维度。这样既保证了信息一致性(不会出现 Agent A 看到的上下文和 Agent B
不同),又保证了关注点多样性。
具体源码:
实现依赖的核心能力
整个模式只依赖一个 Claude Code 的基础能力:Agent 工具返回文本结果。编排者(主 Claude)调用 Agent
后得到一段文本,然后它可以把这段文本写入下一个 Agent 的 prompt 参数。
用伪代码表示就是:
Step 2: 生产者
summary = agent(
prompt="View issue #61590 and return a one-paragraph summary"
)
summary = "用户反馈 /commit 命令在 Windows 上崩溃..."
Step 3: 消费者(5 个并行)
results = parallel_agents([
agent(prompt=f"Search for duplicates of this issue: {summary}. Use keywords: commit crash"),
agent(prompt=f"Search for duplicates of this issue: {summary}. Use keywords: windows error"),
agent(prompt=f"Search for duplicates of this issue: {summary}. Use keywords: /command failure"),
agent(prompt=f"Search for duplicates of this issue: {summary}. Search by symptom description"),
agent(prompt=f"Search for duplicates of this issue: {summary}. Search recent regressions"),
])
Step 4: 消费者(过滤器)
verified = agent(
prompt=f"Original issue: <full text>. Found these candidates: {results}. Filter out false positives."
)
没有任何中间存储、消息队列、状态管理------所有信息流都在 prompt 参数和返回值之间完成。这使得整个流程完全无状态、天然
可追溯(每一步的输入输出都在对话记录里),不需要任何基础设施。
原理解析:
这是「生产者→消费者→过滤器」管道的全部原始代码:
我在上面也加上了对应的中文注释:
文件:.claude/commands/dedupe.md(全文)
工具白名单:Claude 只能调用这两个脚本,不能做任何其他操作
allowed-tools: Bash(./scripts/gh.sh:*), Bash(./scripts/comment-on-duplicates.sh:*)
description: Find duplicate GitHub issues
Find up to 3 likely duplicate issues for a given GitHub issue.
To do this, follow these steps precisely:
═══════════════════════════════════════════════════════
第 1 步:前置守卫 Agent
用一个轻量 Agent 快速判断"值不值得继续往下走"
═══════════════════════════════════════════════════════
- Use an agent to check if the Github issue (a) is closed,
(b) does not need to be deduped, or (c) already has a
duplicates comment that you made earlier. If so, do not proceed.
═══════════════════════════════════════════════════════
第 2 步:【生产者 Agent】
输入:原始 Issue 正文(可能几千字,包含日志、截图描述、情绪表达)
输出:一句话摘要(只保留可搜索的关键信号)
这一步的本质是"信息蒸馏"------丢弃噪音,提炼锚点。
如果不做压缩,5 个搜索 Agent 各自要在上下文中搬运几千字的原始正文。
═══════════════════════════════════════════════════════
- Use an agent to view a Github issue, and ask the agent
to return a summary of the issue
═══════════════════════════════════════════════════════
第 3 步:【5 个并行消费者 Agent】
每个 Agent 的 prompt 中嵌入同一份摘要(来自第 2 步),
但各自使用不同的搜索关键词和策略。
关键短语:"using the summary from #1"
这就是信息传递的显式声明------主 Claude 把第 2 步 Agent 的返回文本,
直接写入第 3 步每个 Agent 的 prompt 参数中。
没有任何中间存储、消息队列或状态管理。
═══════════════════════════════════════════════════════
- Then, launch 5 parallel agents to search Github for
duplicates of this issue, using diverse keywords and
search approaches, using the summary from #1
═══════════════════════════════════════════════════════
第 4 步:【过滤器 Agent ------ 管道的最后一环】
输入:第 2 步的原始 Issue 全文 + 第 3 步 5 个 Agent 的全部搜索结果
输出:剔除误判后,确认的重复 Issue 列表
关键短语:"feed the results from #1 and #2 into another agent"
这一步同时消费前两个阶段的输出,做最终收敛。
═══════════════════════════════════════════════════════
- Next, feed the results from #1 and #2 into another agent,
so that it can filter out false positives, that are likely
not actually duplicates of the original issue. If there
are no duplicates remaining, do not proceed.
