《Java版数据结构 & 集合类剖析》集合框架的封装设计与顺序表:"从 Iterable 到 ArrayList:集合框架的'职业树"
前情提要: 本篇先会对集合框架的封装和设计进行初步的理解,其实适合对数据结构有一定基础的读者,但是为了文章的整体安排,我放到了这里进行讲解,如果是数据结构小白可以直接跳转到顺序表的部分
1、集合框架
在具体介绍之前,我们先要对集合框架、集合类、容器,这三个名词进行解释
- 这三个名词经常进行混在一起用,如果不那么严格来说他们的意思就是集合这一套东西,但严格的来说他们的边界还是有所不同的
- 容器:只要能装对象的,都算。
- 集合框架:Java 官方设计的那一整套层次分明的接口和实现。
- 集合类:集合框架里那些真正干活的、可以 new 出来的具体类。
集合框架的树形关系图如下:
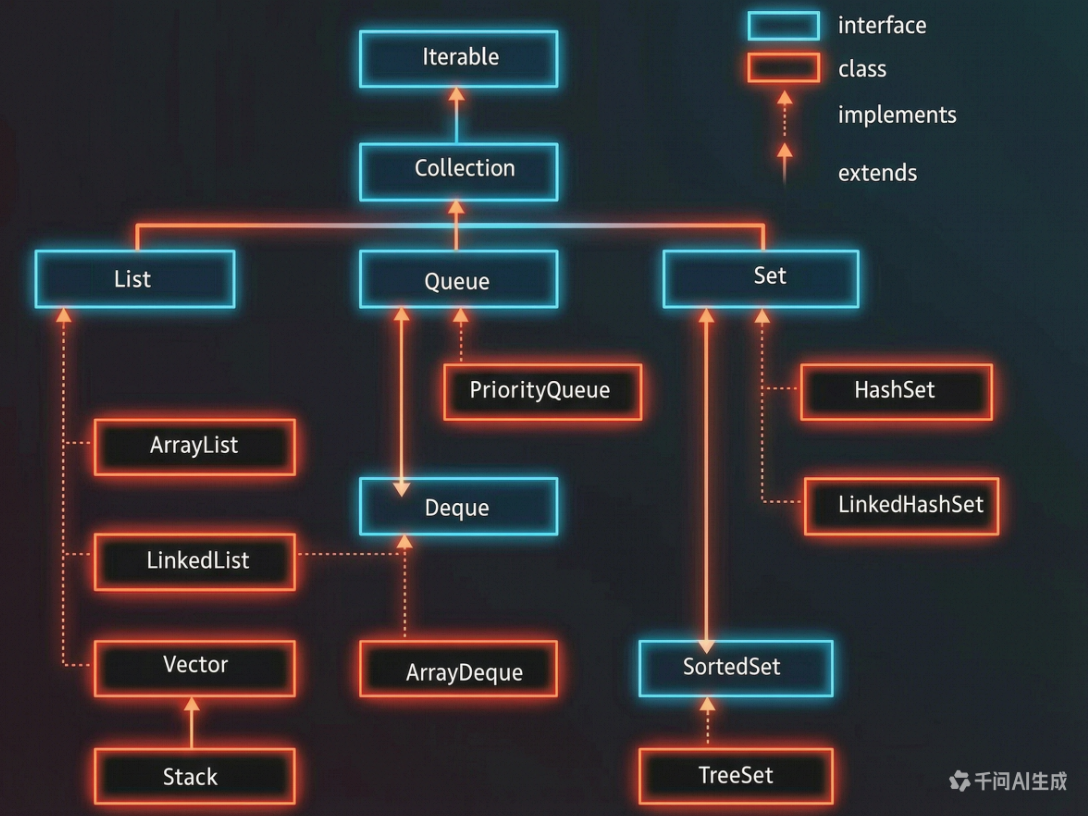
1.1、顶层接口Iterable
如上图所示,Iterable接口就是整个集合框架的顶层,为什么它要作为顶层呢?因为所有的容器本身都需要提供遍历的功能 ,我们不希望每一个不同的容器都以不同的方式来进行遍历,这样就能避免了使用这些容器的学习成本很高的情况。所以集合框架这一套的顶层接口就是Iterable,负责统一迭代器的实现。
如下就是该接口的源码:
java
package java.lang;
import java.util.Iterator;
import java.util.Objects;
import java.util.Spliterator;
import java.util.Spliterators;
//支持lambda函数接口
import java.util.function.Consumer;
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
//进行遍历操作
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}在下面对其进行分段讲解其中的含义:
java
public interface Iterable<T> {
//接口方法
Iterator<T> iterator();
//该接口类中的一个方法
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action); //判断传入的action是否为null
//进行遍历操作
for (T t : this) {
action.accept(t);
}
}
}- 如上Iterator iterator(); 是该接口类中的 唯一一个接口方法 ,它不提供具体实现,而是强制所有子类必须实现这个方法,返回一个属于自己的迭代器。
- default void forEach(Consumer<? super T> action) 它不需要子类强制重写 ,就能为所有 Iterable 的实现类提供一个通用的遍历操作入口 。它的参数是 Consumer<? super T>,表示接收一个消费型操作 (只接收数据做处理、不返回结果的行为)。这个方法允许你把"要对每个元素做什么"作为参数传入,而遍历的逻辑已经帮你封装好了。
- Objects.requireNonNull(action); 该方法判断接收到的参数action是否是null,若为 null 则立即抛出NullPointerException
- action.accept(t); action 是一个 Consumer 对象,accept 是它的唯一抽象方法,具体这个方法做什么,由调用者通过lambda表达式来提供
科普:函数式接口:有且仅有一个抽象方法的接口(它的实例可以用 Lambda 表达式 或 方法引用 来快速创建,而不必写匿名内部类。)
java
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}- 如上,spliterator() 是 Iterable 接口的默认方法,提供基础的可分割迭代器,让集合能快速对接 Stream API,这里不对其进行分析
接下来我们在对其源码继续分析:
上面的iterator()这个接口方法中主要有以下两个方法
java
boolean hasNext();
E next();具体的实现逻辑我们以ArrayList中的迭代器来简单了解一下
java
private class Itr implements Iterator<E> {
int cursor; // 下一个要返回的元素的索引
int lastRet = -1; // 上一次返回的元素的索引,-1 表示没有
public boolean hasNext() {
return cursor != size; // size 是 ArrayList 的元素个数
}
public E next() {
if (cursor >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData; // 内部数组
if (cursor >= elementData.length)
throw new ConcurrentModificationException();
lastRet = cursor;