═══════════════════════════════════════════════════════
第 5 步:执行动作
确认的重复项通过安全包装脚本留言到 GitHub Issue
═══════════════════════════════════════════════════════
- Finally, use the comment script to post duplicates:
./scripts/comment-on-duplicates.sh --potential-duplicates <dup1> <dup2> <dup3>
管道的三个阶段 + 信息形态变化
用伪代码还原主 Claude 实际执行时的信息流:
═══════════════════════════════════════════════════════
阶段 1:生产 ------ 压缩
原始 Issue 可能有 3000 字,摘要压缩到 50 字
丢弃的内容:背景故事、已尝试方案、情绪表达(对搜索无用)
保留的内容:功能名、症状、环境(可搜索的关键信号)
═══════════════════════════════════════════════════════
summary = agent(
prompt="View issue #61590 and return a one-paragraph summary"
)
summary = "用户反馈 /commit 命令在 Windows 上崩溃,报错 ENOENT,v2.1.150"
═══════════════════════════════════════════════════════
阶段 2:分发 ------ 多样性发散
5 个 Agent 拿到同一份摘要,但用不同的搜索策略
核心设计:相同输入 + 不同视角 = 最大化召回率
═══════════════════════════════════════════════════════
results = parallel_agents([
agent(prompt=f"该 Issue 摘要:{summary}。用关键词 'commit crash windows' 搜索"),
agent(prompt=f"该 Issue 摘要:{summary}。用关键词 '/command 错误 ENOENT' 搜索"),
agent(prompt=f"该 Issue 摘要:{summary}。按症状描述搜索,不限关键词"),
agent(prompt=f"该 Issue 摘要:{summary}。搜索标记为 bug 的近期 Issue"),
agent(prompt=f"该 Issue 摘要:{summary}。用中文关键词 '提交 崩溃' 搜索"),
])
results = \[61200, 61500, 59876, 61200, \[\], 61200, 60123 ]
═══════════════════════════════════════════════════════
阶段 3:过滤 ------ 收敛
消费全部搜索结果的并集 + 原始 Issue 全文
逐一比对,剔除误判,只保留真正的重复项
═══════════════════════════════════════════════════════
verified = agent(
prompt=f"""
原始 Issue 全文:<Issue #61590 的完整正文>
搜索到的候选重复项:{results}
请逐一比对,剔除不相关的误判,只返回确认的重复 Issue 编号。
"""
)
verified = 61200, 59876 ← 从 6 个候选中过滤出 2 个确认项
这个模式成立的两个前提
- Agent 的返回值是纯文本------主 Claude 调用 Agent 后拿到的就是一段文本,它天然可以嵌入到下一个 Agent 的 prompt
中。这是 Claude Code 的 Agent 工具自带的能力,不需要任何额外机制。
- 主 Claude 充当编排者------它不亲自搜索,而是负责:调 Agent → 收结果 → 嵌入 prompt → 再调
Agent。整个管道的"内存"就是主 Claude 的上下文窗口,每一步的输入输出都在对话记录里,天然可追溯。
模式 2:多样性注入(Diverse Search Queries)
文件:.claude/commands/dedupe.md
allowed-tools: Bash(./scripts/gh.sh:*), Bash(./scripts/comment-on-duplicates.sh:*)
description: Find duplicate GitHub issues
Find up to 3 likely duplicate issues for a given GitHub issue.
To do this, follow these steps precisely:
- Use an agent to check if the Github issue (a) is closed,
(b) does not need to be deduped, or (c) already has a
duplicates comment that you made earlier. If so, do not proceed.
- Use an agent to view a Github issue, and ask the agent
to return a summary of the issue
═══════════════════════════════════════════════════════
【多样性注入的完整实现:就这一句话】
"launch 5 parallel agents"
→ 并行不是关键,关键是数量。1 个 Agent 的搜索策略覆盖有限,
5 个 Agent 各自从不同角度搜索,合并后召回率远超单个。
"using diverse keywords and search approaches"
→ 这是多样性注入的指令。没有规定具体用什么关键词,
而是把"如何多样化"的决策交给主 Claude 自行判断。
主 Claude 读了第 2 步的摘要后,自己拆解出 5 个搜索方向。
"using the summary from #1"
→ 5 个 Agent 共用一个压缩后的输入,但每个收到不同的搜索指令。
═══════════════════════════════════════════════════════
- Then, launch 5 parallel agents to search Github for
duplicates of this issue, using diverse keywords and
search approaches, using the summary from #1
- Next, feed the results from #1 and #2 into another agent,
so that it can filter out false positives. If there are no
duplicates remaining, do not proceed.
- Finally, use the comment script to post duplicates:
./scripts/comment-on-duplicates.sh --potential-duplicates <dup1> <dup2> <dup3>
这句话是怎么被执行出来的
整个多样性注入依赖一个事实:主 Claude 读了摘要后,自己会拆解出不同的搜索维度。用伪代码还原实际执行过程:
═══════════════════════════════════════════════════════
主 Claude 拿到第 2 步 Agent 返回的摘要:
"用户反馈 /commit 命令在 Windows 11 上崩溃,
执行后终端报 ENOENT 错误,版本 v2.1.150"
然后主 Claude 自己把这份摘要拆解为 5 个搜索方向,
每个方向侧重不同的信号维度:
═══════════════════════════════════════════════════════
Agent A:按功能名搜索
从摘要中提取 "/commit" 作为锚点
agent_a = agent(
prompt='搜索与 "/commit 命令崩溃" 相关的重复 Issue'
)
实际执行的命令:
./scripts/gh.sh search issues "/commit crash" --limit 10
Agent B:按错误特征搜索
从摘要中提取 "ENOENT" 作为锚点
agent_b = agent(
prompt='搜索与 "ENOENT 错误 崩溃" 相关的重复 Issue'
)
实际执行的命令:
./scripts/gh.sh search issues "ENOENT error crash" --limit 10
Agent C:按环境上下文搜索
从摘要中提取 "Windows" + "v2.1.150" 作为锚点
agent_c = agent(
prompt='搜索 "Windows claude-code 崩溃 v2.1.150" 相关的重复 Issue'
)
实际执行的命令:
./scripts/gh.sh search issues "Windows crash claude-code 2.1" --limit 10
Agent D:按用户症状描述搜索(不用技术术语)
用自然语言描述现象,匹配用户报告风格的 Issue
agent_d = agent(
prompt='搜索 "终端执行命令后无响应 程序退出" 相关的重复 Issue'
)
实际执行的命令:
./scripts/gh.sh search issues "terminal unresponsive command exit" --limit 10
Agent E:按时间相关性搜索
搜索最近的 regression 类型 Issue
agent_e = agent(
prompt='搜索最近一个月标记为 bug 的 "/" 命令相关 Issue'
)
实际执行的命令:
./scripts/gh.sh search issues "slash command bug" --limit 10
关键:为什么是"让 Claude 自己拆"而不是"硬编码 5 个维度"
对比两种做法:
做法 A:硬编码(如果这样做)
- Launch 5 parallel agents:
-
Agent A: search by feature name
-
Agent B: search by error code
-
Agent C: search by environment
-
Agent D: search by symptom description
-
Agent E: search by time range
做法 B:实际的做法(让 Claude 自己拆)
- Launch 5 parallel agents, using diverse keywords
and search approaches, using the summary from #1
做法 B 的优势:维度是动态的。如果摘要里没有错误码但提到了特定的 UI 界面,Claude 会自己拆出「按 UI
关键词搜索」这个维度。硬编码的维度列表无法覆盖所有 Issue 类型,但 Claude 读摘要后动态生成的维度可以。
同一个模式在 code-review 中的变体
在 code-review 中,多样性不是靠 Claude 自己拆,而是显式指定每个 Agent 的不同角色:
文件:plugins/code-review/commands/code-review.md 第 30-39 行
═══════════════════════════════════════════════════════
这里不是"让 Claude 自己拆维度",而是显式指定每个 Agent 的透镜
2 个合规 Agent + 2 个 Bug Agent,各自有不同的审查焦点
═══════════════════════════════════════════════════════
Agents 1 + 2: CLAUDE.md compliance sonnet agents
透镜:规则匹配 → "改的代码是否违反了项目规范?"
Agent 3: Opus bug agent
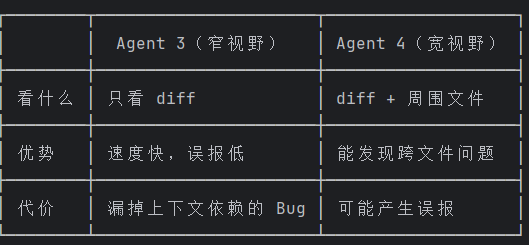
透镜:窄视野 diff → "diff 本身有没有明显错误?"
Scan for obvious bugs. Focus only on the diff itself
without reading extra context.
Agent 4: Opus bug agent
透镜:宽视野上下文 → "放进完整代码里有没有隐藏问题?"
Look for problems that exist in the introduced code.
This could be security issues, incorrect logic, etc.
两个 Agent 3 和 Agent 4 虽然都在找 Bug,但视野边界不同:
总结:
多样性注入在这个项目里有两种实现方式:

模式 3:模型分层(Model Tiering)
文件:plugins/code-review/commands/code-review.md 第 14-57 行
Provide a code review for the given pull request.
To do this, follow these steps precisely:
═══════════════════════════════════════════════════════
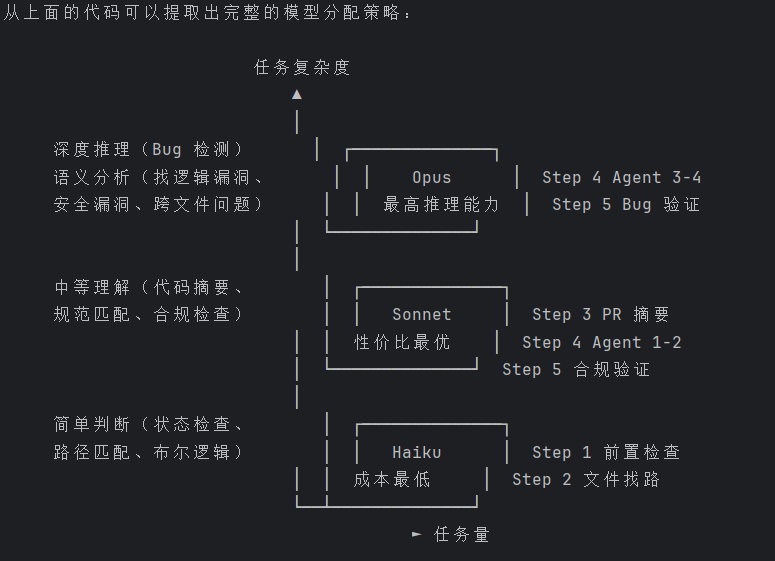
第 1 步:Haiku --- 前置检查
任务:判断 PR 状态(已关闭?草稿?已审查?)