return (E) elementData[cursor++]; // 返回当前元素,游标后移
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
ArrayList.this.remove(lastRet); // 调用集合自身的 remove
cursor = lastRet; // 游标回退
lastRet = -1;
}- 可以看到迭代器的逻辑是通过控制cursor 和lastRet这两个成员变量来实现的
- hasNext() 方法用来判断元素是否遍历结束
- next() 用来返回当前元素,并将游标推进到下一位
- remove() 方法用来删除上一次 next() 返回的元素,这个位置由 lastRet 记录
1.2、 Collection接口
下面直接给出该接口的源码
java
package java.util;
import java.util.function.Predicate;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean removeAll(Collection<?> c);
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(Collection<?> c);
void clear();
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}- Collection翻译过来就是集合的意思,在上面的一些接口方法中,许多都是由Collection来作为参数接收的,目的就是接收某一个容器对象来进行操作
- Collection中提供的规范接口方法属于最通用的几个 ,越往下层的接口就越精细化,直到某个类进行具体的实现。
以下是首先我们需要掌握的Colleciton的接口方法 :
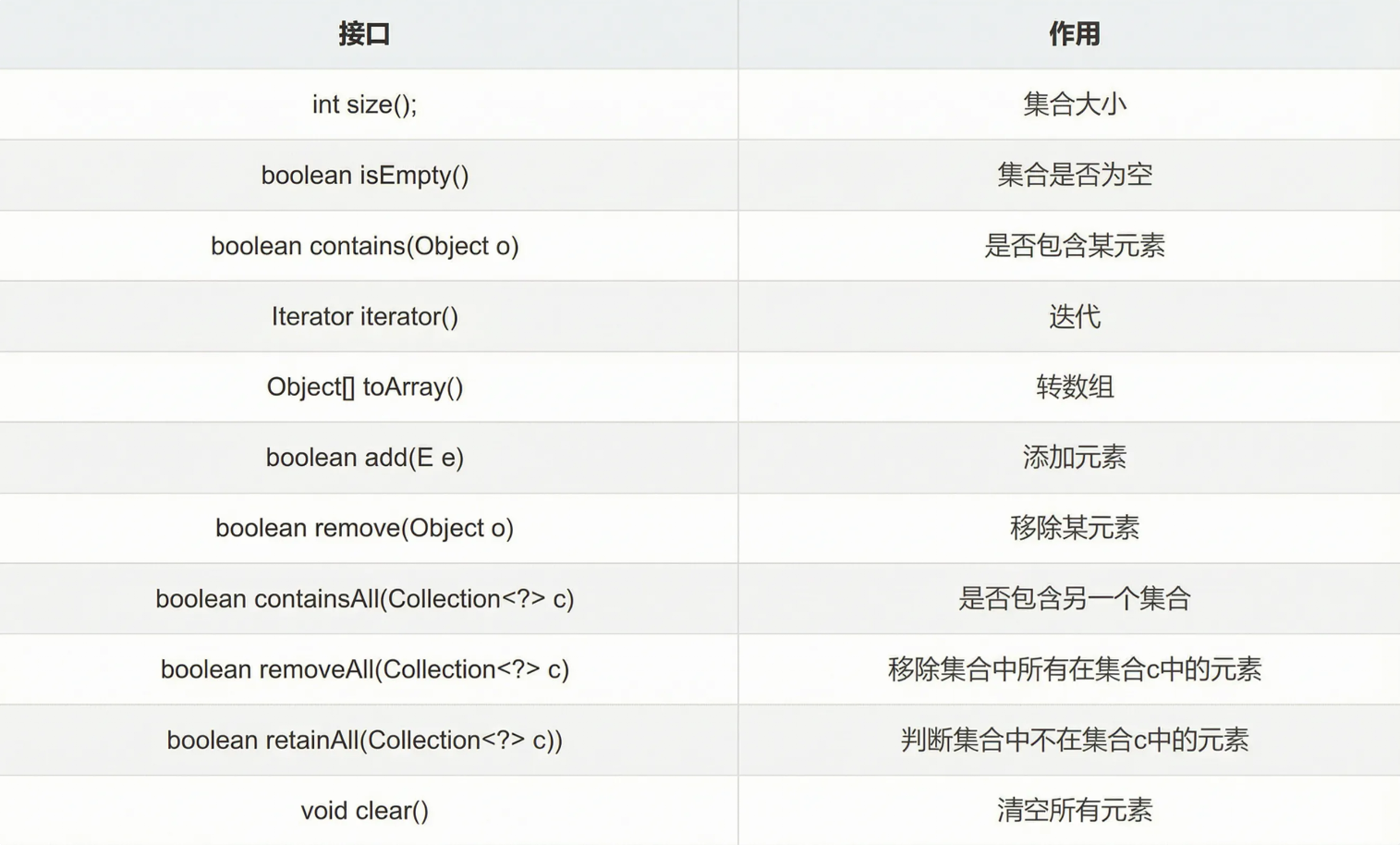
2、List接口
源码如下:
java
package java.util;
import java.util.function.UnaryOperator;
public interface List<E> extends Collection<E> {
<T> T[] toArray(T[] a);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
default void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final ListIterator<E> li = this.listIterator();
while (li.hasNext()) {
li.set(operator.apply(li.next()));
}
}
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
ListIterator<E> i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
boolean equals(Object o);
E get(int index);
E set(int index, E element);
void add(int index, E element);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
List<E> subList(int fromIndex, int toIndex);
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.ORDERED);
}
}- 可以看到List其实比Collection多了添加方法 add 和 addAll 查找方法 get , indexOf , set 等方法,并且支持index下标操作。
这里对List 和 Collection 两个接口进行对比:
- Collection是无序 的(默认你的物理空间不连续),不支持索引操作
- List中的迭代器为ListIterator ,Collection中的迭代器是普通的iterator
- List可以进行排序,所以List接口支持使用sort方法。
- 二者的Spliterator操作方式不一样。
3、ArrayList
接下来我会按五个模块讲解ArrayList的相关内容,先对其封装设计 进行分析,然后掌握其常用方法的使用 ,接着进行源码剖析 ,再对其进行模拟实现 、最后总结这类数据结构的特点。
3.1、ArrayList封装设计
ArrayList类使用的是顺序表(Sequential List)这个数据结构实现的。
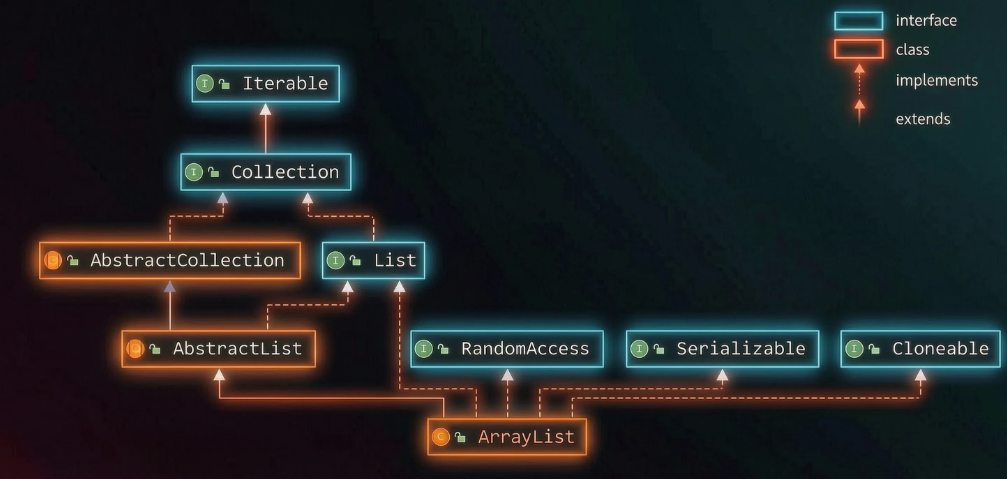
以上是 ArrayList 所继承的类和所实现的接口的图,以下是对这样设计进行分析:
- AbstractCollection 这个类就是把Collection中的部分简单接口,对与其有关的集合类容器逻辑完全相同的方法先实现了,避免后面重复实现
- AbstractList类就是更加精细化,在上面这个类的基础上有实现了list接口,还是避免后面具体的类重复实现。
- RandomAccess 接口相当于急速索引的通行证,众所周知,ArrayList的遍历、尾插的时间复杂度为O(1),其中就是因为,它实现了RandomAccess,支持快速的随机访问,获取元素的速度就是O(1).
- Serializable 接口提供了序列化标记 ,通俗的说,当我们写完代码,会将它存入硬盘,或者通过网络传输到某个服务器,有些协议必须会让你把代码转为二进制,那么有了这个接口的实现,就相当于给对象安装了一个"打包字节流的开关"
- Cloneable 接口在前面介绍过,默认支持实现类的浅拷贝。
3.2、ArrayList常用方法
3.2.1、ArrayList的构造
| 方法 | 解释 |
|---|---|
ArrayList() |
无参构造 |
ArayList(Collectino<? extends E> c) |
利用其它的容器构造ArrayList |
ArrayList(int initialCapacity) |
指定顺序表的初始容量 |
java
import java.util.ArrayList;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
// 1. 无参构造
List<String> list1 = new ArrayList<>();
list1.add("A");
list1.add("B");
System.out.println("无参构造: " + list1);
// 2. 利用其他集合构造
ArrayList<String> list2 = new ArrayList<>(list1);
System.out.println("复制构造: " + list2);
// 3. 指定初始容量
ArrayList<Integer> list3 = new ArrayList<>(20);
list3.add(100);
System.out.println("指定容量构造(当前大小): " + list3.size());
}
}注意:
- 第二个用容器来构造对象,只能是同样实现了Collection接口的容器才可以,如果是实现了Map接口的容器不能用来构造ArrayList对象,例如HashMap
- 我们接收该创建好的对象既可以用ArrayList<>,也可以用List<>来接收(因为ArrayList实现了List接口)这两种接收方式带来的也有一些差别:
- 用ArrayList接收:可以用所有的ArrayList的方法,但是灵活性不高,耦合度高。总的来说只有需要调用ArrayList特有方法,时才考虑用ArrayList<>来进行接收
- 用List接收:代码灵活度高,方便更换底层实现,耦合度降低,不影响ArrayList的随机访问的特性。总的来说大部分情况下推荐用List来接收
List用来接收的优势具体用代码理解:
- 面向接口编程,提高代码灵活性
- 可以轻松更换底层实现:后续若需改用 LinkedList、Vector 或其他 List 实现,只需修改右边 new 的部分,左边无需改动。例如:
javaList<String> list = new LinkedList<>(); //只需改这一处
- 降低耦合,符合依赖倒置原则
- 方法参数、返回值如果定义为 List 接口,则不依赖具体实现类,调用方可以传入任何 List 实现 ,使代码更通用。
javapublic void process(List<String> list) { ... } // 好 public void process(ArrayList<String> list) { ... } // 差,限制了调用方
- 在Java中,这些容器中的容量大小只能通过反射来得到,正常我们只能获得元素的个数。
3.2.2、ArrayList的其它常见操作
| 方法 | 解释 |
|---|---|
boolean add(E e) |
尾插 e |
void add(int index, E element) |
将 e 插入到 index 位置 |
boolean addAll(Collection<? extends E> c) |
尾插 c 中的元素 |
E remove(int index) |
删除 index 位置元素 |
boolean remove(Object o) |
删除遇到的第一个 o |
E get(int index) |
获取下标 index 位置元素 |
E set(int index, E element) |
将下标 index 位置元素设置为 element |
void clear() |
清空 |
boolean contains(Object o) |
判断 o 是否在线性表中 |
int indexOf(Object o) |
返回第一个 o 所在下标 |
int lastIndexOf(Object o) |
返回最后一个 o 的下标 |
List<E> subList(int fromIndex, int toIndex) |
截取部分 list |
3.2.3、ArrayList的遍历
ArrayList可以用三种方式遍历:for循环 +下标,foreach、使用迭代器
java
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ArrayListTraverseDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