本质是一道单选题,不需要推理能力,只需要读 API 返回值做布尔判断
选 Haiku 的原因:成本最低,速度最快,推理能力浪费在这里没意义
═══════════════════════════════════════════════════════
- Launch a haiku agent to check if any of the following are true:
-
The pull request is closed
-
The pull request is a draft
-
The pull request does not need code review (e.g. automated PR,
trivial change that is obviously correct)
- Claude has already commented on this PR
If any condition is true, stop and do not proceed.
═══════════════════════════════════════════════════════
第 2 步:Haiku --- 文件路径匹配
任务:找出变更文件所在目录的 CLAUDE.md 文件列表
本质是路径匹配题,Haiku 足够胜任
═══════════════════════════════════════════════════════
- Launch a haiku agent to return a list of file paths
(not their contents) for all relevant CLAUDE.md files including:
modified by the pull request
═══════════════════════════════════════════════════════
第 3 步:Sonnet --- 中等复杂度理解
任务:阅读 PR diff 并生成变更摘要
需要理解代码语义,但不需要深度 bug 检测
选 Sonnet 的原因:成本比 Opus 低,理解力足够做摘要
═══════════════════════════════════════════════════════
- Launch a sonnet agent to view the pull request and
return a summary of the changes
═══════════════════════════════════════════════════════
第 4 步:模型分层的最核心体现
Agents 1+2:Sonnet --- CLAUDE.md 合规检查
任务本质是"规则匹配"------拿代码去对 CLADE.md 中的每条规定
→ 模式识别题,Sonnet 足够
Agents 3+4:Opus --- Bug 检测
任务本质是"深度推理"------理解代码意图、推导执行路径、发现逻辑漏洞
→ 需要最高推理能力,上 Opus
═══════════════════════════════════════════════════════
- Launch 4 agents in parallel to independently review the changes.
Agents 1 + 2: CLAUDE.md compliance sonnet agents
Audit changes for CLAUDE.md compliance in parallel.
Agent 3: Opus bug agent (parallel subagent with agent 4)
Scan for obvious bugs. Focus only on the diff itself
without reading extra context.
Agent 4: Opus bug agent (parallel subagent with agent 3)
Look for problems that exist in the introduced code.
This could be security issues, incorrect logic, etc.
═══════════════════════════════════════════════════════
第 5 步:验证层的模型再分层
被 Agent 3/4(Opus)发现的 Bug → 用 Opus 验证(需要同等深度)
被 Agent 1/2(Sonnet)发现的合规问题 → 用 Sonnet 验证(匹配级确认即可)
核心思想:验证的深度要和发现的深度匹配。
不会用 Opus 去验证一个"import 顺序不对"的合规问题。
═══════════════════════════════════════════════════════
- For each issue found in the previous step by agents 3 and 4,
launch parallel subagents to validate the issue.
Use Opus subagents for bugs and logic issues,
and sonnet agents for CLAUDE.md violations.
- Filter out any issues that were not validated in step 5.
模型分配决策表
伪代码复现:
用伪代码还原执行时的模型分配
═══════════════════════════════════════════════════════
Step 1:Haiku 做判断题(模型参数 = haiku)
成本假设:Haiku ≈ 1/20 Opus
═══════════════════════════════════════════════════════
should_proceed = agent(
model="haiku",
prompt="PR #2345 是关闭状态吗?是草稿吗?我已经审查过吗?"
)
if not should_proceed:
return # 0.05 个 Opus 单位成本就省下了整个流程
═══════════════════════════════════════════════════════
Step 2:Haiku 做路径匹配(模型参数 = haiku)
═══════════════════════════════════════════════════════
claude_md_files = agent(
model="haiku",
prompt="查看 PR #2345 改了哪些文件,返回这些文件所在目录的 CLAUDE.md 路径"
)
claude_md_files = "CLAUDE.md", "src/utils/CLAUDE.md"
═══════════════════════════════════════════════════════
Step 3:Sonnet 做代码摘要(模型参数 = sonnet)
═══════════════════════════════════════════════════════
pr_summary = agent(
model="sonnet",
prompt="阅读 PR #2345 的 diff,返回变更摘要"
)
pr_summary = "新增了 auth 中间件,修改了 3 个路由文件..."