// 1. for循环 + 下标
System.out.println("for循环 + 下标:");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// 2. foreach(增强for循环)
System.out.println("\nforeach:");
for (String s : list) {
System.out.println(s);
}
// 3. 迭代器
System.out.println("\n迭代器:");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}- 以上可以看到,java集合中没有像数组的\[\] 这种下标访问 ,所以当我们在写一些算法题时想用\[\]访问,可以把它转为数组:用String\[\] s1 = list.toArray(new String0) 这种方式转转换(前提是该数组元素不是基本类型,不然只能手动循环转换)
- 其中我们最常使用的是 for 与 增强for 的迭代方式
- 增强for的底层就是用迭代器实现的
- 原生迭代器在删除元素、低效随机访问集合、通用遍历等方面更便捷。在日常开发中,若需要增删或操作复杂逻辑 ,显式使用迭代器是更好的选择。
3.3、ArrayList 源码剖析
这里我们仅仅只对部分源码进行分析,重在掌握其核心功能的思想,其它不重要的有兴趣可自行了解
3.3.1、 ArrayList的核心成员变量:
java
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
//真正存放元素的数组
transient Object[] elementData; // non-private to simplify nested class access
private int size;
private static final int DEFAULT_CAPACITY = 10;-
EMPTY_ELEMENTDATA 和 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 这两个静态空数组常量,是用在ArrayList的扩容机制上的,两个都表示初始常量为空 的情况来做标记,分成两种是因为他们为空的两种不同原因,第一个是由指定构造容量为 0 时进行标记(List list1 = new ArrayList<>(0) ),第二个是由默认构造 无任何指定 导致的初始容量为 0 进行标记(List list1 = new ArrayList<>()),具体到后面扩容机制再讲
-
elementData 数组就是真正存放元素的数组,可以看到 它被一个很少见的关键字进行修饰:transient:它的作用是被修饰的字段不参与序列化
- 为什么不参与序列化呢? 上面讲到的Serializable接口 提供的序列化在该数组的实现上有问题,因为elementData的实际内容长度并不确定,大部分时候该数组后面很多都是空 ,那么直接进行序列化会导致那些空也被序列化,造成各种资源浪费(内存上,时间上,cpu上,网络传输时的带宽上)
- 因此ArrayList 自己实现了 writeObject 和 readObject 方法,只序列化 [0, size) 范围内的有效元素,反序列化时再重新分配数组
-
最后的那个静态常量是 默认的容量 源码中设为 10
3.3.2、ArrayList的构造函数
三种构造源码如下:
java
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}- 默认构造: 可以看到,直接赋值了上面定义的静态常量数组进行标记,后续的扩容逻辑会用到
- 容器构造 :可以看到,先将传过来的容器转为数组,看元素是否为空,再判断传入的容器类型和自身的类型是否相同 是否都是ArrayList类 (为了数组运行时类型是否相等,因为ArrayList中的数组运行时类型为Object 而像 HashSet 等容器的数组运行时类型可能为 String 类型) 如果相同则直接赋值,如果不相同则用Arrays.copyOf()方法处理再赋值。
- 指定构造 :对传入指定的容量进行判断,如果指定为0 则用开头的静态常量进行标记,不为0直接new数组对象即可。
3.3.3、ArrayList的扩容机制
ArrayList的扩容机制在JDK8前后有写区别,这里我按照的是JDK17版本的扩容机制来分析:
- 首先增加元素来触发扩容机制,这里以add()方法举例:
java
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}- 注意ArrayList中有一个modCount的成员变量,表示该实例修改的次数。(所有集合中都有modCount这样一个记录修改次数的成员变量),每次增改添加都会增加一次ArrayList修改次数
- 私有的重载add方法:
java
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) // 判断数组是否已满