═══════════════════════════════════════════════════════
Step 4:4 个并行 Agent,核任务不同 = 模型不同
═══════════════════════════════════════════════════════
results = parallel_agents([
Sonnet × 2:规则匹配题
agent(model="sonnet", prompt=f"检查 CLAUDE.md 合规性..."),
agent(model="sonnet", prompt=f"检查 CLAUDE.md 合规性..."),
Opus × 2:深度推理题
Opus × 2:深度推理题
agent(model="opus", prompt=f"检查 diff 中的明显 Bug..."),
agent(model="opus", prompt=f"检查完整上下文中的隐藏问题..."),
])
═══════════════════════════════════════════════════════
Step 5:验证层的模型跟随
验证的模型级别 = 发现者的模型级别
═══════════════════════════════════════════════════════
for issue in bug_issues:
agent(model="opus", prompt=f"验证这个 Bug 是否真实: {issue}")
for issue in compliance_issues:
agent(model="sonnet", prompt=f"验证这个合规问题是否真实: {issue}
核心思想:按任务认知复杂度映射模型
这里的模型分层和数据库的存储分级(Hot/Warm/Cold)是同一个思想------不是所有数据都需要放在 SSD 上:

边界条件:如果某个 Agent 的任务用低一级模型也能正确完成,就不要用高一级。Step 1 用 Haiku 判断"PR
是不是关闭的"就属于这种------这个答案的复杂度不配用 Opus。
模式 4:双重独立验证 + 交叉确认
文件:plugins/code-review/commands/code-review.md 第 30-86 行
完整源码 + 注释
═══════════════════════════════════════════════════════
【第一层:双重独立发现】
4 个 Agent 并行审查同一个 PR,但分成两组、各司其职
合规组(Sonnet × 2):两个 Agent 独立检查同一件事
→ 双重覆盖,互相补充------Agent 1 漏掉的规则,Agent 2 可能发现
Bug 组(Opus × 2):两个 Agent 用不同的视野找 Bug
→ Agent 3 窄视野(只看 diff),Agent 4 宽视野(看完整上下文)
→ 一个控制误报率,一个控制召回率
═══════════════════════════════════════════════════════
- Launch 4 agents in parallel to independently review the changes.
Agents 1 + 2: CLAUDE.md compliance sonnet agents
Audit changes for CLAUDE.md compliance in parallel.
Agent 3: Opus bug agent (parallel subagent with agent 4)
Scan for obvious bugs. Focus only on the diff itself
without reading extra context.
Agent 4: Opus bug agent (parallel subagent with agent 3)
Look for problems that exist in the introduced code.
This could be security issues, incorrect logic, etc.
═══════════════════════════════════════════════════
信号质量门槛:明确规定什么才算"有效发现"
必须满足的条件(三选一):
1. 代码无法编译或解析(硬错误)
2. 无论输入如何都产出错误结果(确定性的逻辑错误)
3. 明确的、可引用具体条款的 CLAUDE.md 违规
必须排除的内容:
- 代码风格问题
- 依赖特定输入才能触发的问题(不确定性)
- 主观建议或改进意见
关键句:"If you are not certain an issue is real, do not flag it."
宁可漏报,不要误报------误报会消耗信任,增加人工审核成本。
═══════════════════════════════════════════════════════
CRITICAL: We only want HIGH SIGNAL issues. Flag issues where:
-
The code will fail to compile or parse
-
The code will definitely produce wrong results regardless of inputs
-
Clear, unambiguous CLAUDE.md violations
Do NOT flag:
-
Code style or quality concerns
-
Potential issues that depend on specific inputs or state
-
Subjective suggestions or improvements
If you are not certain an issue is real, do not flag it.
═══════════════════════════════════════════════════════
【第二层:逐一独立验证】
对第 4 步发现的每一个问题,启动一个专用 Agent 验证其真实性。
如果 4 个审查 Agent 共报告了 10 个问题 → 启动 10 个验证 Agent。
验证 Agent 拿到的是:
输入 = PR 摘要 + PR 标题描述 + 具体的问题描述
任务 = 回到代码中核实这个指控是否成立
模型跟随原则:
Bug 类问题 → Opus 验证(验证深度匹配发现深度)
合规类问题 → Sonnet 验证(规则匹配确认即可)
举例:
审查 Agent 说 "变量 userInput 未定义" → 验证 Agent 回去读代码
发现 userInput 确实在第 45 行定义了 → 判定为误报,丢弃
发现 userInput 确实没定义 → 判定为真,保留
═══════════════════════════════════════════════════════
- For each issue found in the previous step by agents 3 and 4,
launch parallel subagents to validate the issue.
Use Opus subagents for bugs and logic issues,
and sonnet agents for CLAUDE.md violations.
═══════════════════════════════════════════════════════
【第三层:交叉确认------只保留通过验证的】
过滤条件:通过第 5 步验证 = 两个独立 Agent 都确认了同一个问题
Agent A(发现者)说"这里有 Bug"
Agent B(验证者)说"我核实了,确实有" ← 才保留
被否决的(验证 Agent 说"不成立")→ 直接丢弃
═══════════════════════════════════════════════════════
- Filter out any issues that were not validated in step 5.
This step will give us our list of high signal issues for our review.