elementData = grow(); // 扩容(无参grow,默认minCapacity = s+1)
elementData[s] = e;
size = s + 1;
}- 扩容核心:grow() 方法:
java
// 无参版本,默认最小容量为当前size+1
private Object[] grow() {
return grow(size + 1);
}
// 真正的扩容方法
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 情况1:不是首次添加(或已经扩容过)
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, // 最小增长量
oldCapacity >> 1 // 首选增长量(0.5倍)
);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
// 情况2:首次添加,且使用无参构造(elementData是空数组)
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
// DEFAULT_CAPACITY = 10
}
}- 工具类 ArraysSupport 中的newLength 提供新的容量的计算
java
// 返回新数组长度
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // 首选长度
if (0 < prefLength && prefLength <= MAX_ARRAY_LENGTH) {
return prefLength; // 正常情况:1.5倍左右
} else {
// 处理超大容量或溢出
return hugeLength(oldLength, minGrowth);
}
}- 这里的逻辑就是将至少要增加的容量 和 固定的 0.5倍扩容容量 来比较,哪个大就按哪个来算新增加的容量
3.3.4、ArrayList中的SubList:一个轻量的"子列表视图"
SubList中的ArrayList的一个非静态内部类 ,它不存储数据 ,而是作为原列表的某段连续区间的"视图"存在。通过subList(fromIndex, toIndex) 方法返回的就是这个内部类的实例。
为什么称这个叫做视图:
- 不对数据进行复制:SubList 内部没有自己的数组,而是通过成员变量root(原始ArrayList)、offset(起始偏移量)、size(区间长度)来表示某一段区间
- 对视图的操作会映射到原列表:对SubList对象的增删改查也会影响到原列表
SubList 的核心成员:
java
private final ArrayList<E> root; // 最底层的原始 ArrayList
private final SubList<E> parent; // 上一级视图(支持嵌套)
private final int offset; // 本视图第一个元素在 root 中的绝对索引
private int size; // 本视图的元素个数其余的源码不进行介绍,其它的核心方法的在下面的模拟实现中体现,去除了复杂的设计封装,更易理解于体会。
3.4、ArrayList的模拟实现
以下是整个模拟实现,后面分段进行分析
MyArrayList 类:
java
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Objects;
public class MyArrayList<T> implements IList<T>{
private Object[] elementData;
static final int DEFAULT_CAPACITY = 10;
int usedSize = 0;
public MyArrayList() {
elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayList(Collection<? extends T> c){
Object[]a = c.toArray();
int size = a.length;
if(size != 0){
elementData = Arrays.copyOf(a,size,Object[].class);
}else{
elementData = new Object[DEFAULT_CAPACITY];
}
}
public MyArrayList(int InitialSize){
elementData = new Object[InitialSize];
}
private void checkPos(int pos){
if(pos < 0 || pos > usedSize){
throw new PosIllegal("越界访问");
}else{
return;
}
}
private boolean isFull(){
return usedSize == elementData.length;
}
@Override
public void add(T data) {
if(isFull()){
grow();
}
elementData[usedSize] = data;
usedSize++;
}