═══════════════════════════════════════════════════════
【补充:已知误报清单】
减少"看起来像 Bug 但其实不是"的情况被反复标记
═══════════════════════════════════════════════════════
Use this list when evaluating issues in Steps 4 and 5
(these are false positives, do NOT flag):
- Pre-existing issues
改之前就有的问题,不在本次审查范围内
- Something that appears to be a bug but is actually correct
看起来奇怪但有意的设计
- Pedantic nitpicks that a senior engineer would not flag
资深工程师不会提的细枝末节
- Issues that a linter will catch
Linter 能发现的,不需要 Agent 重复
- General code quality concerns unless explicitly required in CLAUDE.md
泛泛的代码质量问题,除非规范中明确要求
- Issues mentioned in CLAUDE.md but explicitly silenced in the code
规范中有规定但代码中已标注忽略的(如 lint ignore)
三级过滤拓扑图
用伪代码还原执行时的完整数据流:
═══════════════════════════════════════════════════════
第一层:双重独立发现(4 个 Agent 并行)
合规组两名"独立法官"各自审查同一套规则
Bug 组两名"侦探"用不同的搜索范围
═══════════════════════════════════════════════════════
findings = parallel_agents([
合规组:双重覆盖
agent(model="sonnet", role="合规审查 #1",
prompt="对照 CLAUDE.md 逐条检查本次变更"),
agent(model="sonnet", role="合规审查 #2",
prompt="对照 CLAUDE.md 逐条检查本次变更"),
Bug 组:互补视野
agent(model="opus", role="Bug 检测(窄)",
prompt="只看 diff,找显而易见的错误"),
agent(model="opus", role="Bug 检测(宽)",
prompt="把变更放入完整代码上下文,找隐藏问题"),
])
假设返回:
findings = [
合规发现 A, 合规发现 B, # 来自 Agent 1
合规发现 A, 合规发现 C, # 来自 Agent 2(A 被两个 Agent 独立发现)
Bug 发现 X, Bug 发现 Y, # 来自 Agent 3(窄视野)
Bug 发现 X, Bug 发现 Z, # 来自 Agent 4(宽视野,也发现了 X)
]
去重后待验证:合规 A、合规 B、合规 C、Bug X、Bug Y、Bug Z = 6 个
═══════════════════════════════════════════════════════
第二层:逐一独立验证(每个发现启动一个 Agent)
6 个发现 → 6 个并行验证 Agent
═══════════════════════════════════════════════════════
validations = parallel_agents([
agent(model="sonnet", prompt="核实:合规发现 A 是否真实?"), # → ✓ 通过
agent(model="sonnet", prompt="核实:合规发现 B 是否真实?"), # → ✗ 否决
agent(model="sonnet", prompt="核实:合规发现 C 是否真实?"), # → ✓ 通过
agent(model="opus", prompt="核实:Bug 发现 X 是否真实?"), # → ✓ 通过
agent(model="opus", prompt="核实:Bug 发现 Y 是否真实?"), # → ✗ 否决
agent(model="opus", prompt="核实:Bug 发现 Z 是否真实?"), # → ✗ 否决
])
═══════════════════════════════════════════════════════
第三层:交叉确认------只保留通过验证的
6 个发现 → 3 个确认 → 输出
═══════════════════════════════════════════════════════
confirmed = finding for finding, passed in zip(findings, validations) if passed
confirmed = 合规发现 A, 合规发现 C, Bug 发现 X
核心思想:为什么需要三层
发现层(Step 4): "我怀疑这里有 Bug" ← 倾向于假阳性(宁可错杀)
│
▼
验证层(Step 5): "我核实了,确实有" ← 独立判断(不带偏见)