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity == 0 ? DEFAULT_CAPACITY : oldCapacity * 2;
elementData = Arrays.copyOf(elementData, newCapacity);
}
@Override
public void add(int pos, T data) {
try {
checkPos(pos);
if(isFull()){
grow();
}
for (int i = usedSize - 1; i >= pos; i++) {
elementData[i + 1] = elementData[i];
}
elementData[pos] = data;
usedSize++;
}catch (PosIllegal e){
e.printStackTrace();
throw new IndexOutOfBoundsException("插入位置非法: " + pos);
}
}
@Override
public boolean contains(T toFind) {
for (int i = 0; i < usedSize; i++) {
if (Objects.equals(elementData[i], toFind)) {
return true;
}
}
return false;
}
@Override
public int indexOf(T toFind) {
for (int i = 0; i < usedSize; i++) {
if (Objects.equals(elementData[i], toFind)) {
return i;
}
}
return -1;
}
private void checkPosForAccess(int pos) {
if (pos < 0 || pos >= usedSize) {
throw new IndexOutOfBoundsException("访问位置非法: " + pos);
}
}
@Override
public T get(int pos) {
try {
checkPosForAccess(pos);
return (T) elementData[pos];
}catch (PosIllegal e){
e.printStackTrace();
throw new IndexOutOfBoundsException("获取元素位置非法:" + pos);
}
}
private void setCheckpos(int pos){
if(pos < 0 || pos >= usedSize){
throw new PosIllegal("set 位置不合法 "+ pos);
}
}
@Override
public void set(int pos, T data) {
try{
//java中的数组禁止隔空插入数据
setCheckpos(pos);
elementData[pos] = data;
usedSize++;
}catch (PosIllegal e){
e.printStackTrace();
throw new IndexOutOfBoundsException();
}
}
@Override
public void remove(T del) {
int aim = -1;
for (int i = 0; i < usedSize; i++) {
if(elementData[i].equals(del)){
aim = i;
break;
}
}
if(aim != -1){
for (int i = aim; i < usedSize - 1; i++) {
elementData[i] = elementData[i + 1];
}
usedSize--;
elementData[usedSize] = null;
}else{
return;
}
}
@Override
public void clear() {
for (int i = 0; i < usedSize; i++) {
elementData[i] = null;
}
usedSize = 0;
}
@Override
public void display() {
for (int i = 0; i < usedSize; i++) {
System.out.println(elementData[i] + " ");
}
}
@Override
public int size() {
return usedSize;
}
@Override
public void addFirst(T data) {
if(isFull()){
grow();
}
for (int i = usedSize; i > 0; i++) {
elementData[i] = elementData[i - 1];
}
elementData[0] = data;
usedSize++;
}
@Override
public void removeFirst() {
if (usedSize < 1){
return;
}
for (int i = 0; i < usedSize - 1; i++) {
elementData[i] = elementData[i + 1];
}
elementData[usedSize - 1] = null;
usedSize--;
}
@Override
public void removeLast() {
elementData[usedSize - 1] = null;
usedSize--;
}
}IList接口:
java
public interface IList<T> {
//尾插元素
public void add(T data);
//指定插入元素
public void add(int pos,T data);
//判定是否包含元素
public boolean contains(T data);
//查找某个元素对应的位置
public int indexOf(T toFind);
//读取某个位置的元素
public T get(int pos);
//与数组中某个位置的值进行替换
public void set(int pos,T data);
//删除指定元素
public void remove(T del);
//清空顺序表
public void clear();
//打印顺序表
public void display();
//返回元素个数
public int size();
//额外拓展 :
//头插元素
public void addFirst(T data);
//头删元素
public void removeFirst();
//尾删元素
public void removeLast();
}
}PosIllegal类:
java
public class PosIllegal extends IndexOutOfBoundsException{
public PosIllegal(){}
public PosIllegal(String msg){
System.out.println(msg);
}
}可以看到我上面还写了IList接口,注意实现泛型时接口后面也要跟< T >
javapublic class MyArrayList<T> implements IList<T>{ private Object[] elementData; static final int DEFAULT_CAPACITY = 10; int usedSize = 0; }
- 这三个分别指,存放元素的数组,默认的容量,已被使用的空间个数
构造方法跳过,逻辑和源码差不多,直接看重点:
javaprivate void checkPos(int pos){ if(pos < 0 || pos > usedSize){ throw new PosIllegal("越界访问"); }else{ return; } } private boolean isFull(){ return usedSize == elementData.length; } @Override public void add(T data) { if(isFull()){ grow(); } elementData[usedSize] = data; usedSize++; } private void grow() { int oldCapacity = elementData.length; int newCapacity = oldCapacity == 0 ? DEFAULT_CAPACITY : oldCapacity * 2; elementData = Arrays.copyOf(elementData, newCapacity); } @Override public void add(int pos, T data) { try { checkPos(pos); if(isFull()){ grow(); } for (int i = usedSize - 1; i >= pos; i++) { elementData[i + 1] = elementData[i]; } elementData[pos] = data; usedSize++; }catch (PosIllegal e){ e.printStackTrace(); throw new IndexOutOfBoundsException("插入位置非法: " + pos); } }
- 实现数据插入时我们首先要关注两点:插入的位置是否合理, 空间是否足够
- 在上面的尾插方法中,没有pos指针所以我们只需考虑空间是否足够。
- 用isFull()方法判断空间是否已满 来选择是否调用grow()方法开辟内存空间
- 在java中严格来说是没有手动开辟内存空间的方法的,内存空间的分配其实是由C/C++的本地方法实现的,所以这里只能用数组工具包中的方法Arrays.copyOf()来复制数组 ,顺便给一个新的内存空间长度来实现扩容。
- 在插入完数据要记得更新usedSize 属性
- 在实现指定位置插入时,除了前面提到的两点,还需要将 pos 之后的所有元素往后移动一位 。这个操作虽简单,但细节很容易出错。分享一个小技巧:
- 视角一:循环变量 i 表示"要移动的数据 "
那么 i 从最后一个元素(usedSize - 1)开始,递减到 pos 位置,依次将 elementDatai 赋值给 elementDatai + 1。- 视角二:循环变量 i 表示"移动后的目标位置 "