"我核实了,不存在" ← 此处被否决的发现不会进入最终报告
│
▼
确认层(Step 6): 只保留两个 Agent 都同意的 ← 交集 = 高置信度
这类似于司法体系中的制衡: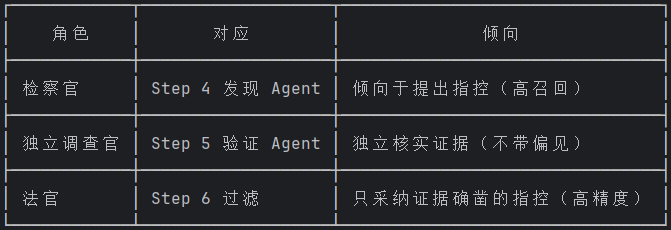
如果去掉 Step 5 验证层,Agent 3/4 发现的 6 个问题会全部进入最终报告------其中 3 个是误报。人工审查 6 个问题中发现 3
个误报 = 信任被消耗。加入验证层后,人工只需要审查 3 个确认问题。
模式 5:架构方案多样化 + 人类择决
文件:plugins/feature-dev/commands/feature-dev.md 第 57-99 行
完整源码 + 注释
═══════════════════════════════════════════════════════
【Phase 3:强制澄清------在所有歧义解决之前,不进入设计】
标注 CRITICAL: DO NOT SKIP ------ 这是结构性的强制中断
AI 最大的隐患不是能力不够,而是基于假设写代码。
这里不依赖 Claude 的"自觉",而是用流程强行制造一个停顿点。
═══════════════════════════════════════════════════════
Phase 3: Clarifying Questions
**Goal**: Fill in gaps and resolve all ambiguities before designing
**CRITICAL**: This is one of the most important phases. DO NOT SKIP.
**Actions**:
-
Review the codebase findings and original feature request
-
Identify underspecified aspects:
刻意列出一份检查清单,防止遗漏
-
edge cases # 边界情况:空输入、极限值、并发
-
error handling # 错误处理:失败了怎么办
-
integration points # 集成点:和哪些现有模块交互
-
scope boundaries # 范围边界:什么做、什么不做
-
design preferences # 设计偏好:性能优先还是可读性优先
-
backward compatibility # 向后兼容:会不会破坏现有功能
-
performance needs # 性能要求:有没有延迟/吞吐量限制
- **Present all questions to the user in a clear, organized list**
不是问"你觉得怎么样?"而是列出具体的、可回答的问题
- **Wait for answers before proceeding to architecture design**
"等待"是关键------Claude 不得在用户回答前进入 Phase 4
═══════════════════════════════════════════════════
兜底条款:如果用户说"你决定吧"
→ 提供推荐方案并获取显式确认
不能把"你决定"理解为"跳过确认环节"
═══════════════════════════════════════════════════
If the user says "whatever you think is best",
provide your recommendation and get explicit confirmation.
═══════════════════════════════════════════════════════
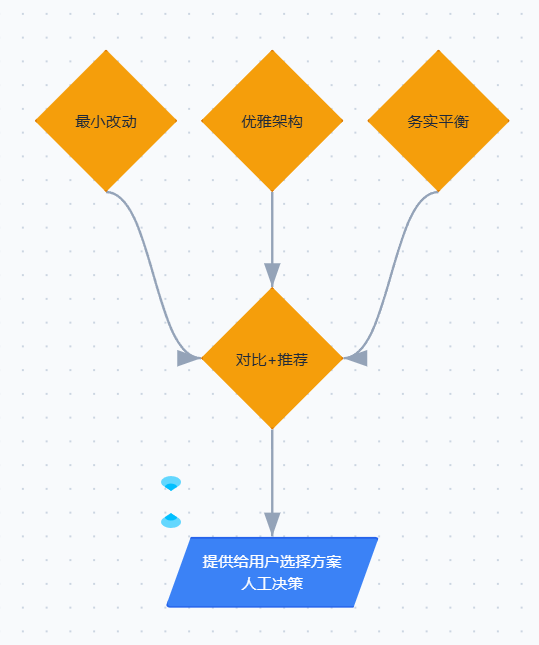
【Phase 4:架构方案多样化------三路并行生成】
核心设计:不给 Claude 一个模糊的"设计方案"指令,
而是强制它从三个不同的价值取向分别设计。
每个 Agent 拿到的是同一个需求 + 不同的设计哲学。
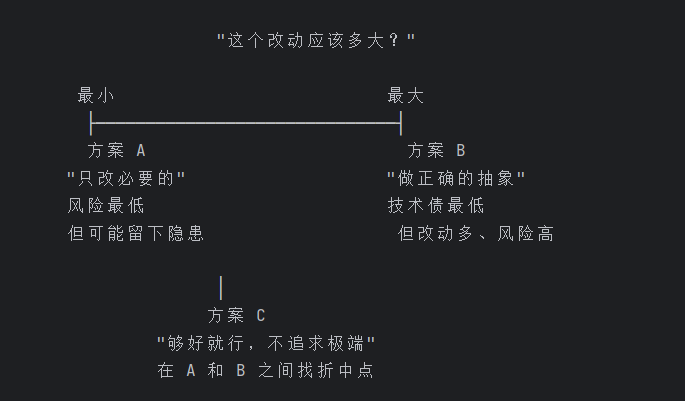
三种哲学:
Agent A "最小改动" → 最大化复用,改动最少,风险最低
Agent B "优雅架构" → 最清晰的抽象,长期可维护
Agent C "务实平衡" → 速度和质量之间找折中
═══════════════════════════════════════════════════════
Phase 4: Architecture Design
**Goal**: Design multiple implementation approaches with different trade-offs
- Launch 2-3 code-architect agents in parallel with different focuses:
Agent A:保守主义
哲学:能不改就不改,能复用就复用
适合:紧急修复、小改动、风险敏感的场景
minimal changes (smallest change, maximum reuse)
Agent B:理想主义
哲学:用最干净的方式做,即使改动多
适合:核心模块、长期维护的代码
clean architecture (maintainability, elegant abstractions)
Agent C:实用主义
哲学:够好就行,不追求完美
适合:大多数日常开发场景
pragmatic balance (speed + quality)
- Review all approaches and form your opinion on which fits best
主 Claude 作为"架构评审",对比三个方案后给出推荐
for this specific task (consider: small fix vs large feature,
urgency, complexity, team context)
- Present to user:
═══════════════════════════════════════════════════
输出格式不是"方案 A 好"一句话,
而是四个结构化部分,给人做决策所需的全部信息:
═══════════════════════════════════════════════════
- brief summary of each approach
每个方案的简要描述------几句话讲清楚核心思路
- trade-offs comparison
对比表------改多少文件、引入多少抽象、风险多大
- **your recommendation with reasoning**
推荐 + 理由------但不是命令
- concrete implementation differences
具体差异------三个方案对同一个文件的不同改法