那么 i 从 usedSize 开始,递减到 pos + 1 位置,依次将 elementDatai - 1 赋值给 elementDatai。
javapublic void clear() { for (int i = 0; i < usedSize; i++) { elementData[i] = null; } usedSize = 0; }
- 这里的clear()方法是清理顺序表,将引用置空,方便jvm进行垃圾回收
javapublic T get(int pos) { try { checkPosForAccess(pos); return (T) elementData[pos]; }catch (PosIllegal e){ e.printStackTrace(); throw new IndexOutOfBoundsException("获取元素位置非法:" + pos); } } private void setCheckpos(int pos){ if(pos < 0 || pos >= usedSize){ throw new PosIllegal("set 位置不合法 "+ pos); } } @Override public void set(int pos, T data) { try{ //java中的数组禁止隔空插入数据 setCheckpos(pos); elementData[pos] = data; usedSize++; }catch (PosIllegal e){ e.printStackTrace(); throw new IndexOutOfBoundsException(); } }
- Java中的集合类没有像C++中的运算符重载机制,所以我们从外部获取某个位置的元素 或者将元素写入某个位置 不能考\[\]符号来进行。因此我们要实现get
和set 方法:- 实现get 方法 首先还是看下标是否合理 ,然后直接用数组下标索引直接返回,没有遍历过程,效率相当高,时间复杂度只有O(1)
- 实现set方法,我们还是先检查下标合理 ,然后直接数组索引定位进行修改,时间复杂度也为O(1)
- 由此可见,顺序表这个数据结构"查"的效率是非常高的
javaint aim = -1; for (int i = 0; i < usedSize; i++) { if(elementData[i].equals(del)){ aim = i; break; } } if(aim != -1){ for (int i = aim; i < usedSize - 1; i++) { elementData[i] = elementData[i + 1]; } usedSize--; elementData[usedSize] = null; }else{ return; } }
- 上面是删除数据的实现,可以看到其中有两次遍历,第一是查找是否存在要删除的数据,第二次遍历是覆盖挪动数据。
除了这个删除方法,我还拓展了以下两种java中不提供的删除方法:头删和尾删
javapublic void removeFirst() { if (usedSize < 1){ return; } for (int i = 0; i < usedSize - 1; i++) { elementData[i] = elementData[i + 1]; } elementData[usedSize - 1] = null; usedSize--; } @Override public void removeLast() { elementData[usedSize - 1] = null; usedSize--; }
- 可以看到这里两种删除,头删的时间复杂度尾O(N) ,尾删的时间复杂度为O(1)。明显尾删的效率远远高于头删,因为头删还要挪动数据。
下面我也拓展了头插:
javapublic void addFirst(T data) { if(isFull()){ grow(); } for (int i = usedSize; i > 0; i++) { elementData[i] = elementData[i - 1]; } elementData[0] = data; usedSize++; }
- 可以看到头插的复杂度也高于尾插
3.5、顺序表性质:
3.5.1、基本定义
- 顺序表 是一种线性表 ,采用一组地址连续的存储单元依次存储数据元素。
- 逻辑上相邻的元素 ,在物理内存中也相邻(数组实现)。
- Java 中的典型代表:ArrayList、Vector
3.5.2、顺序表的优点:
-
随机访问快:通过下标访问元素的时间复杂度为 O(1)。
-
契合CPU的缓存行机制,CPU会一次性将连续的内存块(缓存行)加载到高速缓存中,顺序表的物理空间连续,所以正好让缓存的命中率变得很高
-
尾部操作高效:尾插、尾删(均摊 O(1))。
3.5.3、顺序表的缺点
-
中间/头部操作慢:插入或删除需要移动大量元素,平均 O(n)。
-
空间浪费:实际元素个数可能远小于数组容量(尤其是频繁扩容后)。
-
扩容成本高:扩容时需要复制整个数组,且可能造成内存碎片(JVM 中影响较小)。
- 总的来说顺序表比较适合 "查" 操作比较多的情况,插入和删除操作多的情况,不适合用顺序表