- **Ask user which approach they prefer**
最终决策权在人手中------AI 提供方案,人做选择
═══════════════════════════════════════════════════════
【Phase 5:实现------必须等用户批准】
"DO NOT START WITHOUT USER APPROVAL" 是全文唯一的全大写禁止令
这个门禁确保 Phase 3-4 不是装饰------人必须显式说"开始"
═══════════════════════════════════════════════════════
Phase 5: Implementation
**Goal**: Build the feature
**DO NOT START WITHOUT USER APPROVAL**
**Actions**:
-
Wait for explicit user approval
-
Read all relevant files identified in previous phases
-
Implement following chosen architecture
-
Follow codebase conventions strictly
-
Write clean, well-documented code
-
Update todos as you progress
人类决择的三个断点
在整个 feature-dev 流程中,有三个显式的 Wait / Ask 断点:
═══════════════════════════════════════════════════════
断点 1:Phase 3 末尾------澄清问题后等待回答
═══════════════════════════════════════════════════════
"Present all questions to the user in a clear, organized list"
"Wait for answers before proceeding to architecture design"
═══════════════════════════════════════════════════════
断点 2:Phase 4 末尾------展示方案后等待选择
═══════════════════════════════════════════════════════
"Ask user which approach they prefer"
═══════════════════════════════════════════════════════
断点 3:Phase 5 开头------必须获得显式批准
═══════════════════════════════════════════════════════
"DO NOT START WITHOUT USER APPROVAL"
"Wait for explicit user approval"
用伪代码还原执行流
═══════════════════════════════════════════════════════
Phase 3:列出所有不确定性
═══════════════════════════════════════════════════════
questions = [
"这个功能需要支持多语言吗?",
"并发访问时,写操作应该加锁还是乐观重试?",
"错误时回滚到调用前状态,还是允许部分成功?",
"需要向后兼容 v1 版本的 API 格式吗?",
"预期峰值 QPS 是多少?需要单独做缓存层吗?",
]
输出给用户,然后 ------ 停止。不做任何操作。等待回答。
present_to_user(questions)
wait_for_user_response()
═══════════════════════════════════════════════════════
Phase 4:三路并行架构设计
═══════════════════════════════════════════════════════
architectures = parallel_agents([
agent(prompt="""
需求:{feature_description}
约束:{user_answers_from_phase3}
设计哲学:最小改动。
原则:能复用就不新建,能继承就不重写。
输出:改动方案 + 涉及文件清单 + 风险预估。
"""),
agent(prompt="""
需求:{feature_description}
约束:{user_answers_from_phase3}
设计哲学:优雅架构。
原则:用最干净的抽象,即使改动更多文件。
输出:类图/模块划分 + 接口定义 + 扩展性分析。
"""),
agent(prompt="""
需求:{feature_description}
约束:{user_answers_from_phase3}
设计哲学:务实平衡。
原则:在交付速度和代码质量之间找最优折中。
输出:分阶段实施计划 + 技术债清单 + 各阶段交付物。
"""),
])
主 Claude 对比三个方案,形成推荐意见
recommendation = compare(
architectures,
criteria="改动量", "风险", "可维护性", "扩展性", "实施时间"
)
对人展示:
方案 A(最小改动):改 2 个文件,1 天,风险低,但扩展性差
方案 B(优雅架构):改 8 个文件,3 天,引入 2 个新抽象,风险中
方案 C(务实平衡):改 4 个文件,2 天,预留扩展点,风险低
推荐:方案 C,因为......
present_to_user(architectures, recommendation)
choice = wait_for_user_choice()
人选择 "方案 C" 或 "方案 B,但合并方案 A 的错误处理方式"
═══════════════════════════════════════════════════════
Phase 5:必须等人说"开始"
═══════════════════════════════════════════════════════
wait_for_explicit_approval()
人输入 "开始" / "go ahead" / "按方案 C 实现"
implement(choice)
核心思想:为什么不让 AI 自动选
三个方案的设计哲学不是随意的------它们分别回答了同一个问题的三个极端:
为什么人必须参与决策:AI 不知道团队的上下文------下周有没有发布窗口、这个模块有没有专职
owner、技术债有没有预留配额、团队对新抽象的接受度如何。这些信息不在代码里,只在人的脑子里。三个方案 +
对比表的作用,是把人的隐性知识激活为决策依据。